[Перевод] Загрузка NumPy-массивов с диска: сравнение memmap() и Zarr/HDF5
Если ваш NumPy-массив слишком велик для того, чтобы полностью поместиться в оперативной памяти, его можно обработать, разбив на фрагменты. Сделать это можно либо в прозрачном режиме, либо явно, загружая эти фрагменты с диска по одному.

В такой ситуации можно прибегнуть к двум классам инструментов:
- Метод NumPy
memmap(), прозрачный механизм, который позволяет воспринимать файл, расположенный на диске, так, будто он весь находится в памяти. - Похожие друг на друга форматы хранения данных Zarr и HDF5, которые позволяют, по необходимости, загружать с диска и сохранять на диск сжатые фрагменты массива.
У каждого из этих методов есть свои сильные и слабые стороны.
Материал, перевод которого мы сегодня публикуем, посвящён разбору особенностей этих методов работы с данными, и рассказу о том, в каких ситуациях они могут пригодиться. В частности, особое внимание будет уделено форматам данных, которые оптимизированы для выполнения вычислений и необязательно рассчитаны на передачу этих данных другим программистам.
Что происходит при чтении данных с диска или при записи данных на диск?
Когда файл читают с диска в первый раз, операционная система не просто копирует данные в память процесса. Сначала она копирует эти данные в свою память, сохраняя их копию в так называемом «буферном кэше».
В чём здесь польза?
Дело в том, что операционная система хранит данные в кэше на тот случай, если нужно будет снова прочитать те же данные из того же файла.

Если данные читают снова — то они поступают в память программы уже не с диска, а из оперативной памяти, что на порядки быстрее.

Если память, занятая кэшем, нужна для чего-то другого, кэш будет автоматически очищен.
Когда данные пишут на диск, они перемещаются в обратном направлении. Сначала они пишутся лишь в буферный кэш. Это означает, что операции записи обычно выполняются весьма быстро, так как программе не нужно ориентироваться на медленный диск. Ей, в ходе записи, нужно работать лишь с оперативной памятью.

В итоге же данные сбрасываются на диск из кэша.
Работа с массивом с использованием memmap ()
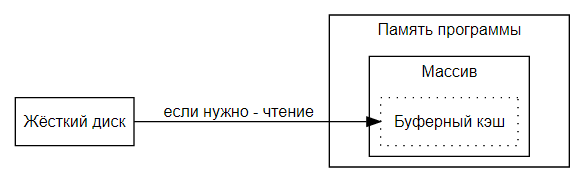
В нашем случае memmap() позволяет воспринимать файл на диске так, как будто бы он представляет собой массив, хранящийся в памяти. Операционная система, прозрачно для программы, выполняет операции чтения/записи, обращаясь или к буферному кэшу, или к жёсткому диску, в зависимости от того, кэшированы ли запрашиваемые данные в памяти или нет. Здесь выполняется примерно такой алгоритм:
- Данные находятся в кэше? Если так — замечательно — к ним можно обратиться напрямую.
- Данные находятся на диске? Доступ к ним будет медленнее, но беспокоиться об это не придётся, они будут загружены в прозрачном режиме.
В качестве дополнительного плюса memmap() можно отметить то, что в большинстве случаев буферный кэш для файла будет встроен в память программы. Это значит, что системе не придётся поддерживать дополнительную копию данных в памяти программы за пределами буфера.
Метод memmap() встроен в NumPy:
import numpy as np
array = np.memmap("mydata/myarray.arr", mode="r",
dtype=np.int16, shape=(1024, 1024))
Выполните этот код, и в вашем распоряжении будет массив, работа с которым для программы будет совершенно прозрачной — независимо от того, осуществляется ли работа с буферным кэшем или с жёстким диском.
Ограничения memmap ()
Хотя в определённых ситуациях memmap() может весьма неплохо себя показывать, у этого метода есть и ограничения:
- Данные должны храниться в файловой системе. Данные нельзя загрузить из хранилища двоичных объектов наподобие AWS S3.
- Если осуществляется интенсивная работа с достаточно большим объёмом данных, диск может стать узким местом системы. Помните о том, что жёсткие диски гораздо медленнее оперативной памяти. То, что чтение с диска и запись на него прозрачны для программы, не означает, что сам диск начал работать быстрее.
- Если работают с N-мерным массивом и при этом нужно получать наборы элементов, расположенных вдоль разных измерений этого массива, то быстро можно получать только те наборы элементов, последовательное расположение которых в файле соответствует структуре массива. Всё остальное потребует большого количества операций чтения с диска.
Поясним последний пункт. Представим, что у нас есть двумерный массив, содержащий 32-битные (4-х байтовые) целые числа. За одну операцию чтения с диска читается 4096 байт. Если с диска читают данные, расположенные в файле последовательно (скажем — такие данные находятся в строках массива), то после каждой операции чтения в нашем распоряжении окажется 1024 целых числа. Но если читают данные, расположение которых в файле не соответствует их расположению в массиве (скажем — данные, расположенные в столбцах), то каждая операция чтения позволит получить лишь 1 необходимое число. В результате окажется, что для получения того же объёма данных придётся выполнить в тысячу раз больше операций чтения.
Zarr и HDF5
Для того чтобы преодолеть вышеозначенные ограничения, можно воспользоваться форматами хранения данных Zarr или HDF5, которые очень похожи:
- С файлами формата HDF5 можно работать в Python с использованием pytables или h5py. Этот формат старше Zarr и имеет больше ограничений, но его плюс заключается в том, что использовать его можно в программах, написанных на различных языках.
- Zarr — это формат, реализуемый с помощью одноимённого Python-пакета. Он гораздо современнее и гибче чем HDF5, но пользоваться им (по крайней мере — пока) можно только в среде Python. По моим ощущениям, в большинстве ситуаций, если нет нужды в многоязычной поддержке HDF5, стоит остановить выбор именно на Zarr. Zarr, например, отличается лучшей поддержкой многопоточности.
Далее мы будем обсуждать только Zarr, но если вам интересен формат HDF5 и его более глубокое сравнение с Zarr — можете посмотреть это видео.
Использование Zarr
Zarr позволяет хранить фрагменты данных и загружать их в память в виде массивов, а также — записывать эти фрагменты данных в виде массивов.
Вот как загрузить массив с использованием Zarr:
>>> import zarr, numpy as np
>>> z = zarr.open('example.zarr', mode='a',
... shape=(1024, 1024),
... chunks=(512,512), dtype=np.int16)
>>> type(z)
>>> type(z[100:200])
Обратите внимание на то, что до тех пор, пока не будет получен срез объекта, в нашем распоряжении не будет numpy.ndarray. Сущность zarr.core.array — это лишь метаданные. С диска загружаются только те данные, которые включены в срез.
Почему я выбрал Zarr?
- Zarr позволяет обойти ограничения
memmap(), рассмотренные выше: - Фрагменты данных можно хранить на диске, в хранилище AWS S3, или в некоей системе хранения данных, предоставляющей возможность работы с записями формата ключ/значение.
- Размер и структуру фрагмента данных задаёт программист. Например, данные можно организовать так, чтобы получить возможность эффективного чтения информации, расположенной по разным осям многомерного массива. Это справедливо и для HDF5.
- Фрагменты можно сжимать. То же самое можно сказать и об HDF5.
Остановимся на двух последних пунктах подробнее.
Размерности фрагментов
Предположим, мы работаем с массивом размером 30000×30000 элементов. Если нужно читать этот массив и перемещаясь по его оси X, и перемещаясь по его оси Y, сохранить фрагменты, содержащие данные этого массива, можно так, как показано ниже (на практике, скорей всего, понадобится больше 9 фрагментов):

Теперь данные, расположенные и по оси X, и по оси Y, можно загружать эффективно. В зависимости от того, какие именно данные нужны в программе, можно загрузить, например, фрагменты (1, 0), (1, 1), (1, 2), или фрагменты (0, 1), (1, 1), (2, 1).
Сжатие данных
Каждый фрагмент можно сжать. Это означает, что данные могут поступать в программу быстрее, чем диск позволяет читать несжатую информацию. Если данные сжаты в 3 раза, это значит, что их можно загружать с диска в 3 раза быстрее, чем несжатые данные, за вычетом времени, необходимого процессору на их распаковку.

После того, как фрагменты загружены, их можно убрать из памяти программы.
Итоги: memmap () или Zarr?
Чем лучше пользоваться — memmap() или Zarr?
Memmap() интересно выглядит в таких случаях:
- Имеется множество процессов, читающих части одного и того же файла. Эти процессы, благодаря применению
memmap(), смогут совместно использовать один и тот же буферный кэш. Это означает, что в памяти нужно держать лишь одну копию данных, независимо от того, сколько выполняется процессов. - У разработчика нет желания вручную управлять памятью. Он планирует просто положиться на возможности операционной системы, которая будет решать все вопросы управления памятью автоматически и незаметно для разработчика.
Zarr особенно полезен в следующих ситуациях (в некоторых из них, как будет отмечено, применим и формат HDF5):
- Данные загружают из удалённых источников, а не из локальной файловой системы.
- Весьма вероятно то, что узким местом системы станет чтение с диска. Сжатие данных позволит эффективнее использовать возможности аппаратного обеспечения. Этот касается и HDF5.
- Если нужно получать срезы многомерных массивов по разным осям, Zarr помогает оптимизировать подобные операции за счёт подбора подходящих размеров и структуры фрагментов. Это справедливо и для HDF5.
Я бы, выбирая между memmap() и Zarr, в первую очередь попробовал бы воспользоваться Zarr — из-за той гибкости, которую даёт этот пакет и реализуемый им формат хранения данных.
Уважаемые читатели! Как вы решаете задачу работы с большими NumPy-массивами?

