[Перевод] Антипаттерны деплоя в Kubernetes. Часть 2

Перед вами вторая часть руководства по антипаттернам деплоя в Kubernetes. Советуем также ознакомиться с первой частью.
Список антипаттернов, которые мы рассмотрим:
Использование образов с тегом latest
Сохранение конфигурации внутри образов
Использование приложением компонентов Kubernetes без необходимости
Использование для деплоя приложений инструментов для развёртывания инфраструктуры
Изменение конфигурации вручную
Использование кubectl в качестве инструмента отладки
Непонимание сетевых концепций Kubernetes
Использование неизменяемых тестовых окружений вместо динамических сред
Смешивание кластеров Production и Non-Production
Развёртывание приложений без Limits
Неправильное использование Health Probes
Не используете Helm
Не собираете метрики приложений, позволяющие оценить их работу
Отсутствие единого подхода к хранению конфиденциальных данных
Попытка перенести все ваши приложения в Kubernetes
6. Использование кubectl в качестве инструмента отладки
Утилита kubectl незаменима при работе с кластерами Kubernetes. Но не стоит использовать её как единственный отладочный инструмент.
При возникновении проблем, особенно в production кластере, вашим первым импульсом не должен быть запуск kubectl. Если вы поступаете именно так, то вы уже проиграли битву, особенно если сейчас 3 часа ночи, сервисы не работают, и вы на связи.
kubectl get ns
kubectl get pods -n sales
kubectl describe pod prod-app-1233445 -n sales
kubectl get svc - n sales
kubectl describe...Вместо этого все ваши кластеры Kubernetes должны иметь надлежащие системы мониторинга, трассировки и сбора логов, которые можно использовать для своевременного выявления проблем. Если вам нужно запустить kubectl для проверки чего-либо, это означает, что вы не учли это, настраивая вашу систему мониторинга.
Сложно переоценить ценность метрик и трассировок, мы расскажем о них отдельно в одном из следующих антипаттернов.
Даже если вы просто хотите проверить конфигурацию кластера, вы также можете использовать для этой цели специальный инструмент. Сегодня существует множество решений для работы с кластерами Kubernetes.
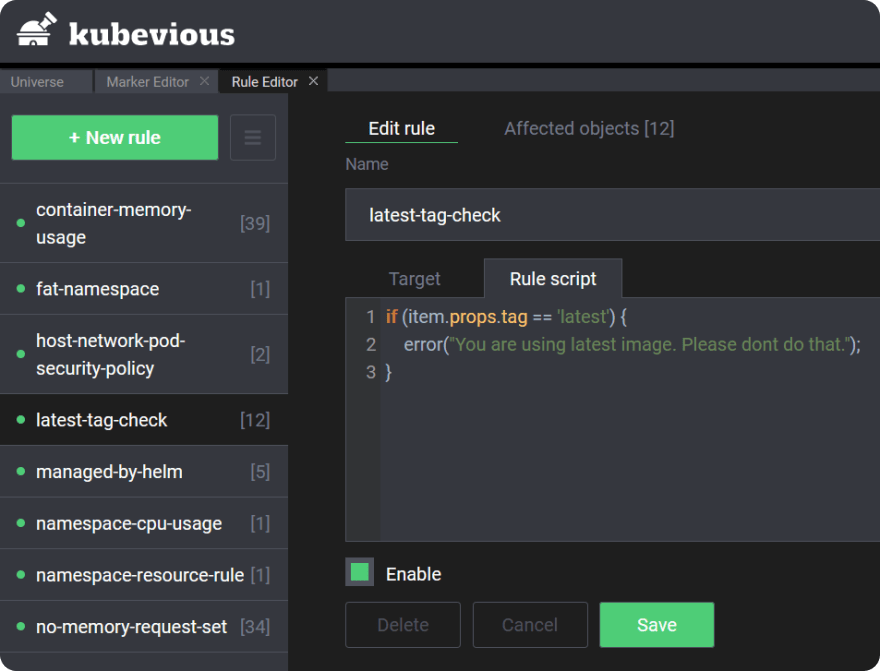
Например, обратите внимание на Kubevious, это универсальная панель управления Kubernetes, которая позволяет вам искать и отображать ресурсы Kubernetes в соответствии с настраиваемыми правилами.
7. Непонимание сетевых концепций Kubernetes
Прошли те времена, когда единственный балансировщик нагрузки был всем, что необходимо для настройки подключения к вашему приложению. Kubernetes представляет свою собственную сетевую модель, и вам нужно разобраться с её основными концепциями. По крайней мере, вы должны быть знакомы с типами сервисов — Load Balancer, Cluster IP, Node Port и понимать, чем сервисы отличаются от Ingress.
Сервисы типа Сluster IP используются внутри кластера, Node Port также могут использоваться внутри кластера, но при этом доступны снаружи, а балансировщики нагрузки могут принимать только входящий трафик.

Но это ещё не всё — потребуется разобраться, как в кластере Kubernetes работает DNS. И не забывать, что весь трафик между служебными компонентами шифруется и нужно контролировать срок действия сертификатов.
Будет полезно разобраться, что такое Service Mesh и какие проблемы она решает. Необязательно разворачивать Service Mesh в каждом кластере Kubernetes. Но желательно понимать, как она работает и зачем вам это нужно.
Вы можете возразить, что разработчику не нужно знать множество сетевых концепций для развертывания приложения, и вы будете правы. Нам нужна абстракция для разработчиков поверх Kubernetes, но у нас ее пока нет.
Как разработчик, вы должны знать, как трафик достигает вашего приложения. Если запрос должен выполнить 5 хопов между подами, узлами и службами, при этом каждый хоп имеет потенциальную задержку 100 мс, то ваши пользователи могут столкнуться с задержкой в 500 мс при посещении веб-страницы. Вы должны знать об этом, чтобы ваши усилия по оптимизации времени отклика были сосредоточены на устранении узких мест.
8. Использование неизменяемых тестовых окружений вместо динамических сред
Когда вы используете виртуальные машины или физические сервера, то командам разработчиков программного обеспечения обычно предоставляется несколько тестовых сред, которые используются для проверки приложения, прежде чем оно попадет в production.
Один из наиболее распространенных подходов — наличие как минимум трех сред (QA / Staging / Production), в зависимости от размера компании их может быть больше. Наиболее важной из них является «интеграционная», которая содержит результат слияния всех обновлений с основной веткой.
Когда вы используете неизменяемые тестовые среды, вы платите за них, даже если они не используются. Но наиболее серьёзной проблемой является изоляция обновлений для последующего тестирования.
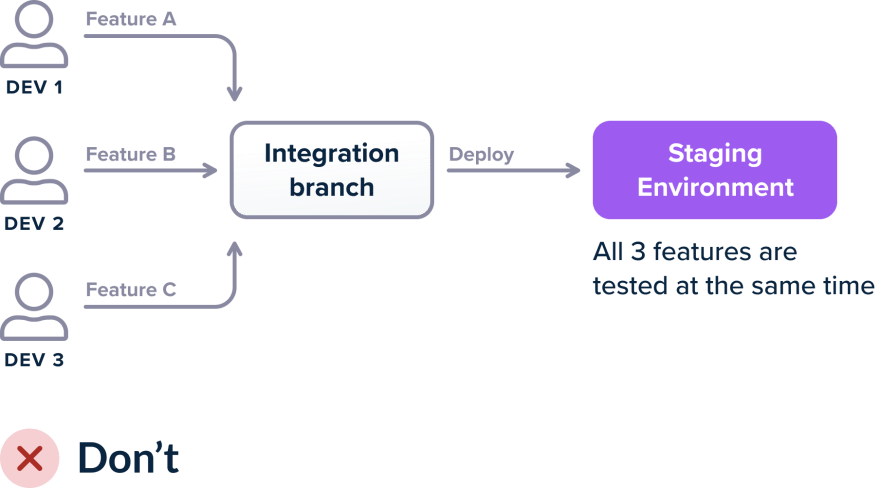
Если вы используете единое окружение для интеграции, когда несколько разработчиков выполняют слияние результатов работы и что-то ломается, не сразу становится понятно, какая из функций вызвала проблему. Если 3 разработчика объединяют свои функции в промежуточной среде и развертывание завершается неудачно (либо сборка завершается неудачно, либо тесты интеграции терпят неудачу, либо показатели взрываются…), тогда существует несколько сценариев:
Обновление A содержит ошибки, B и C в порядке
Обновление B содержит ошибки, A и C в порядке
Обновление C содержит ошибки, B и A в порядке
Каждое обновление в отдельности работает, но при работе вместе с обновлениями A и B возникает ошибка
Каждое обновление в отдельности работает, но при работе вместе с обновлениями A и C возникает ошибка
Каждое обновление в отдельности работает, но при работе вместе с обновлениями B и C возникает ошибка
Каждое обновление в отдельности работает, но все 3 обновления вместе не работают
В результате, если после обновления возникли проблемы в работе сервиса, будет непросто понять, какое из них стало причиной возникновения проблемы.
Способы избежать подобных проблем:
«Резервирование» промежуточного (stage) окружения разработчиками, чтобы они имели возможность тестировать свои обновления изолированно.
Компания создает несколько «staging» сред, которые разработчики используют для тестирования своих обновлений (поскольку единственное staging окружение может быстро стать узким местом).
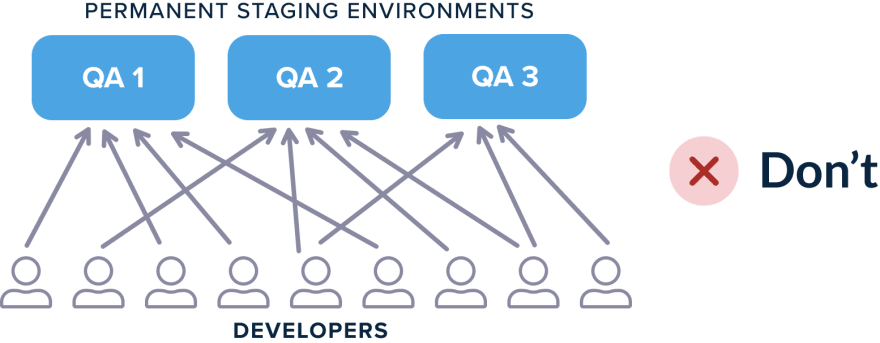
Эта ситуация по-прежнему приводит к проблемам, потому что разработчики должны не только координировать действия между собой при выборе сред, но также потому, что вы должны отслеживать действия по очистке каждой среды. Например, если нескольким разработчикам требуется набор изменений базы данных, им необходимо убедиться, что база данных содержит только необходимые данные, а не данные предыдущего разработчика, который использовал эту среду.
Кроме того, несколько промежуточных (staging) сред могут страдать от проблемы дрейфа конфигурации, когда среды должны быть одинаковыми, но после нескольких изменений это уже не так.
Решение, конечно же, состоит в том, чтобы отказаться от ручного обслуживания статических сред и перейти к динамическим средам, которые создаются и уничтожаются по запросу. С Kubernetes это очень легко сделать:
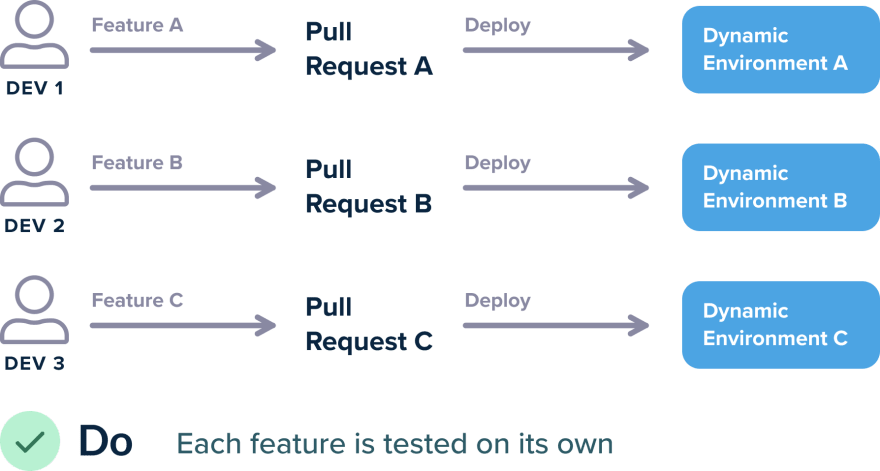
Есть много способов реализовать этот сценарий, по крайней мере, каждый запрос Pull Request должен создавать динамическую среду, содержащую только этот запрос Pull Request и ничего больше. Среда автоматически уничтожается, когда Pull Request объединяется / закрывается или по прошествии определенного времени.
Преимущество динамических сред — это полная свобода разработчиков. Если я разработчик и только что закончил работу с обновлением A, а мой коллега завершил работу над обновлением B, я должен иметь возможность:
git checkout master
git checkout -b feature-a-b-together
git merge feature-a
git merge feature-b
git push origin feature-a-b-togetherКак по волшебству, будет создана динамическая среда: feature-a-b-together.staging.company.com или staging.company.com/feature-a-b-together.
Для создания динамических сред вы можете использовать, например, пространства имен Kubernetes.
Обратите внимание, что это нормально, если у вашей компании есть постоянные staging среды для специализированных нужд, таких как нагрузочное тестирование, тестирование на проникновения, развертывание A / B и т. д. Но для базового сценария «Я разработчик и хочу, чтобы моё обновление работало изолированно и запускались интеграционные тесты» динамические среды — лучшее решение.
Если вы все еще используете постоянные среды для тестирования обновлений, вы усложняете жизнь своим разработчикам, а также тратите системные ресурсы, когда ваши среды активно не используются.
9. Смешивание кластеров Production и Non-Production
Несмотря на то, что Kubernetes специально разработан для оркестрирования кластеров, вы не должны создавать единый кластер для всех ваших окружений. Как минимум у вас должно быть два кластера: производственный и непроизводственный.
Прежде всего, смешивание Production и Non-Production кластеров может привести к нехватке ресурсов.
Так как приложение, работающее некорректно, может утилизировать слишком много ресурсов.
Для разработчиков самая большая проблема связана с безопасностью. Если вы не предпринимаете дополнительных шагов по настройке Kubernetes, то вопреки распространенному мнению, под из одного пространства имен может свободно взаимодействовать с подом из другого пространства имен. Также есть некоторые ресурсы Kubernetes, которые вообще не имеют пространства имен.
Пространства имен Kubernetes не являются мерой безопасности. Если ваша команда обладает глубокими знаниями Kubernetes, то действительно можно поддерживать мультитенантность внутри кластера и защищать все рабочие нагрузки друг от друга. Но это требует значительных усилий, и в большинстве случаев гораздо проще создать второй кластер исключительно для production.
Если вы объедините этот антипаттерн со вторым (сохранение конфигурации внутри образов), должно стать очевидно, что может произойти множество негативных сценариев, например:
Разработчик создает новое пространство имен, используемое для тестирования и production.
Далее развертывается приложение и запускаются интеграционные тесты.
Интеграционные тесты записывают фиктивные данные или очищают БД.
К сожалению, в контейнерах были рабочие URL-адреса и конфигурация внутри них, и, таким образом, все интеграционные тесты фактически повлияли на работу production!
Чтобы не попасть в эту ловушку, гораздо проще просто создать Production и Non-Production кластера. К сожалению, многие руководства описывают сценарий при котором, пространства имен можно использовать для разделения сред, и даже в официальной документации Kubernetes есть примеры с пространствами имен prod / dev.
Обратите внимание, что в зависимости от размера вашей компании у вас может быть больше кластеров, чем два, например:
Production
Pre Production (Shadow) — клон production, но с меньшими ресурсами
Development кластер, который мы уже обсуждали выше
Специализированный кластер для нагрузочного тестирования / тестирования безопасности
И даже отдельный кластер для служебных инструментов
10. Развёртывание приложений без Limits
По умолчанию приложение, развернутое в Kubernetes, не имеет ограничений на использование ресурсов. Это означает, что ваше приложение потенциально может мешать работе всего кластера, поскольку утечка памяти или высокая загрузка ЦП нанесут ущерб остальным приложениям, работающим в кластере.
Это означает, что все ваши приложения (независимо от окружения) должны иметь ограничения на использование ресурсов.
К сожалению, просто взглянуть на среднюю загрузку памяти и ЦП приложением недостаточно. Вам необходимо изучить свое приложение и отследить всплески трафика и нагрузки, а также понять, как оно ведёт себя в этих условиях. Вы же не хотите, чтобы ваше приложение перезапускалось без причины.
Одно из преимуществ Kubernetes — эластичность ресурсов. Если кластер убивает / перезапускает ваше приложение, когда оно начинает обрабатывать значительную нагрузку (например, ваш интернет-магазин испытывает всплеск трафика), вы не используете все преимущества Kubenetes. Вы можете решить эту проблему с использованием vertical pod auto-scaler (VPA).
