[Перевод] Проверенные решения пяти проблем автоматизации тестирования
Ключевые выводы:
Эмуляторы API и сервисов могут помочь в устранении пяти распространенных проблем, возникающих при попытке автоматизировать процесс тестирования.
Можно имитировать API или сервисы, которые еще не доступны.
Эмуляторы могут автоматизировать медленные или ручные процессы на бэкенде или сторонних системах.
Эмуляторы можно использовать для создания тестовых данных и обхода распространенных проблем, которые с ними могут возникнуть.
Эмуляторы можно использовать для создания гипотетических сценариев для тестирования сценариев ошибок и увеличения тестового покрытия.
Можно проводить тестирование на ограничение скорости и троттлинг с помощью их имитации в тест-сьюте.
В этой статье рассмотрим пять типичных проблем, которые часто мешают командам автоматизировать процесс тестирования. Эти проблемы можно решить с помощью имитирования API и сервисов.
За последние 15 лет работы с разными командами разработки я заметил, что использование дублеров тестирования, таких как симуляторы API и сервисов, является стандартной практикой в некоторых командах, которые знают об этой технике. Как правило, это команды придерживаются Agile-подхода или подхода экстремального программирования (Extreme Programming, XP) и имеют опыт работы по методологиям TDD и BDD.
Другие же команды не используют симуляторы или эмуляторы в основном потому, что никогда о них не слышали. Эта статья написана для для тестировщиков, начинающих свой путь в автоматизации тестирования. В ней я покажу, как можно решить несколько повседневных проблем с помощью эмуляторов.
Что такое эмулятор API/сервиса?
Использование эмулятора вместо реального микросервиса, стороннего сервиса или другой программной системы называется имитацией (API или программного обеспечения). Также можно встретить такие названия, как API mocking, виртуализация сервисов, тестовые дублеры, инструменты для создания тестовых заглушек и имитации HTTP (S) и других протоколов.
Сами названия техник не так важны. Важно то, что они позволяют проводить тестирование компонентов в изоляции.
Можно имитировать API, сервисы или и то, и другое. В этой статье я решил выделить оба названия, поскольку на примере своих клиентов я заметил, что разные команды используют разные названия в зависимости от того, в какой стране они находятся.
Я также заметил, что, например, «API» является популярным термином среди разработчиков и тестировщиков, работающих с HTTP, а «сервис» может быть более распространенным среди руководителей отдела разработки или QA в компании, работающей со сторонними поставщиками услуг.
Давайте поработаем с примером микросервисной архитектуры, показанной на рисунке 1. На рисунке изображена типичная ситуация, когда у нас есть веб-сайт, бэкенд которого состоит из нескольких микросервисов, подключающихся к базе данных, сторонней системе и устаревшему мэйнфрейму.

Рисунок 1: Пример микросервисной архитектуры
На рисунке 2 показана инфраструктура разработки и тестирования, которая включает в себя несколько симуляторов.

Рисунок 2: Инфраструктура разработки и тестирования, включающая симуляторы API и сервисов
Тестовое покрытие в автоматизации
Как заметил Мартин Фаулер (Martin Fowler) десять лет назад, измерение тестового покрытия отлично подходит для поиска непроверенного кода, но является плохой целью тестирования.
Я упоминаю об этом в начале статьи, поскольку в некоторых моментах буду использовать термин «тестовое покрытие» в качестве метрики. Хочу уточнить, что имею в виду под фразой »20% покрытия кода автоматизированными тестами». Это означает: «Мы знаем, что 20% кода покрыто различными типами автоматизированных тестов, но 80% кода тестами не покрыто». Это не значит, что «покрытие кода — хорошая метрика для оценки качества наших результатов». Существуют лучшие метрики для измерения качества процесса доставки программного обеспечения, например, четыре ключевые метрики. BDD-подход также может помочь в оценке качества тестов.
Однако знание того, что тесты покрывают код, — это уже неплохое начало. Не покрытый тестами код может привести к таким проблемам, как необнаруженные баги или непреднамеренные изменения в поведении. В частности, покрытие автоматизированными тестами помогает составить повторяющийся набор регрессионных тестов, который будет гарантировать, что поведение системы будет стабильным между релизами.
Проблемы автоматизации тестирования решаются с помощью симуляторов
Во время разработки и тестирования продукта разработчики и тестировщики могут столкнуться с несколькими распространенными проблемами:
Недоступность API/сервисов.
Медленный или ручной процесс в бэкенде или сторонних системах.
Проблемы с тестовыми данными (требуется настройка тестовых данных; изменения тестовых данных нарушают существующие автоматизированные тесты; требуется обновление тестовых данных).
Создание гипотетических сценариев для тестирования сценариев ошибок.
Ограничения API и сторонних сервисов.
Эти проблемы можно решить с помощью симуляторов. Ниже я подробно рассмотрю каждую ситуацию.
На рисунке 3 показано, как каждая из этих проблем может стать более трудоемкой, если с ней придется столкнуться на более поздних этапах пути автоматизации тестирования.

Рисунок 3: Создание автоматизированных тестов проходит быстрее с помощью имитации API и сервисов
Проблема 1: API или сервисы еще недоступны
Если API или сервис еще недоступен, можно использовать эмулятор/симулятор API, чтобы распараллелить работу команды и быстрее создать свой продукт.
Но на этом преимущества не заканчиваются, поскольку симуляторы API помогут в автоматизации тестирования.
Допустим, вы работаете над микросервисом Purchasing, показанным на рисунке 1. Следуя TDD, вы хотите написать тесты для новой функции, которая опирается на новый API в микросервисе Payments. К сожалению, новый API микросервиса Payments все еще разрабатывается. На момент запуска тестов для микросервиса Purchasing нет API, к которому можно подключиться. При недоступном API автоматизированные тесты сфейлят, если не использовать дублер теста, например, симулятор API.
Используя симулятор API, вы можете настроить программные ответы на тестовые данные для нового, несуществующего API, а затем запустить тест. На рисунке 4 показан этот процесс. Вам не нужно ждать другую команду и можно продолжить разработку и тестирование микросервиса Purchasing.

Рисунок 4: Автоматизированные тесты настраивают симулятор API и тестируют микросервис
Кейс: API еще не доступны
В статье «Использование API-First Development и API Mocking для устранения критических зависимостей» я описал простой сценарий, когда четыре команды, работающие над новой платформой, параллельно работают над разными микросервисами. Этот подход позволил им значительно сократить время выхода на рынок.
Команды использовали инструмент для имитации API для создания симуляторов несуществующих API. Эти симуляторы помогли им запускать автоматизированные и ручные исследовательские тесты, не дожидаясь момента, когда другие команды закончат свою работу.
Они придерживались следующего рабочего процесса:
Команды начинают с совместного проектирования API в формате OpenAPI.
Команды «производителей» и «потребителей» могут параллельно работать над своими микросервисами.
Команда «потребителей» может использовать симуляторы для имитации бэкенд-сервиса производителя, что позволяет писать автоматизированные тесты, которые не зависят от реальных бэкенд-микросервисов. Также это позволяет проводить исследовательские ручные тесты, которые не зависят от микросервисов бэкенда.
Обратная связь по поводу спецификации API на этапе разработки очень важна, чтобы позволить API развиваться и учитывать непредвиденные изменения.
Когда микросервисы готовы, их можно протестировать вместе без симуляторов и выпустить в продакшн.
Проблема 2: Медленные/ручные процессы в бэкенде или сторонних системах
Еще одна типичная проблема, мешающая командам создавать автоматизированные тесты, — это медленный и/или ручной процесс, являющийся частью тест-кейсов.
Она наиболее типична при взаимодействии с зависимыми системами с использованием асинхронных технологий, таких как IBM MQ, RabbitMQ, JMS, ActiveMQ или AMQP.
Например, как показано на рисунке 5, микросервисы будут отправлять сообщение-запрос в очередь запросов, чтобы бэкенд-службы могли его использовать. Обработка данных бэкенда может занять несколько минут или часов, прежде чем ответное сообщение поступит в очередь ответов.

Рисунок 5: Обмен сообщениями запроса и ответа с бэкендом
В этом случае автоматизированные тесты могут ждать ответного сообщения от бэкенда несколько минут или часов. Ожидание в течение нескольких минут или часов означает блокировку конвейера сборки на несколько минут или часов для каждого тест-кейса. По этой причине необходимо иметь альтернативный подход к тестированию микросервиса. Симуляторы заменят медленную зависимость и будут отвечать в течение миллисекунд вместо минут или часов, позволяя тестам запускаться без задержки. На рисунке 6 показано внедрение симулятора для компонента бэкенда.

Рисунок 6: Использование имитаторов в обмене сообщениями запроса и ответа
Аналогичный подход понадобится тогда, когда в бэкенд-системах происходит ручная обработка документов запроса. Например, сценарий «human-in-the-loop», когда для завершения пользовательского путешествия и тест-кейса требуется взаимодействие человека с внутренней или сторонней системой. Подобный ручной процесс всегда занимает больше времени, чем допустимо для автоматизированного тестирования, зачастую минуты, часы и даже дни.
Кейс: ручные процессы в бэкенде или сторонних системах
В рамках своей работы я консультировал компанию, работающую над государственным проектом, которая хотела автоматизировать ручные регрессионные тесты. Их проблема заключалась в том, что почти все действия пользователя включали отправку сообщений IBM MQ в государственную службу для обработки. Обработка производилась вручную, даже в тестовых средах. Этот ручной процесс занимал от 30 минут до 2 дней. Команда использовала Traffic Parrot для имитации правительственных систем IBM MQ (дисклеймер: я представляю Traffic Parrot). Симуляторы, которые отвечали за миллисекунды, а не за часы или дни, освободили человека, ответственного за автоматизацию ручных регрессионных тестов.
Проблема 3: трудности с тестовыми данными
Когда вы запускаете автоматизированные тесты, вам необходимо, чтобы зависимые системы поддерживали тестовые сценарии. Это включает в себя настройку API и ответов сервиса в соответствии с тем, что требуется для тест-кейсов.
Настройка тестовых данных бэкенда может быть проблематичной, если они неподконтрольны вашей команде. Полагаться на другую команду в настройке тестовых данных для вас значит, вы можете получить некорректные тестовые данные или вовсе их отсутствие, и следовательно, не сможете продолжать работу над автоматизированными тестами.
Другая проблема заключается в том, что даже если у вас есть тестовые данные, частое выполнение автоматизированных тестов в конвейере сборки может их полностью израсходовать («сжигание» тестовых данных). Тогда вам придется заняться обновлением тестовых данных, что займет еще больше времени, чем частичная установка тестовых данных.
Даже если у вас есть все необходимые тестовые данные, когда вы (или другая команда) запускаете автоматизированные или ручные тесты против тех же сервисов, тестовые данные могут измениться (например, баланс на счете или список купленных пользователем товаров). Тесты снова ломаются из-за проблем с тестовыми данными, а не из-за реальных проблем с продуктом.
Вы хотите, чтобы автоматизированные тесты выдавали статус Failed, когда есть проблемы с кодом, а не когда есть проблемы с управлением тестовыми данными.
Одним из решений проблем, о которых мы говорили выше, является использование симуляторов. В симуляторе можно настроить все необходимые сервисы и ответы API из отдельных тестов, которые будут актуальны только для данного теста. Это позволит протестировать микросервис изолированно, не полагаясь на помощь других команд и зависимых систем. Это показано на рисунке 8.
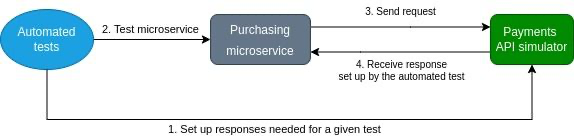
Рисунок 7: Настройка симуляторов из автоматизированных тестов
Кейс: настройка тестовых данных в сторонней системе
Один из моих медиа-клиентов интегрировался со сторонней системой, где они могли настраивать тестовые данные в сторонней системе только вручную через специальный интерфейс. Тестовые данные использовались/сжигались автоматизированными тестами почти каждый день в течение недели. Они создали простой симулятор API с помощью одного из популярных инструментов за 2 часа — означало, что им больше не нужно обновлять тестовые данные в сторонней системе. В течение последующих трех месяцев они потратили еще 20 часов на добавление в симулятор дополнительных ответов, которые покрывали все «happy-path»-сценарии, которые они хотели. Кроме того, они смогли добавить в симулятор сценарии ошибок, которые было невозможно настроить в реальной тестовой среде стороннего разработчика, что привело к увеличению покрытия автоматизированными тестами.
Кейс: моделирование целой аппаратной среды
У того же клиента был микросервис, интегрированный с аппаратной платформой с помощью HTTP REST API. К сожалению, чтобы создать тестовую среду со всеми аппаратными устройствами для поддержки всех тест-кейсов только для автоматизированных тестов, потребовалось бы больше полугода на закупку и установку аппаратных устройств в тестовой среде. Команда решила потратить две недели времени двух разработчиков на создание программного симулятора устройств. Создание симулятора с достаточным количеством функций для их нужд позволило им создавать тесты, не дожидаясь появления новых устройств в тестовой среде.
Проблема 4: Создание гипотетических сценариев для тестирования сценариев ошибок
В дополнение к вышеупомянутым проблемам с тестовыми данными, иногда создание гипотетических ситуаций или сценариев ошибок в некоторых системах в тестовой среде вообще невозможно. Так, если у вас есть баг, который вы хотели бы покрыть автоматизированными тестами, но он зависит от определенной конфигурации бэкенд-систем, которую невозможно воспроизвести в тестовой среде, вы не сможете создать автоматизированный тест.
Когда задействовано несколько внутренних систем, все становится еще сложнее. Например, если микросервисы Payments подключаются к нескольким сторонним API и системам мэйнфреймов, для воспроизведения ошибки, обнаруженной в производственных системах, может потребоваться определенная комбинация ответов от этих систем.
На помощь снова приходят симуляторы. Поскольку симулятор полностью находится под вашим контролем, его можно использовать вместо всех этих сторонних систем и систем мэйнфреймов и детально настроить гипотетическую ситуацию.
Существуют также различные типы ошибок, с которыми вы столкнетесь в производственных средах:
Ответы на ошибки HTTP и других протоколов (такие как 503 service unavailable, 401 unauthorized).
Медленные ответы
Таймауты
Сбивающиеся ответы
Обрывы соединений
Выбранные инструменты моделирования API и систем позволят смоделировать эти типы ошибок и увеличить тестовое покрытие «черного ящика» до высокого процента, более 80%.
Кейс: создание сценариев ошибок в сторонней системе
Я консультировал клиента, чей сторонний сервис имел 23 ожидаемых сценария ошибок, которые нужно учесть, поскольку они могли произойти при обычном использовании продукта. Однако среда сторонней компании не позволяла легко их настроить. Для автоматического тестирования этих сценариев клиент использовал симулятор API, который мог возвращать указанные ответы на ошибки и позволял проводить автоматизированное тестирование своего программного обеспечения методом «черного ящика» во всех 23 случаях ошибок.
Проблема 5: Ограничения сторонних API и сервисов
Многие сторонние API или сервисы имеют ограничения на использование в производственных средах. К ним относятся:
Тротлинг или ограничение скорости — максимальное количество запросов в минуту или час.
Пороговые значения — максимальное количество запросов в секунду в течение нескольких секунд.
Максимальное количество параллельных соединений
С помощью симуляторов можно имитировать сторонний троттлинг, ограничение скорости или максимальное количество параллельных соединений, что позволяет проверить пределы всей тестируемой системы в сценариях «черной пятницы».
Некоторые компании предпочитают ограничивать доступ к своим тестовым средам и «песочницам», чтобы избежать дополнительных расходов на поддержку избыточной инфраструктуры тестирования для всех своих клиентов. Используя симуляторы, вы можете обойти ограничения скорости в сторонних тестовых средах и запустить столько автоматизированных функциональных тестов и тестов производительности на вашей стороне, сколько необходимо.
Среды тестирования бэкэнд-систем могут быть медленными по сравнению с производственными средами, что не позволяет проводить автоматизированное тестирование производительности в среде, подобной производственной. Вы можете использовать симуляторы для имитации времени отклика производственной среды в тестовой среде.
Кейс: ограничение скорости стороннего API
Один из моих клиентов интегрировался со сторонним API с пороговым значением 3 запроса в секунду, непрерывно, в течение 5 секунд. После достижения лимита API возвращало ошибку 429 «Слишком много запросов». Они хотели провести автоматизированное тестирование, в ходе которого их программное обеспечение будет регулировать запросы для достижения допустимого порога разрыва. Они создали симулятор, который имитировал поведение сторонних разработчиков и возвращал ошибку 429, «Слишком много запросов», когда в течение 5 секунд происходило более 3 обращений в секунду, непрерывно. В ходе автоматизированных тестов они подтвердили, что их производственный код может «затормаживаться» (throttle) в течение одной минуты при большом количестве запросов.
Заключение
Изучение новых вещей — это здорово, но новые навыки не принесут отдачи, если вы не будете использовать их на практике. Если вы QA Lead с KPI по переходу от ручного к автоматизированному тестированию, проанализируйте со своей командой, не столкнулись ли вы с вышеупомянутыми проблемами.
Если вы архитектор, разработчик или тестировщик, столкнувшийся с одной или несколько проблем, перечисленных выше, поговорите со своей командой и руководством, чтобы узнать, можете ли вы потратить какое-то время на изучение возможности использования симуляций для решения ваших проблем.
В Википедии есть полезное сравнение инструментов моделирования API, где можно найти тот, который соответствует вашим потребностям.
Обсуждать тему оценки эффективности тестовой стратегии с помощью тестового покрытия мы продолжим на открытом уроке, на который приглашаем всех заинтересованных тестировщиков. На этой встрече мы рассмотрим:
На уроке рассмотрим:
— Оценка эффективности работ по тестированию.
— Что такое тестовое покрытие?
— Создание дерева требований
— Структурные методы построения тестовой модели.
— Как достигать хорошего покрытия?
— Зачем нужны метрики тестового покрытия?
Записаться на открытый урок можно на странице онлайн-курса «QA Lead».
