[Перевод] Работа с графикой на языке Rust. Часть 2

В этой статье я продолжу перевод и исследование WGPU, библиотеки языка Rust для работы с графикой.
Для тех, кто не читал первую статью небольшая вводная информация.
WGPU реализует современный стандарт работы с видео подсистемами — WebGPU и компилируется в разные backend-ы (OpenGL, DirectX12, Metal, Vulkan, WebGL). Он одновременно проще для освоения, чем Vulkan и имеет более продуманное апи, чем OpenGL.
Приступим!
Урок 4. Текстуры
Текстурами называют изображения, которые накладывают поверх сетки (фигуры) для того, чтобы придать ей фактуру и/или детализацию.
Загрузка изображения
Первым делом, нам нужно добавить само изображение в папку с проектом.
Для этого, я сделал папку assets и положил туда картинку:

Для чтения файла я буду использовать image crate:
image = "0.24"
Далее, я сделаю отдельный модуль — texture:
use std::error::Error;
pub struct Texture {
pub texture: wgpu::Texture,
pub view: wgpu::TextureView,
pub sampler: wgpu::Sampler,
}Сделаем новый метод Texture::from_image:
pub fn from_image(
device: &wgpu::Device,
queue: &wgpu::Queue,
img: &image::DynamicImage,
label: Option<&str>
) -> Self {
let diffuse_rgba = diffuse_image.to_rgba8(); // 1
use image::GenericImageView;
let dimensions = diffuse_image.dimensions();
let size = wgpu::Extent3d { // 2
width: dimensions.0,
height: dimensions.1,
// Мы будем работать в 2D пространстве, поэтому используем только один слой
depth_or_array_layers: 1,
};
let texture = device.create_texture( // 3
&wgpu::TextureDescriptor {
label,
size,
mip_level_count: 1,
sample_count: 1,
dimension: wgpu::TextureDimension::D2,
// Указываем режим преобразования цвета из формата sRGB в линейное float [0, 1] значение
format: wgpu::TextureFormat::Rgba8UnormSrgb,
// TEXTURE_BINDING флаг устанавливается, если нужно использовать текстуру в шейдере
// COPY_DST говорит, что позже мы будем копировать позже изображение в эту текстуру
usage: wgpu::TextureUsages::TEXTURE_BINDING | wgpu::TextureUsages::COPY_DST,
}
);
...Преобразуем изображение в массив rgba байтов
Задаем (эмулируем) размерность в 3D пространстве
Создаем тектуру
Сейчас текстура пустая и нужно скопировать туда изображение:
...
// Копируем изображение в созданную выше текстуру
queue.write_texture(
// Задаем, куда копировать изображение
wgpu::ImageCopyTexture {
aspect: wgpu::TextureAspect::All,
texture: &texture,
mip_level: 0,
origin: wgpu::Origin3d::ZERO,
},
// Массив rgba пикселей
&rgba,
// Схема расположения данных
wgpu::ImageDataLayout {
offset: 0,
bytes_per_row: std::num::NonZeroU32::new(4 * dimensions.0),
rows_per_image: std::num::NonZeroU32::new(dimensions.1),
},
size,
);
Self { texture, view, sampler }
}Фильтрация текстур
Эту часть я долго не знал, как перевести, потому что не имел дело с Sampler-ами. Прежде чем разбираться со следующим фрагментом кода, дам небольшую вводную информацию.
Текстурные координаты не зависят от разрешения самой текстуры или экрана. Это означает, что где-то есть механизм, отвечающий за сопоставление текстурных пикселей (иногда их называют тексели) с текстурными координатами. И Sampler как раз и является этим механизмом, у которого есть несколько режимов работы:
let view = texture.create_view(&wgpu::TextureViewDescriptor::default());
let sampler = device.create_sampler(
&wgpu::SamplerDescriptor {
address_mode_u: wgpu::AddressMode::ClampToEdge, // 1
address_mode_v: wgpu::AddressMode::ClampToEdge,
address_mode_w: wgpu::AddressMode::ClampToEdge,
mag_filter: wgpu::FilterMode::Linear, // 2
min_filter: wgpu::FilterMode::Nearest, // 3
mipmap_filter: wgpu::FilterMode::Nearest,
..Default::default()
}
);Мы можем задать разные режимы для каждой из координат
address_mode_*Какой фильтр использовать, когда нужно растянуть (magnify) текстуру
Какой фильтр использовать, когда нужно сжать (minify) текстуру
FilterMode предоставляет две опции:
Linearсмешивает цвет ближайших к текстурной координате текселей. Чем ближе тексель к заданой координате, тем больший вклад он внесет в итоговый цвет. Этот метод еще называют билинейной интерполяциейNearestберет цвет ближайшего к текстурной координате текселя. В этом режиме при близком рассмотрении можно увидеть угловатые узоры и пикселизацию.
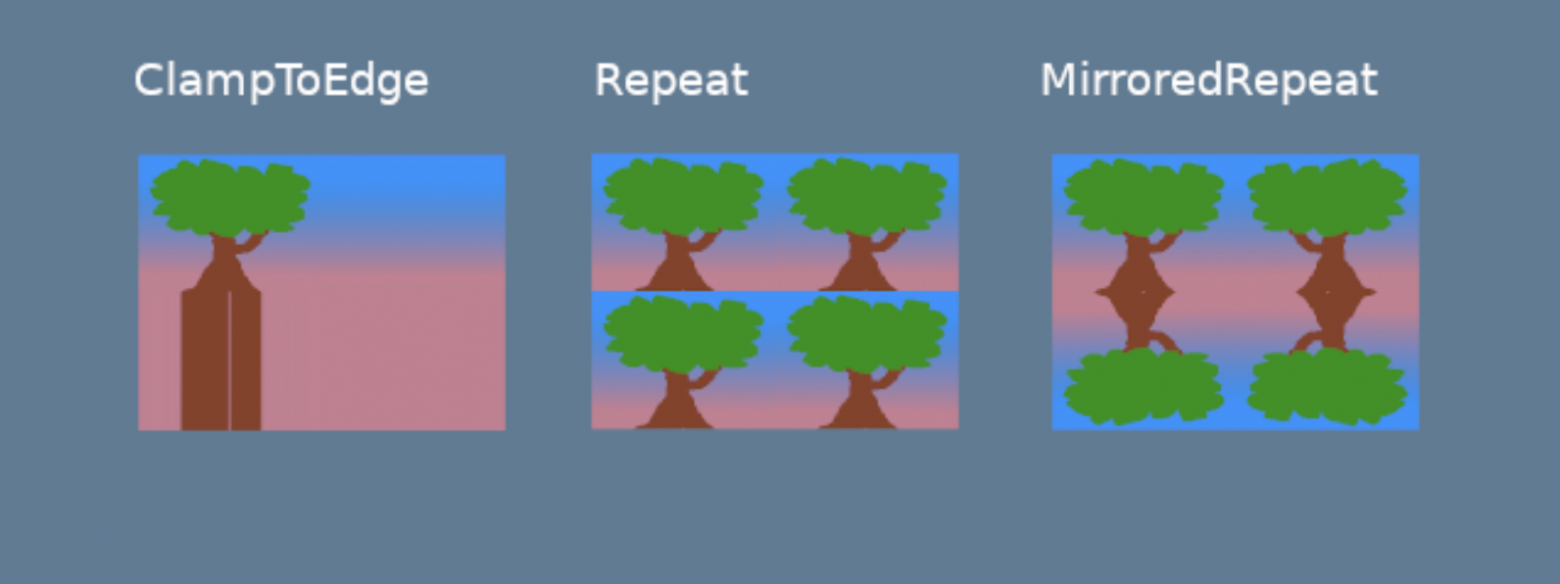
Рассмотрим режимы работы Sampler (AddressMode):
ClampToEdgeлюбой тексель, выходящий за пределы текстурных координат, примет цвет ближайшего к границе текстуры пикселяRepeatпо-русски — замостить, текстура будет повторяться по всей площади фигурыMirrorRepeatпохоже наRepeat, только изображение будет перевернуто, при выходе за границы текстуры
Нам понадобится еще один вспомогательный метод, который будет читать изображение:
pub fn from_bytes(
device: &wgpu::Device,
queue: &wgpu::Queue,
bytes: &[u8],
label: &str
) -> anyhow::Result {
let img = image::load_from_memory(bytes)?;
Ok(Self::from_image(device, queue, &img, Some(label)))
}
Здесь я использовал anyhow::Result из крейта anyhow = "1.0.64", для удобной работы с ошибками.
Теперь можно создать текстуру в методе State::new:
surface.configure(&device, &config);
// Создаем текстуру
let diffuse_bytes = include_bytes!("../assets/tree.png");
let diffuse_texture = Texture::from_bytes(&device, &queue, diffuse_bytes, "tree.png").unwrap();
Мы создали текстуру, view, sampler, но они пока не выполняют никакой работы. Давайте объедению их вместе!
BindGroup
BindGroup описывает набор ресурсов и схему данных для шейдеров. Мы объеденим ресурсы, сделанные выше.
Перед созданием BindGroup, нужно сделать BindGroupLayout:
...
let texture_bind_group_layout =
device.create_bind_group_layout(&wgpu::BindGroupLayoutDescriptor {
entries: &[
wgpu::BindGroupLayoutEntry {
binding: 0, // 1
visibility: wgpu::ShaderStages::FRAGMENT,
ty: wgpu::BindingType::Texture {
multisampled: false,
view_dimension: wgpu::TextureViewDimension::D2,
sample_type: wgpu::TextureSampleType::Float { filterable: true },
},
count: None,
},
wgpu::BindGroupLayoutEntry {
binding: 1, // 2
visibility: wgpu::ShaderStages::FRAGMENT,
// Здесь указываем SamplerBindingType::Filtering, потому что выше в sample_type указано filterable: true
ty: wgpu::BindingType::Sampler(wgpu::SamplerBindingType::Filtering),
count: None,
},
],
label: Some("texture_bind_group_layout"),
});
Эта схема данных содержит 2 связывания: первое для текстуры, второе для Sampler. Они будут видны только во фрагментном (ShaderStages::FRAGMENT) шейдере.
Поле visibility принимает битовую маску из значений NONE, VERTEX, FRAGMENT, или COMPUTE. Для текстур чаще всего используется FRAGMENT.
Теперь можно сделать BindGroup:
...
let diffuse_bind_group = device.create_bind_group(
&wgpu::BindGroupDescriptor {
layout: &texture_bind_group_layout,
entries: &[
wgpu::BindGroupEntry {
binding: 0,
resource: wgpu::BindingResource::TextureView(&diffuse_texture.view), // 1
},
wgpu::BindGroupEntry {
binding: 1,
resource: wgpu::BindingResource::Sampler(&diffuse_texture.sampler), // 2
}
],
label: Some("diffuse_bind_group"),
}
);
Я использую diffuse_texture.view и diffuse_texture.sampler, сделанные выше. BindGroup является частным случаем BindGroupLayout, поэтому между ними есть некоторое сходство. В WGPU их разделили для того, чтобы переключать их динамически (во время выполнения программы), но при этом, чтобы у них была одна схема данных (BindGroupLayout). Позднее, мы будем хранить каждую текстуру в своем BindGroup.
Осталось добавить поля в структуру State:
struct State {
surface: wgpu::Surface,
device: wgpu::Device,
queue: wgpu::Queue,
config: wgpu::SurfaceConfiguration,
size: winit::dpi::PhysicalSize,
render_pipeline: wgpu::RenderPipeline,
vertex_buffer: wgpu::Buffer,
index_buffer: wgpu::Buffer,
num_indices: u32,
// NEW!
diffuse_bind_group: wgpu::BindGroup,
diffuse_texture: texture::Texture,
} И вернуть diffuse_bind_group и diffuse_texture:
impl State {
async fn new() -> Self {
// ...
Self {
surface,
device,
queue,
config,
size,
render_pipeline,
vertex_buffer,
index_buffer,
num_indices,
// NEW!
diffuse_bind_group,
diffuse_texture,
}
}
}Мы сделали подготовительные действия, теперь можно воспользоваться diffuse_bind_group и добавить его в рендеринг:
// render()
// ...
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_bind_group(0, &self.diffuse_bind_group, &[]); // NEW!
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));
render_pass.set_index_buffer(self.index_buffer.slice(..), wgpu::IndexFormat::Uint16);
PipelineLayout
Помните PipelineLayout, который мы сделали во втором уроке? В нем задаются все BindGroupLayout, которые будут использоваться в пайплайне.
async fn new(...) {
// ...
let render_pipeline_layout = device.create_pipeline_layout(
&wgpu::PipelineLayoutDescriptor {
label: Some("Render Pipeline Layout"),
bind_group_layouts: &[&texture_bind_group_layout], // NEW!
push_constant_ranges: &[],
}
);
// ...
Теперь можно будет использовать texture_bind_group_layout в пайплайне!
Новый вершинный буфер
Посмотрим на структуру Vertex:
#[repr(C)]
#[derive(Copy, Clone, Debug, bytemuck::Pod, bytemuck::Zeroable)]
struct Vertex {
position: [f32; 3],
color: [f32; 3],
}Мы напрямую задавали цвет в вершинном буфере. Заменим поле color на tex_coords, так как теперь цвет будет вычисляться во фрагментном шейдере с помощью текстуры:
#[repr(C)]
#[derive(Copy, Clone, Debug, bytemuck::Pod, bytemuck::Zeroable)]
struct Vertex {
position: [f32; 3],
tex_coords: [f32; 2],
}
Так как текстурные координаты кодируются двумя значениями f32, нужно внести соответствующие изменения и в Vertex::description:
...
wgpu::VertexAttribute {
offset: std::mem::size_of::<[f32; 3]>() as wgpu::BufferAddress,
shader_location: 1,
format: wgpu::VertexFormat::Float32x2, // было Float32x3
}
...Теперь обновим сам вершинный буфер:
const VERTICES: &[Vertex] = &[
Vertex { position: [-0.0868241, 0.49240386, 0.0], tex_coords: [0.4131759, 0.99240386], }, // A
Vertex { position: [-0.49513406, 0.06958647, 0.0], tex_coords: [0.0048659444, 0.56958647], }, // B
Vertex { position: [-0.21918549, -0.44939706, 0.0], tex_coords: [0.28081453, 0.05060294], }, // C
Vertex { position: [0.35966998, -0.3473291, 0.0], tex_coords: [0.85967, 0.1526709], }, // D
Vertex { position: [0.44147372, 0.2347359, 0.0], tex_coords: [0.9414737, 0.7347359], }, // E
];Шейдеры
Заключительный этап, перед тем, как мы увидим результат — текстуру на нашем пентагоне. Мы изменили структуру Vertex, эти же изменения нужно отразить в вершинном шейдере:
// Вершинный шейдер
struct VertexInput {
@location(0) position: vec3,
@location(1) tex_coords: vec2, // NEW!
};
struct VertexOutput {
@builtin(position) clip_position: vec4,
@location(0) tex_coords: vec2, // NEW!
};
@vertex
fn vs_main(
model: VertexInput,
) -> VertexOutput {
var out: VertexOutput;
out.tex_coords = vec2(model.tex_coords.x, 1.0 - model.tex_coords.y); // NEW!
out.clip_position = vec4(model.position, 1.0);
return out;
} Обратите внимание на строку out.tex_coords = vec2.
В ней я инвертировал координату y, чтобы картинка не была перевернутая. Это связано тем, что в WGPU координата y направлена вверх, а в текстурах она направлена вниз.

Обновим также фрагментный шейдер:
// Фрагментный шейдер
@group(0) @binding(0)
var t_diffuse: texture_2d;
@group(0) @binding(1)
var s_diffuse: sampler;
@fragment
fn fs_main(in: VertexOutput) -> @location(0) vec4 {
return textureSample(t_diffuse, s_diffuse, in.tex_coords);
} Должно получиться вот так:

Домашнее задание
Добавьте возможность менять текстуру по нажатию на кнопку space.
Ссылка на код урока
Ссылка на оригинал
Урок 5. Uniform буфер и 3D камера
Хотя до этого мы рисовали только двухмерные фигуры, на самом деле, мы работали в трехмерном пространстве. Именно поэтому структура Vertex::position имеет 3 координаты, а не 2. Но мы никак не можем увидеть трехмерное пространство. Чтобы это исправить, добавим камеру.
Создаем перспективу
Этот туториал больше про WGPU, поэтому здесь не будет в деталях рассматриваться математические аспекты работы с камерой, только практика. Если же вы хотите лучше разобраться в этой теме вам сюда и сюда. Мы будем использовать cgmath, который возьмет на себя всю работу с вычислениями. Добавьте его в зависимости проекта:
cgmath = "0.18.0"Теперь можно сделать структуру для работы с камерой. Я сделаю отдельный файл camera.rs:
#[rustfmt::skip]
pub const OPENGL_TO_WGPU_MATRIX: cgmath::Matrix4 = cgmath::Matrix4::new(
1.0, 0.0, 0.0, 0.0,
0.0, 1.0, 0.0, 0.0,
0.0, 0.0, 0.5, 0.0,
0.0, 0.0, 0.5, 1.0,
);
pub struct Camera {
pub eye: cgmath::Point3,
pub target: cgmath::Point3,
pub up: cgmath::Vector3,
pub aspect: f32,
pub fovy: f32,
pub znear: f32,
pub zfar: f32,
}
impl Camera {
pub fn build_view_projection_matrix(&self) -> cgmath::Matrix4 {
let view = cgmath::Matrix4::look_at_rh(self.eye, self.target, self.up); // 1
let proj = cgmath::perspective(cgmath::Deg(self.fovy), self.aspect, self.znear, self.zfar); // 2
return OPENGL_TO_WGPU_MATRIX * proj * view; // 3
}
} Самое интересное происходит в build_view_projection_matrix:
Матрица
viewперемещает мир в позицию камеры. Она будет преобразовывать мировые координаты в координаты пространства окнаМатрица
projсоздает эффект перспективы. Без нее близкие и далекие объекты были бы одного размераВ WGPU используется координатная система DirectX & Metal. Это значит, что в нормализованных координатах (независимых от размера экрана) WGPU оси
xиyнаходятся в промежутке[-1.0, +1.0], а осьzв[0.0, +1.0]. В то же времяcgmathсделан для координатной системы OpenGL. Поэтому я использую матрицуOPENGL_TO_WGPU_MATRIXдля трансляции координат.Добавим теперь камеру в метод
State::new:
struct State {
// ...
camera: Camera,
// ...
}
async fn new(window: &Window) -> Self {
// let diffuse_bind_group ...
let camera = Camera {
// координаты камеры
eye: (0.0, 1.0, 4.0).into(),
// смотрим на центр
target: (0.0, 0.0, 0.0).into(),
up: cgmath::Vector3::unit_y(),
aspect: config.width as f32 / config.height as f32,
fovy: 45.0,
znear: 0.1,
zfar: 100.0,
};
Self {
// ...
camera,
// ...
}
}Теперь у нас есть камера и проекция, нужно каким-то образом отправить ее в шейдер.
Uniform буфер
До этого момента мы использовали буферы для хранения вершинного, индексных массивов и даже текстур. Рассмотрим специальный буфер — uniform. Он отличаются тем, что доступен в любом месте в шейдерах (как глобальные переменные). На самом деле, мы уже использовали его для текстуры и sampler-а. Давайте сделаем еще один буфер для хранения матрицы проекции!
Добавим в файл camera.rs следующий код:
// Данные, которые будут отправляться в шейдер нужно пометить специальной аннотацией
#[repr(C)]
// Pod & Zeroable для удобного приведения типов перед отправкой в WGPU
#[derive(Debug, Copy, Clone, bytemuck::Pod, bytemuck::Zeroable)]
struct CameraUniform {
// We can't use cgmath with bytemuck directly so we'll have
// to convert the Matrix4 into a 4x4 f32 array
view_proj: [[f32; 4]; 4],
}
impl CameraUniform {
fn new() -> Self {
use cgmath::SquareMatrix;
Self {
view_proj: cgmath::Matrix4::identity().into(),
}
}
fn update_view_proj(&mut self, camera: &Camera) {
self.view_proj = camera.build_view_projection_matrix().into();
}
}Теперь сделаем сам буфер в методе State::new:
// создание камеры
let mut camera_uniform = CameraUniform::new();
camera_uniform.update_view_proj(&camera);
let camera_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Camera Buffer"),
contents: bytemuck::cast_slice(&[camera_uniform]),
usage: wgpu::BufferUsages::UNIFORM | wgpu::BufferUsages::COPY_DST,
}
);
// ...Uniform буфер и BindGroup
Чтобы мы могли отправить буфер в видеокарту, нужно создать разметку (схему данных, layout):
// ...
let camera_bind_group_layout = device.create_bind_group_layout(&wgpu::BindGroupLayoutDescriptor {
entries: &[
wgpu::BindGroupLayoutEntry {
binding: 0,
visibility: wgpu::ShaderStages::VERTEX, // 1
ty: wgpu::BindingType::Buffer {
ty: wgpu::BufferBindingType::Uniform,
has_dynamic_offset: false, // 2
min_binding_size: None,
},
count: None,
}
],
label: Some("camera_bind_group_layout"),
});
// ...Буфер камеры нужен только в вершинном шейдере
Поле
dynamicобозначает, будет ли изменяться размер этого буфера. Это полезно, если вы храните массивы
После создания схемы данных, создадим BindGroup для буфера камеры:
// ...
let camera_bind_group = device.create_bind_group(&wgpu::BindGroupDescriptor {
layout: &camera_bind_group_layout,
entries: &[
wgpu::BindGroupEntry {
binding: 0,
resource: camera_buffer.as_entire_binding(),
}
],
label: Some("camera_bind_group"),
});
// ...Так же, как и с текстурой, нужно зарегистрировать схему данных буфера (для если вдруг вы захотите поменять буфер во время выполнения программы):
let render_pipeline_layout = device.create_pipeline_layout(
&wgpu::PipelineLayoutDescriptor {
label: Some("Render Pipeline Layout"),
bind_group_layouts: &[
&texture_bind_group_layout,
// NEW!
&camera_bind_group_layout,
],
push_constant_ranges: &[],
}
);Добавим новые поля в структуру State:
struct State {
// ...
camera: Camera,
camera_uniform: CameraUniform,
camera_buffer: wgpu::Buffer,
camera_bind_group: wgpu::BindGroup,
}
async fn new(window: &Window) -> Self {
// ...
Self {
// ...
camera,
camera_uniform,
camera_buffer,
camera_bind_group,
}
}Теперь у нас есть все для того, чтобы использовать новую камеру в методе State::render:
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_bind_group(0, &self.diffuse_bind_group, &[]);
// NEW!
render_pass.set_bind_group(1, &self.camera_bind_group, &[]);
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));
render_pass.set_index_buffer(self.index_buffer.slice(..), wgpu::IndexFormat::Uint16);
render_pass.draw_indexed(0..self.num_indices, 0, 0..1);Обращение к uniform буферу в шейдере
Добавьте в ваш шейдер структуру CameraUniform (1), uniform буфер (2) и обновите clip_position (3) следующим образом:
// Вершинный шейдер
struct CameraUniform {
view_proj: mat4x4,
};
// 1
@group(1) @binding(0)
var camera: CameraUniform;
struct VertexInput {
@location(0) position: vec3,
@location(1) tex_coords: vec2,
}
struct VertexOutput {
@builtin(position) clip_position: vec4,
@location(0) tex_coords: vec2,
}
@vertex
fn vs_main(
model: VertexInput,
) -> VertexOutput {
var out: VertexOutput;
out.tex_coords = vec2(model.tex_coords.x, 1.0 - model.tex_coords.y);
out.clip_position = camera.view_proj * vec4(model.position, 1.0); // 2
return out;
} Так как мы добавили новую
BindGroup, нужно явно указать индекс, какой именноBindGroupиспользовать для данной переменной, который определяется вrender_pipeline_layout.texture_bind_group_layoutидет в списке первой, поэтому имеет индекс 0. Поэтомуcamera_bind_groupбудет идти под индексом 1Порядок умножения важен при использовании матриц.
matrix_a*matrix_b!=matrix_b*matrix_a
Контроллер камеры
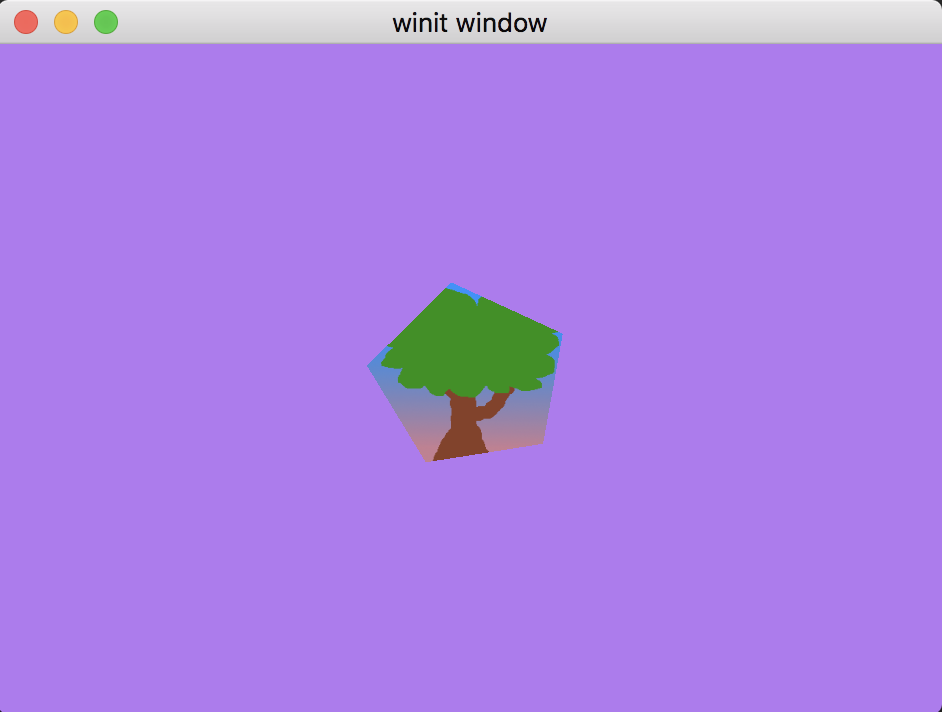
Такой результат должен получиться. Мы как будто смотрим издалека, поэтому картинка уменьшилась. Но пока что все еще не понятно, что мы в 3D пространстве.
Добавим возможность вращать картинку:
pub struct CameraController {
speed: f32,
is_forward_pressed: bool,
is_backward_pressed: bool,
is_left_pressed: bool,
is_right_pressed: bool,
}
impl CameraController {
pub fn new(speed: f32) -> Self {
Self {
speed,
is_forward_pressed: false,
is_backward_pressed: false,
is_left_pressed: false,
is_right_pressed: false,
}
}
pub fn process_event(&mut self, event: &WindowEvent) -> bool {
match event {
WindowEvent::KeyboardInput {
input: KeyboardInput {
state,
virtual_keycode: Some(keycode),
..
},
..
} => {
let is_pressed = *state == ElementState::Pressed;
match keycode {
VirtualKeyCode::W | VirtualKeyCode::Up => {
self.is_forward_pressed = is_pressed;
true
}
VirtualKeyCode::A | VirtualKeyCode::Left => {
self.is_left_pressed = is_pressed;
true
}
VirtualKeyCode::S | VirtualKeyCode::Down => {
self.is_backward_pressed = is_pressed;
true
}
VirtualKeyCode::D | VirtualKeyCode::Right => {
self.is_right_pressed = is_pressed;
true
}
_ => false,
}
}
_ => false,
}
}
pub(crate) fn update_camera(&self, camera: &mut Camera) {
use cgmath::InnerSpace;
let forward = camera.target - camera.eye;
let forward_norm = forward.normalize();
let forward_mag = forward.magnitude();
if self.is_forward_pressed && forward_mag > self.speed {
camera.eye += forward_norm * self.speed;
}
if self.is_backward_pressed {
camera.eye -= forward_norm * self.speed;
}
let right = forward_norm.cross(camera.up);
// Корректировка на случай, если нажаты кнопки вперед/назад
let forward = camera.target - camera.eye;
let forward_mag = forward.magnitude();
if self.is_right_pressed {
// Нужно пересчитать расстояние между target и eye чтобы оно не менялось
// Таким образом eye будет находиться в диапазоне между target и eye
camera.eye = camera.target - (forward + right * self.speed).normalize() * forward_mag;
}
if self.is_left_pressed {
camera.eye = camera.target - (forward - right * self.speed).normalize() * forward_mag;
}
}
}Этот код не идеален, но все же он работает. Можете допилить его под свои нужды!
И, как обычно, нужно добавить контроллер камеры в структуру State:
struct State {
// ...
camera: Camera,
// NEW!
camera_controller: CameraController,
// ...
}
// ...
impl State {
async fn new(window: &Window) -> Self {
// ...
let camera_controller = CameraController::new(0.2);
// ...
Self {
// ...
camera_controller,
// ...
}
}
}Теперь мы можем добавить обработку событий камеры в метод State::input:
fn input(&mut self, event: &WindowEvent) -> bool {
self.camera_controller.process_events(event)
}Но, как ни странно, камера все еще не двигается! По факту, мы только меняем состояние камеры в памяти процесса, поэтому итоговая картинка никак не меняется. Чтобы это исправить, нужно обновить uniform буфер камеры. Есть несколько способов, как это сделать:
Создать отдельный буфер и скопировать туда содержимое
camera_buffer. Новый буфер называют staging буфер. Обычно, применяется именно этот способ, потому что «camera_buffer» доступен только внутри видеокарты, что позволяет сделать GPU оптимизацию скоростиИспользовать асинхронные методы буфера
map_read_asyncиmap_read_async. В целом, это более сложный подход (потому что асинхронный), вместе с которым нужно будет еще использоватьBufferUsages::MAP_READи/илиBufferUsages::MAP_WRITEИспользовать метод
queue.write_buffer
Я выбираю номер три:
fn update(&mut self) {
self.camera_controller.update_camera(&mut self.camera);
self.camera_uniform.update_view_proj(&self.camera);
self.queue.write_buffer(&self.camera_buffer, 0, bytemuck::cast_slice(&[self.camera_uniform]));
}Теперь, когда все готово, нужно вызвать метод State::update в главном цикле main.rs:
Event::RedrawRequested(window_id) if window_id == window.id() => {
// NEW!
state.update();
match state.render() {
Ok(_) => {}
Err(wgpu::SurfaceError::Lost) => state.resize(state.size),
Err(wgpu::SurfaceError::OutOfMemory) => *control_flow = ControlFlow::Exit,
// Все остальные ошибки будут обработаны в следующем кадре
Err(e) => eprintln!("{:?}", e),
}
}Это все, что нужно было сделать. Теперь вы можете управлять камерой с помощью кнопок wsad. Этот пентагон напоминает мне карточки из игры Гарри Поттер, сравните:


Домашнее задание
Сделайте так, чтобы модель вращалась отдельно от камеры (как на гифке). Подсказка: вам понадобится еще одна матрица.
Ссылка на код урока
Ссылка на оригинал
Урок 6. Instancing
Сейчас наша сцена очень простая, один объект в точке (0, 0, 0). Как сделать больше объектов? Техника клонирования (отрисовки одного и того же объекта в разных местах) называется instancing.
Есть много способов, как можно размножить объекты. Например, можно включить в uniform буфер изменяющиеся параметры (позиция и вращение) и обновлять их каждый раз, когда отрисовывается объект.
Это расточительно с точки зрения производительности. Обновление uniform буфера для каждого инстанса увеличить количество операций копирования в каждом кадре. Кроме того, потребуется дополнительный буфер для обновленных данных.
Как можно сделать лучше?
Давайте посмотрим на сигнатуру draw_indexed:
pub fn draw_indexed(
&mut self,
indices: Range,
base_vertex: i32,
instances: Range // <-- Вот сюда
) Аргумент instances принимает список инстансов, которые нужно отрисовать. Это и есть решение! Если я укажу 0..5, тогда будет отрисовано 5 объектов.
Тип Range выглядит странно, почему просто не использовать u32, если этот аргумент определяет количество объектов?
Причина в том, что иногда нужно отрисовать только некоторые фигуры, чего нельзя было бы достичь с параметром u32.
Хорошо, теперь мы знаем, как отрисовать несколько инстансов объекта. Как указать, как именно они должны быть отрисованы? Мы используем instance буфер.
Instance буфер
Instance буфер создается тем же способом, как и uniform буфер.
Первым делом, сделаем структуру Instance:
// instance.rs
struct Instance {
position: cgmath::Vector3,
rotation: cgmath::Quaternion,
}
impl Instance {
pub fn new(position: cgmath::Vector3, rotation: cgmath::Quaternion) -> Self {
Self {
position, rotation
}
}
} Здесь я использую новый математический структуру — Quaternion. Их часто используют для управления вращением. Здесь вы можете подробнее изучить эту тему.
WGSL шейдеры не имеют структур для работы с кватернионами, поэтому сделаем дополнительную структуру, где будет разметка схемы данных:
#[repr(C)]
#[derive(Copy, Clone, bytemuck::Pod, bytemuck::Zeroable)]
struct InstanceRaw {
model: [[f32; 4]; 4],
}
impl InstanceRaw {
pub(crate) fn description<'a>() -> wgpu::VertexBufferLayout<'a> {
use std::mem;
wgpu::VertexBufferLayout {
array_stride: mem::size_of::() as wgpu::BufferAddress,
// Переключаем режим работы с VertexStepMode::Vertex на VertexStepMode::Instance
// Это значит, что шейдер будет итерироваться по инстансам, а не векторам
step_mode: wgpu::VertexStepMode::Instance,
attributes: &[
// mat4 имеет размер 4 векторов vec4, поэтому я делаю 4 слота для каждого вектора
wgpu::VertexAttribute {
offset: 0,
// Пока что в вершинном шейдере я использую 0 и 1 location.
// 2, 3 и 4 зарезервирую на будущее, поэтому здесь shader_location = 5
shader_location: 5,
format: wgpu::VertexFormat::Float32x4,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 4]>() as wgpu::BufferAddress,
shader_location: 6,
format: wgpu::VertexFormat::Float32x4,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 8]>() as wgpu::BufferAddress,
shader_location: 7,
format: wgpu::VertexFormat::Float32x4,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 12]>() as wgpu::BufferAddress,
shader_location: 8,
format: wgpu::VertexFormat::Float32x4,
},
],
}
}
} Данные из этой структуры попадут в wgpu::Buffer. Дополнительное разделение Instance и InstanceRaw играет нам на руку, тк можно будет менять отдельно Instance без возни с матрицами. Нужно только не забыть обновить данные в InstanceRaw перед отрисовкой.
Давайте сделаем метод для конвертации Instance в InstanceRaw:
impl Instance {
// …
fn to_raw(&self) -> InstanceRaw {
InstanceRaw {
model: (cgmath::Matrix4::from_translation(self.position) * cgmath::Matrix4::from(self.rotation)).into(),
}
}
}Добавим теперь инстансы в структуру State:
struct State {
// …
instances: Vec,
instance_buffer: wgpu::Buffer,
} Я буду использовать трейты вычисления из cgmath, их нужно импортировать:
use cgmath::prelude::*;Чтобы создать множество объектов, используем двумерный массив 10×10, определив в начале константы:
const NUM_INSTANCES_PER_ROW: u32 = 10;
const INSTANCE_DISPLACEMENT: cgmath::Vector3 = cgmath::Vector3::new(NUM_INSTANCES_PER_ROW as f32 * 0.5, 0.0, NUM_INSTANCES_PER_ROW as f32 * 0.5); В методе State::new создаем двумерный массив:
// Instancing
let instances = (0..NUM_INSTANCES_PER_ROW).flat_map(|z| {
(0..NUM_INSTANCES_PER_ROW).map(move |x| {
let position = cgmath::Vector3 { x: x as f32, y: 0.0, z: z as f32 } - INSTANCE_DISPLACEMENT;
let rotation = if position.is_zero() {
// Кватернионы могут изменять масштаб, поэтому здесь дополнительная проверка
// на случай, если объект находится в точке (0, 0, 0)
// Так мы избежим ситуации, когда масштаб объекта стал нулевой
cgmath::Quaternion::from_axis_angle(cgmath::Vector3::unit_z(), cgmath::Deg(0.0))
} else {
cgmath::Quaternion::from_axis_angle(position.normalize(), cgmath::Deg(45.0))
};
Instance::new(position, rotation)
})
}).collect::>(); Теперь, когда есть массив объектов, можем записать их в буфер:
let instance_data = instances.iter().map(Instance::to_raw).collect::>();
let instance_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Instance Buffer"),
contents: bytemuck::cast_slice(&instance_data),
usage: wgpu::BufferUsages::VERTEX,
}
); Буфер готов, обновим render_pipeline:
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
vertex: wgpu::VertexState {
// ...
// UPDATED!
buffers: &[Vertex::description(), InstanceRaw::description()],
},
// ...
});Последний штрих в методе State::new, добавим новые поля в структуру:
Self {
// ...
// NEW!
instances,
instance_buffer,
}Рендеринг
Мы сделали множество инстансов, которые можно отрисовать. В методе State::render я добавлю новый instance_buffer в render_pass и укажу количество инстансов для отрисовки:
// NEW!
render_pass.set_vertex_buffer(1, self.instance_buffer.slice(..));
render_pass.set_index_buffer(self.index_buffer.slice(..), wgpu::IndexFormat::Uint16);
// UPDATED!
render_pass.draw_indexed(0..self.num_indices, 0, 0..self.instances.len() as _);Если вы будете добавлять новые инстансы, не забудьте создать ещё раз instance_buffer и camera_bind_group, иначе инстансы не будут отображаться корректно.
Обновим шейдер. Добавьте следующий код в начало файла:
struct InstanceInput {
@location(5) model_matrix_0: vec4,
@location(6) model_matrix_1: vec4,
@location(7) model_matrix_2: vec4,
@location(8) model_matrix_3: vec4,
}; Теперь обновим метод vs_main:
fn vs_main(
model: VertexInput,
instance: InstanceInput,
) -> VertexOutput {
var out: VertexOutput;
let model_matrix = mat4x4(
instance.model_matrix_0,
instance.model_matrix_1,
instance.model_matrix_2,
instance.model_matrix_3,
);
out.tex_coords = vec2(model.tex_coords.x, 1.0 - model.tex_coords.y);
out.clip_position = camera.view_proj * model_matrix * vec4(model.position, 1.0);
return out;
} Я в начале умножаю camera.view_proj, потому что camera.view_proj меняет координаты в пространство камеры, а model_matrix находится в мировом пространстве. Если их поменять местами, то получим некорректный результат (я проверил!).
Итоговый результат:

Домашнее задание
Добавьте вращение инстансов.
Ссылка на код урока
Ссылка на оригинал статьи
