Эволюция подходов к работе с таблицами во фронтенде

Всем привет! Меня зовут Аня Ланда, я фронтенд-разработчик в Самокате. В компании я больше двух лет, общий стаж во фронтенде — 6 лет и всё это время я делаю таблицы. В этом посте расскажу про эволюцию подходов к работе с ними, что меняется на пути от нескольких сотен до сотен тысяч элементов в таблице.
Когда я рассказываю знакомым, что работаю в Самокате, люди сразу вспоминают наше приложение. Но это только верхушка айсберга, а «под водой» много самых разнообразных продуктов. Там и логистика, и управление дарксторами, и работа с курьерами-партнёрами. Мы сопровождаем все этапы бизнеса, от закупки до подсчётов, чтобы в результате всё в свежем, хорошем виде доставили к вашим дверям.
У Самоката сейчас больше 50 продуктов, и я успела поработать в трёх. Вот они на картинке, по порядку расскажу о каждом.
Promo Offering — продукт, в котором я работаю сейчас. Если вы открываете приложения и видите скидки — «минус 30%», «классная цена», что-нибудь в этом роде — то фронтенд приложил к этому руку. И это не простое зачёркивание цен в приложении. Там большая внутренняя кухня: нужно согласовать с поставщиками даты и размеры этих скидок, у них есть разные способы учёта со стороны бухгалтерии, прогнозы продаж со скидками и т.п. Всей этой историей как раз и занимается Promo Offering.
Order Manager — продукт для управления закупками у поставщиков. С него началась моя работа в Самокате и ему будет посвящена большая часть этого материала.
Логистика — продукт распределяющий по нашим дарксторам товары, которые заказали в Order Manager.
Все эти продукты — про таблицы. Казалось бы, почему так? Ответ в истории компании. Самокат вырос из стартапа, которому надо было как-то общаться по заказам с поставщиками. На старте для этого пользовались старым добрым Excel. И частично данная практика остаётся до сих пор, потому что для некоторых поставщиков это единственная понятная им форма общения.
Нашим внутренним пользователям тоже привычно видеть любимый, родной Excel. Так что с одной стороны нам надо сделать удобно (лучше, чем в Excel!), а с другой — привычно. Перетаскиваем данные и сколько-то структуру, но аккуратно проверяем, в каких случаях требуется именно компонент таблиц, а когда просто табличные данные в каком-то (не обязательно табличном) виде.
Мой первый день в Самокате
Когда я пришла в Самокат, в моём продукте не было команды фронтенда, а интерфейсная часть была написана на Angular бэкендером.
Этот «протофронтенд» решал какие-то задачи, и в нём уже были таблицы. И тут прихожу я, единственный фронтенд. В первый же день продакт приходит с задачей: «Нам нужно модифицировать определённую таблицу. Надо её масштабировать, чтобы умела делать сразу несколько вещей, а ещё в ней надо вносить изменения и переключать между группировками».

Товарищ от технической команды: «Вообще-то, у нас Angular. Давайте мы на React перепишем».
Продакт: «Мне всё равно на чём — на Angular, на React. Надо, чтобы закупщики у нас не страдали, по нажатию Enter у них количество к заказу менялось, переходило на новую строчку».
Тестировщик: «Мы автотесты писать будем? Давайте локаторов навешаем».
Продакт: «Хочется иметь выделение по Shift, и массовые действия, чтобы ускорять работу команды закупки».
Ещё один товарищ от технической команды: «Нам дизайн-система нужна».
Ещё один тестировщик вещает уже с полей: «Ребята, там на проде караул, наши закупщики 10 тысяч строк открывают, и у них страница просто падает».
Продакт думает о будущем: «Как мы будем валидировать это всё?»
И скромный бэкендер, который это всё писал на Angular: «Нам же не придётся менять API, для того чтобы это всё сделать?».
И всё это в первый день. Моё лицо было примерно как у этого кота.

Потом я составила у себя в голове план, что примерно надо сделать:
Внедрить хоть какой-нибудь компонент на React, чтобы покрывал максимум продуктовых потребностей.
С минимальными затратами переписать на React уже имеющийся функционал, который был запилен на Angular. При этом используя уже имеющиеся эндпоинты.
Понять, кто такие локаторы и немного помочь команде тестирования.
И 10 тысяч строк. С этим что-то тоже надо было делать.
Встал выбор, какой UI-кит использовать. Понятное дело, что надо было сделать быстро, с минимальными затратами и усилиями. После недолгого поиска решила предложить ребятам не писать с нуля, а выбрать готовое решение. Им стал Ant Design.
Почему Ant Design
Order Manager был уже написан на Ant Design, но на его ангулярной версии. Я почитала API, увидела, что в обеих версиях (и для Angular, и для React), одни и те же компоненты с одинаковыми свойствами и методами. Подумала, что будет легко с параллельным переносом (спойлер: не будет).
Плюс какой-то другой проект в компании тоже использовал Ant Design. К слову, тогда Самокат был в начале своего развития и не было договорённости об использовании определённого UI-кита и библиотеки компонентов.
Плюсом к выбору Ant Design была его довольно понятная документация с примерами на StackBlitz и SandBox (хотя обновляться она могла бы и побыстрее).
Дальше я посмотрела на антовские таблицы. Они имели весь тот функционал, который нам был нужен:
фиксированный заголовок;
фиксированные колонки (справа/слева);
группировка строк;
выбор нескольких строк (даже с группировкой);
сортировка и фильтрация (с кастом фильтрами);
паджинация (с миллионом настроек).
Разумеется, это всё нам предстояло дорабатывать. Плюсом было то, что у антовских таблиц прямо в документации есть гайды, как это сделать. В Ant Design были даже локаторы. Это такие штуки, к которым можно прицепиться в коде для автотестов. Айдишник, классы, data-атрибуты. Вот они на примере.

Но выбор инструмента и его допиливание — это только начало пути, который нам предстояло пройти.
Сбор хотелок от бизнеса
Специально заостряю на них внимание, потому что эти бизнес-требования не высосаны из пальца или выведены из абстрактных паттернов. Это реальные запросы пользователей к конкретному продукту.
Группировка по даркстору и по товару, чтобы все эти товары на соответствующие дарксторы можно было заказать, или, наоборот, отменить.
Редактирование — для изменения количества позиций к заказу.
Переходы по Enter. Ранее я уже писала про 10 тысяч строк. Если бы не было перехода по нажатию Enter — то всё их надо было бы прокликивать (а это кошмар).
Выбор нескольких строк. Необходимая штука для ускорения работы. Чек-боксами прочекал, взял, обнулил. Или отфильтровал товары, у которых будет скидка, выделил — удвоил для всех количество в заказе.
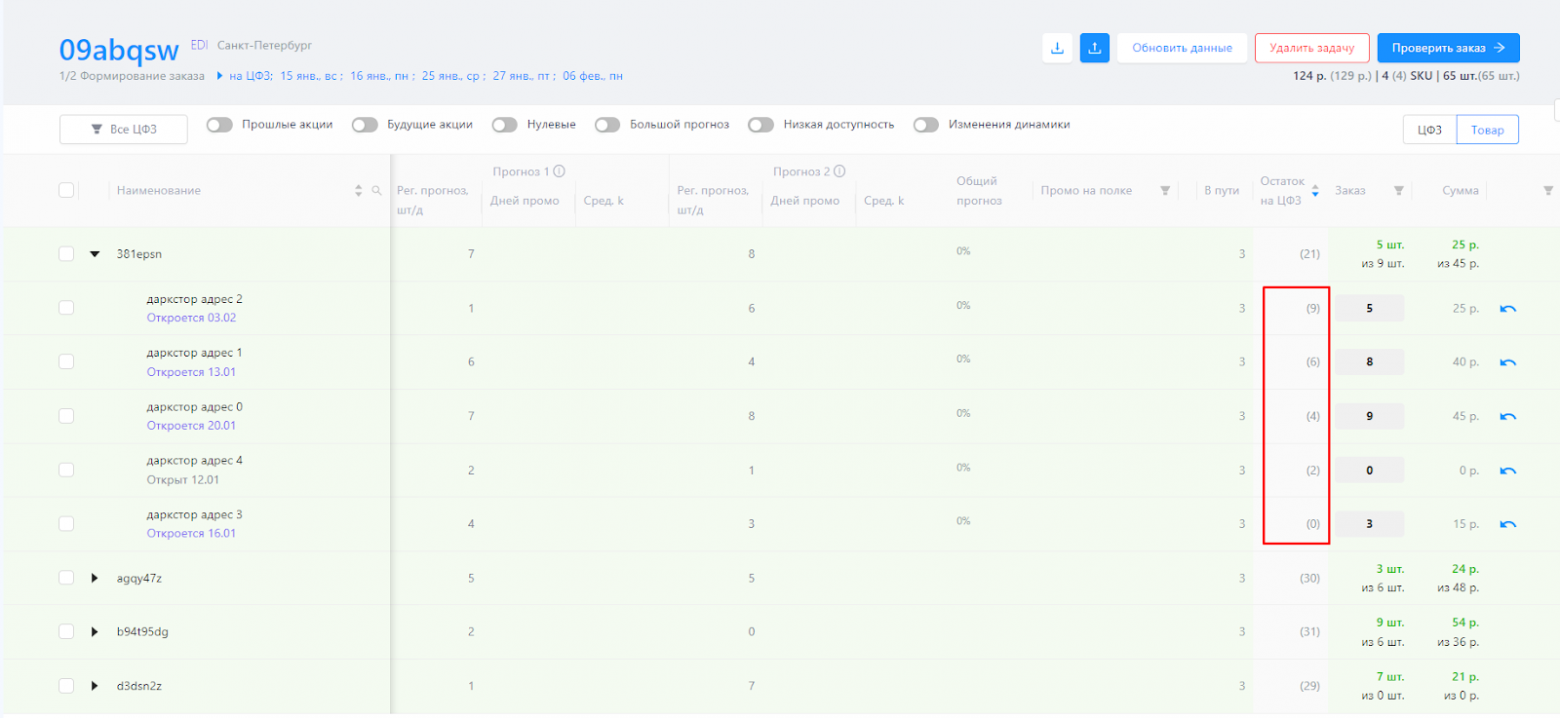
Сортировки и фильтры. Казалось бы, простая очевидная штука. Но у нас тут появилось нечто противоречащее всем UX паттернам. Нашим пользователям нужно было, чтобы таблица умела делать сортировку по разным уровням вложенности. Например, для колонки «Наименование» — по внешнему, а для колонки «Остатки на ЦФЗ (дарксторе)» — по внутреннему, т.к. важно анализировать, в каком дарксторе товара осталось меньше/больше.
После сбора бизнес-требований дошла очередь и до технических. Мы договорились немного переформатировать API. В Самокате принято беречь ресурсы бэка, поэтому мы сто раз думаем, можн ли обойтись силами фронтенда. Так, сортировка, подсчёты, фильтрация и даже группировка — остаются на фронтенде.
Первая реинкарнация таблиц
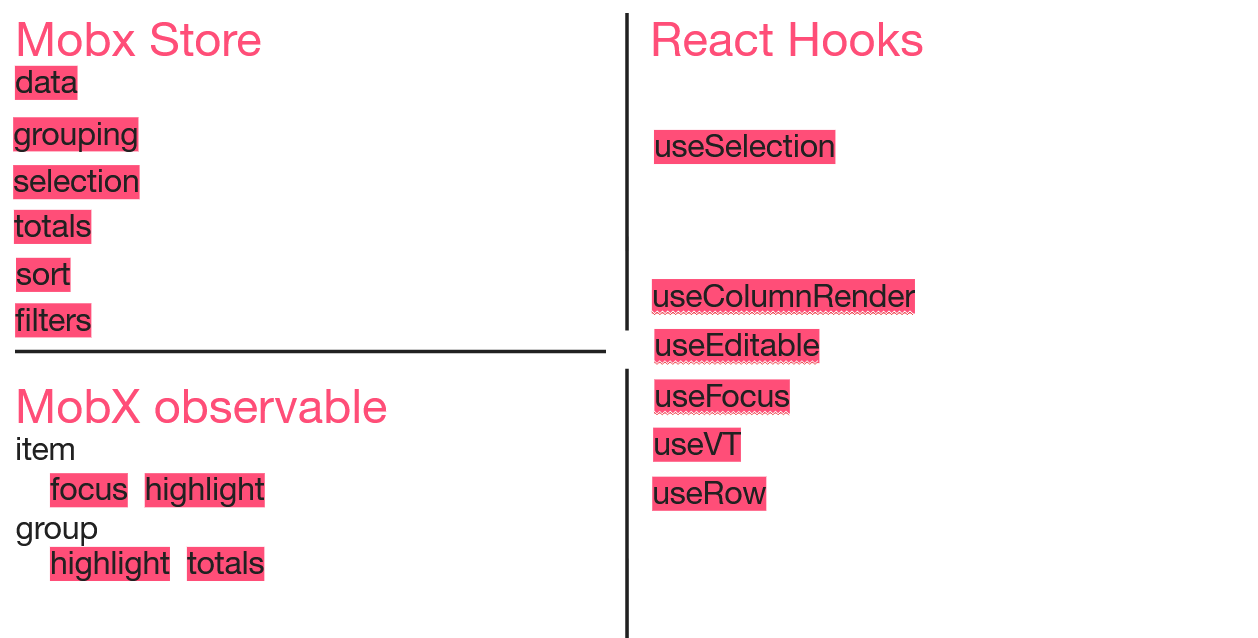
Чтобы наглядно показать преобразования, которые претерпевала наша реализация, я буду постепенно заполнять примерно такую схемку из технических сущностей, которые у нас появляются.

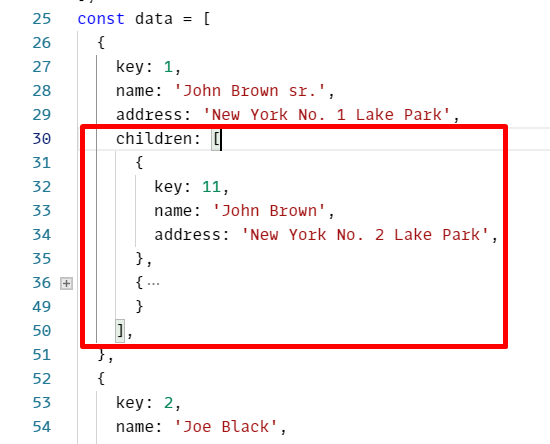
Взяв вышеописанный компонент таблицы, я решила применить те решения, которые предлагает Ant прямо из коробки. Самой сложной в реализации для меня показалась группировка. Ant прекрасно умеет отображать сгруппированные данные. Там достаточно только переформатировать данные, которые ты отправляешь в эту таблицу. К каждой строке, у которой должны быть вложенные строки, достаточно подсунуть свойство children и они отобразятся как надо.
Итак, у нас есть MobX store, который занимается получением/хранением данных, и появился hook useGrouping, в котором происходило преобразование данных для таблицы в нужном формате.
Примечание: MobX уже тогда на уровне компании был выбран в качестве «корпоративного» state-менеджера.
Дальше — реализация выбора нескольких строк. Ant тоже это всё умеет из коробки, даже с группировкой работает отлично. У чекбоксов для группировочных строк три состояния: не выбрано ничего, выбраны все вложенные и частичный выбор.

Действия с выбранными строками были вынесены в хук useSelection.
С сортировками пришлось немного помучаться, ведь предстояло учитывать, что на разных уровнях вложенности в разных колонках она должна вести себя по-разному. Тут можно прямо в колонках написать функцию-компаратор.
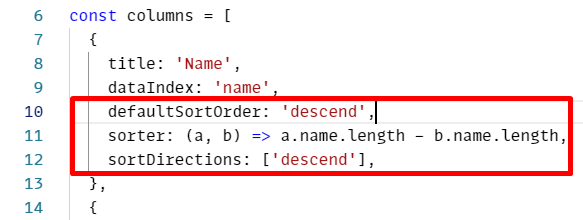
Для этих колонок я тоже завела специальный useSort хук.
С фильтрами тоже порядок. Они в Ant максимально кастомизируемые. Функция onFilter вызывается, когда в заголовке таблицы нажимаешь «применить фильтр».

И тут случается первый alarm: эта замечательная функция onFilter не вызывается для объектов внутри children. Оказалось, что в Ant можно фильтровать только по внешним строкам, а по вложенным — нельзя.
Вот, что мы сделали. У этих таблиц есть метод onChange, который слушает события применения фильтров, сортировок и паджинации. В этом методе мы и стали фильтровать данные, оформив всё это в hook useFilters. Но уже на этом этапе от первого коробочного решения, которое было зашито в компоненте, мы отказались.
Дальше мы замечаем, что группировочные и вложенные строки нужно рендерить по-разному. Да ещё рендер зависит от способа группировки. Где-то пустоту надо подставлять, где-то какой-то другой компонент, а где-то агрегированное значение.

У антовских таблиц можно кастомизировать рендер, и это прекрасно работает.

У антовских таблиц можно кастомизировать рендер, и это прекрасно работает.
Но когда колонок у тебя больше десяти, для каждой писать свой кастомный рендер — я посчитала немножко затратным и оформила в виде useColumnRender хука. Если ячейка для группировочной строки — один рендер, если нет — другой, и вся логика, что для какой колонки — разруливалось внутри этого хука.
Спойлер: не самое удачное решение, в этом проекте мы совсем от него отказались и стали действительно переписывать для каждой колонки render, но уже в следующем проекте нашли более элегантный способ. Он заключается в том, что мы переписали конфиги колонок, чтобы они поддерживали не один рендер, а несколько для разных случаев.
К этому моменту подъехала задачка про редактирование. Для того чтобы редактировать, нам нужно уметь откатывать изменения и быстро перерендеривать. И вот тут спасением стал Mobx observable в паре с observer из библиотеки mobx-react. Ты заворачиваешь одну ячейку в observer, и изменения будут слушаться только на ней. У нас появляется хук useEditable, да ещё мы стали использовать для строк таблицы класс с observable свойствами.
С переводом фокуса в нужную строчку тоже пришлось чуть-чуть поколдовать: суть в том, что по нажатию Enter требовалось переводить фокус на следующую строку, но если она последняя внутри группы, требовалось открывать следующую группу.

Итак, на данном этапе конструкция получилась такая:
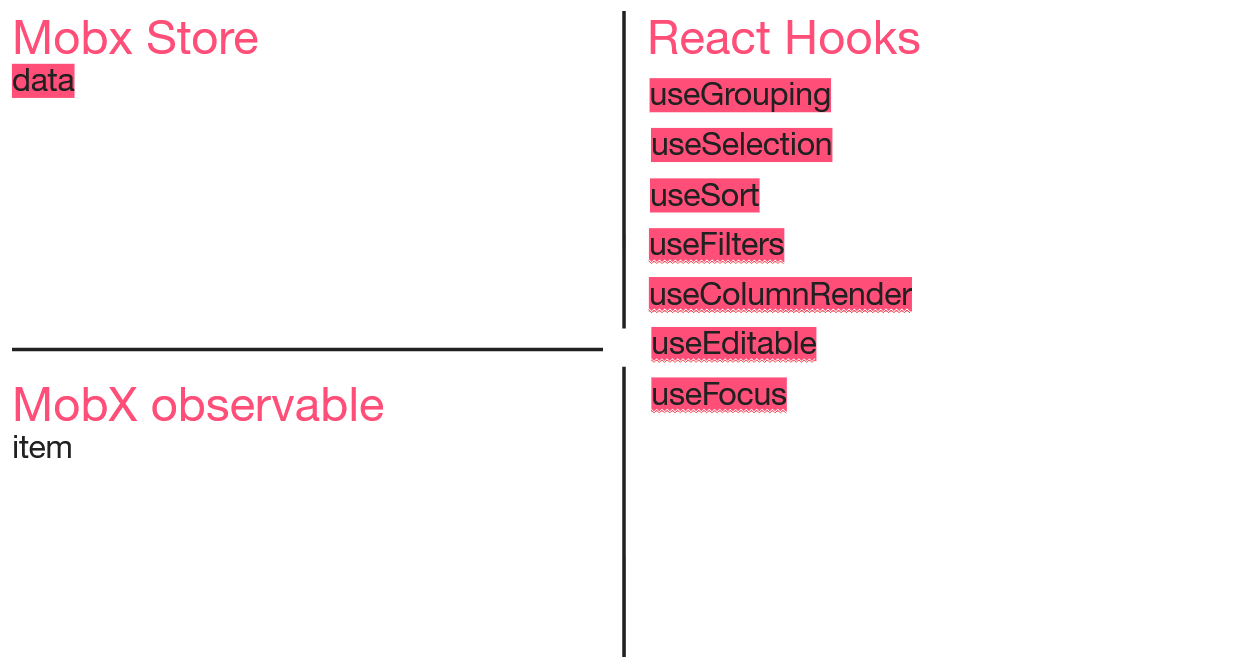
Все требования, кроме двух-трёх, покрыты. Решили, что мы релизнем это, а дальше допилим остальной функционал. Главное, что работало самое необходимое — редактирование количества к заказу и отправка этих самых заказов.
Но после передачи в тестирование пришёл alarm. Что случилось? Функционал был новый как со стороны разработки, так и со стороны бизнеса, и никто не знал, сколько там реально данных будет приходить. На тестовом стенде 1С присылала 90 тысяч строк. Фронтенд такую нагрузку не выдержал.
Стали всей командой думать, реально ли там 90 тысяч строк, или это ошибка на стороне 1С, или ещё что-то. Стали спрашивать наших пользователей. Оказалось, что это вполне реальная история. Не 90, но 40 тысяч строк точно. Сколько-то тысяч единиц товара умноженное на количество дарксторов. С этим надо было что-то делать.
Вторая реинкарнация таблиц
Я решила, что побороть долгий рендер можно прикручиванием react-virtualized. У самого Ant нет виртуализации, но есть специально написанная для него библиотека.
Но после применения хука useVT из этой библиотеки у нас отвалился grouping, так как эта библиотека на тот момент не умела работать с вложенными строками. Всей командой мы стали думать, что делать дальше. Решили сделать плоский список, чтобы всё-таки применить useVT. Визуально это плоский список, в который мы по необходимости подставляем нужные строчки по клику. Из хука эта логика переезжает в Store и он начинает отвечать за группировку.
Естественно, с этим подходом у нас отваливается Select, потому что группировочные строки внутри, теперь не могут использовать методы из Ant. Теперь за Select тоже кто-то должен отвечать. Мы перетаскиваем в Mobx Store логику для выбора как вложенных, так и сгруппированных строк, а старый хук useSelection теперь отвечает только за рендер самих чек-боксов.
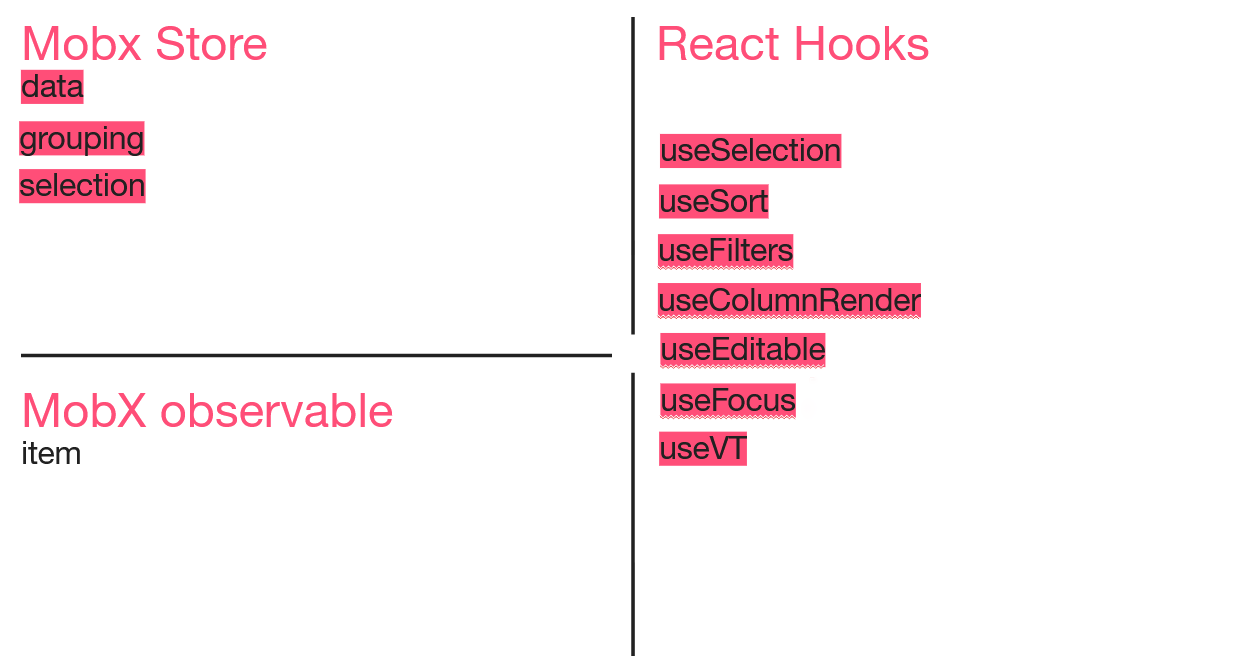
Разбираясь с useFocus, я решила сделать так, что за фокусировку объекта в данный момент отвечает сам объект. По сути, это перенесение логики представления внутрь модели, которое избавило нас от поисков в DOM. MobX observable слушает, в фокусе объект или нет, и сразу перерендеривает одну-единственную ячейку.
Проблемы, вызванные использованием виртуализации, удалось побороть и это помогло нам не падать на больших объёмах данных. Теперь пришло время допиливать остальной запрошенный функционал.
В случае с подсветкой и валидацией пришлось пострадать. Нам нужно было слушать изменения свойств объекта строки, и при некоторых изменениях перекрашивать всю строку. Причина нашей боли в том, что рендер строки таблицы (Row) зашит в таблице. Чтобы подсветка применялась сразу после изменения внутри строки, надо было завернуть компонент в observer. В Ant можно переписать стандартный рендер строки — это мы вынесли useRow хук. А для того чтобы в свойства рендера попал сам observable-объект, я воспользовалась вот таким финтом:

Таким образом, айтемы стали заниматься и своей подсветкой. У них появились observable-свойства, в зависимости от которых мы стали эту подсветку применять. Одновременно с этим пришлось завести отдельный observable-объект для группировочных строк: их-то тоже надо было подсвечивать, но уже в зависимости от того, подсвечены ли вложенные строки.
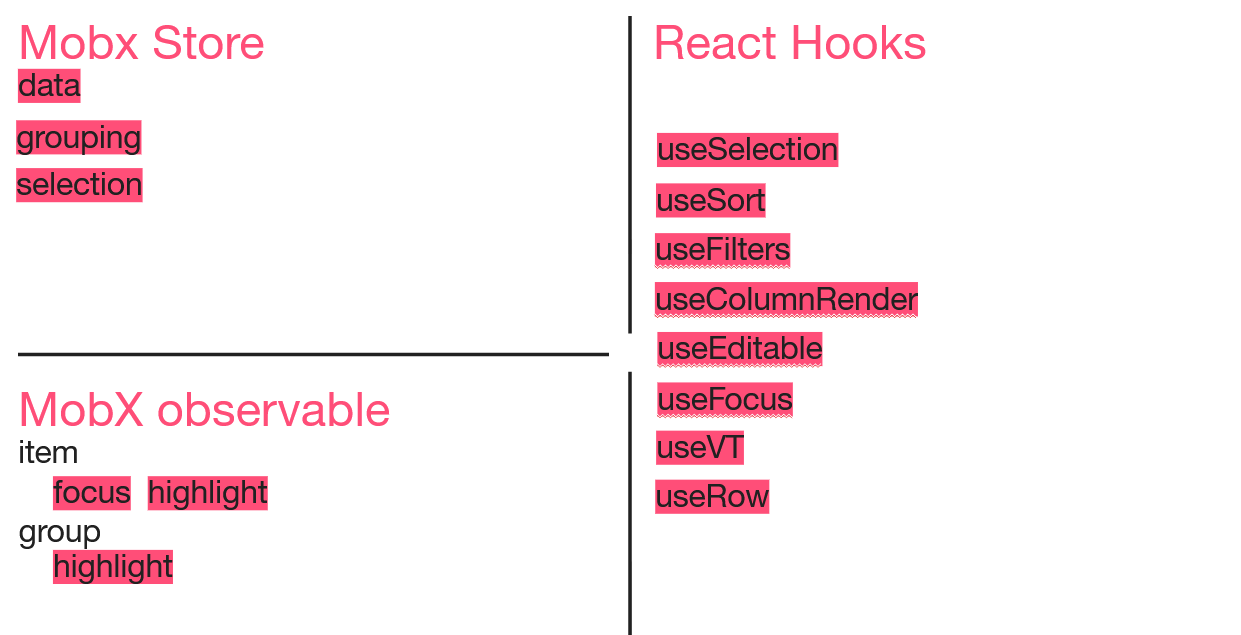
И, наконец, подсчёт тоталов. Что это и для чего? Для каждого заказа нам надо было считать итог не только для всех товаров, но и для каждой группировочной строки в отдельности. Например, на лету подхватывать и пересчитывать, сколько каждого товара и на какую сумму поедет на один даркстор.
Для группировочных строк мы как раз и стали использовать observable объекты, раз уж они у нас уже появились. Тоталы посчитать оказалось несложно.
После всего этого мы держали 40 тысяч строк. Может быть, это спорное решение и можно было это делать на бэке. Но буквально за неделю это решение заработало, и мы выкатились в прод. Неужто на этом все? Конечно, нет.
Третья реинкарнация таблиц
Когда у нас вроде бы всё заработало — поменялись требования. Для Самоката это довольно типичная история. Продукт динамично растёт и приходится переобуваться в прыжке. Поменялось то, что у нас появился новый тип заказов, который использовал практически идентичную таблицу.
Когда я увидела макеты и требования, то думала, что играю в игру «найди 10 отличий».
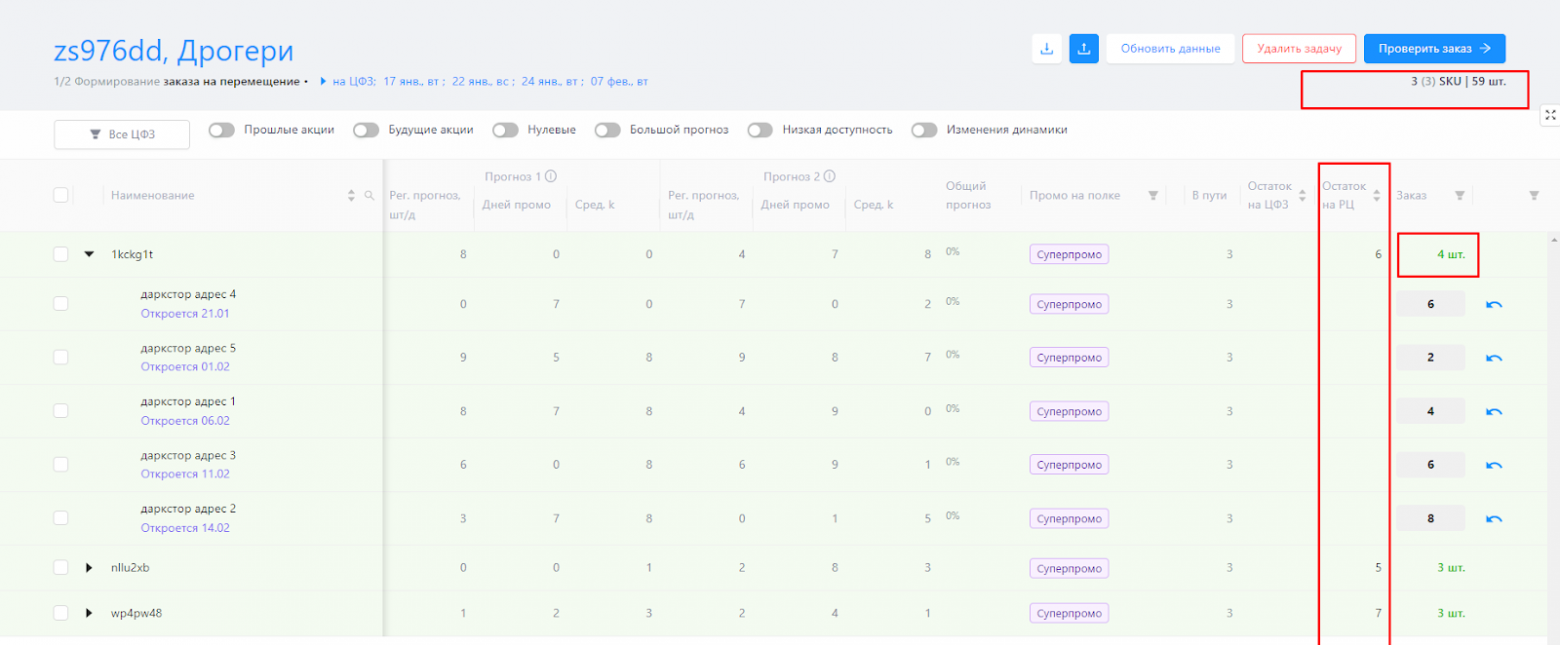
Визуально различия минимальные, все колонки совпадают, за исключением двух последних. Но как потом оказалось, мы должны были работать с совершенно другими сущностями. У них свои правила пересчётов, округлений, валидации, подсветки и т.п.
Недолго думая, я решила, а почему нам не переиспользовать имеющееся, и отнаследовала MobX Store со всеми объектами строк и группировочных строк. Завела абстрактные базовые классы и уже написанный функционал почти полностью переехал в них. На каждый тип заказа — отнаследованный store, item и group.
И тут начались проблемы. Свистопляска с типизацией, с props overrides, размножение этих сущностей. Все определения колонок и хуков были завязаны на старые сущности, теперь же надо было как-то их обобщать — появились немыслимые type unions. Не у каждого типа заказов должно быть то или иное свойство — всё равно приходилось определять в базовом классе, чтобы переиспользовать компоненты.
Чуть позже мы придумали заводить интерфейсы для компонентов, а сами классы для store и сущностей строк стали имплементировать эти интерфейсы — местами избавились от юнионов, но получился полнейший зоопарк как из подходов, так и из налепленных интерфейсов.
Если бы я сейчас оказалась на том этапе разработки, я бы себе посоветовала не наследоваться.
Но несмотря на проблемы, связанные с наследованием, мы сделали на этом этапе самую значимую вещь с точки зрения внутреннего устройства наших таблиц. Мы вытащили практически всю логику из хуков, которая была завязана именно на данные и на их получение и трансформацию (фильтрацию/сортировку/группировку). Таким образом, антовские таблицы у нас вообще перестали использовать тот функционал, который Ant предоставлял, и фактически использовали этот компонент только для разметки, как презентационный. Те хуки, которые остались, тоже теперь отвечают только за рендер, а при событиях, вызванных действиями пользователя, вызывают методы либо store, либо соответствующего observable-объекта строки.
С командой мы потом договорились, что попробуем этот подход, но только не к антовским таблицам. Сделали обычные карточки, затем причесали их так, чтобы они были похожи на строки таблицы и использовали тот же самый Store.
Четвёртая реинкарнация таблиц
В какой-то момент с бэка стало приходить слишком много данных. Причём не количество строк, а именно сами объекты стали приходить очень жирными. Понадобилось добавлять очень много всевозможных дополнительных данных из смежных сервисов: прогнозы, промо акции, статистику продаж за несколько периодов и так далее. И всё это в одной таблице. Снова стали всей командой думать, что можно оптимизировать.
Решили, что всё-таки мы переиначиваем логику. Договорились, что на бэке ребята всё же заводят инфраструктуру под группировочные строки, ведь их надо было где-то хранить, где-то для них что-то пересчитывать. Теперь мы на фронтенде стали ждать сгруппированные данные и подгружать вложенные при разворачивании группировок.
В процессе мы также обнаружили, что MobX объекты создаются в несколько сотен раз медленнее, чем обычные. Т.е. при загрузке страницы с несколькими тысячами объектов, MobX не только увеличивает размеры объектов (что ожидаемо), но и само их создание заметно тормозит загрузку страницы. Для проверки этого мы обвешались метриками (кому интересно, вот ссылка на проект со сравнением, какой объект дольше создаётся и сколько съедает памяти).
Результаты впечатляют: получается, что классовый объект создаётся примерно в 1.5 раза медленнее обычного, а количество созданных MobX объектов с observable свойствами за секунду — вообще ничтожно мало.
Чтобы разобраться с этим, мы стали делать простые JS объекты с группировочными строками, которые пришли с бэка, а затем создавать observable объекты по требованию. Так, мы мы избегаем тормозов при загрузке страницы, и создаём observable объекты только тогда, когда они действительно нужны (например, при редактировании и других пользовательских действиях, когда нужно триггериться на изменения внутри объекта).
Но теперь все эти модификации было сделать очень просто, потому что они уже были в MobX Store. Нужно было просто подменить два-три метода, чтобы это всё заработало. В итоге мы реально держали 2 гигабайта данных на фронте (для 120 тысяч позиций).
Дальше мы оставили эту задачу в покое, отправив аналитиков и продактов, решать проблему уже на уровне бизнеса, потому что 10 тысяч, 40 тысяч строк к заказу — это уже перебор и для поставщиков, и для логистики. Решили думать, как разделять сущности этих заказов, чтобы там было не 40 тысяч, а поменьше. Появились новые типы заказов, которые также наследовались от нашего первого абстрактного класса. Ребята остались пилить Order Manager дальше, а я пошла делать новый продукт Promo Offering.
Работа над ошибками в новом продукте
Я заложилась в архитектуру ещё до того, как мы стартовали, чтобы мы договорились заранее, как избежать проблем.
Сразу договорились, что фильтрация, сортировка, паджинация будут на бэке, и мы отказываемся от группировочных строк, потому что вне зависимости от того, на чьей стороне (на фронтенде или на бэке) будет реализована группировка, она вызовет сложности. По performance мы сразу решили, что используем виртуализацию.
Про QA & Support мы договорились, что пробрасываем сразу в url фильтры, номера страниц, параметры сортировки. В предыдущем проекте это было не предусмотрено.
Про фронтенд мы решили, что для каждой таблицы, в которой есть заметная, внушительная логика, заводим отдельный store, который разруливает эту логику, чтоб не усложнять сам компонент и родительский store. Так, мы завели отдельный store для selection и edit, и их можно отдельно подключать к каждой отдельной таблице. Не используем хуки там, где не надо и избегаем наследования. Пишем acceptance тесты, чтобы не положить прод, если вдруг что.
Фронтенд для больших таблиц: запомнить
Если вдруг пойдёте пилить фронтенд для больших таблиц, помните: сложные интерфейсы сильно удорожают скорость и стоимость. Если продакты и бизнес-аналитики будут непреклонны в этом вопросе — ок, мы можем реализовать их желания, но расхлёбывать потом придётся им. Just a friendly reminder.
Надо учитывать объём данных. Мы сначала не учли, что там может быть 90 и 120 тысяч строк, и получили за это сполна. Теперь учитываем.
Не всегда стандартные, коробочные решения хороши.
И важное — не всегда надо приплетать таблицы! Если можете обойтись чем-нибудь другим и получить такой же результат, рассмотрите повнимательнее такой вариант.
Но если таблицы всё-таки случатся, надеюсь, мой рассказ о граблях сколько-нибудь вам пригодится. Спасибо, что прочитали и пишите о вашем опыте в комментариях!
