Безопасно ускоряем Erlang приложение c помощью NIF на Rust
В статье освещен вопрос интеграции Erlang и Rust на примере реализации вероятностной структуры данных Бёртона Блума, позволяющей проверить принадлежность элемента множеству с необходимой точностью.
Выбор языка
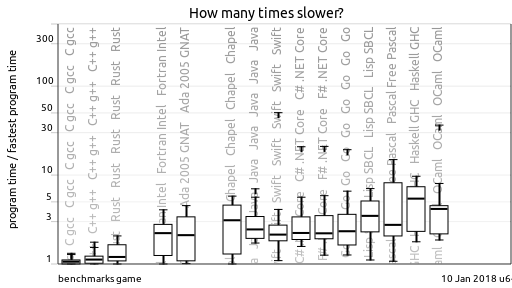
Тесты производительности, основанные на вычислительных задачах, ясно дают понять, в какой лиге играет Erlang.

Поскольку Erlang не обладает сверхбыстрой арифметикой, решать сложные вычислительные задачи на нем видится странным. Однако он прекрасно подходит для вопросов, возникающих при разработке и эксплуатации систем массового обслуживания. Erlang, обладая отличным планировщиком и сборщиком мусора, вкупе с быстрой сетью и обработкой бинарных данных, прекрасно справляется с высококонкуретной распределенной средой. Таким образом, лично для себя я отвел Erlang роль системного клея в архитектуре распределенных серверных приложений.
В реальных системах возникают локальные вычислительные задачи, которые тормозят систему и ухудшают общий UX. Часто бывает так, что тормозит 1% кода, и негативно влияет на остальные 99% системы. Для решения данной проблемы в Erlang, начиная с версии R13B03, существует механизм Native Implemented Functions (NIFs).
В списке мифов про Erlang в пункте 2.7 разработчики предупреждают, что использование интерфейса NIF должно быть последней мерой, так как использование NIF опасно из-за возможных падений VM, вызванных дефектами реализации вашего NIF, и не всегда гарантирует увеличение скорости.
Официальные примеры реализации NIF доступны для C. Код на С и C++ довольно легко сделать небезопасным, например, выйдя за границы памяти структуры или массива, или же пропустив операцию освобождения выделенных ресурсов. На мой взгляд, проблема усугубляется фактором переключения контекста: когда программист, в основном разрабатывающий код на Erlang, переключается на низкоуровневый C, вероятность описанных выше проблем возрастает, особенно в рамках горящих сроков.
Таким образом, хотелось бы получить решение такое же быстрое, как на С/C++, но безопасное и легко поддерживаемое. Давайте посмотрим на самые производительные в вычислительном плане языки.
С точки зрения требований к языку стоит отметить:
- Безопасность. Решение не должно ни при каких условиях ломать Erlang VM
- Производительность. Быть сравнимым по производительности с С++
- Возможность использования в режиме NIF
- Скорость разработки. Необходима хорошая стандартная библиотека и большой набор сторонних библиотек, обеспечивающий удобную экосистему языка.
Из когорты производительных языков наиболее подходящим видится Rust. Он предлагает хорошую производительность и безопасную модель разработки, а также активное сообщество. Дополнительным плюсом Rust является иммутабельность данных и прозрачная модель многопоточности.
Следует заметить, что существует другой вариант оптимизации. Если мы можем пренебречь временем и накладными расходами дополнительного вызова через EPMD, то можно выбрать путь написания Erlang Node, вместо NIF. Для решения этой задачи подходит Java, Go, Rust, Ocaml (из личного опыта). Erlang Node может быть запущена на той же машине или вообще на другом конце земли.
Имплементация
Обзор существующих решений на Rust
После быстрого поиска находится сразу несколько библиотек для написания NIF на rust. Рассмотрим их:
- rustler. Пожалуй, самая популярная и функциональная библиотека, однако авторы сконцентрировали свои усилия на поддержке Elixir. В https://github.com/hansihe/rustler/issues/127 предлагают тащить mix в erlang проект. Документации по использованию в Erlang нет.
- erlang-rust-nif. Представляет из себя низкоуровневую реализацию NIF и подход к сборке расширения. Код выглядит простой трансляцией с C. Сборка имеет граничные условия и не универсальна.
- erlang_nif-sys. Низкоуровневая и полнофункциональная связка. Является основой для Rustler. Требует усилий и времени для написания NIF.
- bitwise_rust. Демонстрирует работу с планировщиком. Также является оберткой без синтаксического сахара над С api.
Поскольку одним из пунктов требований является скорость разработки, наиболее привлекательно выглядит Rustler. Однако вносить в проект дополнительную зависимость в виде Elixir и сборщика mix не хочется.
Rustler
Отвечая на вопрос «зачем вообще тащить в erlang проект elixir?» и следуя принципу KISS, решено использовать rustler, но без дополнительных зависимостей. В качестве билд системы используется rebar3. Самым простым и быстрым шагом является определение pre_hooks для компиляции нашего rust кода.
Для этого допишем в тестовом профиле hook:
{pre_hooks, [
{"(linux|darwin|solaris|freebsd)", compile, "sh -c \"cd crates/bloom && cargo build && cp target/debug/libbloom.so ../../priv/\""}
]}В боевом окружении добавим опцию --release, таким образом в боевой профиль добавляем:
{pre_hooks, [
{"(linux|darwin|solaris|freebsd)", compile, "sh -c \"cd crates/bloom && cargo build --release && cp target/release/libbloom.so ../../priv/\""}
]}После этих манипуляций появляется динамическая библиотека priv/libbloom.so, полностью готовая к загрузке в Erlang VM.
Подробности и пример использования rustler в erlang проекте можно найти в репозитории проекта https://github.com/Vonmo/erbloom
Фильтр Блума
Поскольку экосистема rust предоставляет уже готовые реализации фильтра блума, выбираем подходящую и добавляем в cargo.toml. В данном проекте используется bloomfilter = "0.0.12"
Расширение реализует следующие функции:
new(bitmap_size, items_count)— инициализация фильтра.bitmap_sizeиitems_count— расчетные значения, существует масса готовых калькуляторов.serialize()— упаковка фильтра, например, для последующего сохранения на диск или передачи по сети.deserialize()— восстановление фильтра из сохраненного состояния.set(key)— добавляет элемент в множество.check(key)— проверяет принадлежность элемента множеству.clear()— очищает фильтр.
Erlang
Следует отметить, что загрузка расширения в Erlang — это абсолютный прозрачный процесс. После загрузки вашего модуля, происходит вызов on_load, в котором необходимо реализовать загрузку nif через erlang: load_nif/2. При этом обработка вызовов будет прозрачно происходить уже в Rust.
Правилом хорошего тона является генерация ошибки erlang: nif_error/1 в случае если NIF не загружен.
Подробное описание окружения для сборки проекта можно найти в данной статье.
Итоги
В результате проделанной работы мы получили производительное и безопасное расширение. В наших проектах данное расширение позволяет сократить объем обращений к хранилищу данных в некоторых случаях до 10 раз и обслуживать поток обращений более 500к RPS на машину.
Исходный код расширения доступен на github.
