Балет и роботы
Оцветнение видео под капотом
Продолжаю рассказывать о своём необычном увлечении. Моё хобби заключается в алгоритмическом преобразовании древнего черно-белого видео в материал, который выглядит современно. Про мою первую работу написано в этой статье. Прошло время, мои навыки улучшились, и теперь я не смеюсь над мемом «Zoom and enhance».
Необходимо уточнение, что речь пойдёт не про ручную реставрацию и оцветнение, которые требуют тонны индусов и килограммов денег, а про использование автонастраивающихся алгоритмов (часто именуемых терминами «ИИ», «нейросети»).
Когда-то мои работы были незначительно лучше по четкости и цвету аналогичных работ других любителей, теперь же арсенал применяемых средств расширился настолько, что качество конечного результата зависит лишь от вложенного времени.
▍Небольшая история
Со стороны, процесс автоматического оцветнения видео не воспринимается как нечто заумное, ведь очевидно же, что достаточно скачать некую программку и бросить в неё видеозаписью, а всю сложную работу уже проделал тот, кто сконструировал алгоритм оцветнения и потратил электричество на обучение.
А давайте я вам сейчас расскажу про то, как появился революционный алгоритм оцветнения Deoldify. Даже если вы занимаетесь машинным обучением, не факт, что вы знаете кто такой Джереми Говард (Jеremy Howard). Его профессиональная карьера началась с роли наёмного консультанта, 20 лет назад он занимался тем, что сейчас именуется Data Science, то есть извлечение прибыли из данных с помощью математики.
Продажа парочки стартапов, позволила ему задуматься над осознанным внесением позитивного вклада в развитие человечества. После переезда в Dолину он влился в тусовку топовых специалистов по машинному обучению, а в 2011 он стал лучшим участником соревнований Kaggle.
Важной поворотной точкой стал 2014 год, когда его проект по автоматическому выявлению медицинских аномалий на рентгенограммах показал результаты, которые превосходили качество работы опытных врачей. При этом проект не представлял собой что-либо грандиозное с точки зрения вложенных интеллектуальных и материальных ресурсов, а финальное обучение проводилось в ночь перед презентацией. Типичный рабочий проект, который своим существованием символизировал точку перехода в техническом прогрессе.
У Джереми сформировалось четкое понимание того, что настолько мощный инструмент может стать источником роста в любой области. Главная проблема была (и есть) в том, что количество специалистов по самообучающимся системам несопоставимо с количеством проектов, в которых можно было бы задействовать их способности. С его точки зрения гораздо эффективнее было бы дать этот инструмент всем желающим. Так появился проект «Fast.Ai», который является симбиозом кода и курса обучения. Код с одной стороны значительно упрощает использование Pytorch (средство для конструирования алгоритмов машинного обучения), а с другой содержит массу готовых приёмов, которыми пользуются профессионалы для повышения скорости и качества обучения. Учебный курс строится по принципу «сверху вниз», сначала студенты обучаются использовать готовые конвейеры, затем Джереми показывает как можно написать каждый элемент конвейера с нуля, начиная с живой демонстрации в табличке Excel ключевого алгоритма, лежащего в основе всего Deep Learning. Цель проекта Fast.Ai состоит в том, чтобы научить специалиста из любой области решать типичные задачи на типичных архитектурах (конечно, при наличии способностей к программированию). Чудес не бывает, уровень навыков после такого обучения не превосходит уровень «круглое кати — квадратное верти», но даже этого достаточно для решения рабочих задач на новом уровне, недоступном коллегам.
В обучающем курсе Fast.Ai одна из тем посвящена использованию архитектуры UNet, которая ориентирована на переинтерпретацию изображений. Например, эту архитектуру можно обучить генерировать реалистичные фотографии из изображений, полученных с тепловизора, или контрастно выделять аномалии на снимках. Если говорить обобщенно, то такая архитектура по известной форме и свойствам, позволяет предсказать наличие у формы свойств, выявление которых было целью обучения.
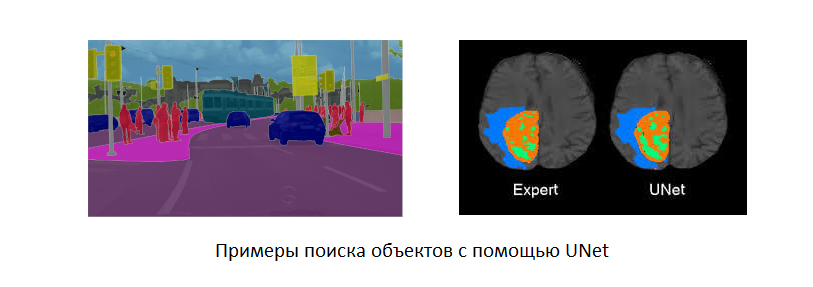

▍Кружок «Умелые ручки»
Главная проблема использования передовых проектов с открытым кодом в области машинного обучения заключается в том, что дружелюбность к пользователю обычно левее нуля. Автор проекта сосредоточен на конвейере обучения, результаты работы алгоритма ему нужны исключительно для презентации сообществу, что нормально, поскольку цель таких проектов — это самопиар и вклад в исследования. Самостоятельный допил проектов пользователем является нормой. Чтобы далеко не ходить: перед обработкой видео его необходимо декодировать, обработать каждый кадр и получившееся сжать в видеофайл, если одно видео обрабатывать несколькими инструментами, то после последовательных пережатий про качество можно забыть. Каждый новый инструмент приходится переделывать на работу с пачкой картинок. А что если в инструменте на уровне конвейера вшито использование за один запуск не более 8 кадров? Для демонстрации алгоритма достаточно, для практических целей нет. Придётся писать внешнюю обертку для многократного запуска, ведь маловероятно, что получится изменить чужой конвейер без потери совместимости с предобученным состоянием алгоритма. И, конечно, академические авторы не особо парятся на тему оптимизации. Есть один проект, который отказывался работать с изображениями больше чем спичечный коробок, после оптимизации он стал требовать в 5 раз меньше видеопамяти и теперь переваривает FullHd.
Можно долго перечислять косяки, которые встречались, достаточно остановиться на том факте, что для работы любого алгоритма необходима установка инструментальных библиотек, иногда может потребоваться 2–3 дня экспериментов прежде чем библиотеки перестанут конфликтовать между собой (даже при наличии перечня точных версий существует масса причин почему придётся долго гуглить).
▍Минутка прекрасного
Выбирать материал для оцветнения не то чтобы очень просто. С одной стороны содержание должно быть любопытно мне, с другой стороны длинный рекламный фильм фирмы Дизеля, насыщенный техническими деталями, вряд ли заинтересует широкую аудиторию, с третьей стороны существуют ограничения в выборе из-за авторских прав. Новые варианты приходят из памяти или в ходе розыска конкретных записей. Мои последние работы посвящены русской балерине Анне Павловой. Про неё достаточно написано и сказано, сохранилось множество фотографий, но так как её профессиональная деятельность связана с движением во времени и пространстве, то самым интересным свидетелем является киноплёнка. К сожалению, часть сохранившихся записей неизвестны широкой публике, а то что сейчас находится поиском совершенно отвратительного качества. Чем интересна фигура Анна Павловой, так это в буквальном смысле фигурой. Её можно считать прообразом эталона современной балерины, возможно, для вас не будет открытием, что, в конце 19-го века, худоба всё ещё коллективно воспринималась как признак болезни либо бедности, конечно, в среде обеспеченных людей встречались разные фигуры, но в целом, упитанность воспринималась, как маркер успешной жизни. Пышущие здоровьем женщины часто выступали на театральной сцене, вот фотографии трёх звёзд того времени.

В одной из моих работ можно даже посмотреть на то, как это выглядело. Зрители, не имеющие хорошего понимания истории, с трудом воспринимают всерьёз такую картину, хотя самые передовые жители нашей планеты наверняка найдут тут позитив.Возвращаясь к Анне Павловой: существует несколько кинолент, запечатлевших балерину в танце. Они существуют в хорошем качестве, но в открытом доступе их нет. Зато в ходе поисков, к моему удивлению, обнаружился целый полнометражный фильм, в котором главную роль сыграла наша балерина. В начале фильма вставлен номер с танцем, не имеющим отношения к сюжету, поэтому вполне уместно считать его отдельным видеороликом, работой над которым я занялся.
▍Проблемы на старте
Декодируем исходное видео в серию файлов PNG. Просматриваем полученные изображения и замечаем, что встречаются кадры, которые повторяют предыдущие.
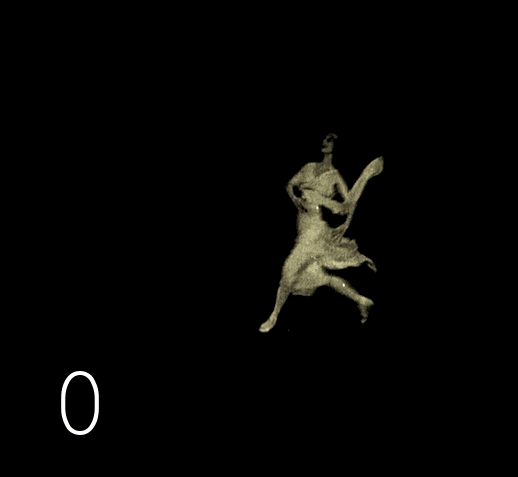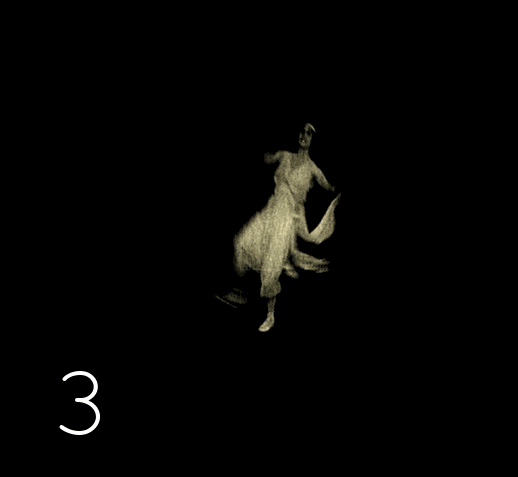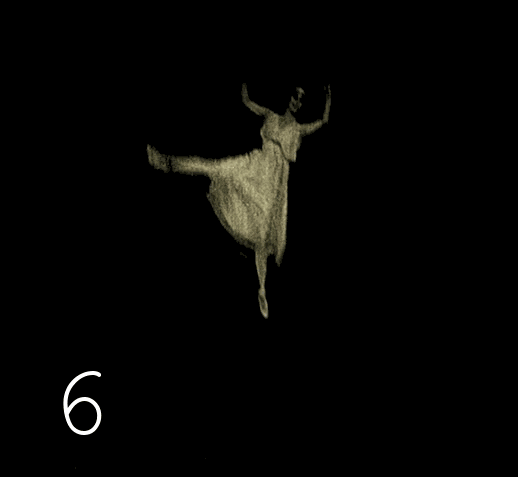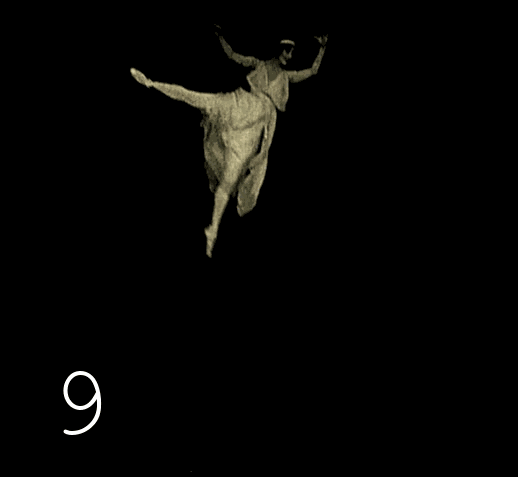
Это стандартная история, ведь на заре кинематографа для экономии пленки использовалась скорость съёмки 12–19 кадров в секунду (далее fps). В более позднюю аналоговую эпоху, когда 99% видеоряда имело скорость 24–25 fps, для демонстрации старых лент использовалось копирование кадр-в-кадр, что приводило к ускоренному воспроизведению. Поэтому в сознании большинства старая хроника прочно ассоциируется с нечеткими мечущимися человечками. Правда заключается в том, что черно-белые оригиналы плёнок очень хорошо сохраняются, даже лучше чем цветные, и имеют разрешение между DVD и FullHd. Всё что вы могли видеть в большинстве случаев было дрянными копиями, переснятыми с проекции на экран. Хотя многие киноленты сохранились лишь на таких копиях (утраты происходят из-за человеческого фактора), всё же количество сохранившихся оригиналов значительно. Доступ к оригиналам имеют только избранные, к счастью, в наши дни компьютерная обработка изображений позволяет неограниченно тиражировать сканированные качественные копии оригиналов, почистить дефекты и воспроизводить материал с нормальной скоростью частоты кадров.
С низкой частотой кадров есть две раздельные проблемы. Во-первых, она нестандартная, если на личном компьютере можно использовать любую скорость воспроизведения, то существует масса случаев, когда необходимо придерживаться диапазона 24–30 fps. Самый простой способ коррекции частоты кадров — это через каждые 3–4 кадра повторять последний. Скорость движения объектов при этом становится естественной, но картинка воспринимается как дёрганная, это собственно вторая проблема. В 2021 году технологии позволяют сделать плавную картинку за счет интерполяции кадров. Технология интерполяции кадров в телевизорах и программных видеопроигрывателях начала встречаться примерно с 2005 г. За счет математических алгоритмов два соседних изображения смешиваются так, что при проигрывании возникает ощущение плавного движения в кадре. Это неплохо получается для 24 fps, так как разница между кадрами редко бывает значительной. Но для 12–19 fps такие алгоритмы не годятся: они рисуют смазанное двойное изображение или сумасшедшие артефакты. Эту задачу успешнее решают самообучающиеся алгоритмы, которые способны запоминать как именно следует рисовать промежуточное изображение для разного движения разных типов объектов.
В современных переизданиях фильмов эпохи немого кино пока не используется применение интерполяции, соответственно в нашем видео присутствуют повторяющиеся кадры, и, если их не убрать, то, когда дело дойдёт до интерполяции кадров получится ерунда, а значит необходимо удалить лишнее.
▍Неожиданный поворот
Ручками удалять такое — замучаешься, плавали, знаем. Запускаем скрипт обнаружения одинаковых кадров, скрипт вываливается с ошибкой «Много совпадений подряд». А, ну, естественно: кадры слишком тёмные, поиск сгребает в одну кучу одинаковые и разные кадры. Запускаем скрипт нормализации динамического диапазона, который автоматически делает контрастными границы, чёрное приводит к чёрному, белое к белому, а затем возвращает на место оттенки серого, которые теряются при подобных манипуляциях.

Снова запускаем поиск дублей, процесс теперь идёт увереннее, но после удаления ненужных кадров обнаруживается что-то новое. С некоторой периодичностью встречается повторение кадров в обратном порядке. Запускаем исходное видео и смотрим внимательно, ого, да они правда применили хитрость, использующую инерционность зрения, и изображение воспринимается менее дёрганным, чем при обычном дублировании кадров.
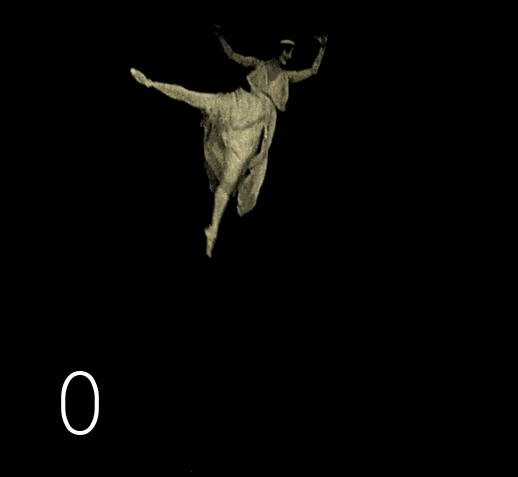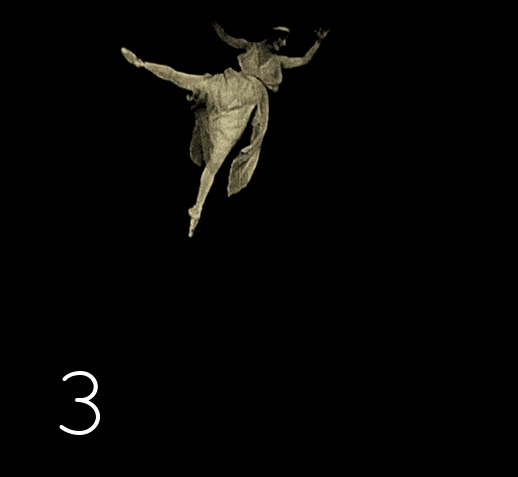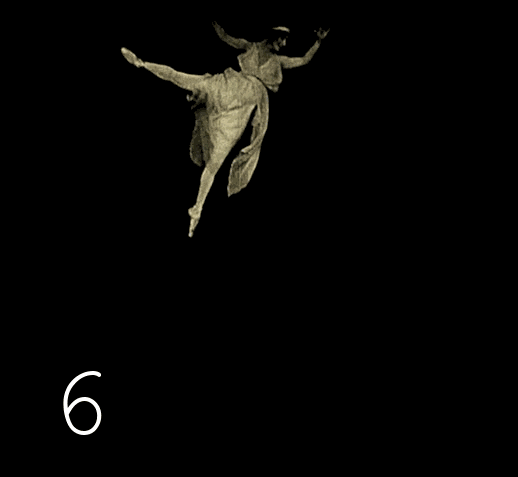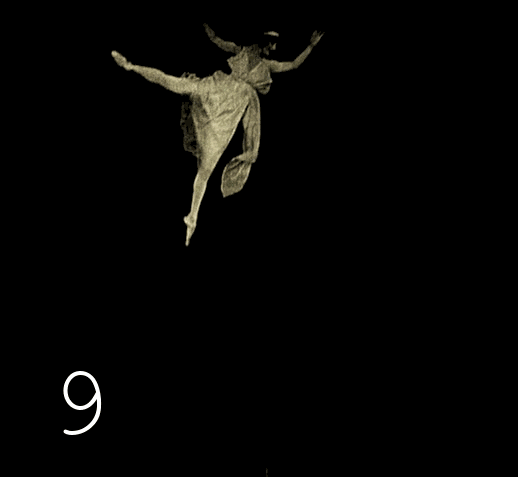

Изменяем скрипт с поиска одинаковых подряд кадров на — поиск одинаковых кадров через один промежуточный. Проверяем результаты — опять сюрприз: встречается повторение через два кадра. После проверки третьей версии скрипта сюрпризы заканчиваются.
Проблема удаления лишних кадров неожиданно стала очень серьезной. На таких тёмных и не насыщенных деталями кадрах нельзя доверять автоматическому поиску дублей, он ошибётся неоднократно, пропустив ненужное и удалив нужное. Прогоняем поиск всех видов дублей на другом эпизоде фильма, в котором количество ошибок будет минимальным. В случае простого повторения, выделив дубли в менеджере файлов, можно понять схему повторения и удалить лишние файлы программно.
Изменяем скрипт поиска дублей, теперь в имена файлов будут добавляться метки в зависимости от вида дублирования. Переносим весь список файлов в Excel и оставляем только метки, переворачиваем столбец в строку и вылетаем за допустимое количество столбцов, теперь придётся разделить на два листа. Выделяем одним цветом дублированные кадры одного типа, что позволит задействовать биологический анализатор шаблонов.

Короткие повторения группируются. Проверяем насколько точно повторяется длинная группа. Группы похожи, но присутствуют небольшие отличия. Это фиаско. Есть несколько возможных причин такой картины: намеренно вносились случайные изменения, или использовалось несколько алгоритмов дополнения кадров, или учитывается содержание кадров, или метод использует не интуитивную функцию. Записывать гораздо более длинную последовательность повторов для математического анализа выглядело как перебор.

Придётся удалять шум руками, используя образец. Прогоняем скрипт поиска дублей на интересующем нас эпизоде, и загружаем последовательность кадров в эксель, раскрашиваем, а рядом вставляем шаблон длинной последовательности. Проставляем маркировку там, где это кажется однозначным, убираем неправильную маркировку. Дальше догадываемся где какие кадры должны быть, и вот большая часть картины восстановлена. Остаётся несколько непонятных мест. Проставляем метки точно по шаблону или по интуиции. Конечно, где-то будут ошибки, но где-то попадём, что на общем фоне правильной последовательности уже не критично, тем более, что в старой хронике почти всегда часть кадров теряется, и выжимать абсолютный идеал в данном случае нет смысла.
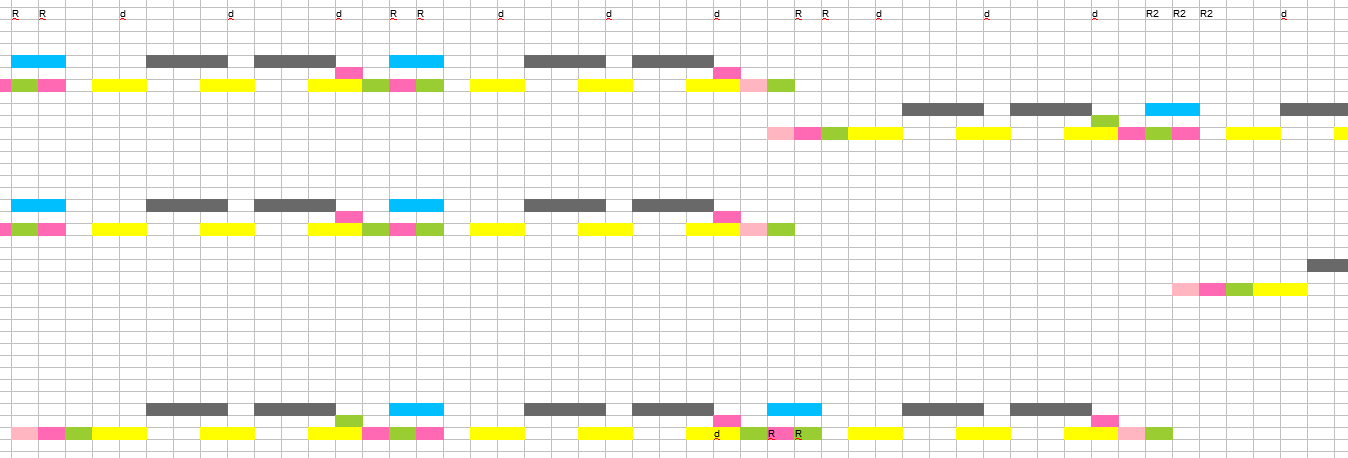
Используя итоговый список, удаляем лишнее, проверяем и вуаля, задача выглядит решенной на 9 из 10.
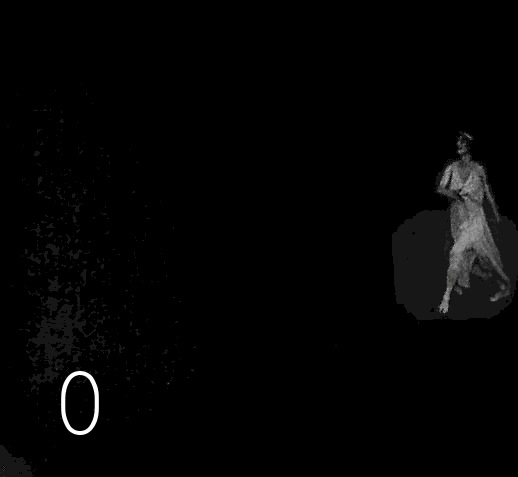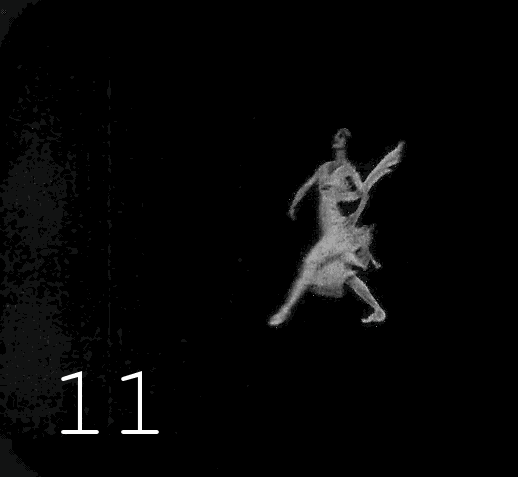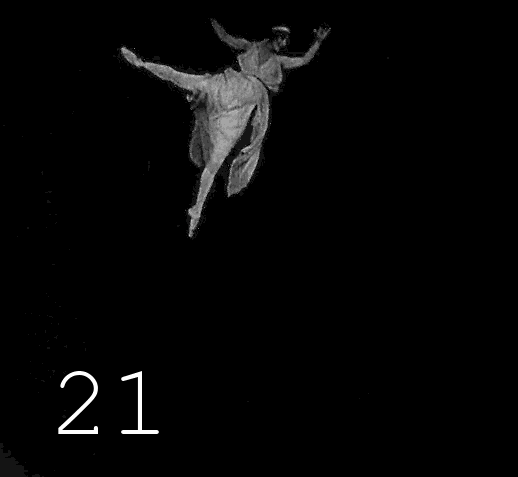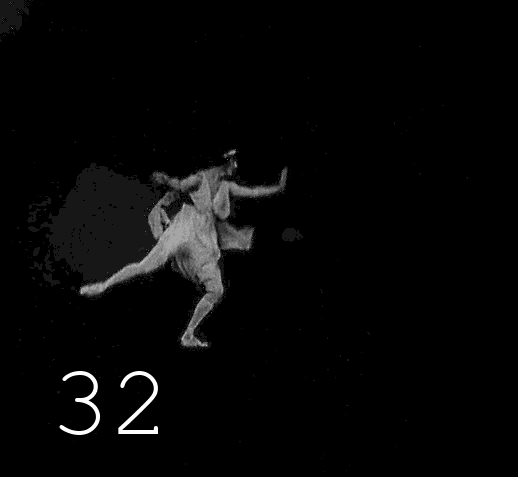
▍Основная работа
Далее следует 17 операций чёрной магии, в ходе которых на диске образуется 17 папок, содержащих кадры видео после каждой манипуляции. Кроме самого оцветнения, производится автоматическая коррекция неудачно оцветнённых кадров, значительное повышение четкости изображения, восстановленному изображению возвращается «аналоговость» (чтобы избавиться от ощущения фотошопа), для всего этого применяется 5 разных инструментов улучшения изображений, связанных между собой скриптами, которые туда-сюда переливают каналы яркости и цвета. Названия инструментов останутся моей профессиональной тайной, уж извините, слишком много труда и времени потрачено на собирание этого зоопарка и его модифицирование. Когда я увидел результаты работы Deoldify 2, мне стало понятно, что моё желание быть лучшим в этой области лишено смысла, как бы классно я не выжимал процентики качества, каждый новый подобный алгоритм превосходит старое в разы. Я бросил заниматься оцветнением и погрузился в Machine Learning с целью собрать свой Deoldify, правда, потом произошла череда событий, отвлекших меня от этой цели. В итоге я объединил несколько готовых проектов в общий процесс, результаты работы которого, хоть как-то заменяют мне мой несостоявшийся алгоритм оцветненения. Возможно, в следующей статье я расскажу как использовать оцветнялку от Google, если получится обуздать её аппетит к памяти, там будет код и подробности.
Для завершения работы над видео необходимо постараться убрать косяки, для этого лучше всего подходит профессиональный видеокомбайн Davinci Resolve. Если отдельно открыть следующую картинку, то можно разглядеть количество элементов в цепи ретуширования. Эта конструкция делает фон чёрным, приближает цвета к естесственным, борется с лишними цветами, создаёт имитацию луча прожектора (скрывает незначительные следы использования коррекции).
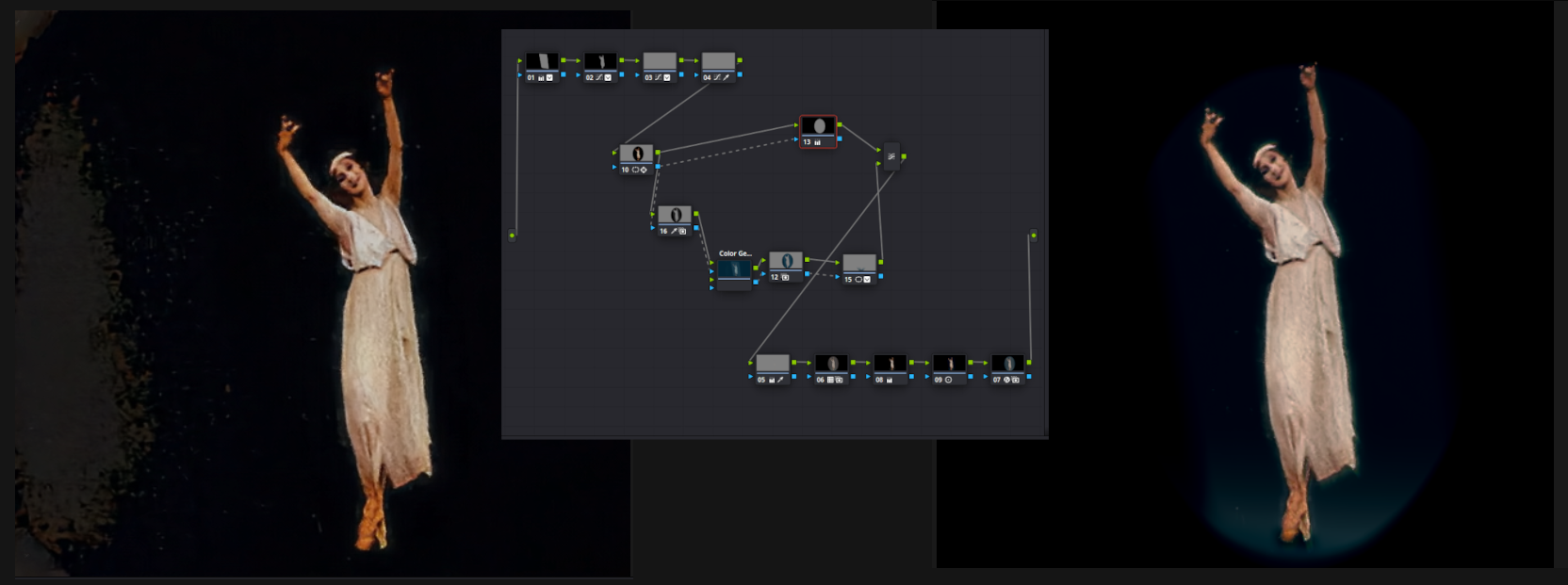
Остаётся сделать интерполяцию кадров, косметическое повышение разрешения до 2K, и вот наше видео готово. Исходная картинка слишком тёмная и чудес ждать не приходится, но зато теперь есть возможность рассматривать плавные движения чёткой фигуры танцовщицы.
Сам же фильм содержит множество сцен с относительно хорошей картинкой, что позволяет оценить насколько сильно алгоритмическая обработка может улучшить изображение. Кадры 2K разрешения слишком большие для статьи, поэтому рядом с полным кадром исходного изображения вставлены уменьшенные в 2 раза финальные кадры.





▍Итоги
Сюжет про танец содержит 1251 кадр (до интерполяции), работа заняла 5 дней.
Музыка добавлена из библиотеки бесплатной музыки Youtube.
Фильм содержит 19660 кадров (до интерполяции), обрабатывалось 14 дней (только алгоритмы, ручная ретушь не применялась). С музыкой тут было сложнее, сначала был вариант, собранный из кусочков оперы, которая лежит в основе сценария фильма, но из-за авторских прав не получилось опубликовать эту версию, пришлось использовать подходящие композиции из первой найденной библиотеки, говорят, вышло лучше чем в первый раз.
Характеристики ЭВМ: Amd Ryzen 3 1200, 4 Гб ОЗУ, GTX 1060 3 Гб
▍- Ссылки на мои работы:Youtube Не.ЧБ
Rutube Не.ЧБ
Instagram
P.s Не смог удержаться, оцветнил :)


