NULL-значения в PostgreSQL: правила и исключения
Навскидку многим кажется, что они знакомы с поведением NULL-значений в PostgreSQL, однако иногда неопределённые значения преподносят сюрпризы. Мы с коллегами написали статью на основе моего доклада с PGConf.Russia 2022 — он был полностью посвящён особенностям обработки NULL-значений в Postgres.
NULL простыми словами
Что такое SQL база данных? Согласно одному из определений, это просто набор взаимосвязанных таблиц. А что такое NULL? Обратимся к простому бытовому примеру: все мы задаём друг другу дежурный вопрос: «Как дела?». Часто мы получаем в ответ: «Да ничего…» Вот это «ничего» нам и нужно положить в базу данных — NULL: неопределённое, некорректное или неизвестное значение.

Допустим, вы суммируете две колонки, и в сотой по счёту записи наткнулись на NULL. Что тогда делать? Или возвращать ошибку, потому что так нельзя, или всё-таки как-то выполнить сложение и идти дальше. Сообщество решило в пользу второго варианта и закрепило это в стандартах языка SQL. Также договорились, что данные любого типа могут оказаться NULL, написали специальные функции и операции для обработки NULL-значений.
NULL может оказаться в столбце с любым типом данных и попасть на вход к любому оператору или функции. Соответственно, все операторы и функции как-то обрабатывают NULL, но результат обработки иногда оказывается неожиданным.
Какие значения не являются NULL?
Давайте теперь посмотрим, что не есть NULL. Ноль — это просто ноль, не NULL. Пустая строка — это пустая строка в Postgres, в отличие от Oracle. Пустой массив, пустой JSON, массив NULL-значений, пустой диапазон — это не NULL. Сложные типы, включающие NULL, уже не являются NULL.

Есть, правда, одно исключение: запись, собранная из NULL-значений, является NULL. Это сделано для совместимости со стандартом языка SQL. Однако, «под капотом» Postgres функции и операторы считают запись, состоящую из NULL-значений, NOT NULL. Ниже приведены результаты обработки такой записи для некоторых из них:
сount (row (NULL)) посчитает такую запись;
num_nulls (row (NULL)) выдаст ноль;
row (NULL) IS DISTINCT FROM NULL выдаст TRUE.
Ещё удивительнее пример с записями, содержащими NULL:
row (NULL: int, 'Bob':: TEXT) IS NULL ожидаемо выдаст FALSE, но
row (NULL: int, 'Bob':: TEXT) IS NOT NULL тоже выдаст FALSE!
Тем не менее, это поведение не является багом и описано в документации.
Операции с NULL
Почти все бинарные операции с NULL — сложить, вычесть, умножить, конкатенировать — дают на выходе NULL. С этим стоит быть осторожнее. Если вы к строке или к JSON конкатенируете что-то, оказавшееся NULL, то получаете на выходе NULL. А если вы ещё и сделали UPDATE в базу данных, выйдет совсем нехорошо.
Тем не менее, логическая операция TRUE OR NULL на выходе даёт TRUE. FALSE AND NULL даёт в результате FALSE. То есть существуют некоторые исключения из общего правила.

Операции сравнения
Операции сравнения — больше, меньше, больше или равно — c NULL на выходе дают NULL. При этом и сам NULL не равен самому себе. Впрочем, в PostgreSQL есть параметр transform_null_equals, который по умолчанию выключен. Если его включить, то NULL будет равен NULL.
Для проверки любого значения на NULL в Postgres предусмотрен специальный оператор — … IS NULL, … IS NOT NULL. Также может быть непривычно, что при сравнении булевых переменных с NULL или при применении оператора равенства помимо значений TRUE и FALSE возможно ещё и неизвестное значение. При этом оператор IS (NOT) UNKNOWN — это аналог IS (NOT) NULL для булевых переменных.
Операторы IS TRUE или IS FALSE для булевых переменных дают или TRUE, или FALSE. NULL в результате их применения получиться не может. Использование оператора IS TRUE позволяет писать более надёжный код, чем обычное сравнение = TRUE, которое может выдать не учтённое программистом NULL-значение и пойти «не туда».

Что если нам нужно сравнить два значения X и Y, считая, что NULL-значения равны друг другу? Можно самому написать конструкцию из логческих операторов, но существует уже готовый оператор X IS (NOT) DISTINCT FROM Y. Правда, планировщик PostgreSQL плохо понимает этот оператор и может выдавать долгие планы выполнения для запросов с ним.
Cпециальные функции для работы с NULL
Обратимся к специальным функциям для работы с NULL. Всем известная coalesce возвращает первый NOT NULL аргумент. Есть nullif, есть num_nulls — этой функции можно дать сколько угодно аргументов, она посчитает количество NULL-значений. С помощью функции num_nonnulls можно посчитать NOT NULL значения.
Как правило, функции с произвольным числом аргументов игнорируют NULL. Такие функции, как greatest, concat его просто проигнорируют. При этом функция создания массивов включит NULL-значение во вновь образованный массив, за этим надо следить.

NULL и агрегатные функции
Что касается агрегатных функций, то array_agg, json_agg включают NULL в агрегат, а конкатенация строки не может вставить NULL-значение в середину строки, и поэтому она NULL игнорирует.
Статистические функции min, max, sum игнорируют NULL, а вот с выражением Count всё хитро. Count по конкретному полю посчитает только строки, где выражение NOT NULL, а вот Count со звёздочкой посчитает всё, включая NULL-значения.

Что со всем этим делать? Можно почитать в справке или потестировать, как функция обрабатывает NULL-значения. А лучше использовать выражение FILTER и в явном виде исключить все NULL-значения.
NULL и пользовательские функции
Теперь о пользовательских функциях. При создании пользовательской функции по умолчанию включен режим CALLED ON NULL INPUT, то есть при наличии NULL среди аргументов функция вызовется и будет обрабатывать это значение. Если вам это не нужно, можно использовать RETURNS NULL ON NULL INPUT либо STRICT — в этом случае функция, обнаружив NULL хотя бы в одном аргументе, сразу возвращает NULL и дальше вообще не думает — для экономии времени.

Многие системные функции в PostgreSQL определены именно как STRICT, поэтому стали возможны некоторые математические казусы. Например, NULL можно разделить на ноль, и в результате вы получите NULL — вместо ошибки деления на ноль. NULL в степени ноль тоже является NULL, хотя в математике любое число в нулевой степени, даже если это сам ноль, даёт единицу. Непонятно, правильно ли такое поведение с философской точки зрения, но вроде пока никто не жаловался.
Группировка и сортировка
Если говорить о группировке, то она считает все NULL-значения одинаковыми, так как это делает оператор IS NOT DISTINCT FROM. При сортировке есть специальные подвыражения, в которых можно указать NULLS FIRST или NULLS LAST. По умолчанию выбирается NULLS LAST, то есть считается, что неопределённые значения больше всех остальных чисел.

Сортировка работает так при создании выборки, индекса, в агрегатных функциях и оконных функциях.
NULL и записи
Когда мы формируем запись из нескольких значений, то сравниваются все NOT NULL значения. Если найдётся различие, то результат будет FALSE. Если все NOT NULL значения совпадают, и нашёлся NULL, то будет NULL.

Сравнение на больше/меньше выполняется по другим правилам. Как только попадётся не совпадающее значение, тогда оно будет больше или меньше, а если обнаружится NULL, то будет NULL.
NULL и диапазоны
С бинарными операциями разобрались, но что если у нас тернарная операция? Например, SELECT NOW BETWEEN NULL AND NULL. Получится, ожидаемо, NULL.
Однако, точно такое же выражение, сформулированное через диапазоны, неожиданно даёт TRUE. Да, с точки зрения Postgres здесь и сейчас мы находимся в неопределённом промежутке времени!

Согласно стандарту SQL, все диапазонные типы — не только временные, а все вообще —воспринимают границу NULL как бесконечность.
Я полюбопытствовал и выяснил, что промежуток от минус бесконечности до плюс бесконечности входит в промежуток от NULL до NULL, а обратное — неверно.
Выходит, что NULL здесь даже несколько больше, чем бесконечность.
Также я попытался проверить, входит ли NULL в промежуток от минус бесконечности до плюс бесконечности. Оказалось, что это неизвестно. Это контринтуитивный для меня момент: мне казалось, что полный диапазон значений от минус до плюс бесконечности должен включать в себя любое значение, в том числе и неопределённое. Но нет, в PostgreSQL это не так.
Откуда в запросах появляются NULL-значения?
Во-первых, они попадают в базу данных при вставке или обновлении и продолжают храниться в столбцах таблиц.
Во-вторых, они записываются в базу как результат подзапроса не нашедшего ни одной строки — в этом случае подзапрос вернёт вам NULL.
В-третьих, NULL-значения могут появляться в результате операции объединения LEFT JOIN.
В-четвёртых, NULL-значения появлются как результат некоторых функций при некоторых условиях.
В-пятых, их можно создать вручную, например, при использовании конструкции CASE. В каком-то хитром запросе вы можете указать, что при определённых условиях получится неизвестное значение.

Структура базы данных и NULL
Во-первых, можно запретить хранение NULL-значений в столбце. Есть специальное ограничение (constraint) NOT NULL. Крайне рекомендую так и поступать — всегда запрещать хранение NULL-значений, если только вы не планируете хранить и обрабатывать NULL именно в этом столбце.
При определении ограничения (constraint) тоже есть одна особенность: если условие возвращает NULL, это считается допустимым, и такая запись может быть вставлена.
Например, ограничение Foreign key позволяет в дочерней таблице вставить запись со ссылкой, которая является NULL. Это будет допустимо.
Ограничение CHECK (price > 0) даст вам вставить в таблицу поле для Price со значением, равным NULL.

Ограничение unique позволяет создать несколько записей со значением NULL. Правда, в PostgreSQL 14 уже появилось специальное «заклинание», которое может запретить несколько записей с NULL.
Как NULL хранится внутри записи БД?
NULL вообще не хранится среди полей записи, но если там есть хотя бы одно NULL-значение, то создаётся битовая карта неопределённых значений, которая называется t_bits. Стоит запомнить, что самое первое NULL-значение влечёт за собой создание такой карты и расход некоторого количества места.
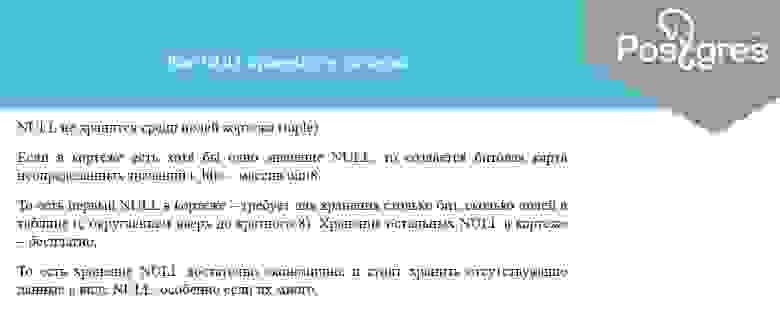
Правда, все дополнительные NULL-значения в этой записи вы уже храните бесплатно и достаточно компактно. Если вы действительно экономите каждый байт в своей базе данных, хранение NULL — правильное занятие.
NULL и индексы
Postgres хранит NULL-значения в btree-индексах. Этим он отличается от Oracle. Также Postgres может использовать такой индекс при поиске записей по NULL-значению.
Тем не менее, хранение NULL-значений в индексе для вас бесполезно, если у вас нет такого типа запросов (они довольно редки, и их можно проверить в представлении pg_stats_statements).

Также пользы не будет при большом количестве NULL-значений в индексе, и следовательно, плохой селективности. В этом случае будет дешевле сделать последовательное сканирование таблицы, а не возиться с индексом.
Вот пример случая с большим числом NULL-значений в таблице. У вас есть внешний ключ (foreign key) на какую-то родительскую таблицу, но реальная ссылка используется редко, и в основном в дочерней таблице NULL-значения.
Или же у вас может быть какой-то хитрый функциональный индекс, который часто возвращает NULL. Здесь у нас пример по JSONB-ключу key1, а если у вас в JSON этот ключ встречается нечасто, то и большинство значений будет NULL.
Если у вас NULL-значений много, то вам поможет перестроение индекса на частичный с условием WHERE <ваше поле или выражение> IS NOT NULL. То есть мы просто выкидываем такие значения из нашего индекса. Это принесёт ряд улучшений:
— во-первых, сокращается размер индекса на дисках, в том числе на репликах и бэкапах;
— во-вторых, уменьшится количество записей в журнал предзаписи (WAL);
— в-третьих, освободится место в оперативной памяти и улучшится кэширование.
В моей практике были случаи, когда реально удавалось сократить размер индекса на порядок.
В поиске таких индексов поможет представление pg_stats. В нём есть поле null_frac, которое показывает долю NULL-значений в столбцах таблиц. То есть с помощью этого представления можно определить, есть ли у вас кандидаты на оптимизацию.
Сценарий аккуратного переезда вполне очевиден:
— создаёте новый частичный индекс;
— по представлению pg_stat_user_indexes убеждаетесь, что запросы переехали на новый индекс;
— удаляете старый индекс.
Выводы
Значение NULL может преподнести некоторые сюрпризы, если вы к нему не готовы.
Стоит проверить, как работают с NULL вызываемые вами функции и ваш код.
Запрещайте NULL там, где вы не планируете его использовать явным образом.
Проверяйте ваши индексы на наличие NULL-значений — возможно, за счёт оптимизаций удастся сэкономить некоторое количество памяти и ресурсов процессора.
Полезные ссылки
В статье Хаки Бенита рассматриваются как раз такие переполненные NULL-значениями индексы, есть SQL запрос для их поиска в вашей базе данных и практический результат перестроения: https://hakibenita.com/postgresql-unused-index-size
Классическая статья Брюса Момжиана (Bruce Momjian) под названием «NULLs Make Things Easier?» доступна здесь: https://momjian.us/main/writings/pgsql/nulls.pdf
Также рекомендуем ознакомиться с книгой Егора Рогова «PostgreSQL 14 изнутри»: https://edu.postgrespro.ru/postgresql_internals-14.pdf
