[Перевод] Кто убил сетевой коммутатор?
Недавно мы выявили интересный сбой в системе Hubris. Изначально этот код работал корректно, но со временем, в связи с изменениями в окружении и сопутствующих условиях, он превратился в ошибку.
Этот инцидент и процесс выявления и исправления ошибки предоставили нам новый взгляд на процесс разработки в контексте Hubris. Такие ошибки в ядре Hubris случаются нечасто, благодаря его компактности. Однако, этот особенный случай заставил меня зафиксировать его: речь идет о том, как две отдельные полезные функции, взаимодействуя вместе, привели к сбою в системе.
Что такое Hubris?
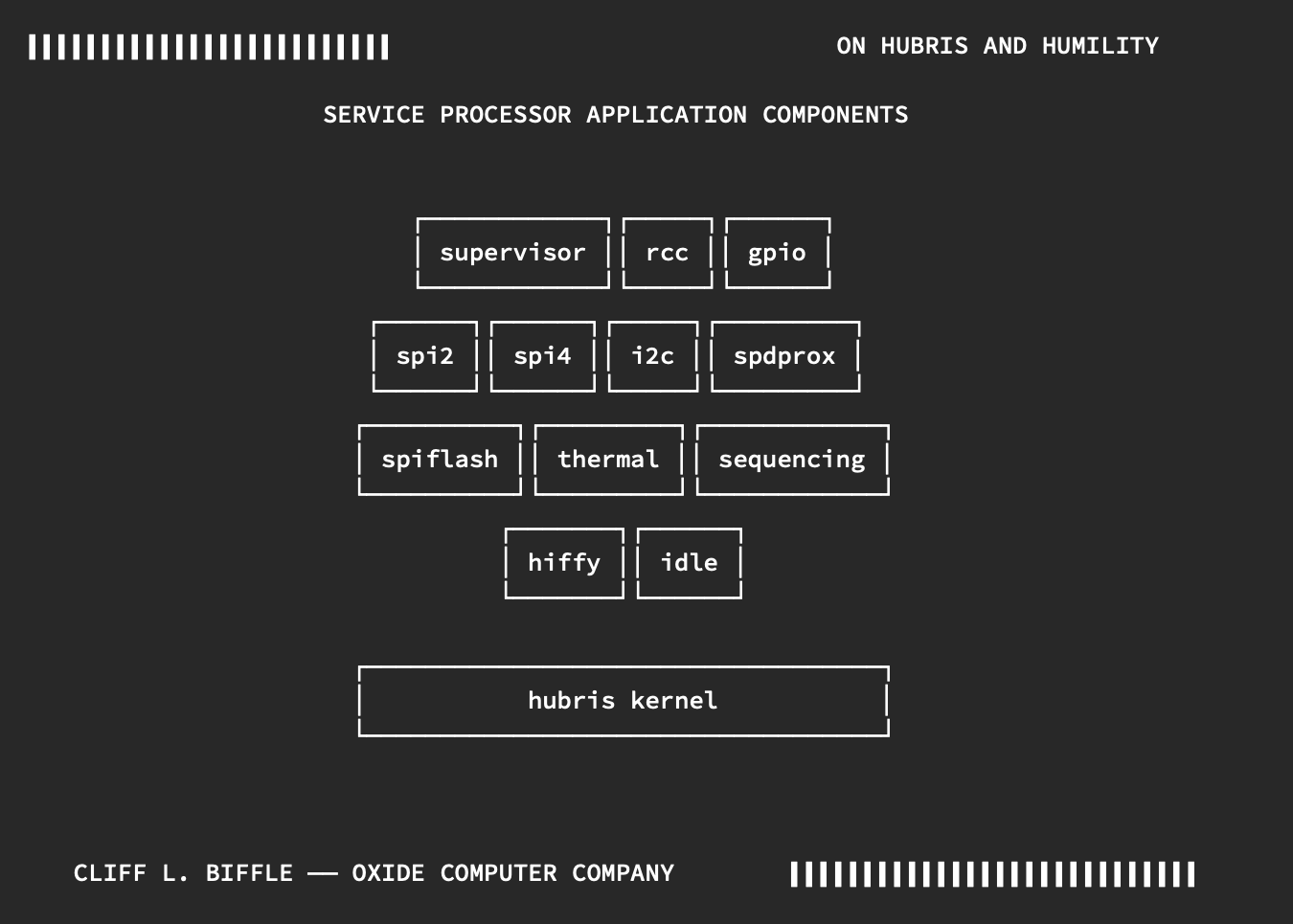
Hubris — это операционная система, созданная специально для встроенных систем. Эти системы находятся в устройствах, которые мы обычно не рассматриваем как компьютеры, например, внутри клавиатуры. Эта операционная система разработана для управления сложными процессорами, такими как те, что используются в Oxide Rack, которые мы традиционно воспринимаем как «настоящие компьютеры».
Hubris обладает рядом уникальных особенностей. Я подробнее расскажу о важных моментах, связанных с этой темой, но если вам интересно узнать больше, я рекомендую ознакомиться с нашим руководством — оно будет полезно для тех, кто не знаком с Hubris, а также с презентацией, в которой была объявлена эта операционная система.
Сцена преступления
Как это бывает в захватывающих детективных рассказах о преступлениях, давайте начнем с жертвы.
Мой коллега, Арьен Рудселар, играет ключевую роль в разработке прошивки для наших сетевых коммутаторов в Oxide. Он проводил тестирование своего нововведения в процесс загрузки и конфигурации системных часов — критически важных компонентов, от которых зависит запуск всех остальных функций. Однако после внесения казалось бы незначительного изменения, коммутатор внезапно отказался включаться.
Было замечено, что некоторые секции прошивки отзывались на запросы, но ключевой процесс — последовательность подачи питания — как будто перестал функционировать. Без подачи питания сетевой коммутатор превращался в ничто иное, как в огромный и тяжелый предмет для удержания бумаг.
Неправильное управление последовательностью подачи питания может фактически уничтожить аппаратуру. Вставал вопрос: был ли коммутатор безвозвратно потерян или он просто не отвечал? И как изменение кода, не связанное напрямую с процессом питания, могло повлиять на него?
Вот и загадка!
Теперь, когда мы описали обстановку, давайте отступим на шаг назад и обсудим некоторые детали архитектуры Hubris, чтобы лучше понять ситуацию.
Максимизация ограниченного объема оперативной памяти
На микроконтроллерах, с которыми работает Hubris, одной из основных технических задач является управление ограниченным объемом оперативной и флэш-памяти. В качестве примера возьмем нашу внутреннюю плату с отладочным зондом I2C, которая располагает всего 8 кБ оперативной и 32 кБ флэш-памяти. Для сравнения, даже бюджетный смартфон, который вы можете использовать для чтения этого текста, имеет в миллион раз больше памяти.
Hubris сталкивается с этим ограничением более остро, чем другие операционные системы для встроенных приложений, так как наша прошивка состоит из множества отдельных программ, называемых задачами. Каждая задача содержит собственную копию всех необходимых данных, включая стандартные библиотечные функции, что обычно приводит к более высоким требованиям к памяти, хоть и не настолько высоким, как можно было бы предположить.
Для обеспечения изоляции задач и предотвращения их взаимного влияния при сбоях мы используем аппаратный блок защиты памяти. Но это влечет за собой дополнительную нагрузку на объем оперативной и флэш-памяти. В микроконтроллерах ARM, преимущественно из линейки Cortex-M, которые мы используем для запуска Hubris, любая область памяти, защищенная блоком защиты, должна соответствовать степени двойки по размеру и быть выровнена соответственно. Это означает, что если вам требуется всего лишь один байт сверх 1024, размер области увеличивается вдвое до 2048 байт, вне зависимости от ваших предпочтений.
Ранее в Hubris мы защищали оперативную и флэш-память задачи отдельными блоками, что было просто, но приводило к фрагментации и потере памяти между задачами. Это было особенно раздражающим, учитывая первоначальные ограничения по памяти.
Мой коллега Мэтт Китер недавно усовершенствовал нашу систему, внедрив более интеллектуальный механизм: теперь система старается сокращать объем занимаемой памяти задачами, объединяя их в несколько сегментов, размеры которых являются степенями двойки, где это практически осуществимо. Следует подчеркнуть «где это практически осуществимо», поскольку аппаратные ограничения позволяют каждой задаче использовать не более восьми таких сегментов. В ряде случаев данное нововведение позволило нам вернуть до 30% оперативной памяти. Благодаря этому наши малогабаритные устройства теперь не так переполнены, как раньше, и мне не приходится постоянно заниматься оптимизацией кода, обеспечивая таким образом запас свободного пространства.
Данный прогресс действительно впечатляет. Но как это связано с текущим контекстом? Об этом я расскажу вам чуть позже. А пока давайте рассмотрим следующий пункт:
Доказательство
Арьен воспользовался Humility, нашим инструментом для отладки Hubris, и провёл тщательный анализ неработающего сетевого коммутатора. Служебный процессор, который управляет последовательностью подачи питания, казалось, в рабочем состоянии, что позволило исключить вероятность аппаратных неполадок.
Одной из стандартных команд, применяемых нами для мониторинга состояния системы на Hubris, является «humility tasks». Эта команда отображает список задач, выполняемых процессором, и предоставляет информацию об их текущем статусе. Когда Арьен запустил эту команду, его внимание привлекла одна конкретная строка: задача, отвечающая за управление последовательностью включения питания, показывала следующий статус:
mem fault (precise: 0x801bffd) in syscall (was: wait: reply from i2c_driver/gen0)
Также мы заметили, что задача перезапускалась 115 раз. Обычно перезапуск задач производится в ответ на сбои, что дало понять, что проблема возникала повторно при каждой попытке секвенсора активировать систему.
Следовательно, задача была недействительной. Осталось выяснить, кто инициировал её завершение.
Ответ на этот вопрос тесно связан с ключевыми принципами межпроцессного взаимодействия в Hubris.
Расширение заимствований Rust между задачами в механизме межпроцессного взаимодействия в Hubris
В Hubris задачи могут общаться друг с другом через механизм межпроцессного взаимодействия (IPC), обмениваясь сообщениями. Этот процесс очень похож на вызов функции: отправляющая задача приостанавливается, в то время как принимающая задача приступает к работе, а затем возвращает результат, позволяющий первой задаче продолжить выполнение.
Выбор данной схемы был обусловлен рядом причин, среди которых выделяется её совместимость с системой управления ресурсами языка Rust. Аналогично тому, как функция может одолжить управляемую ей память другой функции и затем безопасно получить её обратно, задача в Hubris может передать часть своей памяти другой задаче вместе с IPC сообщением.
Этот механизм активно применяется в прошивках на базе Hubris. Например, задачи, желающие взаимодействовать с I2C устройством, могут передать часть своей памяти драйверу I2C шины, который в свою очередь осуществляет чтение или запись данных непосредственно в этой памяти. Такой подход освобождает драйвер шины от необходимости иметь собственный буфер или другие ресурсы и минимизирует количество операций копирования данных.
Однако неправильное использование механизма передачи памяти через IPC может стать потенциальным риском для безопасности системы. Важной составляющей надёжности Hubris является изоляция задач: они не разделяют память, позволяя каждой задаче оперировать в своём собственном пространстве без вреда для других. Отсюда следует, что важно обеспечить, чтобы передача памяти через IPC не нарушала эту изоляцию.
Любая попытка передать память, которая фактически не существует, считается невозможной, так как ядро Hubris не разрешает это.
Если задача-источник попытается передать недоступную ей память серверу, ядро сообщит об ошибке серверу и клиенту. Для сервера это не критично, но клиентская задача будет немедленно остановлена. Мы исходим из предположения, что такое нарушение доступа может быть результатом ошибки, повреждения или попытки взлома исходной задачи, и предпочитаем сразу же прекращать её работу, не позволяя даже на момент ответить.
При этом ядро фиксирует информацию об инциденте, и после соответствующего форматирования эта информация превращается в статусный отчёт, подобный тому, который Арьен наблюдал в задаче-секвенсоре. Давайте подробнее рассмотрим, что это за отчёт.
mem fault (precise: 0x801bffd) in syscall (was: wait: reply from i2c_driver/gen0)
Это указывает на следующее:
mem faultозначает, что задача была прервана из-за неправильной обработки памяти;preciseиспользуется, потому что мы можем точно определить адрес, который был обработан неправильно;in syscallуказывает на то, что задача находилась в состоянии системного вызова, когда произошел сбой;was: wait: reply from i2c_driver/gen0указывает на то, что в момент сбоя задача ожидала ответа на сообщение, отправленное драйверу I2C. Мы всегда пытаемся записать состояние задачи непосредственно перед возникновением сбоя, чтобы облегчить процесс отладки.
(Если вам интересно, gen0 означает, что i2c_driver находится в первом поколении, что означает, что он ни разу не выходил из строя. sequencer был на поколении 115!)
Ядро системы различает фактические и синтетические ошибки. Фактическая ошибка происходит, когда задача выполняет некорректные операции, такие как обращение к нулевому указателю или попытка записи в зону своего кода. Такие ошибки генерируются аппаратно (в данном случае, блоком защиты памяти) в ответ на неправомерные действия задачи. Это означает, что они могут появиться только в процессе активной работы задачи, когда она совершает действия, нарушающие правила.
В противоположность аппаратным нарушениям, синтетические ошибки связаны с нарушением программных принципов. Процессор не осведомлён о концепциях таких, как «IPC» или «обмен памятью между задачами», поскольку они являются частью архитектуры системы Hubris. Для этих правил установлены отдельные критерии. Когда задача нарушает эти критерии, мы реагируем так же, как и на фактическую аппаратную ошибку, например, обращение к несуществующему адресу памяти. Однако мы используем отдельный набор данных об ошибке, который классифицирует её как синтетическую, для отличия от аппаратных ошибок.
Таким образом, из этого достаточно подробного отчета мы узнали следующее:
Задача-секвенсор нарушила правила ядра для доступа к памяти.
Это произошло по адресу
0x801bffd, который является необычным, но допустимым адресом во флеш-памяти для процессора.Это произошло в рамках IPC, отправленного драйверу I2C.
Это кажется весьма тревожным! Обычно, нарушения в доступе к памяти свидетельствуют о серьёзных ошибках в программе или о повреждении данных. Тот факт, что такое произошло в работе задачи-секвенсора, которая давно не подвергалась изменениям, может свидетельствовать о наличии скрытой проблемы с целостностью данных.
Это было бы довольно странным, учитывая, что наша прошивка написана почти исключительно на Rust, языке, который обеспечивает высокий уровень защиты от ошибок, связанных с повреждением данных. И всё же, все признаки указывают на возможное нарушение в целостности данных.
… или это не так?
Когда функции атакуют
Адрес, связанный с нарушением доступа к памяти, был 0x801bffd.
Когда Арьен запросил мою помощь, это уже показалось необычным. Действительно, это адрес во флеш-памяти, но странным было то, что он находится на три байта от следующей степени двойки. Мы могли исключить вероятность случайного переполнения при вычислении адреса, так как в системах Hubris имеются встроенные проверки на переполнение целых чисел при выполнении операций — в случае такой ошибки задача была бы прервана, и проблема выявлена немедленно.
Затем я вспомнил недавние изменения в планировании памяти, внесённые Мэттом.
Следует учесть, что MPU нашего процессора требует, чтобы размеры блоков памяти были степенью двойки и соблюдалось их выравнивание. Я запустил команду humility mem, чтобы проверить распределение памяти в системе, и действительно нашел участок, оканчивающийся на 0x801c000, и другой участок, начинающийся с этого же адреса.
И оба эти участка относились к одной и той же задаче.
LOW HIGH SIZE ATTR ID TASK
0x08018000 - 0x0801bfff 16киБ r-x--- 17 sequencer
0x0801c000 - 0x0801dfff 8киБ r-x--- 17 sequencer
Изначально всё функционировало нормально, до тех пор пока не возникли проблемы.
Компонент ядра Hubris, отвечающий за проверку доступа к памяти, играет решающую роль в обеспечении безопасности системы. Мы стремимся к тому, чтобы наиболее чувствительные участки кода были максимально упрощены. Как я уже говорил, в ранние дни разработки Hubris, когда я занимался написанием этой части ядра, у задач было только по одному блоку для RAM и флеш-памяти.
Тогда я сделал код проверки доступа более простым, чтобы это отразить. Код выглядел следующим образом:
self.region_table().iter().any(|region| {
region.covers(slice)
&& region.attributes.contains(desired)
&& !region.attributes.intersects(forbidden)
})Доступ был разрешен, если существовала хотя бы одна область в таблице областей задачи, которая:
полностью покрывала заимствованный сегмент памяти,
имела все необходимые атрибуты (например, была доступной для записи, если IPC требовал этого),
не имела никаких «запрещенных» атрибутов, таких как содержание отображаемых в память регистров или использование для аппаратного DMA (такая память в настоящее время не могла быть передана в аренду по определенным причинам).
В момент создания, данный фрагмент кода был корректным, однако основывался на допущении, что вся заимствованная память укладывается в один сегмент.
Это предположение устарело после того, как Мэтт реализовал функцию планирования задач, но мы упустили это из виду. Таким образом, код, который был простым и понятным, стал неприменимым.
Стоит упомянуть, что этот код применяется исключительно для проверки заимствованной памяти. Обычные операции доступа к памяти в работающей программе контролируются аппаратным блоком защиты памяти, который не сталкивается с подобной проблемой. Это означает, что, скорее всего, у задачи не было проблем при обращениях к памяти в пределах этой границы сегмента… до тех пор, пока не возникла попытка передать этот участок во временное пользование.
Когда две безвредные функции объединяются и приводят к сбоям в работе сетевого коммутатора…
В нашей системе сборки задачи распределяются по принципу использования возможностей по мере их появления. Поскольку оборудование MPU ограничивает каждую задачу максимум восемью сегментами памяти, а многие задачи фактически являются драйверами устройств с регистрами, которые доступны по определенным адресам в этих сегментах, иногда мы сталкиваемся с нехваткой свободных слотов в таблице из восьми сегментов для эффективного распределения задач.
Тем не менее, когда представляется возможность, мы стремимся максимально эффективно упаковать задачи, занимая несколько сегментов памяти.
Это приводит к тому, что границы этих сегментов могут пересекаться с зонами флеш-памяти и ОЗУ, предназначенными для задач. Особо стоит подчеркнуть, что расположение этих границ может быть неожиданным для разработчиков самих задач. Размещение задач в памяти и положение границ зависят от требований к размеру, специфичных для каждой задачи.
Это подразумевает, что даже небольшое, на первый взгляд безвредное, изменение в задаче A, ведущее к минимальному изменению её размера, может вызвать сдвиг границ сегментов MPU в несвязанной задаче B.
Теперь стало ясно, что такая ситуация неприемлема. Случайные ошибки, исчезающие после внедрения кода для отладки, представляют собой особенно коварный вид проблем. И именно с такими неполадками мы столкнулись — любые изменения в коде могли повлиять на решения о распределении памяти и определении её границ, что, в свою очередь, могло привести к сбоям в системе.
Мэтт незамедлительно отключил функцию компоновки задач в системе сборки, что позволило Арьену собрать исправленный образ прошивки и продолжить его исследования по взлому сетевого коммутатора. В то же время я приступил к составлению отчета о найденном баге и начал готовиться к тому, чтобы столкнуться с последствиями проблемы, которую я ненамеренно создал четыре года назад.
Звонок идет изнутри дома!
Теперь, когда ядро ошибочно прерывало работу задач в стремлении обезопасить память, стало очевидно, что алгоритм защиты памяти нуждается в пересмотре. То, что ранее казалось желательным упрощением, теперь стало ненужным.
Основная задача алгоритма оставалась неизменной с момента его создания в 2020 году:
Разрешить задачам указывать секции памяти, которые они хотят передать с помощью сообщения.
Обеспечить, чтобы задача обладала фактическим доступом к памяти, которую она стремится использовать. К примеру, если задача намерена передать память для записи, она сама должна иметь возможность осуществлять запись в эту память. В противном случае, система может ошибочно предоставить задаче права, которыми она не должна обладать.
Основное отличие теперь заключается в том, что мы должны разрешить передачу памяти через сегменты MPU, при условии, что эти сегменты являются точно примыкающими друг к другу.
Новый алгоритм гораздо более сложен по сравнению с первоначальной версией, поскольку наша цель — осуществить обработку таблицы сегментов за один проход. В Hubris мы прилагаем усилия, чтобы избегать операций, время выполнения которых может изменяться в зависимости от задачи. Хотя мы и не всегда достигаем идеала, мы стремимся к этому. Поэтому было критически важно, чтобы эффективность алгоритма определялась исключительно размером таблицы сегментов — который фиксирован и составляет восемь -, а не объемом передаваемой памяти. Это достижимо за один проход, если таблица отсортирована по адресам; я внес соответствующие изменения в систему сборки, чтобы это было всегда так. Вы можете ознакомиться с коммитом для изучения всех тонкостей, но важно помнить следующее:
// ... сюда относятся вещи, связанные с созданием таблицы областей ...
// Упорядочиваем области задачи в порядке возрастания адреса.
// ЭТО ВАЖНО. Ядро использует это свойство для более дешевых проверок доступа.
regions.sort_by_key(|i| region_table.get_index(*i).unwrap().1.base);В свете значительной сложности нового алгоритма, моя коллега Элиза Вайсман настоятельно рекомендовала извлечь его из основной части ядра Hubris и разместить в более гибком пакете, что упростит процесс модульного тестирования. Мы уже разработали модульные тесты для наиболее критических сценариев; в соответствии с подходом Кента Бека, мы намерены продолжать добавление тестов «до того момента, когда беспокойство сменится утомлением».
Когда я упоминаю о «намного более сложном» коде, я имею в виду его сложность по сравнению с первоначальной реализацией в Hubris, выполняющей аналогичную функцию. Тем не менее, этот код гораздо проще, чем его аналоги в большинстве других операционных систем. Ниже приведен полный код с комментариями из оригинальной версии. (Следует отметить, что здесь 'фрагмент' не относится к сегменту кода на языке Rust в ядре, а обозначает структуру, которая представляет сегмент памяти, запрошенный задачей, с указанием его адреса и размера.)
// С учетом условий предварительной обработки функции,
// таблица областей упорядочена по возрастанию базового адреса,
// и внутренние области не пересекаются.
// Это позволяет использовать алгоритм с одним проходом.
let mut scan_addr = slice.base_addr();
let end_addr = slice.end_addr();
for region in table {
if region.contains(scan_addr) {
// Убедимся, что это допустимо!
if !region_ok(region) {
// Переходим к коду обработки сбоя в конце
break;
}
if end_addr <= region.end_addr() {
// Мы исчерпали срез в этой области,
// дальнейшая обработка не требуется.
return true;
}
// Продолжаем сканирование в конце этой области.
scan_addr = region.end_addr();
} else if region.base_addr() > scan_addr {
// Мы пропустили наш целевой адрес, не найдя подходящих областей!
break;
}
}
// Мы достигаем этой точки, исчерпав таблицу областей,
// или обнаружив область с более высоким адресом, чем у среза.
falseС применением этой новой реализации мы вновь можем активировать функциональность сжатия задач, не рискуя причинить разработчикам задач дополнительные трудности. От момента, когда Арьен выявил сбой в сетевом коммутаторе, до исправления ошибки в ядре прошло около трех часов. На следующее утро я уже приступил к созданию модульных тестов.
Неудача с Hubris
Самым интересным моментом в этом эпизоде является то, что не случилось, или, более точно, как система отреагировала на неудачу и в каких ситуациях сбоев удалось избежать.
Мы преодолели путь от ситуации, когда «сетевой коммутатор не включался после обновления прошивки», до момента, когда два инженера, находясь на расстоянии в 3000 миль друг от друга (я — на западном побережье США, а Мэтт — на восточном), анализировали отчеты о сбоях независимо друг от друга и устранили неполадку в ядре всего лишь за три часа. Ранее я тратил гораздо больше времени на исправление одного бага, связанного с повреждением памяти, в других системах. Я считаю, что ключевым моментом здесь является следующее:
Изоляция сбоев. Когда произошел сбой при последовательном запуске на сложном оборудовании, он затронул лишь часть системы. Программное обеспечение сетевого коммутатора разделено на 23 независимых компонента (задачи). Некоторые из них, разумеется, зависят от последовательности запуска на разных этапах их жизненного цикла, что является критически важным! Тем не менее, они продолжали функционировать на протяжении ста пятнадцати попыток сбоя и перезагрузки. Среди них следующие:
Система обновления прошивки.
IP-стек сети, предоставляющий интерфейс управления и контроля.
Различные сетевые службы, начиная от реализации базового протокола эха и заканчивая интерфейсом управления планом управления стойки.
I2C, SMBus и PMBus для всех датчиков, вентиляторов и прочих устройств, контролирующих использование ресурсов и физическое состояние системы.
Драйверы для 32 трансиверов QSFP 100 гигабит на передней панели коммутатора.
…и многие другие. Они смогли функционировать без перебоев благодаря эффективной изоляции ошибок, реализованной через систему Hubris, которая проявилась в двух ключевых аспектах. Во-первых, если задача, связанная с последовательностью запуска, терпела неудачу, это не влияло на состояние других задач, аппаратную часть или основу системы. Во-вторых, механизм обмена данными между процессами в Hubris был спроектирован с предположением, что отдельные задачи могут выйти из строя, и обеспечивал возможность автоматического повторения операций, определенных как «идемпотентные». Это давало возможность клиентам отсоединяться от серверов, столкнувшихся с сбоями.
Принципиальное соблюдение безопасности. В Hubris мы стремимся к тому, чтобы внедрять и поддерживать концепцию «безопасной по умолчанию» как в самой реализации, так и в API. Это означает, что мы предпочитаем предотвращать работу некоторых корректных программ в ущерб возможности выполнения некорректных или злонамеренных программ. Например, исходный алгоритм контроля доступа к памяти был настроен таким образом, что он мог блокировать доступ для правильной программы, чтобы исключить возможность несанкционированных доступов со стороны некорректной или вредоносной программы. Это привело к редкому случаю ошибки проверки доступа к памяти в ядре, который не поставил под угрозу безопасность системы. Мы тщательно следим за этим принципом на всех уровнях системы, рассматривая весь входящий поток данных как потенциально опасный и считая любое неоднозначное использование системы как ошибочное. В результате, даже в случае сбоев системы, они происходят в формах, которые не поддаются эксплуатации.
Улучшенная безопасность разделения памяти. С нашим механизмом передачи памяти через IPC, даже когда задача управления последовательностью и драйвер I2C фактически использовали общую память в момент сбоя последовательности, драйвер I2C оставался невредимым и продолжал функционировать. Он так и не потребовал перезапуска. Мы исходим из предпосылки, что задача, выполняющая роль сервера (как драйвер I2C в этом случае), обычно обслуживает несколько клиентов и поэтому должна быть устойчива к случайным ошибкам этих клиентов, включая потенциальные нарушения доступа к памяти.
Синергия инструментов разработки. Мой коллега Брайан Кэнтрилл создал код, который положил начало Humility, нашему отладчику, в то время как я занимался написанием кода для основы Hubris. Обе эти системы развивались и совершенствовались параллельно, и я не могу представить этот процесс иначе. С помощью Humility Арьен смог быстро идентифицировать причину сбоя (вплоть до конкретной строки кода) и в течение нескольких минут создать дамп сервисного процессора, который он затем загрузил в чат-канал, доступный Мэтту и мне.
Отчеты о сбоях в прошивке являются чрезвычайно полезными. Я никогда не имел прямого доступа к устройству, которое вышло из строя, и на самом деле не знаю его физического местоположения. Однако это неважно; благодаря инструменту Humility, мы можем получать точные снимки состояния наших встроенных систем, даже когда кто-то имеет к ним физический доступ. В Hubris, согласно нашей концепции дизайна, функциональность для создания дампов памяти при сбоях не встроена напрямую в ядро — она расположена в отдельной задаче. Реализация этой возможности через сетевой доступ была сложной задачей, которую прекрасно осветил Мэтт Китер в своей презентации на конференции OSFC 2023 для тех, кто заинтересован в деталях. Hubris записывает сжатые дампы памяти задач, которые сбойнули, в оперативную память, откуда мы можем их извлекать через сеть. Следует отметить, что для сохранения конфиденциальности наших клиентов, эти процессоры никогда не обрабатывают данные клиентской рабочей нагрузки, только системный управленческий трафик. К тому же, модуль дампа сбоев не включен в корневую цепочку доверия, управляющую криптографическими ключами. Мы также никогда не отправляем отчеты о сбоях автоматически. Несмотря на то, что описанный сбой произошел в одной из наших лабораторий, в случае сбоя у клиента, ему потребуется отправить нам дамп, если он сочтет это безопасным. Это обеспечивает возможность получения отчетов о сбоях без необходимости доступа к постоянной памяти, такой как флэш-память.
Простота дизайна и реализации. Ядерная концепция и архитектура Hubris отличаются простотой. Изначально мне было сложно поверить, что такой подход сможет обеспечить создание эффективной производственной прошивки, но мои сомнения оказались напрасными. Система межпроцессного взаимодействия основана всего на трех операциях и лишена сложных или избыточных элементов. Это означает, что если возникает ошибка, связанная с межпроцессным взаимодействием, потенциальных мест для поиска проблемы существенно меньше.
Даже если бы потребовалось провести более широкий поиск ошибки, независимая от архитектуры часть ядра Hubris насчитывает всего 1,789 строк кода, что эквивалентно примерно четырем копиям данного сообщения. Это означает, что при необходимости один разработчик мог бы осуществить полный просмотр всего ядра в поисках ошибки.
Хотя до сих пор нам не приходилось прибегать к такому мероприятию, уверенность в том, что мы могли бы это сделать при необходимости, придает дополнительное спокойствие.
Тесная и равноправная интеграция в команде. Хотя это и не является прямым атрибутом Hubris, трудно отделить его от команды разработчиков Oxide, стоящей за его созданием. Наш коллектив является поистине совместным пространством без внутренних барьеров. Мы высоко ценим культуру, основанную на прозрачности, интеллектуальной заинтересованности и общении, и в то же время отвергаем излишнюю оборонительность, стремление к разделению власти и ограничение доступа к информации. Мы приложили немало усилий для того, чтобы сформировать и сохранить такую атмосферу, и это находит отражение в нашем коллективистском подходе к организации работы, который превосходит стандартные границы традиционных командных структур.
Если бы меня не было в офисе в тот роковой день, другой член команды взял бы на себя инициативу и исправил бы ошибку в мое отсутствие. Будь то Мэтт, Лора Абботт, Элиза, Арьен, Брайан или кто-то другой из нашего коллектива — их действия были бы лишены страха перед возможными последствиями. Возможно, они потратили бы немного больше времени, поскольку именно я создал первоначальный код и лучше знал его проблемные места, однако разница не была бы существенной. Огромное значение имеет поддержание кода в состоянии, когда он остаётся понятным, хорошо задокументированным и доступным для анализа. Также важно сохранять в команде такую среду, где каждый член готов и способен внести свой вклад.
