Apache Spark или возвращение блудного пользователя
Продолжаем цикл статей про DMP и технологический стек компании Targetix.
На это раз речь пойдет о применении в нашей практике Apache Spark и инструментe, позволяющем создавать ремаркетинговые аудитории.
Именно благодаря этому инструменту, однажды посмотрев лобзик, вы будете видеть его во всех уголках интернета до конца своей жизни.
Здесь мы и набили первые шишки в обращении с Apache Spark.
Архитектура и Spark-код под катом.

Введение
Для понимания целей разъясним терминологию и исходные данные.
Что же такое ремаркетинг? Ответ на этот вопрос вы найдете в вики), а если коротко, то ремаркетинг (он же ретаргетинг) — рекламный механизм, позволяющий вернуть пользователя на сайт рекламодателя для совершения целевого действия.
Для этого нам требуются данные от самого рекламодателя, так называемая first party data, которую мы собираем в автоматическом режиме с сайтов, которые устанавливают у себя наш код — SmartPixel. Это информация о пользователе (user agent), посещённых страницах и совершённых действиях. Затем мы обрабатываем эти данные с помощью Apache Spark и получаем аудитории для показа рекламы.
Решение
Немного истории
Изначально планировалось написание на чистом Hadoop используя MapReduce задачи и у нас это даже получилось. Однако написание такого вида приложения требовало большого количество кода, в котором очень сложно разбираться и отлаживать.
Для примера трёх разных подходов мы приведём код группировки audience_id по visitor_id.
public static class Map extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
String[] split = s.split(" ");
context.write(new Text(split[0]), new Text(split[1]));
}
}
public static class Reduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
HashSet set = new HashSet<>();
values.forEach(t -> set.add(t));
ArrayWritable array = new ArrayWritable(Text.class);
array.set(set.toArray(new Text[set.size()]));
context.write(key, array);
}
}
public static class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJarByClass(Run.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(ArrayWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Затем на глаза нам попался Pig. Язык основанный на Pig Latin, который интерпретировал код в MapReduce задачи. Теперь для написания требовалось куда меньше кода, да и с эстетической точки зрения он был куда лучше.
A = LOAD '/data/input' USING PigStorage(' ') AS (visitor_id:chararray, audience_id:chararray);
B = DISTINCT A;
C = GROUP B BY visitor_id;
D = FOREACH C GENERATE group AS visitor_id, B.audience_id AS audience_id;
STORE D INTO '/data/output' USING PigStorage();
Вот только была проблема с сохранением. Приходилось писать свои модули для сохранения, т.к. разработчики большинства баз данных не поддерживали Pig.
Здесь то на помощь пришел Spark.
SparkConf sparkConf = new SparkConf().setAppName("Test");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
jsc.textFile(args[0])
.mapToPair(str -> {
String[] split = str.split(" ");
return new Tuple2<>(split[0], split[1]);
})
.distinct()
.groupByKey()
.saveAsTextFile(args[1]);
Здесь и краткость, и удобство, так же наличие многих OutputFormat, которые позволяют облегчить процесс записи в базы данных. Кроме того в данном инструменте нас интересовала возможность потоковой обработки.Нынешняя реализация
Процесс в целом выглядит следующим образом:
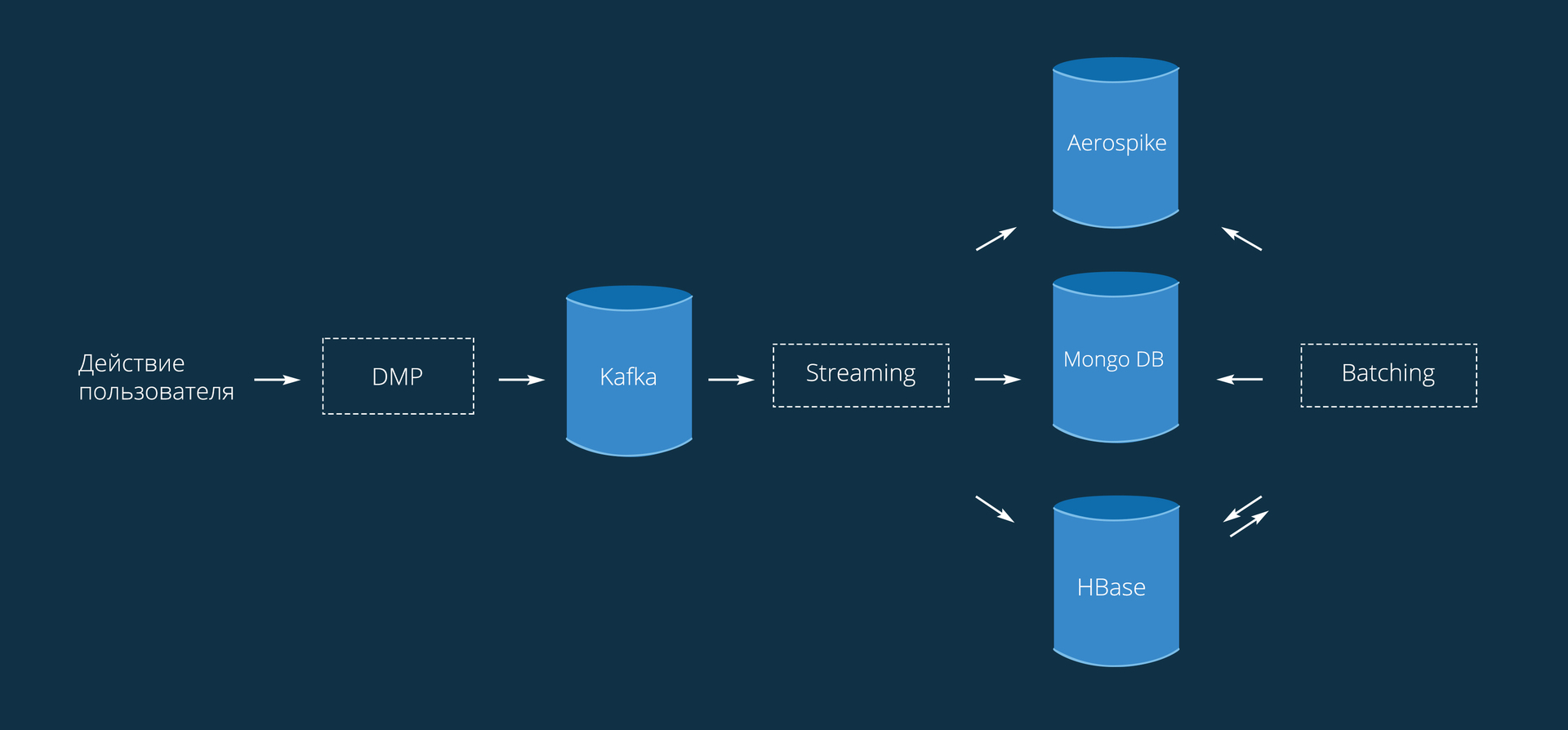
Данные попадают к нам со SmartPixel’ей, установленных на сайтах. Код приводить не будем, он очень простой и аналогичен любой внешней метрике. Отсюда данные приходят в виде { Visitor_Id: Action }. Под Action тут можно понимать любое целевое действие: просмотр страницы/товара, добавление в корзину, покупка или любое кастомное действие, установленное рекламодателем.
Обработка ремаркетинга состоит из 2 основных модулей:
- Потоковая обработка (streaming).
- Пакетная обработка (batching).
Потоковая обработка
Позволяет добавлять пользователей в аудитории в режиме реального времени. Мы используем Spark Streaming с интервалом обработки 10 секунд. Пользователь добавляется в аудиторию почти сразу после совершенного действия (в течение этих самых 10 секунд). Важно отметить, что в потоковом режиме допустимы потери данных в небольших количествах из-за пинга до баз данных или каких-либо других причин.
Главное — это баланс между временем отклика и пропускной способностью. Чем меньше batchInterval, тем быстрее данные обработаются, но много времени будет потрачено на инициализацию соединений и другие накладные расходы, так что за раз обработать можно не так много. С другой стороны, большой интервал позволяет за раз обработать большее количество данных, но тогда больше тратится драгоценного времени с момента действия до добавления в нужную аудиторию.
public class StreamUtil {
private static final Function, JavaRDD> eventTransformFunction =
rdd -> rdd.map(t -> Event.parseFromMsgPack(t._2())).filter(e -> e != null);
public static JavaPairReceiverInputDStream createStream(JavaStreamingContext jsc, String groupId, Map topics) {
HashMap prop = new HashMap() {{
put("zookeeper.connect", BaseUtil.KAFKA_ZK_QUORUM);
put("group.id", groupId);
}};
return KafkaUtils.createStream(jsc, String.class, byte[].class, StringDecoder.class, DefaultDecoder.class, prop, topics, StorageLevel.MEMORY_ONLY_SER());
}
public static JavaDStream getEventsStream(JavaStreamingContext jssc, String groupName, Map map, int count) {
return getStream(jssc, groupName, map, count, eventTransformFunction);
}
public static JavaDStream getStream(JavaStreamingContext jssc, String groupName, Map map,
Function, JavaRDD> transformFunction) {
return createStream(jssc, groupName, map).transform(transformFunction);
}
public static JavaDStream getStream(JavaStreamingContext jssc, String groupName, Map map, int count,
Function, JavaRDD> transformFunction) {
if (count < 2) return getStream(jssc, groupName, map, transformFunction);
ArrayList> list = new ArrayList<>();
for (int i = 0; i < count; i++) {
list.add(getStream(jssc, groupName, map, transformFunction));
}
return jssc.union(list.get(0), list.subList(1, count));
}
}
Для создания потока сообщений нужно передать контекст, необходимые топики и имя группы получателей (jssc, topics и groupId соответственно). Для каждой группы формируется свой сдвиг очереди сообщений по каждому топику. Также можно создавать несколько получателей для распределения нагрузки между серверами. Все преобразования над данными указываются в transformFunction и выполняются в том же потоке, что и получатели.
public JavaPairRDD conditions;
private JavaStreamingContext jssc;
private Map hlls;
public JavaStreamingContext create() {
sparkConf.setAppName("UniversalStreamingBuilder");
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
sparkConf.set("spark.storage.memoryFraction", "0.125");
jssc = new JavaStreamingContext(sparkConf, batchInterval);
HashMap map = new HashMap();
map.put(topicName, 1); // Kafka topic name and number partitions
JavaDStream events = StreamUtil.getEventsStream(jssc, groupName, map, numReceivers).repartition(numWorkCores);
updateConditions();
events.foreachRDD(ev -> {
// Compute audiences
JavaPairRDD rawva = conditions.join(ev.keyBy(t -> t.pixelId))
.mapToPair(t -> t._2())
.filter(t -> EventActionUtil.checkEvent(t._2(), t._1().condition))
.mapToPair(t -> new Tuple2<>(t._2().visitorId, t._1().id))
.distinct()
.persist(StorageLevel.MEMORY_ONLY_SER())
.setName("RawVisitorAudience");
// Update HyperLogLog`s
rawva.mapToPair(t -> t.swap()).groupByKey()
.mapToPair(t -> {
HyperLogLog hll = new HyperLogLog();
t._2().forEach(v -> hll.offer(v));
return new Tuple2<>(t._1(), hll);
}).collectAsMap().forEach((k, v) -> hlls.merge(k, v, (h1, h2) -> HyperLogLog.merge(h1, h2)));
// Save to Aerospike and HBase
save(rawva);
return null;
});
return jssc;
}
Здесь, чтобы соединить два (events и conditions) RDD (Resilient Distributed Dataset), используется join по pixel_id. Метод save — фейковый. Это сделано для того, чтобы разгрузить представленный код. На его месте должно находиться несколько преобразований и сохранений.
Запуск
public void run() {
create();
jssc.start();
long millis = TimeUnit.MINUTES.toMillis(CONDITION_UPDATE_PERIOD_MINUTES);
new Timer(true).schedule(new TimerTask() {
@Override
public void run() {
updateConditions();
}
}, millis, millis);
new Timer(false).scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
flushHlls();
}
}, new Date(saveHllsStartTime), TimeUnit.MINUTES.toMillis(HLLS_UPDATE_PERIOD_MINUTES));
jssc.awaitTermination();
}
Вначале создается и запускается контекст. Параллельно этому запускается 2 таймера для обновления условий и сохранения HyperLogLog. Обязательно в конце указывается awaitTermination (), иначе обработка закончится не начавшись.
Пакетная обработка
Раз в день перестраивает все аудитории, что решает проблемы устаревших и утерянных данных. Есть у ремаркетинга одна неприятная особенность для пользователя — навязчивость рекламы. Здесь вступает lookback window. Для каждого пользователя сохраняется дата его добавления в аудиторию, таким образом мы можем контролировать актуальность информации для пользователя.
Занимает 1.5–2 часа — все зависит от нагрузки на сеть. Причем большая часть времени это сохранение по базам: загрузка, обработка и запись в Aerospike 75 минут (выполняется в одном pipeline), остальное время — сохранение в HBase и Mongo (35 минут).
JavaRDD> av = HbaseUtil.getEventsHbaseScanRdd(jsc, hbaseConf, new Scan())
.mapPartitions(it -> {
ArrayList> list = new ArrayList<>();
it.forEachRemaining(e -> {
String pixelId = e.pixelId;
String vid = e.visitorId;
long dt = e.date.getTime();
List cond = conditions.get(pixelId);
if (cond != null) {
cond.stream()
.filter(condition -> e.date.getTime() > beginTime - TimeUnit.DAYS.toMillis(condition.daysInterval)
&& EventActionUtil.checkEvent(e, condition.condition))
.forEach(condition -> list.add(new Tuple3<>(condition.id, vid, dt)));
}
});
return list;
}).persist(StorageLevel.DISK_ONLY()).setName("RawVisitorAudience");
Здесь почти то же, что и в потоковой обработке, но не используется join. Вместо него используется проверка event по списку condition с таким же pixel_id. Как оказалось, такая конструкция требует меньше памяти и выполняется быстрее.
Сохранение в базы
Сохранение из Kafka в HBase изначально было зашито в потоковый сервис, но из-за возможных сбоев и отказов было решено вынести его в отдельное приложение. Для реализации отказоустойчивости использовался Kafka Reliable Receiver, который позволяет не терять данные. Использует Checkpoint для сохранения метаинформации и текущих данных.
Количество записей в HBase на текущий момент около 400 миллионов. Все события хранятся в базе 180 дней и удаляются по TTL.
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable", "true");
jssc.checkpoint(checkpointDir);
Теперь вместо
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, batchInterval);
используем
JavaStreamingContext jssc = JavaStreamingContext.getOrCreate(checkpointDir, new ВашРеализованыйКласс());
Сохранение в Aerospike происходит при помощи самописного OutputFormat и Lua-скрипта. Для использования асинхронного клиента пришлось дописать два класса к официальному коннектору (форк).
public class UpdateListOutputFormat extends com.aerospike.hadoop.mapreduce.AerospikeOutputFormat {
private static final Log LOG = LogFactory.getLog(UpdateListOutputFormat.class);
public static class LuaUdfRecordWriter extends AsyncRecordWriter {
public LuaUdfRecordWriter(Configuration cfg, Progressable progressable) {
super(cfg, progressable);
}
@Override
public void writeAerospike(String key, Bin bin, AsyncClient client, WritePolicy policy, String ns, String sn) throws IOException {
try {
policy.sendKey = true;
Key k = new Key(ns, sn, key);
Value name = Value.get(bin.name);
Value value = bin.value;
Value[] args = new Value[]{name, value, Value.get(System.currentTimeMillis() / 1000)};
String packName = AeroUtil.getPackage(cfg);
String funcName = AeroUtil.getFunction(cfg);
// Execute lua script
client.execute(policy, null, k, packName, funcName, args);
} catch (Exception e) {
LOG.error("Wrong put operation: \n" + e);
}
}
}
@Override
public RecordWriter getAerospikeRecordWriter(Configuration entries, Progressable progressable) {
return new LuaUdfRecordWriter(entries, progressable);
}
}
Асинхронно выполняет функцию из указанного пакета.
В качестве примера представлена функция добавления в список новых значений.
local split = function(str)
local tbl = list()
local start, fin = string.find(str, ",[^,]+$")
list.append(tbl, string.sub(str, 1, start - 1))
list.append(tbl, string.sub(str, start + 1, fin))
return tbl
end
local save_record = function(rec, name, mp)
local res = list()
for k,v in map.pairs(mp) do
list.append(res, k..","..v)
end
rec[name] = res
if aerospike:exists(rec) then
return aerospike:update(rec)
else
return aerospike:create(rec)
end
end
function put_in_list_first_ts(rec, name, value, timestamp)
local lst = rec[name]
local mp = map()
if value ~= nil then
if list.size(value) > 0 then
for i in list.iterator(value) do
mp[i] = timestamp end
end
end
if lst ~= nil then
if list.size(lst) > 0 then
for i in list.iterator(lst) do
local sp = split(i)
mp[sp[1]] = sp[2] end
end
end
return save_record(rec, name, mp)
end
Этот скрипт добавляет в список аудиторий новые записи вида «audience_id, timestamp». Если запись существует, то timestamp остается прежним.
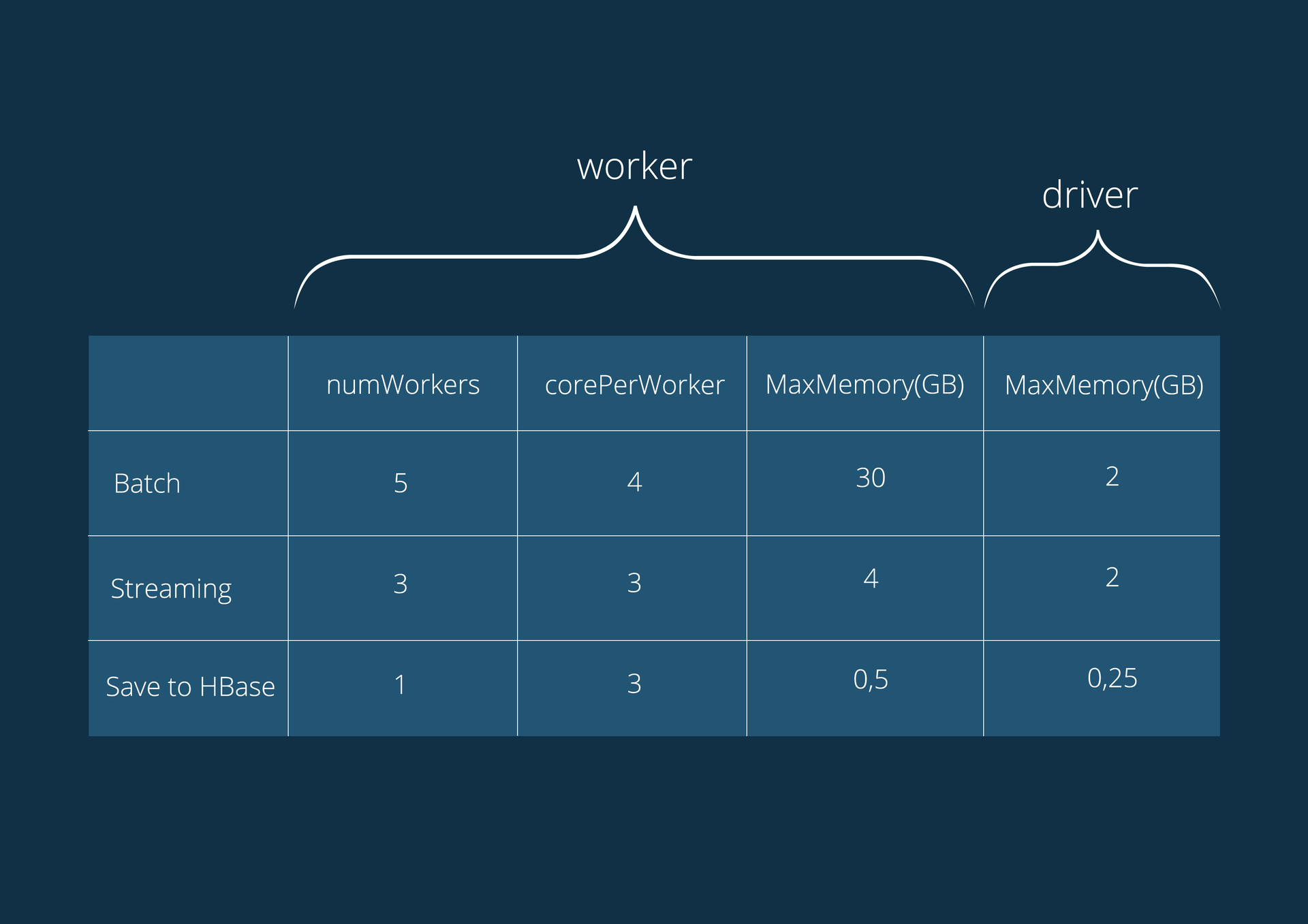
Характеристики серверов, на которых работают приложения:
Intel Xeon E5–1650 6-cores 3.50 GHz (HT), 64GB DDR3 1600;
Операционная система CentOS 6;
Версия CDH 5.4.0.
Конфигурация приложений:
В заключении
На пути к данной реализации мы опробовали несколько вариантов (С#, Hadoop MapReduce и Spark) и получили инструмент, который одинаково хорошо справляется как с задачами потоковой обработки, так и пересчётов огромных массивов данных. За счёт частичного внедрения лямбда архитектуры, повысилось переиспользование кода. Время полной перестройки аудиторных каналов, снизилось с десятка часов, до десятка минут. А горизонтальная масштабируемость стала как никогда простой.
Попробовать наши технологии вы всегда можете на нашей платформе Hybrid.
P.S.
Особая благодарность выражается DanilaPerepechin за неоценимую помощь в написании статьи.
