Делаем домашнюю ферму для рендеринга видео
В этой статье я расскажу о своём опыте создания отдельного сервера («ферма» уж больно громко сказано) для рендеринга видео в домашних условиях.
Как известно, ренедеринг видео и трёхмерных изображений занимает много времени и требует много ресурсов компьютера. Ещё свежи воспоминания, как будучи студентом я ставил на ночь жужжащий компьютер с запущенной программой сборки фильма, а на утро оказывалось, что либо не хватило места на жёстком диске, либо что-то забыл добавить в ролик и всё приходилось начинать сначала. Сейчас настоящие профессионалы делают эту операцию удалённо. Например, режиссёр Джеймс Камерон во время съёмок фильма «Аватар» специально для себя сделал заказ на создания целого дата-центра, в котором запускались рендеринги сцен. Я пока ещё не настолько крут, чтобы строить свой отдельный дата-центр, но идея того, что эта операция могла бы быть запущена отдельно на другом сервере не давала мне покоя долгое время.
Вторая проблема — это монтаж самого видео. Несмотря на то, что современные компьютеры становятся мощнее, развитие видеокамер тоже не стоит на месте и получившиеся видео файлы становятся всё тяжелее и тяжелее. И, как следствие, их становится проблематично обрабатывать. Когда монтируешь продолжительный фильм, то предпросмотр трека с наложенными фильтрами и переходами начинает подгружать процессор и изображение начинает лагать, делая творческий процесс монтажа утомительным. Из того, что я пробовал, самый продуктивный был iMovie, что предустановлен на всех Маках. Даже фильм продолжительностью в 45 минут можно было редактировать без особых проблем на относительно маломощном макбуке. Можно было применить любой фильтр и увидеть результат в окне предпросмотра без каких-либо лагов. Так что владельцам маков тут повезло. Один минус у iMovie: во время работы он начинает потреблять непомерное количество дискового пространства. Видимо, это связано с агрессивным кэшированием для редактирования и предпросмотра.
В этой статье я опишу свой опыт, как я пытался решить эти две проблемы монтажа и рендеринга на примере домашнего видео ролика.

Если сравнивать с виндой или МакОсью, для линукса как правило бывает не так уж и много десктопных приложений, но выбор именно редакторов видео оказался на удивление широк. Поиграв с нескольким вариантами, я пока остановился на Kdenlive для работы с небольшими видео. При сравнении с другими программами там есть хороший набор функций, но в рамках данной статьи нас интересует всего одна, но приятная особенность: при сведении уже готового фильма, программа предлагает две возможности — как обычно срендерить в файл или сгенерировать скрипт.
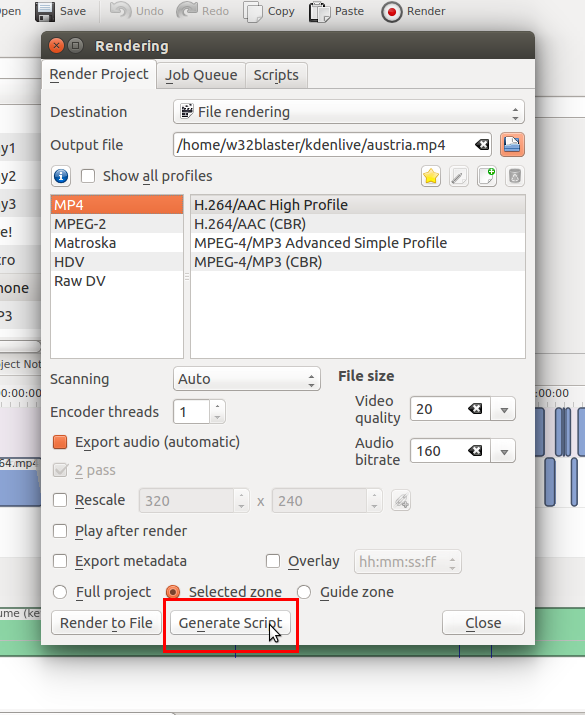
При этом она просто создаст обычный shell-скрипт, который можно запустить потом из командной строки. В том числе и на другом компьютере. К чему я клоню? Да просто таким образом можно сводить проект на удалённом сервере. Для этого можно использовать облака, свой сервер, ну или даже мощный рабочий компьютер, который остаётся постоянно включённым в офисе (но я, конечно же, этого не говорил). План простой: сводим проект, генерируем скрипт, перекидываем весь проект на сервер, запускаем процесс удалённо.
Но это звучит слишком просто для настоящих бизонов. Добавим немного условий в задачу. Я уже жаловался, что монтаж оригинальных видео-файлов является задачей, требующей много ресурсов. Во время работы мы просматриваем результат на маленьком окошке предпросмотра, десятками раз прокручивая отдельные сюжеты, подгоняя субтитры, меняя фильтры и добавляя музыкальное сопровождение. А что если монтировать проект с маленькими видео-файлами, а уже окончательную сборку проводить с оригиналами? Всё равно мы скорее всего редко раскрываем предпросмотр во весь экран во время работы. В итоге, процесс выглядел бы таким образом:
- Для каждого видео исходника мы создадим его легковесный клон.
- Оригиналы мы перекинем на сервер.
- Монтаж будет производиться на личном компьютере с использованием легковесных копий (я использовал свой лаптоп).
- Перед сборкой мы проект перекидываем на сервер, где уже имеются исходники в оригинальном качестве.
- Замещаем легковесные клоны оригинальными.
- Запускаем рендеринг фильма в высоком разрешении.
- Опционально: оповещаем о завершении процесса по емайлу или СМС.
- Скачиваем готовый результат на личный компьютер.
- Тащимся от готового видео (и собственного мастерства).
Обо всём по порядку.
Для линукса есть довольно популярная программа для конвертирования и сжатия видео — HandBrake. Так как задача у нас просто сжать исходники, я особо выдумывать с настройками не буду и просто использую готовые пресеты. Выбираем iPod, которые даёт неплохой результат (напоминаю, видео для домашнего использования) и пробую сжать исходники.

Иногда после отличного отпуска у нас этих исходников могут быть десятки, если не сотни, и нужно эту работу как-то автоматизировать. Конкретно у HandBrake есть свой командный интерфейс. Поэтому можно быстро накатать скриптик, ну что-то типа этого:
#!/bin/bash
# convert.sh
quality=30
for file in ls $1/*
do
tempfile="${file##*/}"
filename="${tempfile%.*}"
outputFile="$2/$filename.mp4"
echo -e "\n\n Compress file $file"
HandBrakeCLI -i $file -o $outputFile --preset="iPod" -q $quality -w 160
done
Запустив его командой convert.sh ./original-videos ./small-videos, мы создадим для каждого файла его уменьшенную и оптимизированную копию. Единственное условие, чтобы облегчить нам жизнь в будущем, мы условимся, что все файлы и их клоны будут иметь одинаковое имя (хотя, скорее всего, разные расширения). Вот пример того, что у меня получилось. Две папки:
/small-videos /original-videos FILE0001.mp4 FILE0001.MOV FILE0002.mp4 FILE0002.MOV FILE0003.mp4 FILE0003.MOV ... ...
Таким образом, потом можно по имени программно заменить копии на их оригиналы. После этого папка с оригинальными видео отправляются на сервер, а маленькие копии остаются на нашем лаптопе для дальнейшей работы.
Пример оригинального видео и его легковесного клона:
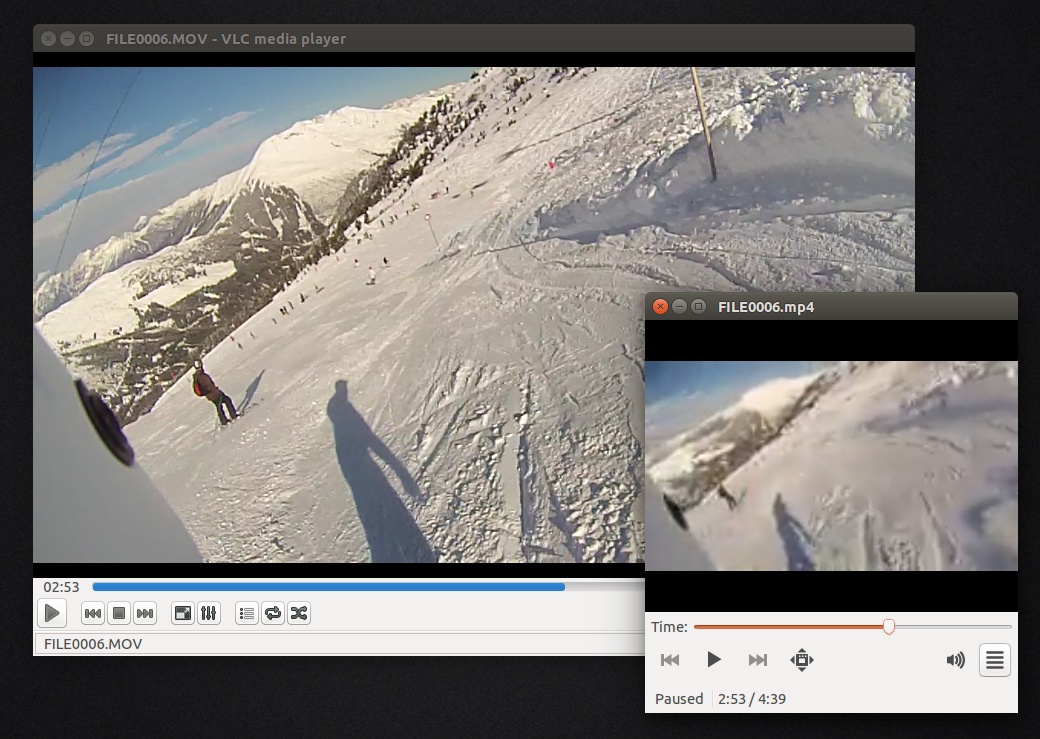
Эмм… не переборщил ли я со сжатием? Всё только ради чистоты эксперимента!
Так, хорошо, начали проект. Качество предпросмотра отвратительное, конечно, но что поделать: мы же хотели избавиться от гнусных лагов, тормозящих всю работу. Продолжая плакать и колоться, монтируем фильм. Пока всё работает шустро, особо не напрягая процессор. Критический момент: настало время сведения. Мы жмём заветную кнопку Generate Script…, сохраняем результат. Теперь разберёмся, что именно только что произошло и что программа вообще сохранила.
В домашней папке KDEnlive (по умолчанию это ~/kdenlive/scripts/) появилось два файла:
- shell скрипт my-movie_001.sh
- и файл my-movie_001.sh.mlt
Shell-файл my-movie_001.sh имеет короткий набор команд:
#! /bin/sh
SOURCE="/home/w32blaster/kdenlive/scripts/my-movie_001.sh.mlt"
TARGET="/home/w32blaster/kdenlive/my-movie.mp4"
RENDERER="/usr/bin/kdenlive_render"
MELT="/usr/bin/melt"
PARAMETERS="-pid:8613 $MELT hdv_1080_50i avformat - $SOURCE $TARGET properties=x264-medium g=120 crf=20 ab=160k threads=1 real_time=-1"
$RENDERER $PARAMETERS
Особой уличной магии тут нет: он просто хранит в себе пути и настройки, а потом запускает рендер с необходимыми параметрами. При желании их можно редактировать, но обратить внимания стоит на один параметр — «threads=1», который, как нетрудно догадаться, устанавливает количество потоков. В зависимости от мощности процессора, это число можно увеличить, значительно повысив производительность рендеринга. Тем более, мы же собираемся запустить его на более мощном компьютере, не нагружая наш лаптоп.
Но особый интерес для этого эксперимента всё же представляет другой файл, который помечен многозначительным объявлением
SOURCE="/home/w32blaster/kdenlive/scripts/my-movie_001.sh.mlt"
Что за MLT файл такой?

Оказывается (по крайней мере, для меня), в мире открытого программного обеспечения существует такой формат для передачи видео-трансляций, а также одноимённый фреймворк, называемый MLT. На сайте сказано, что это:
MLT is an open source multimedia framework, designed and developed for television broadcasting. It provides a toolkit for broadcasters, video editors, media players, transcoders, web streamers and many more types of applications. The functionality of the system is provided via an assortment of ready to use tools, XML authoring components, and an extensible plug-in based API.
С помощью консольной программы melt, можно сводить видеопроекты прямо в консоли. То есть в теории, можно даже сделать целый фильм, не выходя из консоли. Просто для этого нужно написать и запустить километровую команду, что большинство делать, конечно же, не любит. Вместо этого весь проект описывается специальным форматом MLT, который основан на вездесущем XML. Таким образом, рендеринг видео — это запуск консольной программы melt, которой скармливают как параметры будущего фильма, так и сам проект в MLT формате. Сам же MLT файл генерируется GUI программой. В моём случае, как я уже упоминал, это была KDenlive, с которой кстати поставляется melt в качестве зависимости. Подробнее об использовании этой утилиты в офф.доках.
Теперь давайте глянем на структуру самого MLT файла, сгенерированного из нашего фильма:
Videos/small/FILE0001.mp4
... тут идут параметры видео-исходника
... параметры фильтра ...
1
1
2
transition
mix
1
1
237
.... много-много переходов, наложений и прочих параметров ....
Несмотря на объём и кажущуюся сумбурность, этот файл имеет довольно простую структуру:
- mlt — главный тэг, который объявляет, что это не что иное, как описание видео в mlt-формате. Так же первыми объявляются параметры проекта, которые удалены из примера для простоты.
- producer — это объект, являющийся исходником картинки. Это может быть видео, музыка, изображение, просто цветовая заливка, титры и даже другой mlt-файл (об этом чуть ниже). Внутри имеется много параметров, и в случае работы с файлами, важным является путь к ресурсу. Для каждого ресурса, который добавлен в наш проект, генерируется отдельный «продюсер».
- playlist — плейлист, который состоит из всех «продюсеров». Тут же могут быть фильтры (в примере выше, это фильтр затухания звука). Для каждого ресурса указываем какой именно отрезок следует вставить. То есть когда мы обрезаем у ролика края на timeline, то на уровне формата MLT мы просто устанавливаем параметры in и out у тэга entry. Ну, и сам тэг entry имеет ссылку на «продюсер».
- tractor — собственно, это и есть весь наш фильм, или timeline, как его ещё принято называть. То, что официально называется нелинейным монтажом, когда мы изменяем порядок и перетаскиваем видео-ролики между собой на трекере — всё это описывается тут. Все переходы, наложения, титры и всё-всё-всё описывается именно тэгом «tractor».
Подробнее о структуре mlt-файла тут.
Итак, мы сгенерировали первый mlt-файл, который будет содержать структуру самого фильма, составленного из сжатых видео-клонов. Каждый раз, когда мы будем готовы рендерить фильм, мы будем генерировать этот файл со структурой. Вроде разобрались с тем, как проект получается на стороне клиента (т.е. на лаптопе), теперь нужно разобраться, как с этим работать на сервере перед собственно самим рендерингом. План состоит в том, чтобы перед началом сборки заменить все «продюсеры» в mlt-файле с маленькими видео на точно такие же, но с оригинальными и уж потом запускать сведение. В идеале, никто не заметит подмены.
Для этой операции нужно узнать, какие именно маленькие файлы соответствуют большим оригиналам. Проблема осложняется ещё и тем, что у «продюсера» используются технические данные видео ролика. Вот пример одного из них:
producer
1328
pause
Videos/Austria2015-small/FILE1235.mp4
2
video
30
0
160
90
90000
yuv420p
0
709
1
h264
H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10
52987
audio
fltp
48000
2
aac
AAC (Advanced Audio Coding)
163117
eng
mp42
512
isomiso2avc1
HandBrake 0.10.1 2015030800
1
1
1
1
1
0
avformat
30
1
709
160
90
0
1
1
Не плохо так, да? Нужно как-то заменить все эти параметры ресурса и желательно не вручную. Проблема осложняется ещё и тем, что для mlt нет схемы, таким образом программно трудно проверить корректность файла. Рискнём и постараемся обойтись без схемы.
Как будем замещать мета-данные клонов оригинальными (которые, естественно, будут разными, поскольку сами видео разные)? К счастью, melt достаточно умён, чтобы самому сделать корректный mlt, который он сам же потом и будет потреблять. Когда мы запускаем рендеринг с помощью команды melt нам нужно указать источники данных («producer», как показано выше) и потребителя, куда поток перенаправляется («consumer»). Потребитель бывает разный, все варианты можно посмотреть тут или же набрав команду из консоли:
$ melt -query "consumers"
---
consumers:
- decklink
- xgl
- qglsl
- sdl
- sdl_audio
- sdl_preview
- sdl_still
- cbrts
- xml
- sdi
- jack
- avformat
- multi
- null
- gtk2_preview
- blipflash
- rtaudio
...
Как видно, перенаправить вывод рендеринга можно во что угодно. Например, во время обычного рендеринга в файл используется avformat. Всё, что мы смонтируем, сохранится в один файл. В качестве второго примера, возможно направить вывод сразу же в stdout, используя команду:
$ melt original.mlt -consumer libdv
Тогда откроется окно с проигрыванием видео и melt будет сводить фильм, одновременно перенаправляя его на лету в открывшееся окно.
Но если указать в качестве потребителя «xml», а источником указать видео-файлы, то melt перечислит все файлы и их технические параметры и выведет весь контент в XML-формате в красиво оформленный MLT-файл. Вот пример команды:
$ melt *.MOV -consumer xml:original.mlt
Она сгенерирует MLT-файл, содержащий только лишь «продюсеры» на видеофайлы в данной директории с разрешением MOV. Естественно, с корректными мета-данными оригинальных (больших) видеофайлов. Так именно это и нужно для нашего коварного плана! Итак:
- Мы знаем, где на сервере лежат оригиналы.
- На основе этих оригиналов мы генерируем в командной строке MLT-файл, который содержит только одни «продюсеры» с оригинальными видео и их мета-данными. Назовём его original.mlt. В этом файле нет описания фильма (то есть тэга tractor), только одни исходники. Мы его будем использовать как источник т.н. правильных «продюсеров».
- Мы перекидываем с лаптопа на сервер текущий MLT-файл, который содержит наш фильм с актуальными изменениями, но с «подпорченными» маленькими копиями. Назовём его small.mlt
- Помятуя о том, что оригиналы и копии имеют одинаковые имена (но, возможно, разные расширения), мы можем сопоставить «правильные» продюсеры из первого MLT файла с «обрезанными» из второго MLT файла
- Нужно заменить не только сами продюсеры, но и их ID, поскольку они наверняка будут разными.
- Можно приступать к сведению.
В результате каждый продюсер наподобие такого:
Videos/small/FILE1234.mp4
... его мета-данные
должен быть замещён продюсером подобным этому:
Videos/original/FILE1234.MOV
... его мета-данные
Для того, чтобы совершить эту операцию, я набросал небольшой питоновский скрипт с тестом. На самом деле, я — приверженец Джавы, так что это мой первый код на Питоне. Если после прочтения вы посчитаете, что мои кривые руки нужно таки выпрямить, то ваши мысли и предложения приветствуются в виде пулл-реквеста.
#!/usr/bin/env python
import xml.etree.ElementTree as ET
import os.path
import sys, getopt
def main(argv):
'''
The main purpose of this programm is to take the given MLT file containing
producers with an compressed ("small") resources (video, images, sound) and
replace them with identical producers with uncompressed ("original") resources
from another MLT file
Example of usage:
python process.py -s ~/Videos/small.sh.mlt -p ~/Videos/original/original.mlt
'''
smallVideosFile, originalVideosFile, homeDir = _extractCLArguments(argv)
if (smallVideosFile == '' or originalVideosFile == ''):
print "Error. Both arguments -s and -p must be provided!"
sys.exit(2)
print "Start MLT file processor. We will modify %s using data from %s" % (smallVideosFile, originalVideosFile)
# Parse the MLT file with small resources
smallTree = ET.parse(smallVideosFile)
smallTreeRoot = smallTree.getroot()
# and MLT file with original (big, full size) resources
originalTree = ET.parse(originalVideosFile)
originalTreeRoot = originalTree.getroot()
# prepare maps "video file name" <==> "producer ID"
mapSmallProducers = _getMapOfProducerIds(smallTreeRoot)
mapOriginalProducers = _getMapOfProducerIds(originalTreeRoot)
# build map "small producer ID" <==> "original producer ID", having the same video resource
mapID = _mergeMaps(mapSmallProducers, mapOriginalProducers)
# update 'root' value in MLT tag
_updateRootTag(homeDir, smallTreeRoot)
# then replace all the producers containing small videos with those with original videos
_replaceAllSmallProducersWithOriginal(mapOriginalProducers, smallTreeRoot, originalTreeRoot)
# print modified MLT to output file
ET.ElementTree(smallTreeRoot).write(smallVideosFile, encoding='utf-8', xml_declaration=True)
def _extractResourceName(fullName):
'''
Extracts only the resource name from full path. For example,
if the fullName is Videos/small/FILE1114.mkv this method returns FILE1114
'''
if "?" in fullName:
withoutParam = fullName.split("?",1)[0]
return os.path.splitext(os.path.basename(withoutParam))[0]
else:
return os.path.splitext(os.path.basename(fullName))[0]
def _mergeMaps(mapSmallProducers, mapOriginalProducers):
'''
Builds map of producer IDs: each small producer's ID should
match appropriate big producer's ID, having the same resource.
'''
mapID = {}
for fileName, oldProducerId in mapSmallProducers.items():
if (fileName in mapOriginalProducers):
mapID[oldProducerId] = mapOriginalProducers[fileName]
return mapID
def _getMapOfProducerIds(tree):
'''
Builds the map for the given file: "resource (video file name)" <=> "producer ID".
'''
arrProducers = tree.findall('producer')
# Collect the map "resourse (video file name)" <==> "id of the producer"
mapIdToResource = {}
for producer in arrProducers:
resourceType = producer.find("*[@name='mlt_service']").text
isReplacementNeeded = (resourceType == "avformat" or resourceType == "framebuffer" or resourceType == "xml")
if (isReplacementNeeded):
resourceValue = producer.find("*[@name='resource']").text
# extract only filename (without path and extension)
fileName = _extractResourceName(resourceValue)
mapIdToResource[fileName] = producer.attrib.get('id')
else:
print "[Ignored] the producer %s (resource type is %s) is ignored" % (producer.attrib.get('id'), resourceType)
pass
return mapIdToResource
def _replaceAllSmallProducersWithOriginal(mapOriginalProducers, rootToBeModified, rootOriginal):
'''
Replaces all DOM-element 'Producer' containing small resources with
identical producers, containing the original resource
'''
print "Replace old producer having small size with another one having original resource:"
arrSmallProducers = rootToBeModified.findall('producer')
for producer in arrSmallProducers:
resourceType = producer.find("*[@name='mlt_service']").text
if (resourceType == "avformat"):
_replaceProducerAvformat(producer, mapOriginalProducers, rootToBeModified, rootOriginal)
elif (resourceType == "framebuffer"):
_replaceProducerFramebuffer(producer, mapOriginalProducers, rootToBeModified, rootOriginal)
elif (resourceType == "xml"):
_replaceProducerXml(producer, mapOriginalProducers, rootToBeModified, rootOriginal)
def _replaceProducerAvformat(producer, mapOriginalProducers, rootToBeModified, rootOriginal):
'''
Replace entirely one producer, containing small resource
with similar producer from original tree. Resulting producer
should have the same ID, but it must get all the
values from original tree (URLs, codec properties and other technical
information)
'''
resourceValue = producer.find("*[@name='resource']").text
fileName = _extractResourceName(resourceValue)
if(fileName in mapOriginalProducers):
# remember in, out and length from small producer
attrIn = producer.attrib.get('in')
attrOut = producer.attrib.get('out')
length = producer.find("*[@name='length']").text
producerId = producer.attrib.get('id')
originalId = mapOriginalProducers[fileName]
origProducer = rootOriginal.find('.//producer[@id="' + originalId + '"]')
if origProducer is not None:
rootToBeModified.remove(producer)
# do not touch original node, deal with clone instead
origProducerClone = origProducer.copy()
# update in, out and length to match with small producer
origProducerClone.set('in', attrIn)
origProducerClone.set('out', attrOut)
origProducerClone.set('id', producerId)
origProducerClone.find("*[@name='length']").text = length
rootToBeModified.insert(1, origProducerClone)
print " - Avformat resource (id=%s) is replaced with resource (id=%s)" % (producerId, originalId)
else:
print " - [Ignored] Avformat resource (id=%s) was not found. File name is '%s' and found original ID is '%s'" % (producerId, fileName, originalId)
def _replaceProducerFramebuffer(producer, mapOriginalProducers, rootToBeModified, rootOriginal):
'''
Update given producer's resource. The resulting
producer should have the same properties except resource path.
Keep in mind, that we need to keep the parameter after "?" sign.
'''
resourceNode = producer.find("*[@name='resource']")
resourceValue = resourceNode.text
producerId = producer.attrib.get('id')
fileName = _extractResourceName(resourceValue)
if(fileName in mapOriginalProducers):
originalId = mapOriginalProducers[fileName]
origProducer = rootOriginal.find('.//producer[@id="' + originalId + '"]')
if origProducer is not None:
originalResourcePath = origProducer.find("*[@name='resource']").text
extension = resourceValue.split("?",1)[1]
resourceNode.text = originalResourcePath + "?" + extension
print " - Framebuffer resource (id=%s) is replaced with resource (id=%s)" % (producerId, originalId)
else:
print " - [Ignored] the Framebuffer resource (id=%s) is ignored!" % (producerId)
def _replaceProducerXml(producer, mapOriginalProducers, rootToBeModified, rootOriginal):
'''
Update given producer in case if it is XML resource.
The resulting producer should have updated resource path
including .mlt extension.
'''
resourceNode = producer.find("*[@name='resource']")
resourceValue = resourceNode.text[:-4] # trim .mlt extension
producerId = producer.attrib.get('id')
fileName = _extractResourceName(resourceValue)
if(fileName in mapOriginalProducers):
originalId = mapOriginalProducers[fileName]
origProducer = rootOriginal.find('.//producer[@id="' + originalId + '"]')
if origProducer is not None:
originalResourcePath = origProducer.find("*[@name='resource']").text
resourceNode.text = originalResourcePath + ".mlt"
print " - XML resource (id=%s) is replaced with resource (id=%s)" % (producerId, originalId)
def _updateRootTag(homedir, rootToBeModified):
'''
In order to find all the resources, MLT uses the arggument "root"
placed in tag MLT. When we work on different computers, we must also
update this value in order MELT would be able to find resources.
'''
if (homedir != ''):
rootToBeModified.set('root', homedir)
def _extractCLArguments(argv):
inputfile = ''
outputfile = ''
homedir = ''
try:
opts, args = getopt.getopt(argv,"hs:p:u:",["smallfile=","producersfile=", "userhomedir="])
except getopt.GetoptError:
print 'process.py -s -p '
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print '''process.py -s -p -u
where "smallFile" is a mlt file to be modified
and "producersFile" is a mlt file containing the list of producers
with original resources.
'''
sys.exit()
elif opt in ("-s", "--smallfile"):
inputfile = arg
elif opt in ("-p", "--producersfile"):
outputfile = arg
elif opt in ("-u", "--userhomedir"):
homedir = arg
return inputfile, outputfile, homedir
if __name__ == "__main__":
main(sys.argv[1:])
Запускать этот скрипт вот такой командой:
# python process.py -s small.mlt -p original.mlt
которая скажет «возьми все продюсеры из файла original.mlt и замени их на соответсвующие в файле small.mlt, но остальное не трогай».
Ну что же, теперь пора попробовать собрать проект удалённо. Как полагается в линуксе, создадим на серверной стороне понятный и простой shell-скрипт, …
#!/bin/bash
SMALL_RESORCES="Small"
ORIGINAL_RESOURCES="Original"
KDENLIVE_SCRIPT="austria-2015_001.sh"
PY_SCRIPT="/home/ilya/home-workspace/mlt-producer-replacer/process.py"
CURRENT_DIR="/home/ilya/Videos/MltProcessor"
rm log
echo -e "\n\n Step 1. Rename all the .mp4.mlt resources to .MOV.mlt"
rm $ORIGINAL_RESOURCES/*.MOV.mlt
for file in $ORIGINAL_RESOURCES/*.mlt; do
cp "$file" "$ORIGINAL_RESOURCES/`basename $file .mp4.mlt`.MOV.mlt"
done
echo -e "\n\n Step 2. Generate fresh list of producers with original sources"
rm $CURRENT_DIR/original.mlt
cd ~
melt $CURRENT_DIR/$ORIGINAL_RESOURCES/*.{MOV,mp3} -consumer xml:original.mlt
cd $CURRENT_DIR
mv ~/original.mlt $CURRENT_DIR
echo -e "\n\n Step 3. Update MLT and replace small videos with original ones"
# process the main MLT file
cp $KDENLIVE_SCRIPT.mlt $KDENLIVE_SCRIPT.mlt-BACKUP
python $PY_SCRIPT -s $KDENLIVE_SCRIPT.mlt -p $CURRENT_DIR/original.mlt -u $HOME
echo -e "\n\n Step 4. Update additional MLT files"
# process other MLT resources, that are producers with type=xml
for i in $ORIGINAL_RESOURCES/*.MOV.mlt; do
python $PY_SCRIPT -s $i -p $CURRENT_DIR/original.mlt -u $HOME
done
echo -e "\n\n Step 5. Run rendering"
./$KDENLIVE_SCRIPT
echo -e "\n\n Step 6. Make it smaller"
HandBrakeCLI -i austria.mp4 -o austria.small.m4v --preset="Universal"
echo "FINISHED" >> log
… который делает всё, что нам нужно: генерирует свежий MLT из оригиналов, запускает питоновский скрипт по замещению исходников и запускает рендеринг. В конце можно воткнуть оповещение по емайлу или СМС.
Примечание. Хотелось бы прокомментировать небольшую тонкость, которая описана в Step 1 и Step 4 в приведённом выше скрипте. Как я уже упоминал выше, помимо видео и картинок в качестве исходников могут выступать также и другие mlt файлы. С такой ситуацией вы можете столкнуться, если воспользоваться одной из т.н. Clip Job. Допустим, вы хотите проиграть клип задом наперёд.
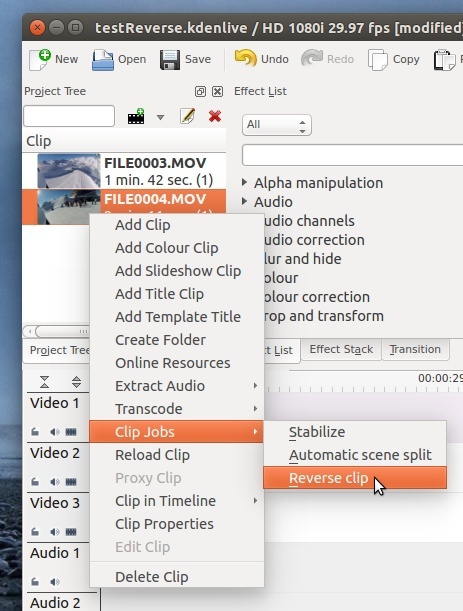
В таком случае будет создан отдельный файл, который будет содержать всего один продюсер, с наложенными на видеоролик фильтрами. Называться этот файл будет {fileName}.{extension}.mlt. Использоваться в проекте он будет примерно так:
producer
Videos/MltProcessor/Original/IMG_3764.MOV.mlt
xml
....
Поскольку у нас оригиналы и копии могут иметь разные расширения, то нам в Step 1 следует переименовать их, чтобы melt смог корректно найти эти ролики. Скажем, файл IMG_3764.mp4.mlt должен быть переименован в IMG_3764.MOV.mlt. Ну и в завершение нам нужно их обработать нашим питоновским скриптом на шаге Step 4 точно так же, как мы обработали наш основной mlt.
Теперь суммируем, как создание фильма выглядит с самого начала и до конца.
- Мы собираем все исходники (можно даже и музыку), создаём уменьшенные клоны.
- Создаём новый проект в GUI программе типа Kdenlive, добавляем в него все клоны.
- Несмотря на то, что проект ещё не готов, жмём на Generate file, чтобы сгенерировать shell-скрипт. По желанию, можно установить число threads в параметрах. Больше этот файл меняться не будет.
- Закидывам на сервер оригиналы видео, питоновский скрипт и shell-скрипт из предыдущего пункта.
- Начинаем монтаж фильма. Когда готовы свести фильм и посмотреть его в полном качестве, рендерим заново свежий файл mlt.
- Закидываем только один этот файл на сервер и запускаем самописный shell-скрипт (Листинг 2).
Естественно, во время монтажа мы можем рендерить фильм бесчисленное количество раз, так что каждый раз нам нужно отправлять на сервер всего лишь один файл mlt и продолжать работу на лаптопе. Всё остальное будет оставаться неизменным. Но главная фишка в том, что запустив рендеринг, мы можем без труда заняться своими делами, продолжить монтаж или пойти спать, выключив лаптоп, так как процесс будет запущен на удалённом сервере.
В итоге, снова напишем совсем небольшой скрипт, который будем запускать каждый раз с лаптопа:
#!/bin/bash
SERVER_HOSTNAME="10.20.30.40"
USERNAME="ilya"
REMOTE_PROJECT_DIR="/home/ilya/Videos/MltProcessor"
REMOTE_ORIGINAL_DIR="/home/ilya/Videos/MltProcessor/Original"
LOCAL_MLT="/home/w32blaster/kdenlive/scripts/austria-2015_001.sh.mlt"
LOCAL_SOURCES_DIR="/home/w32blaster/Videos/Austria2015-small"
# 1. Upload main MLT file
scp $LOCAL_MLT $USERNAME@$SERVER_HOSTNAME:$REMOTE_PROJECT_DIR
# 2. Upload all others MLT files, that represents producer sources
scp $LOCAL_SOURCES_DIR/*.mlt $USERNAME@$SERVER_HOSTNAME:$REMOTE_ORIGINAL_DIR
# 3. Execute rendering on the remote server
ssh $USERNAME@$SERVER_HOSTNAME "$REMOVE_PROJECT_DIR/run.sh"
Конечно, можно автоматизировать и это, например, синхронизировать наш MLT-файл через облачное хранилище и на сервере мониторить, когда файл изменится, после чего автоматически запускать рендеринг, и прочее, и прочее, но я предлагаю читателю заняться этим увлекательным делом уже самостоятельно.
Конечно, на этой основе пока рано начинать свой стартап, придумывать броское название и рисовать логотип с усами-очками. В этом случае я всего лишь попытался воплотить саму идею процесса. Такой способ пока не для общего пользования, а скорее для гиков увлекающихся, потому что нужно сделать слишком много телодвижений, чтобы настроить систему на совместную работу. К тому же для «свободного художника» интерфейс Kdenlive окажется не настолько эстетичным и интуитивным, как у того же iMovie. Но субъективно могу сказать, что процесс создания ролика стал заметно быстрее, особенно если используется большое количество отснятого исходного материала.
Немного мыслей.
- Вполне возможно, что данный метод работает не со всеми фильтрами Kdenlive, у меня не было возможность протестировать всё
- Желательно иметь физический доступ к серверу, потому что перекинуть на него все оригиналы в высоком качестве по сети со средним каналом будет долго. Идеальный вариант: перекинуть видео файлы с помощью флешки или переноски.
- И да, если вы считаете, что я сам придумал проблему и сам же её решил, то в оправдание могу сказать, что я нашёл отличный предлог, чтобы наконец-то ознакомиться с Питоном, чему весьма рад :)
Всем хороших выходных! А тем, кто уже парафинит скользяк, точит канты и мечтает о сугробах — удачного катания в будущем сезоне!
