[Перевод] Оптимизация стратегии игры в Блэкджек методом Монте-Карло
Перевод статьи подготовлен специально для студентов курса «Machine learning».
Обучение с подкреплением штурмом взяло мир Искусственного Интеллекта. Начиная от AlphaGo и AlphaStar, все большее число видов деятельности, в которых раньше доминировал человек, теперь завоевано агентами ИИ, работающими на основе обучения с подкреплением. Короче говоря, эти достижения зависят от оптимизации действий агента в определенной среде для достижения максимального вознаграждения. В последних нескольких статьях от GradientCrescent мы рассмотрели различные фундаментальные аспекты обучения с подкреплением, от основ систем с бандитами и подходов, основанных на политике, до оптимизации поведения на основе вознаграждения в Марковских средах. Все эти подходы требовали полных знаний о нашей среде. Динамическое программирование, например, требует, чтобы мы обладали полным распределением вероятностей всех возможных переходов состояний. Однако в действительности мы обнаруживаем, что большинство систем невозможно интерпретировать полностью, и что распределения вероятностей не могут быть получены в явном виде из-за сложности, врожденной неопределенности или ограничений вычислительных возможностей. В качестве аналогии рассмотрим задачу метеоролога — число факторов, участвующих в прогнозировании погоды, может быть настолько велико, что точно вычислить вероятность оказывается невозможным.
Для таких случаев решением являются методы обучения, такие как Монте-Карло. Термин Монте-Карло обычно используется для описания любого подхода к оценке, основанной на случайной выборке. Другими словами, мы не прогнозируем знания о нашей окружающей среде, а учимся на опыте проходя через примерные последовательности состояний, действий и вознаграждений, полученных в результате взаимодействия с окружающей средой. Эти методы работают путем непосредственного наблюдения вознаграждений, возвращаемых моделью во время нормальной работы, чтобы судить о среднем значении ее состояний. Интересно, что даже без каких-либо знаний о динамике окружающей среды (которую нужно рассматривать как распределение вероятностей переходов состояний) мы все еще можем получить оптимальное поведение для максимизации вознаграждения.
В качестве примера рассмотрим результат от броска 12 костей. Рассматривая эти броски как единое состояние, мы можем усреднить эти результаты, чтобы приблизиться к истинному прогнозируемому результату. Чем больше выборка, тем точнее мы приблизимся к фактическому ожидаемому результату.

Средняя ожидаемая сумма на 12 костях за 60 бросков равна 41,57
Этот вид оценки на основе выборки может показаться знакомым читателю, поскольку такая выборка также выполняется для систем k-бандитов. Вместо того, чтобы сравнивать различных бандитов, методы Монте-Карло используются для сравнения различных политик в Марковских средах, определяя значение состояния по мере следования определенной политике до завершения работы.
Оценка значения состояния методами Монте-Карло
В контексте обучения с подкреплением методы Монте-Карло являются способом оценить значение состояния модели путем усреднения результатов выборки. Из-за необходимости в терминальном состоянии методы Монте-Карло по своей сути применимы к эпизодическим средам. Из-за этого ограничения методы Монте-Карло обычно рассматриваются как «автономные», в которых все обновления выполняются после достижения терминального состояния. Можно привести простую аналогию с поиском выхода из лабиринта — автономный подход заставил бы агента дойти до самого конца, прежде чем использовать промежуточный полученный опыт, чтобы попытаться сократить время прохождения лабиринта. С другой стороны, при online-подходе агент будет постоянно менять свое поведение уже во время прохождения лабиринта, может быть он заметит, что зеленые коридоры ведут в тупики и решит избегать их, например. Мы обсудим online-подходы в одной из следующих статей.
Метод Монте-Карло может быть сформулирован следующим образом:

Чтобы лучше понять, как работает метод Монте-Карло, рассмотрим диаграмму перехода состояний ниже. Вознаграждение за каждый переход состояния отображается черным цветом, к нему применяется коэффициент дисконтирования 0,5. Давайте пока отложим в сторону фактическое значение состояния и сосредоточимся на расчете результатов одного броска.

Диаграмма перехода состояний. Номер состояния отражен красным цветом, результат — черным.
Учитывая, что терминальное состояние возвращает результат равный 0, давайте вычислим результат каждого состояния, начиная с терминального состояния (G5). Обратите внимание, что мы установили коэффициент дисконтирования в 0,5, что приведет к взвешиванию в сторону более поздних состояний.
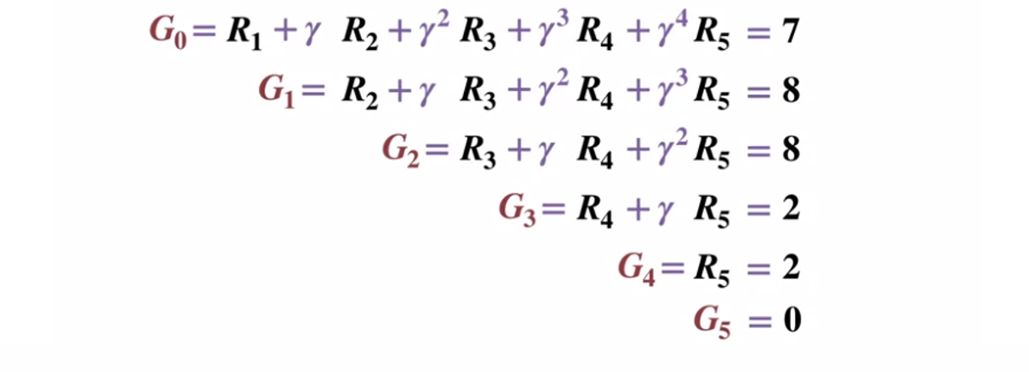
Или в более общем виде:
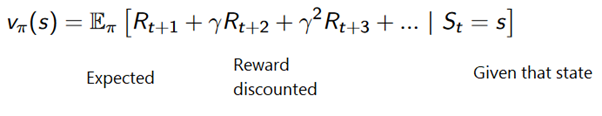
Чтобы избежать хранения всех результатов в списке, мы можем выполнить процедуру обновления значения состояния в методе Монте-Карло постепенно, с помощью уравнения, которое имеет некоторое сходство с традиционным градиентным спуском:
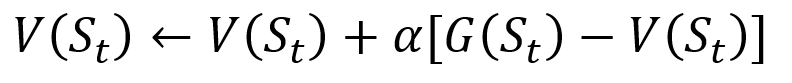
Инкрементная процедура обновления Монте-Карло. S — это состояние, V — его значение, G — его результат, а A — параметр значения шага.
В рамках обучения с подкреплением методы Монте-Карло можно даже классифицировать как «First-visit» или «Every visit». Вкратце, разница между ними заключается в том, сколько раз состояние может быть посещено за проход до обновления Монте-Карло. Метод Монте-Карло «First-visit» оценивает значение всех состояний как среднее значение результатов после единичных посещений каждого состояния до завершения работы, тогда как метод Монте-Карло «Every visit» усредняет результаты после n посещений до завершения работы. Мы будем использовать Монте-Карло «First-visit» на протяжении всей этой статьи из-за его относительной простоты.
Управление политикой с помощью методов Монте-Карло
Если модель не может предоставить политику, Монте-Карло можно использовать для оценки значений состояний-действий. Это полезнее, чем просто значение состояний, поскольку представление о значении каждого действия (q) в данном состоянии позволяет агенту автоматически формировать политику из наблюдений в незнакомой среде.
Если говорить более формально, мы можем использовать Монте-Карло для оценки q (s, a, pi), ожидаемого результата при запуске с состояния s, действии a и последующей политике Pi. Методы Монте-Карло остаются теми же, за исключением того, что появляется дополнительная размерность действий, предпринимаемых для определенного состояния. Считается, что пара состояние-действие (s, a), посещается за проход, если когда-либо посещается состояние s и в нем выполняется действие a. Аналогичным образом, оценка значения-действия может осуществляться с помощью подходов «First-visit» и «Every visit».
Как в динамическом программировании, мы можем использовать обобщенную политику итераций (GPI) для формирования политики из наблюдения значений состояний-действий.
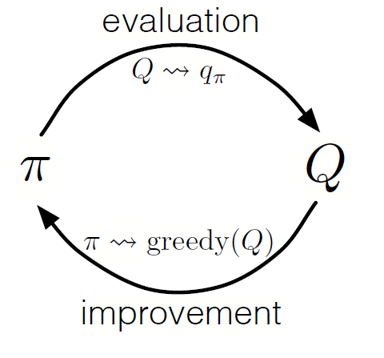
Чередуя шаги оценки политики и совершенствования политики и включая в себя исследования для обеспечения того, чтобы все возможные действия были посещены, мы можем достичь оптимальной политики для каждого состояния. Для Монте-Карло GPI это чередование обычно выполняется после окончания каждого прохода.

Монте-Карло GPI
Стратегия игры в блэкджек
Чтобы понять лучше, как метод Монте-Карло работает на практике в задаче оценки различных значений состояния, давайте проведем пошаговую демонстрацию на примере игры в блекджек. Для начала давайте определимся с правилами и условиями нашей игры:
- Мы будем играть только против дилера, других игроков не будет. Это позволит нам рассматривать руки дилера, как часть окружающей среды.
- Значение карт с числами равняются номинальным значениям. Значение карт-картинок: Валета, Короля и Дамы равно 10. Значение туза может быть 1 или 11 в зависимости от выбора игрока.
- Обе стороны получают по две карты. Две карты игрока лежат лицевой стороной вверх, одна из карт дилера также лежит лицевой стороной вверх.
- Цель игры в том, чтобы сумма карт в руке была <=21. Значение больше 21 – перебор, если у обеих сторон значение равно 21, то игра сыграна в ничью.
- После того как игрок увидел свои карты и первую карту дилера, игрок может выбрать брать ему новую карту («еще») или нет («хватит»), пока он не будет удовлетворен суммой значений карт в руке.
- Затем дилер показывает свою вторую карту — если получившаяся сумма меньше 17, он обязан брать карты пока не достигнет 17 очков, после этого он карты больше не берет.
Давайте посмотрим, как работает метод Монте-Карло с этими правилами.
Раунд 1.
Вы набираете в общей сложности 19. Но вы пытаетесь поймать удачу за хвост, рискуете, получаете 3 и разоряетесь. Когда вы разорились, у дилера была только одна открытая карта с суммой 10. Это можно представить следующим образом:
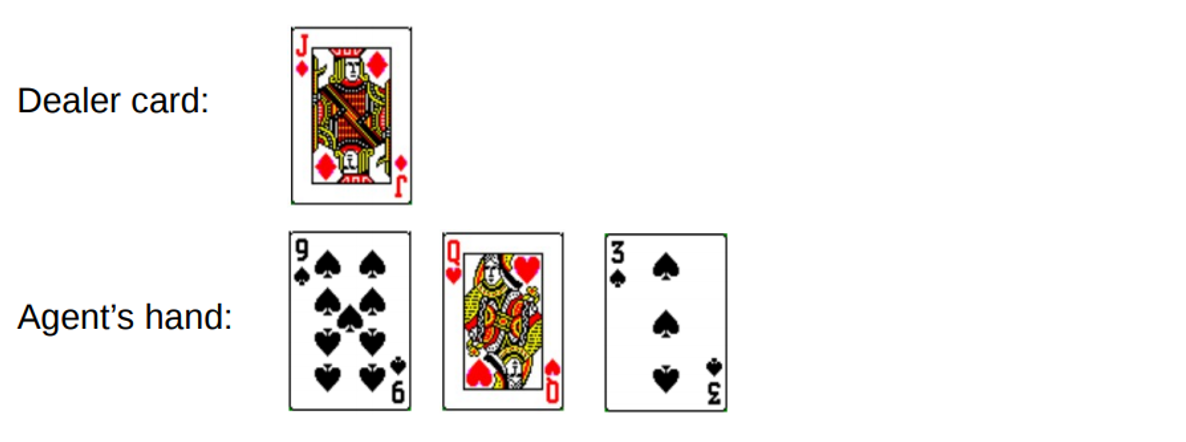
Если мы разорились, наша награда за раунд получилась -1. Давайте назначим это значение в качестве возвращаемого результата предпоследнего состояния, используя следующий формат [Сумма агента, Сумма дилера, туз?]:

Что ж, сейчас нам не повезло. Перейдем к другому раунду.
Раунд 2.
Вы набираете в общей сложности 19. В этот раз вы решаете остановиться. Дилер набирает 13, берет карту и разоряется. Предпоследнее состояние можно описать следующим образом.

Давайте опишем состояния и вознаграждения, которые мы получили в этом раунде:

С окончанием прохода мы теперь можем обновить значения всех наших состояний в этом раунде используя вычисленные результаты. Беря коэффициент дисконтирования за 1, мы просто распространяем наше новое вознаграждение по рукам, как это было сделано с переходами состояний ранее. Поскольку состояние V (19, 10, no) ранее вернуло -1, мы вычисляем ожидаемое возвращаемое значение и присваиваем его нашему состоянию:

Окончательные значения состояний для демонстрации на примере блекджека.
Реализация
Давайте напишем игру в блекджек с использованием метода Монте-Карло first-visit, чтобы узнать все возможные значения состояния (или различных комбинаций на руках) в игре, используя Python. В основе нашего подхода будет лежать подход Sudharsan et. al. Как обычно, весь код из статьи вы можете найти на нашем GitHub.
Чтобы упростить реализацию, будем использовать gym из OpenAI. Подумайте об окружающей среде, как об интерфейсе для запуска игры в блекджек с минимальным количеством кода, это позволит нам сосредоточиться на реализации обучения с подкреплением. Удобно, что вся собранная информация о состояниях, действиях и вознаграждениях хранится в переменных «observation», которые накапливаются в ходе текущих сеансов игры.
Давайте начнем с импорта всех библиотек, которые нам понадобятся, чтобы получать и собирать наши результаты.
import gym
import numpy as np
from matplotlib import pyplot
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from collections import defaultdict
from functools import partial
%matplotlib inline
plt.style.use(‘ggplot’)
Дальше давайте инициализируем нашу среду gym и определим политику, которая будет координировать действия нашего агента. По сути, мы будем продолжать брать карту, пока сумма в руке не достигнет 19 или более, после чего мы остановимся.
#Observation here encompassess all data about state that we need, as well as reactions to it
env = gym.make(‘Blackjack-v0’)
#Define a policy where we hit until we reach 19.
# actions here are 0-stand, 1-hit
def sample_policy(observation):
score, dealer_score, usable_ace = observation
return 0 if score >= 19 else 1
Давайте определим метод для генерации данных для прохода, используя нашу политику. Мы будем хранить информацию о состоянии, предпринятых действиях и вознаграждении за действие.
def generate_episode(policy, env):
# we initialize the list for storing states, actions, and rewards
states, actions, rewards = [], [], []
# Initialize the gym environment
observation = env.reset()
while True:
# append the states to the states list
states.append(observation)
# now, we select an action using our sample_policy function and append the action to actions list
action = sample_policy(observation)
actions.append(action)
# We perform the action in the environment according to our sample_policy, move to the next state
observation, reward, done, info = env.step(action)
rewards.append(reward)
# Break if the state is a terminal state (i.e. done)
if done:
break
return states, actions, rewards
Наконец, давайте определим функцию прогнозирования Монте-Карло first visit. Во-первых, мы инициализируем пустой словарь для хранения текущих значений состояний и словарь, хранящий количество записей для каждого состояния в разных проходах.
def first_visit_mc_prediction(policy, env, n_episodes):
# First, we initialize the empty value table as a dictionary for storing the values of each state
value_table = defaultdict(float)
N = defaultdict(int)
Для каждого прохода мы вызываем наш метод generate_episode, чтобы получать информацию о значениях состояний и вознаграждениях, полученных после наступления состояния. Мы также инициализируем переменную для хранения наших инкрементных результатов. Затем мы получаем вознаграждение и текущее значение состояния для каждого состояния, посещенного во время прохода, и увеличиваем нашу переменную returns на значение награды за шаг.
for _ in range(n_episodes):
# Next, we generate the epsiode and store the states and rewards
states, _, rewards = generate_episode(policy, env)
returns = 0
# Then for each step, we store the rewards to a variable R and states to S, and we calculate
for t in range(len(states) — 1, -1, -1):
R = rewards[t]
S = states[t]
returns += R
# Now to perform first visit MC, we check if the episode is visited for the first time, if yes,
#This is the standard Monte Carlo Incremental equation.
# NewEstimate = OldEstimate+StepSize(Target-OldEstimate)
if S not in states[:t]:
N[S] += 1
value_table[S] += (returns — value_table[S]) / N[S]
return value_table
Напомню, что поскольку мы реализовываем first-visit Монте-Карло, мы посещаем одно состояние за один проход. Поэтому мы выполняем условную проверку словаря состояний, чтобы увидеть, было ли посещено состояние. Если это условие выполняется, мы имеем возможность вычислить новое значение с помощью определенной ранее процедуры обновления значений состояния по методу Монте-Карло и увеличить число наблюдений для этого состояния на 1. Затем мы повторяем процесс для следующего прохода, чтобы в конечном итоге получить среднее значение результата.
Давайте запустим то, что у нас получилось и посмотрим на результаты!
value = first_visit_mc_prediction(sample_policy, env, n_episodes=500000)
for i in range(10):
print(value.popitem())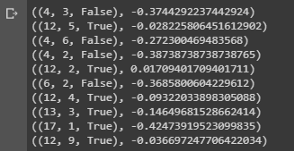
Вывод выборки, показывающей значения состояний различных комбинаций на руках в блекджеке.
Мы можем продолжить делать наблюдения методом Монте-Карло для 5000 проходов и построить распределение значений состояния, описывающее значения любой комбинации на руках игрока и дилера.
def plot_blackjack(V, ax1, ax2):
player_sum = np.arange(12, 21 + 1)
dealer_show = np.arange(1, 10 + 1)
usable_ace = np.array([False, True])
state_values = np.zeros((len(player_sum), len(dealer_show), len(usable_ace)))
for i, player in enumerate(player_sum):
for j, dealer in enumerate(dealer_show):
for k, ace in enumerate(usable_ace):
state_values[i, j, k] = V[player, dealer, ace]
X, Y = np.meshgrid(player_sum, dealer_show)
ax1.plot_wireframe(X, Y, state_values[:, :, 0])
ax2.plot_wireframe(X, Y, state_values[:, :, 1])
for ax in ax1, ax2: ax.set_zlim(-1, 1)
ax.set_ylabel(‘player sum’)
ax.set_xlabel(‘dealer sum’)
ax.set_zlabel(‘state-value’)
fig, axes = pyplot.subplots(nrows=2, figsize=(5, 8),subplot_kw={'projection': '3d'})
axes[0].set_title('state-value distribution w/o usable ace')
axes[1].set_title('state-value distribution w/ usable ace')
plot_blackjack(value, axes[0], axes[1])
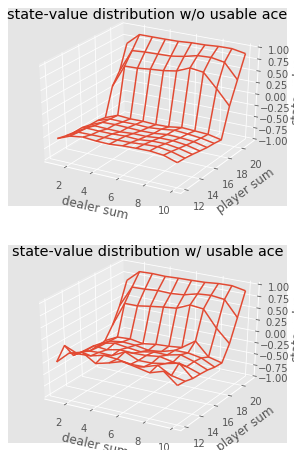
Визуализация значений состояний различных комбинаций в блекджеке.
Итак, давайте подытожим то, что мы узнали.
- Методы обучения на основе выборок позволяют нам оценивать значения состояния и состояния-действия без какой-либо динамики перехода, просто путем выборки.
- Подходы Монте-Карло основываются на случайной выборке модели, наблюдении вознаграждений, возвращаемых моделью, и сборе информации во время нормальной работы для определения среднего значения ее состояний.
- С помощью методов Монте-Карло возможна Обобщенная политика итераций.
- Значение всех возможных комбинаций в руках игрока и дилера в блекджеке можно оценить с помощью многократных симуляций Монте-Карло, открывающих путь для оптимизированных стратегий.
На этом заканчивается введение в метод Монте-Карло. В нашей следующей статье мы перейдем к методам обучения вида Temporal Difference learning.
Источники:
Sutton et. al, Reinforcement Learning
White et. al, Fundamentals of Reinforcement Learning, University of Alberta
Silva et. al, Reinforcement Learning, UCL
Platt et. Al, Northeaster University
На этом все. До встречи на курсе!
