Делаем ТруЪ-DevOps в мире хранилищ данных

Меня зовут Василий, и уже больше пяти лет я причиняю DevOps в хранилищах. Последние полтора года руковожу группой автоматизации хранилищ данных в Почтатехе.
В нашем data warehouse 6,5 петабайт активных данных. Вы и сами можете представить масштабы, когда речь идет о Почте России: работа сайта и приложения, логистика, трейсинг посылок и даже строительство сортировочных центров основываются на данных нашего хранилища.
Я расскажу, как мы применяем DevOps-практики на таких объемах DWH и как внедрить подобное у себя.
Эта статья написана на основе доклада, с которым я выступал на конференции SmartData 29 октября 2022.
Как работает DWH в Почтатехе
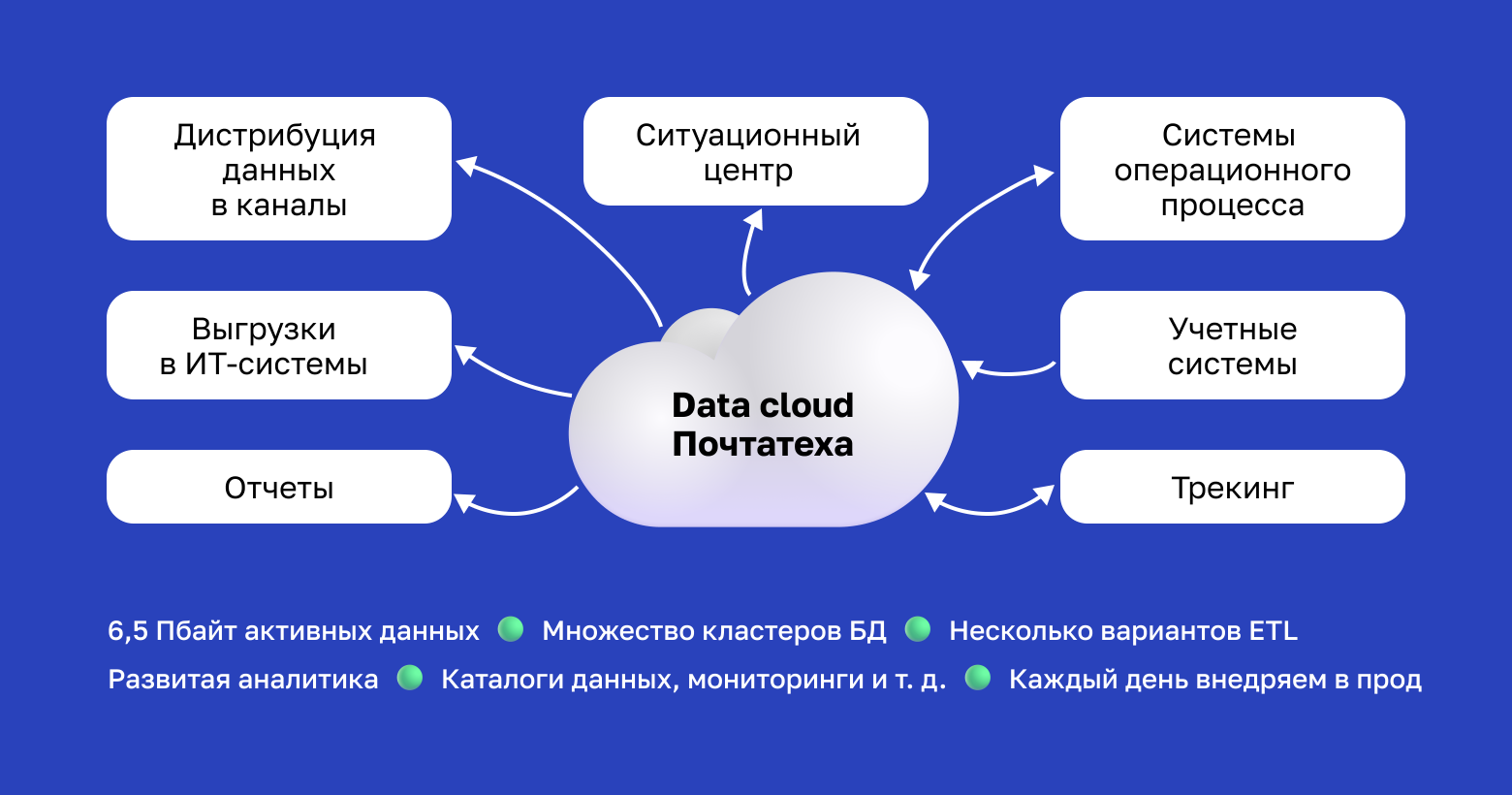
Масштабы Data Cloud
Мы используем три вида СУБД под разные нужды, несколько ETL-движков и обвязку в виде логических моделей данных, средств маскирования, мониторинга и всего остального.
На сам Data Cloud работают больше 100 человек: кто-то занимается аналитикой, кто-то пилит ETL, также есть data science-подразделение и администрирование самой платформы. Бизнес-функциональностью занимается несколько внутренних команд и подрядных организаций.
Каждые день-два внедряется новая функциональность, что-то тестируется, рядом пилотируются новые решения, продукты и подходы.
Роли и процесс разработки
Все хранилища уникальны, но у них есть общие черты: везде присутствуют аналитики, разработчики, функциональный и системный саппорт. Наше хранилище — не исключение.
Наверняка вы знаете специфику работы этих ребят лучше меня.
Аналитики обрабатывают входные требования, пишут постановки для разработчиков, взаимодействуют с бизнесом, определяют сроки поставок новой функциональности и отвечают за них перед заказчиком.
Разработчики работают с функциональными требованиями, пишут код ETL, опираясь на архитектуру хранилища, формируют структуры баз данных и разбирают проблемы на проде, если что-то сильно взорвалось.
Тестировщики тестируют все подряд.
Функциональный саппорт — это специальные ребята, которые выкатывают код разработчиков и занимаются функциональным сопровождением отгруженного кода.
Системщики (платформщики, SRE) обеспечивают функционирование платформы. Ведь в любом случае DWH — это платформа со своим набором СУБД, BI-средств, ETL-движков и кучей всего под разные слои или нужды.
Стандартный процесс разработки выглядит так.
Аналитик получил или сформировал бизнес-требования (BRD) совместно с бизнесом. Он же написал ТЗ и счастливо передал его в разработку.
После этого подключается разработчик и осознает постановку. Здесь начинается разработка кода и его отладка на dev-окружениях.
Дальше формируется поставка и выкатывается куда-нибудь на препрод-окружение, где код передается тестировщику. Тот его тестирует, возможно, возвращает на доработку. В итоге сразу или через несколько итераций он передает эстафету дальше.
Следом саппорт запрашивает или формирует admin-гайды, разворачивает на проде, включает в свой SLA и оказывает дальнейшее сопровождение функционала.
Инструменты команды разработки
Итак, роли обозначены, теперь поговорим про инструментарий.
В процессе, где задействовано множество людей, должен существовать таск-трекер. Допустим, Jira с каким-нибудь линейным процессом от аналитики до выката.
Также обычно присутствует база знаний вроде Confluence или другого wiki-движка. В ней мы храним архитектурные документы, мануалы, постановки для разработчиков и т. п.
Поскольку мы говорим про DWH, то есть одна или несколько СУБД и хотя бы один ETL-движок. Для определенности пусть это будет Airflow.
Но самая важная технология, с которой работают абсолютно все, — SQL.
SQL — самое большое преимущество работников хранилищ и одновременно главный недостаток. Я хочу уделить этому инструменту особое внимание. О недостатках поговорим позже, а вот о преимуществах — прямо сейчас.
Первое — это универсальный язык коммуникации между всеми участниками процесса. Посудите сами: аналитик при анализе источников данных использует SQL, при написании постановки на разработку он может указать запрос в качестве проверочного.
При грамотной постановке разработчику достаточно оптимизировать запрос и обернуть его в ETL.
Функциональное сопровождение при внедрении может воспользоваться тем же запросом для проверки результатов загрузки.
Во многих ситуациях бизнес-заказчик также может дать конкретный запрос на вход аналитику, и это еще больше упростит коммуникацию.
Обязательно нужно сказать про порог вхождения в SQL. По сравнению с классическими языками программирования он минимален. Бонусы тут очевидны — от быстрого обучения новых сотрудников до горизонтальной миграции специалистов между подразделениями.
Для начала нам этой информации хватит. Я еще не сказал про дата-сайентистов, которые крутят свои космические модели на данных наших хранилищ. Мы про них тоже немного поговорим, но позже.
Что вне хранилища
Теперь мы заглянем в мир «за окном» — в область классических приложений, микросервисов и всего того, о чем модно писать на Хабре.
Наша стандартная команда разработки выглядит немного иначе: отсутствует подразделение функционального саппорта или релиз-инженеры. В более развитых командах их место занимают тестировщики.
Процесс разработки максимально автоматизирован: форматы постановок задач согласованы, большая часть кода и различных тестов к нему генерируется прямо на основе постановок, релизы выкатываются автоматически.
Разработка нового функционала осуществляется параллельно, выполняются не только функциональные тесты, но и проверки на качество кода через различные линтеры и т. п.
При деплоях никто не думает о том, на какой сервер, сервис или кластер нужно развернуть приложение или доработку. Выкат осуществляется либо по кнопке, либо по каким-то триггерам или событиям в бизнес-процессе. Откаты на стабильные версии — одно удовольствие: есть выбор из множества стратегий.
Все участники получают уведомления: кто-то на почту, кто-то в мессенджер. При этом уведомления только нужные и соответствующие роли сотрудника.
Например, менеджеру проектной команды совершенно не нужны логи. Если свалился деплой, он нуждается в самом объявлении и, возможно, информации о том, чей конкретно код не взлетел. Разработчику же или девопсу логи нужны — они их и получают.
Естественно, коммуникация тут просто прекрасна. Задачки переезжают из статуса в статус сами, мониторинг присылает уведомления кому надо и когда надо, красивые дашборды радуют глаз всех причастных.
Ну и наш бог — великий и ужасный time-to-market — время от постановки задачи до выката в продуктовую среду. Весь процесс измерим, точки отказа понятны и проработаны. В общем, сказка.
Как сделать DevOps в DWH
Если в вашем хранилище все так же, как я только что описал, — поздравляю, вы большие молодцы. Если же нет, но вы хотите разобраться в этом, давайте поймем, почему так произошло.
Помните: SQL без состояний бесполезен
Исторически сложилось так, что ИТ и BI с какого-то момента развивались если не параллельно, то редко пересекаясь. Конечно, за последние пять лет ситуация заметно выровнялась, но тот инструментарий, который появлялся последнее десятилетие в ИТ, трудно адаптировать под нужды DWH.
Здесь как раз нужно проговорить недостающие слова про SQL. Он, безусловно, прекрасен, но есть один большой недостаток: у него нет состояний. Когда мы говорим про базы данных, мы подразумеваем миграции, то есть некую секвенцию из запросов и ETL-потоков, которые привели нашу, допустим, таблицу к текущему состоянию на проде.
В какой-нибудь Java мы можем скомпилировать программу на любом ее жизненном отрезке и выпускать старые, новые или промежуточные версии нашей программы. В мире SQL мы себе такого позволить не можем и вынуждены придумывать велосипед.
Если мы захотим откатить таблицу, то не сможем просто взять ее первоначальный DDL и накатить. Нам нужно будет выполнить еще один alter, который удалит только что добавленную колонку. И само собой, нам нужно будет вместе с этой миграцией откатить все, что было с ней связано: ETL, модели, вьюхи, процедуры и прочее.

Когда мы анализировали, что мешает просто применять практики DevOps как есть, мы пришли к святому граалю — нужно «засостоянить» SQL. И все, о чем я расскажу дальше, является следствием полученного опыта и сделанных ошибок.
Надо каким-то образом реализовать эти состояния для SQL либо избавиться от него. Потому что единственное, что мешает относиться к хранилищу как совокупности приложений, — неидемпотентность SQL, а вот с приложениями мы работать умеем.
Договаривайтесь об ограничениях — это основа коммуникации
Давайте вернемся в 2009 год. Тогда Джон Оллспоу и Пол Хэммонд на инженерной конференции представили свой революционный доклад «Более 10 деплоев в день, кооперация разработчиков и сопровождения в компании Flickr» — очень рекомендую к просмотру.
Технически ребята рассказали, как они договорились передавать код разработки в определенном формате. Тогда как со стороны инфраструктуры была соответствующая дырка, из которой осуществлялась автоматизированная раскатка кода.
Само собой, это вызвало революцию, которую и окрестили словом DevOps.

На самом деле, за кадром остался бриллиант. Эти два человека стандартизировали входные и выходные форматы, построив жестко структурированный интерфейс между двумя подразделениями. И только ПОСЛЕ того, как договорились о стеке, выработали правила именования, состав поставки и прочее, они автоматизировали выкат.
В этом и есть ценность: DevOps — это про коммуникацию. Она может быть автоматической, автоматизированной или организационной, это не важно. Важно, чтобы процесс был прозрачен и люди знали, как на этой стадии коммуницировать со всеми остальными участниками.
Я не говорю о том, что надо знать, к кому прийти или как перетаскивать задачи в Jira, нет! Правильная коммуникация — это не написать постановку в формате, удобном конкретному человеку, а наоборот, сделать ее по шаблону. Даже если нет кодогенерации, разработчику будет привычнее работать с чем-то стандартным на входе, а не каждый раз адаптироваться под конкретного аналитика. Это и есть тот самый интерфейс, который построили парни из Flickr.
Стройте интерфейс взаимодействия
С идеологией разобрались. Но я знаю, что интереснее поговорить про автоматизацию. Ее назвали простым словом «пайплайн» или конвейер. Его цель — поддерживать неразрывную цепочку между технологическими стадиями процесса.
Под конвейером мы понимаем всю цепочку процесса — от постановки задачи аналитиком до ее выката в продакшен.
Отличной иллюстрацией пайплайна является схема процесса в Jira. Мы видим, где у нас входы и выходы из процесса, а также transition (перемещения) — это и есть точки коммуникации, где девопс с командой должны построить свои интерфейсы.
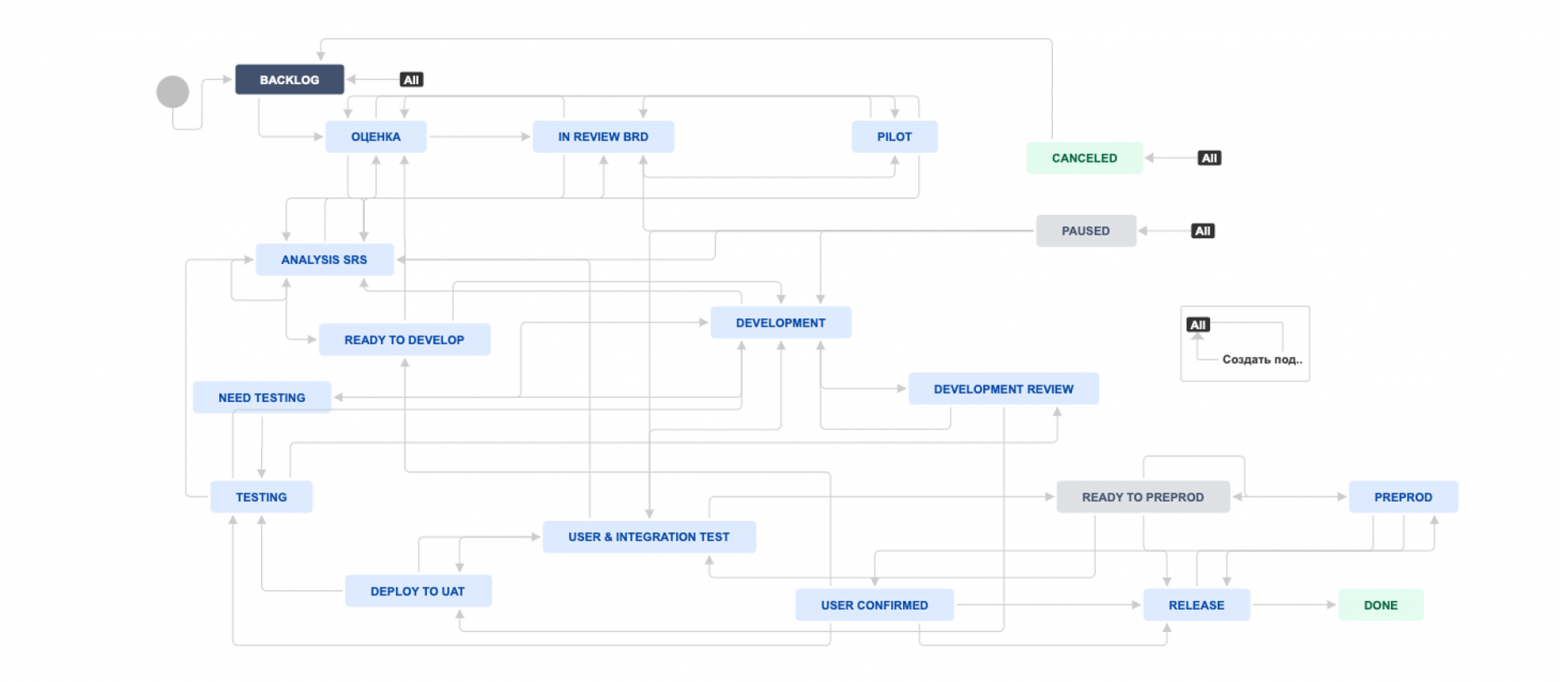
Давайте прямо сейчас накидаем ТЗ на построение интерфейса взаимодействия.
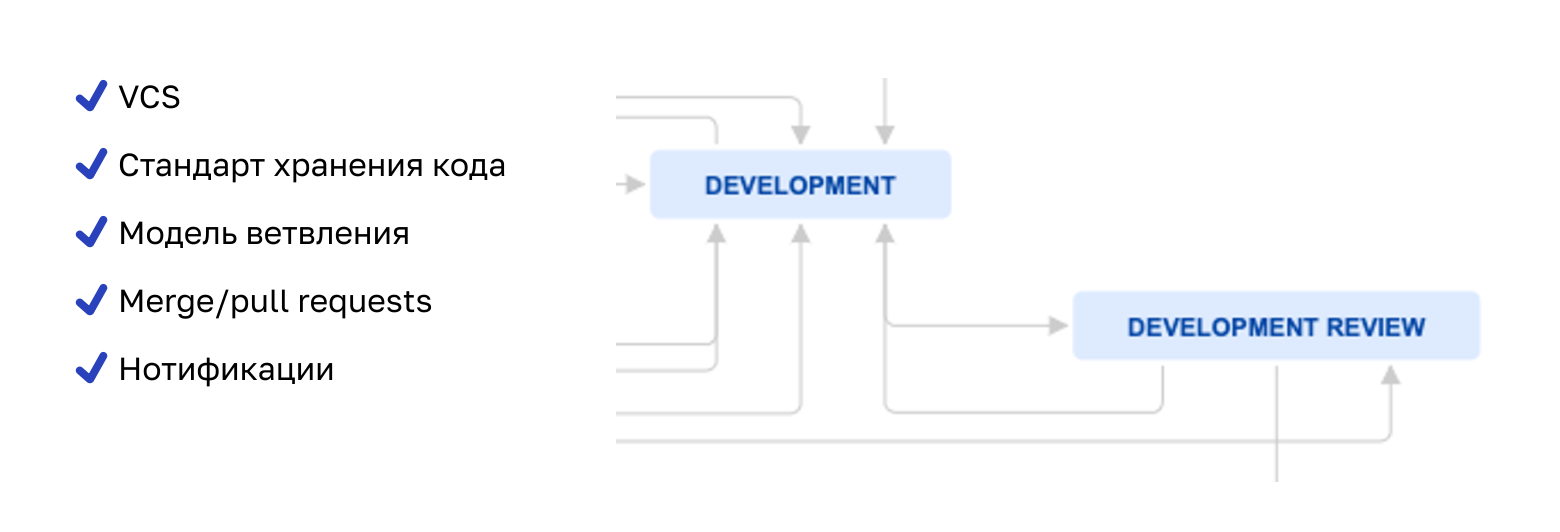
Возьмем точку между разработкой и, например, код-ревью. Если нужно проверять код, значит, он должен где-то храниться. Мы понимаем, что нужна система контроля версий. Хорошо бы, чтобы у нее была возможность оставлять комментарии по коду.
Еще нужно оповещать ревьювера о том, что ему, вообще-то, нужно что-то проверять, — получаем требование к нотификации, например, на почту. Плюс разработчик тоже должен понять, что его код проверен или отклонен с замечаниями.
Из такой простой, казалось бы, задачи мы получаем следующее:
У нас должна появиться система контроля версий.
Чтобы команда не рехнулась, структура хранения кода должна быть стандартизирована.
Нужен стандарт по ветвлению с привязкой к статусам задач в Jira. Мы у себя используем модифицированный gitflow.
Должна появляться сущность merge/pull-request как сигнал от разработчика, что он выполнил свою часть работы и можно ревьюить, а также как место, где ревьювер оставляет свои комментарии.
Мы должны интегрировать систему контроля версий с почтой или мессенджером для передачи нотификаций исполнителям, чтобы процесс не прерывался.
 Пример ТЗ на построение интерфейса взаимодействия
Пример ТЗ на построение интерфейса взаимодействия
Детализировать можно и дальше, но давайте закрепим, для чего все это нужно.
Система контроля версий — это интерфейс взаимодействия разработчика со всеми участниками процесса. Структура кода важна для того, чтобы разработчики не договаривались каждый раз заново. Стандарт по ветвлению — многосторонняя история. Если она завязана на Jira, то вообще сказка: в любой момент все понимают, на какой стадии процесс. Merge/Pull-request — не прихоть: это нотификация для лида или ревьювера. А нотификации избавляют от необходимости каждый раз спрашивать друг друга о том, что происходит с задачей.
Версионируйте SQL
Я прекрасно понимаю, что вы не очень хотите читать про код-ревью, и вам интереснее узнать про то, как укрощать SQL. Но чтобы понять это, важно было увидеть, как задача «одомашнивания» код-ревью выглядит в глазах девопса.
На самом деле, мы не можем дать ответы на все вопросы. Часть из них вам придется искать внутри команды с разработчиками, девопсами, аналитиками и другими коллегами.
Базовый принцип, от которого мы пляшем: git — единственный источник правды. Второй принцип — подход по версионированию файлов SQL.
Про второй принцип и поговорим. Мы «изобрели» объектную структуру. Идем от вершины: сначала тип СУБД, затем схемы, затем типы объектов внутри каждой схемы — таблицы, представления, процедуры и т. д.
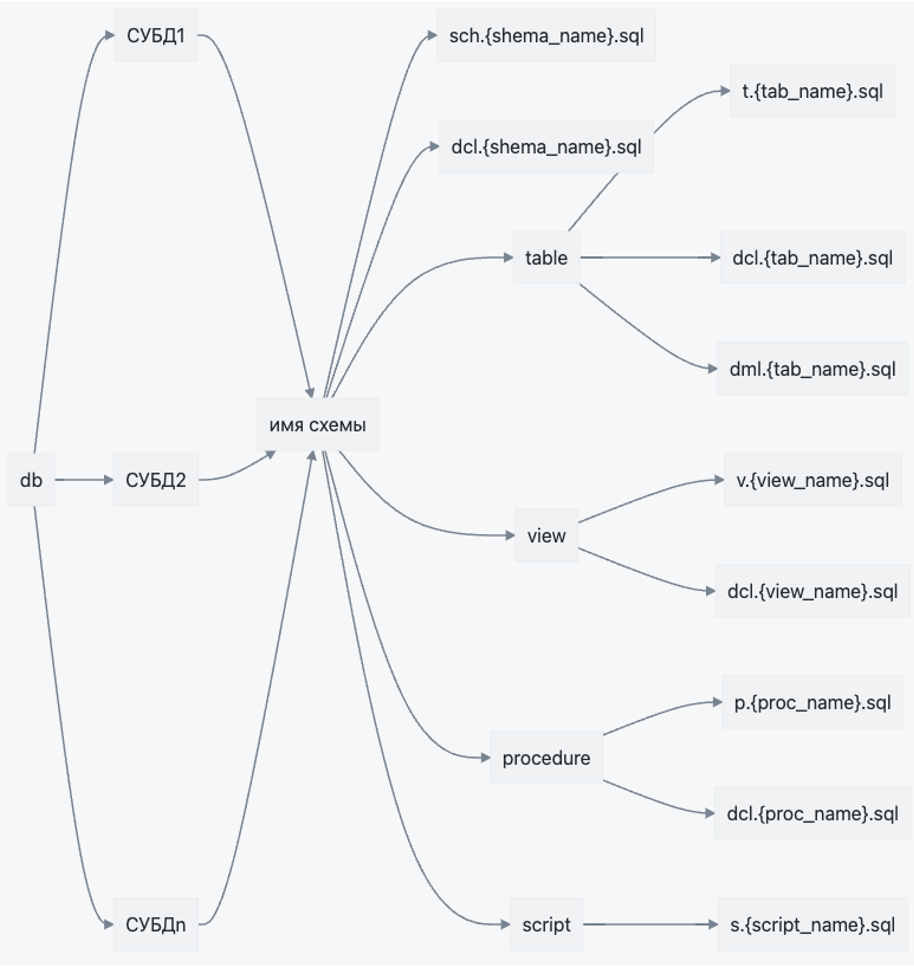 Версионирование SQL
Версионирование SQL
С процедурами и вьюхами мы поступаем следующим образом. Внутри папки view существует SQL-файл с конкретной вью. Все имена объектов — в нижнем регистре. Названия файлов начинаются с префикса, показывающего тип и имя объекта. Внутри же таких скриптов — конструкции вида create or replace. То есть при накате вьюх и процедур мы их просто переписываем.
 Накат вью и процедур
Накат вью и процедур
А вот с таблицами ситуация иная: для таблицы существует ее init-скрипт, то есть DDL, с которым создавалась таблица. Далее таблица меняется только с помощью alter. Каждый новый alter пишется в новом скрипте и имеет номерной индекс. Зачем так?
Во-первых, мы хотим получить стройный таймлайн миграций, чтобы уметь воспроизводить состояние на точку времени. Например, чтобы создать тестовый стенд или перенакатить какую-либо таблицу на точку времени.
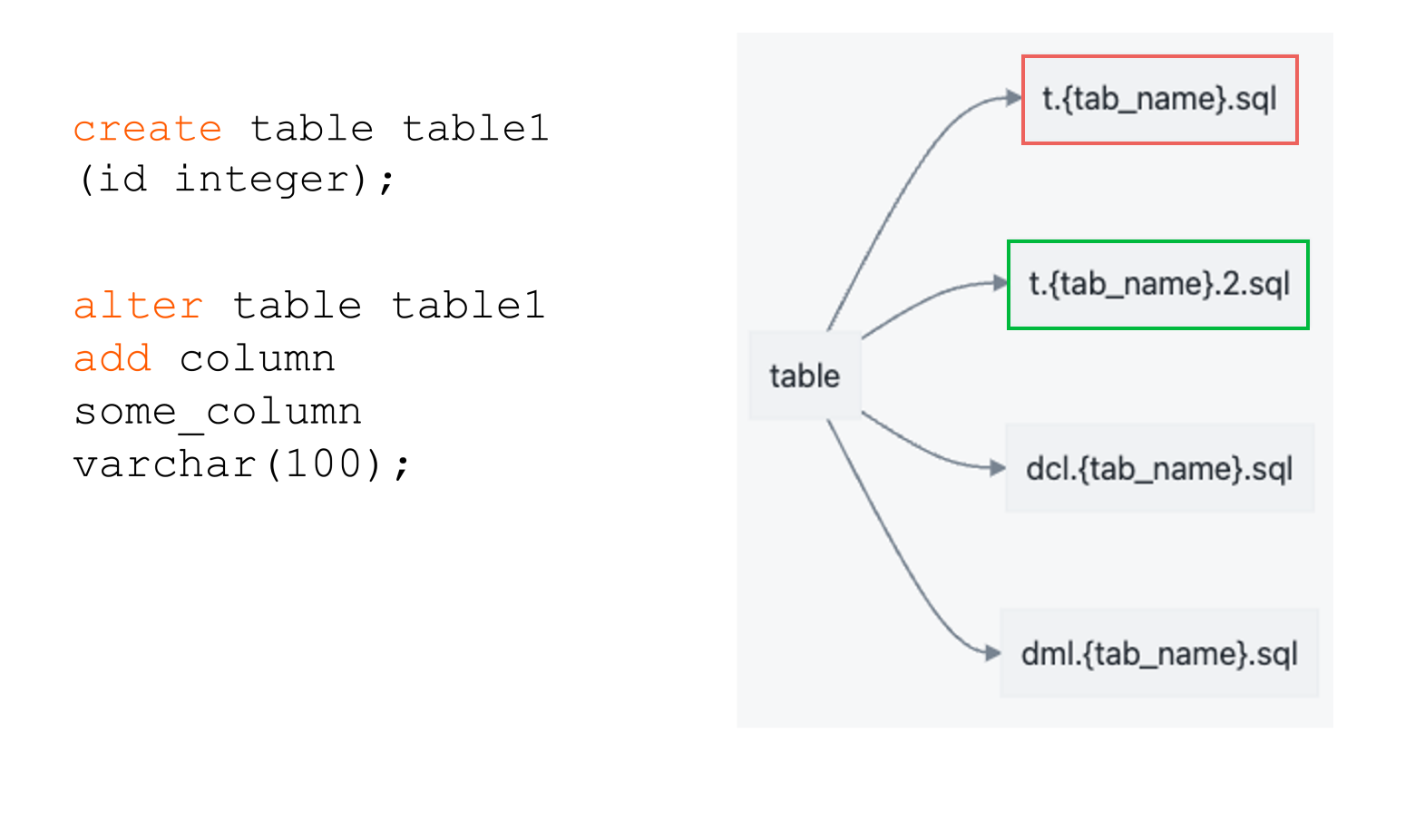 Накат таблиц
Накат таблиц
Также мы хотим получить конфликт между двумя разработчиками, которые меняют одни и те же объекты. Это уже фишка git’а — он не дает слить в master, который отображает состояние прода, разные изменения в одном и том же файле. По сути, первый разработчик проскочит, а вот второй узнает, что таблица изменилась и, возможно, нужно поправить его alter.
Не используйте стандартные сборщики и инсталляторы
Теперь все, что касается сборки кода и его деплоя. У меня тут плохие новости: ни одна из стандартных утилит типа Liquibase для нужд хранилища, по моему опыту, не подходит. Мы делаем кастом.
Сборщики и инсталляторы пишем на Python. Благо, язык очень гибок и популярен среди дата-сайентистов, а значит, под него есть миллион библиотек, драйверов для СУБД, шаблонизаторов, парсеров и т. д.
Поскольку мы живем в парадигме «миграций», этот подход нужно поддержать и при сборке. По сути, мы формируем патчи. Хорошая новость в том, что при нашем стандарте такой подход достаточно просто реализуется тривиальным git diff.
Наш gitflow
Перед вами модифицированный gitflow:
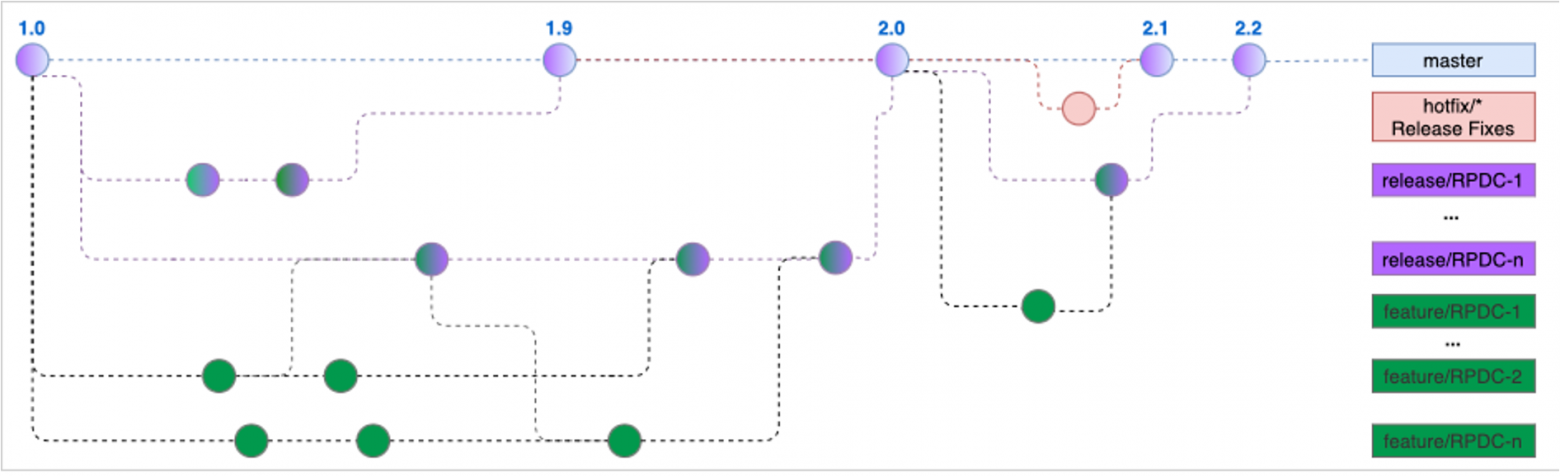
Гит — он как дерево: сверху ветка master. Она отражает состояние кода в продуктивной среде. Точки на всех ветках или коммиты — это слепки кода в момент времени. То есть при установке патча на продуктивную среду на ветке мастера появляется новая точка.
Также у нас есть релизные и фича-ветки. При разработке ветвимся от мастера в фича-ветку, затем нужный набор фич через механизм merge-request или pull-request консолидируем в release-ветке.
Сборка инкремента
И наступает момент сборки. С помощью git diff мы видим разницу между master и нашим релизом и получаем список файлов для упаковки. Ну и кладем все эти файлы в практически исходной структуре в TAR-архив, который потом передается на установку дальше на разные среды.
 Cборка
Cборка
По сборке есть еще один момент. Не всегда нужно забирать только diff. Например, если дело касается изменения файла внутри приложения, разумно его поместить целиком. Мы так делаем с Airflow DAG — если что-то поменялось внутри DAG, собираем и деплоим его целиком со всем содержимым.
Здесь стоит отметить, что любые договоренности подтверждаются исключениями. Например, мы не все SQL-файлы храним в такой структуре. Часть параметров для ETL храним прямо рядом с DAG, точно так же пакуем их и устанавливаем.
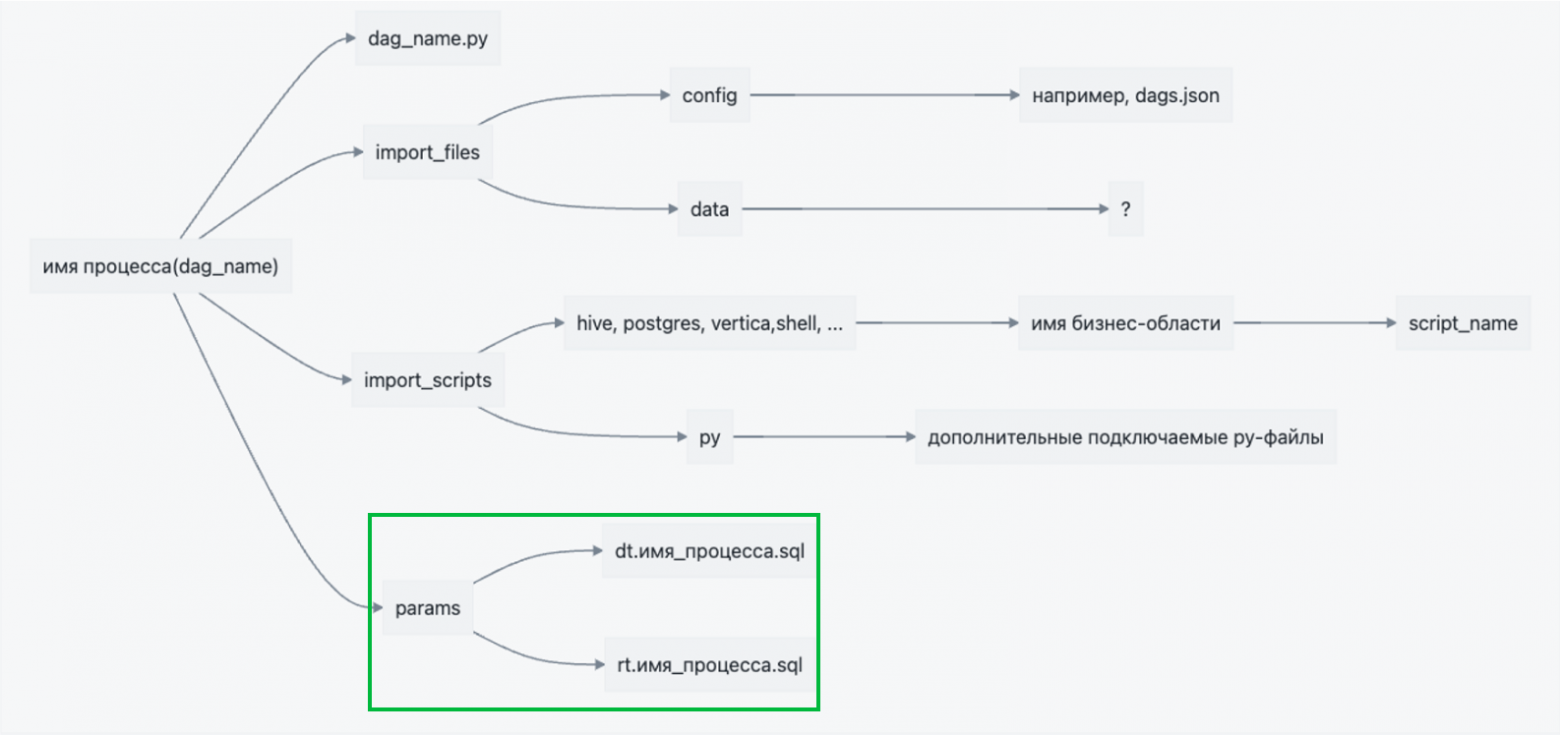 Структура ETL
Структура ETL
Деплой
Release_notes
Теперь поговорим про деплой. Разумеется, он тоже кастомный. У нас он построен по следующим принципам: разработчик при сборке релиза оформляет в git файл release_notes в специальном текстовом формате. В нем определяется порядок установки артефактов, instance, на который происходит деплой, а также указываются значения переменных для деплоя в dev-среду.
 Release_notes
Release_notes
Тут нужно сделать ремарку. Дело в том, что наши скрипты параметризированы. То есть в текстах, например, SQL-запросов в bash-like стилистике заданы плейсхолдеры, в которые при установке подставляются конкретные значения. Такие значения зависят от конкретной среды: это могут быть разные периоды загрузок, названия схем и вообще все, что разработчик захочет параметризовать.
${var_name}="value”Сценарий раскатки патча
Итак, release_notes разработчик описал. Теперь уже мы нашими механизмами конвертируем этот файл в штуку под названием Release Info. Ее ключевая идея — это сценарий раскатки патча на все среды, который находится в нашей базе знаний Confluence.
Release Info дает ответственным людям возможность задать значения переменных на разных средах. Например, аналитикам, которым не хочется идти изучать git. Также мы обогащаем этот Release Info дополнительной информацией: ссылками на гайды, задачами в Jira и т. д.
 Release Info
Release Info
Установка
Ну и финальный этап — специалист сопровождения нажимает на кнопку, соответствующую среде, и происходит установка.
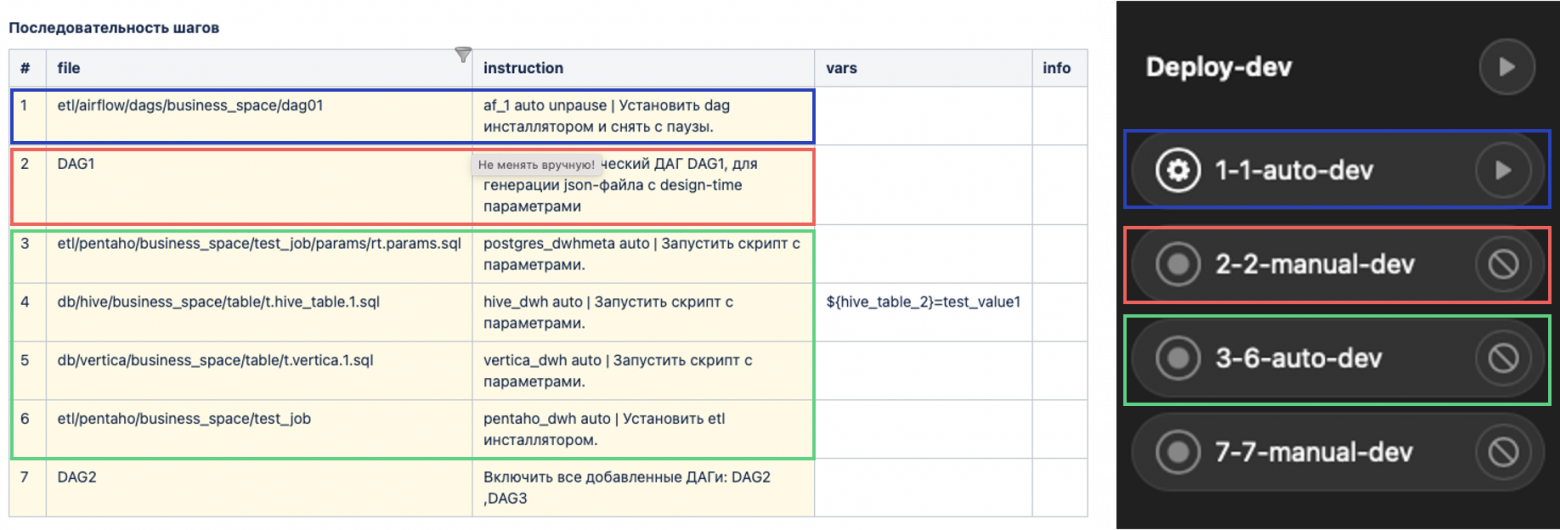
 Пайплайн в GitLab
Пайплайн в GitLab
Внимательный читатель заметит, что кнопочек по раскатке много. Дело в том, что наш деплой пока не автоматический, а автоматизированный. Это значит, что в Release Info могут быть какие-то ручные действия, которые должен выполнить сотрудник сопровождения. Например, запустить какие-то Airflow-потоки от определенной даты после применения соответствующих DDL-ей автоматически.
Мы придумали следующее: парсим Release Info и делим действия по блокам на автоматические и ручные. Далее — располагаем их в правильном порядке, а затем генерируем пайплайн по выкату на основе этих блоков. То есть наш инсталлятор умеет понимать инструкции вида «прогони нам блок автоматических действий номер 3». На данном этапе релизер прожимает кнопку с ручными действиями, сигнализируя пайплайну, что ручной этап завершен. Тогда пайплайн сразу запускает следующий блок автоматических действий. И так до победного.
Немного о data science
Я обещал коснуться дата-сайентистов. И здесь, к сожалению, не будет вау-эффекта. Наши ребята пишут модели на Python. Их код мы пакуем в Docker и кладем в наш внутренний Docker Registry.
Единственное, что мы кладем в патч при выкате их моделей, — HelmChart. Это файл с метаданными для Kubernetes, с помощью которого и происходит раскатка. То есть наш инсталлятор подает через kubectl HelmChart в K8s, для которого это нативный формат. Соответственно, наши модели крутятся в Kubernetes.

Так делайте, а так не делайте
Итак, мы поняли, где и как хранить наш SQL-код. Возможно, кто-то даже запомнил, как работать с параметрами и переменными. Усвоили, что Git diff — наш друг. Узнали, как этот код паковать и как его установить через дополнительные интерфейсы в виде сценариев. Также мы увидели, как может выглядеть интерфейс по автоматизированному выкату. Ну и самое главное: я надеюсь, вы поняли, что такое DevOps. Не перестану это повторять: коммуникация — ключ ко всему.
Для тех, кто пойдет что-то делать руками, расскажу про несколько граблей, по которым мы потоптались.
Автоматически определять последовательность скриптов — плохая идея. На предыдущем проекте мы реализовали эту функциональность, спалив много костов, а сама фича оказалась ненужной и неудобной. На данный момент я думаю, что файл со сценарием установки — вполне рабочий.
Не делайте текстовый файл с придуманной разметкой для release_notes. Возьмите что-то нативное для вашего языка, на котором будете пилить свой фреймворк: пусть это будет YML, TOML, JSON. Да хоть XML, лишь бы он был валидируемый и неплохо читался. В итоге сейчас у нас YML.
Чтобы вы поняли глубину проблемы, наш код по парсингу и дальнейшей обработке файла release_notes весит несколько килобайт. А вот пример парсинга TOML-файла сразу в готовый словарь, если вы выбрали TOML-файл за основу:
>>> with open("pyproject.toml", mode="rb") as fp: ... tomllib.load(fp) ...
{'build-system': {'requires': ['flit_core>=3.2.0,<4'], 'build-backend': 'flit_core.buildapi'}, 'project': {'name': 'tomli', 'version': '2.0.1', 'description': "A lil' TOML parser", 'requires-python': '>=3.7', 'readme': 'README.md', 'keywords': ['toml'], 'urls': {'Homepage': 'https://github.com/hukkin/tomli', 'PyPI': 'https://pypi.org/project/tomli'}}}
Сразу старайтесь писать свой фреймворк в объектно-ориентированном стиле. Аппетит растет во время еды, и достаточно быстро придет тот момент, когда с ворохом скриптов совсем ничего нельзя будет поделать. Тогда придется начать работу с чистого листа.
Gitflow без develop — хорошо. Я бы не рекомендовал использовать модерновые модели типа Trunk-based или Feature-driven формат. Попробуйте обычный gitflow, но без develop-ветки, потому что она мешает параллельной разработке.
Совет для девопсов: не ленитесь делать маленькие улучшайзеры. У всех и так будет болеть голова от обилия информации. Сделав, например, генератор Release info, который будет создавать шаблонизированный файл с прописанными файлами в поставке и переменными, вы сильно упростите всем жизнь.
Ваш фреймворк должен быть покрыт тестами. Хороший показатель для юнит-тестов будет в районе 70% покрытия. Обязательно делайте тесты на реальную функциональность. При доработках вы должны знать, что именно ломается.
Прямая совместимость — must. Мы этот момент когда-то упустили, и это было очень больно для пользовательского опыта. Дело в том, что множество доработок по каким-то причинам откладывается в долгий ящик. И когда приходит время к ним возвращаться, возникает сюрприз — инсталлятор уже не может установить что-то по старой версии release_notes или Release info.
Парсить SQL на запросы — плохо. Синтаксический анализ SQL можно реализовать, только если у вас есть инженер, хорошо знакомый с парсингами естественного языка. Это про всякие ANTLR-штуки и прочее. За это надо браться либо всерьез, либо не браться вовсе. Имейте в виду: код интерпретаторов известных СУБД — наверное, одна из самых больших охраняемых коммерческих тайн. Мы у себя файлы со скриптами передаем в интерпретаторы целиком. Но может быть, потому что плохо смотрели или выбрали не тот язык. Кто знает, возможно, на Java с этим попроще.
Последний совет: отгружайте функциональность порциями. Не нужно сидеть и полгода писать фреймворк — напишете либо не то, либо не так.
И еще раз про коммуникацию и людей
Итак, мы определились с местом DevOps в команде. Ключевой аспект здесь — культура. Помните, что люди из BI жили параллельно с ИТ и многие вещи считают чем-то из области фантастики. Качайте их культуру, рассказывайте, как бывает рядом. Мы делаем это так.
Регулярные публичные встречи. Обязательно соберите сообщество с активными людьми из всех подразделений. Привлекайте их к проработке стандартов, правил и соглашений. Мы у себя проводим регулярные онлайн-статусы, где рассказываем, над чем сейчас работает команда и к чему стремится. На эту встречу может прийти любой, но обязательно нужно звать лидов от каждого линейного отдела или проектной команды. Со временем состав участников вырастет — большинство само просится получить информацию из первых рук.
Открытые бэклог и roadmap. У нас есть публичный бэклог, который в основном формируется на таких встречах. Еще есть интерактивный roadmap. Мы строим его в Structure — это плагин для Jira — что-то вроде Microsoft Project, только сразу с привязкой к реальным таскам (сейчас смотрим в сторону плагина Roadmap). Все изменения, анонсы и информирование мы проводим через блог — это фича в Confluence. Документацию ведем также в Confluence. Все стандарты, инструкции — там же.
Демо для разных ролей. Мы периодически проводим технические демо для всех желающих. Тут совет: если вы внедряете что-то, то проведите несколько демонстраций — одну для разработчиков, другую, например, для аналитиков. Потому что фокус у всех разный, и так вы сможете учесть специфику каждого. А ответы на вопросы будут актуальны для всех участников.
Общая точка для консультаций. В какой-то момент мы стали завсегдатаями чатиков. Поэтому завели бота, который отправлял сообщения в один чат, откуда мы могли сами консультировать команду, не теряя сообщения и не задумываясь, откуда они пришли. Когда мы поняли, что запрос на консультации большой, сделали общий публичный чат. Чтобы завести туда людей, мы некоторое время отказывались давать консультации где-либо кроме него. Это сработало: мы терпеливо отвечали на каждый вопрос в чатике, а потом случилось чудо. Другие участники стали сами отвечать на вопросы. Так и формируется комьюнити.
И самое главное — прозрачность. Заметьте, что вся деятельность группы абсолютно на виду. Понятно, как ставить задачи, куда бежать и как давать обратную связь. В общем, больше прозрачности богу прозрачности!
Ну и в заключение — помогайте девопсам. Мы классные:)
