Увеличь это! Современное увеличение разрешения в 2023

Почти 4 года назад вашим покорным слугой была опубликована статья Увеличь это! Современное увеличение разрешения, которая набрала +376 хабролайков и 176 тысяч просмотров. Но прогресс на месте не стоит! Новые нейросетевые методы жгут! Их результаты прекрасны и великолепны. 1,5 года назад на хабре была неплохая статья Апскейл, который смог (+160), в которой были показаны плюсы новых алгоритмов.
Но всегда ли все прекрасно? Конечно нет!
Мой любимый пример фантастических способностей нейросетевых алгоритмов выше. В шарике отражается наша лаборатория. Бюст Зевса был взят в датасет, чтобы оценить работу нейросетей с полутенями, но результат «обработки полутеней» сильно превзошел ожидания. Во-первых, мудрые голубые глаза и покрасневшие губы! Во-вторых, Зевс теперь причесан! В-третьих, его борода стала короче и тоже аккуратно подстрижена! Наконец, Зевс теперь выглядит ощутимо моложе и… человечнее! О, жители Олимпа, согласитесь, это просто божественно!
Почему нам таки есть что сказать по теме? За последние годы мы создали 3 бенчмарка Video Super-Resolution под разные кейсы использования, которые на данный момент занимают первые 3 (из 14) места в соответствующем разделе на сайте paperswithcode.com. Кроме того, в наши бенчмарки входят коммерческие апскейлеры (что редкость!):
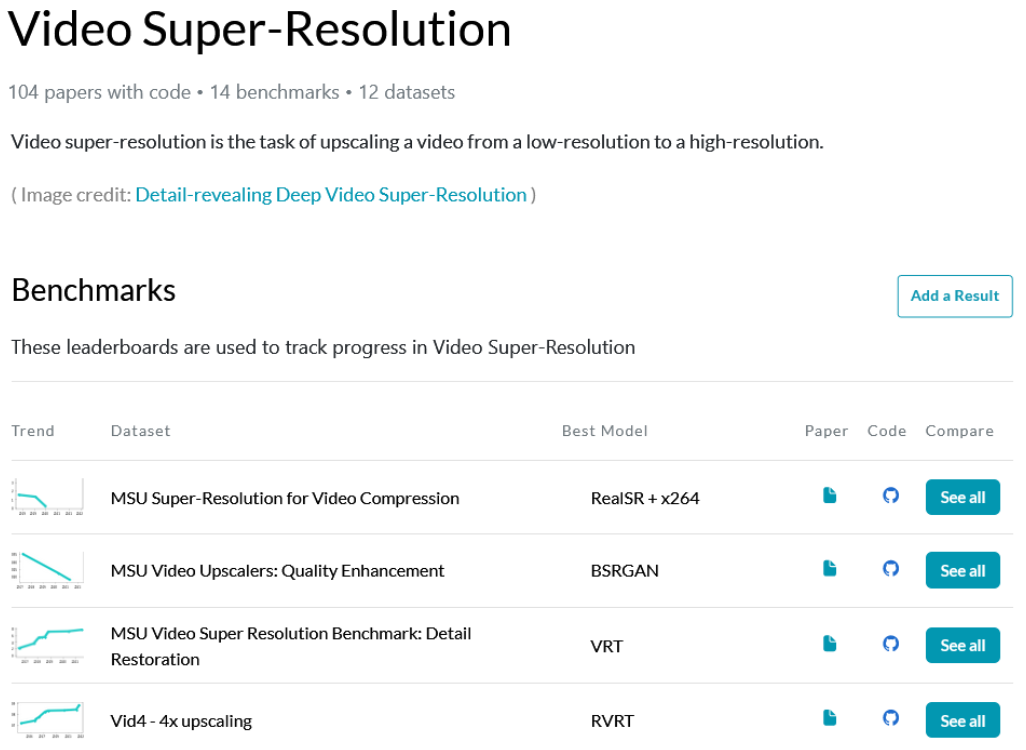
Подобная деятельность безмерно актуальна, поскольку если 4 года назад на GitHub было меньше 200 репозиториев Super-Resolution, то сейчас их там больше 900 и разобраться в этом море исходников стало совсем непросто.
Естественно, при создании бенчмарков у нас было много чудных примеров. Более того, сейчас мы целенаправленно создаем датасет артефактов нейросетевых алгоритмов апскейла.
Кому интересно посмотреть, какие забавные косяки бывают у новых алгоритмов, а также как выглядят наилучшие результаты, которые даже меня, занимающегося темой 14+ лет, удивляют — добро пожаловать под кат (много картинок и букв)!
Поехали!
Краткое содержание предыдущих серий
Если кратко пересказать начало прошлой статьи, то алгоритмы Super-Resolution (SR) делятся на улучшающие результат визуально («сделай мне красиво») и восстанавливающие информацию:
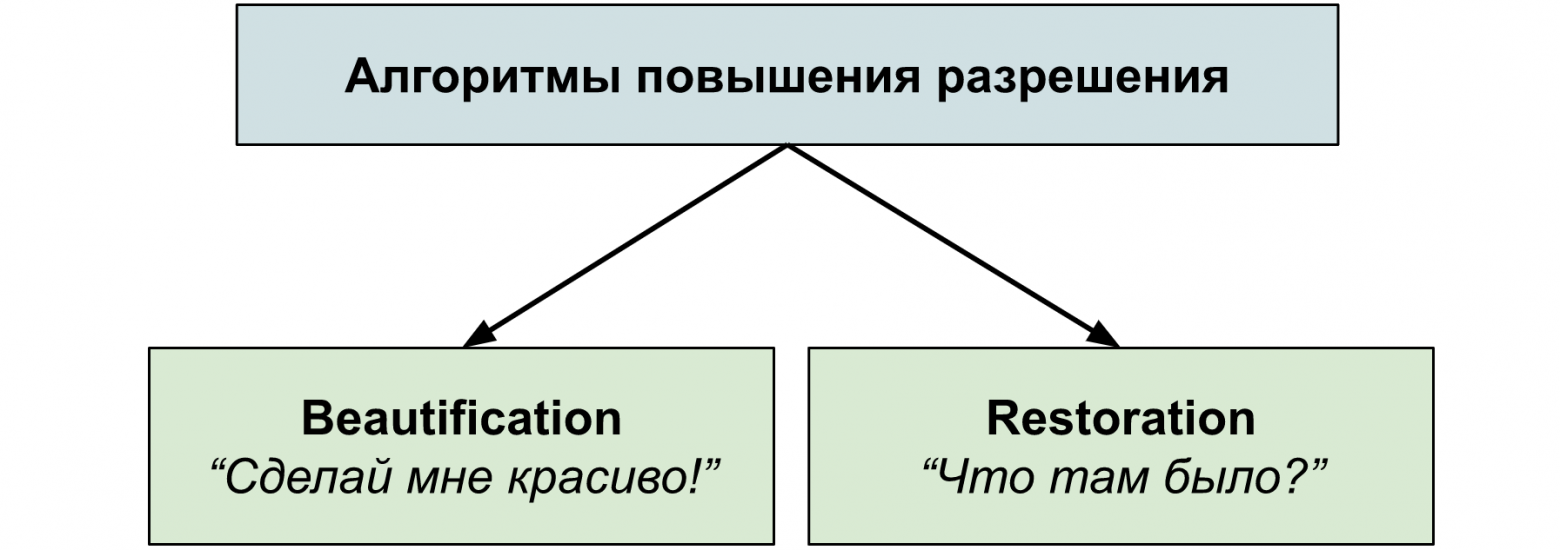
Когда мы работаем с видео, то есть возможность восстановить разрешение, взяв информацию с прошлых или следующих кадров. Но сделать это алгоритмически намного сложнее, поэтому более 90% алгоритмов заняты именно бьютификацией, то есть пытаются не «восстановить», а «догадаться», что было изображено в этом месте (сюда относятся, например, все алгоритмы Image Super-Resolution). Иногда это получается хорошо, иногда нет. Процент успешных случаев каждый год растет. Заметим, что именно прогресс в «угадывании» текстуры в прошлом году помог выстрелить нашумевшим DALL-E 2, Stable Diffusion и Midjourney, поскольку по ресурсам намного эффективнее оказалось генерировать из промпта картинку 512×512 и дальше повышать ее разрешение вариациями на тему SR, чем сразу пытаться генерировать картинку большого разрешения.
Автора, впрочем, интересуют больше восстанавливающие SR, и в первую очередь работающие достаточно быстро (то есть практические). Один из подходов тут — накапливать качественный кадр высокого разрешения, каждый раз используя следующий кадр низкого разрешения для уточнения. Ключевыми при этом являются точная процедура оценки движения (motion estimation) и собственно функция синтеза нового High Resolution кадра по Low Resolution и старому High Resolution. 14 лет назад моим студентом Кареном Симоняном был создан довольно удачный алгоритм на эту тему (см. Fast video super-resolution via classification), а позднее Карен закончил аспирантуру в Англии, где придумал архитектуру VGG, работал в Google DeepMind, а сейчас Chief Scientist в Inflection.AI. Вот так звездно складывается судьба тех, кто рано успешно займется Super-Resolution, говорю я студентам…
Главный плюс восстанавливающих SR — это потенциально более высокое качество результата. Они, безусловно, сложнее и по вычислительной, и по алгоритмической сложности, но хорошо видно, как это становится все меньшей проблемой с каждым годом, а значит за ними однозначно будущее. В качестве доказательства можно привести такой график (из нашей статьи):
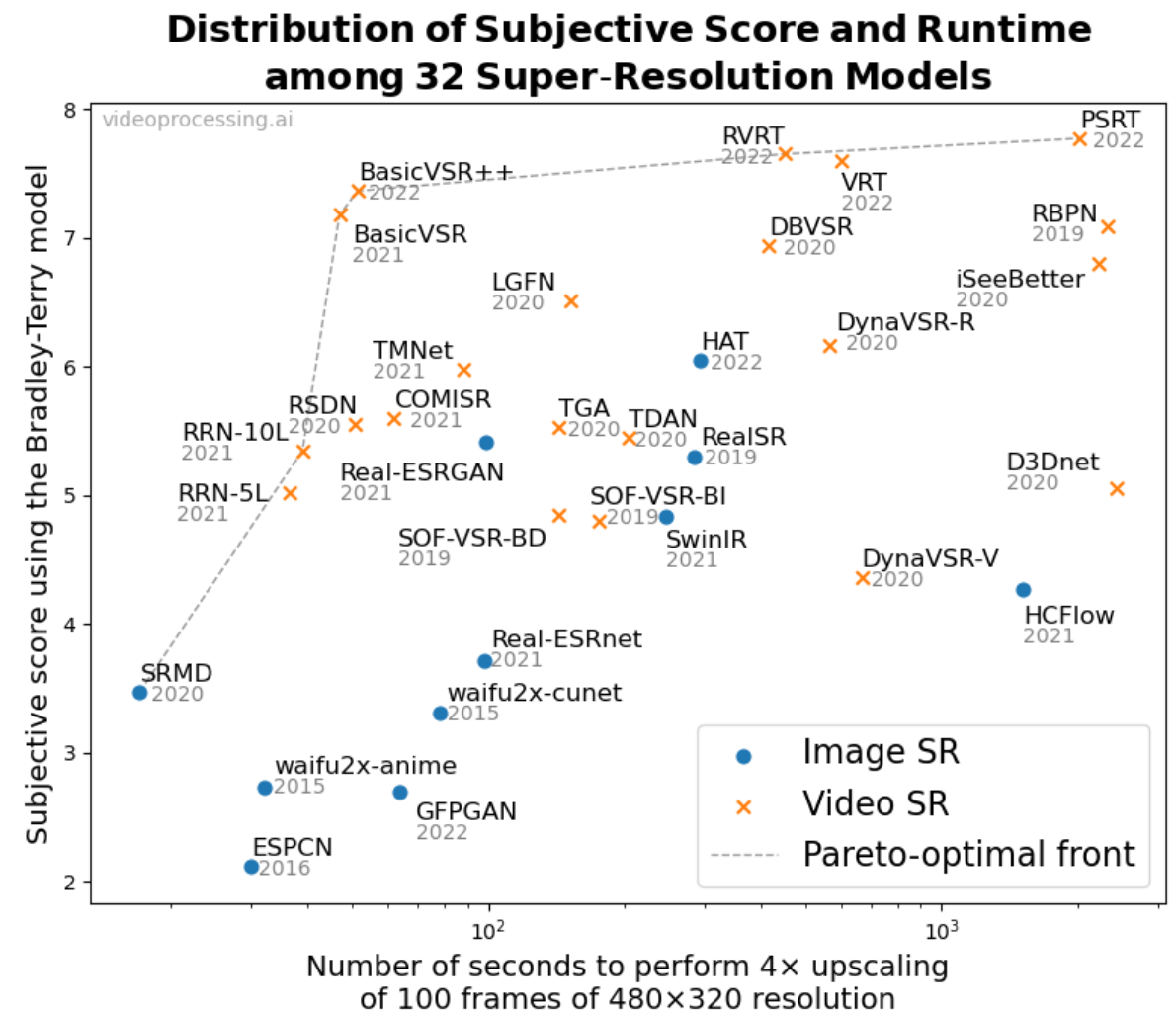
По вертикальной оси тут субъективное качество, то есть оценка людьми. По горизонтали — скорость в логарифмической шкале. Крайние слева быстрее крайних справа больше чем в 1000 раз. При этом обычно развитие идет через взятие новых планок качества, за счет усложнения архитектуры и кардинального падения скорости. С дальнейшим серьезным ускорением, уже за счет небольшого падения качества. И так по кругу. На графике хорошо видно, что хотя самый быстрый алгоритм (пока) Image SR, все остальные алгоритмы на парето-оптимальном фронте — Video SR, более того — большинство из них свежие (хотя график строился прошлой весной). И потенциал их развития, что по качеству, что по ускорению далеко не исчерпан.
Также напомню, что сегодня алгоритмы Video Super-Resolution добрались уже до фотографий на смартфонах. Еще в прошлой статье я описывал, как Google Pixel 3 из пачки кадров восстанавливает кадр с большим разрешением. Вы с рук снимаете фото, а на самом деле в буфер кладется несколько кадров в RAW (по сути — видео), и из них смартфон восстанавливает кадр большего разрешения с большим количеством реальных деталей. Этот цифровой зум нового поколения сегодня повторили многие флагманские смартфоны.
Но еще перспективнее ситуация с телевизорами. Количество 4K экранов растет на глазах. Еще в 2019 году их доля в продажах новых телевизоров по миру превысила 50% (!) и продолжает расти. Более того, давно не проблема купить 8К экран. Вот предложения от 150 тыс. руб. на маркете, озоне и далее по списку. Сегодня если покупается умный телевизор, то он обязан быть минимум 4K (эта характеристика востребована более, чем HDR или любая другая характеристика):
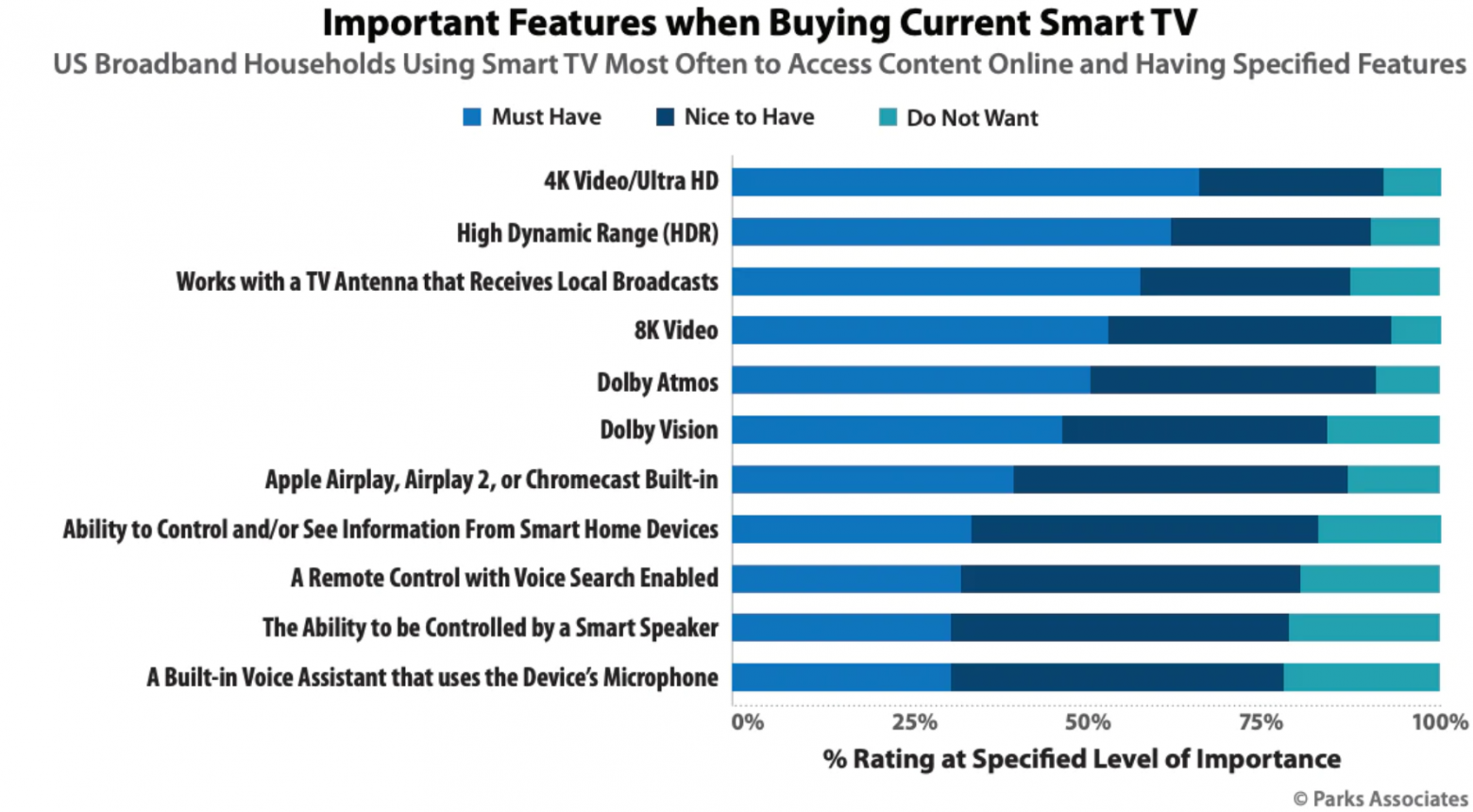
И их покупатели таки хотят смотреть на них картинку в высоком разрешении, а не это ваше жалкое замыленное древнее 2K (про типичное вещание в 480р некоторых онлайн-кинотеатров деликатно промолчим)!
Все вышеизложенное создает огромный спрос на Super-Resolution как со стороны компаний, так и со стороны обычных пользователей. И, казалось, 900+ репозиториев GitHub должны решить все проблемы! Берешь репозиторий с самым большим числом звезд, заводишь у себя на компе (с хорошей GPU карточкой, которая почему-то есть не у всех) и радуешься прогрессу. Ведь так? Сейчас увидим!
Ключевое этой части:
Хотя восстанавливающими алгоритмами из-за их сложности и хайпа занимается на порядок меньшее число исследователей, постепенно увеличивается количество хорошо работающих и сравнительно быстрых реализаций таких алгоритмов.
Сегодня даже при съемке фотографии смартфоном все чаще используется восстанавливающий Video Super-Resolution, но основной спрос на такие алгоритмы придет с массовым распространением 4K и 8K телевизоров. И это произойдет в ближайшие годы на наших глазах.
Артефакты Super-Resolution
Если посмотреть репозитории и свежие статьи, то хорошо видно, что основной фокус сегодня сместился с алгоритмов, увеличивающих разрешение в 2 раза (2х), к увеличивающим разрешение в 4 раза (4х), ибо разрешение телевизоров растет и нужно из FullHD делать 8K:

То есть в новой картинке у нас не 3 из 4 пикселей интерполированы, а 15 из 16, что заметно сложнее. Происходит так потому, что почти всегда, если просто 2 раза последовательно применить алгоритм увеличения 2х, результат будет заметно хуже, чем применение 4х за один раз. Но артефактов у 4х хватает. Зато если подход дает меньше артефактов на 4х, то, как правило, его работа на 2х очень хороша, то есть отлаживать алгоритмы таким образом оказывается проще.
Изменение текстов
Хуже всего пока SR даются тексты. Ниже художества от Real-ESRGAN (на секундочку 17 тысяч звезд гитхаба, 3-е место среди всех SR репозиториев, а учитывая акцент первого места на лица, а второго на анимацию — это первый по звездам репозиторий среди универсальных):
 Real-ESRGAN: хорошо видно, что у бикубика читаемость цифр и текста выше
Real-ESRGAN: хорошо видно, что у бикубика читаемость цифр и текста выше
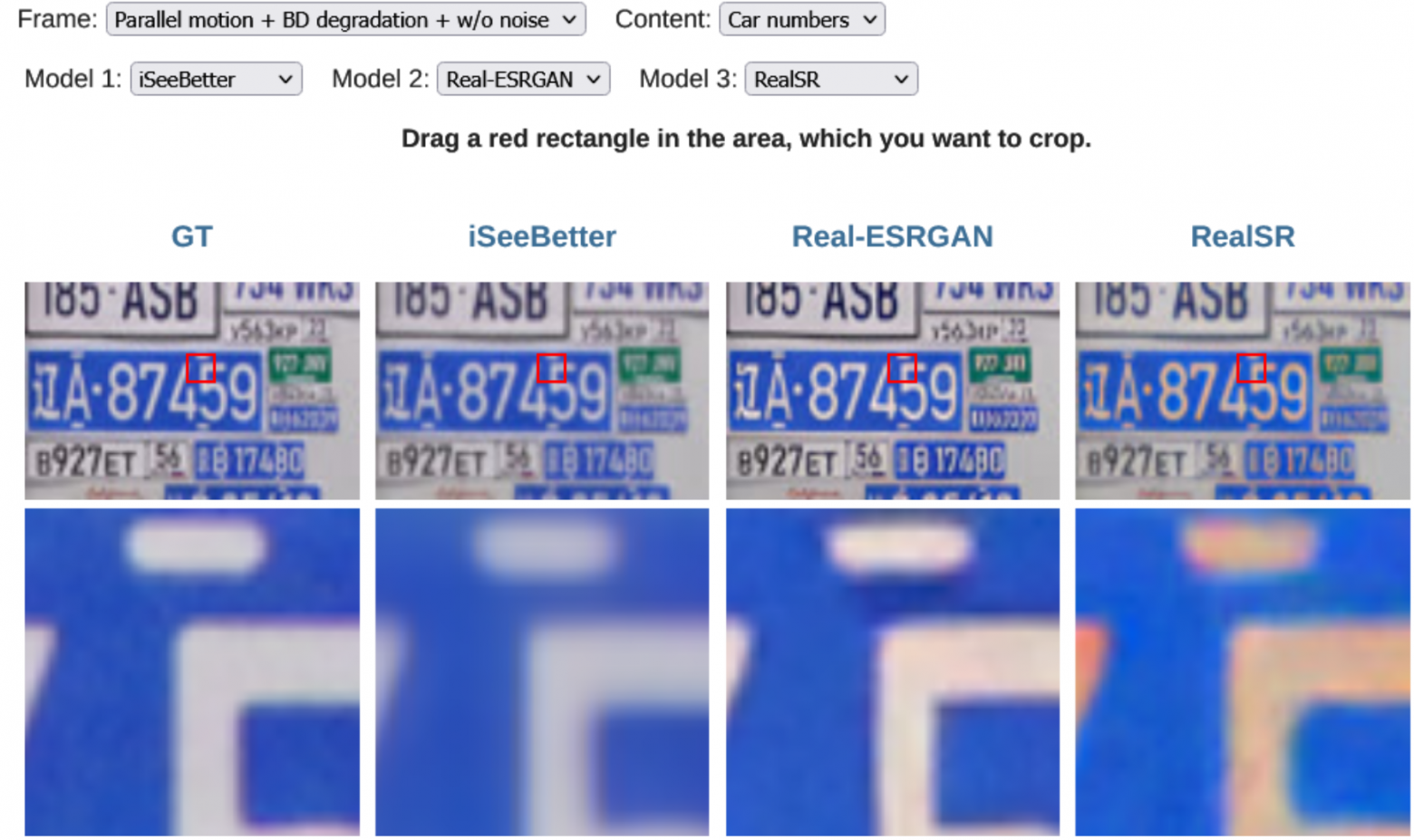
Наиболее неприятна на практике проблема с автомобильными номерами, когда 6 превращается в 8, или 8 — в 0 даже у лучших алгоритмов. А видео с дешевого китайского видеорегистратора (с дешевой матрицей, объективом и выкрученным до безобразия сжатием) люди хотят восстановить довольно часто.
DISCLAIMER: ЕСЛИ У ВАС ВОЗНИКНЕТ МЫСЛЬ ПРИСЛАТЬ НАМ ВИДЕО НА ВОССТАНОВЛЕНИЕ НОМЕРА ИЛИ ЛИЦА — ПОЖАЛУЙСТА, СНАЧАЛА ВНИМАТЕЛЬНО ПОЛНОСТЬЮ ПРОЧИТАЙТЕ ПРОШЛУЮ СТАТЬЮ!
Ниже пример, как восстанавливают российские номера разные SR (GT — это исходная картинка):
 Фрагмент российского номера в бенчмарке MSU Video Super-Resolution Benchmark: Detail Restoration
Фрагмент российского номера в бенчмарке MSU Video Super-Resolution Benchmark: Detail Restoration
Хорошо видно, что есть довольно удачные реализации, есть ужасные. Сортировка — по нашей метрике ERQA (Edge Restoration Quality Assessment — ссылка на исходники). Вариации звездного и хайпового Real-ESRGAN (который на других кейсах работает неплохо) прочно обосновались в конце списка.
А это для разнообразия — китайские автомобильные номера (также отсортированные по ERQA):
 Фрагмент китайского номера в бенчмарке
Фрагмент китайского номера в бенчмарке
Интересно, что лидеры несколько поменялись, но эпичных примеров (в том числе от Real-ESRGAN) хватает. Обратите внимание, что весь низ списка на этом примере занимает «второй по звездочкам» SR с GitHub waifu2x (которого на данном примере специально погоняли с разными параметрами). Количество звезд, как хорошо видно из этих примеров, не означает пристойной работы алгоритма в вашем кейсе.
Особенно сильно страдают иероглифы, поскольку в одном символе там намного больше деталей (плата за большую компактность текстов), которые часто могут сильно убиваться при применении Super-Resolution:
 И снова большой привет от Real-ESRGAN
И снова большой привет от Real-ESRGAN
Изменение текстур
Другая распространенная проблема SR — это изменение текстур. Ниже пример, на котором на относительно шумном видео часть кожи на лице бабушки алгоритм превратил в некий кусок бороды (если у бабушки борода, это уже не бабушка, а дедушка, но нейросеть этого пока «не знает» и добавила волосы даже на губу):
 И опять звездный Real-ESRGAN
И опять звездный Real-ESRGAN
А тут зубы молодого человека стали золотыми. В середине прошлого века это было модно, кстати:
 Приключения с RealBasicVSR
Приключения с RealBasicVSR
А вот пример, который мне очень нравится. В оригинале была кирпичная стена, и в увеличенном изображении… тоже кирпичная стена! И это, безусловно, фантастический успех нейросетей в «понимании» характера текстур. Есть маленькое «но» — размер кирпичей стал примерно в 3 раза меньше, и идут они существенно менее ровно (кстати, мелкая кирпичная кладка «проявилась» и на светлой колонне рядом, происходит «сползание» текстуры):
 Это опять наш любимый Real-ESRGAN
Это опять наш любимый Real-ESRGAN
В упоминавшейся выше статье «Апскейл, который смог» было много заслуженных дифирамбов Real-ESRGAN, надеюсь, теперь у вас будет лучшее понимание суровой реальности, с которой придется столкнуться при его использовании.
Бывают забавные примеры и у коммерческого софта. Например, был грустный жираф со вполне себе аутентичными пятнами, а после увеличения его голова словно сделана из пластика. Опять немного изменилась текстура материала, но для человека это очень заметно и критично:
 Коммерческий Topaz Video Enhance AI AMQS 1
Коммерческий Topaz Video Enhance AI AMQS 1
Подобные артефакты крайне нетривиально автоматически ловить. Визуально проблема хорошо видна, и если немного изменить параметры или метод (которых в том же Topaz очень много), то проблема уходит. Но хотелось бы все это делать автоматически, а не оч умелыми ручками. Пока это сложно. Работаем над этим.
Неравномерная резкость
Еще одна проблема, весьма характерная для Super-Resolution, — это неравномерное увеличение резкости объектов заднего плана. Особенно актуально это для фильмов, где съемка с малой ГРИП (глубиной резко изображаемого пространства) — базовый прием. А SR может из своих высших соображений внезапно сделать отдельные фрагменты дальше расположенных объектов резкими, сохраняя размытыми ближе расположенные объекты:
 Наш пока еще горячо любимый Real-ESRGAN
Наш пока еще горячо любимый Real-ESRGAN
Это не очень хорошо, потому что человек на «низком уровне» распознавания по резкости ориентируется на глубину объектов сцены, и, если дальние объекты имеют «неправильную» резкость, это доставляет дискомфорт. Также в видео подобные резкие объекты заднего плана могут то становиться резкими, то опять размытыми, что тоже (как бы помягче…) не доставляет радости при просмотре. Причем если для природных объектов это еще не так бросается в глаза, то аналогичные проблемы на зданиях и других искусственных объектах смотрятся крайне неестественно:
 Для разнообразия SwinIR (то, что девушка стала резче — хорошо, но дальние окна испорчены)
Для разнообразия SwinIR (то, что девушка стала резче — хорошо, но дальние окна испорчены)
Понятно, что сегодня существует довольно много методов восстановления глубины сцены, которые могут помочь детектировать эти артефакты, но в любом случае их анализ пока не является ни тривиальным, ни в достаточной степени точным. Поэтому для получения годного результата нужны будут ваши мозолистые руки и, главное, зоркий глаз…
Добавление и искажение объектов
Отдельная интересная тема, когда сеточке что-то там «показалось» и она добавляет объект в сцену или искажает его. Например, у девушки ниже были довольно крупные ресницы (накладные?), которые самый залайканный SR на GitHub на сегодня мало того, что превратил в оправу очков, так еще и добавил в глаз еще одно лицо. Что характерно — тоже в очках:
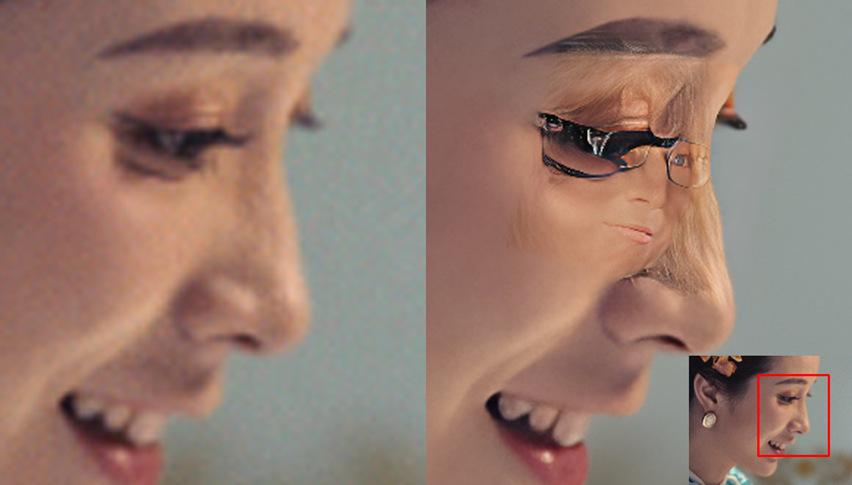 Работа с лицами очень неплохого GFPGAN
Работа с лицами очень неплохого GFPGAN
Или вот в глаз младенца алгоритм лицо добавил. И опять в очках! Это уже тенденция, как вы понимаете (не поворачивайтесь боком к этой нейросети!):
 И это лучший GFPGAN!
И это лучший GFPGAN!
Но это не все проблемы с самым лучшим (по звездам) алгоритмом. Например, ниже он превратил палочку в длинный-длинный зуб (еще один с другой стороны и будет вампир!):
 Оригинал, бикубик и GFPGAN
Оригинал, бикубик и GFPGAN
Но и это не самое веселое! Если присмотреться — молодой человек изначально вполне себе европейской внешности после SR стал… немного азиатом (хорошо видно по глазам). А вот не надо было щуриться! Эту сеть обучила и выложила в открытый доступ китайская компания Tencent, поэтому неудивительно, что в обучающей выборке могло быть некоторое (скажем вежливо) смещение национального состава, но в любом случае уже можно предсказывать, что на 8К телевизорах использование этого алгоритма приведет к тому, что герои вашего любимого сериала станут (иногда!) чуть более китайскими. А если загрузить другие веса, то наоборот — чуть более европейскими. В общем — для кого-то бага, а для кого-то новая бизнес-ниша и уникальная опция Super-Smart-AI-TV 2030! С большой вероятностью пересматривать любимые старые дорамы, щелкая пресетами на 16К экранах, через 10 лет может оказаться весьма занятным развлечением! Откроется много новых деталей!
Короче, прогресс наблюдается очень мощный и очень быстрый. Новые репозитории появляются буквально каждые 2 дня. И самые лучшие результаты, естественно, не у тех, у кого больше всех звезд, а у новых лидеров.
Картинки, приведенные выше, взяты из нашего создаваемого сейчас датасета артефактов Super-Resolution. Его цели:
Поиск контента наиболее сложного для современных SR
Более глубокий анализ плюсов и минусов текущих алгоритмов SR (сразу проверять их на сложных примерах)
Создание базы для обучения новых метрик качества SR
Создание максимально автоматического pipeline для конвертации материалов в 8K на базе имеющихся алгоритмов (со всеми их недостатками)
Ниже показан пример автоматической разметки артефакта (подсказка зоркому глазу):
 Плохо заметный без подсказки баг и тепловая карта метрики
Плохо заметный без подсказки баг и тепловая карта метрики
Совершенствование метрик артефактов позволяет уменьшить объем ручной работы, то есть ускорить создание датасета. А рост датасета позволяет в свою очередь улучшить метрики. И так по кругу, пока не кончатся деньги на толокеров! Далее крупный датасет позволит с лучшим качеством тестировать алгоритмы и обучать новые метрики уже непосредственно на нем. А новые метрики позволят увеличить автоматизацию конвертации больших объемов данных. Так выглядят шаги прогресса в современном мире, где рулят данные.
Пользуясь случаем приглашаю к сотрудничеству компании, которым интересно качество, и исследователей, у которых есть амбиции и компетенции для анализа восприятия нейросетевых артефактов человеком (биологи и психологи также приглашены!). Аналогичный датасет мы сейчас разрабатываем для нейросетевых алгоритмов сжатия, взяв за основу предшественников разрабатываемого сейчас JPEG AI, и там уже мно-о-о-о-ого интересного и эпичного (надеюсь, как-нибудь тут опишем эту нейросетевую революцию, которая зреет в стенах исследовательских лабораторий прямо сейчас).
Ключевое этой части:
Прогресс алгоритмов Super-Resolution за последние 3 года колоссальный, однако идеального алгоритма нет и в ближайшие годы точно не будет.
Более того, артефакты новых алгоритмов становятся все более изощренными и сложными в обнаружении (одни «более китайские» лица чего стоят!). Выше были показаны существенные проблемы у всех алгоритмов из TOP-3 по звездам на GitHub в топике SR.
Параллельно с совершенствованием алгоритмов сейчас совершенствуются метрики артефактов, что позволит в относительно короткой перспективе заметно повысить качество полностью автоматического увеличения разрешения.
Мы опубликовали сравнительно простую метрику Edge Restoration Quality Assessment (just run pip install erqa) и сейчас работаем над более сложными и интересными метриками. Желающие поучаствовать в создании и использовании датасета артефактов SR — you are warmly welcome!
Наши бенчмарки Super-Resolution
Я довольно регулярно рассказываю, по каким причинам средняя эффективность научных исследований оставляет желать лучшего (наука живет в своей башне из слоновой кости). В очередной раз проиллюстрируем тему на примере бенчмарков. Пальцем некультурно показывать не будем, но многие бенчмарки построены на открытых датасетах. Ведь открытость — это всегда хорошо и благо, согласитесь! Из плюсов:
Открытый датасет позволяет резко упростить сабмиты в бенчмарк. В худшем случае авторы бенчмарка даже не проверяют результат, а просто добавляют в таблицу цифры, присланные авторами алгоритма. Профит!
Авторам алгоритма можно не раскрывать свой алгоритм и код (чего не любят те, кто патентует, и те, у кого работает не так, как заявлено), что также повышает популярность. Опять профит!
Цитирование такого бенчмарка и его лидерборд растут весьма быстрыми темпами. А цитирование в современном научном мире — это главное. Снова профит!
Минусы прекрасно понимают все, кто пытался воспроизвести результаты статей на своих данных. Почему-то на других данных топовые методы таких бенчмарков часто не воспроизводятся. При этом наука устроена так, что если метод показывает наилучшие результаты в бенчмарке, то он типа «выбил SOTA» и статья о нем довольно легко проходит на топовую конференцию (что критично для отчетов по крупным научным грантам). Поэтому если очень надо… Подробнее про кризис воспроизводимости можно почитать тут.
Дальше кто-то говорит: «Да это уже полное безобразие (с воспроизводимостью), мы тут новый датасет собрали, посмотрите, на нем совсем другие алгоритмы в топе!» Так рождается N+1 бенчмарк (верно для любого N), естественно также открытый, и история повторяется. При этом выбирать лучшие алгоритмы все равно можно, но для этого надо искать методы, которые более-менее высоко (но не в топе) на нескольких бенчмарках. Иногда, бывает, приходит компания и финансирует создание бенчмарка с закрытым датасетом. Он менее выгоден ученым (и цитирование растет медленнее, и алгоритмы нужно тяжело и мучительно прогонять самостоятельно). Но в итоге (на какое-то время) удается понять, кто реально работает.
Так вот, нами как людьми, которым не нужны цитирования, работающими в основном с компаниями, создано 3 бенчмарка разных кейсов Video SR на закрытых датасетах. Правда Low Quality данные открыты, что облегчает сабмиты (и заточку, поэтому с получением финансирования планируем полностью закрытые треки для лидеров), и нам удается держаться в топе категории Video Super-Resolution среди 16 бенчмарков. Каждый из этих бенчмарков достоин отдельной статьи, я считаю, но более интересные результаты там будут при увеличении числа методов в лидерборде. Поэтому пообещаем написать про них отдельные статьи, когда у первого будет 100, второго 150, а у третьего 250 строчек в лидерборде. А пока кратко расскажем, о чем они и почему в них разное число строк.
Video Super-Resolution Benchmark: Detail Restoration
Данный бенчмарк сравнивает алгоритмы на датасете, снятом на физическом стенде со следующими разделами:
«Board» — с разными текстурами, в том числе лицами
«Car numbers» — с номерами машин разных стран
«Noise» — шаблон псевдослучайного шума для анализа близости алгоритмов, анализируемых методом черного ящика.
«QR» — для анализа, насколько убиваются QR коды (а они, как правило, убиваются)
«Text» — для анализа, как выживают шрифты, иероглифы и рукописный шрифт
«Mira» — для анализа заточки алгоритма под миры
«Metal paper» — для анализа работы с реальным шумом
«Color lines» — для анализа искажений цветов

Это разные виды анализа, которые в совокупности могут много интересного поведать о конкретных характеристиках SR.
На данный момент в бенчмарке 32 метода, и хотя датасет высокого разрешения закрыт, можно скачать данные в низком разрешении, прогнать на них свой алгоритм и залить эти данные нам. Алгоритм появится в лидерборде и вырезках с возможностью удобно сравнить его на разном контенте:
Из интересного — мы (пусть с задержкой) прогоняем лучшие алгоритмы сами, чтобы получить скорость, и прогоняем через субъективное сравнение (то есть через оценку людьми), поэтому можно строить такие интересные графики соотношения скорости к качеству, в том числе на отдельных частях бенчмарка:
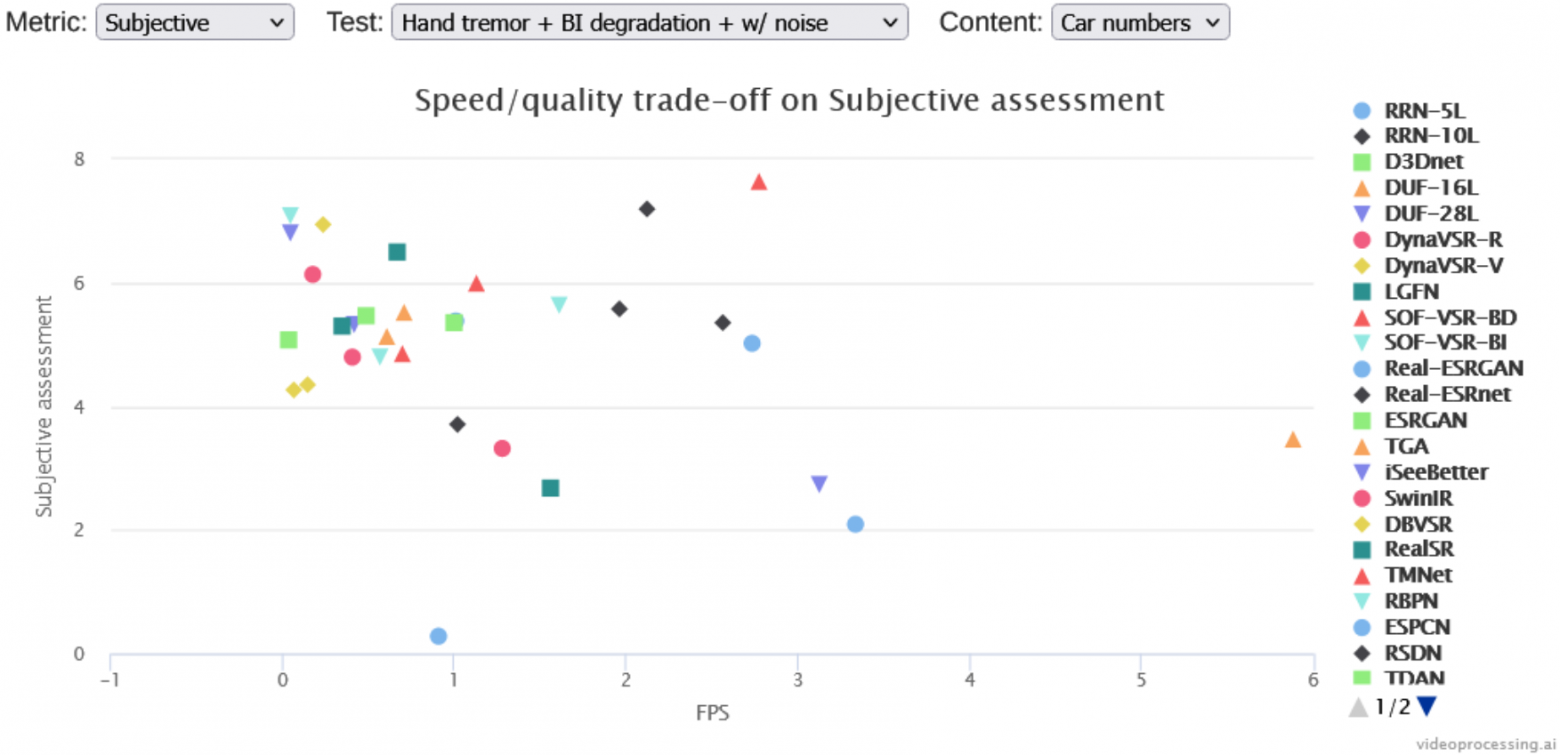
Video Upscalers Benchmark: Quality Enhancement
Этот бенчмарк менее академичен и активно сравнивает на разном контенте коммерческие апскейлеры, в том числе:
Сравнение идет в 4 треках: увеличение в 2 и в 4 раза, а также съемка и анимация (каждый вариант с каждым). Для лучших методов также прогоняется субъективное сравнение.
Обратите внимание ниже, что на некоторых клипах новые SR обгоняют исходные видео по субъективным результатам (оценка людьми) даже при масштабировании в 4 раза. И так происходит не один раз!
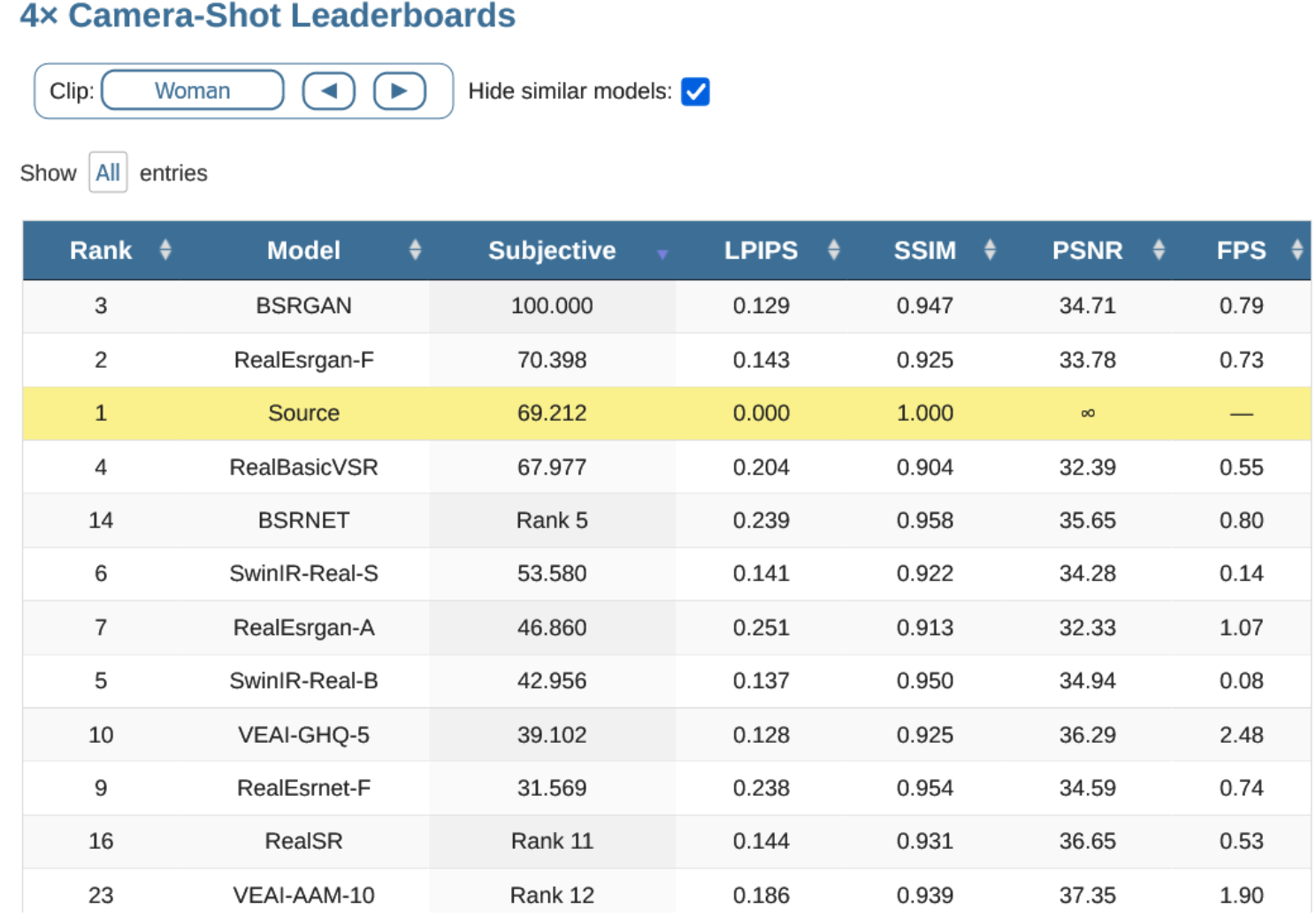
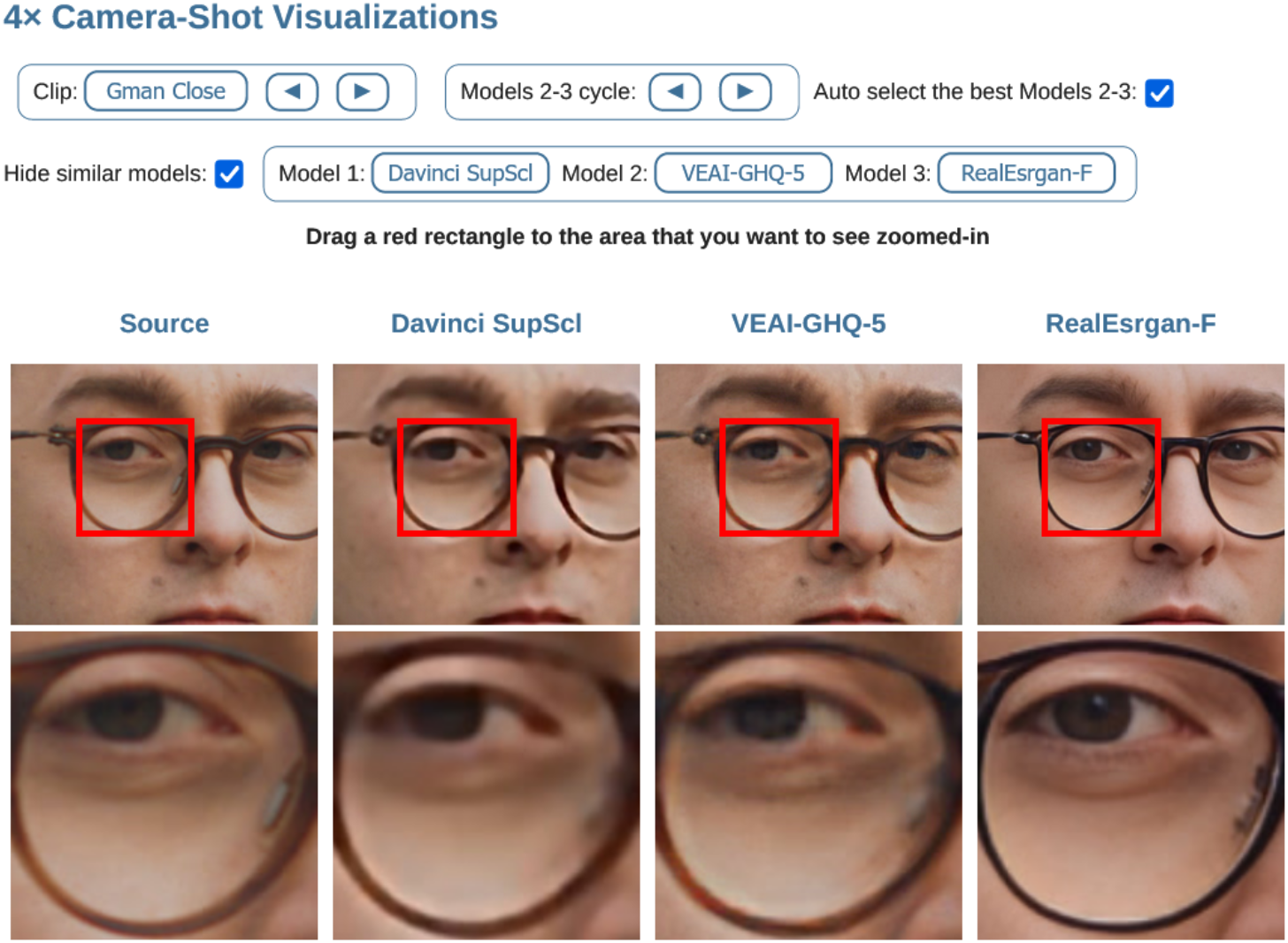
Там же легко сравнить клипы визуально и понять, почему люди так оценивают SR вслепую:
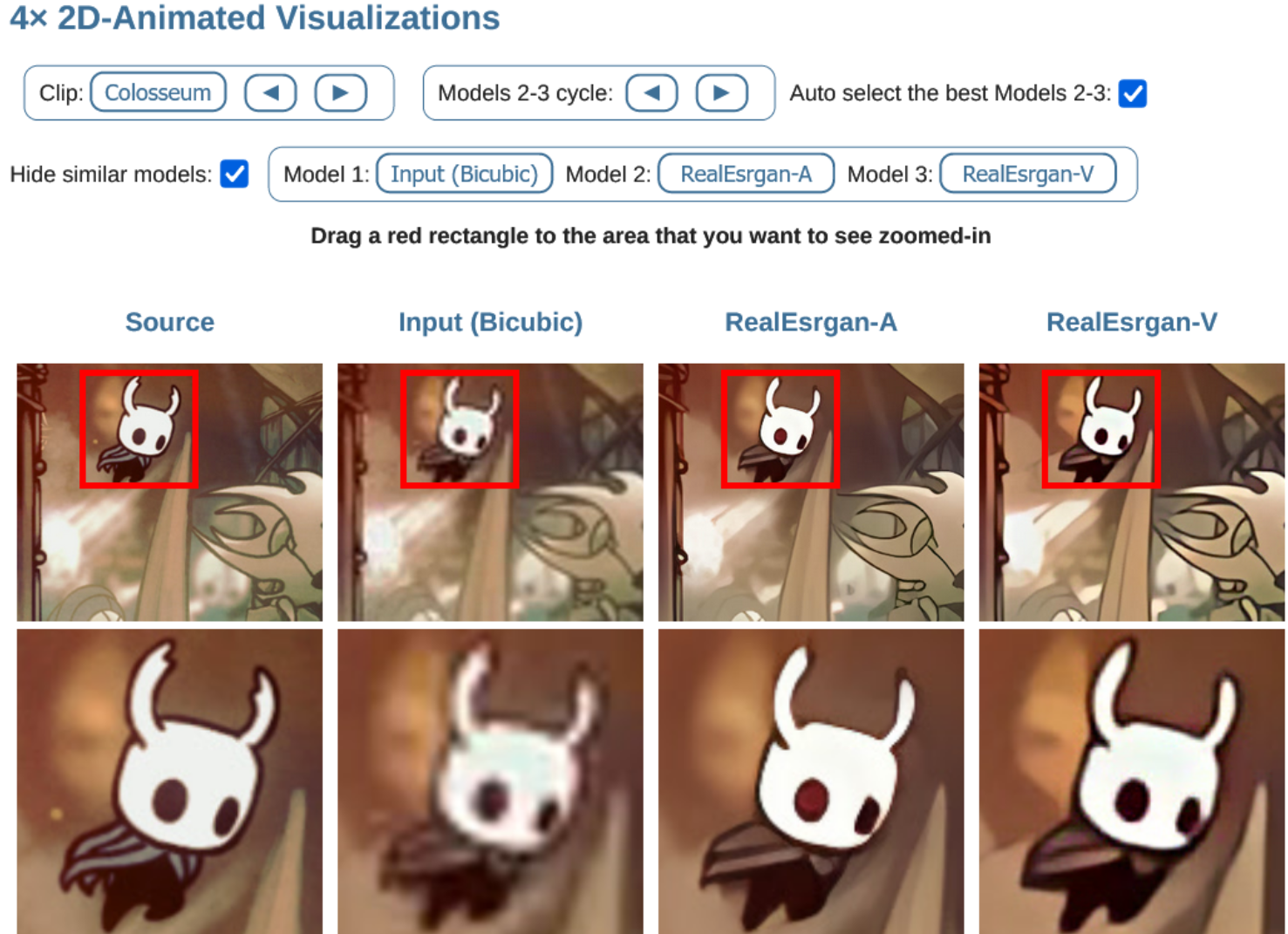
Первые впечатляющие результаты у алгоритмов SR были на анимации/мультфильмах/аниме и многие методы специально на них ориентируются. Поэтому в бенчмарке есть отдельный трек для них. Хорошо видно, что Bicubic для увеличения разрешения анимации сегодня — это однозначно выбор неудачников:
Всего в бенчмарке сейчас 42 метода. Вы можете помочь нарастить их число, сделав свой сабмит так же, как в предыдущем бенчмарке.
Super-Resolution for Video Compression
Ну и, наконец, в каком-то смысле профессиональный бенчмарк — это измерение качества работы SR в зависимости от использования разных алгоритмов сжатия.
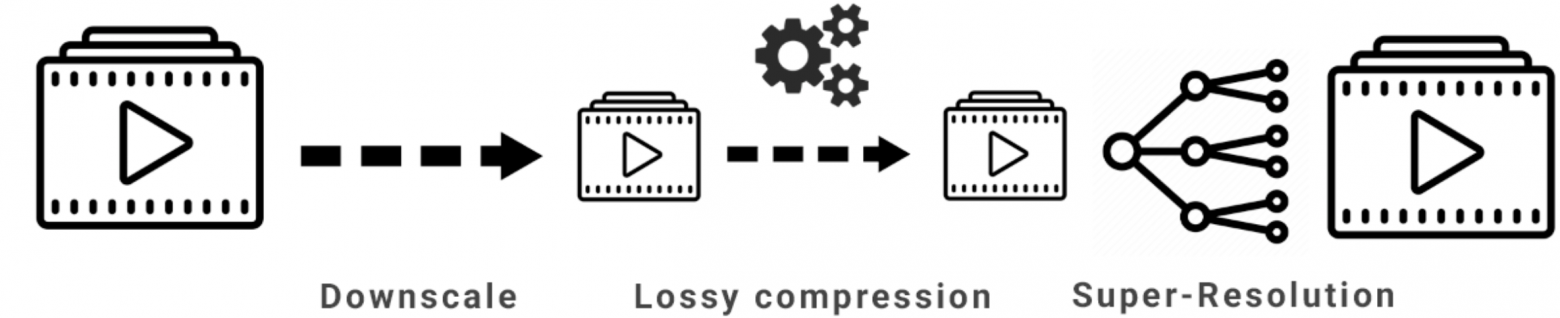
Для максимизации качества увеличения разрешения критичны так называемые высокие частоты в кадре. При этом не секрет, что именно высокие частоты наиболее страдают при сжатии. Как следствие, алгоритм, который демонстрирует великолепные результаты на RAW, может очень сильно провалиться, когда ему на вход придет обычное видео с YouTube. Более того, выясняется, что небезразлично, каким именно стандартом был сжат поток. И чем более свежий стандарт (и лучше он сжимает), тем относительно хуже показывают себя алгоритмы увеличения разрешения.
Глобально это означает, что для ваших любимых 8К телевизоров и заметно сжатого контента необходимо использовать другие алгоритмы и (по крайней мере пока) подбирать алгоритм в зависимости от контента и кодека.
В данный момент в бенчмарке представлены стандарты H.264 (AVC), H.265 (HEVC), H.266 (VVC), AV1 и китайский AVS3. По сути это основной набор, претендующий на лидерство в ближайшие 10 лет, после ухода на заслуженную пенсию H.264.
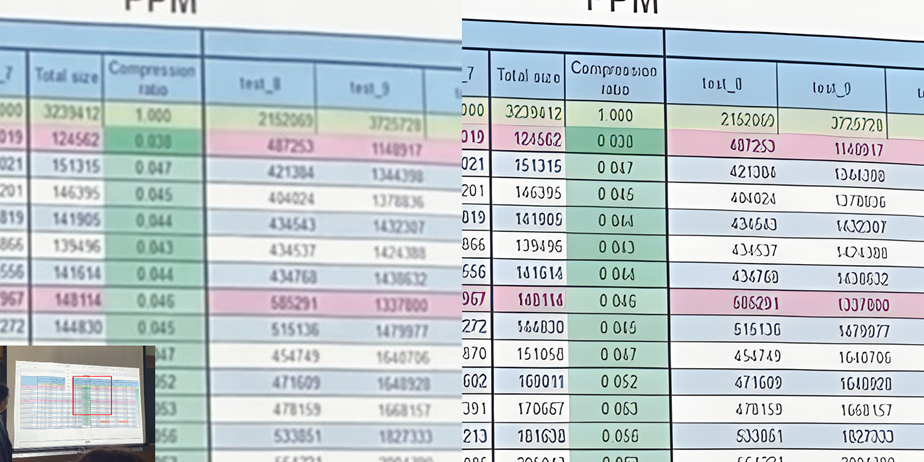
Существенное отличие этого бенчмарка заключается в том, что в силу заметной разницы в результатах SR между стандартами сжатия видео приходится прогонять пары SR+Codec. Всего сейчас прогнано 87 пар и видно, что для x264, x265 и AVS3 наилучший результат показал RealSR (в первую очередь для «убитых» низким битрейтом видео), для VVC — COMISR, а для AV1 — SwinIR. В таблице ниже приведены значения BSQ-rate (Bitrate-for-the-Same-Quality), поэтому чем ниже значение в таблице, тем лучше и все значения в единой шкале:
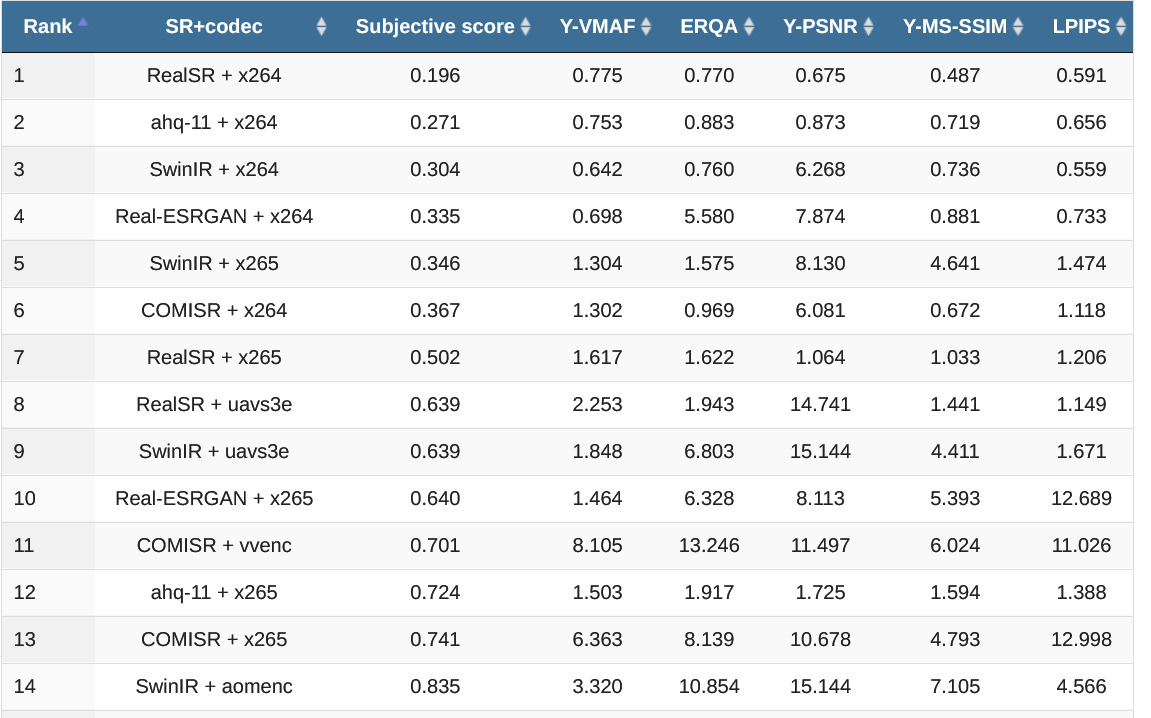 Значения BSQ-rate для каждой метрики, сортировка по субъективному качеству
Значения BSQ-rate для каждой метрики, сортировка по субъективному качеству
Из-за вычислительной и финансовой сложности результатов с субъективными сравнениями в бенчмарке не так много, поэтому это своего рода скоринг и отладка методики, которые позволят в дальнейшем в большем масштабе (скорее всего на деньги какой-то компании) сделать более серьезное исследование. Но уже сейчас интересно посмотреть, как некоторые SR весьма неплохо отрабатывают с x264. На примере ниже коммерческий Topaz (пресет ahq-11) + low resolution x264 отрабатывает заметно более качественно, чем «чистый» x264, да и RealSR хорош:

В данной работе, пожалуй, сильнее всего проявились недостатки «старых» метрик, когда в некоторых случаях их коэффициенты корреляции с субъективной метрикой ушли в отрицательные значения (чем лучше качество согласно метрике, тем хуже результат!):
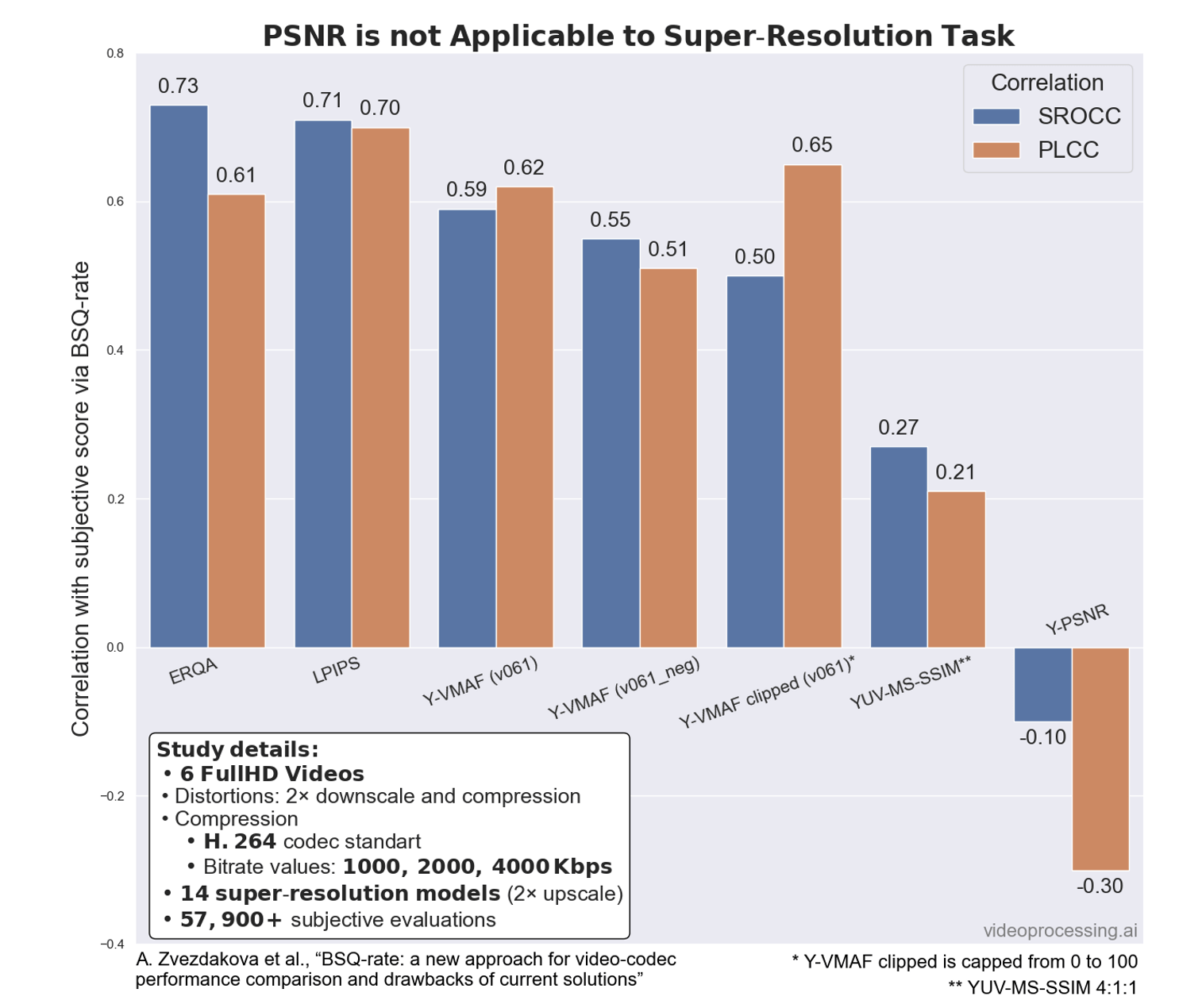
Это означает, что для улучшения результатов в этой задаче критично появление новых метрик, причем желательно дифференцируемых.
В рамках этого бенчмарка у нас в свое время был выпущен отчет на 80 страниц который дает представление о том, сколько в этой теме тонких моментов. Пока результат можно сформулировать так: создание SR специально ориентированных на работу в паре с кодеком имеет смысл и даст ощутимый прирост качества результата, особенно на устройствах с высоким разрешением, но поле это на данный момент почти не паханное. Специально акцентирую для желающих восстановить лицо или номер на сильно сжатой последовательности — это ваш кейс. И работы здесь до годного результата еще очень много.
Традиционно замечу, что вы также можете сабмитить свои результаты в этот бенчмарк, помогая расширять его!
Ключевое этой части:
Быстрый рост числа репозиториев и невозможность воспроизвести результаты многих SOTA алгоритмов на наших данных спровоцировали нас на создание трех бенчмарков с разными датасетами и анализом кейсов практического применения SR.
Выше дан смысл бенчмарков, дальше можно идти на их страницы и смотреть конкретику. Помните, что если вам не хватает методов, то вы можете помочь, сделав сабмит понравившегося вам метода. Во-первых, вы увидите его на графиках, а во-вторых, если метод будет хорош, мы сделаем для него субъективное сравнение.
Измерение качества Super-Resolution
В комментариях обязательно найдутся профессиональные фотографы, которые возведут очи к небу и скажут что-то типа: «зачем выдумывать что-то новое, ведь уже два века ЕСТЬ МИРЫ!» Спорить с этим очень сложно. Миры действительно существуют давно, и деды наши их использовали, и прадеды для оценки объективов фотоаппаратов, потери резкости телевизионного сигнала и так далее. Если кратко, то это специальная картинка, по которой (с поправкой на муар) с момента слияния различимых линий в единый серый можно судить о разрешении:

Про миры мы, конечно, знаем (см. описание первого бенчмарка). Но в новой чудной нейросетевой реальности с ними есть одно маленькое-маленькое «НО». Как показывает опыт, даже способностей третьекурсника хватает, чтобы добавить миры в обучающую выборку и резко улучшить результат SR. Ниже пруф:
 Сверху исходный Real-ESRGAN, снизу — дообученный третьекурсником (картинка кликается, смотреть в исходном разрешении)
Сверху исходный Real-ESRGAN, снизу — дообученный третьекурсником (картинка кликается, смотреть в исходном разрешении)
Поэтому результат на мирах для нейросетевых методов показывает только наличие чего-то похожего в обучающей выборке (заметим, что это мы еще не использовали нагло ту же картинку для обучения). Оптиков может немного смутить, конечно, что поменялось направление косых линий между 7 и 8. Но у исходного Real-ESRGAN изменения направления линий было намного больше! Можно надеяться и верить, что авторы алгоритма ничего такого в выборку не подмешали. Это очень профессиональный религиозный подход (поскольку основан на вере). Здравствуй, вычислительная фотография!
Именно из-за возможности легко добавить в обучающий датасет миры измерение на них потеряло практический смысл. Понятно, что остаются еще всякие ухищрения, типа забора из датасета Kodak (тот случай, когда компании уже почти нет, а забор еще остался):

Но, к сожалению, если в обучающей выборке были похожие картинки, то заборы, лестницы, ряды окон небоскребов и другие подобные паттерны будут обрабатываться выше среднего, что на резкости остальных деталей практически не скажется… Вот такая печаль!
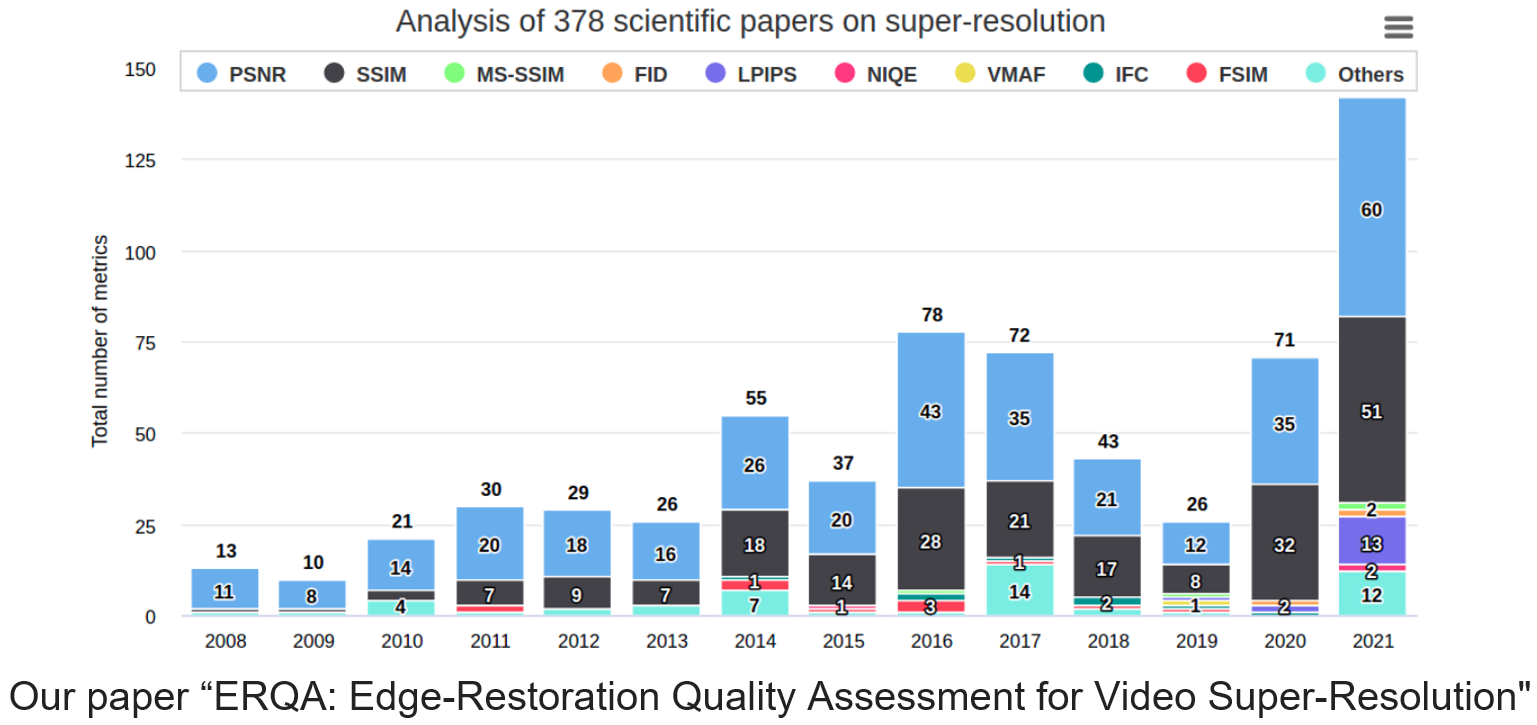
В свое время мы проанализировали почти 400 статей по SR на предмет используемых метрик и хорошо видно, что в большинстве статей до сих пор используется PSNR:
На картинке ниже видно, что 99% людей считает, что левая картинка лучше, а PSNR считает, что правая лучше, причем значительно:

Так происходит потому, что если резкая граница немного промахивается по местоположению (а точно угадать ее местоположение на субпиксельном уровне непросто), то PSNR жестко штрафует алгоритм за такую границу, причем, если граница более плавная, штраф меньше. По сути это означает, что PSNR «поощряет» более размытый результат и нужны новые метрики.
Если внимательно посмотреть на график в начале этой части, можно увидеть там рост популярности метрики LPIPS для измерения качества SR. Метрика неплохая, дифференцируемая (то есть может быть поставлена в loss), но… как выяснилось, она взламывается (можно существенно увеличить результат, не улучшая алгоритма, подробнее про взлом метрик рассказано тут). Вот пример накрутки метрики в 10 раз:
 LPIPS, взломанный с сохранением других метрик (что сложнее)
LPIPS, взломанный с сохранением других метрик (что сложнее)
