Учим Алису здороваться
Хочу поделиться опытом добавления некоторой вольности Алисе (внутри колонок поддерживающих локальный API).

О локальном API колонок уже писали тут.
Идея заключается в том, чтобы Алиса реагировала на присутствующих людей. Для этого их необходимо идентифицировать, например, с помощью распознавания лиц. В статье будет использован самый простой (на мой взгляд), вариант создания модели для распознавания — тренировка модели в Google Teachable Machine, так как он не требует знаний и хорошего железа.
Для управления колонкой используется модуль node-red-contrib-yandex-station-management для Node-Red позволяющий отправлять на колонку текст, который произнесет Алиса (а так же посылать команды, управлять воспроизведением и получать статус колонки). Еще Алиса в случайное время будет выдавать некоторую «отсебятину».
Все скрипты, упомянутые в статье, и инструкции по их запуску и настройке можно скачать из репозитория.
Используемые инструменты: Все действия выполнялись на:
Intel NUC core i5
4GB RAM
Видеокарта Haswell-ULT Integrated Graphics Controller (не задействована).
Веб камера для сбора лиц и отладки
Камера выдающая RTSP поток для основной задачи
ОС Ubuntu Server 20.04
В репозитории присутствует файл docker-compose.yml для быстрой установки Node-Red, MQTT и PostgreSQL. Инструкцию по установке docker-compose можно почитать тут. Основной скрипт запускается без использования docker.
Для установки Tensorflow и OpenCV в Ubuntu 20.04 необходимо выполнить:
sudo apt install python3-venv python3-dev
pip3 install opencv-python@4.5.1 tensorflow@2.10.0 paho
Статьи про установку и настройку вышеперечисленных сервисов без использования Docker:
Принцип работы:
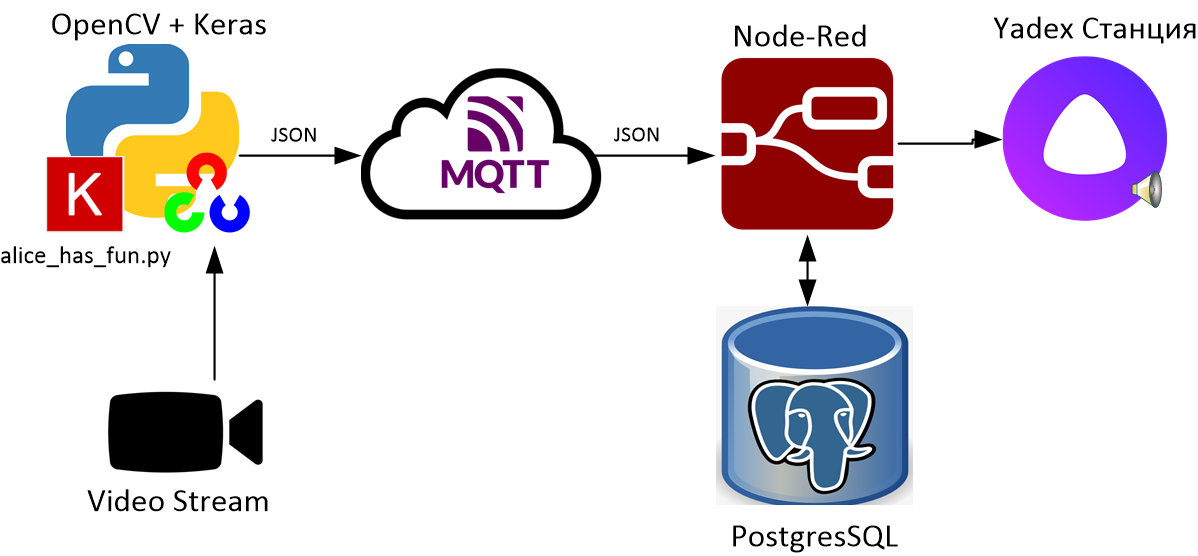
Скрипт
alice_has_fun.pyраспознает лица и отправляет процент совпадения в MQTT брокер в формате json;Node-Red получает сообщения об обнаружении людей из MQTT, для каждого лица получает из БД время его последней фиксации и обновляет его на текущее;
В зависимости от времени суток и того, как давно система фиксировала человека, Node-Red отправляет на станцию команду сказать что-либо. Фразы для Алисы, а так же время последней фиксации хранятся в БД PostgreSQL;
Основной поток в Node-Red:

При первом запуске docker-compose необходимо настроить блок My Yandex Station станции, потоки добавляются автоматически.
Настройка блока Yandex Station:
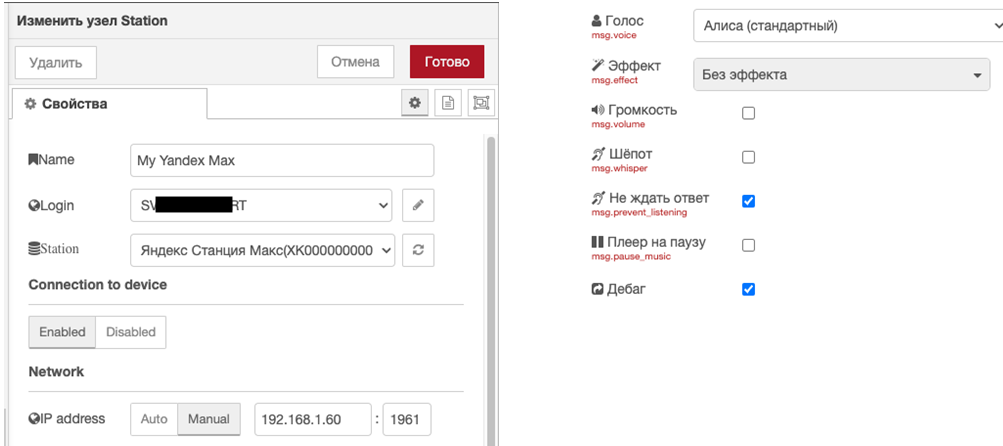
Если станция имеет статический IP адрес лучше использовать режим Manual для наиболее быстрого обнаружения станции.
В настройках блока можно выставить ожидание ответа (и Алиса действительно отвечает, если послать ей фразу как дела и ответить хорошо, она за вас порадуется), голос, шепот и прочее.
Цепочка, которая начинается с блока alice_fun, срабатывает в случайное время, кратное заданной в настройках блока задержке, и Алиса произносит случайную фразу из списка Fun без ожидания ответа. В блоке rand3 можно установить ограничение, чтобы Алиса не болтала ночью.
Для того чтобы Алиса произносила фразы последовательно и не прерывала сама себя создан подпоток Say by case:

Подпоток организует очередь фраз и блокирует отправку последующих сообщений на 3 секунды каждый раз когда отправляет Алисе очередную, так же выполняется проверка текущего состояния колонки, если колонка слушает или говорит в данный момент очередь блокируется.
Для более удобного добавления новых фраз в БД присутствует поток UI. Так же добавлен UI управления воспроизведением, спасибо twocolors.

Создание модели для распознавания лиц
В репозитории присутствует скрипт collect_images.py для сбора лиц и сохранения их в коллекцию. Я собирал примерно по 150–300 вариантов для каждого человека. Скрипт запускается следующим образом:
python3 collect_images.py -i
source:
0 — Первая веб камера
Поток («rtsp://192.168.1.86:8554/unicast»)
Расположение медиа файла («raw/IMG_2404.MOV»)
face_name: Имя поддиректории куда будут сохранены выделенные лица
Перед камерой, не сильно артикулируя и слегка покручивая головой, рассказываем что ни будь, пока не наберется нужное количество фото. То же проделываем с парой друзей. Коллекции сохраняются в директорию detected:
Полученные коллекции необходимо добавить в Google Teachable Machine, обучить и скачать готовую модель в формате Keras h5. Для проверки модели можно показывать фото участников в камеру.
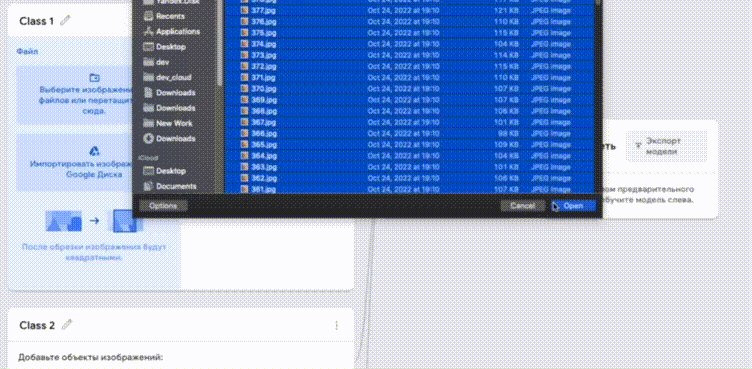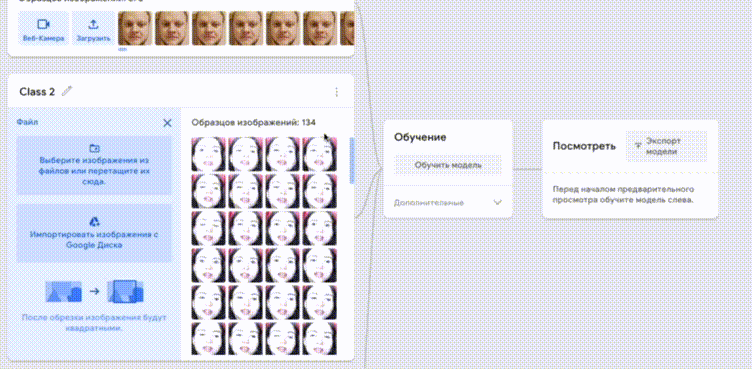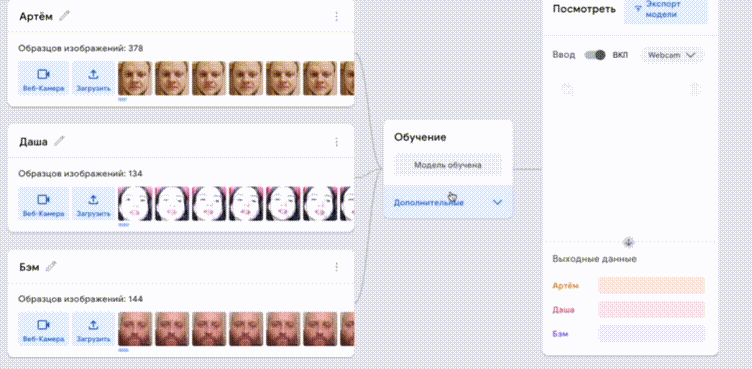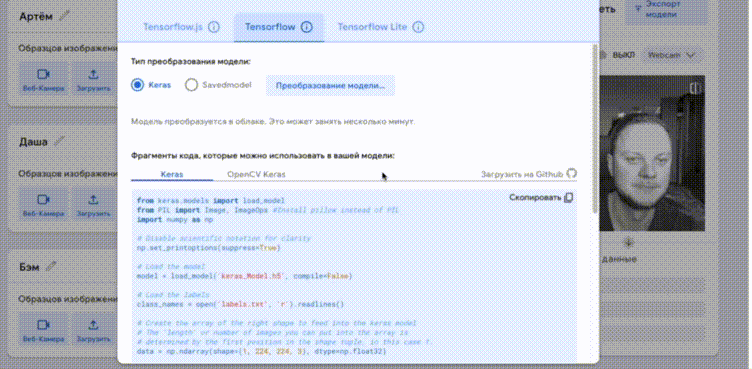
Модель в формате h5 вместе с файлом labels.txt необходимо скопировать в директорию со скриптом alice_has_fun.py. В файле labels.txt первый столбец содержит порядковый номер класса, его можно убрать.
Для запуска Node-Red, PorstgerSQL и Mosquitto необходимо выполнить:
docker-compose up -d
После того как все сервисы запущены и настроены, необходимо отредактировать файл конфигурации config.json в котором задаются различные параметры.
Описание параметров config.json:
{
"mqtt_pub": true,
"show_camera": false,
"input_source": 0,
"frame_recognition_rate": 4,
"publish_min_dalay": 1,
"camera_w": 1080,
"camera_h": 720,
"mqtt_broker": "127.0.0.1",
"mqtt_port": 11883,
"save_on_detect": true,
"draw_rect": true,
"min_predict_threshold": 65
}
Параметр | Назначение |
|---|---|
mqtt_pub | Елси True то рзультаты не публикуются в MQTT брокер |
show_camera | Елси True то с помощью cv2.imshow отображается видео из источника |
input_source | Число (0 это первая веб камера), адрес потока («rtsp://192.168.1.86:8554/unicast») или расположение видео файла («raw/IMG_2404.MOV») |
frame_recognition_rate | Частота распознавания кадров в секунду |
publish_min_dalay | Задержка перед публикацией, публикуются средние значения из распознаных кадров |
camera_w | Ширина видео для устройств поддерживающих задание разрешения видео |
camera_h | Высота видео для устройств поддерживающих задание разрешения видео |
mqtt_broker | Адрес MQTT брокера |
mqtt_port | Порт MQTT брокера |
save_on_detect | Помимо публикации в брокер также будет сохранен кадр в директорию on_detect |
draw_rect | выделять лица |
min_predict_threshold | минимальный процент совпадения для публикации |
После того как лица выделены и выполнено предсказание, его результат публикуется в MQTT брокер. Если частота распознавания выше чем частота публикации, например, распознавание 4 кадра в секунду, а публикация 1 раз в секунду, то публикуется наибольшее значение предсказаний преодолевших порог.
Запуск:
python3 alice_has_fun.py
Проверка работоспособности
Если все настроено правильно в консоли будут появляться сообщения вроде:
1/1 [==============================] - 0s 44ms/step
1/1 [==============================] - 0s 48ms/step
1/1 [==============================] - 0s 45ms/step
1/1 [==============================] - 0s 42ms/step
Creating Images........../on_detect/2022-11-13/2022-11-13_13_59_59.jpg
Send {"Бэм": 71.39} to topic for_alice/peoples
1/1 [==============================] - 0s 45ms/step
1/1 [==============================] - 0s 48ms/step
Видео демонстрация:
Исходный код проекта.
P.S. Используемый способ создания модели не является оптимальным и используется лишь для того, чтобы уменьшить порог вхождения в данную область. Если кто — то разбирается в технологиях распознавания лиц и есть идеи по улучшению проекта, пожалуйста, напишите об этом в комментариях.
