Интерпретируемость в машинном обучении: итоги 2021 г
В наши дни уже ни для кого не секрет, что понимать логику работы моделей машинного обучения важно и нужно. Иначе можно насобирать множество проблем: от того, что модель не будет принята конечным пользователем, потому что непонятна, до того, что она будет работать неправильно, а поймем мы это уже слишком поздно.
Для интерпретируемости в машинном обучении прочно устоялись термины Interpretable ML и Explainable AI (XAI). Объединяет их одно — стремление сделать модели машинного обучения понятными для конечного пользователя.
Под катом давайте поговорим о том, что интересного произошло в интерпретируемости в 2021 г.
Ключевые тренды и события 2021 г. в Interpretable ML
Сначала поговорим обобщенно, а затем детальнее раскроем наиболее интересные пункты.
DARPA подвели итоги 4хлетней программы по объяснимому ИИ, которую сформулировали в 2015 году и стартовали в 2017 м. Цель программы — дать конечным пользователям возможность лучше понимать системы с ИИ, доверять им и эффективно управлять ими. Ключевые итоги, которые сформулировала DARPA, можно детально изучить по ссылке, или прочитать ниже в этой статье.
Мы научились интерпретировать модели, но как узнать, какой метод объяснения лучше?
Пожалуй, самое пристальное внимание в области XAI в 2021 г. было направлено на оценку качества методов интерпретации — для возможности сравнения методов между собой. В основном, работы посвящены созданию методик с конкретными количественными метриками для локальной интерпретации black-box моделей. При этом в январе 2022 г. на arxiv появилась знаковая работа, в которой авторы систематизируют около 300 работ в области XAI, опубликованных на CS конференциях в 2014–2020 гг. и предлагают набор из метрик, которые могут стать универсальными для оценки различных методов интерпретируемости: как для локальной интерпретации (как объяснить каждое отдельное предсказание), так и для глобальной (как работает модель в целом). Об этом также напишем далее более подробно.Актуальность темы XAI только растет. Но хороших и доступных системных обзоров, учитывающих проблематику внедрения методов в бизнес-процессы все еще единицы. Так, и в 2021 г. в разных бизнес-источниках продолжили ссылаться на отчет PwC по Explainable AI от 2018 г. В обзоре достаточно простым языком сделан обзор проблематики XAI, структурированы подходы к объяснению моделей, а также обоснована необходимость инвестиций в сферу XAI и применения интерпретации в бизнес-процессах.
Прорывы и заслуживающие внимания достижения в отдельных областях ML. Об этом в 2021 г. был проведен Interpretable & Causal ML трек на конференции Data Fest Online. Чуть ниже обсудим, какие там были доклады по Interpretable ML. А о трендах 2022 г. мы подробно расскажем на секции Reliable ML в рамках конференции Data Fest 3.0, которая пройдет уже 5 июня.
Применение методов интерпретируемости алгоритмов для бизнеса уже давно не является чем-то прорывным. Поэтому наиболее интересными являются либо проблемы применения этих методов, с которыми бизнес сталкивается на практике: в техническом решении какого-либо вопроса объяснения ML, или в вопросе внедрения методов интерпретируемости в бизнес-процессы компании.
Для меня, например, одной из таких проблем стала задача агрегированного вывода об устойчивой значимости и знаке влияния факторов множества однотипных предсказательных моделей. Если мы строим множество black-box моделей с похожим набором факторов на ряд близких по содержанию таргетов, то можно ли научным подходом сделать вывод о робастном влиянии того или иного фактора на них? А что делать, если мы хотим объяснить заказчику результаты работы оптимизационных алгоритмов?
Если вы хотите поговорить об этом, то также приходите 5 июня на круглый стол по вопросам интерпретируемости в машинном обучении. А если готовы рассказать о своем опыте и/или болях, связанных с интерпретируемостью ML моделей, welcome вот в эту гугл-форму, постараемся вам помочь.
Итоги XAI программы DARPA за 2017–2021 гг.
DARPA завершила и подвела итоги 4хлетней программы по объяснимому ИИ, которую сформулировало в 2015 году и стартовало в 2017 м.
По мнению DARPA, 2015 г. стал переломным в значимости темы Interpretable ML. С этого года активизировались исследования по интерпретируемости в 3х направлениях: интерпретируемость в области DL, усиление точности более интерпретируемых моделей, таких как Bayesian Rule Lists, а также развитие универсальных методов интерпретируемости (model-agnostic techniques), где превалировали методы, наподобие LIME.
Программа XAI DARPA подчеркивала, что ее целью является конечный пользователь, который зависит от решений или рекомендаций системы ИИ, и поэтому должен понимать, почему она предлагает то или иное решение. В итоге хотели предложить новые методы/упорядочить существующие, чтобы для каждой задачи предлагать оптимальный метод, исходя из противоречия точности алгоритма и возможности его интерпретировать.
Содержание XAI DARPA было разделено на три основные технические области:
разработка новых методов XAI
понимание психологии объяснения
оценка качества новых методов XAI — для возможности их объективного сравнения между собой.
Методы, рассмотренные в рамках программы, концентрируются на интерпретации DL алгоритмов и возможности оценки эффективности методов локальной интерпретации (объяснение конкретного/локального предсказания модели). Здесь можно посмотреть таблицу с краткими тезисами про все рассмотренные методы и ссылки на детальные разборы/статьи.
Все технические результаты XAI DARPA были интегрированы в репозиторий, содержание которого можно изучить на сайте https://xaitk.org/ . Методы, проработанные в рамках программы собраны в 2 раздела: ML-алгоритмы, направленные на прогноз (Analytics) и автономные системы (Autonomy).
Верхнеуровневые ключевые выводы, которые сформулировали в DARPA XAI:
Пользователи предпочитают системы, которые предоставляют решения с объяснениями, а не системы, которые предоставляют только решения.
Чтобы объяснение модели улучшали конечный результат использования модели, задача, решаемая моделью, должна быть достаточно сложной (Позиция PARC, UT Dallas)
Когнитивная нагрузка пользователя для интерпретации объяснений может снизить производительность пользователя. В сочетании с предыдущим пунктом, объяснения и сложность задач должны быть откалиброваны, чтобы повысить производительность пользователя (UCLA, штат Орегон)
Объяснения более полезны, когда ИИ неверен, и особенно ценны в пограничных случаях (UCLA, Rutgers)
Показатели эффективности объяснения могут меняться со временем (Raytheon, BBN)
Рекомендации могут значительно повысить доверие пользователей по сравнению с одними только объяснениями (Калифорнийский университет в Беркли)
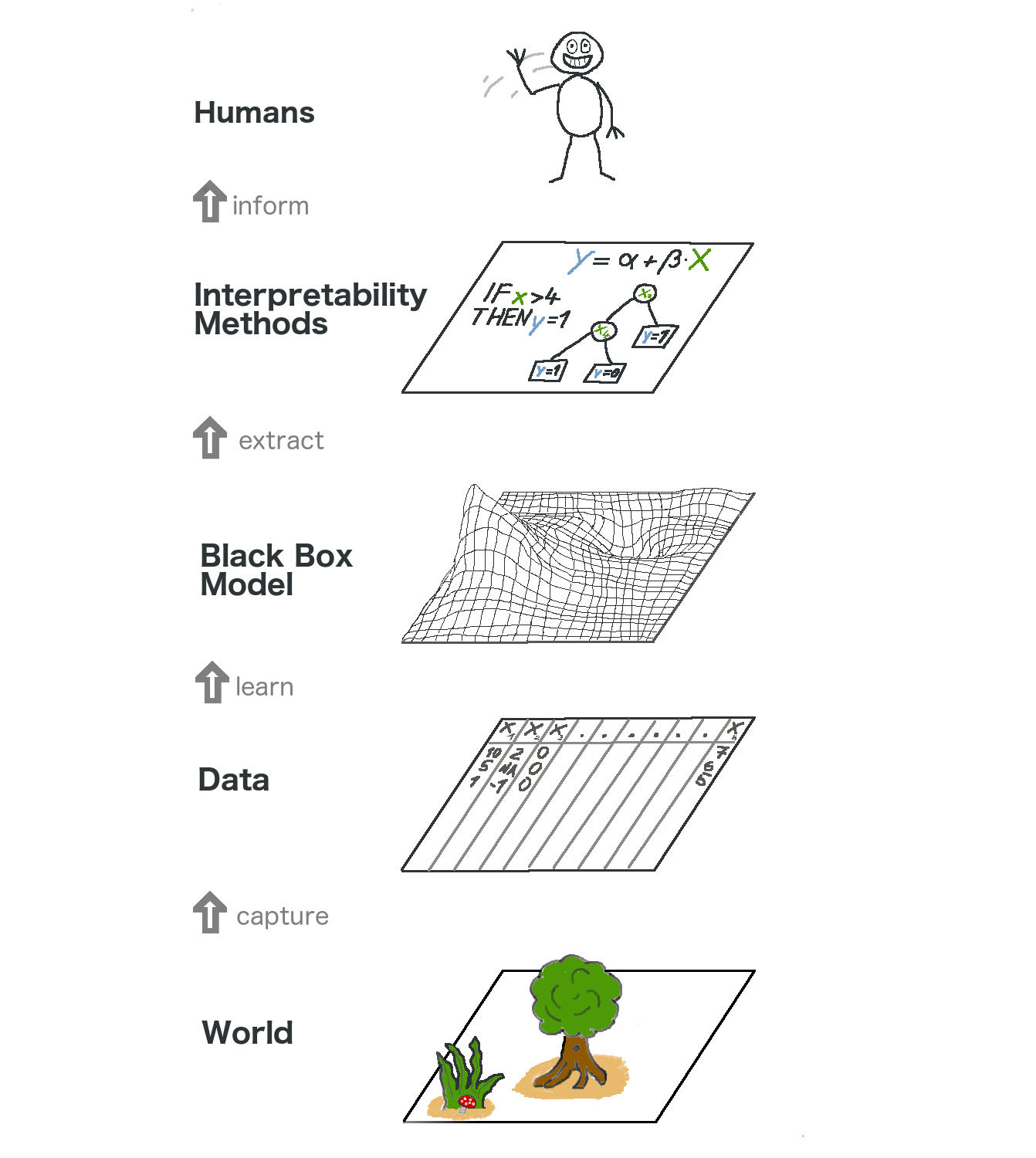
 Интерпретируемость моделей vs. точность ML-алгоритмов по итогам программы DARPA.
К картинке можно задать довольно много вопросов. Приводим, как видят авторы.
Интерпретируемость моделей vs. точность ML-алгоритмов по итогам программы DARPA.
К картинке можно задать довольно много вопросов. Приводим, как видят авторы.
Усиление акцента на оценке эффективности методов Interpretable ML
Системная оценка эффективности методов
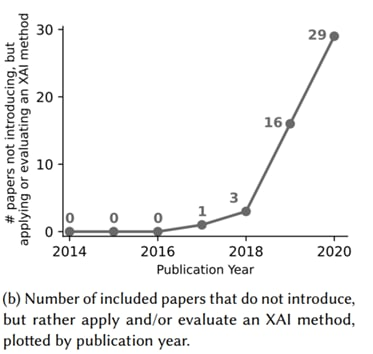
В январе 2022 г. на arxiv появилась знаковая работа, в которой авторы систематизируют около 300 работ в области XAI, опубликованных на CS конференциях в 2014–2020 гг. Отдельным разделом в ней приведен обзор исследований, посвященных оценке эффективности методов XAI.
Основным результатом статьи является предложение универсального фреймворка для оценки эффективности методов как локальной, так и глобальной интерпретируемости. Авторы предлагают 12 стандартизированных метрик для универсальной оценки XAI методов, подчеркивая, что важность метрик варьируется в зависимости от целей интерпретации модели в каждом случае.
Метрики разбиты на три категории, в зависимости от того, на чем они делают акцент:
(1) Ориентированные на содержание объяснения:
Корректность (Correctness) — насколько точны объяснения в сравнении с «истинным» поведением объясняемой модели.
Полнота (Completeness) — насколько полно объяснение отражает разные аспекты поведения модели.
Консистентность (Consistency) — объяснения должны зависеть от входов и выходов модели, а не от конкретной реализации метода XAI.
Непрерывность (Continuity) — для похожих входных данных должны генерироваться похожие объяснения.
Контрастность (Contrastivity) — объяснение должно указывать на факторы, необходимые и достаточные для принятия моделью именно такого решения, какое она приняла.
Ковариатная сложность (Covariate complexity) — взаимодействия между факторами, которыми оперирует объяснение, должны быть достаточно простыми для понимания, даже если исходный алгоритм включает сложные взаимодействия.
(2) Ориентированные на форму объяснения:
Компактность объяснения (Compactness) — чем короче объяснение, тем оно лучше.
Композиция (Compositionality) — насколько выразительны и понятны формат и структура интерпретации.
Уверенность (Confidence) — предоставляет ли метод XAI вероятностную оценку своей уверенности в предложенном объяснении.
(3) Ориентированные на потребности пользователя:
Контекст (Context) — насколько метод учитывает потребности и уровень экспертизы конечного пользователя.
Согласованность (Coherence) — до какой степени интерпретация согласуется с опытом, знаниями и убеждениями пользователей.
Контролируемость (Controllability) — насколько пользователь может взаимодействовать с объяснением и настраивать его под свои нужды.
Стоит ли говорить о том, что в статье также в прекрасном структурированном виде приводятся и предложения конкретных количественных метрик для указанных выше разделов — на основе обзора статей за 2014–2020 гг.
 Тема оценки качества методов XAI становится все более актуальной
Тема оценки качества методов XAI становится все более актуальной
Локальная интерпретация black-box моделей
В 2021 г. многие работы в XAI были посвящены созданию методик с конкретными количественными метриками для локальной интерпретации black-box моделей.
Хотелось бы также рассказать про одну из статей как пример структурированного подхода к количественному сравнению между собой методов локальной интерпретации для конкретной задачи:
Для количественного сравнения предложены метрики:
Max-Sensitivity. Показывает устойчивость XAI метода путем измерения максимального изменения результата интерпретации при небольших изменениях значений признаков с помощью Монте-Карло симуляций. Метрика минимизируется.
Area Under the Most Relevant First perturbation curve. Оценивает, насколько быстро качество модели будет убывать, если мы начнем скрывать от нее информацию признаков (например, перемешивая пиксели), начиная с самых «важных». Мы хотели бы, чтобы самыми «важными» считались признаки, действительно определяющие решение модели. Таким образом, хорошее объяснение минимизирует AUC-MoRF.
File Size. Размер результирующего файла метода XAI: чем меньше файл, тем проще и понятнее он, скорее всего, будет для конечного пользователя.
Computational Time. Вычислительная сложность метода XAI. Минимизируем.
По результатам исследования наибольшую успешность показали LIME и Grad-CAM. При этом LIME значительно уступает Grad-CAM по скорости.
Кстати, если вы хотели разобраться в Grad-CAM и не знали с чего начать, то в 2019 г. на секции Data Fest по Interpretable ML был прекрасный доклад Кости Лопухина — «Объяснение предсказаний нейросетей: Grad-CAM is all you need».
А для более детального погружения в возможности и недостатки LIME можно посоветовать вот эту статью 2021 г.
Interpretable & Causal ML Track — Data Fest Online 2021
На ежегодном Data Fest уже в третий раз прошел трек по вопросам Reliable ML — Interpretable & Causal ML Track 2021.
Вот тут можно посмотреть великолепное вступление о тематике трека
