Хрустальный шар с извилинами: как мозг предсказывает речь

Мозг человека считается одним из самых сложных механизмов, на понимание работы, которого люди потратили не одно столетие, но так и не смогли получить полную картину. Именно в мозге протекают процессы, связанные с обработкой и хранением информации, с принятием решений, с контролем действий. Но до сих пор ученый свет не может дать единый ответ на вопрос — каков основной принцип или механизм работы мозга? Многие считают, что мозг работает по принципу сравнения сенсорной информации и построенных в нем предсказаний. К примеру, участвуя в беседе, человек воспринимает ряд сенсорной информации — голос собеседника, речь (т. е. сами слова), мимика, движения. А его мозг постоянно пытается предсказать, что собеседник скажет дальше. Ранее это была лишь теория, но благодаря ученым из Института психолингвистики Макса Планка (Нидерланды) теория была подтверждена на практике. Какие опыты провели ученые, что они показали, и смогли ли они открыть тайну работы мозга? Ответы на эти вопросы мы найдем в докладе ученых. Поехали.
Основа исследования
Для нас речь является обыденным делом, но на нейронном уровне это сложнейший процесс. И речь идет даже не о говорении, а о восприятии речи. Для понимания устной речи требуется преобразования неоднозначных потоков стимулов в иерархию все более абстрактных репрезентаций, начиная от звуков речи и заканчивая смыслом. Есть теория, что во время этого процесса мозг полагается на предсказание, чтобы направлять интерпретацию поступающей информации в нужное русло. Этот феномен был назван предиктивной обработкой, которая была успешно применена для создания искусственных систем распознавания речи. Помимо этого были исследования, показавшие наличие этого феномена и в других процессах, связанных, к примеру, с восприятием и двигательным контролем. Следовательно, можно предположить, что предиктивная обработка является фундаментальным процессом, который управляет всеми другими подпроцессами работы мозга.
Существует ряд доказательств реальности предиктивной обработки речи. Например, поведенческие и мозговые реакции очень чувствительны к нарушениям лингвистических закономерностей и к отклонениям от языковых ожиданий в более широком смысле. Хотя такие эффекты хорошо задокументированы, два важных вопроса о роли предсказания в обработке речи остаются нерешенными.
Первый вопрос касается степени распространенности прогнозирования. Одни труды показывают, что прогностическая обработка речи повсеместна и происходит рутинно и непрерывно у любого человека. Другие исследования говорят об обратном, указывая на преувеличение важности этого процесса ввиду применения неточных методов экспериментальной оценки.
Второй вопрос касается репрезентативной природы предсказаний: происходит ли лингвистическое предсказание прежде всего на уровне синтаксиса или, скорее, на лексическом, семантическом или фонологическом уровне?
В рассматриваемом нами сегодня труде ученые попытались получить ответы на оба эти вопроса. В частности, они проанализировали записи активности мозга из двух независимых экспериментов участников, слушающих аудиокниги, и использовали нейронную сеть (GPT-2) для количественной оценки лингвистических предсказаний.
Результаты исследования
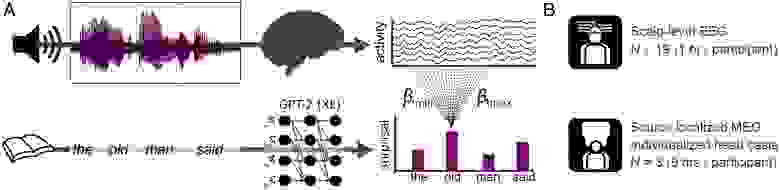
Изображение №1
В ходе опытов испытуемые слушали аудиокнигу в исполнении человека (т. е. речь была естественное, а не сгенерированной компьютером). В первом варианте опыта в течение 1 часа велась электроэнцефалографическая запись (ЭЭГ) активности мозга 19 участников. Во втором эксперименте были собраны 9-часовые магнитоэнцефалографические (МЭГ) данные у трех испытуемых с использованием индивидуальных слепков головы, которые позволили с высокой точностью локализовать нейронную активность.
Первым делом ученые попытались найти доказательства лингвистического предсказания в целом. Они пришли к выводу, что, если мозг постоянно предсказывает будущую речь, нейронные реакции на слова должны быть чувствительны к нарушениям контекстуальных предсказаний, давая сигналы «ошибки предсказания», которые считаются отличительной чертой предсказательной обработки. Для этого был использован метод деконволюции (регрессионный ERP*), что позволило оценить влияние ошибки прогнозирования на вызванные ответы.
ERP* (event-related potential / потенциал, связанный с событием) — измеренный отклик мозга, который является прямым результатом определенного ощущения, когнитивного или моторного события.
Чтобы количественно оценить лингвистические предсказания, был проведен анализ книг, которые слушали испытуемые, с помощью GPT-2 модели. GPT-2 — это большая модель на основе преобразователя, которая предсказывает следующее слово по предыдущим словам.
Чтобы проверить, модулируются ли нейронные реакции на слова контекстуальными предсказаниями, было проведено сравнение трех регрессионных моделей.
Базовая модель формализовала гипотезу о том, что естественное, пассивное понимание языка не требует предсказания. Эта модель не включала регрессоры, связанные с контекстуальными прогнозами, но включала потенциально смешанные переменные (такие как частота, сложность семантической интеграции и акустика).
Модель ограниченного предсказания формализовала гипотезу о том, что во время понимания речи предсказания генерируются не постоянно, а только для подмножества слов в ограничивающих контекстах и эти прогнозы работают по принципу «все или ничего».
Данная модель была реализована с применением всех регрессоров из базовой модели, а также регрессор «неожиданностей». Этот регрессор был включен только для подмножества слов в наиболее ограничивающих контекстах. Была использована линейная метрика невероятности слова, поскольку предсказание по принципу «все или ничего» приводит (в среднем) к линейной зависимости между вероятностью слова и реакцией мозга.
Третья модель рассматривала непрерывное прогнозирование и включала все регрессоры из базовой модели, а также логарифмическую метрику невероятности слова (неожиданности) для каждого слова в аудиокниге. Это формализовало гипотезу о том, что мозг постоянно генерирует вероятностные прогнозы и что реакция на стимул пропорциональна его отрицательной логарифмической вероятности.

Изображение №2
Сравнение всех трех моделей в рамках их способности прогнозировать активность мозга показала, что именно модель непрерывного прогнозирования работает лучше остальных (2A). Эффект был очень последовательным как у ЭЭГ испытуемых, так и у МЭГ испытуемых.
Модель ограниченного прогнозирования отличалась от модели непрерывного прогнозирования в двух аспектах: она предполагала линейную зависимость между вероятностью и реакцией мозга; прогнозы ограничены ограничивающими контекстами.
Дополнительное сравнение модели непрерывного прогнозирования с другими контрольными моделями подтвердило, что в процессе восприятия речи эффекты предсказуемости слов являются логарифмическими и не ограничиваются словами в ограничивающем контексте. Эти эффекты обнаруживаются как для контекстных слов, так и для функциональных (вспомогательных).
Установив, что неожиданность слова модулирует нейронные реакции, ученые охарактеризовали этот эффект в пространстве и времени. Анализируя MEG данные, ученые попытались понять, какие нейронные источники лексической неожиданности были наиболее важными для объяснения нейронных данных, сравнив эффективность базовой модели и модели непрерывного прогнозирования.
Это показало, что общая неожиданность слова модулировала нейронные ответы во всей речевой сети (2C). Опыты с применением неожиданных слов показал, что они вызывают наиболее негативный нейронный ответ. Другими словами, мозг при прослушивании аудиокниги ожидает (прогнозирует) услышать определенное слово. Если же в результате произносится совершенно другое, то это вызывает всплеск нейронной активности максимума через 400 мс после начала слова (2B).
В совокупности эти результаты представляют собой явное свидетельство прогностической обработки, подтверждая, что ответы мозга на слова модулируются прогнозами. Эти модуляции не ограничиваются сдерживающими контекстами и происходят во всей речевой сети.
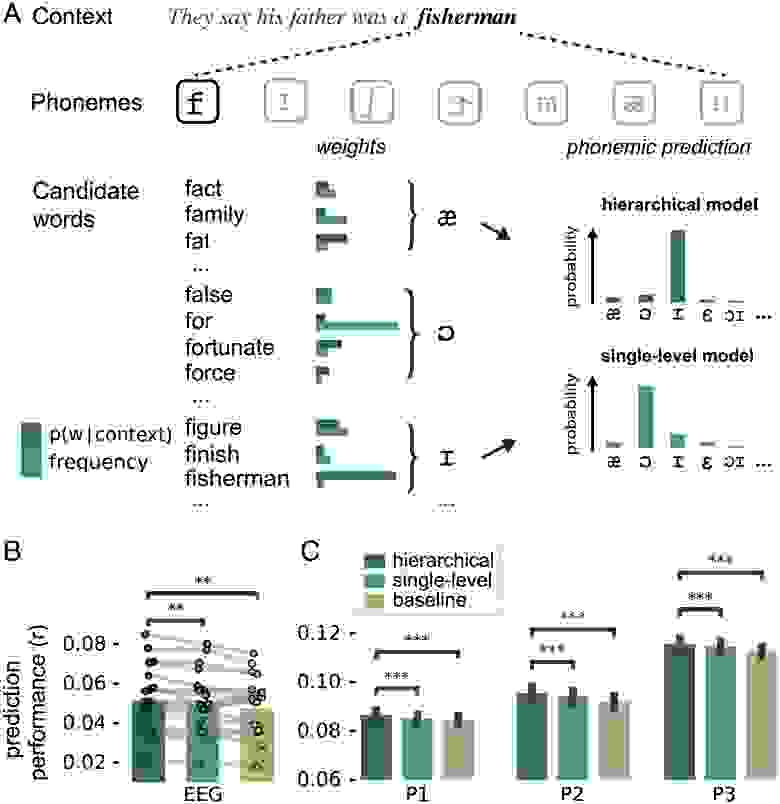
Далее необходимо было понять, на каком уровне происходит предсказание — синтаксис, семантика, фонетика или на всех уровнях сразу.
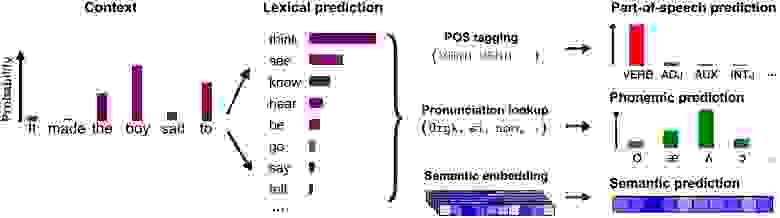
Изображение №3
Чтобы это выяснить, ученые разделили совокупные лингвистические прогнозы на уровне слов из искусственной нейронной сети на отдельные лингвистические измерения (схема выше).
Это позволило получить оценки трех предсказаний, специфичных для конкретных признаков: предсказание части речи (POS от part of speech) (определяемое как распределение вероятности по синтаксическим категориям), семантическое предсказание и фонематическое предсказание.
Ученые предположили, что если мозг генерирует прогнозы на заданном уровне (например, синтаксисе или грамматике), то нейронные реакции должны быть чувствительны к ошибкам прогнозирования, специфичным для этого уровня. Для проверки этой гипотезы была сформулирована новая регрессионная модель, включающая в себя все переменные из модели лексического прогнозирования в качестве отвлекающих регрессоров и три дополнительных регрессора интереса.
Поскольку эти регрессоры были в какой-то степени коррелированны, необходимо было понять, к какой области мозга относится каждый из них, а также на какие аспекты прогнозирования они влияют.
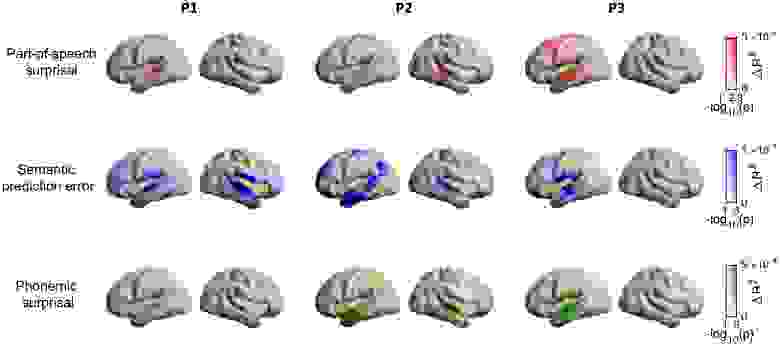
Изображение №4
Несмотря на индивидуальные отличия между участниками МЭГ исследования, наблюдалась вполне однородная картина нейронной активности в ответ на те или иные регрессоры. В зависимости от типа регрессора, отвечающего за определенный речевой уровень (семантика, фонетика и т. д.), наблюдался всплеск нейронной активности в определенной зоне мозга.
Это показывает, что мозг по-разному реагирует на разные типы лингвистических элементов. Другими словами, процесс речевого прогнозирования осуществляется на всех уровнях речевого восприятия.
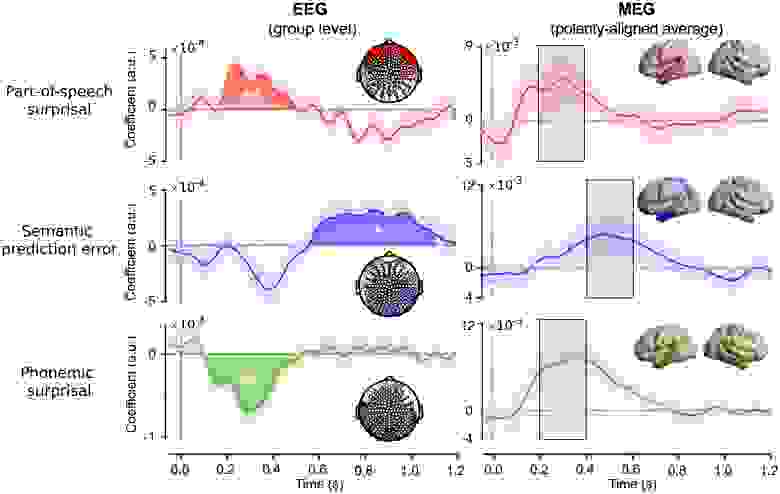
Изображение №5
Установив, что три разных типа ошибок предсказания независимо модулируют нейронные реакции в разных областях мозга, ученые дополнительно исследовали природу этих эффектов. Это было сделано путем проверки коэффициентов, которые описывают, как колебания данного регрессора модулируют реакцию с течением времени.
Данный анализ показал, что разные классы ошибок предсказания взывают реакции мозга, которые диссоциированы как во времени, так и в пространстве. В частности, в то время как фонематические прогнозы и прогнозы POS модулируют относительно ранние нейронные ответы (от 100 до 400 мс) в ряде фокальных височных (и лобных) областей, которые являются ключевыми для синтаксической и фонетической/фонематической обработки, семантические прогнозы модулируют более поздние ответы (> 400 мс) в широко распределенном наборе областей распределенной семантической системы.
Эти результаты показывают, что лингвистическое предсказание не реализуется одной системой, а происходит во всей речевой и языковой сети, образуя иерархию лингвистических предсказаний на всех уровнях анализа.
Изображение №6
Установив, что мозг генерирует лингвистические прогнозы на нескольких уровнях анализа, ученые решили проверить, взаимодействуют ли между собой прогнозы на разных уровнях.
Одна гипотеза говорит о том, что они инкапсулированы: прогнозы в отдельных системах могут использовать разную информацию, например, разворачиваться в разных временных масштабах, что делает их независимыми.
Другая же говорит о том, что прогнозы на разных уровнях могут информировать и ограничивать друг друга, эффективно сходясь в одно многоуровневое прогнозирование, как предполагает иерархическая прогностическая обработка.
Одним из способов определить, какая из гипотез верна, является оценка различных схем получения фонематических прогнозов. Такие прогнозы могут быть основаны исключительно на информации, получаемой в короткий промежуток времени. В таком варианте прогнозируемая вероятность следующей фонемы получается из когорты слов, совместимых с фонемами на данный момент (6А). Таким образом, эта схема влечет за собой одноуровневую модель: прогнозы основаны только на одном уровне информации — коротких последовательностях фонем. Другими словами, мозг пытается спрогнозировать последующие слова, основываясь исключительно на предыдущих фонемах.
Альтернативный вариант заключается в использовании для прогнозирования не только последовательных фонем в слове, но и более длинного предшествующего лингвистического контекста. В этом случае вероятность следующей фонемы все равно будет получена из когорты слов, совместимых с представленными до сих пор фонемами, но теперь каждое слово-кандидат взвешивается по его контекстуальной вероятности (6А). Такая модель уже может считаться иерархической, так как основана и на коротких последовательностях фонем, и на длинных последовательностях слов.
Сравнение прогностической эффективности обеих моделей показало, что прогностическая модель намного эффективнее, чем непрогностическая базовая модель (6B и 6C). Дальнейшее сравнение показало, что именно иерархическая модель прогнозирования работает значительно лучше, как в ЭЭГ, так и в МЭГ. Это говорит о том, что нейронные прогнозы фонем (основанные на коротких последовательностях звуков речи внутри слова) основаны на лексических прогнозах, эффективно включающих длинные последовательности предшествующих слов в качестве контекстов.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых и дополнительные материалы к нему.
Эпилог
В рассмотренном нами сегодня труде ученые смогли на практике подтвердить гипотезу о том, что мозг человека в рамках восприятия речи работает по принципу прогностической обработки.
В ходе опытов испытуемые слушали аудиокниги, а ученые собирали данные ЭЭГ и МЭГ, которые в дальнейшем анализировались. Слова из аудиокниг также были проанализированы с применением глубоких нейронных сетей. Это позволило установить, насколько каждое из слов непредсказуемо.
Когда мы слышим устную речь, наш мозг делает подробное статистическое ожидание для каждого слова и звука и является крайне чувствительным к степени непредсказуемости, т. е. реакция мозга куда сильнее, если слово оказывается неожиданным в контексте речи.
Ученые приводят в пример то, как мы часто заканчиваем фразы или предложения собеседника, когда он говорит медленно или забывает слово, которое хотел применить. Важная особенность заключается в том, что этот процесс протекает в мозге постоянно.
Другими словами, наш мозг можно сравнить с функцией автозаполнения в поисковиках, мессенджерах и т. д. Но, в отличие от этих программ, наш мозг предсказывает не только слова, но и другие элементы речи на разных уровнях (звуки, контекст, грамматика, семантика и т. д.).
Подобное открытие, а точнее подтверждение уже существующей теории на практике, лишний раз показывает, насколько сложной системой является мозг человека. В будущем ученые намерены провести аналогичные опыты, но уже с визуальными и слуховыми стимулами, дабы понять, есть ли в таком случае прогностическая обработка информации.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
