JavaScript: заметка о сканере предварительной загрузки и пропуске невидимого контента

Привет, друзья!
В этой заметке я хочу рассказать о двух вещах:
- Сканере предварительной загрузки (теоретическая часть).
- Пропуске невидимого контента (практическая часть).
Обе технологии используются браузером для повышения скорости загрузки веб-приложений.
Теоретическая часть представляет собой адаптированный и дополненный перевод этой статьи. Практическая часть — это небольшой эксперимент по применению новых свойств CSS, о которых рассказывается в этой статье (перевод).
Если вам это интересно, прошу под кат.
Сканер предварительной загрузки
Что такое сканер предварительной загрузки?
В каждом браузере есть основной парсер (primary parser) HTML (далее — просто парсер), который токенизирует (tokenize) разметку и преобразует ее в объектную модель. Разбор разметки продолжается до тех пор, пока парсер не встретит блокирующий ресурс, такой как стили, загружаемые через элемент link, или скрипт, загружаемый через элемент script без атрибута async или defer.
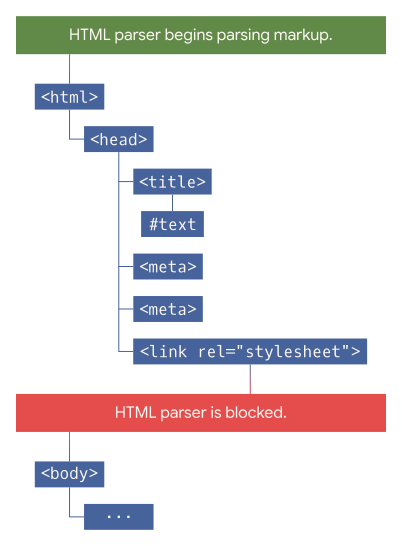
На приведенной диаграмме парсер блокируется загрузкой внешнего CSS-файла с помощью элемента link. Браузер не будет разбирать остальной документ и ничего не будет рендерить до тех пор, пока не загрузит и не разберет эту таблицу.
В случае с файлами CSS парсинг и рендеринг блокируются во избежание вспышки нестилизованного контента (flash of unstyled content, FOUC), когда на мгновение появляется нестилизованная версия страницы перед применением к ней соответствующих стилей.
Браузер также блокирует парсинг и рендеринг страницы, когда встречает тег script без атрибута async или defer.
Обратите внимание: скрипты с type="module" загружаются отложено по умолчанию.
Причина такого поведения браузера состоит в том, что скрипт может модифицировать DOM до завершения обработки разметки парсером.
Блокировка парсинга и рендеринга является нежелательной, поскольку может помешать обнаружению других важных ресурсов. К счастью, кроме основного, в браузере также имеется дополнительный парсер (secondary parser), который называется сканером предварительной загрузки (preload scanner) (далее — просто сканер).
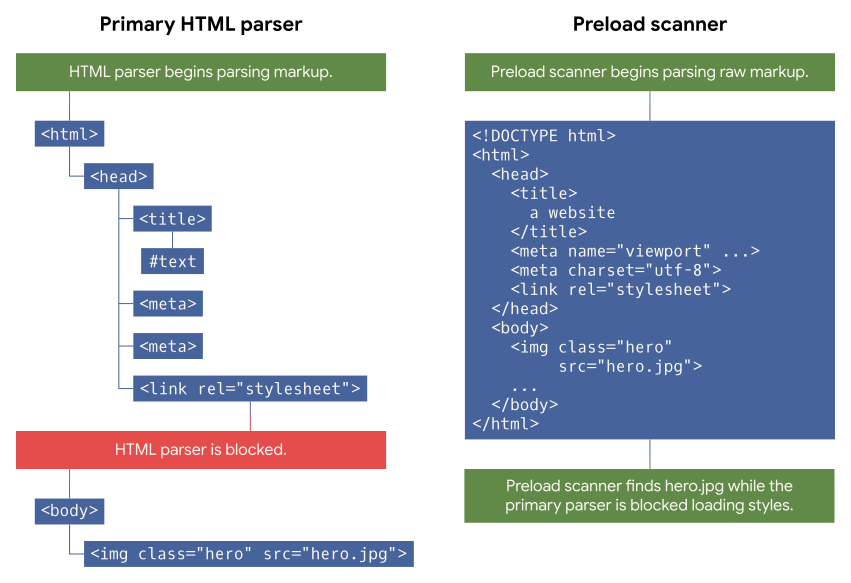
Основной парсер блокируется обработкой CSS и не «видит» изображение в body. Однако сканер продолжает свою работу, обнаруживает изображение и загружает его, не дожидаясь разблокировки парсера.
Роль сканера — исследование разметки с целью обнаружения ресурсов для предварительной загрузки, т.е. до обнаружения этих ресурсов парсером.
Как увидеть работу сканера?
Рассмотрим страницу со стилизованными изображением и текстом. Блокировка парсинга и рендеринга файлом CSS позволяет реализовать искусственную задержку в 2 секунды с помощью прокси-сервера. Задержка помогает увидеть работу сканера на сетевом водопаде (network waterfall):
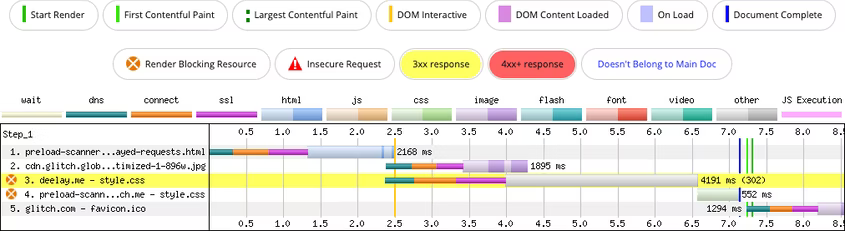
Сканер обнаружил элемент img, несмотря на блокировку парсинга и рендеринга. Без этой оптимизации браузер не сможет предварительно загружать ресурсы в период блокировки. Это означает, что будет больше последовательных запросов и меньше параллельных.
Может ли разработчик помочь сканеру? Нет. Но он может ему не мешать. Рассмотрим парочку примеров.
Внедренные скрипты
Предположим, что в head у нас имеется такой код:
Внедренные (injected) скрипты (ym.min.js) по умолчанию являются асинхронными (как будто у них имеется атрибут async). Такие скрипты запускаются сразу и не блокируют рендеринг. Звучит прекрасно, не правда ли? Да, но если расположить такой script после link, загружающего внешний файл CSS, то результат будет следующим:
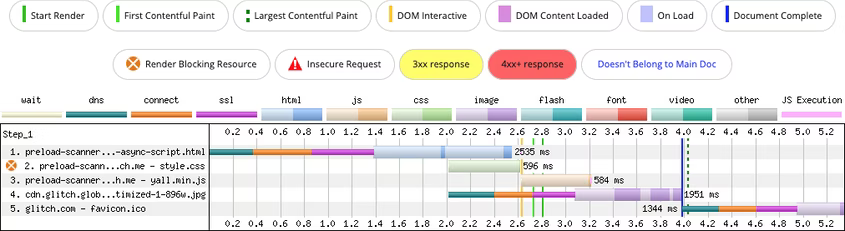
Страница содержит одну таблицу стилей и встроенный асинхронный скрипт. Сканер не может обнаружить такой скрипт в период блокировки, поскольку он внедряется на клиенте.
Вот что здесь происходит:
- Сначала запрашивается основной документ.
- На 1,4 секунды прибывает первый байт навигационного запроса.
- На 2 секунде запрашиваются стили и изображение.
- Парсер блокируется загрузкой стилей и встроенный
JS, который внедряет асинхронный скрипт, выполняется только на 2,6 секунды.
Таким образом, запрос на получение скрипта выполняется только после завершения загрузки стилей. Это может негативно сказаться на времени до интерактивности (Time to Interactive, TTI).
Перепишем код следующий образом:
Результат:

Сканер обнаруживает асинхронный скрипт в период блокировки и загружает его одновременно со стилями.
Данную проблему также можно решить с помощью rel=«preload»:
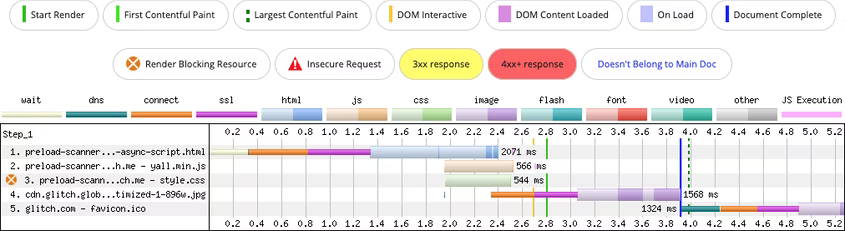
Предварительная загрузка решает задачу, но возникает другая проблема: в первом примере асинхронный скрипт загружается с «низким» приоритетом, а таблица стилей с «наивысшим», во втором случае стили также загружаются с «наивысшим» приоритетом, а приоритет загрузки скрипта становится «высоким».
Чем выше приоритет загрузки ресурса, тем больше пропускной способности выделяется ему браузером. Высокий приоритет скрипта может стать проблемой при медленном соединении или большом размере файла.
Ответ прост: если скрипт требуется при запуске приложения, не внедряйте его в DOM с помощью встроенного JS.
Ленивая загрузка с помощью JS
Ленивая или отложенная (lazy) загрузка — отличный метод обработки данных, часто применяемый к изображениям. Однако неправильное применение этой техники может привести к тому, что важные ресурсы не будут своевременно обнаружены сканером (получение ссылки на изображение, его загрузка, декодирование и отображение).
Взглянем на такую разметку:
![Example]()

Использование атрибута data-* является распространенной практикой, используемой ленивыми загрузчиками (lazy loaders, например, vanilla-lazyload). Когда изображение попадает в область просмотра, загрузчик меняет data-src на src. Обычно, это реализуется с помощью Intersection Observer API. Это заставляет браузер загрузить ресурс.
Паттерн работает до тех пор, пока изображение не находится в области просмотра при запуске приложения. Поскольку сканер не читает атрибут data-src как атрибут src (или srcset), ссылка на изображения остается скрытой. Более того, загрузка изображения откладывается до загрузки, компиляции и выполнения кода ленивого загрузчика.
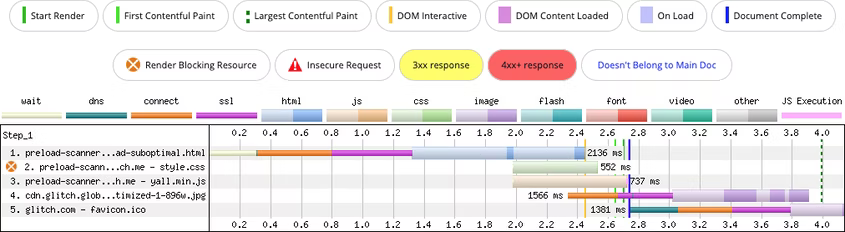
В отдельных случаях при нахождении «ленивого» изображения в области просмотра при запуске приложения замены data-src на src вообще не происходит, поэтому при использовании, например, react-lazyload, иногда приходится вручную вызывать метод forceCheck для определения нахождения элемента в области просмотра.
Обратите внимание: у элемента img (и iframe) есть специальный атрибут для ленивой загрузки — loading=«lazy». Как только поддержка этого атрибута Safari станет стабильной, всем будет счастье. Много изображений на сайте? Рассмотрите возможность использования Imgproxy.
В зависимости от размера изображения или размера занимаемой им части области просмотра, изображение может стать целью для оценки скорости загрузки основного контента (Largest Contentful Paint, LCP) страницы.
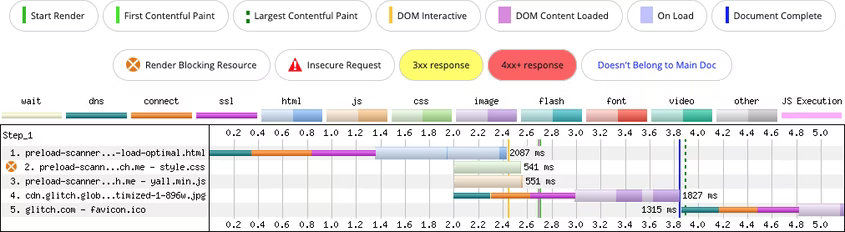
Убедитесь в том, что изображения и другие ресурсы, находящиеся в области просмотра при запуске приложения, загружаются незамедлительно (eager):

Фоновые изображения CSS
Помните, что сканер исследует разметку. Он не сканирует другие ресурсы, такие как стили, в которых изображения могут запрашиваться в свойстве background-image.
Как и HTML, CSS преобразуется в объектную модель — CSSOM. При обнаружении внешних ресурсов при конструировании CSSOM, они запрашиваются во время обнаружения, а не предварительно.
Предположим, что кандидат LCP — это элемент с background-image:
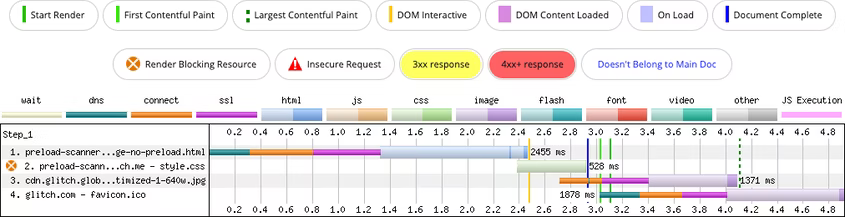
Загрузка изображения начинается только после его обнаружения парсером CSS.
Эту проблему можно решить предварительной загрузкой изображения с помощью rel="preload":

Общая рекомендация такова: везде, где это возможно, вместо background-image следует использовать элемент img.
Рендеринг разметки на стороне клиента
Не секрет, что JS замедляет скорость загрузки страницы. Речь идет о тех случаях, когда JS используется для доставки контента. Это обеспечивает лучший опыт разработки. Но лучший опыт разработки не всегда означает лучший пользовательский опыт.
Рендеринг разметки на стороне клиента нивелирует работу сканера:
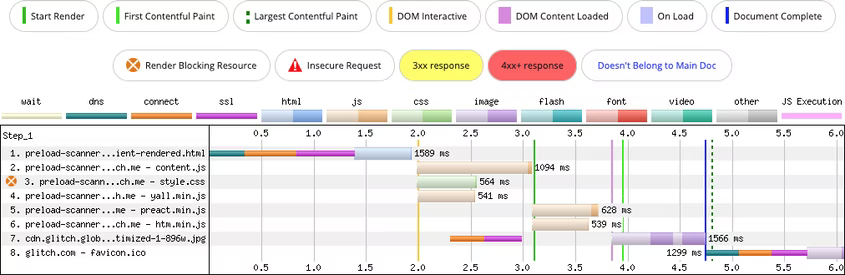
Поскольку контент формируется JS и рендерится фреймворком, изображение в разметке остается скрытым для сканера. Это замедляет обнаружение важных ресурсов и негативно влияет на LCP.
Рендеринг разметки на стороне клиента также может негативно сказаться на интерактивности до следующей отрисовки (Interaction to Next Paint, INP).
Более того, рендеринг очень большого объема разметки на клиенте похож на выполнение тяжелой, а, значит, продолжительной вычислительной задачи (long task) по сравнению с обработкой разметки, полученной браузером от сервера. Дело в том, что разметка, полученная от сервера, делится браузером на небольшие части («чанки», chunks) во избежание выполнения длительных задач, что может привести к утрате браузером интерактивности. Клиентская разметка, в свою очередь, обрабатывается как единая монолитная задача, что может ухудшить такие показатели, как общее время блокировки (Total Blocking Time, TBT) и время ожидания до первого взаимодействия с контентом (First Input Delay, FID).
Рендеринг разметки на стороне сервера (Server-Side Rendering, SSR) или генерация статической разметки всегда более предпочтительна, чем рендеринг HTML на стороне клиента. Альтернативой может служить генерация статической разметки на сервере и ее гидратация на клиенте.
Пропуск невидимого контента
Новое свойство CSS content-visibility позволяет разработчику предоставлять браузеру разрешение на пропуск рендеринга невидимого контента, т.е. контента, находящегося за пределами области просмотра при запуске приложения. В настоящее время данное свойство поддерживается только браузерами на основе WebKit. Делается это следующим образом:
/* класс элемента, рендеринг которого может быть пропущен */
.profile-card {
content-visibility: auto;
/* другие возможные (основные) значения: visible, hidden */
}По моим наблюдениям, браузер рендерит видимый контент с запасом, примерно равным размеру области просмотра. Другими словами, пропускается рендеринг контента, находящего «далее» приблизительно 200% размера области просмотра.
Дефолтным размером «пропущенного» контента является 16x16px. Последующий рендеринг такого элемента может привести к ужасному опыту скроллинга, когда полоса прокрутки прыгает вверх и вниз или в лучшем случае остается на месте. Во избежание этого рекомендуется указывать «типичный» размер контента с помощью свойства contain-intrinsic-size. Сигнатура:
contain-intrinsic-size: [auto] [width] [height];Ширина и высота пока могут задаваться только в пикселях (если указано одно значение, оно будет применяться и к ширине, и к высоте). Значение auto указывает браузеру запоминать размер отрендеренного элемента (пропуск невидимого контента выполняется «туда и обратно»: пропускается рендеринг не только тех элементов, которые еще не попали в область просмотра, но и тех, которые из нее вышли).
Пример:
.profile-card {
content-visibility: auto;
/* ! */
contain-intrinsic-size: auto 200px 100px;
}В простейших случаях (как в примере из оригинальной статьи) это прекрасно работает: пропуск невидимого контента действительно на порядок повышает скорость рендеринга страницы. Но будет ли это работать при рендеринге разметки на стороне клиента? Давайте это проверим.
Обратите внимание: для разработки приложения я буду использовать React и TypeScript, но выбор фреймворка и использование типизатора особого значения не имеют. Для работы с зависимостями я буду использовать Yarn.
Разработка приложения
Разработаем простое приложение для рендеринга карточек пользователей в количестве 1000 штук.
Создаем шаблон приложения с помощью Vite:
# content-visibility - название приложения (директории)
# --template react-ts - используемый шаблон
yarn vite create content-visibility --template react-tsПереходим в созданную директорию и устанавливаем пакет для генерации «рыбатекста»:
cd content-visibility
yarn add lorem-ipsumПриводим директорию src к следующему виду:
- src
- App.tsx
- index.css
- main.tsx
- UserCard.tsx
- vite-env.d.tsПодключаем шрифт в index.html:
Content Visibility
Начнем с компонента карточки пользователя (UserCard.tsx):
import { forwardRef } from 'react'
type Props = {
imageUrl: string
title: string
subtitle: string
description: string
}
export const UserCard = forwardRef(
({ imageUrl, title, subtitle, description }, ref) => (

{title}
{subtitle}
{description}
)
) Здесь все просто: компонент принимает адрес изображения, заголовок, подзаголовок и описание, формирует и возвращает разметку. О перенаправлении ссылки поговорим чуть позже.
Займемся основным компонентом (App.tsx).
Импортируем зависимости и компонент, определяем функцию для генерации «рыбатекста» и переменную для идентификатора аватара пользователя:
import { loremIpsum } from 'lorem-ipsum'
import { useEffect, useRef } from 'react'
import { UserCard } from './UserCard'
const getLorem = (n: number) => {
const [first, ...rest] = loremIpsum({ count: n, units: 'word' }).toLowerCase()
return `${first.toUpperCase()}${rest.join('')}`
}
let avatarCount = 0Для получения ссылок на аватары прибегнем к помощи Pravatar. Данный ресурс предоставляет всего 70 разных изображений, поэтому нам и нужен счетчик.
Мы хотим, чтобы размер карточек был динамическим, т.е. зависел от ширины области просмотра (как в реальных приложениях). Но что делать с contain-intrinsic-size? Один из вариантов — измерить размер первой карточки после рендеринга и внедрить соответствующие стили в head:
function App() {
// ссылка на карточку
const userCardRef = useRef(null)
useEffect(() => {
if (userCardRef.current) {
// если стили уже внедрены, ничего не делаем
// (в режиме разработки рендеринг выполняется дважды)
if (document.head.querySelector('#content-visibility')) return
// получаем ширину и высоту карточки
const { width, height } = window.getComputedStyle(userCardRef.current)
// создаем элемент `style` и внедряем его в `head`
const styleTagTemplate = `
`.trim()
document.head.insertAdjacentHTML('beforeend', styleTagTemplate)
}
}, [])
return (
{/* передаем ссылку первой карточке */}
Можно пойти дальше и переопределять contain-intrinsic-size при каждом изменении размера области просмотра:
const onResize = () => {
if (userCardRef.current) {
const { width, height } = window.getComputedStyle(userCardRef.current)
const styleTag = document.head.querySelector('#content-visibility')
if (styleTag) {
styleTag.textContent = `.profile-card { contain-intrinsic-size: auto ${width} ${height}; }`
}
}
}
useEffect(() => {
window.addEventListener('resize', onResize)
return () => {
window.removeEventListener('resize', onResize)
}
}, [])Но такие вычисления будут негативно влиять на производительность приложения, поэтому обойдемся без них.
Определяем стили в index.css:
body {
margin: 0;
font-family: 'Montserrat', sans-serif;
}
h2,
h3,
p {
margin: 0;
}
.app {
display: flex;
flex-wrap: wrap;
}
.profile-card {
box-sizing: border-box;
max-width: calc(33% - 1rem);
display: flex;
gap: 1rem;
align-items: center;
padding: 0.5rem;
margin: 0.5rem;
box-shadow: 0 1px 3px rgba(0, 0, 0, 0.2);
border-radius: 2px;
/* ! */
content-visibility: auto;
}
@media (max-width: 1280px) {
.profile-card {
max-width: calc(50% - 1rem);
}
}
@media (max-width: 900px) {
.profile-card {
max-width: 100%;
}
}
.profile-card img {
width: 100px;
border-radius: 50%;
}
.info-section {
display: flex;
flex-direction: column;
gap: 0.5rem;
}
.info-section h2 {
font-size: 1.4rem;
}
.info-section h3 {
font-style: italic;
font-size: 0.8rem;
}Запускаем приложение с помощью команды yarn dev:

Открываем инструменты разработчика и «перебираем» элементы с классом profile-card посредством наведения курсора. В определенный момент получаем от браузера сообщение о том, что «потомки элемента пропущены из-за content-visibility»:
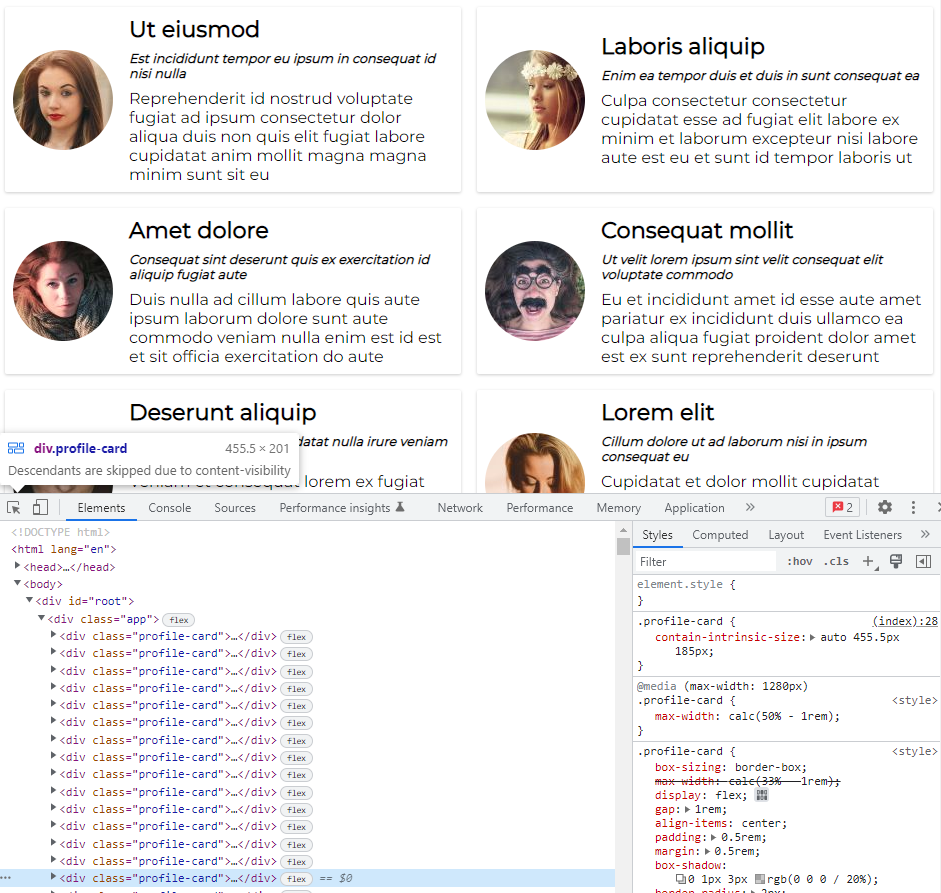
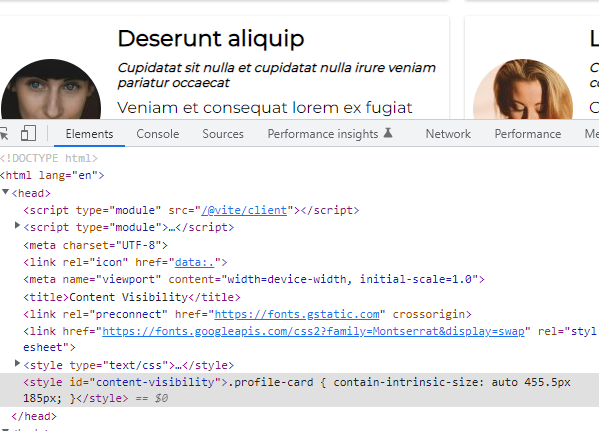
Заглянув в head, убедимся во внедрении стилей, определяющих типичный размер контента:
Ускорило ли это рендеринг страницы? Для чистоты эксперимента создадим 2 сборки приложения.
Выполняем команду yarn build. Это приводит к генерации директории dist с файлами сборки в корне проекта. Меняем название данной директории на with-cv.
Удаляем content-visibility: auto; из index.css и все, что связано с contain-intrinsic-size, из App.tsx, и снова выполняем сборку с помощью yarn build. Меняем название директории dist на without-cv.
В качестве локального сервера для запуска приложений используем serve. Устанавливаем его глобально:
yarn global add serveИ запускаем оба приложения:
serve -s with-cv
serve -s without-cvОткрываем приложения в браузере в анонимном режиме.
Для измерения производительности приложения воспользуемся вкладкой Performance инструментов разработчика. Открываем данную вкладку и нажимаем на кнопку обновления в верхнем левом углу:
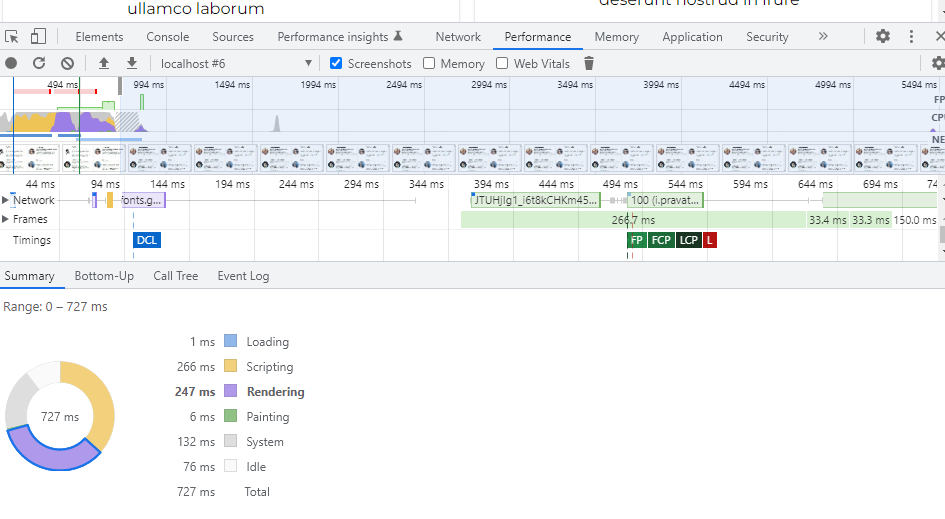
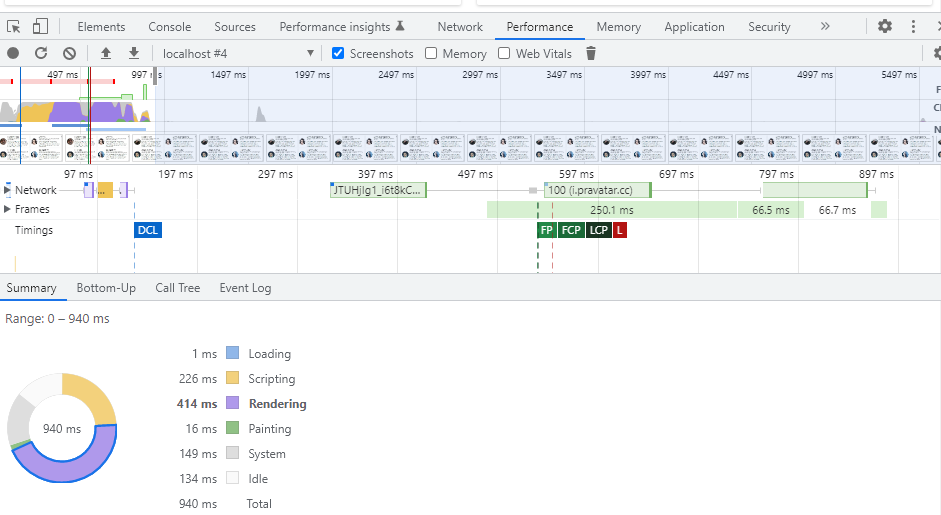
Нас интересуют показатели Rendering и Painting. Честно говоря, результаты получаются не очень стабильными: иногда значения примерно одинаковые, но, в среднем, скорость рендеринга и отрисовки страницы, на которой браузеру разрешено пропускать невидимый контент, в 2 раза выше. Таким образом, даже в случае рендеринга разметки на стороне клиента браузер делает все возможное для ускорения загрузки страницы.
Подведем некоторые итоги:
- скорее всего, к моменту стандартизации
contain-intrinsic-sizeбудет принимать значения не только в пикселях, но и, как минимум, в процентах; - пока не очень понятно, как вычислять
contain-intrinsic-sizeбез использованияJSв случае с динамическим размером содержимого; - использование
content-visibility: autoсо временем может стать хорошей альтернативой или дополнением к другим паттернам ленивой загрузки; - учитывая очевидные преимущества пропуска рендеринга невидимого контента, можно предположить, что
content-visibility: autoв будущем (в той или иной степени) станет поведением браузера по умолчанию.
Пожалуй, это все, чем я хотел поделиться в этой заметке. Надеюсь, вы нашли для себя что-то интересное и не зря потратили время.
Благодарю за внимание и happy coding!

