Apache Cassandra: механизмы репликации и поддержания согласованности
Apache Cassandra — это распределенная NoSQL база данных. В этой статье будут описаны основные механизмы передачи, репликации и поддержания согласованности данных внутри сети.
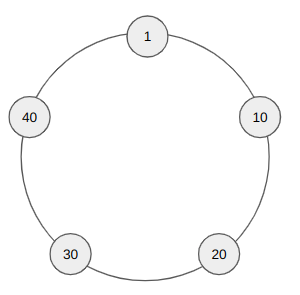
Сразу перейдем к примерам. Пусть мы имеем 5 отдельных серверов, которые мы объединили в единую сеть — кластер. Каждому узлу сети (ноде) присваивается некоторое уникальное значение (токен), получаемое хешированием ее IP адреса. Таким образом, внутри кластера мы можем расположить ноды на кольце так, чтобы значения значения ключей шли от меньшего к большему по часовой стрелке, соответственно максимальное значение переходит в минимальное. На картинке для простоты токен будем представлять в виде двухзначного числа.
Cassandra можно назвать смесью key-value и табличных баз данных. Допустим у нас есть следующая обычная таблица, в которой мы храним id пользователей, их email и номер.
id | phone | |
05 | 05@ya.ru | 05–05–05 |
17 | 17@ya.ru | 17–17–17 |
21 | 21@ya.ru | 21–21–21 |
36 | 36@ya.ru | 36–36–36 |
44 | 44@ya.ru | 44–44–44 |
Cassandra разбивает таблицу по ее primary key (в данном случае это id пользователей) и формирует так называемые partition key, которое будем называть просто ключом строки. В рамках ключа происходит формирование строк, каждая их которых имеет имя колонки, временную метку (timestamp) и значение. Но важное отличие Cassandra от реляционных СУБД состоит в том, что разные ключи могут хранить различные колонки.
Также Cassandra формирует семейства колонок (column family), которые могут содержать в себе различные наборы ключей. Это можно сравнить с разными таблицами. Для более сложной логики БД и тяжелых запросов обычные column family вы можете объединять в super column family. В сегодняшних примерах мы будем работать с единственным семейством колонок.
Запись данных
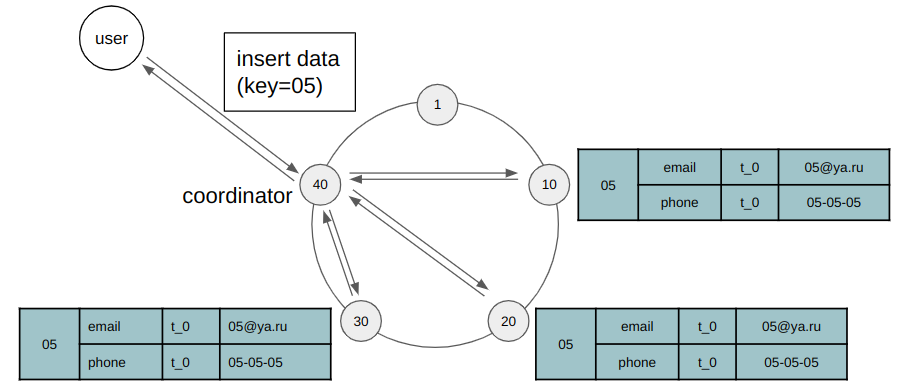
Пусть вы хотите записать в кластер первую строку нашей таблицы. В кластере все ноды равноправны, поэтому неважно куда именно придет запрос. Это решит драйвер, который скорей всего отправит данные на ближайший к вам сервер. Узел, получивший данные, называется координатором для этого ключа. Далее координатор формирует токен, хешируя ключ, и определяет на какую ноду переслать данные. Здесь также для простоты будем считать, что токеном является ключ, то есть id пользователя.
Данная запись отправляется первому узлу ключ, которого равен или больше ключа нашей записи, а также реплицируется последующим n-1 узлам, где n — это коэффициент репликации (replication factor — RF), который вы задаете для своей системы самостоятельно. Он регулирует избыточность данных в системе. Обычно n равняется 3 или 5, но важно, чтобы это было нечетное число, чтобы было возможно определять большинство. В данном примере RF = 3.
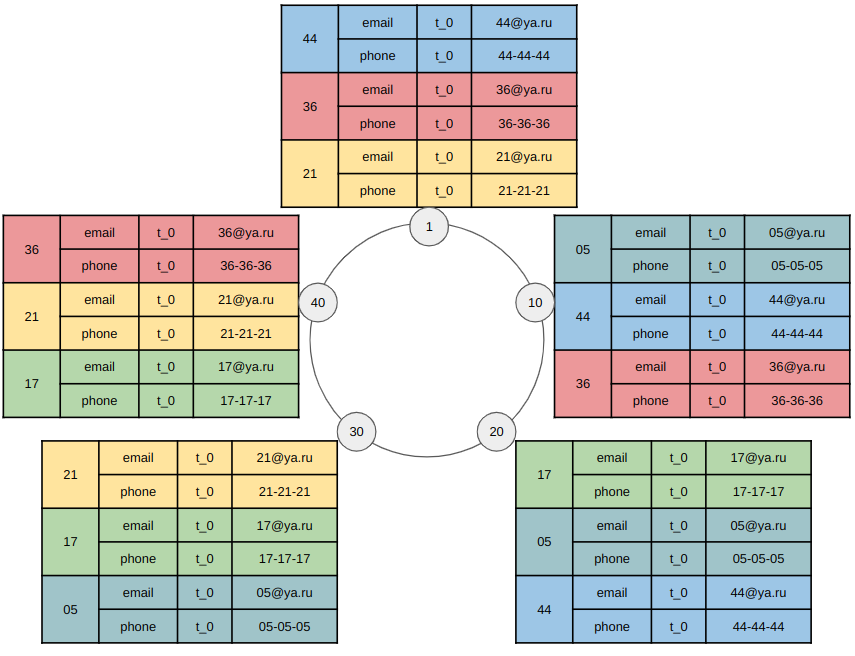
А вот как распределятся остальные строки таблицы.
Согласованность данных
В Cassandra вы можете выбирать различные настройки согласованности (consistency) данных на запись и на чтение. Данные настройки влияют на то, сколько подтверждений должен получить координатор, чтобы сообщить пользователю, что его запрос завершен успешно. Есть следующие варианты задания consistency level.
ANY: запрос считается обработанным, как только координатор получил его.
ONE, TWO, THREE: ожидание подтверждения от 1, 2 и 3 нод соответственно с любого кластера.
LOCAL_ONE: ожидание подтверждения от 1 ноды в кластере координатора.
QUORUM: ожидание подтверждения от большинства реплик-нод со всех кластеров. То есть если у вас есть 2 кластера при RF=3, то необходимо дождаться подтверждения от 4 любых нод (4 > 6/2).
LOCAL_QUORUM: ожидание подтверждения от кворума нод в кластере координатора. То есть в аналогичной ситуации с 2 кластерами при RF=3 необходимо дождаться подтверждения от 2 нод текущего кластера (2 > 3/2).
EACH_QUORUM: ожидание подтверждения от кворума нод с каждого кластера.
ALL: дожидаемся ответа со всех реплик-нод всех кластеров.
Consistency level на чтение задается точно также за исключением ANY.
Важно, что для достижения полной согласованности данных в конечном счете (eventual consistency), то есть при чтении вы всегда будете получать самые свежие записи, необходимо выполнение следующего условия. Суммарное количество подтверждений от реплик на запись и чтение должно быть строго больше чем ваш replication factor: W + R > RF.
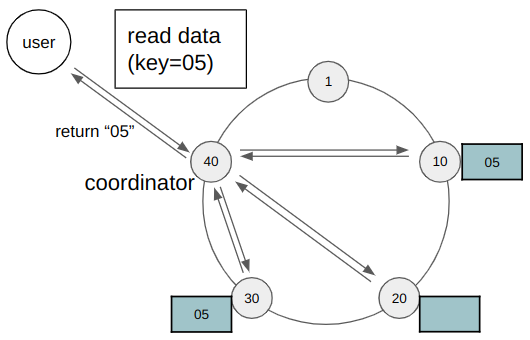
Продолжая предыдущий пример, пусть по какой-то причине в узел с ключом 20 не записались данные, то при сonsistency level = quorum на запись и на чтение, пользователь при чтении все равно получит самое обновленное состояние ключа 05, так как 2 + 2 > 3. Аналогичного поведения можно достигнуть, например, при использовании ALL на запись и ONE на чтение. И наоборот при ONE на запись и ALL на чтение.
Timestamps
Cassandra использует подход Last Write Wins, согласно которому временные метки (timestamps) запросов определяют порядок приоритета операций. Этот подход может привести к некоторой потере данных, но в отличие от логических часов это сильно повышает скорость работы системы.
В Cassandra версии 2.0 и ниже временные метки запросам назначал узел-координатор, в момент получения данных. Это приводило к различным проблемам.
Например, пользователь делает последовательные запросы на запись в одну колонку определенного ключа: q_1 и q_2, но по каким-то причинам запросы попали к разным координаторам: q_1 к более дальнему и получил временную метку t_10, а q_2 к более близком и получил метку t_8. Соответственно ноды-реплики обработают запросы неправильно, а именно запрос q_2 будет отклонен, так как t_8 < t_10. При чтении пользователь увидит значение, записанное запросом q_1, когда как ожидает запись от q_2.
Подобная ситуация может произойти и при отправке запросов одному координатору, но из-за банальной задержки в сети запрос q_1 все равно может получить более позднюю временную метку. Именно поэтому, начиная с версии 2.1, временные метки формируются на стороне клиента.
Несмотря на подобное формирование timestamps, запросы могут прийти с одинаковыми временными метками, так как в Cassandra время округляется до микросекунд. В таком случае сначала выполняются запросы на удаление, а затем уже на вставку и обновление. При совпадении операций, приоритет на выполнение имеет лексикографически большая операция. То есть при записи в колонку значения 1 или 2 будет записано 2.
Естественно при формировании timestamps на стороне клиентов всем необходимо постоянно синхронизировать свои часы, что иногда может быть затруднительно.
Масштабирование
Если необходимо добавить новый узел в кластер, то узлу назначается такой токен, чтобы разгрузить сильно загруженные узлы. В примере для наглядности в узлах не показаны реплицированные данные, то есть случай, когда replication factor равен 1. В иной ситуации данные, реплицированные с предыдущей ноды по кольцу, тоже перемещаются на новую ноду. Также на практике для ускорения работы перемещение данных происходит не только с исходной ноды, а также происходит копирование с других реплик для распараллеливания процесса.
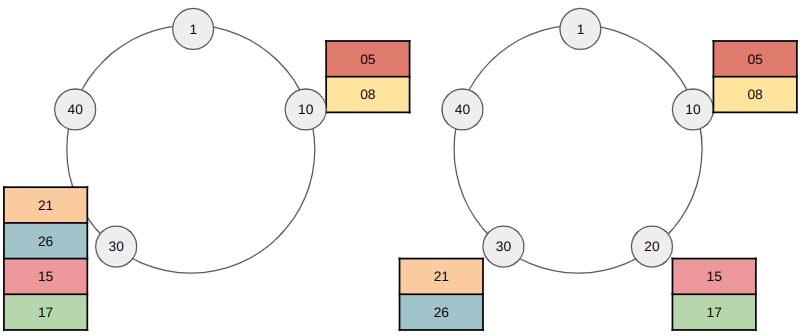
Падение узла
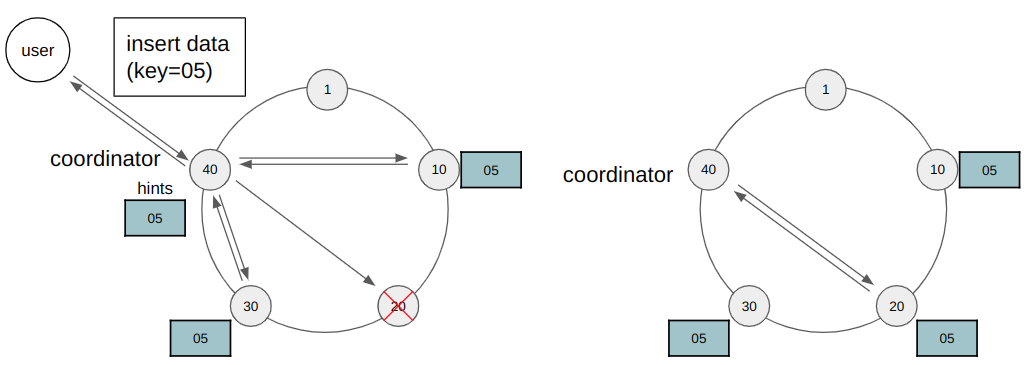
Пусть клиент хочет записать некоторые данные по ключу 05, но один из узлов вышел из строя по каким-либо причинам. Тем не менее координатор получит кворум голосов и сообщит клиенту об успешной операции. При этом он запомнит запрос о записи. Как только нода вернется в работу, координатор отправит ей необходимый запрос. Данный подход называется hinted handoff. Стандартно у ноды есть 3 часа, чтобы вернуться в сеть, иначе координатор подчистит данный запрос и реплики останутся рассинхронизированы. Это исправляется с помощью read repair и anti-entropy repair.
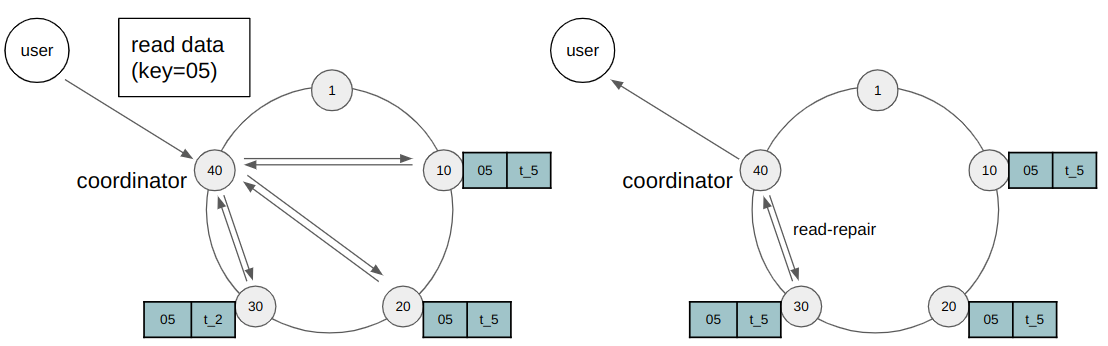
Read repair
Возникшая несогласованность может быть исправлена с помощью read repair. Данный механизм работает при запросах на чтение. Допустим пользователь хочет прочитать данные по ключу 05. Для этого координатор опрашивает реплики. И если он обнаружит, что реплики не согласованы, то он обновит данные там, где это необходимо. Важно, что клиенту не будет возвращен результат чтения, пока не завершится read repair. Блокировка чтения используется, чтобы при последовательных запросах на чтение клиент не получил более старые данные.
Anti-entropy repair
Тем не менее для согласованности периодически нужно вручную запускать anti-entropy repair. Для этого по каждому узлу строится двоичное дерево хешей (дерево Меркла), листья которого — это хэши отдельного взятых ключей. Каждый родитель является хэшем своих детей. Такая структура позволяет быстро сравнивать ноды между собой, находить в каких диапазонах ключей они различаются и исправлять данные.
Выводы
Cassandra прекрасная распределенная база данных. Она абсолютно отказоустойчива, в ней нет единой точки отказа, так как все узлы в кластерах равноправны. Также Cassandra обеспечивает практически линейную масштабируемость при увеличении объёма данных.
