Infrastructure as a Code: ожидания и реальность

Есть такие ребята — SRE (с англ. Site Reliability Engineering), которые выросли из старых добрых и бородатых системных администраторов. Но они устали заниматься ежедневной рутиной и решили всё автоматизировать. Именно поэтому 50% времени SRE пишут код.
Не спешите применять это правило ко всем знакомым SRE, потому что в основном они поддерживают инфраструктуру проекта: запускают серверы, мониторят Kubernetes и перекладывают JSON из одного сервиса в другой. Решение всех этих задач они стремятся оформить в виде кода: скриптов, утилит, пайплайнов и манифестов.
А ведь со временем кода станет очень много, и его придётся читать, тестировать, рефакторить. Можно переписать внутреннее устройство функции, но для пользователя функции её поведение не изменится. Зато читабельность и производительность кода возрастут!
Рефакторить — перерабатывать архитектуру кода так, чтобы это было незаметно внешним пользователям.
У ребят из команды SRE основной объём кода будет инфраструктурным, то есть манифесты описания инфраструктуры. И стандарт де-факто для такого описания сегодня — это Terraform. Жизненный цикл сопровождения такого Tеrraform-кода зависит от проекта, и тут нет «волшебной пилюли» и строгих правил.
Разберём один из примеров организации IaaC-репозитория (Infrastructure as a Code) для Terraform и начнём с вредных советов.
Ничто не предвещало беды
На старте проекта вы создаёте свою первую виртуальную машину в Terraform-манифесте с помощью соответствующего ресурса.
Ресурсом в Terraform называется блок, описывающий инфраструктурный объект в облаке: виртуальная машина, сеть или DNS-запись.
Здесь и далее в качестве примера будем использовать Terraform-провайдер для Yandex Cloud.
Сделайте так, чтобы в файле-манифесте compute.tf у вас появилось описание:
compute.tf
resource "yandex_compute_instance" "default" {
name = "test"
platform_id = "standard-v1"
zone = "ru-central1-a"
resources {
cores = 2
memory = 4
}
boot_disk {
initialize_params {
image_id = "image_id"
}
}
network_interface {
subnet_id = "${yandex_vpc_subnet.foo.id}"
}
metadata = {
foo = "bar"
ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}"
}
}Хотя нет. Сначала нужно создать VPC и подсеть: разместим эти ресурсы в файле network.tf.
network.tf
resource "yandex_vpc_network" "foo" {}
resource "yandex_vpc_subnet" "foo" {
zone = "ru-central1-a"
network_id = "${yandex_vpc_network.foo.id}"
v4_cidr_blocks = ["10.5.0.0/24"]
} Теперь нам нужно запустить Kubernetes-кластер в облаке, поэтому создадим файл k8s.tf:
k8s.tf
resource "yandex_kubernetes_cluster" "my_cluster" {
name = "name"
description = "description"
network_id = "${yandex_vpc_network.network_resource_name.id}"
master {
version = "1.17"
zonal {
zone = "${yandex_vpc_subnet.foo.zone}"
subnet_id = "${yandex_vpc_subnet.foo.id}"
}
public_ip = true
security_group_ids = ["${yandex_vpc_security_group.security_group_name.id}"]
maintenance_policy {
auto_upgrade = true
maintenance_window {
start_time = "15:00"
duration = "3h"
}
}
master_logging {
enabled = true
log_group_id = "${yandex_logging_group.log_group_resoruce_name.id}"
kube_apiserver_enabled = true
cluster_autoscaler_enabled = true
events_enabled = true
}
}
service_account_id = "${yandex_iam_service_account.service_account_resource_name.id}"
node_service_account_id = "${yandex_iam_service_account.node_service_account_resource_name.id}"
labels = {
my_key = "my_value"
my_other_key = "my_other_value"
}
release_channel = "RAPID"
network_policy_provider = "CALICO"
kms_provider {
key_id = "${yandex_kms_symmetric_key.kms_key_resource_name.id}"
}
} И сюда же добавим описание нод-кластера. Или давайте добавим ноды в отдельный файл k8s-nodes.tf, ведь бывает много отдельных групп, которые нужно быстро найти:
k8s-nodes.tf
resource "yandex_kubernetes_node_group" "my_node_group" {
cluster_id = "${yandex_kubernetes_cluster.my_cluster.id}"
name = "name"
description = "description"
version = "1.22"
labels = {
"key" = "value"
}
instance_template {
platform_id = "standard-v2"
network_interface {
nat = true
subnet_ids = ["${yandex_vpc_subnet.foo.id}"]
}
resources {
memory = 2
cores = 2
}
boot_disk {
type = "network-hdd"
size = 64
}
scheduling_policy {
preemptible = false
}
container_runtime {
type = "containerd"
}
}
scale_policy {
fixed_scale {
size = 1
}
}
allocation_policy {
location {
zone = "ru-central1-a"
}
}
maintenance_policy {
auto_upgrade = true
auto_repair = true
maintenance_window {
day = "monday"
start_time = "15:00"
duration = "3h"
}
maintenance_window {
day = "friday"
start_time = "10:00"
duration = "4h30m"
}
}
}Но виртуальных машин у нас может быть много, да и кластеров K8s тоже. Поэтому разделим их не по типу ресурса, а по проектам. Так проще сопровождать конкретный проект. Создадим файл project1.tf.
Зависимости
Ресурсы в манифестах обязательно зависят друг от друга — идентификаторы одних ресурсов будут использоваться в описании других.
Например, чтобы быстро находить серверы при настройке сетевых доступов между ними, создадим файл для групп безопасности (security groups) — sg.tf.
Виртуальным машинам нужен доступ в Kubernetes, а сервисам в Kubernetes — к виртуальным машинам. А ещё некоторые виртуальные машины «ровнее других», и им нужен доступ к сервисам в другом проекте (но не наоборот).
В одном проекте такие зависимости легко реализуются. Можно сослаться на идентификатор ресурса в соответствующих правилах:
resource "yandex_vpc_security_group" "group1" {
name = "My security group 1"
description = "description for my security group"
network_id = yandex_vpc_network.foo.id
# Разрешаем исходящий трафик к хостам group2
egress {
protocol = "UDP"
description = "rule3 description"
security_group_id = yandex_vpc_security_group.group2.id
port = 8080
}
}
resource "yandex_vpc_security_group" "group2" {
name = "My security group 2"
description = "description for my security group"
network_id = yandex_vpc_network.foo.id
# Разрешаем входящий трафик от хостам group1
ingress {
protocol = "TCP"
description = "rule1 description"
security_group_id = yandex_vpc_security_group.group1.id
port = 8080
}
}Но подождите, у нас тут циклическая зависимость двух ресурсов. Давайте для каждого сервиса будем создавать по две группы безопасности. Одну сделаем пустой и будем указывать её в правилах других групп безопасности, а вторая поработает в правилах:
# Пустая группа для хостов group1
resource "yandex_vpc_security_group" "group1-initial" {
name = "My initial security group 1"
description = "description for my security group"
network_id = yandex_vpc_network.foo.id
}
resource "yandex_vpc_security_group" "group1" {
name = "My security group 1"
description = "description for my security group"
network_id = yandex_vpc_network.foo.id
# Чтобы избежать циклических зависимостей, указываем пустую group2-initial
egress {
protocol = "UDP"
description = "rule3 description"
security_group_id = yandex_vpc_security_group.group2-initial.id
port = 8080
}
}
resource "yandex_vpc_security_group" "group2-initial" {
name = "My security group 2"
description = "description for my security group"
network_id = yandex_vpc_network.foo.id
}
resource "yandex_vpc_security_group" "group2" {
name = "My security group 2"
description = "description for my security group"
network_id = yandex_vpc_network.foo.id
ingress {
protocol = "TCP"
description = "rule1 description"
security_group_id = yandex_vpc_security_group.group1-initial.id
port = 8080
}
}Запутанно, тут у нас зарождается начало первой макаронины, но зато это решает нашу проблему с циклом. А все зависимости между сервисами можно держать в голове: когда джун придёт за помощью, вы быстро укажете строчку в манифесте, чтобы вставить нужное правило.
Некоторое время спустя
Репозиторий разрастается, к одному способу организации добавляется второй, а потом третий, и мы получаем вот такой набор файлов.
Содержимое репозитория
.
├── project1.tf
├── project1-xyz.tf
├── project1-db-master.tf
├── project1-s3-project2-copy1.tf
├── project1-s3-project3-copy1.tf
├── project1-s3-project3.tf
├── project1-s3-project4.tf
├── project1-subnets.tf
├── project1-secrets.tf
├── project-6.tf
├── project2-test.tf
├── project2-test2.tf
├── project2-integrations.tf
├── project2-from-company.tf
├── project2-dev.tf
├── project2-ci.tf
├── project2-to-company-sg.tf
├── project2-to-company.tf
├── jump-host.tf
├── monitoring.tf
├── cdn-internal.tf
├── cdn-external.tf
├── cicd.tf
├── siem-dev-compute.tf
├── cloud-init
│ ├── de-keys
│ ├── de-devops-keys
│ ├── de-admin-keys
│ ├── de-whoami-keys
│ ├── devops-keys
│ ├── ipv4-router.yaml
│ ├── ipv6-router.yaml
│ ├── scripts.yaml
│ ├── k8s-keys
│ ├── super-super-users.yaml
│ └── super-users.yaml
├── cloud.tf
├── cloud_company_test.tf
├── compute-non-production.tf
├── compute.tf
├── control.tf
├── servers.tf
├── dev-project1-integrations-kafka-topics.tf
├── dev-project1-integrations-kafka.tf
├── dev-project1-integrations.tf
├── dev-project1-db.tf
├── my-vm.tf
├── dns-microservices.tf
├── dns-macroservices.tf
├── inokentiy.tf
├── accounting-1c.tf
├── accounting-1c-enterprise.tf
├── accounting-backups.tf
├── accounting-db.tf
├── accounting-analytics.tf
├── accounting-project8-s3.tf
├── accounting-containers.tf
├── accounting-s3.tf
├── accounting-subnets.tf
├── accounting.tf
├── express-all.tf
├── security-rules-s3.tf
├── security-rules.tf
├── ci-project1-sec.tf
├── ci-ansible.tf
├── ci-autotests.tf
├── ci-common.tf
├── ci-deploy.tf
├── ci-accounting.tf
├── ci-infra.tf
├── ci-here.tf
├── ci-project8.tf
├── ci-build.tf
├── ci-tf.tf
├── cicd2.tf
├── mons.tf
├── iam.tf
├── proxy-nonsecure.tf
├── proxy-secure.tf
├── ipsec.tf
├── k8s-sib.tf
├── k8s-common.tf
├── k8s-dev-common-nodes.tf
├── k8s-dev-ingress.tf
├── k8s-dev-nodes.tf
├── k8s-dev-sa.tf
├── k8s-dev-vm-nodes.tf
├── k8s-dev.tf
├── k8s-secure-dev-common-nodes.tf
├── k8s-secure-dev-ingress.tf
├── k8s-secure-dev-nodes.tf
├── k8s-secure-dev-vm-nodes.tf
├── k8s-secure-dev.tf
├── k8s-test-common-nodes.tf
├── k8s-test-ingress.tf
├── k8s-test-nodes.tf
├── k8s-test-secure-common-nodes.tf
├── k8s-test-secure-ingress.tf
├── k8s-test-secure-nodes.tf
├── k8s-test-secure-sql-nodes.tf
├── k8s-test-secure-vm-nodes.tf
├── k8s-test-secure.tf
├── k8s-test-sa.tf
├── k8s-test-vm-nodes.tf
├── k8s-test.tf
├── keys.tf
├── lb.tf
├── test-dev-compute.tf
├── adapter.tf
├── connector.tf
├── db-backend-baza.tf
├── db-backend.tf
├── db.tf
├── midnight-computer.tf
├── nat.tf
├── network.tf
├── cache.tf
├── outputs.tf
├── secure-dmz.tf
├── backups.tf
├── project8-stand-folder.tf
├── project8-stand-sg.tf
├── project8-stands.tf
├── project8-proxy.tf
├── project8-new-left.tf
├── project8-new.tf
├── project8-new-vars.tf
├── project8-folder.tf
├── project8-some-tests.tf
├── project8-lb.tf
├── project8-proxy-compute.tf
├── project8-proxy-sg.tf
├── project8-proxy-variables.tf
├── project8-smoke-compute.tf
├── project8-smoke-dns.tf
├── project8-smoke-db.tf
├── project8-smoke-network.tf
├── project8-smoke-s3.tf
├── project8-smoke-sg.tf
├── project8-smoke-variables.tf
├── project8-test-compute.tf
├── project8-test-dns.tf
├── project8-test-folder.tf
├── project8-test-lb.tf
├── project8-test-lockbox.tf
├── project8-test-db.tf
├── project8-test-network.tf
├── project8-test-copies.tf
├── project8-test-sg.tf
├── project8-test-variables.tf
├── project8-testlab-compute.tf
├── project8-to-internet.tf
├── project8-test-folder.tf
├── project8-test.tf
├── proxy-to-partners.tf
├── qa.tf
├── containers.tf
├── s3.tf
├── s3_project8_project1.tf
├── s3_project8_project2.tf
├── external-to-project8.tf
├── scripts
│ ├── manage.sh
│ └── unmanage.sh
├── project7-test.tf
├── project7.tf
├── sg-for-servers.tf
├── sg.tf
├── sg-nikolay.tf
├── work-in-progress.tf
├── ver1-work-in-progress.tf
├── sib-compute.tf
├── sib-lb.tf
├── sib-db.tf
├── sib-other.tf
├── sib-sg.tf
├── wtf.tf
├── analyze-compute.tf
├── analyze-lb.tf
├── analyze-db-proxy.tf
├── analyze-other.tf
├── analyze-sg.tf
├── templates
│ ├── script.yaml
│ ├── open.yaml
│ ├── forwarder.yaml
│ ├── logs.yaml
│ └── logs-forwarder.yaml
├── test-project1-integrations-kafka-topics.tf
├── test-project1-integrations-kafka.tf
├── test-project1-integrations.tf
├── test-project1-db-int.tf
├── test-project1-db.tf
├── test-project1-s3-exchange.tf
├── test-project1-s3-project8.tf
├── test-project1-s3-wtf.tf
├── test-project1-subnets.tf
├── test-dns-microservices.tf
├── test-dns-macroservices.tf
├── test-backend-kafka.tf
├── test-backend-redis.tf
├── test-backend-db.tf
├── secrets-test-dev-compute.tf
├── secrets.tf
├── playground.tf
├── manager.tf
├── s3-share.tf
└── sa.tfЕсли вы хотели посмотреть на реальный проект — вот он выше.
Теперь нам нужно разделить тестовое и продовое окружения, и после долгой плодотворной дискуссии мы с командой решаем продублировать весь этот набор файлов для прода.
Если запустить terraform plan в таком проекте, то можем ждать от 10 до 40 минут, и наш state заблокируется на всё время выполнения.
planпоказывает намерения изменений, которые Terraform собирается выполнить.
terraform state— это хранилище состояния текущей инфраструктуры. Такое состояние сравнивается с кодом описания в манифестах и с реальным положением вещей в облаке. После такого сравнения Terraform принимает решение о выполнении изменений. Стейт хранится в файле, поэтому можете использовать различные бэкенды для централизованного размещения этого файла.
Как раз успеете распить цикорий всей командой.
Хотя, конечно, добавление очередной виртуальной машины или правила в группу безопасности займёт гораздо больше времени: понадобится раскрутить клубок зависимостей, вставить описание ресурсов в нужное место и проделать несколько итераций запуска terraform plan для отладки изменений.
Одна и та же задача решается по-разному в разных файлах, и кажется, чтобы проделать аналогичное изменение в этот раз, проще создать новый файл и описать ресурсы заново.
Самое главное — работой вы точно будете обеспечены! Со временем и вовсе станете матёрыми экспертами: в голове кристаллизуется граф зависимостей между ресурсами, в котором вы будете хорошо ориентироваться, а у молодого и неопытного джуна появится наставник.
Вам же придётся доверять этому коду до тех пор, пока в голове «сидят» особенности работы всех зависимостей.
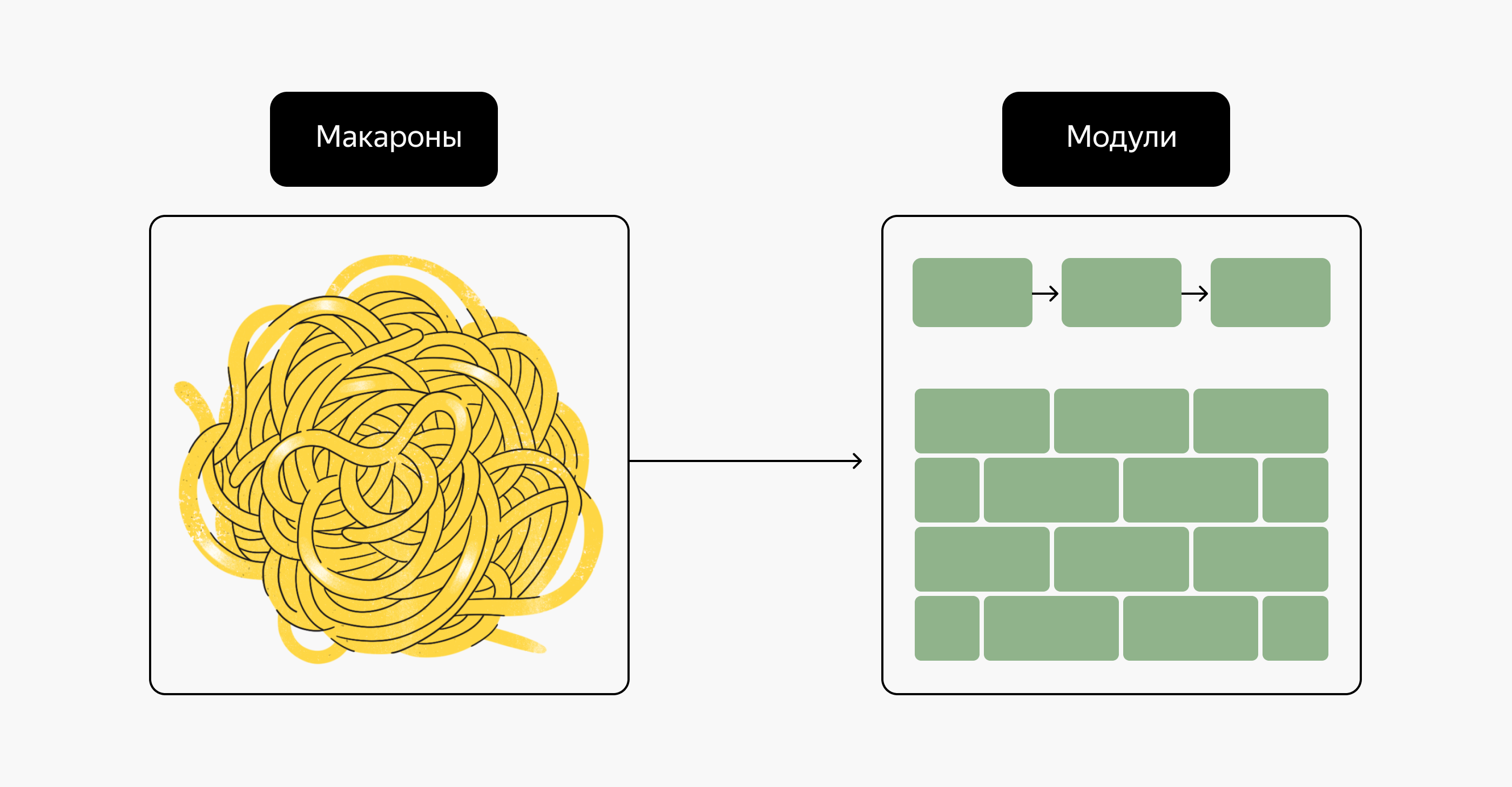
А что тут плохого?
Давайте выпишем список совершенных грехов:
В репозитории отсутствует хоть сколько-нибудь логичная структура — в этом наборе файлов сам чёрт ногу сломит.
Блокирование стейта снижает эффективность команды: кто-то катит очередные изменения, а вы ждёте, пока они применятся.
Неопределённые интерфейсы в зависимостях. Тут можно провести аналогию с языками динамической типизации: несоответствия типов могут всплывать слишком поздно, когда они уже нанесли вред продовой инфраструктуре.
Много «копипасты» и повторения кода.
К такому коду мало доверия: новичку сложно ответить на вопрос «Что будет, если я запущу
terraform apply?».Как это всё запускать в CI?
А как надо?
Модули
Описание вашего проекта нужно начать с Terraform-модулей. Terraform-модуль — это набор манифестов, собранных вместе для решения определенной задачи. Модуль можно выложить в общий доступ с помощью git-репозитория, хранить локально или использовать специальный сервис Terraform Registry. Типовой модуль может иметь следующую файловую структуру:
├── main.tf
├── outputs.tf
├── variables.tf
├── README.mdВо-первых, модули создают удобные абстракции, и вы можете описать инфраструктуру с помощью архитектурных терминов вместо использования физических объектов. Сравните:
Слева | Справа |
В этом проекте нам нужно запустить три сервера в разных зонах доступности, балансировщик и кластер баз данных | В этом проекте мы запустим сервис API-прокси для бесшовной интеграции нового бэкенда |
И какой вариант вам больше нравится?
Во-вторых, модули описывают строгие контракты для входных и выходных переменных. При использовании модулей вы соединяете выходные переменные (outputs) одного модуля c входными переменными (variables) другого модуля, а строгие контракты позволяют избежать ошибок в процессе сопровождения инфраструктуры и серьёзных инцидентов.
Например, описание сложной переменной для сетевых интерфейсов определяется её типом:
variable "network_interfaces" {
description = "Instance network interfaces"
# optional и значения по умолчанию появились в Terraform ≥ 1.3
type = map(object({
subnet_id = string
ip_address = optional(string)
security_group_ids = optional(set(string))
ipv6 = optional(bool)
nat = optional(bool)
nat_ip = optional(string)
dns_record = optional(object({
dns_zone_id = string
ttl = optional(number, 300)
ptr = optional(bool, true)
}))
nat_dns_record = optional(object({
dns_zone_id = string
ttl = optional(number, 300)
ptr = optional(bool, true)
}))
}))
default = {}
}Если на вход подать некорректный объект, например, не указав обязательное поле subnet_id, то Terraform сообщит нам об ошибке на ранней стадии валидации кода.
В-третьих, для каждого отдельного модуля можно написать тесты.
Тесты
Тесты для инфраструктурной автоматизации обеспечивают надёжное доверие к этой самой инфраструктурной автоматизации: поведение модуля тестируют на разных входных параметрах, а при изменении кода модуля можно будет понять влияние этого изменения на инфраструктуру.
Тесты особенно полезны в сложных модулях, в которых используются динамические блоки, циклы и вычисляемые локальные переменные (locals): поведение таких модулей почти невозможно прогнозировать, только читая код.
Наиболее популярный фреймворк для тестирования модулей — это Terratest — библиотека для Go, с помощью которой можно проверить как простые test-кейсы (ожидаемый output), так и сложную интеграционную логику с другими модулями.
package test
import (
"testing"
"github.com/gruntwork-io/terratest/modules/terraform"
"github.com/stretchr/testify/assert"
)
func TestTerraformModule(t *testing.T) {
terraformOptions := terraform.WithDefaultRetryableErrors(t, &terraform.Options{
TerraformDir: "./tests",
})
// Удаляем ресурсы после тестов
defer terraform.Destroy(t, terraformOptions)
// Запускаем apply для тестовых ресурсов
terraform.InitAndApply(t, terraformOptions)
output := terraform.Output(t, terraformOptions, "hello_world")
// Проверяем - тестируем, что output соответствует ожиданиям
assert.Equal(t, "Hello, World!", output)
}При тестировании Terraform-модулей будет создаваться реальная инфраструктура в облаке. Такие тесты не похожи на Unit-тестирование — возможности создать mock-объекты для облачных провайдеров пока нет. Хотя что-то можно проверить, анализируя только вывод
terraform plan.
Разбивка кода проекта на логичную структуру
Теперь подумаем, как нам разбить весь проект на логичную структуру. В любом проекте обязательно выделяется инфраструктурный фундамент в виде VPC, подсетей и DNS-зоны. Назовём этот фундамент infra:
.
└── terraform
└── infra
├── dns
│ └── main.tf
├── sa
└── vpcДля каждого окружения заведём отдельную директорию:
.
└── terraform
├── envs
│ ├── dev
│ ├── prod
│ └── test
└── infra
├── dns
├── sa
└── vpcНо для работы с такой структурой нам нужно зайти в каждую директорию и выполнить terraform apply, а для обмена данными можно использовать terraform_remote_state источника данных (data source).
Terragrunt
Конечно, в любой CI-системе это можно организовать с помощью скриптов. Для оркестрации инфраструктурного Terraform-кода в сложном проекте хорошо зарекомендовал себя инструмент-враппер Terragrunt. Как и в случае с чистым Terraform, вы разбиваете код на модули, но для вызова этих модулей и передачи им входных переменных используете конфигурационные файлы terragrunt.hcl:
.
└── terraform
├── envs
│ ├── dev
│ │ └── compute
│ │ └── terragrunt.hcl
│ │ k8s
│ │ └── terragrunt.hcl
│ ├── prod
│ └── test
└── infra
├── dns
├── sa
└── vpcПри выполнении команды terragrunt run-all apply в корневой директории проекта оркестратор пройдётся по всем вложенным директориям и применит конфигурацию модуля, описанную в terragrunt.hcl.
Для каждого расположения конфигурации Terragrunt создаст свой собственный state-файл, например, envs/dev/compute/terraform.tfstate в настроенном бэкенде, а для обмена данными между этими стейтами будут использоваться переменные и выходные переменные модулей.
Чтобы описать зависимости между двумя модулями, используют ключевое слово dependency:
dependency "vpc" {
config_path = "../../../infra/vpc"
}
inputs = {
vpc_id = dependency.vpc.outputs.vpc_id
}В этом примере мы описали зависимость модуля compute от модуля vpc и передали входную переменную vpc_id в модуль compute.
Вспомним всё и подведём итоги
Давайте теперь вспомним список проблем, который мы составляли в самом начале, и что получили:
В репозитории присутствует логичная структура: модули и их использование в Terragrunt позволили разбить код на логичные структурные блоки.
Каждая небольшая часть инфраструктуры работает со своим состоянием, не блокируя работу с другими: для каждого окружения создаётся свой state-файл.
Между модулями определены интерфейсы в виде входных переменных и выходных значений.
Организация кода в виде модулей добавляет возможность переиспользования.
К коду модуля больше доверия за счёт тестов: мы можем убедиться, что модуль работает корректно.
CI теперь можно организовать довольно гибко: для каждой части инфраструктуры и для каждого окружения.
Заключение
В этой статье мы рассмотрели, как можно организовать инфраструктурный код в Terraform-проекте. Мы разбили код на модули, описали зависимости между ними и научились запускать их с помощью Terragrunt.
Теперь можно смело переходить к следующему этапу — автоматизации с помощью CI-систем. Конечная цель организации инфраструктурного кода — создание надёжной и масштабируемой инфраструктуры, которая может поддерживаться и расширяться без лишних трудностей для SRE-инженера и команды, а таких трудностей можно избежать благодаря CI-системам.
Тестирование кода с помощью Terratest также имеет решающее значение для обеспечения качества и безопасности вашей инфраструктуры. Тестирование позволяет проверить, работает ли код так, как он должен работать, и выявлять ошибки и проблемы до того, как они станут критическими. Тестирование также помогает вам убедиться, что ваша инфраструктура работает так, как вы ожидаете, и что она не будет нежелательно изменена во время разработки.
