[Перевод] Переход с ETL на ELT

ETL (Извлечение-Трансформация-Загрузка) и ELT (Извлечение-Загрузка-Трансформация) — два термина, которые часто используются в области дата-инжиниринга, особенно в контексте захвата и преобразования данных. Хотя эти термины часто используются как взаимозаменяемые, они относятся к немного разным концепциям и имеют различные последствия для проектирования конвейера данных.
В этом посте мы проясним определения процессов ETL и ELT, обозначим различия между ними и обсудим преимущества и недостатки, которые они предлагают инженерам и командам по работе с данными в целом. И самое главное, я опишу, как недавние изменения в формировании современных команд по работе с данными повлияли на ландшафт борьбы ETL против ELT.
Понимание Извлечения (Extract), Загрузки (Load) и Трансформации (Transform) независимо друг от друга
Главный вопрос при сравнении ETL и ELT, очевидно, последовательность выполнения шагов Извлечения, Загрузки и Трансформации в рамках данных.
Пока давайте не будем обращать внимание на эту последовательность выполнения и сосредоточимся на самой терминологии и обсудим, что предполагает каждый отдельный шаг.
Извлечение: Этот шаг относится к процессу извлечения данных из постоянного источника. Этим источником данных может быть база данных, конечная точка API, файл или что-то еще, что содержит любую форму данных, включая структурированные или неструктурированные.
Шаг извлечения забирает данные из различных источников
Трансформация: На этом этапе от пайплайна ожидается выполнение некоторых изменений в структуре или формате данных для достижения определенной цели. Трансформация может быть выбором атрибута, изменением записей (например, преобразованием 'Великобритания' в 'UK'), проверкой данных, соединением с другим источником или чем-то еще, что меняет формат входных сырых данных.

Шаг трансформации выполняет ряд преобразований входных сырых данных
Загрузка: Шаг загрузки относится к процессу копирования данных (сырых или преобразованных) в целевую систему. Обычно целевая система является Хранилищем Данных (т.е. системой OLAP, используемой для аналитических целей) или прикладной базой данных (т.е. системой OLTP).
Загрузка данных в целевую систему
Неминуемо, последовательность выполнения этих трех шагов имеет значение. И с увеличивающимися объемами данных, которые необходимо обрабатывать, порядок выполнения имеет большое значение. Давайте обсудим, почему!
Extract Transform Load (ETL)
ETL означает Извлечение-Трансформация-Загрузка, и сам термин относится к процессу, где шаг извлечения данных следует за шагом трансформации и завершается шагом загрузки.

Извлечение > Трансформация > Загрузка
Шаг трансформации данных в процессах ETL происходит в промежуточной среде вне целевой системы, где данные преобразуются непосредственно перед их загрузкой в назначение.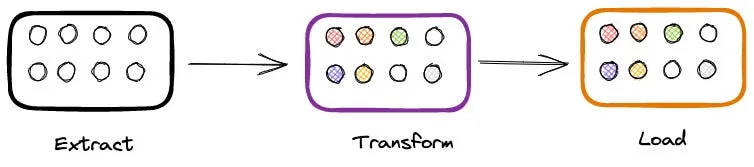
В ETL шаг трансформации происходит в промежуточной среде/сервере, а затем преобразованные данные загружаются в целевую систему
Extract Load Transform (ELT)
С другой стороны, ELT, что означает Извлечение-Загрузка-Трансформация, относится к процессу, где шаг извлечения следует за шагом загрузки, и окончательный шаг трансформации данных происходит в самом конце.

Извлечение > Загрузка > Трансформация
В отличие от ETL, в ELT не требуется промежуточная среда/сервер, поскольку трансформация данных выполняется внутри целевой системы, которая обычно является Хранилищем Данных размещенным в облаке.

В ELT шаг трансформации происходит внутри целевой системы
Как выбрать между ETL и ELT
ETL и ELT имеют свои плюсы и минусы, и, скорее всего, вы столкнетесь с обоими в своей повседневной работе, учитывая, что они обычно используются для разных случаев использования.
ETL лучше всего подходит в случаях использования, когда данные находятся в пределах предприятия и должны быть структурированы перед загрузкой их в целевую базу данных или хранилище. Следовательно, процесс ETL обычно предпочтительнее, когда в процессе участвуют меньшие объемы данных и/или когда предстоит выполнить сложные трансформации.
Кроме того, поскольку ETL преобразует данные до этапа загрузки, конфиденциальные данные могут быть замаскированы, зашифрованы или полностью удалены перед их загрузкой. Этот аспект ETL может помочь компаниям и командам легче соблюдать и внедрять соответствие различным нормативам (например, GDPR).
Поскольку трансформация происходит на промежуточном сервере, есть дополнительная нагрузка на перемещение преобразованных данных в целевую систему. Кроме того, в целевой системе не будет сырых данных (т.е. данных в форме до трансформации). Это означает, что при необходимости дополнительных трансформаций мы должны будем снова извлекать сырые данные.
С другой стороны, ELT обеспечивает большую гибкость по сравнению с ETL, поскольку последний изначально предназначался для структурированных (реляционных) данных. Современные облачные архитектуры и хранилища данных позволяют использовать ELT как для структурированных, так и для неструктурированных данных.
Как было сказано ранее, ETL следует использовать для небольших объемов данных. ELT обеспечивает более быстрое преобразование, поскольку не зависит от размера данных и обычно выполняется по мере необходимости.
Кроме того, если данные загружаются перед их преобразованием как часть процесса ELT, это означает, что пользователи и системы по-прежнему имеют доступ к исходным данным. Это значит, что если впоследствии потребуются дополнительные преобразования, у нас уже есть исходные данные в хранилище данных, к которым можно обратиться в любое время. Единственным недостатком является необходимость дополнительного хранения этих исходных данных, но учитывая постоянно снижающуюся стоимость хранения, я не думаю, что это серьезная проблема.
Теперь, когда мы все хорошо понимаем технические аспекты процессов ETL и ELT, позвольте мне задать вопрос. Когда речь идет о выборе между одним и другим, речь идет только о технической реализации?
Речь не только о том, когда выполнять преобразование
Кроме того, сфера данных постоянно развивается и движется вперед, и роли в области данных не исключение из этой быстро меняющейся среды. ETL против ELT — это не только о том, где происходит этап преобразования — это (также) о том, кто должен их выполнять.
Этап преобразования обычно включает в себя некоторую бизнес-логику. Традиционные процессы ETL раньше выполнялись инженерами по работе с хранилищами данных (не уверен, актуально ли это сейчас), что означает, что эти люди также отвечали за разработку бизнес-логики.
С другой стороны, процессы ELT развивались благодаря природе и ландшафту современных команд по работе с данными и их формированию. Шаги EL (Извлечение-Загрузка) обычно выполняются инженерами по данным, тогда как этап Преобразования выполняется так называемыми аналитическими инженерами.
И это кажется мне вполне логичным. Инженер по данным — это чисто технический специалист, который заботится об эффективности, масштабируемости, готовности и доступности (кроме еще целого миллиона других вещей). С другой стороны, аналитический инженер — это технический специалист с гораздо лучшим пониманием бизнеса. И поэтому имеет смысл, чтобы аналитический инженер отвечал за преобразование данных, учитывая, что (обычно) преобразование соответствует бизнес-ценности.
Современные облачные архитектуры, стеки данных (включая облачные системы OLAP) и формирование команд сделали процессы ELT более актуальными и эффективными. На основе моего личного опыта я бы сказал, что происходит переход от ETL к ELT, несмотря на то, что ETL все еще актуален и полезен.
Современные дата-стеки и команды отдают предпочтение процессам ELT
Хотя ETL не умер, на мой взгляд, современные стеки данных и технологии отдают предпочтение процессам ELT. Как пример, давайте рассмотрим dbt (data build tool), который является одним из самых горячих нововведений в сфере данных и который стал фактическим инструментом преобразования для аналитиков и инженеров.
Обычно мы хотим загрузить в хранилище данных необработанные данные (т.е. без применения какого-либо преобразования) из внешних или внутренних источников данных. Затем, на основе этих моделей данных (в dbt мы обычно называем их моделями стадии) мы строим дополнительные модели (промежуточные и mart), которые являются результатом некоторых процессов преобразования, происходящих внутри хранилища данных.
В таких рабочих процессах, поэтому имеет смысл загружать данные в хранилище до их преобразования. Это также позволяет в любое время иметь доступ к необработанным данным, чтобы поддерживать будущие варианты использования.
Если вы заинтересованы в более глубоком понимании того, как работает dbt и как различные компоненты взаимодействуют для преобразования сырых данных и создания значимых моделей данных для поддержки принятия решений, я бы порекомендовал следующую статью.
Заключение
Проектирование конвейеров данных — это сложная задача, и при ее выполнении необходимо тщательно учитывать множество факторов. Когда речь идет о загрузке данных из источников данных в хранилище данных, обычно можно выбрать один из двух подходов.
В этой статье мы обсудили, как ETL и ELT выполняют последовательность шагов для преобразования и загрузки (или загрузки и преобразования) данных в систему назначения.
В зависимости от ландшафта организации и конкретного варианта использования вы можете выбрать один из них. Я надеюсь, что это руководство предоставило вам все необходимые детали, чтобы выбрать наилучший и наиболее эффективный подход, когда речь идет о загрузке и преобразовании данных.

А еще самое важное в нашем ТГ-канале. Без лишнего спама.
