[Перевод] Онлайн-миграция данных из HBase в TiDB с нулевым даунтаймом

Для Pinterest СУБД HBase является одним из самых критически важных бэкендов хранения, лежащим в основе многих онлайн-сервисов хранения наподобие Zen (база данных графов), UMS (wide-column-хранилище) и Ixia (вторичный сервис индексации, работающий почти в реальном времени). Несмотря на то, что экосистема HBase имеет различные преимущества, например, высокую согласованность на уровне строк при высоких объёмах запросов, гибкую схему и низкую задержку доступа к данным, интеграцию с Hadoop и так далее, она не сможет отвечать потребностям наших клиентов через 3–5 лет. Это вызвано высокими эксплуатационными затратами, излишней сложностью и отсутствием такой функциональности, как вторичные индексы, поддержка транзакций и так далее.
Выполнив оценку более десятка различных бэкендов хранения данных, проведя бенчмарки трёх лучших бэкендов при помощи теневого трафика (асинхронным копированием трафика продакшена в среду вне продакшена) и тщательно оценив производительность, мы решили использовать в качестве окончательного кандидата на роль Unified Storage Service (унифицированного сервиса хранения) СУБД TiDB.
Внедрение Unified Storage Service под управлением TiDB — крупный и сложный проект, растянувшийся на несколько кварталов. Он включает в себя миграцию данных из HBase в TiDB, проектирование и реализацию Unified Storage Service, миграцию API с Ixia/Zen/UMS на Unified Storage Service и миграцию офлайн-задач из экосистемы HBase/Hadoop в экосистему TiSpark. При этом мы обязаны были поддерживать SLA по доступности сервиса и задержкам.
В этой статье мы расскажем о рассмотренных вариантах миграции данных с их недостатками. Также мы подробно объясним, как была выполнена миграция данных из HBase в TiDB для одного из первых сценариев использования: таблицы размером 4 ТБ, обслуживающей 14 тысяч запросов на чтение в секунду (qps) и 400 запросов на запись в секунду с нулевым даунтаймом. В конце мы поговорим о том, как была проведена верификация для обеспечения 99,999% целостности данных, и о том, как измерялась целостность данных между двумя таблицами.
Стратегии миграции данных
Если упростить, стратегия миграции данных с нулевым даунтаймом состоит из следующих этапов:
- Если у вас есть база данных А и нужно мигрировать данные в базу данных Б, то следует начать с того, чтобы дублировать операции записи в базу данных А и базу данных Б.
- Импортировать дамп базы данных А в базу данных Б, параллельно разрешая конфликты с текущими операциями записи.
- Выполнить валидацию обоих массивов данных.
- Прекратить выполнять операции записи в базу данных А.
Каждый сценарий использования уникален и может иметь собственный набор уникальных трудностей.
Мы рассмотрели различные подходы проведения миграции данных и окончательно выбрали методологию с учётом следующих компромиссов:
- Выполнение дублируемых операций записи (запись в два источника истины в стиле sync/async) из сервиса в обе таблицы (HBase и TiDB) и использование режима бэкенда TiDB в lightning для поглощения данных.
Эту стратегию реализовать проще всего. Однако скорость, предоставляемая режимом бэкенда TiDB, равна 50 ГБ/ч, поэтому она полезна только для миграции данных таблиц меньшего размера.
- Сделать дамп снэпшота таблицы HBase и выполнять потоковые текущие операции записи из cdc (change data capture) HBase в топик Kafka, а затем выполнить поглощение данных этого дампа при помощи локального режима в инструменте lightning. Позже начать дублируемые операции записи из слоя сервиса и применять все обновления из kafka topic.
Эту стратегию было трудно реализовать из-за сложностей разрешения конфликтов при применении обновлений cdc. Кроме того, наши внутренние инструменты для захвата cdc HBase сохраняют только ключ, поэтому потребовались бы дополнительные ресурсы на разработку.
- Альтернатива приведённой выше стратегии: мы считываем ключи из cdc и сохраняем их в другое хранилище данных. Позже, начав дублируемые операции записи в обе таблицы, мы считываем их последнее значение из источника истины (HBase) и записываем в TiDB. Мы реализовали эту стратегию, однако существовал риск потери обновлений, если асинхронный маршрут сохранения ключей через cdc имел бы проблемы с доступностью.
Оценив достоинства и недостатки всех стратегий, мы решили выбрать вариант, описанный в следующей части статьи.
Процесс миграции
Определения:
Клиент: сервис/библиотека вниз по потоку, общающаяся с сервисом Thrift.
Сервис: сервис Thrift, обслуживающий онлайн-трафик (в условиях данной миграции это Ixia).
Задача MR: приложение, работающее во фреймворке Map Reduce.
Асинхронная операция записи: сервис возвращает клиенту ответ OK, не дожидаясь ответа от базы данных.
Синхронная операция записи: сервис возвращает клиенту ответ только после получения ответа от базы данных.
Дублируемая операция записи: сервис выполняет запись в обе таблицы синхронным или асинхронным образом.

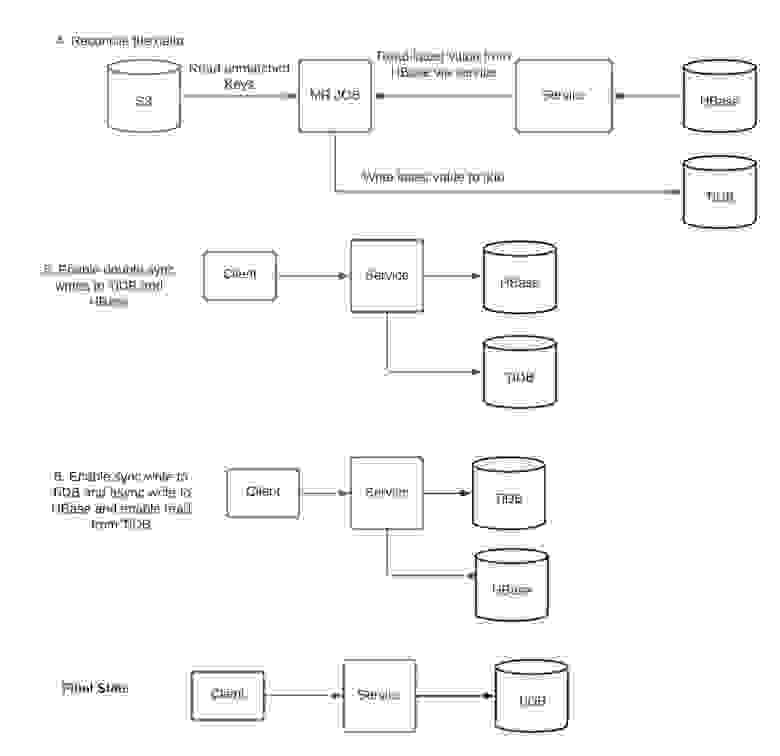
Подробности реализации
Так как HBase является schemaless-хранилищем, а TiDB использует строгую схему, прежде чем приступить к миграции, необходимо было спроектировать схему, содержащую корректные типы данных и индексы. Для нашей таблицы на 4 ТБ между схемами HBase и TiDB используется отображение 1:1. Это значит, что схема TiDB была спроектирована при помощи задачи Map Reduce, анализирующей все столбцы в строке hbase и их максимальный размер. После этого были проанализированы запросы для создания корректных индексов. Процесс состоял из следующих этапов:
- Мы использовали hbasesnapshotmanager для создания снэпшота HBase и сохранили его как csv-дамп в s3. Строки CSV мы сохранили как закодированные в Base64, чтобы обойти ограничения на особые символы. Затем мы использовали TiDB lightning в локальном режиме, чтобы начать поглощать этот csv-дамп, выполняя декодирование base64 перед сохранением строки в TiDB. После завершения поглощения и перехода таблицы TiDB в состояние онлайна начались асинхронные дублируемые операции записи в TiDB. Асинхронные дублируемые операции записи гарантируют, что SLA TiDB не повлияет на SLA сервиса. Хотя у нас была готова система мониторинга/пейджинга для TiDB, в это время TiDB работала в теневом режиме.
- Выполнили снэпшоты таблицы HBase и TiDB при помощи задачи Map Reduce. Строки сначала преобразовывались в стандартный объект и сохранялись как SequenceFiles в S3. Мы разработали собственный TiDB Snapshot Manager при помощи коннектора MR и использовали hbasesnapshotmanager для HBase.
- Считывали последовательные файлы при помощи задачи Map Reduce, записывавшей несовпадающие строки обратно в s3.
- Считывали эти несовпадающие строки из s3, затем считывали его последнее значение из сервиса (на основе HBase) и записывали значение во вторичную базу данных (TiDB).
- Включили дублируемые синхронные операции записи, чтобы операции записи выполнялись и в HBase, и в TiDB. Ежедневно выполняли задачу синхронизации из этапов 3, 4 и 5 для сравнения равенства данных в TiDB и HBase, чтобы получать статистику по несовпадению данных между TiDB и HBase и выполнить их синхронизацию. Механизм дублируемых синхронных операций записи не имеет возможности отката на случай сбоя записи в одну базу данных. Поэтому необходимо периодически выполнять задачи синхронизации, чтобы гарантировать отсутствие несоответствий.
- Продолжили синхронные операции записи в TiDB и включили асинхронные операции записи в HBase. Включили считывание из TiDB. На этом этапе SLA сервиса уже полностью зависит от доступности TiDB. Мы продолжили выполнять асинхронные операции записи в HBase, чтобы сохранить согласованность данных на случай, если нам потребуется откатиться назад.
- Полностью прекратили выполнять запись в HBase и вывели из эксплуатации таблицу HBase.
Работа с несоответствиями
- Сценарии возникновения несоответствий, вызванных недоступностью бэкенда.
Фреймворк дублируемых операций записи, встроенный в слой сервиса Ixia, не выполняет откат операций записи на случай их частичного сбоя из-за недоступности какой-либо из баз данных. Проблема такого сценария решается периодическим выполнением задач синхронизации для таблиц HBase и TiDB. При устранении таких несоответствий источником истины считается первичная база данных (HBase). На практике это значит, что если произошёл сбой записи в HBase, но в TiDB она прошла успешно, то в процессе синхронизации она будет удалена из TiDB.
- Сценарий возникновения несоответствий, вызванных условием гонки во время дублируемых операций записи и синхронизации.
Существует вероятность записи устаревших данных в TiDB, если события происходят в такой последовательности: (1) задача синхронизации выполняет считывание из HBase; (2) текущая операция записи выполняется в HBase синхронно, а в TiDB асинхронно; (3) задача синхронизации выполняет запись ранее считанного значения в TiDB.
Такой класс проблем также устраняется многократным выполнением задач синхронизации, поскольку после каждого выполнения количество таких несоответствий существенно снижается. На практике, для достижения 99,999% согласованности между HBase и TiDB для таблицы на 4 ТБ, обслуживающей 400 запросов записи в секунду достаточно одного выполнения задачи синхронизации. Это было подтверждено вторым дампом таблиц HBase и TiDB и сравнением их значений. При сравнении строк мы зафиксировали для таблиц 99,999% согласованности.
Преимущества
- Мы наблюдали трёх-пятикратное снижение 99-го перцентиля задержек для операций записи. 99-й перцентиль задержек запросов в этом сценарии снизился с 500 мс до 60 мс.
- Была достигнута согласованность считывания после записи, что было одной из наших целей для миграции с Ixia.
- После завершения миграции архитектура с точки зрения количества задействованных компонентов упростилась. Это существенно поможет нам в случае отладки проблем в продакшене.
Сложности и уроки
▍ Развёртывание TiDB на мощностях организации
Развёртывание TiDB в инфраструктуре Pinterest стало для нас отличной возможностью научиться новому, потому что мы не использовали TiUP (универсальный инструмент развёртывания TiDB). Это вызвано тем, что многие функции TiUP пересекаются с внутренними системами Pinterest (например, с системами развёртывания, сервисом автоматизации эксплуатационного инструментария, конвейерами метрик, управлением сертификатами TLS и так далее), а затраты на ликвидацию пробела между ними перевешивали преимущества.
Поэтому мы поддерживаем собственный репозиторий кода релизов TiDB и имеем конвейеры сборки, релизов и развёртывания. В реализации безопасного управления кластерами существует множество нюансов, и об этом нам пришлось узнать на собственном опыте, поскольку всеми ими занимается TiUP.
Так мы создали собственную платформу TiDB поверх AWS-инфраструктуры Pinterest, на которой мы можем выполнять без даунтайма апгрейды версий, апгрейды типов инстансов и операции по масштабированию кластеров.
▍ Поглощение данных
Выполняя поглощение данных и синхронизацию, мы столкнулись с перечисленными ниже проблемами. Стоит отметить, что на каждом этапе мы получали полную поддержку Pingcap. Также мы внесли несколько патчей в кодовую базу TiDB, которые были смержены вверх по цепочке.
- TiDB lightning версии 5.3.0 не поддерживал автоматическое обновление сертификатов TLS, и эту проблему было сложно отлаживать из-за отсутствия релевантных логов. Внутренний сервис Pinterest управления сертификатами обновляет сертификаты каждые 12 часов, поэтому мы столкнулись с несколькими ситуациями сбоев задач поглощения данных и нам пришлось решать их совместно с Pingcap. Эта функция была выпущена с версией TiDB 5.4.0.
- Локальный режим lightning потреблял много ресурсов и влиял на онлайн-трафик в отдельной таблице, обслуживаемой из того же кластера на этапе поглощения данных. Pingcap вместе с нами работала над устранением кратковременных и долговременных проблем Placement Rules, чтобы на реплику, обслуживающую онлайн-трафик, не влиял локальный режим.
- Чтобы коннектор MR СУБД TiDB мог выполнять снэпшот таблицы на 4 ТБ за разумное время, ему требовалось устранить проблемы с масштабируемостью. Также коннектор MR требовал улучшений в области TLS, мы разработали патчи, которые были смержены.
После улучшений и исправлений мы смогли выполнить поглощение 4 ТБ данных примерно за 8 часов, а проведение одного раунда синхронизации и верификации заняло примерно 7 часов.
▍ Ixia
Таблица, миграцию которой мы выполняли в рамках этой операции, обслуживалась Ixia. Мы столкнулись с парой проблем надёжности асинхронных/синхронных дублируемых операций записи и изменений паттернов запросов. Проблемы сервиса Thrift (Ixia) стало сложнее отлаживать из-за сложной распределённой архитектуры систем самой Ixia. Подробнее об этом можно прочитать в другой нашей статье.

