Как создать внутреннюю базу знаний для большой IT-компании. Из хаоса в гиперспейсы

Когда на вопрос «Что за фича?» сказали: «Посмотри в Confluence!»
Привет! Меня зовут Таня Дудо, я менеджер продуктовых знаний в Selectel. В тексте расскажу, как решили создать внутреннюю базу знаний о продуктах и процессах для более 800 человек. Опишу, как к этому пришли, кропотливо выуживали важную доку из массива данных и придумали решение — гиперспейсы.
Мы развиваем базу знаний на Confluence, но подходы и решения, описанные в тексте, могут быть полезны в работе с другими площадками. Мемы и уроки из опыта — под катом.
Дисклеймер: Работа над созданием и развитием внутренней базы знаний в Selectel еще идет — это буквально эксперимент в режиме реального времени. Поэтому этот текст — первая серия моего рассказа. В нем разложу по полочкам, как разрабатывали архитектуру и внедряли новые процессы, работали с подводными камнями и побочными задачами. Сначала было «вау», потом совсем не «вау», а потом снова «вау».
С чем можно сравнить работу по созданию внутренней БЗ? Разбор статей похож на добычу полезных ископаемых. Выуживание важных материалов из огромного массива данных — на промывание песка в поисках золота. Категоризация и обязательные артефакты похожи на составление карты путешествия. Работа с фидбеком — на западню, в которую тебя заманили добрые существа, а потом решили прикончить. А в конце… впрочем, до конца нам еще предстоит дойти.
Почему мы решили, что нам скучно живется нужна единая база знаний
В любой компании есть внутренняя документация. Ее содержание зависит от специфики и сферы. Например, в продуктовых командах перед запуском продукта накапливают информацию о целевой аудитории и проблемах, собирают прототипы, проводят интервью с клиентами, описывают функциональности и много чего еще.
Когда команда небольшая, знания и документация циркулируют по компании естественным образом: самой доки не так уж и много. Все в курсе, что происходит с продуктом и где (или у кого) можно найти ответ на интересующий вопрос. Со временем компании начинают расти, вместе с ними растет продукт, появляются новые сервисы. Документации становится больше, а команды уже не так часто говорят обо всех деталях на кофе-поинтах или общих встречах.
В общем, знания о продуктах начинают накапливаться стихийно. Энтузиасты пытаются сохранять и передавать знания, но у них редко хватает ресурса создавать что-то общее для всех команд.
В итоге стихийная база знаний становится похожа на библиотеку, в которой на корешках книг нет названий, библиотекарь ушел в запой, а старожилы имеют только примерное представление о том, где лежит книга, которая очень нужна прямо сейчас.
В какой-то момент тема актуальности передачи внутренних знаний «заболела» и у нас в Selectel. Мы знаем, как создавать подробную и классную документацию для клиентов, но вот внутреннюю вели не всегда с такой педантичностью.
Чем больше становилась команда, тем важнее было наладить процессы в передаче знаний. И если внутри продуктовых команд и продуктового департамента регулярные синхроны помогали поддерживать обмен знаниями на приемлемом уровне, то сервисные команды — вроде ИТО (инженерно-технического отдела), техподдержки и продаж — закапывались в обилии и разнородности документации и не всегда могли быстро найти ответы на свои вопросы. А это напрямую влияло на скорость решения задач.
Настал момент, когда нужно выделить ресурсы и сделать удобную внутреннюю базу знаний с логичной и масштабируемой структурой. С ее помощью мы сохраним уже накопленные знания и будем легко находить нужную информацию в будущем.

Что было дальше
Начали с масштабного анализа того, что уже есть в Confluence.
- Пообщались с теми, кто пишет доку. Разбирались, по какой логике они складывают ее в свои пространства сейчас, как передают знания в сервисные подразделения, как следят за актуальностью и работают с обратной связью, если документы непонятные.
- Пообщались и с теми, кто ее читает. Узнали, как они ищут информацию сейчас, что делают, если не находят ее, куда передают фидбек или запрос на новую статью.
Этот этап занял три недели: провели больше 15 встреч с продуктовыми и 4 встречи с сервисными командами. Параллельно углублялись в чтение каждого пространства, в котором хранилась документация по продуктам.

Момент, когда мы поняли, сколько работы предстоит сделать.
Проанализировав всю информацию, которую удалось собрать на первом этапе, увидели три варианта развития событий. У каждого — куда без этого — были свои плюсы и минусы.
Первый вариант
Сломать все то, что есть сейчас. Перелопатить всю документацию, создать типовую структуру пространств и принудительно загнать в нее старые статьи.
Плюсы решения: сразу получаем понятную базу документации для читателей.
Минусы решения: изменения внедряются слишком быстро. В итоге есть риск, что идеально-стерильная база в новой конфигурации через какое-то время снова превратится в то, чем была до этого.
Складывать доку так, как привыкли, легче, чем по-новому. Структура недостаточно гибкая и «обхоженная». Ресурсозатратность всех участников: максимальная.
Второй вариант
Не вторгаться в продуктовые пространства. Собрать всю важную информацию для продаж, ИТО и технической поддержки в другом месте.
Плюсы решения: не вторгаемся агрессивно в продуктовые пространства. На первом этапе можно продолжать ее вести привычным образом, добавляя лишь теги к публикации. Сервисные команды получают понятную базу знаний, а продукты не страдают от резких изменений.
Минусы решения: в любом случае нужно перелопачивать всю документацию, чтобы понять, какие статьи пригодятся сервисным командам, а какие нет. Нужно сразу построить модель базы знаний, которая будет хорошо масштабироваться.
Третий вариант
Ничего не трогать.

Взвесив все за и против, решили пойти по второму пути и создали гиперспейсы.
Что такое гиперспейсы и как они работают
Структура
Гиперспейсы — страницы в Confluence с макросом «Содержимое по меткам».
«Какая же это база знаний, если это простая страница с макросом?», — спросите вы. Все дело в структуре: мы создали три верхнеуровневые страницы с названием сервисной команды, которой предназначается база знаний. Под этой верхнеуровневой страницей команды есть по одной странице на каждый продукт. А уже внутри страницы продукта есть колонки-разделы, в которые складываются статьи определенного типа (и именно здесь работает макрос).
Например, путь к инструкции «Автоматизированное удаление подсетей и VLAN» для техподдержки будет выглядеть так: пространство «Гиперспейс» → страница «Для саппорта» → страница «Выделенные серверы» → колонка «Управление подсетями».
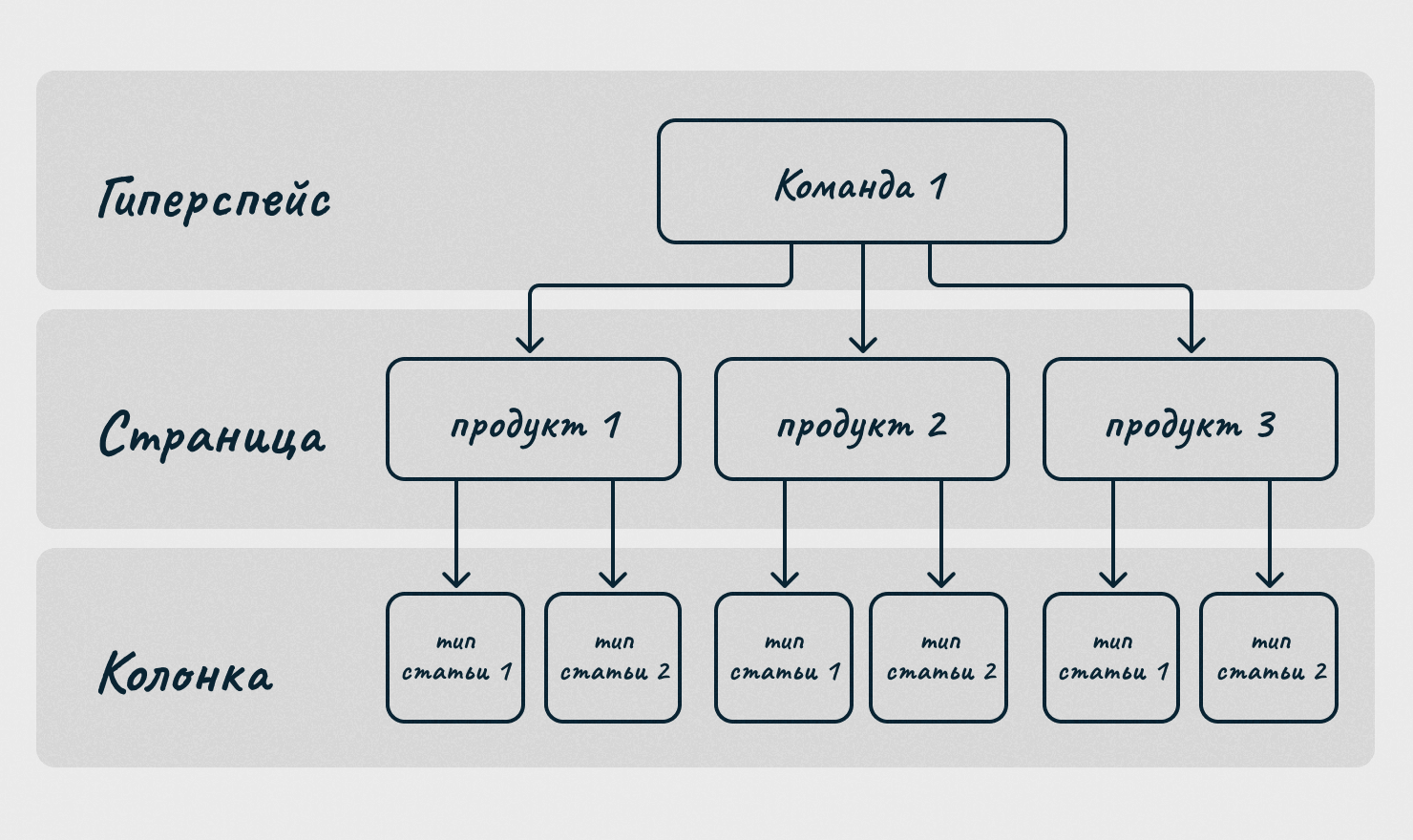
Почему такую архитектуру назвали «гиперспейсами»? Потому что совершенно не важно, в каком пространстве изначально опубликована документация, в какой иерархии она находится и какие статьи лежат вокруг. Макрос находит ее и вытягивает на нужную страницу по меткам.
Макрос «Содержимое по меткам» работает как поиск по базе данных. Он находит статьи с нужными тегами и выводит их на страницу согласно заданным параметрам. Можно настроить отображение по дате создания, изменения или алфавиту, сделать обратную сортировку. Также можно включить отображение названия родительского пространства — того пространства, в котором эта статья была изначально опубликована. Еще можно выбрать отображение всех тегов, которые присвоены конкретной статье. Мы последними двумя опциями не воспользовались — решили отключить названия родительских пространств и тегов, чтобы не перегружать страницу гиперспейса.
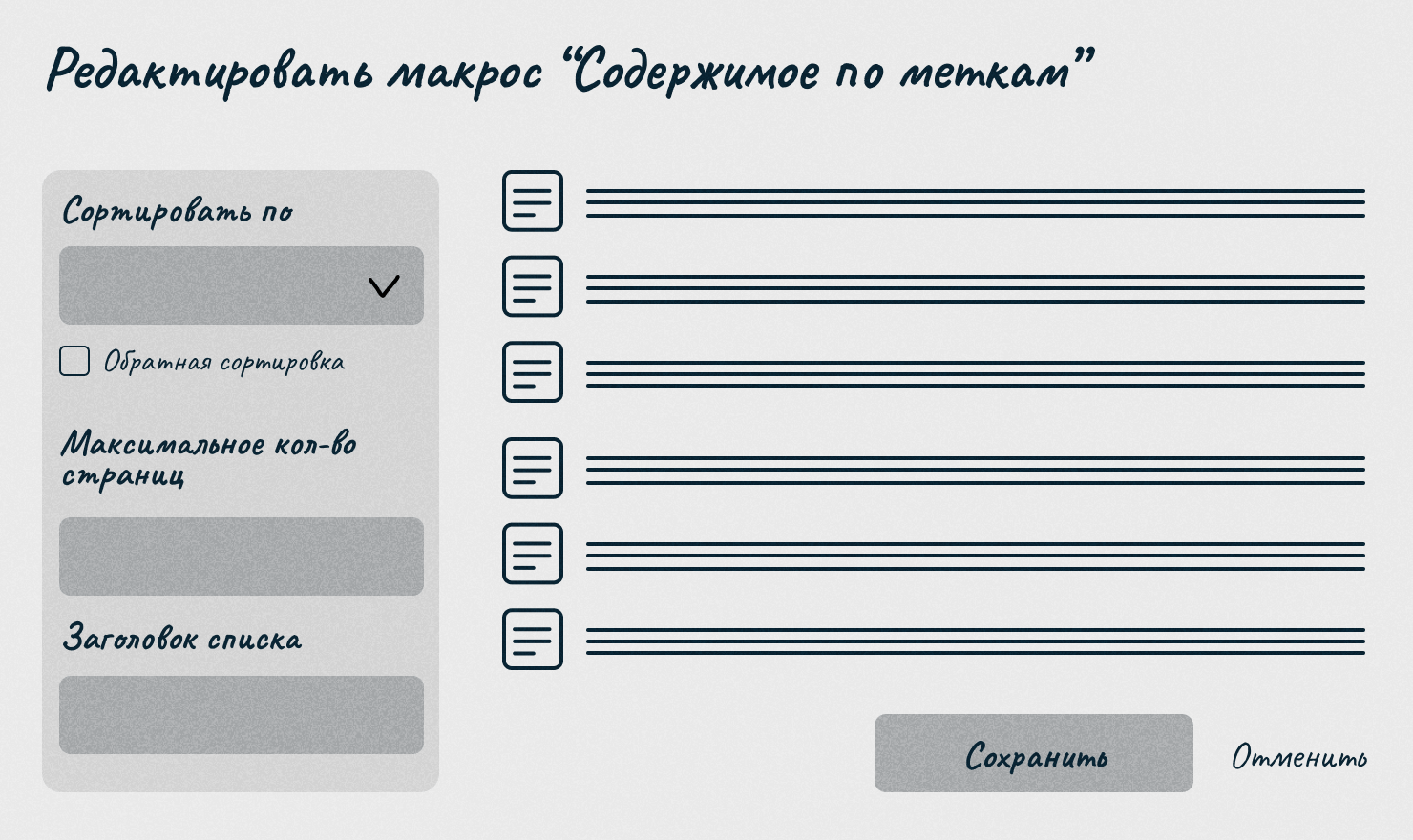
В тексте мы не используем скрины из Confluence, потому что это конфиденциальная информация. Иллюстрации передают общую идею.
Теги
Чтобы статья попала в нужное место, обозначили каждый уровень тегом:
- тег команды определяет, какому отделу предназначается эта инструкция,
- тег продукта показывает, на какой странице гиперспейса она должна находиться,
- тег раздела относит статью в нужную колонку.
Для наглядности работы системы вернемся к примеру с к инструкцией «Автоматизированное удаление подсетей и VLAN».
- Она предназначается техподдержке, значит, ставим тег «support».
- Относится к продукту «Выделенные серверы» — ставим тег «dedicated»
- Должна находиться в разделе «Управление подсетями», для которой нужен тег «network».

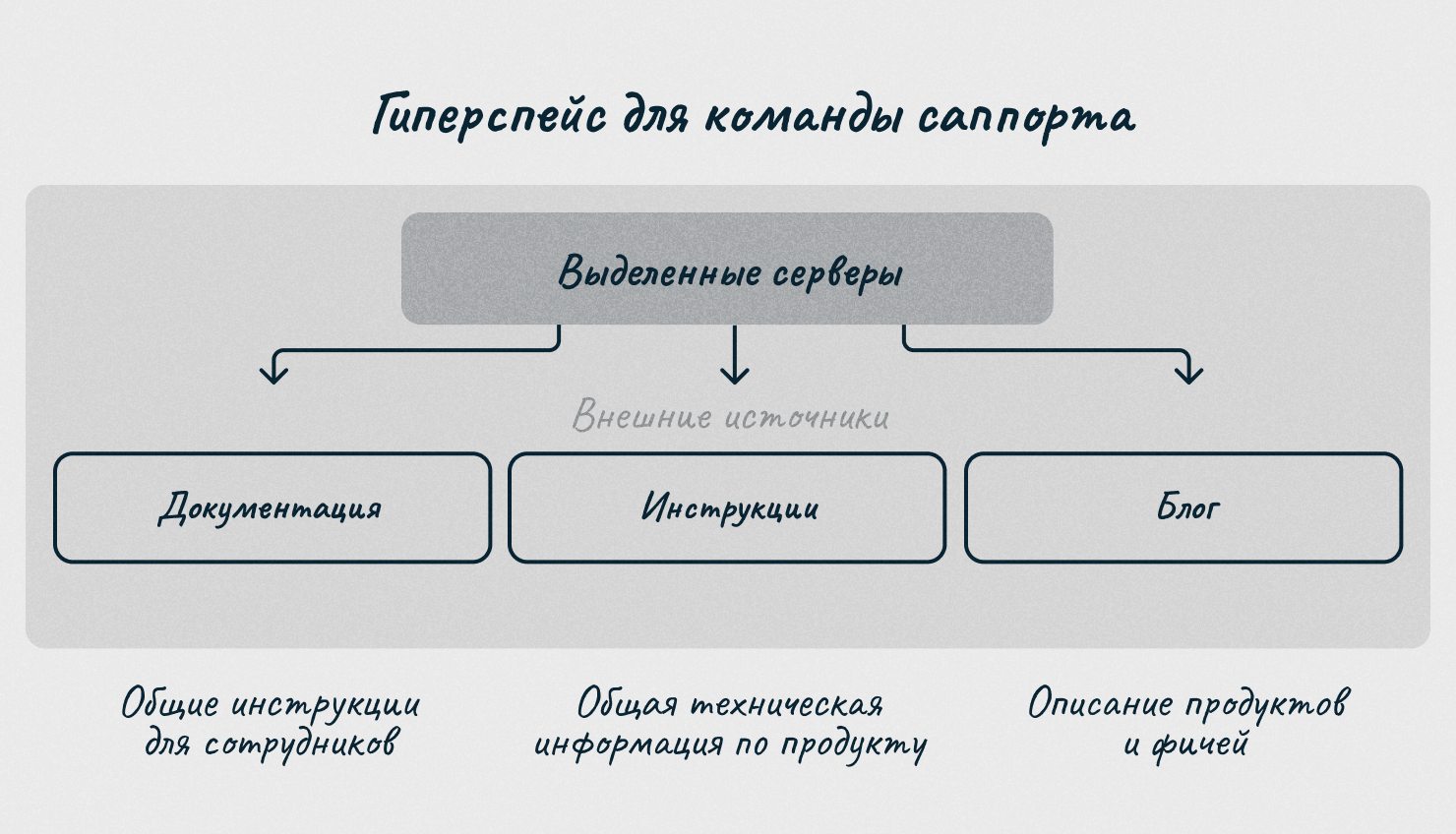
Основные колонки, которые есть в наших гиперспейсах, отличаются от продукта к продукту. Например, в гиперспейсе выделенных серверов есть статьи по работе с подсетями и VLAN, а в гиперспейсе облачной платформы их нет.
Еще мы добавили на страницу кнопки для перехода во внешнюю базу знаний, блог компании или раздел с инструкциями — часто на этих ресурсах можно найти статьи, которые помогают погрузиться в продукт, решить какую-то проблему или провести быструю диагностику.
Поиск релевантных данных
После того, как мы определили структуру гиперспейсов, началось самое веселое: пошли искать нужные статьи по всему Confluence. Охватить сразу три сервисные команды и 15+ продуктов было очень сложно, поэтому остановились на команде техподдержки (она решает проблемы клиентов 24/7). Стали собирать для них гиперспейсы по трем продуктам: выделенным серверам, облачной платформе и облачной платформе на базе VMware.
Эффективнее всего было искать статьи вместе с коллегой из отдела технической поддержки, которая занималась обучением новичков и хорошо знала, какие статьи могут пригодиться в работе, а какие больше относятся к «внутрянке» продуктовых команд. Мы запланировали несколько встреч, на которых подробно, буквально по косточкам, разбирали каждое продуктовое пространство, а потом еще дополнительные источники, где могли быть полезные статьи.
В итоге наш гиперспейс в конфлюенсе стал выглядеть так:
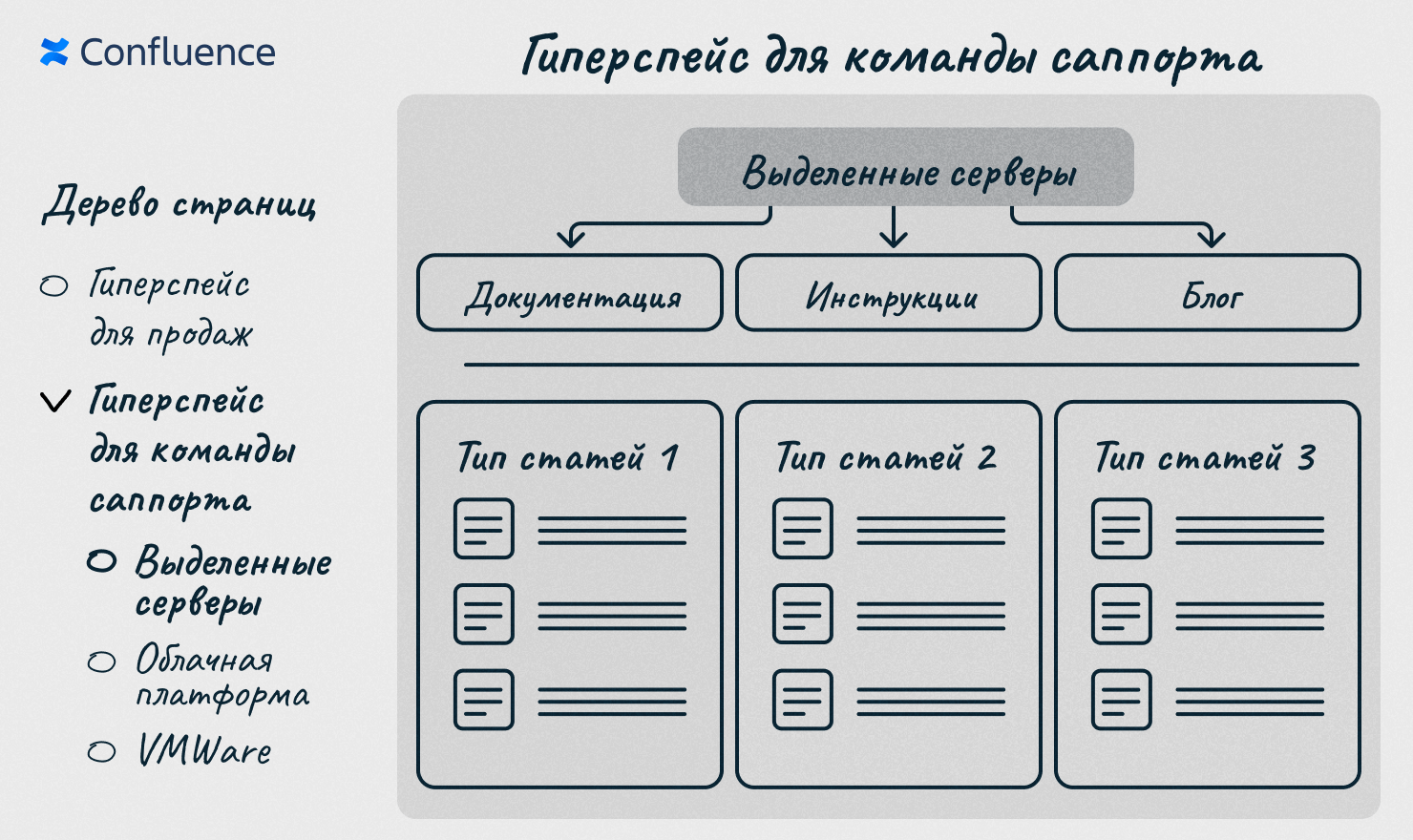
Этот этап был самым выматывающим, но и самым занятным.
Иногда мы находили классные и полезные статьи в совершенно неожиданных местах. Иногда за странными названиями скрывались бриллианты, а за интригующими названиями разделов — пустые страницы.
По дороге нашли кучу побочных битых процессов. Например, выяснили, что у нас нет единых стандартов форматирования статей (кто-то оформлял «предупреждение» капсом и красным шрифтом, кто-то макросом «предупреждение») и быстренько провели обучение по макросам.
Сбор гиперспейса по продукту занял у нас две недели от момента «мы придумали разделы» до момента «кажется, мы нашли все нужные статьи».
Итоги первого этапа
С момента старта исследований прошло три месяца. За это время мы запустили первые гиперспейсы для техподдержки по трем флагманским продуктам. Когда опубликовали изменения и привлекли команду на тест, получили «вау» и кучу хвалебного фидбека.
Но вот проверку временем гиперспейсы прошли неидеально. Выяснилось, что:
- Не хватает важных статей про продукты → так появилась задача про сбор обязательных артефактов.
- У наших сотрудников очень разный уровень владения Confluence. Это сказывается на подготовке документации. Например, не используются макросы для работы с текстами, нет единых правил оформления, типовые страницы создаются вручную, хотя можно использовать шаблоны → так появилась задача на обучение по работе с Confluence.
- Гиперспейсы должны жить и поддерживаться самими продуктовыми командами. Так было задумано изначально, но, кажется, теперь настало время отдавать базу знаний людям и смотреть, как они будут их наполнять и поддерживать.
В следующей серии расскажу, как мы отдали продактам MVP и что из этого вышло. Спойлерить не буду, но ваши предположения или истории из практики буду ждать в комментариях.
Возможно, эти тексты тоже вас заинтересуют:→ Как использовать макросы в Confluence, чтобы систематизировать и оформить документацию по продукту и процессам?
→ Как эффективно делиться результатами своей работы? О «хвастовстве» здорового человека
→ «Хабр, не закрывайте старый редактор!» Как мы хакнули систему, ускорив верстку статей в несколько раз
