[Перевод] Как помочь компилятору повысить быстродействие вашей программы

Современные компиляторы весьма далеко продвинулись в области оптимизации ПО. Но иногда им бывает трудно подобрать наилучший способ оптимизации. К счастью, мы можем помочь им в этом выборе.
Под катом старший разработчик ПО компании Google, Minhaz A V*, рассказывает об оптимизации производительности кода. Менее чем за час работы автор ускорил код на 18%, добавив в него всего пару строк. Несмотря на то, что в большинстве примеров этого материала используется C++, статья может быть полезна широкому кругу читателей.
*Обращаем ваше внимание: позиция автора не всегда может совпадать с мнением МойОфис.
Современные компиляторы не просто компилируют код, то есть выполняют трансляцию языка высокого уровня в язык ассемблера или машинные инструкции. Они тратят много ресурсов на оптимизацию нашего кода для достижения наилучшей производительности. Разумеется, чтобы это стало возможным, программист должен указать соответствующие флаги компиляции. Вместо оптимизации быстродействия кода всегда можно поручить компилятору минимизировать размер скомпилированного файла или повысить скорость компиляции. В данной статье акцент будет сделан на оптимизации производительности.
Современные процессоры
 Фото: Франческо Вантини. Источник: https://unsplash.com/photos/ZavLsrP4CDI
Фото: Франческо Вантини. Источник: https://unsplash.com/photos/ZavLsrP4CDI
Поговорим о современных процессорах. Как правило, устройство центрального процессора изучается в институте, но мы часто забываем эти знания.
SIMD или SISD?
SISD расшифровывается как Single Instruction Stream, Single Data Stream (единый поток инструкций, единый поток данных). Обычно инструкции программного кода выполняются последовательно, т. е. одна за другой. Предположим, у нас есть два массива — a и b — и мы хотим написать программу, которая изменяет элементы массива a с помощью операции:
![a[i] = a[i] + b[i];](https://habrastorage.org/getpro/habr/upload_files/d32/d2d/d02/d32d2dd0269316517dcaf2c4e7caa0c9.svg)
выполняемой для каждого возможного значения индекса i.
 На примере простейшего алгоритма разворота массива видно, как мы можем визуализировать исполнение инструкций нашего кода на процессоре. Источник: https://github.com/Wunkolo/qreverse (лицензия MIT).
На примере простейшего алгоритма разворота массива видно, как мы можем визуализировать исполнение инструкций нашего кода на процессоре. Источник: https://github.com/Wunkolo/qreverse (лицензия MIT).
Программисты склонны писать код, оптимизируя Ω (то есть нижнюю границу сложности алгоритма, или «лучший случай») — и это хорошая практика. Но современные процессоры способны на большее.
Современные процессоры поддерживают SIMD, что расшифровывается как Single Instruction, Multiple Data (одна инструкция, множество данных). Такие вычислительные устройства могут демонстрировать параллелизм на уровне данных (не путать с конкурентностью), то есть могут исполнять одновременно одну и ту же инструкцию сразу для множества данных.
Для приведённого выше примера, процессоры с технологией SIMD могли бы сгруппировать операции для параллельного исполнения в одном пакете следующим образом:
a[0] = a[0] + b[0];
a[1] = a[1] + b[1];
a[2] = a[2] + b[2];
a[3] = a[3] + b[3];Инструкция SIMD для операции сложения называется addps в SSE или vaddps в AVX и поддерживает группировку четырех или восьми элементов соответственно (целочисленный тип).
 Визуализация исполнения инструкций процессором SIMD на примере алгоритма разворота массива. Источник: https://github.com/Wunkolo/qreverse (лицензия MIT).
Визуализация исполнения инструкций процессором SIMD на примере алгоритма разворота массива. Источник: https://github.com/Wunkolo/qreverse (лицензия MIT).
То есть ваш код мог бы работать в k раз быстрее, если бы вы могли дать команду процессору запускать алгоритм именно таким образом.
И вы действительно можете это сделать.
Существуют интринсики (intrinsics) — внутренние функции, которые обрабатываются компилятором особым образом. С их помощью можно указать процессору на необходимость применения векторных операций (SIMD) вместо скалярных (SISD).
Вот пример кода для вычисления поэлементной суммы двух массивов с помещением в целевой массив с помощью Neon Intrinsics:
// Источник: https://stackoverflow.com/a/69799101/2614250
#include
void add_arrays(int* a, int* b, int* target, int size) {
for(int i=0; i Согласитесь, что код, написанный таким образом, выглядит не очень хорошо. Подобный подход требует более глубокого знания платформоспецифичных интринсиков, да и поддерживать такой код не так просто. Впрочем, есть способ написать одновременно легко поддерживаемый и высокопроизводительный код, —, но это тема уже для другой статьи.
Хорошая новость в том, что в большинстве случаев вам не придётся писать код с интринсиками, чтобы достичь высокой производительности кода. И здесь мы переходим к следующей теме — векторизации.
Векторизация
SIMD поддерживает инструкции, которые могут работать с векторными типами данных. В приведенном выше примере группы элементов массива, например, a[0...3] или b[4...7], могут называться векторами.
Векторизация подразумевает использование векторных инструкций для ускоренного выполнения программы. Она может осуществляться как программистами (путем написания векторных инструкций), так и непосредственно компилятором. Второй подход называется автовекторизацией.
Автовекторизация может быть выполнена AOT-компилятором во время компиляции или JIT-компилятором во время выполнения программы.
Раскрутка цикла
Раскрутка цикла — это метод преобразования цикла, при котором компилятор ускоряет работу программы ценой увеличения размера исполняемого файла.
Целью раскрутки цикла является повышение быстродействия программы путем уменьшения количества инструкций, управляющих циклом, например, арифметических операций над указателями и проверки конца цикла в рамках каждой итерации.
Простой пример развертывания цикла:
// Обычный цикл for c 16 млн. итераций
for (int i = 0; i < 16000000; ++i) {
a[i] = b[i] + c[i];
}
// Раскрученный цикл for
for (int i = 0; i < 4000000; i+=4) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
a[i+2] = b[i+2] + c[i+2];
a[i+3] = b[i+3] + c[i+3];
}Далее в этой статье я поделюсь некоторыми показателями производительности для этих двух приёмов.
Современные компиляторы
 gcc на Mac — изображение автора.
gcc на Mac — изображение автора.
Современные C++ компиляторы используют такие методы оптимизации кода, как векторизатор циклов, позволяющие генерировать векторные инструкции для кода, написанного в скалярном формате.
Зачастую наш скалярный код на самом деле исполняется процессором с помощью векторных инструкций. Однако чтобы компилятор понимал, может ли он автоматически векторизировать код или нет, сам код должен быть написан определенным образом. Иногда компилятор не способен определить, можно ли безопасно векторизировать определенный цикл или нет. То же самое касается раскрутки цикла.
Но не волнуйтесь. Есть способы сообщить компилятору, что можно безопасно компилировать код с помощью этих оптимизаций.
Приведенные ниже методы должны работать для определенной группы компиляторов, которые могут генерировать Neon-код (подробнее читайте ниже), например, GCC, LLVM-clang (присутствует в Android NDK) и Arm C/C++ Compiler.
Передача компилятору инструкций для лучшей автовекторизации
В качестве демонстрационной задачи я возьму преобразование изображения из формата YUV в формат ARGB. Для оценки производительности я буду использовать Pixel 4a (устройство на базе Android).
Пример кода для преобразования изображения из формата YUV в формат ARGB. По умолчанию алгоритм построчно преобразовывает каждый пиксель:
// Код, выполняющий преобразование YUV изображения в формат ARGB.
for (int y = 0; y < image_height; ++y) {
for (int x = 0; x < image_width; ++x) {
int y_idx = (y * y_row_stride) + (x * y_pixel_stride);
y_val = static_cast(y_buffer[y_idx]);
int uvx = x / 2;
int uvy = y / 2;
int uv_idx = (uvy * uv_row_stride) + (uvx * uv_pixel_stride);
u_val = static_cast(u_buffer[uv_idx]) - 128;
v_val = static_cast(v_buffer[uv_idx]) - 128;
// Вычисление значений RGB
r = y_val + 1.370705f * v_val;
g = y_val - (0.698001f * v_val) - (0.337633f * u_val);
b = y_val + 1.732446f * u_val;
int argb_idx = y * image_width + x;
argb_output[argb_idx] = a | r << 16 | g << 8 | b;
}
} На устройстве Pixel 4a для 8-мегапиксельного изображения (3264×2448 = ~8 миллионов пикселей) я запустил приведенный выше код и получил следующую среднюю задержку времени выполнения.
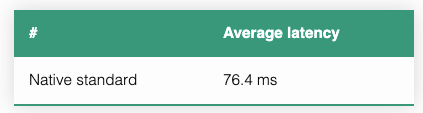 Средняя задержка времени выполнения приведенного выше кода на устройстве Pixel 4A для 8-мегапиксельного изображения.
Средняя задержка времени выполнения приведенного выше кода на устройстве Pixel 4A для 8-мегапиксельного изображения.
Стоит отметить, что компилятор уже пытается оптимизировать код. Он был запущен с флагом компиляции -O3 (то есть включена оптимизация скорости кода ценой увеличения размера бинарного файла и времени компиляции). Этот флаг подразумевает в том числе и включение автовекторизации.
Декларация pragma loop vectorize
Поместив следующую декларацию #pragma непосредственно перед циклом for, вы покажете компилятору, что цикл не содержит зависимостей данных, которые могут препятствовать автовекторизации:
#pragma clang loop vectorize(assume_safety)Важное примечание. Используйте эту декларацию #pragma только тогда, когда это действительно безопасно, чтобы случайно не прийти в состояние гонки.
Итак, если мы добавим ее в пример выше:
#pragma clang loop vectorize(assume_safety)
for (int y = 0; y < image_height; ++y) {
for (int x = 0; x < image_width; ++x) {
// остальная часть кода совпадает с предыдущим примером
}
}Мы получим следующие средние значения задержки:
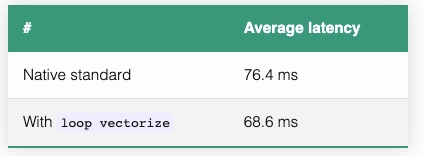 Ускорение на 11,4% достигнуто за счёт добавления директивы векторизации цикла.
Ускорение на 11,4% достигнуто за счёт добавления директивы векторизации цикла.
Декларация pragma loop unroll
Аналогичным образом при помощи следующей инструкции мы можем поручить компилятору раскручивать циклы:
#pragma clang loop unroll_count(2)Итак, если мы добавим в пример выше:
#pragma clang loop vectorize(assume_safety)
for (int y = 0; y < image_height; ++y) {
#pragma clang loop unroll_count(4)
for (int x = 0; x < image_width; ++x) {
// остальная часть кода совпадает с предыдущим примером
}
}Мы получим следующие средние числа задержки:
 Ускорение на 18,5% за счет добавления директив векторизации и развертывания цикла.
Ускорение на 18,5% за счет добавления директив векторизации и развертывания цикла.
Целочисленный аргумент N директивы unroll_count(N) подсказывает компилятору, на какое количество инструкций требуется увеличить тело цикла, — вы можете протестировать эту директиву с разными значениями и выбрать лучшее.
Мы ускорили наш код на 18%, добавив всего лишь две строчки и потратив менее часа усилий! При этом получившийся код легко читается и не вызывает трудностей при поддержке.
Некоторые другие советы
Для создания циклов используйте
<вместо<=или!=.Опция
-ffast-mathможет значительно повысить производительность операций над числами с плавающей точкой, но при этом нарушает обратную совместимость со стандартами IEEE и ISO для математических операций и может приводить к небольшим неточностям результатов вычислений из-за агрессивных оптимизаций.
TL; DR;
Вы можете значительно ускорить свой код, используя директивы, которые помогают компиляторам реализовать наиболее мощные механизмы оптимизации.
В рассматриваемом примере я смог добиться ускорения на 18% с двумя дополнительными строками кода, а сам код намного проще читать и поддерживать, чем код с векторными функциями-интринсиками.
Заключение
Итоговое ускорение, полученное с помощью этого подхода, зависит от степени независимости данных в рассматриваемом конкретном алгоритме.
Проведение тестов и бенчмарков с различной конфигурацией позволит добиться наиболее значительных улучшений. Повышение производительности (если вам удастся его достичь), безусловно, окупит потраченное на разработку время. Я планирую продолжать писать о способах повышения производительности кода без ущерба для удобства его поддержки. Многие полезные вещи я узнал во время работы над задачами в Google и собственными любительскими проектами.
[Бонус] Есть что еще почитать!
В этом разделе я немного расскажу о некоторых недостаточно раскрытых выше концепциях.
Neon
Нет, это не благородный газ. Neon является реализацией архитектуры Arm Advanced SIMD. Назначение Neon заключается в ускорении операций над данными благодаря следующим элементам:
Тридцать два 128-битных векторных регистра, каждый из которых способен содержать несколько потоков (lanes) данных.
Инструкции SIMD для одновременной работы на этих нескольких потоках данных.
Источник: developer.arm.com
В документации описано несколько способов использования этой технологии:
Использование библиотек с открытым исходным кодом и поддержкой Neon.
Функция автовекторизации в компиляторах, которые могут воспользоваться преимуществами Neon.
Использование функций-интринсиков Neon — компилятор заменит их соответствующими инструкциями Neon. Это предоставит низкоуровневый доступ к конкретным инструкциям Neon из кода C/C++.
Написание ассемблерного кода с инструкциями Neon — прерогатива только опытных программистов.
Ссылки
Что такое Neon?
Лучшие практики программирования для достижения целей автовекторизации
***
В блоге МойОфис на Хабре вы можете ознакомиться с переводами других интересных зарубежных текстов:
Впереди — больше переводов и подробных материалов с ИТ-экспертизой от специалистов МойОфис. Следите за нашими новостями и блогом на Хабре!
