Жизненный цикл ML в боевых условиях
В реальном внедрении ML само обучение занимает от силы четверть усилий. Остальные три четверти — подготовка данных через боль и бюрократию, сложный деплой часто в закрытом контуре без доступа в интернет, настройка инфраструктуры, тестирование и мониторинг. Документы на сотни листов, ручной режим, конфликты версий моделей, open source и суровый enterprise — все это ждет data scientist«а. Но такие «скучные» вопросы эксплуатации ему не интересны, он хочет разработать алгоритм, добиться высокого качества, отдать и больше не вспоминать.
Возможно, где-то ML внедряется легче, проще, быстрее и одной кнопкой, но мы таких примеров не видели. Все, что выше — опыт компании Front Tier в финтехе и телекоме. О нем на HighLoad++ рассказал Сергей Виноградов — эксперт в архитектуре высоконагруженных систем, в больших хранилищах и тяжелом анализе данных.

Жизненный цикл модели
Обычно жизненный цикл в нашей предметной области состоит из трех частей. В первой от бизнеса поступает задача. Во второй data engineer и/или data scientist готовят данные, строят модель. В третьей части начинается хаос. В последних двух случаются разные интересные ситуации.
Мастер на все руки
Первая частая ситуация — data scientist или data engineer имеет доступ на прод, поэтому ему говорят: «Ты все это сделал, ты и ставь».
Человек берет Jupyter Notebook или пачку notebook, рассматривает их исключительно как артефакт деплоя и начинает радостно тиражировать на каких-то серверах.
Кажется, все хорошо, но не всегда. Позднее расскажу почему.
Беспощадная эксплуатация
Вторая история заковыристее, и обычно случается в компаниях, в которых эксплуатация достигла состояния легкого маразма. Data scientist приносит свое решение в эксплуатацию. Там открывают эту черную коробку и видят нечто ужасное:
- notebooks;
- pickle разных версий;
- ворох скриптов: непонятно где и когда их запускать, где сохранять данные, которые они порождают.
В этом пазле эксплуатация сталкивается с несовместимостью версий. Например, data scientist не указал конкретную версию библиотеки, и эксплуатация взяла последнюю. Спустя время прибегает data scientist:
— Вы поставили scikit-learn не той версии, теперь все метрики поехали! Нужно откатиться на предыдущую версию.
Это полностью ломает прод, и эксплуатация страдает.
Бюрократия
В компаниях с зелёными логотипами, когда data scientist приходит в эксплуатацию и приносит модель, обычно в ответ получает документ на 800 листов: «Следуй этой инструкци, иначе твое изделие никогда не увидит свет».
Грустный data scientist уходит, бросает все на полпути, а потом увольняется — ему не интересно этим заниматься.
Деплой
Предположим, data scientist прошел все круги и в итоге все задеплоил. Но понять, что все работает как надо, он не сможет. По моему опыту в тех же благословенных банках нет мониторинга продуктов data science.
Хорошо, если специалист пишет результаты своей работы в БД. Спустя время он их получит и посмотрит, что происходит внутри. Но так бывает не всегда. Когда бизнес и data scientist просто верят, что все замечательно и отлично работает, это выливается в неудачные кейсы.
МФО
Как-то мы разрабатывали скоринговый движок для одной большой микрофинансовой организации. Они не пускали на прод, а просто взяли от нас каскад моделей, поставили и запустили. Результаты тестирования моделей их удовлетворили. Но спустя 6 месяцев пришли обратно:
— Все плохо. Бизнес не идет, нам все хуже и хуже. Вроде модели отличные, но выдачи падают, фрода и дефолта все больше, а денег меньше. За что мы вам заплатили? Давайте разбираться.
При этом доступ напрямую к модели опять не дают. Месяц выгружали логи, причем шестимесячной давности. Выгрузку мы еще месяц изучали и пришли к выводу, что в какой-то момент IT-подразделение МФО изменило входные данные, и вместо документов в json стали присылать документы в xml. Модель ожидала json, а получала xml, грустила и считала, что данных на входе нет.
Если данных нет, то и оценка происходящего отличается. Без мониторинга этого не обнаружить.
Новая версия, каскад и тесты
Часто мы сталкиваемся с тем, что модель хорошо работает, но зачем-то разработана новая версия. Модель опять же нужно как-то принести, и заново пройти все круги ада. Хорошо, если версии библиотек как в прошлой модели, а если нет — деплой начинается заново…
Иногда перед выводом новой версии в бой, мы хотим ее протестировать — вывести на прод, посмотреть на том же потоке трафика, убедиться, что она хороша. Это снова полная цепочка деплоя. Дополнительно настраиваем системы так, чтобы по этой модели реальной выдачи не происходило, если речь про скоринг, а был только мониторинг и анализ результатов для дальнейшего анализа.
Бывают ситуации, когда используется каскад моделей. Когда результаты работы следующих моделей зависят от предыдущих, как-то между ними надо наладить взаимодействие и где-то опять же все это сохранять.
Как решать такие проблемы?
Часто проблемы решает один человек вручном режиме, особенно в маленьких компаниях. Он знает, как все работает, держит в голове все версии моделей и библиотек, знает, где и какие скрипты работают, какие витрины они строят. Это все прекрасно. Особенно прекрасны истории, которые ручной режим оставляет после себя.
История с наследством. В одном маленьком банке работал добрый человек. Однажды он уехал в южную страну и не вернулся. После него нам досталось наследство: куча кода, который генерирует витрины, на которых работают модельки. Код прекрасный, работает, но мы не знаем точную версию скрипта, который генерирует ту или иную витрину. В бою присутствуют все витрины, и все они запускаются. Два месяца мы потратили на то, чтобы разобрать этот затейливый клубок и как-то структурировать.
В суровом enterprise, люди не хотят заморачиваться всякими Питонами, Юпитерами и пр. Они говорят:
— Давайте купим IBM SPSS, поставим и все будет замечательно. Проблемы с версионированием, с источниками данных, с деплоем там как-то решены.
Такой подход имеет право на существование, но не все могут его себе позволить. В любом случае, это такая качественная зазубренная игла. На нее подсаживаются, а слезть не получается — зазубрины. И стоит это обычно очень дорого.
Open Source — противоположность предыдущего подхода. Разработчики прошерстили интернет, нашли массу Open Source решений, которые в разной степени решают их задачи. Это отличный способ, но для себя мы не нашли решений, которые бы удовлетворяли нашим требованиям 100%.
Поэтому мы выбрали классический вариант — свое решение. Свои костыли, велосипеды, все свое, родное.
Что хотим от своего решения?
Не писать все самостоятельно. Хотим взять компоненты, особенно инфраструктурные, которые хорошо себя зарекомендовали и знакомы эксплуатации в тех учреждениях, с которыми работаем. Мы лишь напишем окружение, которое позволит легко изолировать работу data scientist от работы DevOps.
Обрабатывать данные в двух режимах: как в пакетных — Batch, так и real-time. Наши задачи предусматривают оба режима работы.
Легкости деплоя, причем в закрытом периметре. Во время работы с чувствительными приватными данными, выхода в интернет нет. В это время все должно быстро и аккуратно доезжать до продакшна. Поэтому мы стали смотреть в сторону Gitlab, CI/CD pipeline внутри него и Docker.
Модель — не самоцель. Мы не решаем задачу построения модели, мы решаем бизнес-задачу.
Внутри pipeline должны присутствовать правила и конгломерат моделей с поддержкой версионированности всех компонентов pipeline.
Что подразумевается под pipeline? В России действует ФЗ 115 о противодействии отмыванию доходов и финансированию терроризма. Только оглавление рекомендаций ЦБ занимает 16 экранов. Это простые правила, которые банк может выполнить, если у него есть такие данные, или не может, если данных нет.
Оценка заемщика, финансовых транзакций или другой бизнес-процесс — это поток данных, которые мы обрабатываем. Поток должен пройти через подобного рода правила. Эти правила простым способом описывает аналитик. Он не data scientist, но хорошо знает закон или иные наставления. Аналитик садится и понятным языком описывает проверки для данных.
Строить каскады моделей. Часто возникает ситуация, когда следующая модель использует для своей работы значения, которые получены в предыдущих моделях.
Быстро проверять гипотезы. Повторю предыдущий тезис: data scientist сделал какую-то модель, она крутится в бою и хорошо работает. По какой-то причине специалист придумал решение лучше, но не хочет рушить устоявшийся рабочий процесс. На тот же боевой трафик в боевой системе data scientist вешает новую модель. Она не участвует напрямую в принятии решений, но обслуживает тот же трафик, считает какие-то выводы и эти выводы где-то хранятся.
Легкую возможность переиспользования. Во многих задачах бывают однотипные компоненты, особенно те, что связаны с извлечением фич или правилами. Эти компоненты мы хотим перетаскивать в другие pipelines.
Что решили сделать?
Для начала мы хотим мониторинг. Причем два его вида.
Мониторинг
Технический мониторинг. Если какие-то компоненты pipeline задеплоены, в эксплуатации должны видеть, что происходит с компонентой: как потребляет память, CPU, диск.
Бизнес-мониторинг. Это инструмент data scientist, который позволяет абстрагироваться от технических нюансов реализации. На уровне проектирования, конструирования помогает определять, какие метрики модели должны быть доступны в мониторинге, например, распределение фичей или результаты работы скорингового сервиса.
Data scientist определяет метрики и его не должно волновать, как они попадут в систему мониторинга. Важно лишь, что он определил эти метрики и внешний вид dashboard, на котором отобразятся метрики. Дальше специалист запустил все на продакшн, задеплоил, и спустя время метрики полились в мониторинг. Так data scientist без доступа к проду может видеть, что происходит внутри модели.
Тестирование
Тестировать pipeline на консистентность. Учитывая специфику pipeline, это некий вычислительный граф. Мы хотим понимать, что граф реализуем, можно его обойти и найти из него выход.
У графа есть компоненты — модули. Все модули должны проходить unit и интеграционное тестирование. Процесс должен быть прозрачным и легким для data scientist.
Разработчик описывает модель и тесты сам или с чьей-то помощью. Помещает все в Gitlab, pipeline, настроенный Continuous Integration, поднимает, тестирует, видит результаты. Если все хорошо — идет дальше, нет — начинает заново.
Data scientist сосредоточен на модели и не знает, что под капотом. Для этого ему дается несколько вещей.
- API для интеграции с ядромсамой системы через шину данных — message bus. В данном случае специалисту требуется описать, что идет на вход и что на выход из его модели, точки входа и точки стыка с разными компонентами внутри pipeline.
- После обучения модели появляется артефакт — файл XGBoost или pickle. У data scientist есть executer для работы с артефактами — это он должен интегрировать внутрь компоненты pipeline.
- Легкий и прозрачный API для data scientist для мониторинга работы компонентов pipeline — технический и бизнес мониторинг.
- Простая и прозрачная инфраструктура для интеграции с источниками данных и сохранения результатов работы.
Часто у нас работают модели, и спустя время приходит аудит, который хочет поднять всю историю работы сервиса. Аудит хочет проверить корректность работы, отсутствие фрода с нашей стороны. Нужны простые инструменты, чтобы любой аудитор, который знает SQL, мог залезть в специальное хранилище и посмотреть, как все работало, какие решения принимались и почему.
Мы заложили основу под две важные для нас истории.
Customer Journey. Это возможность использовать механизмы сохранения всей клиентской истории — того, что происходило с клиентом в рамках бизнес-процессов, которые реализованы на этой системе.
У нас могут быть внешние источники данных, например, DMP-платформы. От них мы получаем информацию о поведении человека в сети и в мобильных устройствах. Это может оказывать влияние на LTV его модели и на скоринговые модели. Если заемщик просрочит платеж, мы можем предсказать, что это не злой умысел — просто возникли проблемы. В этом случае к заемщику применяем мягкие методы воздействия. Когда проблемы разрешатся, клиент закроет кредит. Когда он придет в следующий раз, мы будем знать всю его историю. Data scientist достанет наглядную историю из модели и проведет скоринг в лайт-режиме.
Выявление аномалий. Мы постоянно сталкиваемся с очень сложным миром. Например, слабые точки внутри ускоренной оценки МФО могут быть источником автоматического фрода.
Customer Journey — концепция быстрого и легкого доступа к потоку данных, который идет через модель. Модель позволяет легко обнаруживать аномалии, которые характерны фроду в момент его массового возникновения.
Как все устроено?
Не долго думая мы взяли Kafka в качестве Message Bus patch. Это хорошее решение, которое используется у многих наших клиентов, эксплуатация умеет с ним работать.
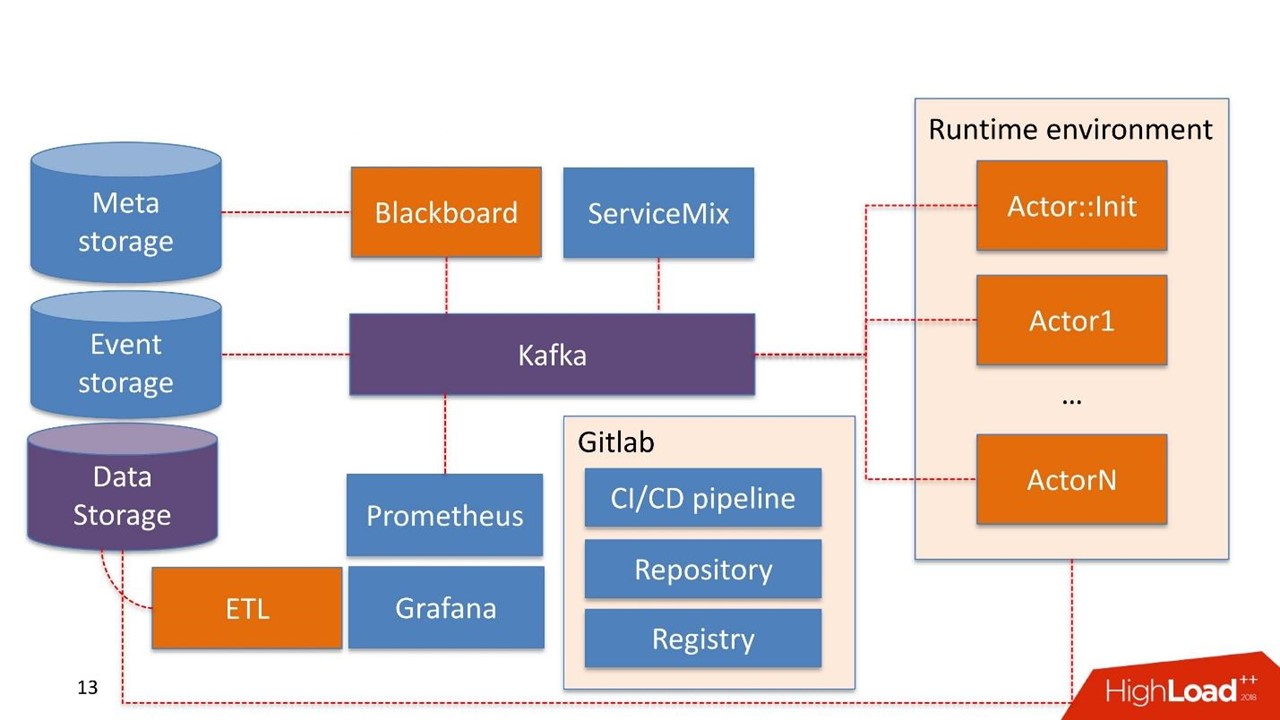
Часть компонентов системы могут уже использоваться в самой компании. Мы не строим систему заново, а переиспользуем то, что у них уже есть.
Data Storage в данном случае это хранилище, которое обычно уже есть у клиента. Это может быть Hadoop, реляционные и нереляционные БД. Мы умеем нативно работать из коробки с HDFS, Hive, Impala, Greenplum и PostgreSQL. Эти хранилища рассматриваем как источник для витрин.
Данные поступают в хранилище, проходят через наш ETL либо ETL заказчика, если он у него существует. Строим витрины, которые дальше используются внутри моделей. Data Storage у нас используется в режиме read-only.
Наши разработки
Blackboard. Название взято из одной довольно странной практики математиков 30–40 годов. Это менеджер pipelines, которые живут в админ-системе. У Blackboard есть некий Meta Storage. В нем сохраняются сами pipelines и конфигурации, которые необходимы для инициализации всех компонентов.
Вся работа системы начинается с Blackboard. Каким-то чудом pipeline оказался в Meta Storage, Blackboard спустя время это понимает, вытаскивает актуальную версию pipeline, инициализирует ее и посылает сигнал внутрь Kafka.
Есть Runtime environment. Он построен на Docker«ах и может быть растиражирован на серверы, в том числе в приватном облаке заказчика.
Из коробки идет основной Actor: Init — это инициализатор. Это джин, который умеет делать только две вещи: строить и разрушать компоненты. Он получает команду от Blackboard: «Вот pipeline, его нужно запустить на таких-то серверах с такими-то ресурсами в таких-то количествах — работай!» Дальше актор все это запускает.
Математически актор — это функция, которая на вход он принимает один или больше объектов, внутри изменяет состояние объектов по некоему алгоритму, на выходе порождает новый объект или изменяет состояние существующего.
Технически актор — программа на Python. Запускается в Docker-контейнере со своим окружением.
Актор не знает о существовании иных акторов. Единственная сущность, которая знает, что кроме актора существует весь pipeline в целом — это Blackboard. Он отслеживает состояние выполнения всех акторов внутри системы и ведет актуальное состояние, которое выражается в мониторинге как картина всего бизнес-процесса в целом.
Actor: Init порождает множество Docker-контейнеров. Кроме этого, акторы умеют работать с Data storage.
В самой системе есть компонента Event Storage. В качестве Event Storage используем ClickHouse. Его задача проста: вся информация, которой обмениваются между собой актор через Kafka, сохраняется в ClickHouse. Делается это для дальнейшего аудита. Это лог работы pipeline.
Также акторы могут быть разработаны для Customer Journey. Они видят изменения лога pipeline, и могут на лету перестраивать витрины, которые нужны для работы моделей или компонентов с правилами, уже внутри pipeline. Это непрерывный процесс изменения данных.
Мониторинг достаточно примитивно построен на Prometheus. Актору дается базовый API, и в закрытом режиме, но достаточно прозрачно для разработчика, он посылает в Kafka сообщения с метриками. Prometheus вычитывает метрики с Kafka и сохраняет в своем хранилище.
Для визуализации используем Grafana.
Две точки интеграции
Первая — точка интеграции с источниками данных, которые проходят через ETL в хранилище данных. Вторая точка интеграции, когда сервис используется уже потребителем данных, например, скоринговым сервисом.
Мы взяли Apache ServiceMix. По опыту эти точки интеграции однотипные с однотипными протоколами: SOAP, RESTful, реже очереди. Каждый раз разрабатывать свой конструктор или сервис, чтобы сгенерировать очередной SOAP-сервис мы не хотим. Поэтому берем ServiceMix, описываем в SDL, в котором сконструированы модели данных этого сервиса и методы, которые в нем существуют. Дальше продавливаем роутером внутри ServiceMix, и он генерирует сам сервис.
От себя мы добавили хитрое синхронно-асинхронное преобразование. Все запросы, которые живут внутри системы — асинхронные и идут через Message Bus.
В массе скоринговые сервисы синхронные. Запросы ServiceMix поступают через REST либо SOAP. В этот момент он проходит через наш Gateway, который сохраняет знания о HTTP сессии. Дальше посылает сообщение в Kafka, оно пробегает через какой-то pipeline, и порождается решение.
При этом решения может еще и не быть. К примеру, что-то отвалилось, либо есть жесткий SLA на принятие решения, и Gateway отслеживает: «ОК, я получил запрос, он пришел мне в другой топик Kafka, либо мне ничего не пришло, но у меня сработал триггер по таймауту». Дальше опять идет преобразование синхронного в асинхронный, и в рамках той же HTTP сессии идет ответ потребителю с результатом работы. Это может быть ошибка или нормальный прогноз.
В этом месте, кстати, мы съели невкусную собаку благодаря великому и могучему Open Source. Мы использовали ServiceMix одной из последних версий, а Kafka предыдущих версий и все прекрасно работало. В этот Gateway мы писали, основываясь на тех кубиках, которые были уже в ServiceMix. Когда вышла новая версия Kafka, мы радостно ее схватили, но выяснилось, что поддержка хэддеров внутри сообщения в Kafka, которые раньше существовали, изменились. Gateway внутри ServiceMix больше с ними не умеет работать. Чтобы это понять, мы потратили массу времени. В результате построили свой Gateway, который умеет работать с новыми версиями Kafka. О проблеме написали разработчикам ServiceMix и получили ответ: «Спасибо, мы обязательно вам посочувствуем в следующих версиях!»
Поэтому мы вынуждены следить за обновлениями и регулярно что-то менять.
Инфраструктура — это Gitlab. Мы используем практически все, что в нем есть.
- Репозиторий кода.
- Continues Integration/Continues Delivery pipeline.
- Registry для ведения реестра Docker-контейнеров.
Компоненты
Мы разработали 5 компонентов:
- Blackboard — управление жизненным циклом pipeline. Где, что и с какими параметрами запускать из pipeline.
- Feature extractor работает просто — сообщаем Feature extractor, что на вход получаем такую-то модель данных, из данных выбираем нужные поля, маппируем их в определенные значения. Например, получаем дату рождения клиента, преобразуем в возраст, используем как фичу в своей модели. Feature extractor отвечает за обогащение данных.
- Rule based engine — проверка данных по правилам. Это простой язык описания, который позволяет человеку, знакомому с построением блоков
if, else, описать правила для проверки внутри системы. - Machine learning engine — позволяет запускать executor, инициализировать обученную модель и подавать её на вход данные. На выходе модель данные забирает.
- Decision engine — движок принятия решений, выход из графа. Имея каскад моделей, например, разные ветки оценки заемщика, вы должны каком-то месте принять решение о выдаче денег. Набор правил для решения должен быть простым. Например, у нас есть анализ LTV-модели — прогноз заработка определенной суммы денег, если прогнозируемая сумма меньше пороговой, ответ отрицательный.
Пример работы
Рассмотрим пример скорингового сервиса с двумя наборами входных данных. Первый — анкета заемщика, которую он сам заполняет. Второй — кредитная история из бюро кредитных историй, которая повествует о его финансовой дисциплине.
Так выглядит pipeline в этом синтетическом примере.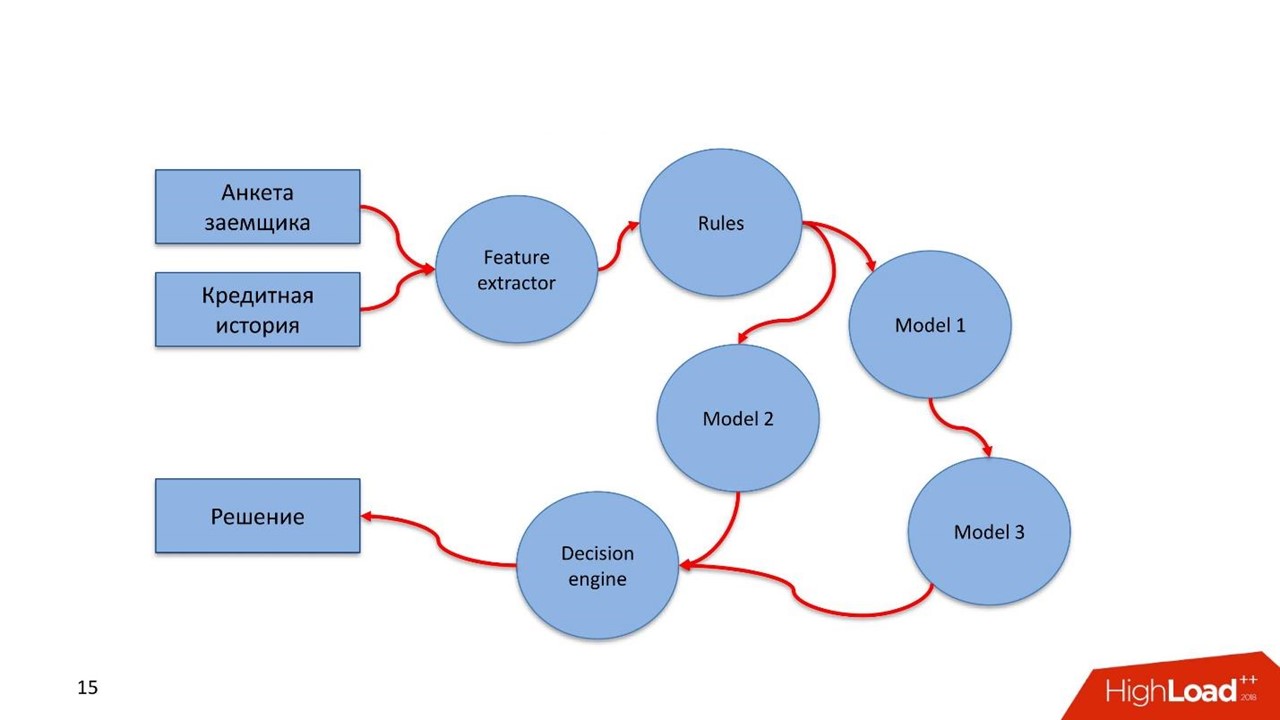
- Разработчик описывает Feature extractor: какие фичи, какие данные извлекаем из анкеты и кредитной истории, в каком виде подаем в модель.
- Набор правил. Например, проверка стоп-факторов: реальность паспорта, валидность, действительная дата рождения и возраст больше 18.
- Описывается набор моделей. В зависимости от типа, заемщик оценивается разными моделями. Если разработчик придумал еще модель, которая использует результаты работы предыдущей модели, то также здесь описывает и вставляет в pipeline.
- Формируется Decision engine. В нем описываются правила принятия решений на основании результатов работы моделей и правил.
- Порождается решение.
Все это описываем с помощью yaml. На текущий момент пока нет никакой визуальной формы описания. Мы думали об этом, но сил, времени и ума сделать это пока не хватило. Поэтому мы сделали это с помощью текстового редактора и языка yaml.
Разработчик pipeline, описывая все компоненты, указывает их тип: feature extractor, rules, models, decision engine, ее имя и версию. Это важно — на основании имени и версии генерируется Docker-контейнер. Это ссылка на Registry, где живут Docker-контейнеры. Актор-инициализатор, который их вызывает, обращается по этому имени. Поэтому, если ошибиться, то при сборке будет создан Docker-контейнер с этим именем и останется на века.
Pipeline
Мы хотели сделать все быстрее, поэтому стали писать на Python — мы его знаем и умеем на нем быстро писать. Feature extractor, правила, модели и decision engine сделали на Python.
Pipeline нарисовали на yaml. Хранение описания системного окружения в meta storage мы еще не доделали — это выполняется руками.
Если Runtime environment растиражирован на 10 серверах, то Blackboard должен знать, что он этот pipeline должен запустить на 10 серверах. Можно указать, где и какие конкретно компоненты запустить: серверы, правила, IP-адреса для точки входа Kafka, порты, топики. Пока это все работает в ручном режиме.
Все артефакты сохраняются в GitLab. Развертывание и изначальная инициализация производятся Ansible. Оказалось, что это сложный процесс. Условно большая инфраструктура на пару десятков серверов разворачивается за несколько часов, но наш инженер эксплуатации написал 50 000 строк кода на Ansible для этого.
Как выглядит деплой?
В GitLab есть pipeline. Разработчик закоммитил в GitLab. CI увидел процесс, заметил новый артефакт, прогнал тесты, породил результаты. Дальше вступает GitLab Runner, в нем конструируются Docker-контейнеры всех компонентов, которые описаны в pipeline. Если удалось собрать — все сохраняется в Registry.
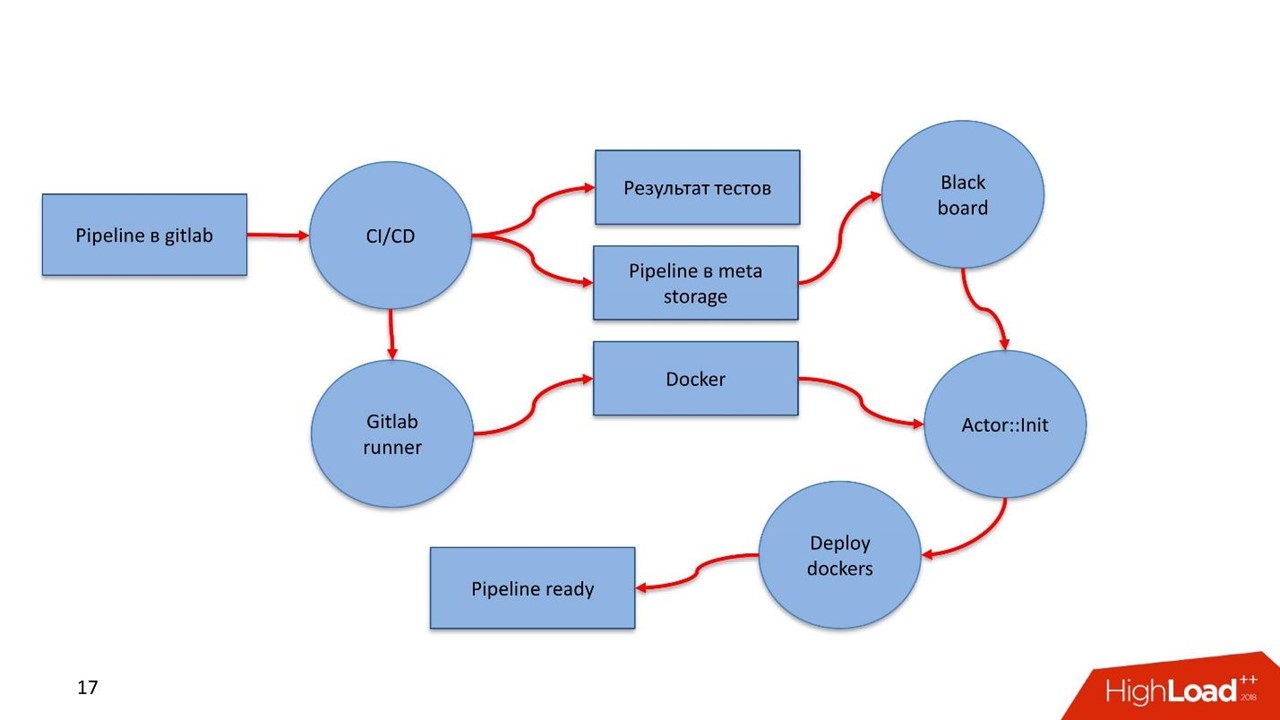
Преимущество Docker в том, что мы отстраняемся от проблем с версионностью. В каждом Docker-контейнере для каждой компоненты существует своя версия необходимых библиотек. В итоге CI pipeline сохраняет само описание pipeline в бизнес-процессах в Meta Storage, с которым работает Blackboard.
Blackboard регулярно заглядывает в Meta Storage — увидел новые изменения, достал, провалидировал, разослал сообщения актору-инициализатору. Тот подтянул Docker-контейнер и спустя несколько минут растиражировал, поднял, запустил.
Актор-инициализатор получает от Blackboard из Meta Storage все необходимые для запуска конфигурационные параметры: подключения к БД, к Kafka, к системе мониторинга. Любую информацию, которая должна быть конфигурируема, про которую Docker-контейнер изначально ничего не знает, он получает в момент инициализации.
Лампочки загорелись, в мониторинге появились Docker-контейнеры, засветились — pipeline готов!
Изначально мы разрабатывали все в DigitalOcean. Потом научились деплоить в AWS и Scaleway, но последний не очень любим.
Для наших заказчиков главное, что все это может крутиться внутри его периметра. Весь pipeline и вся его инфраструктура может находиться под управлением заказчика. Гарантировано, что нет никаких утечек.
А это вообще быстро?
Сложно оценивать — формальные критерии непросты. К примеру, самый сложный pipeline, который мы делали на real-time запросах был такой.
- 2 Feature extractor входных данных. Размер данных чуть меньше 1 Мб, т.е. json с колоссальным количеством данных.
- 8 моделей — 8 экземпляров ML engine. Все они крутились на базе XGBoost.
- 18 блоков наборов правил в RB engine (115 ФЗ). В блоках 1000 правил проверки на отмывание доходов.
- 1 decision engine.
Сейчас этот сервис крутится и обрабатывает 200 запросов в секунду. Через 2 Feature extractor, 8 моделей, 18 блоков и 1 decision engine принятие решения занимает в среднем 1,2 с.
Планы
Discovery ресурсы. Автоматически отслеживать, что отвалились какие-то серверы не получается. О том, что сервер отвалился в момент деплоя, узнаем в процессе деплоя. Над решением сейчас работаем. Все ресурсы руками описываем в Meta Storage.
Визуальное проектирование pipeline. Хотим внедрить некий движок, как BPM. С ним разработчик не будет писать в yaml с кучей синтаксических и орфографических ошибок, а будет визуально двигать кубики, доставать из репозитория готовые и рисовать.
Поддержку акторов на других языках. Сейчас ради эксперимента пишем актор на Java, Scala, R. Само ядро на Python, но актор исполняется независимо от всей системы, и язык может быть любой. Достаточно обеспечить набор API на других языках, чтобы разработчик pipeline мог писать акторы на знакомом языке.
Что в итоге?
Первая версия разработки — это месяц работы двух человек. До продуктового решения — еще полгода работы. В результате получили конструктор, которым сами с трудом научились пользоваться. С трудом, потому что образ конструктора потребовал несколько итераций и подходов. Все что выше описано — его состояние на ноябрь 2018 года.
В попытках эксплуатации конструктора мы натыкались на любопытные грабли, обходили и научились с ним работать. И не зря — легче жить и нам, и эксплуатации клиентов, у которых используется конструктор.
Процесс понятен и для разработчиков, и для эксплуатации. Мы ушли от многих проблем, которые связаны с тем, как этот несчастный notebook вывести на прод, как модель мониторить и деплоить.
Например, что-то такое я и имел в виду, когда говорил, что между идеальным алгоритмом в вакууме и его применением лежит пропасть. Приглашаю тех, кто уже научился её преодолевать, подать доклад на UseData Conf. А тех, кто хочет больше узнать, как машинное обучение применяется в практических задачах, на конференцию 16 сентября.
