[Перевод - recovery mode ] Самый быстрый и безопасный PNG декодер в мире
TL; DR: декодер изображений PNG из стандартной библиотеки языка программирования Wuffs работает в 1.22–2.75 раза быстрее, чем libpng (широко используемая реализация PNG декодера на C с открытым исходным кодом), C-библиотеки libspng, lodepng и stb_image, а также самые популярные библиотеки для работы с PNG на Go и Rust.
Декодирование PNG с помощью Wuffs обсуждалось на Hacker News №1, Hacker News №2, /r/programming, /r/rust и lobste.rs.
Вступление
PNG (Portable Network Graphics) — это один из самых распространенных форматов для сжатия изображений без потерь, основанный на алгоритме сжатия zlib. Он был изобретен в 1990-х годах, когда доминировали 16-битные CPU, а максимальный размер оперативной памяти в 64 Кб все еще был насущной проблемой. Более современные форматы изображений (например, WebP) и алгоритмы сжатия (например, Zstandard) могут сжимать изображения более эффективно при сравнимых скоростях декодирования, но миллиарды существующих PNG затрудняют миграцию. По одной из метрик PNG по-прежнему является наиболее используемым форматом изображений в Интернете. Кроме того, телеметрия Mozilla IMAGE_DECODE_SPEED_XXX (выборка от 03.04.2021, Firefox Desktop nightly 89) ставит PNG на второе место после JPEG:
В большинстве случаев для декодирования PNG применяется libpng — широко распространенная рефернсная open-source реализация энкодера и декодера PNG, построенная на базе библиотеки zlib, аналогично широко распространенной реализации формата (алгоритма) сжатия zlib.
Wuffs — это memory-safe язык программирования XXI века со стандартной библиотекой, написанной на нем самом. Он предназначен для безопасной работы с «небезопасными» форматами файлов (Wrangling Untrusted File Formats Safely).
Прим. пер.: Wuffs можно использовать либо как самостоятельный язык программирования (Wuffs-the-language), либо как C-бибилиотеку, так как исходный код на Wuffs транспилируется в C (Wuffs-the-library). В статье будет идти речь об использовании Wuffs как C библиотеки.
На ноутбуке средней ценовой категории с x86_64 CPU (актуально на 2021 год — прим. пер.) Wuffs может декодировать PNG изображения в 1.5–2.75 раза быстрее, чем libpng:
libpng_decode_19k_8bpp 58.0MB/s ± 0% 1.00x
libpng_decode_40k_24bpp 73.1MB/s ± 0% 1.00x
libpng_decode_77k_8bpp 177MB/s ± 0% 1.00x
libpng_decode_552k_32bpp_ignore_checksum 146MB/s ± 0% (*)
libpng_decode_552k_32bpp_verify_checksum 146MB/s ± 0% 1.00x
libpng_decode_4002k_24bpp 104MB/s ± 0% 1.00x
libpng 1.00x to 1.00x
----
wuffs_decode_19k_8bpp/clang9 131MB/s ± 0% 2.26x
wuffs_decode_40k_24bpp/clang9 153MB/s ± 0% 2.09x
wuffs_decode_77k_8bpp/clang9 472MB/s ± 0% 2.67x
wuffs_decode_552k_32bpp_ignore_checksum/clang9 370MB/s ± 0% 2.53x
wuffs_decode_552k_32bpp_verify_checksum/clang9 357MB/s ± 0% 2.45x
wuffs_decode_4002k_24bpp/clang9 156MB/s ± 0% 1.50x
wuffs_decode_19k_8bpp/gcc10 136MB/s ± 1% 2.34x
wuffs_decode_40k_24bpp/gcc10 162MB/s ± 0% 2.22x
wuffs_decode_77k_8bpp/gcc10 486MB/s ± 0% 2.75x
wuffs_decode_552k_32bpp_ignore_checksum/gcc10 388MB/s ± 0% 2.66x
wuffs_decode_552k_32bpp_verify_checksum/gcc10 373MB/s ± 0% 2.55x
wuffs_decode_4002k_24bpp/gcc10 164MB/s ± 0% 1.58x(*) В «упрощенном API» libpng нет возможности отключить проверку контрольной суммы, поэтому для libpng в кейсах *_ignore_checksum мы используем результаты для кейсов *_verify_checksum.
В бенчмарках используется следующая нотация: 77k_8bpp означает PNG изображение шириной 160 пикселей, высотой 120 пикселей и цветовой моделью размером 8 бит (размер индекса палитры) на один пиксель. При декодировании в формат 32bpp BGRA получается 160 × 120 × 4 = 76800 байт, сокращенно 77k. Другие примеры (dst — выходной формат, src — входной формат):
Обработка 4002k байт со скоростью 104 Мб/с или 164 Мб/с означает, что libpng или Wuffs требуется около 38 миллисекунд или 24 миллисекнуды соответственно для декодирования данного изображения размером 1165 × 859.
Замеры для некоторых других реализаций PNG (libspng, lodepng, stb_image, image/png из стандартной библиотеки языка Go и реализации PNG на Rust) представлены в Приложении.
Примеры команд из статьи получены с помощью примеров кода, доступных в репозитории Wuffs.
Используемые техники оптимизации
Сначала пара слов о том, как вообще устроен формат PNG. Процесс декодирования PNG состоит из следующих основных этапов (приведены самые ресурсозатратные операции):
Два алгоритма хэширования для вычисления контрольных сумм — CRC-32 и Adler-32. Оба создают 32-битные хэши, но сами алгоритмы отличаются.
Декомпрессия с помощью алгоритма DEFLATE.
2D фильтрация (своего рода подготовка данных для сжатия, позволяющая учесть двумерность данных — прим. пер.): зачастую эффективнее сжимать разность цветов соседних пикселей нежели сами цвета пикселей.
Каждый из этих этапов может быть оптимизирован.
Вычисление и проверка контрольных сумм
CRC-32
В статье 2009 года «Fast CRC Computation for Generic Polynomials Using PCLMULQDQ Instruction» рассказывается о том, как реализовать вычисление CRC-32 используя x86_64 SIMD-инструкции. Реализация этой техники в Wuffs выглядит примерно так. Код для ARM еще проще, так как ARM имеет отдельные инструкции для вычисления CRC-32.
Для оценки производительности различных реализаций хэш-функций существует набор тестов и бенчмарков SMHasher. Согласно этим бенчмаркам, наша реализация CRC-32 с SIMD в 47 раз быстрее, чем наивная реализация CRC-32 в SMHasher.
Что касается реальной производительности, то пример example/crc32 из Wuffs более-менее эквивалентнен программе /bin/crc32 из Debian с точки зрения функциональности, но при этом этом он в 7.3 раз быстрее (0.056 секунд против 0.410 секунд) на этом файле размером 178 Мб:
$ ls -lh linux-5.11.3.tar.gz | awk '{print $5 " " $9}'
178M linux-5.11.3.tar.gz
$ g++ -O3 wuffs/example/crc32/crc32.cc -o wcrc32
$ time ./wcrc32 /dev/stdin < linux-5.11.3.tar.gz
05b309fb
real 0m0.056s
$ time /bin/crc32 /dev/stdin < linux-5.11.3.tar.gz
05b309fb
real 0m0.410sAdler-32
Об ускорении вычисления хэш-функции Adler-32 с помощью SIMD-инструкций не написано статей (актуально на 2021 год — прим. пер.), однако это возможно: вот реализации для ARM и x86_64 в Wuffs.
Реализация Adler-32 из Wuffs примерно в 6.4 раза быстрее (11.3 ГБ/с против 1.76 ГБ/с), чем реализация из zlib (указана как mimic_*) согласно benchstat:
$ cd wuffs
$ # ¿ is just an unusual character that's easy to search for. By
$ # convention, in Wuffs' source, it marks build-related information.
$ grep ¿ test/c/std/adler32.c
// ¿ wuffs mimic cflags: -DWUFFS_MIMIC -lz
$ gcc -O3 test/c/std/adler32.c -DWUFFS_MIMIC -lz
$ # Run the benchmarks.
$ ./a.out -bench | benchstat /dev/stdin
name speed
wuffs_adler32_10k/gcc10 11.3GB/s ± 0%
wuffs_adler32_100k/gcc10 11.6GB/s ± 0%
mimic_adler32_10k/gcc10 1.76GB/s ± 0%
mimic_adler32_100k/gcc10 1.72GB/s ± 0%Игнорируем контрольные суммы
Очевидно, что самая быстрый способ проверить контрольную сумму — это не проверять ее вообще, пропуская эти значения при чтении PNG файла. Согласно результатам бенчмарка для *_ignore_checksum против *_verify_checksum, приведенных ранее, разница в производительности составляет около 4%. Разница не слишком большая, однако, как было уже сказано, отключение проверки контрольных сумм в libpng составляет проблему, но для Wuffs это можно сделать одной строкой. Однако, если вы используете альтернативный декодер PNG (не Wuffs), то отключение проверки контрольных сумм может ускорить декодирование даже больше, чем на 4% в случае, если декодер не использует SIMD-оптимизированную реализацию хэш-функций. При этом следует помнить, что отключение проверки контрольных сумм — это компромисс: мы теряем возможность обнаружить повреждение данных и таким образом, вообще говоря, отклоняемся от спецификации PNG, которая прямо предписывает это делать.
Декомпрессия DEFLATE
Основная часть данных после сжатия с помощью DEFLATE состоит из последовательности кодов: либо «символьных» кодов (фактически исходных данных), либо кодов копирования. Существует 256 возможных символьных кодов, по одному на каждый возможный распакованный байт. Каждый код копирования состоит из длины (сколько байт нужно скопировать, от 3 до 258 включительно) и расстояния (с какого места в «истории» или в ранее распакованном выводе нужно скопировать, от 1 до 32768 включительно).
Например, слово «banana» может быть сжато в виде такой последовательности:
Коды кодируются по Хаффману, что означает, что они занимают переменное (но целое) число бит (от 1 до 48 включительно) и не обязательно начинаются или заканчиваются на границах байтов. Символьные коды всегда порождают один байт информации. Копирующие коды же выдают до 258 байт. Таким образом, максимальное количество выходных байт одного кода (будь то символьный код или код копирования) равно 258 (запомните это число, мы вернемся к нему позже).
Wuffs v0.2 предоставлял реализацию DEFLATE, аналогичную библиотеке zlib, и показывал сопоставимую производительность, по крайней мере, на x86_64. В Wuffs v0.3 были добавлены две существенные оптимизации для современных процессоров, поддерживающих 64-битной записи и чтения из памяти без выравнивания: ввод и вывод чанками по 8 байт.
Ввод чанками по 8 байт
Как было отмечено выше, коды копирования DEFLATE занимают от 1 до 48 бит. Реализация процедуры обработки одного такого кода в zlib считывает входные биты в нескольких местах цикла. В inffast.c имеется 7 экземпляров hold += (unsigned long)(*in++) << bits; bits += 8;, загружающих входные биты по 1 байту (8 бит) за раз. Вместо этого мы можем читать по 64 бита за раз. Некоторые из прочитанных битов будут отброшены, если в буфере уже есть необработанные биты, но это не страшно: чтение этих битов приведет к битовому сдвигу нулями, а побитовое ИЛИ с нулями — это no-op. Более подробно эти тонкости при работе с битами рассматриваются статье Фабиана «ryg» Гизена в этом посте 2018 года.
Для Wuffs чтение 64 битов за раз увеличило производительность микробенчмарка DEFLATE в 1.30 раз.
Вывод чанками по 8 байт
Рассмотрим последовательность кодов DEFLATE для сжатия фразы TO BE OR NOT TO BE. THAT IS ETC. Второй TO BE может быть представлен кодом копирования с длиной 5 и расстоянием 13. Копирование 5 байт можно реализовать с помощью следующей последовательности из пяти команд (при этом чтение и запись мы делаем без выравнивания): чтение 4 байтов; запись 4 байтов; чтение 1 байта; запись 1 байта; out_ptr += 5. При достаточно большом расстоянии кода копирования такая последовательность команд будет работать корректно даже без выравнивания. Очевидной оптимизацией в плане количества команд будет «копировать излишние данные» (чтение 8 байт; запись 8 байт; out_ptr += 5).
: TO_BE_OR_NOT_??????????????????????
: ^ ^
: out_ptr-13 out_ptr
:
:
: [1234567) copy 8 bytes
: v v
: TO_BE_OR_NOT_TO_BE_OR??????????????
: ^ ^
: out_ptr += 5
:
:
: [) write 1 byte
: vv
: TO_BE_OR_NOT_TO_BE.OR??????????????
: ^^
: out_ptr += 1Запись результатов обработки последующих кодов (например, символьного кода '.') будет делаться поверх «излишне скопированных» данных, то есть наша оптимизация не сломает алгоритм. Заметим, что API библиотеки zlib не дает возможность применить такую оптимизацию: функция inflateBack использует единый буфер для «истории» и вывода, поэтому перезапись 8 байт может изменить буфер «истории», и сделать результаты декодирования некорректными.
Для Wuffs округление длины кодов копирования до кратного 8 ускорило работу микробенчмарка DEFLATE в 1.48 раз.
Сравнение с gzip
Формат gzip — это, грубо говоря, сочетание алгоритма DEFLATE с проверкой контрольной суммы с помощью CRC-32. Как и пример example/crc32, пример example/zcat более-менее эквивалентнен программе /bin/zcat из Debian с точки зрения функциональности, но при этом этом он в 3.1 раз быстрее (2.680 секунд против 8.389 секунд) на том же файле размером 178 Мб:
$ gcc -O3 wuffs/example/zcat/zcat.c -o wzcat
$ time ./wzcat < linux-5.11.3.tar.gz > /dev/null
real 0m2.680s
$ time /bin/zcat < linux-5.11.3.tar.gz > /dev/null
real 0m8.389sОчевидно, что контрольная сумма, вычисленная нашей программой, должна быть равна контрольной сумме, вычисленной с помощью /bin/zcat:
$ ./wzcat < linux-5.11.3.tar.gz | ./wcrc32 /dev/stdin
750d1011
$ /bin/zcat < linux-5.11.3.tar.gz | /bin/crc32 /dev/stdin
750d1011
$ tail --bytes=8 linux-5.11.3.tar.gz | hd
00000000 11 10 0d 75 00 78 70 3fAll-at-once декомпрессия
Для объяснения второй техники оптимизации шага декомпрессии рассмотрим следующую аналогию. Тактика бега на скорость из точки А в точку Б по ровной дороге тривиальна: нужно бежать изо всех сил. А теперь предположим, что точка Б находится на краю обрыва, внизу которого плавают голодные акулы, питающиеся бегунами. Тогда нам придется разделить наш забег на два этапа: начальный этап бега изо всех сил (обозначен синим) и этап осторожного добегания или вообще ходьбы, в котором главной целью является не свалиться с обрыва (обозначен красным).
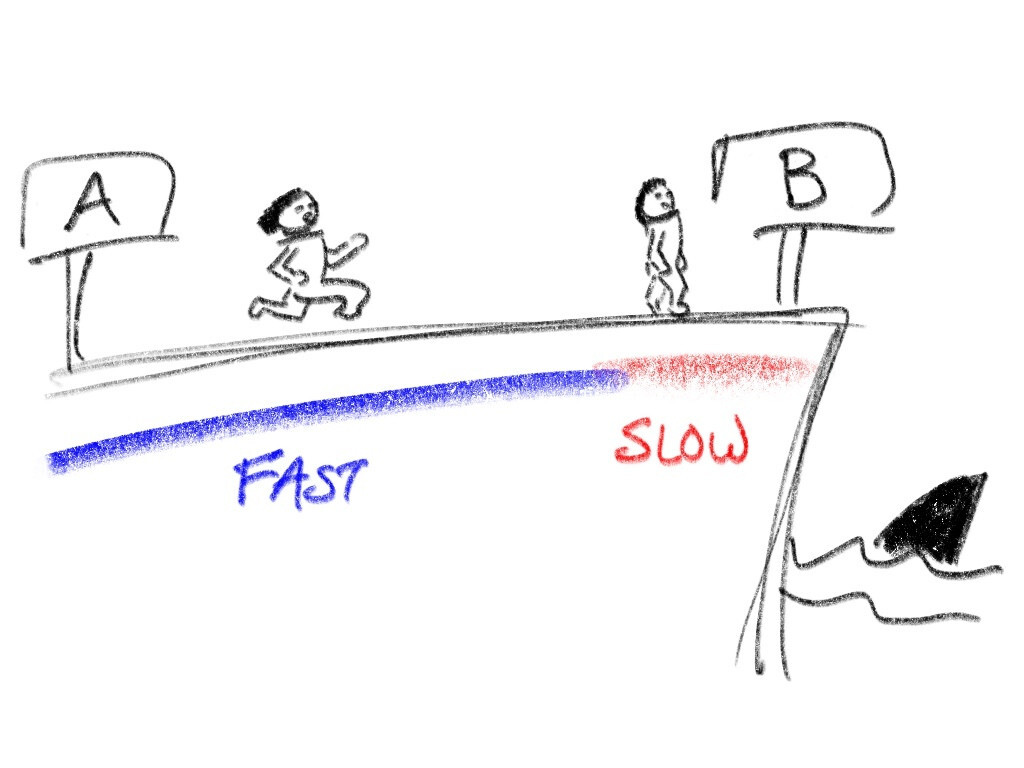
Декомпрессия DEFLATE предполагает запись распакованных данных в некий буфер (наш забег), где вылезание за его границы представляет собой классический buffer overflow (обрыв с акулами). Чтобы избежать этого, библиотека zlib имеет две реализации декомпрессии: быструю «синюю» (используется когда, например, до конца буфера остается 258 или более байт) и медленную «красную» (используется во всех других случаях).
Кроме того, libpng выделяет два буфера (для текущего и предыдущего ряда пикселей) и обращается к zlib N раз, где N — высота изображения в пикселях. Каждый раз буфер назначения имеет размер ровно в одну строку (ширина в пикселях, умноженная на количество байт на пиксель, плюс байт для хранения конфигурации фильтра), что означает, что zlib распаковывает последние 258 или более байт каждой строки с помощью медленной «красной» реализации. Для наглядности, это примерно четверть пикселей RGB изображения размером 300 × 200, а с точки зрения скорости декодирования потери будут еще больше.
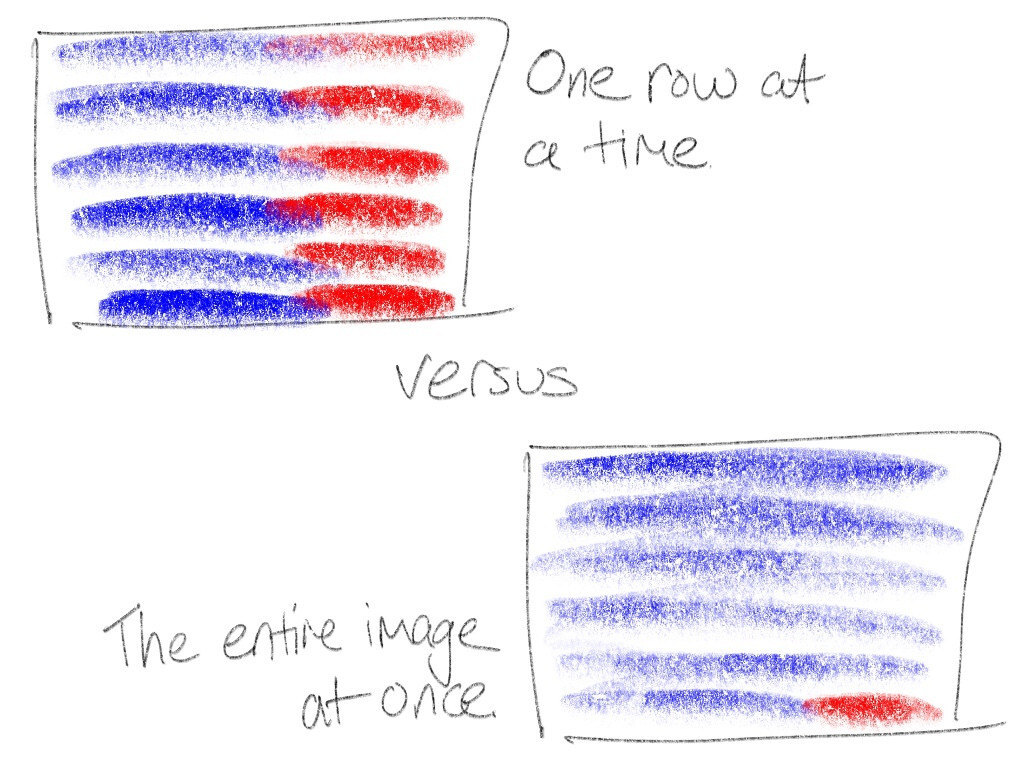
Алгоритм декомпресии формата zlib в Wuffs также использует это разделение на медленную и быструю реализации, так как это критично для безопасности, но в отличие от libpng, декомпрессия выполняется сразу для всего изображения (all-at-once), а не построчно. Другими словами, почти все (более 99% пикселей RGB изображения размером 300 × 200) пиксели теперь находятся в быстрой «синей» зоне. Это хорошо уже само по себе, но кроме того позволяет избежать кэш-промахов и branch misprediction при чередовании «синего» и «красного» кода.
Очевидно, что такой метод требует O(ширина изображения × высота изображения) промежуточной памяти вместо O(ширина изображения) памяти, но это не очень страшно, так как если изображение декодируется в оперативную память, а не на диск, то это само по себе уже требует O(ширина изображения × высота изображения) памяти. Кроме того, API Wuffs предоставляет вызывающей стороне некоторый выбор в отношении использования памяти. Вместо запроса «мне нужно M байт памяти для декодирования этого изображения» Wuffs говорит «мне нужно от M0 до M1 (включительно) байт памяти, и чем больше вы мне дадите, тем быстрее я буду работать». В текущей версии (0.3.0 — прим. пер.) Wuffs всегда устанавливает M0 равным M1 (выбора нет, all-at-once декомпрессиия используется всегда), но в будущих версиях может быть реализована возможность построчной декомпрессии, предлагая выбор между реализациями.
Фильтрация
И Wuffs, и libpng используют SIMD для ускорения 2D фильтрации. Например, вот реализация фильтрации в Wuffs для x86. Однако, на этом этапе libpng может показывать немного бóльшую производительность, поскольку, в отличии от Wuffs, он может гарантировать, что все строки изображения выровнены по оптимальным для SIMD границам. Wuffs же дает куда меньше гарантий относительно выравнивания, отчасти потому, что Wuffs не может самостоятельно выделять память, но в основном потому что all-at-once декомпрессия требует отказа от возможности, например, выравнивать начало каждой строки по 4 байта. Тем не менее, профилирование показывает, что на шаг декомпрессии тратится намного больше времени, чем на фильтрацию, так что преимущества all-at-once оптимизации перевешивают оверхед на фильтрацию без выравнивания.
Почему бы не оптимизировать так же уже существующие реализации PNG декодеров вместо создания еще одной с нуля?
В теории это можно было сделать, но есть ряд причин, почему стоило написать все с нуля.
Почему нет смысла патчить libpng?
А точнее, почему это бесперспективно. Как минимум по нескольким причинам:
libpngнаписан на C, а значит он скорее всего имеет проблемы с memory safety. Более того, его API для обработки ошибок построен наsetjmpиlongjmp, а сотниgotoусложняют статический или формальный анализ.Несмотря на то, что формат файла практически не менялся с 1999 года (версия 1.2 была формализована в 2003 году, а APNG — это неофициальное расширение), в
libpngбыло обнаружено 74 CVE с 2002 по 2021 год, 9 из которых — с 2018 года.В исходниках
libpngвстречаются такие вещи как, например, лаконичный комментарий «TODO: WARNING: TRUNCATION ERROR: DANGER WILL ROBINSON», добавленный больше десяти лет назад. Думаю, не нужно пояснять, что здесь не так.Код
libpngна самом деле невероятно сложен. Например грубая прикидка с помощью командыwc -l .c arm/.c intel/*.cв репозиторииlibpngдаст нам 35182 строки кода (без учета заголовочных файлов). Аналогичная команда для Wuffs покажет нам 2110 строк. Конечно,libpngтакже реализует энкодер PNG, но даже с учетом этого остается разница примерно на порядок.
Попытки пропатчить zlib
Я пытался пропатчить zlib несколько лет назад, но это оказалось сложнее, чем я думал, из-за упомянутой выше проблемы с API inflateBack. Так или иначе, существуют форки zlib zlib-ng/zlib-ng, и cloudflare/zlib которые решают часть проблем с производительностью с помощью похожих оптимизаций. Однако, использование, например zlib-ng вместо ванильного zlib в libpng дает совсем небольшой прирост производительности:
libpng_decode_19k_8bpp 58.0MB/s ± 0% 1.00x
libpng_decode_40k_24bpp 73.1MB/s ± 0% 1.00x
libpng_decode_77k_8bpp 177MB/s ± 0% 1.00x
libpng_decode_552k_32bpp_ignore_checksum 146MB/s ± 0% (†)
libpng_decode_552k_32bpp_verify_checksum 146MB/s ± 0% 1.00x
libpng_decode_4002k_24bpp 104MB/s ± 0% 1.00x
libpng 1.00x to 1.00x
----
zlibng_decode_19k_8bpp/gcc10 63.8MB/s ± 0% 1.10x
zlibng_decode_40k_24bpp/gcc10 74.1MB/s ± 0% 1.01x
zlibng_decode_77k_8bpp/gcc10 189MB/s ± 0% 1.07x
zlibng_decode_552k_32bpp_ignore_checksum/gcc10 skipped
zlibng_decode_552k_32bpp_verify_checksum/gcc10 177MB/s ± 0% 1.21x
zlibng_decode_4002k_24bpp/gcc10 113MB/s ± 0% 1.09x
zlibng 1.01x to 1.21xПочему стоит попытаться пропатчить Go и Rust
И Go, и Rust — это современные memory safe языки, однако для существующих проектов на C/C++ проще внедрить Wuffs, который транспилируется в C. Тем не менее, вполне возможно, что внедрение оптимизаций, описанных в этой статье в реализации декодера PNG на Go или Rust имеет смысл. Например, ни в Go, ни в Rust реализация Adler-32 не использует SIMD. Возможно, также стоит попробовать оптимизировать DEFLATE: реализация DEFLATE в Go читает только один байт за раз, а реализация miniz_oxide в Rust хоть и читает 4 байта за раз, но это все еще хуже, чем читать по 8 байт. Кроме того, ни в Go, ни в Rust декодер PNG не использует all-at-once декомпрессию.
Однако стоит отметить, что в отличие от Go и Rust, memory safety в Wuffs обеспечивается во время компиляции, а не с помощью проверок в рантайме (например, что индекс i при доступе к a[i] не выходит за границы массива или что (x + y) не переполняет u32). Компиляторы Go и Rust выполняют часть этих проверок во время компиляции (например, при итерации по элементам массива), но часть проверок все равно делается в рантайме, например, при декодировании DEFLATE-кодов. Очевидно, такие проверки могут значительно влиять на производительность. В этом плане мне нравится девиз языка Zig «Performance and Safety: Choose Two», но, в отличие от Zig, в Wuffs нет отдельных режимов сборки «Release Fast» и «Release Safe»: единственный режим сборки (компиляция кода на C с флагом -O3) дает и безопасность, и производительность.
Заключение
Только что вышла версия Wuffs 0.3.0-beta.1, которая содержит самый быстрый и безопасный в мире декодер PNG. Примеры использования из C и C++ доступны здесь. PNG декодер пока не поддерживает цветовые пространства и гамма-коррекцию (см. Issue 39), но даже без этого Wuffs может представлять некоторую ценность.
Прим. пер.: состояние Wuffs на 2023 год обсуждается ниже в абзаце «Комментарий переводчика».
Приложение
Подробные результаты бенчмарков
libpng здесь — это /usr/lib/x86_64-linux-gnu/libpng16.so из дистрибутив Debian Bullseye.
libpng_decode_19k_8bpp 58.0MB/s ± 0% 1.00x
libpng_decode_40k_24bpp 73.1MB/s ± 0% 1.00x
libpng_decode_77k_8bpp 177MB/s ± 0% 1.00x
libpng_decode_552k_32bpp_ignore_checksum 146MB/s ± 0% (†)
libpng_decode_552k_32bpp_verify_checksum 146MB/s ± 0% 1.00x
libpng_decode_4002k_24bpp 104MB/s ± 0% 1.00x
libpng 1.00x to 1.00x
----
wuffs_decode_19k_8bpp/clang9 131MB/s ± 0% 2.26x
wuffs_decode_40k_24bpp/clang9 153MB/s ± 0% 2.09x
wuffs_decode_77k_8bpp/clang9 472MB/s ± 0% 2.67x
wuffs_decode_552k_32bpp_ignore_checksum/clang9 370MB/s ± 0% 2.53x
wuffs_decode_552k_32bpp_verify_checksum/clang9 357MB/s ± 0% 2.45x
wuffs_decode_4002k_24bpp/clang9 156MB/s ± 0% 1.50x
wuffs_decode_19k_8bpp/gcc10 136MB/s ± 1% 2.34x
wuffs_decode_40k_24bpp/gcc10 162MB/s ± 0% 2.22x
wuffs_decode_77k_8bpp/gcc10 486MB/s ± 0% 2.75x
wuffs_decode_552k_32bpp_ignore_checksum/gcc10 388MB/s ± 0% 2.66x
wuffs_decode_552k_32bpp_verify_checksum/gcc10 373MB/s ± 0% 2.55x
wuffs_decode_4002k_24bpp/gcc10 164MB/s ± 0% 1.58x
wuffs 1.50x to 2.75x
----
libspng_decode_19k_8bpp/clang9 59.3MB/s ± 0% 1.02x
libspng_decode_40k_24bpp/clang9 78.4MB/s ± 0% 1.07x
libspng_decode_77k_8bpp/clang9 189MB/s ± 0% 1.07x
libspng_decode_552k_32bpp_ignore_checksum/clang9 236MB/s ± 0% 1.62x
libspng_decode_552k_32bpp_verify_checksum/clang9 203MB/s ± 0% 1.39x
libspng_decode_4002k_24bpp/clang9 110MB/s ± 0% 1.06x
libspng_decode_19k_8bpp/gcc10 59.6MB/s ± 0% 1.03x
libspng_decode_40k_24bpp/gcc10 77.5MB/s ± 0% 1.06x
libspng_decode_77k_8bpp/gcc10 189MB/s ± 0% 1.07x
libspng_decode_552k_32bpp_ignore_checksum/gcc10 223MB/s ± 0% 1.53x
libspng_decode_552k_32bpp_verify_checksum/gcc10 194MB/s ± 0% 1.33x
libspng_decode_4002k_24bpp/gcc10 109MB/s ± 0% 1.05x
libspng 1.02x to 1.62x
----
lodepng_decode_19k_8bpp/clang9 65.1MB/s ± 0% 1.12x
lodepng_decode_40k_24bpp/clang9 72.1MB/s ± 0% 0.99x
lodepng_decode_77k_8bpp/clang9 222MB/s ± 0% 1.25x
lodepng_decode_552k_32bpp_ignore_checksum/clang9 skipped
lodepng_decode_552k_32bpp_verify_checksum/clang9 162MB/s ± 0% 1.11x
lodepng_decode_4002k_24bpp/clang9 70.5MB/s ± 0% 0.68x
lodepng_decode_19k_8bpp/gcc10 61.1MB/s ± 0% 1.05x
lodepng_decode_40k_24bpp/gcc10 62.5MB/s ± 1% 0.85x
lodepng_decode_77k_8bpp/gcc10 176MB/s ± 0% 0.99x
lodepng_decode_552k_32bpp_ignore_checksum/gcc10 skipped
lodepng_decode_552k_32bpp_verify_checksum/gcc10 139MB/s ± 0% 0.95x
lodepng_decode_4002k_24bpp/gcc10 62.3MB/s ± 0% 0.60x
lodepng 0.60x to 1.25x
----
stbimage_decode_19k_8bpp/clang9 75.1MB/s ± 1% 1.29x
stbimage_decode_40k_24bpp/clang9 84.6MB/s ± 0% 1.16x
stbimage_decode_77k_8bpp/clang9 234MB/s ± 0% 1.32x
stbimage_decode_552k_32bpp_ignore_checksum/clang9 162MB/s ± 0% 1.11x
stbimage_decode_552k_32bpp_verify_checksum/clang9 skipped
stbimage_decode_4002k_24bpp/clang9 80.7MB/s ± 0% 0.78x
stbimage_decode_19k_8bpp/gcc10 73.3MB/s ± 0% 1.26x
stbimage_decode_40k_24bpp/gcc10 81.8MB/s ± 0% 1.12x
stbimage_decode_77k_8bpp/gcc10 214MB/s ± 0% 1.21x
stbimage_decode_552k_32bpp_ignore_checksum/gcc10 145MB/s ± 0% 0.99x
stbimage_decode_552k_32bpp_verify_checksum/gcc10 skipped
stbimage_decode_4002k_24bpp/gcc10 79.7MB/s ± 0% 0.77x
stbimage 0.77x to 1.32x
----
go_decode_19k_8bpp/go1.16 39.4MB/s ± 1% 0.68x
go_decode_40k_24bpp/go1.16 46.7MB/s ± 1% 0.64x
go_decode_77k_8bpp/go1.16 78.3MB/s ± 0% 0.44x
go_decode_552k_32bpp_ignore_checksum/go1.16 skipped
go_decode_552k_32bpp_verify_checksum/go1.16 118MB/s ± 0% 0.81x
go_decode_4002k_24bpp/go1.16 50.5MB/s ± 0% 0.49x
go 0.44x to 0.81x
----
rust_decode_19k_8bpp/rust1.48 89.8MB/s ± 0% 1.55x
rust_decode_40k_24bpp/rust1.48 122MB/s ± 0% 1.67x
rust_decode_77k_8bpp/rust1.48 158MB/s ± 0% 0.89x
rust_decode_552k_32bpp_ignore_checksum/rust1.48 skipped
rust_decode_552k_32bpp_verify_checksum/rust1.48 136MB/s ± 0% 0.93x
rust_decode_4002k_24bpp/rust1.48 122MB/s ± 0% 1.17x
rust 0.89x to 1.67xВоспроизведение
Wuffs транспилируется в код на C, а точнее в C библиотеку без зависимостей, состоящую из одного файла. Таким образом, для запуска бенчмарков вам не нужно ничего, кроме компилятора C:
$ cd wuffs
$ # ¿ is just an unusual character that's easy to search for. By
$ # convention, in Wuffs' source, it marks build-related information.
$ grep ¿ test/c/std/png.c
// ¿ wuffs mimic cflags: -DWUFFS_MIMIC -lm -lpng -lz
$ gcc -O3 test/c/std/png.c -DWUFFS_MIMIC -lm -lpng -lz
$ # Run the tests.
$ ./a.out
$ # Run the benchmarks.
$ ./a.out -benchБенчмарки для Go и Rust вынесены в отдельные программы.
Используемое железо
Все метрики были получены на бюджетном ноутбуке с x86_64 CPU:
$ cat /proc/cpuinfo | grep model.name | uniq
model name: Intel(R) Core(TM) m3-6Y30 CPU @ 0.90GHzНиже также приведены результаты бенчмарков для Raspberry Pi 4 (32-битный armv7l), которые не столь впечатляющи как результаты для x86_64, но тем не менее разница в производительности между libpngи Wuffs все равно заметная:
libpng_decode_19k_8bpp 44.1MB/s ± 0% 1.00x
libpng_decode_40k_24bpp 54.6MB/s ± 0% 1.00x
libpng_decode_77k_8bpp 123MB/s ± 0% 1.00x
libpng_decode_552k_32bpp_ignore_checksum 101MB/s ± 0% (†)
libpng_decode_552k_32bpp_verify_checksum 101MB/s ± 0% 1.00x
libpng_decode_4002k_24bpp 82.1MB/s ± 0% 1.00x
libpng 1.00x to 1.00x
----
wuffs_decode_19k_8bpp/clang9 82.5MB/s ± 0% 1.87x
wuffs_decode_40k_24bpp/clang9 105MB/s ± 0% 1.92x
wuffs_decode_77k_8bpp/clang9 303MB/s ± 0% 2.46x
wuffs_decode_552k_32bpp_ignore_checksum/clang9 180MB/s ± 0% 1.78x
wuffs_decode_552k_32bpp_verify_checksum/clang9 174MB/s ± 0% 1.72x
wuffs_decode_4002k_24bpp/clang9 100MB/s ± 0% 1.22x
wuffs_decode_19k_8bpp/gcc8 79.8MB/s ± 0% 1.81x
wuffs_decode_40k_24bpp/gcc8 106MB/s ± 0% 1.94x
wuffs_decode_77k_8bpp/gcc8 271MB/s ± 0% 2.20x
wuffs_decode_552k_32bpp_ignore_checksum/gcc8 177MB/s ± 0% 1.75x
wuffs_decode_552k_32bpp_verify_checksum/gcc8 170MB/s ± 0% 1.68x
wuffs_decode_4002k_24bpp/gcc8 100MB/s ± 0% 1.22x
wuffs 1.22x to 2.46xКомментарий переводчика (актуальное состояние Wuffs)
Несмотря на то, что с момента публикации оригинального поста прошло больше двух лет, Wuffs не только не уступил позиций по части декодирования PNG (кто-то даже называет его «ridiculously fast»), но и обзавелся рядом новых возможностей:
Последняя версия Wuffs на момент написания поста — 0.3.3. Для нее доступны следующие интерфейсы:
