Дайджест статей машинного обучения и искусственного интеллекта
Хабр, привет.
Отфильтровав большое количество статей, конференций и подписок — собрал для вас все наиболее значимые гайды, статьи и лайфхаки из мира машинного обучения и искусственного интеллекта. Всем приятного чтения!
1. Проекты искусственного интеллекта, с которыми можно поиграться уже сегодня. Что вы знаете про искусственный интеллект и машинное обучение? Современный тренд или потенциально мощная сила, способная убивать людей? Эти модные понятия всё чаще на слуху, но далеко не все знают, что же это на самом деле. Пришло время изучить эти технологии с помощью простого и интересного подхода — попробовать искусственный интеллект и нейросети самостоятельно на практике.
→ Подробнее
2. Изучение ИИ, если ты сосешь в математике. Может быть, вы хотели бы копать глубже и запустить программу распознавания изображений в TensorFlow или Theano? Возможно, вы офигительный разработчик или системный архитектор и вы очень хорошо знаете компьютеры, но есть только одна маленькая проблема: Вы сосете в математике.

→ Подробнее
3. Как построить систему модерации сообщений. Системы автоматической модерации обычно встроены в веб-сервисы и приложения, где должно обрабатываться большое количество пользовательских сообщений. Такие системы могут снизить затраты на ручную модерацию и ускорить модерацию, обрабатывая все пользовательские сообщения в режиме реального времени. В этой статье будет обсуждаться разработка системы автоматической модерации с использованием алгоритмов машинного обучения.
→ Подробнее
4. Список инструментов искусственного интеллекта, которые вы можете использовать сегодня — для личного пользования (⅓). За несколько недель я пролистал буквально тысячи сайтов (более 6000 ссылок), чтобы представить вам полный список лучших продуктов ИИ и наиболее перспективных компаний в этой области.

→ Подробнее
5. Список инструментов искусственного интеллекта, которые вы можете использовать сегодня — для бизнеса (2/3). В этот список входят компании, работающие над продуктами для искусственного интеллекта и машинного обучения, в основном для бизнес-целей, не характерные для какой-либо отрасли.

→ Подробнее
6. Список инструментов искусственного интеллекта, которые вы можете использовать сегодня — для бизнеса (2/3). При создании целостного списка, я обнаружил, что он стал слишком длинным и запутанным, поэтому я решил, что будет проще разбить весь список на 2 части, для удобства восприятия.

→ Подробнее
7. Список инструментов искусственного интеллекта, которые вы можете использовать сегодня — для конкретной отрасли (3/3). Последний фрагмент головоломки — часть 3. Вот взгляд на отраслевые компании, которые используют различные формы искусственного интеллекта для решения действительно интересных и специфических задач для разных рынков.

→ Подробнее
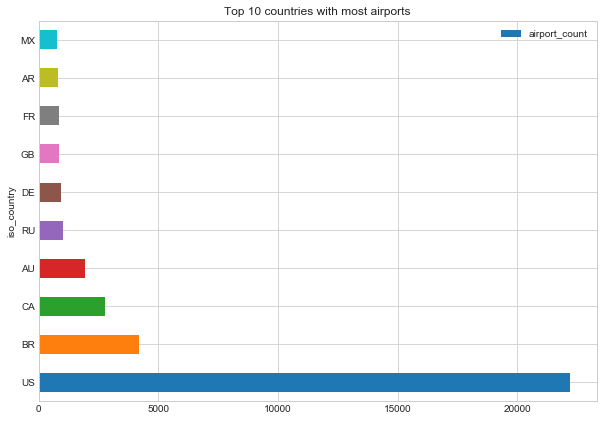
8. Работа с данными по-новому: Pandas вместо SQL. Раньше SQL как инструмента было достаточно для исследовательского анализа: быстрого поиска данных и предварительного отчёта по ним. Сейчас данные бывают разных форм и не всегда под ними подразумевают «реляционные базы данных». Это могут быть CSV-файлы, простой текст, Parquet, HDF5 и многое другое. Здесь вам и поможет библиотека Pandas.
→ Подробнее
9. Лучшие датасеты для машинного обучения и анализа данных. Для анализа данных и машинного обучения требуется много данных. Можно было бы собрать их самостоятельно, но это утомительно. Здесь нам на помощь приходят готовые датасеты в самых разных категориях.

→ Подробнее
10. Здравоохранение и блокчейн — интеллектуальные контракты, страхование и цепочки поставок. Всё с намеком на AI. К этому пришли умные контракты, программируемые операторы if/then, которые можно было бы реализовать в сети блокчейна. Это позволит быстро и эффективно рассчитывать и выполнять решения с сохраненными данными без необходимости человеческой обработки.

→ Подробнее
11. Как разработать отличные навыки для голосовых помощников в 2019 году. Примите правильные методики, чтобы начать разработку своего следующего навыка, рассмотрев несколько ключевых элементов голосовых интерфейсов и пользовательского опыта.
→ Подробнее
12. Почему, когда и как использовать многопоточность и многопроцессорность Python. Цель этого руководства — объяснить, почему в Python необходимы многопоточность и многопроцессорность, когда использовать один поверх другого и как использовать их в своих программах.

→ Подробнее
13. Сквозная модель анализа и прогнозирования данных с использованием Python в табличных данных SAP HANA. Этот блог помогает подключиться к базе данных SAP HANA (версия 1.0 SPS12), а затем извлечь данные из таблицы HANA / просмотреть и проанализировать данные с помощью библиотеки Python Pandas.
→ Подробнее
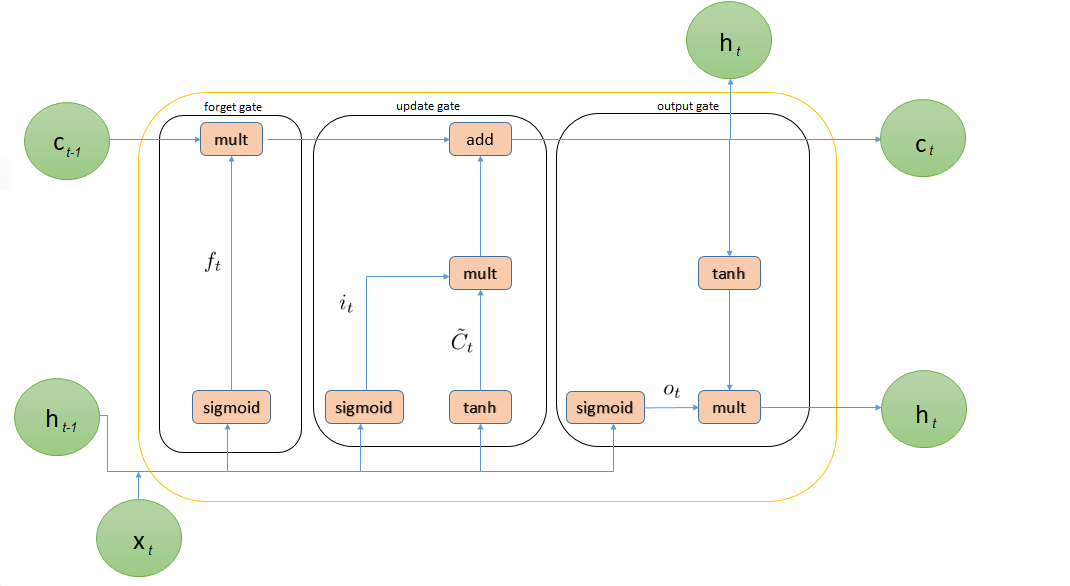
14. Демистификация архитектуры сетей с кратковременной памятью (LSTM). Мы используем долговременную оперативную память (LSTM) и Gated Recurrent Unit (GRU), которые являются очень эффективными решениями для решения проблемы исчезающего градиента, и они позволяют нейронной сети захватывать гораздо более дальние зависимости.
→ Подробнее
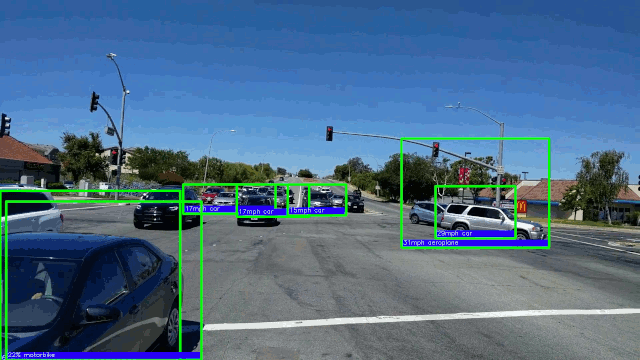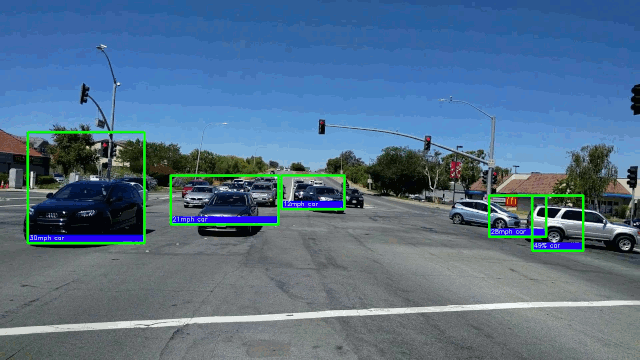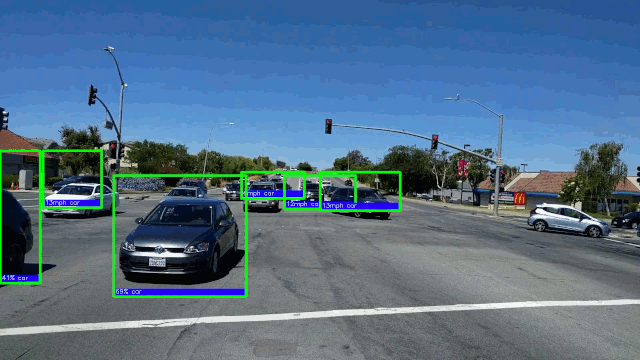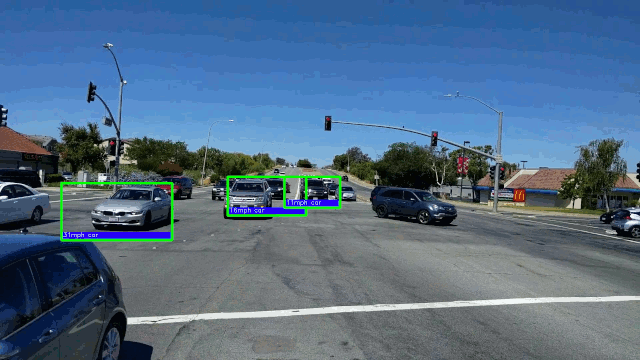
15. Обнаружение автомобиля в режиме реального времени с частотой 50 кадров в секунду на графическом процессоре AMD. Здесь мы фокусируемся на моделях обнаружения объектов глубокого обучения из-за их превосходной точности.
→ Подробнее
16. Обзор методов классификации в машинном обучении с помощью Scikit-Learn. Для машинного обучения на Python написано очень много библиотек. Сегодня мы рассмотрим одну из самых популярных — Scikit-Learn. Scikit-Learn упрощает процесс создания классификатора и помогает более чётко выделить концепции машинного обучения, реализуя их с помощью понятной, хорошо документированной и надёжной библиотекой.
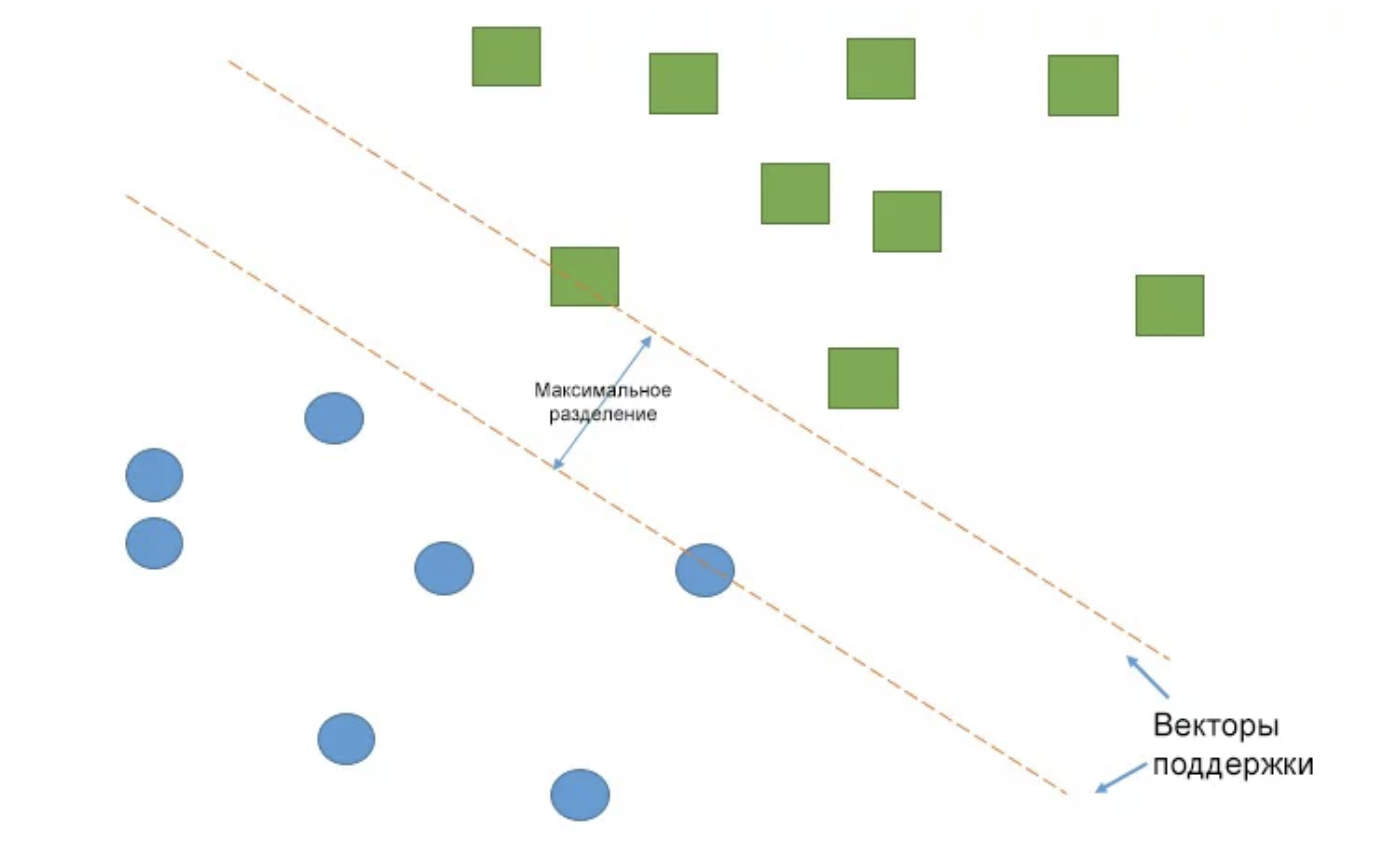
→ Подробнее
17. Введение в форензику. Компьютерная криминалистика (форензика) — прикладная наука о раскрытии преступлений, связанных с компьютерной информацией, об исследовании цифровых доказательств, методах поиска, получения и закрепления таких доказательств.

→ Подробнее
18. Искусственный интеллект на практике: создаём экспертную систему для приготовления шашлыка. Выглядит это примерно так: система задаёт ряд вопросов, причём последующие вопросы зависят от полученных ответов. Затем система делает вывод и показывает всю цепочку рассуждений, которая к нему привела. То есть знания и опыт эксперта тиражируются, а что не менее важно — тиражируется сам ход его рассуждений.

→ Подробнее
19. Реализация и разбор алгоритма «случайный лес» на Python. В этой статье мы научимся создать и использовать алгоритм «случайный лес» (Random Forest) на Python. Помимо непосредственного изучения кода, мы постараемся понять принципы работы модели. Этот алгоритм составлен из множества деревьев решений, поэтому сначала мы разберёмся, как одно такое дерево решает проблему классификации. После этого с помощью алгоритма решим проблему, используя набор реальных научных данных. Весь код, используемый в этой статье, доступен на GitHub в Jupyter Notebook.
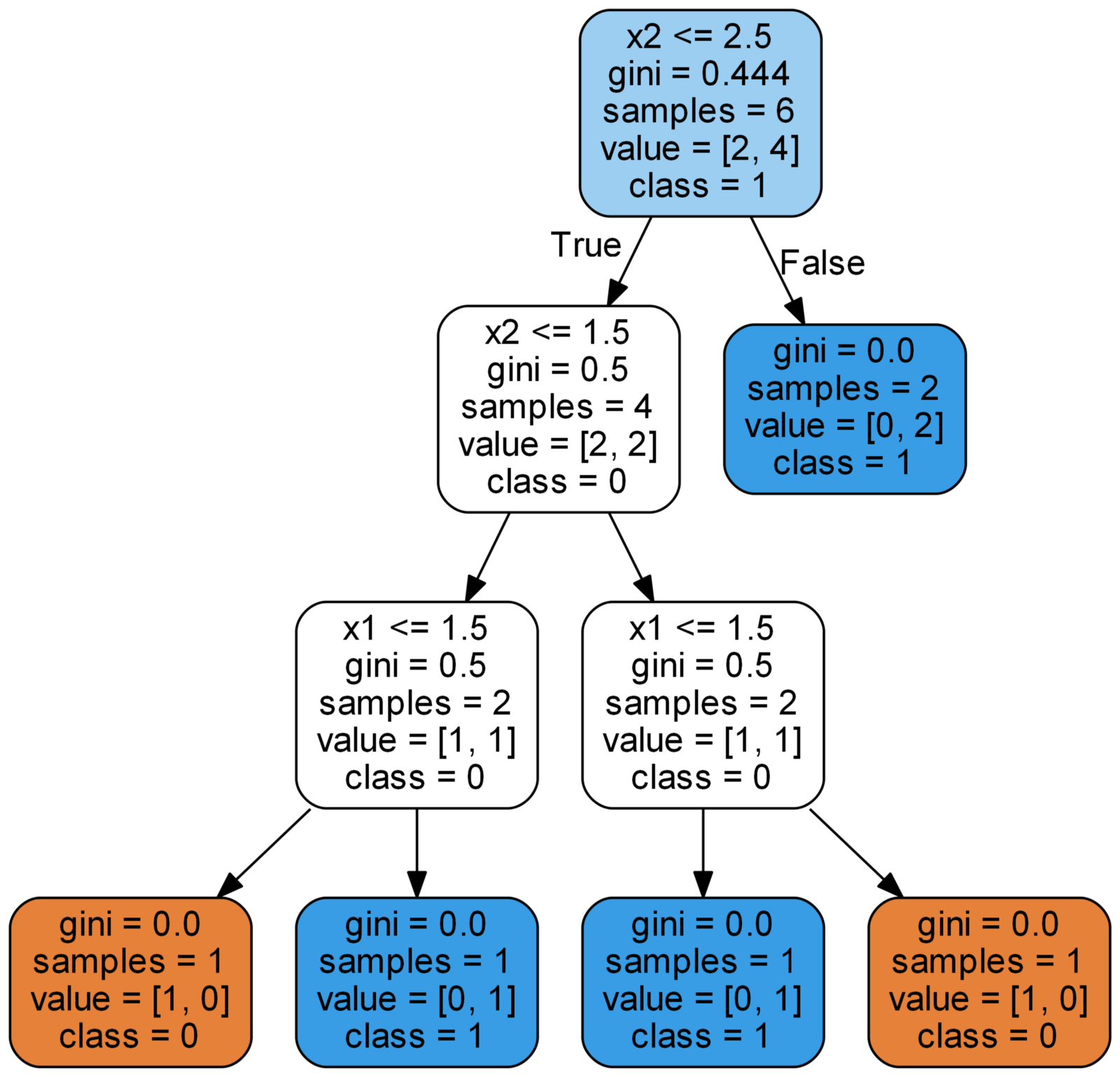
→ Подробнее
20. Human in the Loop: как сократить ресурсы на разметку данных. Использование глубокого обучения и больших размеченных данных дает возможность точно моделировать спектр различных явлений. Разметка данных — ресурсоемкий процесс, и не всегда размеченные данные находятся в открытом доступе.
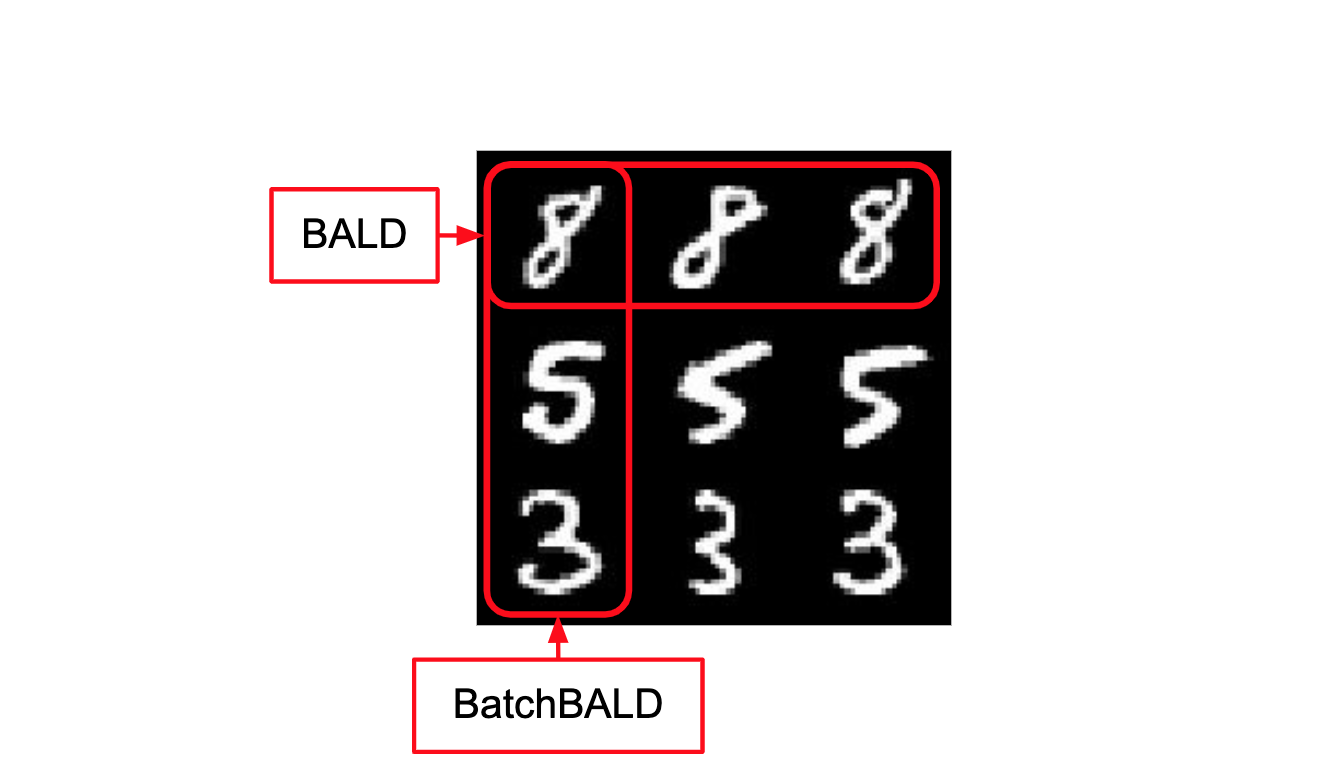
→ Подробнее
21. Симпсоны получили визуализацию данных. Естественно, когда я обнаружил, что могу загрузить все сценарии эпизодов, которые я когда-либо мог хотеть (через kaggle), я знал, что я должен был сделать. Имея доступ ко всему, что когда-либо говорил Гомер, я не удержался от того, чтобы надеть свою шляпу для исследователя данных, чтобы высказать некоторые идеи одного из самых ярких анимационных телевизионных шоу последних трех десятилетий.

→ Подробнее
22. Как новички могут создавать классные визуализации данных? Для аналитиков данных визуализация — это всегда вневременное исследование, поскольку оно раскрывает нам законы, лежащие в основе данных.

→ Подробнее
23. Настройка автоматических оповещений AWS Lambda Data Pipeline.
→ Подробнее
24. Всеобъемлющее современное учебное пособие по распознаванию изображений. Быстрая мультиклассовая классификация изображений с использованием библиотек fastai и PyTorch

→ Подробнее
25. Deep Domain адаптация в компьютерном зрении. За последнее десятилетие область компьютерного зрения достигла огромных успехов. Этот прогресс в основном связан с неоспоримой эффективностью сверточных нейронных сетей (CNN). CNN позволяют делать очень точные прогнозы, если они обучаются с использованием высококачественных аннотированных данных обучения.
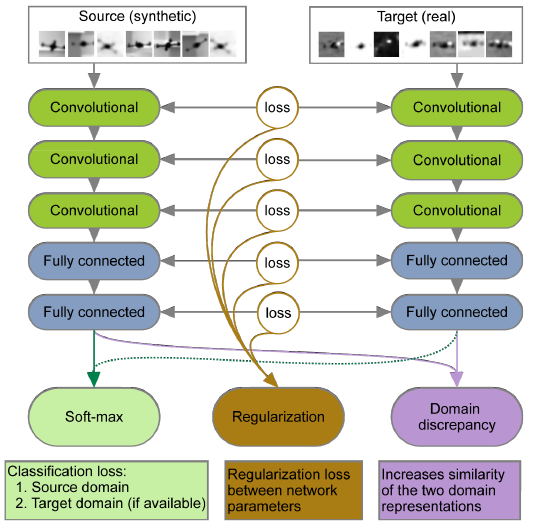
→ Подробнее
26. Оптимизация нейронной сети. Покрытие оптимизаторов, импульс, адаптивные скорости обучения, нормализация партии и многое другое.
→ Подробнее
27. Алгоритмические решения алгоритмического смещения: техническое руководство. Я хочу поговорить о технических подходах к смягчению алгоритмического уклона.
→ Подробнее
28. Наводящий компьютерный дизайн. Содействие дизайну через машинное обучение.

→ Подробнее
29. Генерация набора данных: создание эскизов фотографий с помощью GAN. Данные являются основой наших моделей ML и DL. Мы не можем создавать сильные программы, если у нас нет соответствующего набора данных для обучения алгоритмов.

→ Подробнее
Кто не прочёл мой дайджест новостей за июнь, оставляю ссылку.
На этом наш короткий дайджест подошел к концу. Добавляйте в закладки, делитесь с коллегами, делайте выводы и работайте продуктивно. На постоянной основе этот дайджест выходит в телеграм-канале Нейрон (@neurondata) и подписывайтесь на меня в Хабре, не пропускайте следующих дайджестов.
Всем знаний!
