[Перевод] Спортивные часы Garmin: изучаем GarminOS и её ВМ MonkeyC

Коротко: прошивку своих Garmin Forerunner 245 Music я реверснул ещё в 2022 году, обнаружив дюжину уязвимостей в их платформе для разработчиков приложений Connect IQ (CIQ). Уязвимости эти можно использовать для обхода разрешений и компрометации часов. Я опубликовал различные скрипты и пробные версии приложений на GitHub. Представители Garmin сообщили, что некоторые из обнаруженных уязвимостей существуют аж с 2015 года и затрагивают более сотни моделей, включая фитнес‑часы, наручные устройства для активного отдыха и GPS для велосипедов.
Почему я стал копаться в спортивных часах Garmin
Garmin — крупный игрок на мировом рынке фитнес‑устройств. В 2020 году, по данным Counterpoint Research, она заняла 2-е место после Apple на мировом рынке смарт‑часов. Что касается безопасности их устройств, в интернете практически нет информации об этом. И мне стало интересно покопаться во всём этом, так как найденная информация может затронуть значительное число конечных пользователей, в том числе и меня.
В начале 2022 года всё, что я смог найти в сети, это запись в блоге «A Watch, A Virtual Machine, and Broken Abstractions» Диониса Блазакиса (2020). Она давала представление о том, как работают часы Garmin Forerunner 235 и как реализованы их приложения. Эта запись стала отправной точкой моих исследований.
Уязвимости
В качестве тизера перечислю уязвимости, которые я обнаружил и передал информацию о них Garmin:
Anvil Secure ID | CVE ID | CIQ API версия (минимальная) | Коротко |
GRMN-01 | CVE не запрашивался | 1.0.0 | TVM не гарантирует, что |
GRMN-02 | CVE-2023–23 301 | 1.0.0 | Выход за границы чтения при загрузке строковых ресурсов |
GRMN-03 | CVE не запрашивался | 1.0.0 | Несогласованный размер при загрузке строковых ресурсов |
GRMN-04 | CVE-2023–23 298 | 2.3.0 | Целочисленное переполнение при инициализации |
GRMN-05 | CVE-2023–23 304 | 2.3.0 |
|
GRMN-06 | CVE-2023–23 305 | 1.0.0 | Переполнение буфера при загрузке ресурсов шрифта |
GRMN-07 | CVE-2023–23 302 | 1.2.0 | Переполнение буфера в |
GRMN-08 | CVE-2023–23 303 | 3.2.0 | Переполнение буфера в |
GRMN-09 | CVE-2023–23 306 | 2.2.0 | Запись за пределами памяти |
GRMN-10 | CVE-2023–23 300 | 3.0.0 | Переполнение буфера в |
GRMN-11 | Аналогично GRMN-09 | 2.2.0 | Путаница в типах в |
GRMN-12 | CVE не запрашивался | 1.0.0 | Нативные функции не проверяют количество аргументов |
GRMN-13 | CVE-2023–23 299 | 1.0.0 | Обход разрешений с помощью манипулирования определения поля |
Я договорился с Garmin о том, что отложу публикацию уязвимостей до 2023 года. Компания рассказала, что несколько уязвимостей существовали с версии 1.0.0, опубликованной в январе 2015 года. Представители Garmin также уточнили, что уязвимости затронули более ста устройств, совместимых с Connect IQ, и были исправлены в CIQ API версии 3.1.x.
Предварительное изучение
Приложения CIQ выполняются внутри виртуальной машины (названной TVM в прошивке, которую я прочитал как «The Virtual Machine»), реализованной в их операционной системе Garmin (удачно названной GarminOS). TVM в основном используется для обеспечения стабильности, но также добавляет уровень безопасности:
Если выполнение приложения занимает слишком много времени, виртуальная машина прерывает его.
Виртуальная машина заботится о выделении и освобождении памяти, чтобы предотвратить утечки памяти.
Виртуальная машина блокирует доступ приложений к чувствительным API, если у них нет соответствующих разрешений (например, доступ к местоположению GPS).
Пост Диониса посвящён безопасности операционных кодов (opcodes) TVM, которые реализованы нативно. В нем выделено несколько критических проблем, которые могут быть заэксплуатированы с помощью вредоносного ассемблерного кода для взлома уровня виртуализации и получения возможности выполнения нативного кода на часах, позволяя полностью контролировать их.
Сценарий атаки заключается в том, что пользователь устанавливает вредоносное приложение CIQ (вручную или из магазина Connect IQ). Можно провести параллель с приложениями для Android, когда пользователь устанавливает вредоносный APK на своё мобильное устройство из Play Store либо из стороннего источника. Почитайте эту запись, если хотите знать больше. Хотя там речь шла только о Forerunner 235, я был почти уверен, что обнаруженные уязвимости затронули гораздо более широкий спектр устройств.
Во время изучения прошивки Garmin я попробовал найти ответ на три вопроса:
Как Garmin загружает приложения CIQ?
Как реализованы разрешения для приложений?
Что представляют собой нативные функции, кратко упомянутые в записи Диониса?
GarminOS и TVM
GarminOS — это собственная разработка Garmin, что довольно необычно для нашего времени. В этой ОС реализованы управление потоками и памятью, но нет концепции пользовательского режима и режима ядра, а также поддержки нескольких процессов. Написана преимущественно на C, но в последние пару лет UI‑фреймворк начал переходить на C++, о чём говорится в этом подкасте.
Публичная документация по их ОС ограничена, но мы знаем, что их часы используют процессоры серии ARM Cortex M, что может помочь в реверс‑инжиниринге в дальнейшем. Здесь мы будем анализировать и тестировать модель Garmin Forerunner 245 Music.
Интересно, что компания Garmin разработала свой собственный язык программирования под названием MonkeyC, который используется для написания приложений, которые могут работать на часах. Они предоставляют SDK и документацию API, на которую разработчики могут опираться при создании приложений для CIQ.
Язык MonkeyC представляет собой смесь Java и JavaScript. Он компилируется в байт‑код, который интерпретируется TVM Garmin
Вот пример простой программы MonkeyC, которая выводит «Hello Monkey C!» в файл журнала приложения:
import Toybox.Application as App;
import Toybox.System;
class MyProjectApp extends App.AppBase {
function onStart(state) {
System.println("Hello Monkey C!");
}
}Анализ прошивки
Сначала я попытался проанализировать обновление прошивки, которое временно хранится на часах, когда они предлагают обновить их. Однако я быстро понял, что это была инкрементная сборка и не содержала всю прошивку целиком.
К счастью, Garmin предоставляет на своём сайте образы бета‑версий прошивки, в которых содержится все необходимое. Они представлены в формате GCD, который был неофициально задокументирован Гербертом Оппманном.
Проанализировав обновление прошивки GCD, я извлёк запись FW_ALL_BI, содержащую необработанный образ для моих часов:
Методом проб и ошибок я смог напрямую загрузить образ прошивки как ARM: LE:32: Cortex, используя Ghidra, со следующей Memory Map:

Обратите внимание на начальный адрес 0x3000 для флэш-памяти. Я говорил, что образы бета-версии прошивки содержат всё, но это не совсем так, поскольку в них отсутствует загрузчик, который, скорее всего, расположен между адресами 0x0 и 0x3000.
Различная информация, которую я собрал в ходе реверс-инжиниринга:
NULL(0),
INT(1),
FLOAT(2),
STRING(3),
OBJECT(4),
ARRAY(5),
METHOD(6),
CLASSDEF(7),
SYMBOL(8),
BOOLEAN(9),
MODULEDEF(10),
HASH(11),
RESOURCE(12),
PRIMITIVE_OBJECT(13),
LONG(14),
DOUBLE(15),
WEAK_POINTER(16),
PRIMITIVE_MODULE(17),
SYSTEM_POINTER(18),
CHAR(19),
BYTE_ARRAY(20);TVM преобразует эти объекты в 5-байтовую структуру, которая помещается в стек
Первый байт представляет тип данных (
0x01дляint,0x02дляfloat,0x05дляArray,0x09дляBooleanи т.д.) .Оставшиеся 4 байта представляют либо прямое значение (например,
0x11223344для целого числа, закодированного с использованием 32 бит), либо идентификатор, указывающий на другую структуру, расположенную в куче, для более сложных типов (Hash,Array,Resourceи т. д.).
TVM поддерживает в общей сложности 53 опкода (полный список тут)
Включая такие распространённые, как add, sub, return, nop.
А также более специализированные, вроде
newbie(для выделения объектов ByteArray) илиgetm(для разрешения модулей при использовании оператораimportилиusing).Эти коды операций реализованы в машинном коде на C и упоминались в блогозаписи, с которой и началось моё знакомство с вопросом.
CIQ-приложения
При компиляции приложения SDK CIQ генерирует файл PRG (мне кажется, это от слова программа, «Program»), содержащий множество разделов, включая секции кода, данных, подписи и разрешений.
Секции PRG определяются с помощью кодировки Type-Length-Value (TLV), в которой:
4 байта: тип секции, с использованием магического значения (например, 0xc0debabe для раздела кода)
4 байта: длина секции
n байт: данные секции, указанные в предыдущем пункте
Мне очень нравится использовать Kaitai Struct, когда нужно анализировать двоичные файлы в интерактивном режиме. Я написал структуру Kaitai для файлов PRG, с поддержкой дизассемблирования (но не для ресурсов; я думаю, что мои навыки Kaitai недостаточно хороши для этого). Она доступна на GitHub.
Например, разборка TLV-секций может быть выполнена следующим образом:
section:
doc: A section
seq:
- id: section_type
type: u4
- id: length
type: u4
- id: data
size: length
type:
switch-on: section_type
cases:
# [...]
section_magic::section_magic_head: section_head
# [...]
enums:
section_magic:
# [...]
0xd000d000: section_magic_head
# [...]Сигнатуры
Файлы PRG подписываются с использованием RSA и стандарта PKCS #1 v1.5 с SHA1. Они могут содержать любой из следующих разделов подписи:
В первом случае включается только 512-байтовая подпись. Во втором случае включается как 512-байтовая подпись, так и открытый ключ. Похоже, что на часах нет возможности отклонять приложения, подписанные разработчиком.
Добавить поддержку подписи разработчика в нашу структуру Kaitai несложно:
section_developer_signature_block:
doc: Developer signature block
seq:
- id: signature
size: 512
- id: modulus
size: 512
- id: exponent
type: u4Когда компилятор создаёт файл PRG, он сначала генерирует и добавляет все секции (заголовок, точки входа, данные, код, ресурс и так далее). Затем вычисляет подпись RSA и добавляет секцию подписи. Наконец, добавляет конечную секцию, которая содержит все нули (магическое значение равно 0, длина равна 0, всего 8 байт).
Я эту часть изучил бегло. Ровно настолько, чтобы научиться подписывать свои собственные исправленные файлы PRG. Если кто-то захочет поковыряться в этом направлении, дайте мне знать.
Поверхность атаки
Поскольку синтаксический анализ PRG-файлов выполняется в машинном коде, это интересное средство атаки:
Формат файла содержит несколько смещений, которые могут привести к целочисленному переполнению/неполному заполнению, если они не проверены должным образом.
В нем указываются разрешения, необходимые приложению, а также сигнатура (подпись) для проверки.
Он содержит таблицу ссылок и другую информацию, используемую для разрешения символов или обработки исключений во время выполнения.
В файл PRG можно встраивать сложные структуры данных, в том числе изображения, анимацию и шрифты.
Насколько я могу судить, Garmin правильно обрабатывает длину секций. Другие атрибуты длины внутри этих секций часто кодируются с помощью 2 байт, но в коде хранятся внутри четырехбайтовых целочисленных данных, что предотвращает множество сценариев целочисленного переполнения.
Но есть ещё много других аспектов, которые необходимо проверить. Давайте рассмотрим несколько проблем, которые я обнаружил при реверс-инжиниринге PRG.
Ресурсы
MonkeyC поддерживает несколько типов ресурсов. В документации упоминаются строки, растровые изображения, шрифты, данные JSON и анимация.
Определения строк
Определения строк обрабатываются опкодом news. При вызове news вы передаёте символ в ваше определение строки, которое обычно находится внутри секции данных вашей PRG. Оно начинается с контрольного значения (sentinel) 0x1, за которым следует длина строки, закодированная с использованием 2 байт, затем байты строки.
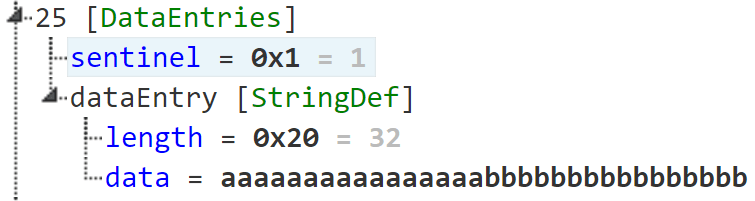
В CVE-2020–27486 объясняется, что опкод news выделяет буфер строки на основе длины, указанной в определении строки, а затем вызывает strcpy для копирования байтов строки. Это может привести к повреждению памяти, поскольку strcpy не использует указанную длину и останавливается только на первом нулевом байте.
Посмотрев на опкод операции news, я убедился, что это пофикшено с помощью strncpy. Но копнув глубже, я отметил ещё одну, хотя и менее важную проблему.
При загрузке определения TVM сначала разрешает символ в его значение, которое обозначает «физическое» смещение внутри секции. Старший байт (MSB) символа указывает, в каком разделе:
MSB
0x00(т.е. между0x000000и0x10000000не включительно), мы указываем на раздел данных PRGMSB
0x10(т.е. между0x10000000и0x20000000не включительно), мы указываем на секцию кода PRGMSB
0x20(т.е. между0x20000000и0x30000000не включительно), мы указываем на раздел данных API (хранится в прошивке)MSB
0x30(т.е. между0x30000000и0x40000000не включительно), мы указываем на секцию кода API (также хранится в прошивке)
Затем TVM использует младшие 6 байт в качестве смещения внутри этих секций. (Есть ещё MSB 0x40 для встроенных функций, но к ним я вернусь позже).
Под разделами данных и кода API я подразумеваю, что в прошивку встроена копия SDK, скомпилированная из MonkeyC. Хотя это не файл PRG, как приложение, которое мы разрабатываем, они содержат одинаковые структуры данных. Раздел кода API содержит байт-код MonkeyC, а раздел данных API содержит определения классов и строк.
TVM проверяет, что смещение, вычисленное по символу, находится в пределах границ ожидаемой секции. Например, если ваш раздел данных PRG составляет 0x1000 байт, а вы указываете символ 0xdeadbeef, значение которого равно 0x00aabbcc, это приведёт к неудаче, поскольку 0xaabbcc находится за пределами раздела данных PRG (0xaabbcc > 0x1000).
Однако существует проблема со строками. Определения строк определяют длину считываемых данных, и TVM не проверяет, выходит ли она за пределы конца раздела. Поэтому можно поместить определение строки на границе раздела с большим размером, и TVM будет считывать данные за пределами раздела (до следующего нулевого байта).

Фактически, поскольку отправным значением для строковых определений является 0x01, мы также можем легко найти смещения в разделах данных API и кода, которые можно рассматривать как допустимые определения строк. Таким образом, мы не ограничены в размещении наших недопустимых определений строк в наших разделах PRG, мы также можем найти их в разделах API.
Шрифтовые ресурсы
Прошивка, которую я анализировал, поддерживает два типа шрифтов: не-Unicode (значение sentinel 0xf047) и Unicode (значение sentinel 0xf23b). Первый больше не поддерживается при компиляции PRG-файла, но код для работы с ними все ещё присутствует в прошивке (скорее всего, по причинам ретросовместимости).
Формат, не поддерживаемый Unicode, короче и проще в описании:
Индекс | Размер в байтах | Имя |
|---|---|---|
0×00 | 4 | контрольное значение |
0×04 | 4 | высота |
0×08 | 4 | количество глифов |
0×0c | 4 | минимум |
0×10 | 2 | размер данных |
0×12 | 3 * количество глифов | буфер таблицы глифов |
n | 4 | контрольный глиф |
n + 4 | 1 * размер данных | дополнительный буфер данных |
При загрузке шрифта нативный код неверно вычисляет размер буфера, необходимого для загрузки данных, из-за целочисленного переполнения строки 7:
e_tvm_error _tvm_app_load_resource(s_tvm_ctx *ctx,int fd,uint app_type,s_tvm_object *resource,s_tvm_object *out)
{
uint size_buffer;
// [...]
file_read_4bytes(fd, &font_glyph_count);
file_read_2bytes(fd, &font_data_size);
size_buffer = (font_data_size & 0xffff) + (int)font_glyph_count * 4 + 0x34;
tvm_mem_alloc(ctx, glyph_table, &glyph_table_data);
// [...]
for (i = 0; i < font_glyph_count; i++) {
glyph = glyph_table_data[i];
file_read_2bytes(fd, glyph);
}
// [...]
}Можно создать такой заголовок шрифта, который приведёт к выполнению операций записи за пределами границ. Например, выбрав следующие значения:
Вычисленный размер буфера будет равен: (0x108 & 0xffff) + 0x4000001A * 4 + 0x34 = 0x1000001a4.Поскольку регистры могут хранить только 32-битные значения, он будет усечён до 0x1000001a4 & 0xffffffff = 0x1a4. Затем прошивка попытается скопировать глифы 0x4000001A в буфер размером 0x1a4 байта.
Аналогичные проблемы можно обнаружить при разборе шрифтов Unicode, а также растровых ресурсов. Однако попытка перезаписать большие буферы на небольших встроенных устройствах может оказаться непростой задачей. Я решил продолжить реверс прошивки, чтобы выявить уязвимости, которые, возможно, будет легче использовать.
Нативные функции
При извлечении данных API и участков кода из прошивки я заметил, что хотя многие функции были реализованы в MonkeyC, другие были реализованы нативно (на что указывают их символы, начинающиеся с 0x40).
При вызове метода символы, начинающиеся с 0x40, рассматриваются как индекс внутри таблицы обратных вызовов:
// [...]
if ((field_value[0].value & 0xff000000) == 0x40000000) {
// `i * 4` is checked earlier in the function to be within bounds
tvm_native_method = *(code **)(PTR_tvm_native_callback_methods_00179984 + i * 4);
ctx->pc_ptr = (byte *)tvm_native_method;
err = (*tvm_native_method)(ctx, nb_args);
// [...]В моей прошивке я насчитал 460 нативных функций! Это большая поверхность атаки, поскольку ошибка в любой из них потенциально может позволить скомпрометировать ОС.
Следует обратить внимание на символы, начинающиеся с 0×40:
Их 2-й MSB указывает на количество аргументов.
Оставшиеся 2 байта указывают на смещение в таблице обратных вызовов.
Например, символ 0x40050123 указывает на нативную функцию (MSB равен 0×40), которая ожидает 5 параметров (2-й MSB равен 0x05) и чей индекс в таблице равен 0x123.
Разрешение нативных символов функций
Я хотел разрешить символы этих нативных функций, чтобы ускорить реверсинг. Я нашел и извлёк раздел данных API на основе его магического значения 0xc1a55def.

Раздел данных API встроен в прошивку
Затем я проанализировал и прошерстил все методы, начинающиеся с 0×40. Для этого я скомпилировал свою структуру Kaitai на Python, чтобы автоматизировать процесс. Ниже приведён пример такого метода из среды разработки Keitai:

На скриншоте выше можно увидеть, что:
Мы находимся внутри определения класса с ID модуля
0x800490, который наследуется от модуля с ID0x800003.Первое определение поля является методом (тип 0×6), символом которого является
0x800018, а значением —0x300055D9Второе определение поля также является методом (тип 0×6), символом которого является
0x800446, а значением —0x4002015F
Пока что сосредоточимся на определении второго поля. Поскольку MSB его значения равен 0x40, это нативная функция, которая принимает 2 параметра и расположена со смещением 0x15F в таблице обратных вызовов.
Мы можем найти отладочный символ 0x800446 в SDK, предоставляемом конечным пользователям:
monkeybrains.jar.src$ grep $((16#800446)) ./com/garmin/monkeybrains/api.db
getHeartRateHistory 8389702Но есть аж два getHeartRateHistory, согласно документации. Какой из них правильный? Используем идентификатор модуля:
monkeybrains.jar.src$ grep $((16#800490)) ./com/garmin/monkeybrains/api.db
Toybox_SensorHistory 8389776Ага, нативный обратный вызов со смещением 0x15F — это Toybox.SensorHistory.getHeartRateHistory. Вы уже догадались: ID родительского модуля 0x800003 — Toybox.
Этот метод, по-видимому, принимает только один параметр (options), но TVM объектно-ориентирован, поэтому под капотом getHeartRateHistory принимает два параметра: this и options.
Мы можем автоматизировать этот процесс (Kaitai в Python, плюс некоторый дополнительный код Python для разбора отладочных символов) для всех нативных функций и переименовать функции в Ghidra.

Теперь стало намного проще реверсить нативные функции, поскольку мы можем узнать их аргументы, основываясь на официальной документации.
Toybox.Cryptography.Cipher.initialize переполнение буфера.
Если обратиться к документации, метод Toybox.Cryptography.Cipher.initialize рассчитывает 4 параметра:
algorithm, который является перечислением для указания AES128 или AES256.mode, который является перечислением для указания ECB или CBC.key, который представляет собойByteArrayсекретного ключа.iv, который является
ByteArrayвектора инициализации.
Метод initialize нативно реализован в прошивке:
e_tvm_error native:Toybox.Cryptography.Cipher.initialize(s_tvm_ctx *ctx,uint nb_args)
{
// [...]
byte static_key_buffer [36];
ushort key_data_length;
// [...]
// Anvil: Retrieve the key parameter and store it into `key`.
// [...]
// Anvil: Retrieve the underlying byte array data
eVar1 = tvm_object_get_bytearray_data(ctx,(s_tvm_object *)key,&bytearray_data);
psVar2 = (s_tvm_ctx *)(uint)eVar1;
if (psVar2 != (s_tvm_ctx *)0x0) goto LAB_0478fd0c;
// Anvil: And the byte array length
key_data_length = *(ushort *)&bytearray_data->length;
// Anvil: Copy the byte array data to the static buffer
memcpy(static_key_buffer,bytearray_data + 1,(uint)key_data_length);
// [...]
// Anvil: if CIPHER_AES128 then expected size is 16
if (*(int *)(local_78 + 0x18) == 0) {
expected_key_size = 0x10;
}
else {
// Anvil: if CIPHER_AES256, then expected size is 32
if (*(int *)(local_78 + 0x18) == 1) {
expected_key_size = 0x20;
}
// [...]
}
// Anvil: If the key size is unexpected, throw an exception
if (((key_data_length != expected_key_size) && (psVar2 = (s_tvm_ctx *)thunk_FUN_00179a5c(ctx,(uint *)object_InvalidOptionsException,PTR_s_Invalid_length_of_:key_for_reque_047900d0), psVar2 != (s_tvm_ctx *)0x0)) || /* [...] */ ) goto LAB_0478fd1a;
// [...]В приведённом выше фрагменте кода нативная функция извлекает данные ключа и вызывает memcpy, чтобы скопировать их в статический буфер, расположенный в стеке. Когда копирование выполнено, она проверяет размер ключа и выдаёт ошибку, если значение недопустимо.
Однако в этот момент мы уже испортили стек, включая значение регистра программного счетчика (PC).
Та же логика применима к вектору инициализации в функции initialize, хотя на этот раз буфер располагается не в стеке, а в куче:
// [...]
// Anvil: Retrieves the IV byte array data
eVar1 = tvm_object_get_bytearray_data(ctx,(s_tvm_object *)iv,&bytearray_data);
psVar2 = (s_tvm_ctx *)(uint)eVar1;
if (psVar2 != (s_tvm_ctx *)0x0) goto LAB_0478fc06;
iv_length = bytearray_data->length;
// Anvil: Assigns its length to a structure at offset 0x16
*(short *)(local_78 + 0x16) = (short)iv_length;
// Anvil: Copy the byte array data to the buffer on the heap
memcpy(local_78 + 6,bytearray_data + 1,iv_length & 0xffff);
// [...]
// Anvil: If the IV size is not 16, throw an exception
if (*(short *)(local_78 + 0x16) != 0x10) {
if (psVar2 != (s_tvm_ctx *)0x0) goto LAB_0478fc06;
psVar2 = (s_tvm_ctx *)thunk_FUN_00179a5c(ctx,(uint *)object_InvalidOptionsException,PTR_s_Invalid_length_of_:iv_for_reques_047900dc);
}
// [...]Следующее приложение MonkeyC может вызвать сбой при копировании ключевого параметра:
var keyConvertOptions = {
:fromRepresentation => StringUtil.REPRESENTATION_STRING_HEX,
:toRepresentation => StringUtil.REPRESENTATION_BYTE_ARRAY
};
var keyBytes = StringUtil.convertEncodedString(
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbb",
keyConvertOptions
);
var ivBytes = StringUtil.convertEncodedString(
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",
keyConvertOptions
);
var myCipher = new Crypto.Cipher({
:algorithm => Crypto.CIPHER_AES128,
:mode => Crypto.MODE_ECB,
:key => keyBytes,
:iv => ivBytes
});Toybox.Ant.BurstPayload запись за пределами памяти
Судя по документации, метод Toybox.And.Burst Payload.add ожидает только один параметр: message как массив или массив байтов. Метод добавляет объект сообщения во внутренний буфер. Он реализован нативно:
e_tvm_error native:Toybox.Ant.BurstPayload.add(s_tvm_ctx *ctx,uint nb_args)
{
// [...]
// Anvil: Retrieves our current BurstPayload instance object
object = (s_tvm_object *)(ctx->frame_ptr + 5);
field_size = 0;
// Anvil: Retrieves its `size` field
eVar1 = tvm_get_field_size_as_int(ctx,object,&field_size);
uVar2 = (uint)eVar1;
if (uVar2 == 0) {
// Anvil: If the `size` field is >= 0x2000, we abort
if (0x1fff < (int)field_size) {
return OUT_OF_MEMORY_ERROR;
}
// [...]
// Anvil: Retrieves our `message` parameter
eVar1 = tvm_message_copy_payload_data(ctx,ctx->frame_ptr + 10,payload_data);
// [...]
// Anvil: Retrieves our instance's `burstDataBlob` field
eVar1 = tvm_object_get_field_value-?(ctx,object,field_burstDataBlob,&burst_data_blob,1);
// [...]
if ((uVar2 == 0) && (uVar2 = _tvm_object_get_object_data(ctx,burst_data_blob.value,(undefined *)&blob_data), uVar2 == 0)) {
// Anvil: We write our `message` data to the internal buffer.
*(undefined4 *)(blob_data + field_size + 0xc) = payload_data._0_4_;
*(undefined4 *)(blob_data + field_size + 0x10) = payload_data._4_4_;
// [...]Первое, что бросается в глаза, — это проверка поля размера. Хотя функция проверяет верхнюю границу его значения, она не проверяет наличие отрицательных значений.
Как мы можем контролировать поле size объекта BurstPayload? MonkeyC поддерживает наследование, поэтому мы можем просто наследоваться от объекта и переопределять его значение после вызова его конструктора.
Например, в следующем фрагменте кода поле size переопределяется на 0xdeadbeef после вызова родительского метода initialize.При вызове add нативная функция попытается записать 8 байт данных, начиная с blob_data + 0xdeadbeef + 0xc.
class MyBurstPayload extends Ant.BurstPayload {
function initialize() {
Ant.BurstPayload.initialize();
self.size = 0xdeadbeef;
}
}
// [...]
var burst = new MyBurstPayload();
var data = new[8];
for (var j = 0; j < 8; j++) {
data[j] = 0x44;
}
burst.add(data);Toybox.Ant.BurstPayload Путаница в типах
Помимо неправильной проверки размера, в коде есть ещё одна проблема. Предполагается, что burstDataPayload является объектом определённого типа (если посмотреть на метод initialize BurstPayload, кажется, что он является объектом Resource).
Однако, используя тот же метод, который мы использовали для переопределения поля size, мы можем изменить поле burstDataPayload, чтобы оно стало объектом другого типа.
Например, следующий код изменяет поле burstDataBlob на объект Array:
class MyBurstPayload extends Ant.BurstPayload {
function initialize() {
Ant.BurstPayload.initialize();
self.size = 0;
// Both objects are INT
self.burstDataBlob = [0, 0];
}
}
// [...]
var burst = new MyBurstPayload();
var data = [
// First object, changing from INT to FLOAT
0x02, 0x42, 0x42, 0x43, 0x43,
// Second object, changing from INT to FLOAT
0x02, 0x45, 0x45,
];
burst.add(data);При вызове функции add нативная функция переопределит первые 8 байт данных массива. Эти байты представляют первые 2 хранимых объекта (5 байт первого объекта и 3 байта второго), которые имеют тип INT. Мы переопределяем их своими собственными объектами типа FLOAT.
Такую же картину можно наблюдать и в других нативных функциях, где они предполагают, что поля объекта такие же, как в SDK. И не принимают во внимание случай, когда они были изменены путём наследования.
Теперь для некоторых уязвимых встроенных функций требуются разрешения. Для устранения уязвимостей, связанных с полезной нагрузкой Toybox.Ant.BurstPayload, наше приложение CIQ должно добавить модуль Toybox.Ant в свой список разрешений (вместе с модулем Toybox.Background).
Мне было интересно понять, как прошивка обеспечивает соблюдение разрешений.
Разрешения
Определения модулей имеют флаг, который указывает, требуют ли они разрешения для использования. Этот флаг установлен для различных основных модулей, таких как:
Toybox.Antдля связи с AntToybox.UserProfileдля получения информации о пользователе (дата рождения, вес и т. д.)Toybox.Positioningдля получения GPS-координатВесь список тут
PRG-файл включает идентификаторы модулей, к которым ему необходим доступ, в раздел разрешений. Например, если вашему приложению нужен доступ к модулю Toybox.UserProfile, оно включит его ID (0x800012) в раздел разрешений, как показано ниже:

Эти разрешения затем перечисляются в магазине Connect IQ для каждого приложения. Например, в приложении Spotify CIQ указано следующее разрешение:

Что соответствует модулю Toybox.Communications.
Проверка разрешений
В прошивке я нашёл функцию, которая проверяет разрешения. Ее псевдокод выглядит следующим образом:
uint prg_tvm_has_permission(s_tvm_ctx *ctx, int module_id, byte *out_bool) {
// For each module ID in the permissions section
// Is it equal to requested module ID?
// If yes, then we return true as in authorized
// If no, we check the next ID in the section
// No match found, we return false as in unauthorized
}Первое, что бросалось в глаза в этой функции, это:
// [...]
bVar1 = module_id == module_Toybox_SensorHistory;
*out_bool = 0
if ((bVar1) && (ctx->version < VERSION_2.3.0)) {
*out_bool = 1;
return 0;
}
// [...]Изучая атрибут version, я понял, что он берётся из версии, указанной в разделе заголовка PRG. Мы можем подделать head, чтобы указать версию ниже 2.3.0 и автоматически получить доступ к модулю Toybox.SensorHistory. Этот модуль предоставляет доступ к такой информации, как пульс, высота над уровнем моря, давление, уровень стресса и др.
До этого момента я не понимал, когда вызывается функция prg_tvm_has_permission. Копая дальше, я заметил, что на неё ссылаются следующие опкоды:
getmдля разрешения модуляgetvдля получения атрибута из модуляputvдля обновления атрибута из модуля
Функция prg_tvm_has_permission получает идентификатор модуля, который либо разрешен (с помощью getm), либо на который ссылаются при чтении/записи атрибута (с помощью getv/putv).
К сожалению, мы не можем изменить этот идентификатор модуля, поскольку он анализируется непосредственно из определений классов в секции данных SDK, хранящейся в прошивке. Попытка наследоваться от привилегированного модуля также не сработала.
Определения классов и полей
Если вы помните, определение класса содержит информацию высокого уровня, такую как идентификатор родительского модуля (если таковой имеется) и типы приложений. Оно также содержит список определений полей, соответствующих каждому полю, определяемому классом.
Модули определяются как определения классов в разделе данных. Это относится как к модулям, предоставляемым SDK, так и к модулям, которые создаются (под капотом) при написании приложения PRG.
Определение поля может быть любым типом MonkeyC (как перечислено в начале этой статьи) вплоть до типа 15 (double) из-за того, что при разборе TVM тип AND объединяется с 0xf. Сюда входят целые числа, строки, другие определения классов и методы. Это не может быть, например тип 17 или 18.

В определении класса, показанном выше, мы видим, что первое определение поля — это метод (тип 6), символом которого является 0xD, а значением — 0x100000D5. Если вы помните определения строк, то понимаете, что 0x100000D5 означает, что он находится по смещению 0xD5 в секции кода PRG-файла.
При вызове метода 0xD TVM будет анализировать определение класса, затем определения его полей, пока не найдёт соответствие для этого символьного значения. В нашем случае он найдёт 0x100000D5, переведёт его в смещение в нужной секции и перенаправит выполнение туда. Я упрощаю, но суть такова.
Возникает вопрос: что будет, если мы обновим значение определения поля, чтобы оно указывало на раздел SDK? Например, мы сделаем следующее:
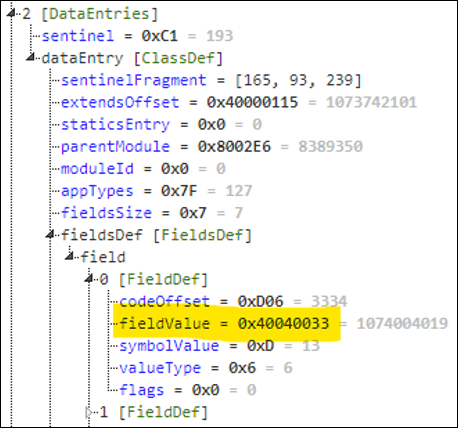
Итак, мы изменили 0x100000D5 на 0x40040033. Если вы помните, предполагается, что это должно представлять нативную функцию (0x40), которая принимает 4 параметра (0x04) и имеет смещение 0×33 в таблице обратных вызовов (значение 0x40040033 характерно для моей версии прошивки). Эта нативная функция на самом деле является Toybox.Communications.openWebPage , которая должна требовать разрешений, поскольку она находится внутри привилегированного Toybox.Communications модуля.
Теперь, когда TVM проверяет наличие разрешений, он в конечном итоге проверяет ID нашего модуля, то есть проверяет, требует ли определение класса нашего модуля разрешений. Поскольку это не так, он с радостью позволит вам вызвать метод 0xD, который в итоге вызовет нативную функцию openWebPage.
Если развить идею, то мы могли бы встроить полную копию SDK в наш PRG-файл! Достаточно исправить различные смещения и почистить флаги разрешений. После этого можно использовать любые модули, даже с пустым разделом разрешений.
Это позволяет полностью обойти проверку разрешений Garmin.
Заключение
Вот такая история о том, как создавать приложения с помощью MonkeyC и запускать их на устройствах Garmin. Для большего удобства я скомпоновал различные скрипты и proof-of-concepts в репозитории GitHub.
Некоторые из уязвимостей, такие как CVE-2023–23299, появились ещё в первой версии CIQ API (1.0.0), опубликованной в 2015 году. А потому затрагивают сотни моделей производителя.
Есть и другие направления исследований гаджетов Garmin. Например, интересен стек Bluetooth с низким энергопотреблением (BLE), который взаимодействует с датчиками, а также участвует в обмене данными между часами и смартфоном (например, для отправки данных в мобильное приложение Garmin Connect).
Одно могу сказать точно — я лишь поверхностно покопался в вопросе. Если залезать туда с головой, можно нарыть ещё много интересных вещей.
Спасибо за внимание!
Что ещё интересного есть в блоге Cloud4Y
→ Информационная безопасность и глупость: необычные примеры
→ NAS за шапку сухарей
→ Взлом Hyundai Tucson, часть 1, часть 2
→ Столетний язык программирования — какой он
→ 50 самых интересных клавиатур из частной коллекции
