[Перевод] Видеоускоритель Apple и невозможный баг
В конце 2020 года компания Apple выпустила M1 — первого представителя собственной архитектуры GPU под названием AGX, по слухам, созданной на основе серии Imagination PowerVR. С тех пор мы занимались реверс-инжинирингом AGX и созданием опенсорсных графических драйверов. В январе прошлого года я отрендерила треугольник при помощи своего собственного кода, но с тех пор нас продолжал преследовать ужасный баг:
Драйвер не справлялся с рендерингом больших количеств геометрии.
Вращающийся кубик отрисуется нормально, низкополигональная геометрия тоже, но детализированные модели не рендерились. GPU рендерил только часть модели, а потом останавливался.
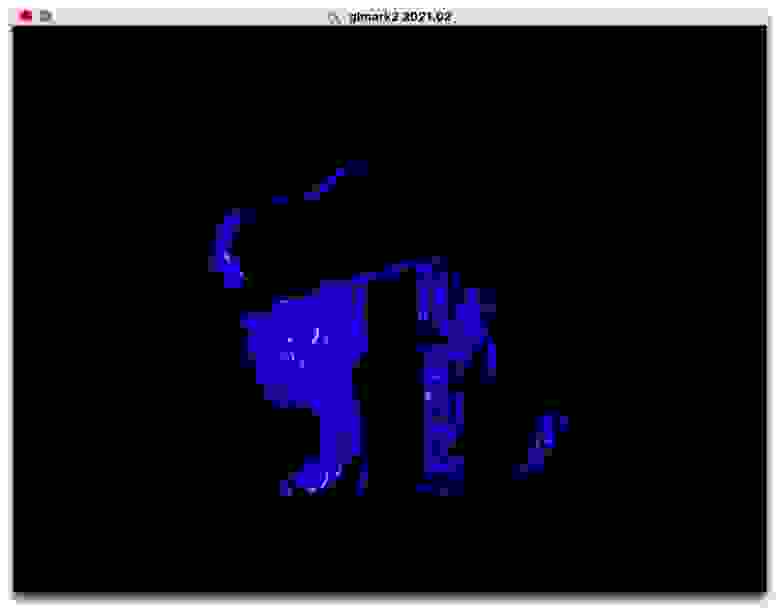
Частично отрендеренный по Фонгу кролик
Сложно было определить, какой объём мы можем рендерить без сбоев. Это зависело не только от сложности геометрии. Одна и та же геометрия могла рендериться с простыми шейдерами, но давать сбой со сложными.
Это намекало, что рендеринг детализированной геометрии сложным шейдером «занимает слишком много времени» и в GPU происходит таймаут. Вероятно, он рендерит только те части, которые успел сделать вовремя.
Учитывая аппаратную архитектуру, такое объяснение маловероятно.
Эту гипотезу легко проверить, потому что мы можем управлять таймингом при помощи шейдера, выполнение которого может занимать любое нужное нам время:
for (int i = 0; i < LARGE_NUMBER; ++i) {
/* код, не позволяющий оптимизатору удалить цикл */
}
Поэкспериментировав с таким шейдером, мы выяснили следующее:
- Если у шейдеров есть временной лимит для защиты от бесконечных циклов, то он астрономически высок. Наш кролик никак не сможет превзойти этот лимит.
- Симптомы таймаута отличаются от симптомов того, как наш драйвер рендерит слишком много геометрии.
Эту теорию исключаем.
Давайте экспериментировать дальше. Изменив шейдер и понаблюдав, где он ломается, мы нашли единственную часть шейдера, влияющую на баг: количество данных, интерполируемых на одну вершину. Современные графические API позволяют указывать меняющиеся данные («varying») для каждой вершины, например, цвет или нормаль к поверхности. При рендеринге каждого треугольника оборудованием эти «varyings» интерполируются вдоль треугольника, создавая плавные входные данные для фрагментного шейдера, что позволяет эффективно реализовать стандартные графические техники, например, затенение по Блинну-Фонгу.
Сложив всю информацию, мы поняли, что важно произведение количества вершин (сложности геометрии) и количества данных на вершину (сложности затенения). Это произведение является «общим количеством данных на одну вершину». GPU не удаётся выполнить задачу, если мы используем слишком много общих данных на вершину.
Почему?
Когда оборудование обрабатывает каждую вершину, вершинный шейдер создаёт данные для каждой вершины. Эти данные должны куда-то передаваться. Реализация этого зависит от аппаратной архитектуры. Давайте рассмотрим стандартные архитектуры GPU. [Дальнейшие объяснения будут существенно упрощены, но вполне достаточно для наших целей.]
Традиционные рендереры немедленного режима (immediate mode renderer) выполняют рендеринг непосредственно в буфер кадров. Сначала они выполняют вершинный шейдер для каждой вершины треугольника, а затем выполняют фрагментный шейдер для каждого пикселя треугольника. Данные «varying» каждой вершины передаются почти напрямую между шейдерами, то есть рендереры немедленного режима эффективны для сложных сцен.
Однако у них есть недостаток: рендеринг напрямую в буфер кадров требует огромного количества операций доступа к памяти для постоянной записи результатов работы фрагментного шейдера и для считывания результатов при смешении. Рендереры немедленного режима подходят для дискретных десктопных GPU с высоким энергопотреблением, имеющих отдельную видеопамять.
В отличие от них, тайловые отложенные рендереры (tile-based deferred renderers) разделяют рендеринг на две части. Сначала оборудование выполняет все вершинные шейдеры для всего кадра, а не только для одной модели. Затем буфер кадров разделяется на небольшие тайлы, а специальное оборудование под названием «тайлер» (tiler) определяет, какие треугольники находятся в каждом тайле. После этого для каждого тайла оборудование выполняет все соответствующие фрагментные шейдеры и записывает готовый результат со смешением в память.
Тайлеры уменьшают трафик памяти, необходимый для буфера кадров. Так как оборудование рендерит по одному тайлу за раз, оно хранит «кэшированную» копию этого тайла в буфере кадров (называемом тайловым буфером (tilebuffer)). Тайловый буфер мал, всего несколько килобайтов, однако доступ к нему очень быстр. Запись в тайловый буфер — это малозатратная операция, и в отличие от смешения в немедленных рендерерах, здесь оно выполняется практически без затрат. Так как доступ к основной памяти — это затратная операция, а мобильные GPU не могут позволить себе иметь отдельную видеопамять, тайлеры подходят для мобильных GPU, например, Arm Mali, Imaginations PowerVR и Apple AGX.
Да, AGX — это мобильный GPU, спроектированный для iPhone. M1 — это чрезвычайно быстрый десктоп, однако его обобщённая память и GPU с тайлером корнями уходят в мобильные телефоны. Тайлеры хорошо работают в десктопах, однако имеют определённые недостатки.
Во-первых, в начале кадра содержимое тайлового буфера неопределённо. Если приложению нужно сохранить имеющееся содержимое буфера кадров, драйверу нужно загрузить буфер кадров из основной памяти и сохранить его в тайловый буфер. Это затратная операция.
Во-вторых, поскольку все вершинные шейдеры выполняются до всех фрагментных шейдеров, оборудованию нужен буфер для хранения выходных данных всех вершинных шейдеров. Обычно для этого требуется гораздо больше данных, чем пространство внутри GPU, поэтому этот буфер должен храниться в основной памяти. Это тоже затратно.
Ага! Поскольку AGX — это тайлер, ему требуется буфер всех данных для каждой вершины. Сбой происходит, когда мы используем слишком много общих данных вершин, переполняя буфер.
А если выделить буфер побольше?
В некоторых тайлерах, например, в старых версиях Mali GPU компании Arm, драйвер пользовательского пространства вычисляет, насколько большим должен быть этот буфер данных «varying», и выделяет его. [На самом деле это хуже, чем кажется. Начиная с новой архитектуры Valhall, Mali распределяет varying гораздо эффективнее.]
Чтобы устранить эти сбои, мы можем попробовать увеличить размеры всех выделяемых буферов, надеясь, что один из них содержит данные вершин.
Ничего не вышло.
Очень здорово наблюдать за тем, что делает драйвер Metal компании Apple. Мы можем создать программу Metal, отрисовывающую переменное количество геометрии, и трассировать распределения памяти GPU, выполняемые Metal при работе нашей программы. При этом мы выясняем, что увеличение количества отрисовываемой геометрии не увеличивает размеров выделенных буферов. На самом деле, это не меняет ничего в передаваемом ядру буфере команд, за исключением одного поля «количество вершин» в команде отрисовки.
Мы знаем, что буфер существует. Если он не выделяется пользовательским пространством (а похоже, так и есть), то должен выделяться ядром или прошивкой.
Забавная мысль: возможно, мы вообще не указываем размер буфера. Возможно, это нормально, что он переполняется, и есть способ обработки такого переполнения.
Настало время для небольшого расследования. Изучая скудную публичную документацию, доступную для AGX, мы узнали в одной из презентаций для WWDC следующее:
Тайловый вершинный буфер (Tiled Vertex Buffer) хранит выходные данные фазы тайлинга, в которые входят и данные вершин после преобразования…Но если он полон, это может привести к частичному рендерингу. При частичном рендеринге GPU разделяет проход рендеринга для сброса содержимого этого буфера.
Точное попадание. Буфер, который мы ищем, «тайловый вершинный буфер», может переполняться. Чтобы справиться с этим, GPU перестаёт принимать новую геометрию, рендерит уже имеющуюся геометрию и перезапускает рендеринг.
Так как частичный рендеринг вредит производительности, разработчикам приложений Metal нужно знать о нём, чтобы оптимизировать свои приложения. Должны существовать счётчики производительности, указывающие на эту проблему. Поискав, мы обнаружили два:
- Количество частичных рендеров.
- Количество байтов, использованных в буфере параметров.
Постойте-ка, что это за «буфер параметров»?
Помните слухи о том, что AGX создана на основе PowerVR? В публичных руководствах по оптимизации PowerVR написано следующее:
Список, содержащий указатели на каждую вершину и передаваемый из приложения, называется буфером параметров (parameter buffer, PB) и хранится в системной памяти вместе с вершинными данными.Каждому varying требуется дополнительное пространство в буфере параметров.
Тайловый вершинный буфер и является буфером параметров. PB — это название в PowerVR, TVB — это публичное название Apple, а внутри Apple по-прежнему используется название PB.
Что происходит при переполнении буфера параметров в PowerVR?
В старой презентации PowerVR говорится, что когда буфер параметров заполнен, «рендер сбрасывается», а это означает, что «сбрасываемые данные должны извлекаться из буфера кадров в процессе выполнения последовательного рендеринга тайлов». Иными словами, при этом выполняется частичный рендеринг.
Похоже, что оборудованию Apple M1 не удаётся выполнить частичный рендеринг. Давайте ещё раз взглянем на поломанный рендер.
Тот же самый кролик
Обратите внимание, что части модели отрендерены корректно. В начале рендерятся части сцены, которые имеют не только чёрный цвет. Давайте разберёмся в логическом порядке событий.
Сначала оборудование выполняет вершинные шейдеры для кролика, пока не переполнится буфер параметров. Это работает: частичная геометрия отображена правильно.
Далее оборудование растеризирует частичную геометрию и выполняет фрагментные шейдеры. Это работает: шейдинг выполнен правильно.
В-третьих, оборудование сбрасывает частичный рендер в буфер кадров. Это необходимо сделать, иначе мы ничего не увидим.
В-четвёртых, оборудование выполняет вершинные шейдеры для оставшейся части геометрии кролика. Это должно работать: конфигурация идентична исходным вершинным шейдерам.
В-пятых, оборудование растеризирует и затеняет оставшуюся геометрию, смешивая её со старым частичным рендером. Так как AGX является тайлером, для сохранения этого имеющегося частичного рендера оборудованию нужно загрузить его обратно в тайловый буфер. Мы понятия не имеем, как оно это делает.
В конце оборудование сбрасывает рендер в буфер кадров. Это должно происходить так же, как в первый раз.
Единственный проблематичный шаг — это загрузка буфера кадров обратно в тайловый буфер после частичного рендеринга. Обычно драйвер имеет два «дополнительных» фрагментных шейдера. Один очищает тайловый буфер в начале, а другой сбрасывает содержимое тайлового буфера в конце.
Если приложению нужно сохранить содержимое имеющегося буфера кадров вместо записи цвета очистки, программа загрузки тайлового буфера выполняет считывание из буфера кадров, чтобы снова загрузить содержимое. Для этого требуется довольно много кода, но в нашем драйвере это срабатывает.
При внимательном изучении выясняется, что AGX требуется больше вспомогательных программ.
Программа сохранения обеспечивается дважды. Я заметила это при первом запуске оборудования, но причина дублирования оставалась непонятной. Отключив каждую копию по отдельности и понаблюдав за тем, что ломается, я выяснила причину: одна программа сбрасывает финальный рендер, а другая сбрасывает частичный рендер. [Так зачем же нужно дублирование? Я пока не видела, чтобы Metal использовал разные программы для каждой программы. Однако чтобы эта схема работала для рендеринга переднего буфера, частичные рендеры должны сбрасываться во временный буфер. Разумеется, на этом этапе можно использовать и двойную буферизацию.]
…А что насчёт программы, загружающей буфер кадров в тайловый буфер?
Если частичный рендер возможен, то используются две программы загрузки. Одна записывает цвет очистки или загружает буфер кадров (это зависит от настроек приложения). С ней мы разобрались. Другая всегда загружает буфер кадров.
…Всегда загружает буфер кадров, в том числе и для загрузки обратно с частичным рендером, даже если в начале кадра произошла очистка?
Если проблема в этой программе, то мы можем легко это проверить. Metal должен требовать её для отрисовки того же кролика, поэтому мы можем запустить приложение Metal, отрисовыывающее кролика, и вмешаться в его память GPU, чтобы заменить эту вспомогательную программу загрузки программой, всегда загружающей полностью чёрный цвет.

Metal отрисовывает кролика, модифицируя его память
В этом случае Metal приходит к похожему сбою. Это означает, что мы добрались до первопричины проблемы. В своём коде драйвера мы не указали никакой программы для этой загрузки частичного рендера. До этого момента это работало нормально. Если буфер параметров никогда не переполняется, эта программа не используется. Однако как только требуется частичный рендер, отсутствие этой программы означает, что GPU разыменовывает нулевой указатель и вызывает сбой. Это объясняет сбои GPU, с которыми мы сталкивались в начале.
Как и Metal, мы передаём собственную программу для загрузки тайлового буфера после частичного рендеринга…
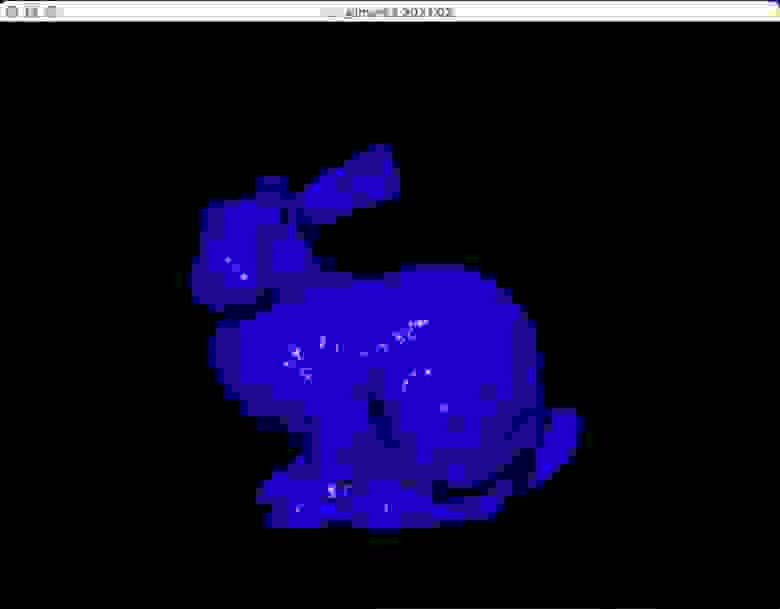
Кролик с нашим исправлением
…но это не исправляет рендеринг! Чёрт побери этот GPU. Сбои пропали, но в течение первых нескольких кадров рендер всё равно не совсем правильный, а это значит, что частичные рендеры по-прежнему поломаны. Обратите внимание на странные артефакты лап.
Любопытно, что спустя несколько кадров рендер «чинит себя», и это намекает на то, что буфер параметров перестаёт переполняться. Это подразумевает, что размер буфера может изменяться (ядром или прошивкой), а система в ответ на переполнение спустя несколько кадров увеличивает буфер параметров. Этот механизм выглядит логичным:
- Оборудование не может самостоятельно распределить больше пространства под буфер параметров.
- Переполнение буфера параметров — затратное событие, поскольку для частичных рендеров требуется огромная пропускная способность памяти.
- Слишком большое распределение буфера параметров впустую тратит память в случае приложений, рендерящих простую геометрию.
Если изначально сделать буфер параметров маленьким, а затем увеличивать его в ответ на переполнение, то можно создать баланс, снижающий объём занимаемой памяти GPU и минимизирующий частичные рендеры.
Вернёмся к нашему ошибочному рендерингу. На самом деле наша программа использует два буфера: буфер цветов (буфер кадров)… и буфер глубин. Буфер глубин не виден напрямую, зато он упрощает «тест глубин», отсекающий дальние пиксели, перекрытые ближними пикселями. Механизм частичного рендеринга отсекает геометрию, а тест глубин отсекает пиксели.
Это могло бы объяснить отсутствие пикселей на кролике. При частичном рендеринге тест глубин сломан. Но почему? Тест глубин зависит от буфера глубин, поэтому буфер глубин тоже нужно сохранять после частичного рендеринга и загружать обратно при продолжении работы. Сравнивая трассировки нашего драйвера с трассировками Metal в поисках соответствующих различий, мы наткнулись на конфигурацию, которая необходима для того, чтобы работали сбросы буфера глубин.
И после всего этого мы получили нашего кролика.
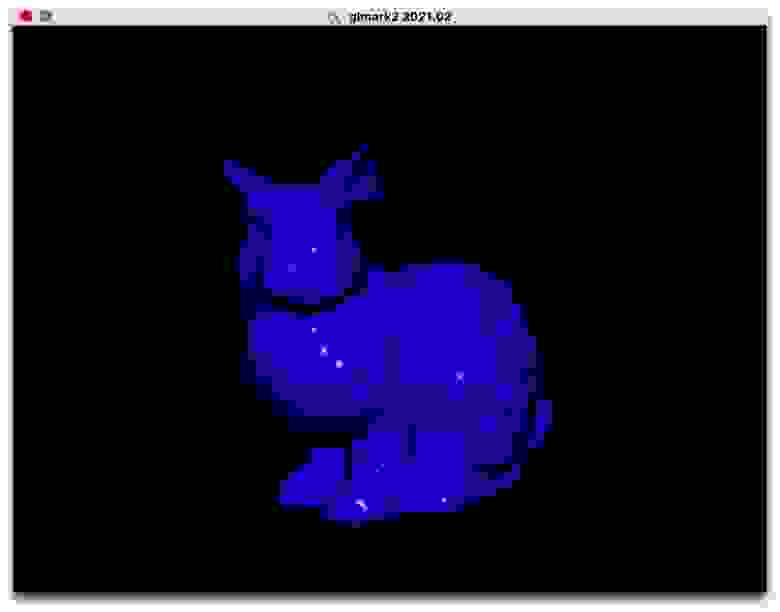
Готовый кролик с затенением по Фонгу
