Node.js: Клонирование ключей. Is eval() evil?
На примере простой задачи клонирования ключей объекта посмотрим, есть ли реальные альтернативы по производительности столь презираемой JavaScript-разработчиками функции eval().

Подобная задача возникает, если оригинальное значение ключа надо оставить у объекта, а как-то обработанное — положить рядом в новый соответствующий ключ. То есть, для начала, из {"a" : 1, "b" : 2} надо получить {"a" : 1, "a-copy" : 1, "b" : 2, "b-copy" : 2}.
Пару лет назад я уже рассказывал, почему максимальная производительность подобных операций на JavaScript важна для нашего сервиса потокового анализа логов PostgreSQL, как можно поускорять парсинг с помощью WebAssembly, и вот сегодня — продолжение.
Сначала договоримся, что объекты у нас не совсем произвольные, а имеют вполне конкретные интересные нам ключи 'a'..'h' и 'mask' — битовую маску, сигнализирующую их присутствие в объекте. То есть имеют вид вроде:
{
"mask" : 13 // a:1 + c:4 + d:8
, "a" : 123
, "c" : 321
, "d" : 222
}#0: фиксируем тестовый набор
Чтобы все наши тесты проходили на едином наборе объектов, сгенерируем его и сохраним в файл:
const fs = require('node:fs');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', ... , 'h']
const size = 1 << 16; // количество объектов в тесте - 64K
const objs = Array(size).fill().map(_ => {
const mask = Math.random() * (1 << keys.length) | 0; // формируем и сохраняем маску ключей объекта
const obj = {mask};
for (let i = 0; i < keys.length; i++) {
if (mask & (1 << i)) {
obj[keys[i]] = Math.random() * (1 << 16) | 0; // заполняем ключи согласно маске
}
}
return obj;
});
// сохраняем массив в файл
fs.writeFileSync('./objs-64k.json', JSON.stringify(objs));#1: «как слышится, так и пишется»
Чтобы оттолкнуться хоть от какого-то значения производительности, напишем самый «примитивный» вариант кода, который просто перебирает все ключи объекта и создает новые для интересующих нас:
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const ts = hrtime();
for (const obj of objs) {
for (const [key, val] of Object.entries(obj)) {
if (keys.includes(key)) {
obj[`${key}-copy`] = val;
}
}
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 131msЭтот код для наших 64K объектов показывает время порядка 131ms.
#2: замена по матрице
В коде выше, как минимум, две нехорошие с точки зрения производительности вещи:
includesпроверяет наличие ключа в массиве за линейное время, в худшем случае, полностью перебирая весь массив`${key}-copy`создает новую строку каждый раз
Исправим это, заменив includes на in-проверку наличия ключа в объекте, а формирование строки — ее извлечением из этого же объекта:
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const repl = Object.fromEntries(keys.map(key => [key, `${key}-copy`])); // copy-ключи
const ts = hrtime();
for (const obj of objs) {
for (const [key, val] of Object.entries(obj)) {
if (key in repl) {
obj[repl[key]] = val;
}
}
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 104msТакой код уже выполняется на 20% быстрее! Но мы все равно тут обращаемся в repl-объект дважды. Исправим и это:
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const repl = Object.fromEntries(keys.map(key => [key, `${key}-copy`])); // copy-ключи
const ts = hrtime();
for (const obj of objs) {
for (const [key, val] of Object.entries(obj)) {
const copy = repl[key];
if (copy) {
obj[copy] = val;
}
}
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 102msМелочь -, а приятно!
#3: битовая маска
Но во всех предыдущих вариантах мы никак не использовали тот факт, что нам заранее известно, какие ключи есть в объекте, и перебирали и фильтровали их все. А давайте будем перебирать только нужные, примерно как использовали это при генерации?
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const repl = Object.fromEntries(keys.map(key => [key, `${key}-copy`])); // copy-ключи
const ts = hrtime();
const ln = keys.length;
for (const obj of objs) {
const mask = obj['mask'];
for (let i = 0; i < ln; i++) {
if (mask & (1 << i)) {
const key = keys[i];
const copy = repl[key];
obj[copy] = obj[key];
}
}
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 44msПочти в 2.5 раза быстрее!
Но зачем перебирать все биты маски, если мы точно знаем, что оставшиеся старшие — нулевые? Можно и не перебирать:
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const repl = Object.fromEntries(keys.map(key => [key, `${key}-copy`])); // copy-ключи
const ts = hrtime();
for (const obj of objs) {
for (let i = 0, mask = obj['mask']; mask; i++, mask >>= 1) {
if (mask & 1) {
const key = keys[i];
const copy = repl[key];
obj[copy] = obj[key];
}
}
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 42msВыиграли копейку, но она — рубль бережет!
#4: наборы-по-маске
Теперь обратим внимание, что сам перечень ключей каждого объекта мы все равно «перебираем» -, а давайте не будем? Для этого всего-то надо нужный набор ключей и их замен сгенерировать для каждой маски заранее (их всего-то 2 ^ nKeys):
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const copy = keys.map(key => ({key, copy : `${key}-copy`})); // copy-ключи
const maskKeys = Array(1 << keys.length).fill() // наборы ключей каждой маски
.map((_, mask) => {
const res = [];
for (let i = 0; mask; i++, mask >>= 1) {
if (mask & 1) {
res.push(copy[i]);
}
}
return res;
});
const ts = hrtime();
for (const obj of objs) {
for (const {key, copy} of maskKeys[obj['mask']]) {
obj[copy] = obj[key];
}
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 36msОднако, еще на 15% эффективнее!
#5: наконец, eval
Очевидно, что раз уж мы заранее знаем по каждой маске, какие ключи должны быть скопированы, то почему бы не превратить это в готовую функцию?
const objs = require('./objs-64k.json');
const keys = Array(8).fill()
.map((_, i) => String.fromCharCode('a'.charCodeAt() + i)); // ключи ['a', .., 'h']
const hrtime = process.hrtime.bigint;
const copy = keys.map(key => `obj['${key}-copy'] = obj['${key}']`); // copy-сегменты
const maskFunc = Array(1 << keys.length).fill() // copy-функции для каждой маски
.map((_, mask) => {
const res = [];
for (let i = 0; mask; i++, mask >>= 1) {
if (mask & 1) {
res.push(copy[i]);
}
}
return (0, eval)(`obj => {` + res.join(',') + `}`);
});
const ts = hrtime();
for (const obj of objs) {
maskFunc[obj['mask']](obj);
}
console.log(Number(hrtime() - ts)/1e6, 'ms');
// 42msОй… внезапно откатились к предыдущему результату:
-- 64K
for[mask] = 36ms
eval = 42ms +16%Давайте резюмируем, что у нас получилось на выборке 64K объектов — лучшим оказался for-of по предрассчитанному набору ключей для каждой маски:
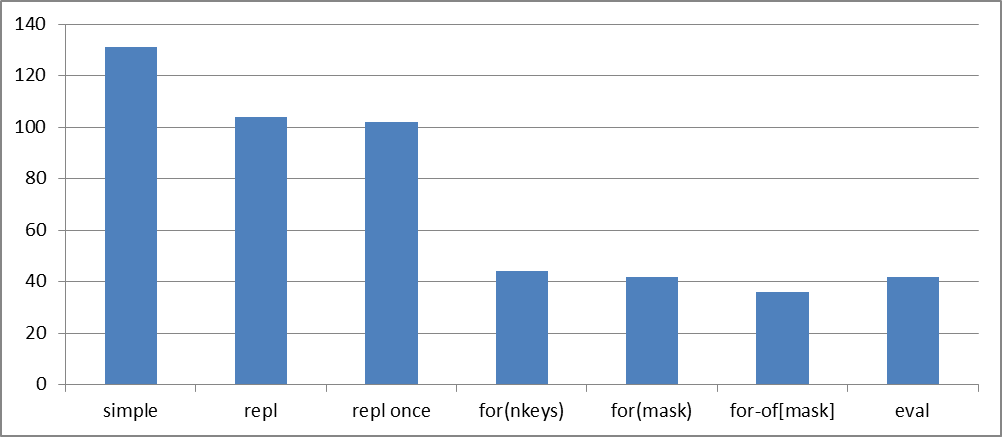 Время клонирования ключей для 64K объектов
Время клонирования ключей для 64K объектов
Но так ли плох eval?
Может, у нас движок V8 не успел «прогреть» каждую из функций? Попробуем тест для миллиона объектов:
-- 1M
for[mask] = 418ms
eval = 434ms +4%Нет, это не случайность, и банальный перебор объектов все равно быстрее. Но уже не на 16%, а всего на 4%! Ну-ка, ну-ка…
-- 4M
for[mask] = 1702ms
eval = 1241ms -27%Промеряем для разного количества объектов:
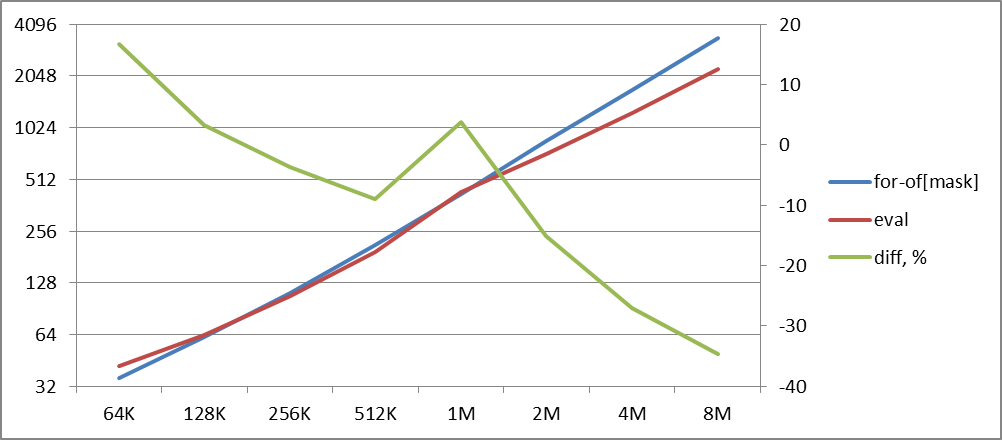 Разница между eval и for-of на разном количестве объектов
Разница между eval и for-of на разном количестве объектов
А eval-то все-таки оказывается существенно быстрее, если их достаточно много!
Очевидно, что данные для 1M на данном графике представляют некоторую аномалию, и вместо +4% должно было получиться -10%, но отложим пока этот вопрос.
И, если следовать графику, то в нашем случае для комбинаций из 8 ключей, начиная примерно с 200K объектов, eval — лучший выбор!
