[Перевод] Как кастомные решения помогли сэкономить на сетевой инфраструктуре

Построение инфраструктуры CDN связано с большим количеством технических вопросов: от выбора оборудования и установки его в датацентрах до пользовательского интерфейса для взаимодействия с возможностями сети. Мы приводим перевод статьи из блога Fastly, где команда рассказывает об очень интересных кастомных решениях для работы с сетью (значительная часть которых независимо была использована в инфраструктуре Айри).
В результате оптимизации инфраструктуры удалось добиться минимального времени простоя при отказе какого-либо узла и большой масштабируемости системы.
Масштабирование
Постепенно развивать CDN — непросто, поскольку сама суть услуги предполагает клиентов с обширной географией запросов. Поэтому изначально Fastly сконцентрировалась на том, что в индустрии отсутствовало: максимальная прозрачность и контроль над тем, как контент доставляется на «границе».
Когда мы только начинали, наш недостаток опыта в сетевых технологиях мало на что влиял. Наша типичная точка присутствия (POP) состояла из двух хостов, напрямую соединенных с провайдерами по BGP (Border Gateway Protocol). К началу 2013 года мы выросли настолько, что этого числа хостов уже не хватало.
Масштабировать нашу топологию, подсоединяя еще больше кэшей напрямую к провайдерам, как показано на рис. 1(а), было нельзя. Провайдеры не хотят работать таким образом из-за стоимости портов и сложности настройки дополнительных BGP-сессий.
Рис. 1. Влияние масштабируемой топологии сети
Очевидным решением могло быть сетевое устройство, как показано на рис. 1(b). Хотя это мог бы быть допустимый компромисс, природа CDN такова, что предполагает постоянное увеличение географического охвата и трафика.
Сегодня наши самые небольшие точки присутствия включают в себя два сетевых устройства, как показано на рис. 1©. Как это работает, показано на рис. 2. Маршрутизатор получает маршруты напрямую от провайдеров через BGP и вставляет их в базу FIB (Forwarding Information Base). Таблица поиска, реализованная аппаратно, используется для выбора маршрута. Хосты направляют трафик на маршрутизатор, который перенаправляет пакеты на наиболее подходящий следующий участок сети, согласно поиску в FIB устройства.
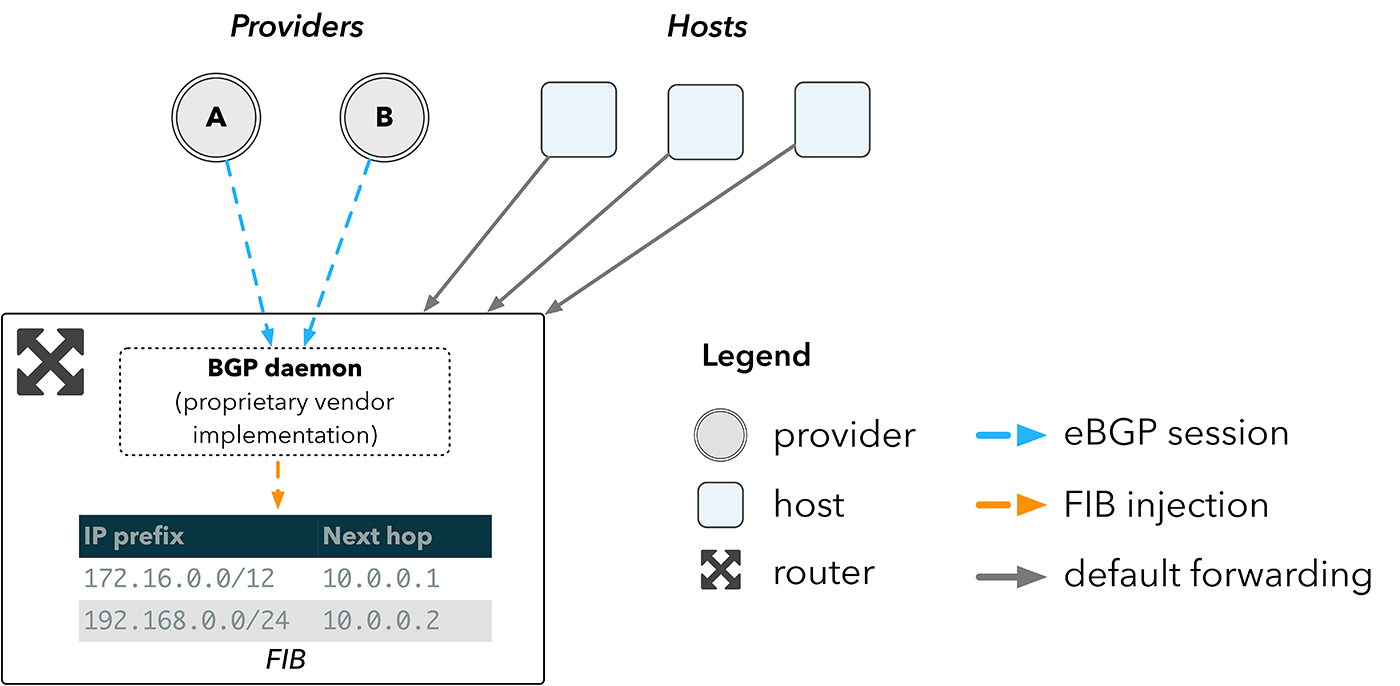
Рис. 2. Сетевая топология с использованием роутера
Чем больше FIB, тем больше маршрутов может хранить устройство. Пограничные маршрутизаторы должны быть в состоянии хранить таблицу роутинга для всего интернета, которая сейчас превосходит 600 000 записей. Аппаратная часть, которая требуется для хранения такой FIB, формирует основную часть стоимости маршрутизатора.
Маршрутизация без маршрутизаторов
В традиционных облачных средах стоимость пограничных маршрутизаторов быстро становится ничтожной на фоне огромного объема серверов и свитчей, которые они обслуживают. Но CDN должны обладать большим количеством выгодно расположенных точек, откуда они доставляют контент. Поэтому сетевые устройства могут составлять значительную долю в затратах на инфраструктуру CDN.
Идея потратить несколько миллионов долларов на очень дорогое сетевое «железо» нам совсем не нравилась. Мы бы лучше инвестировали эти деньги в обычные серверы, которые напрямую отвечают за то, насколько эффективно мы доставляем контент.
Можно было бы воспользоваться коммутаторами, но в них очень ограниченная FIB — порядка десятков тысяч маршрутов, что намного меньше, чем нам нужно. К 2013 году такие вендоры как Arista стали внедрять функциональность, которая помогла бы нам справиться с этим ограничением. Вендоры стали позволять запускать наше собственное ПО на коммутаторах.
Вместо того чтобы полагаться на FIB в сетевом устройстве, мы могли переправлять трафик на хосты. BGP-сессии от наших провайдеров все равно терминировались бы на коммутаторах, но маршруты далее шли бы к хостам.
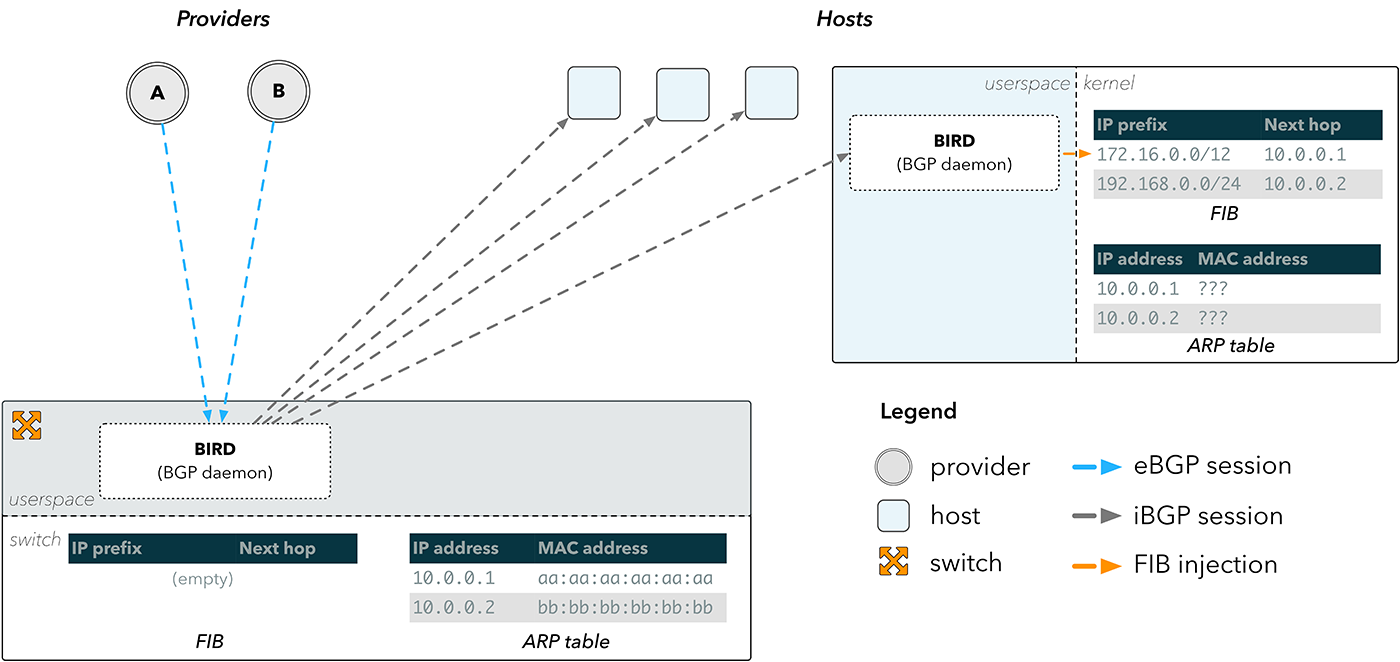
Рис. 3. Отражение маршрутов BGP
Внешние BGP-сессии (eBGP) терминируются на BGP-демоне, таком как BIRD, который запущен на коммутаторе. Полученные маршруты затем отправляются через внутренние BGP-сессии (iBGP) на BIRD, запущенный на хостах, который затем вставляет маршруты напрямую в ядро хоста.
Это решает проблему обхода FIB на коммутаторе, но не проблему, как отправить пакеты обратно в интернет. Запись в FIB состоит из префикса места назначения и адреса следующего участка сети. Чтобы отправить пакет на следующий участок, устройство должно знать его физический адрес в сети. Эти данные хранятся в таблице протокола определения адресов ARP (Address Resolution Protocol).
На рис. 3 показано, что коммутатор обладает правильной ARP-информацией для наших провайдеров, поскольку он подключен к ним напрямую. Хосты же ею не обладают и поэтому не могут определить следующий участок сети для того, что было прислано им по BGP.
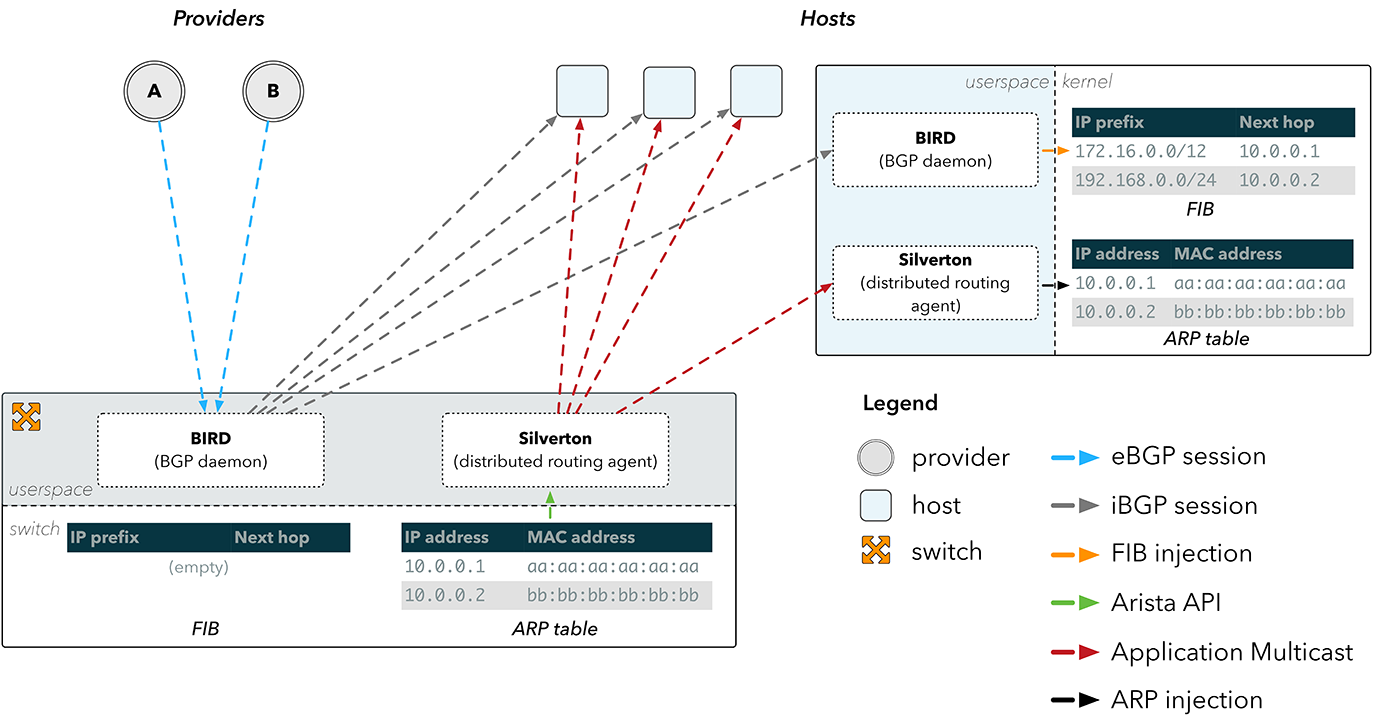
Рис. 4. Распространение ARP с помощью Silverton
Silverton — распределенный маршрутизирующий агент
Это стало причиной появления Silverton — нашего собственного контроллера сети, который управляет маршрутизацией в наших точках присутствия. Мы поняли, что мы можем просто запускать демона на коммутаторе, который узнает об изменениях в ARP-таблице через API на устройствах Arista. Узнав об изменении физического MAC-адреса провайдера, Silverton затем распространяет эту информацию по нашей сети, и клиенты на хостах переконфигурируют наши серверы с учетом информации, как напрямую достичь провайдеров.
Имея IP- и MAC-адреса провайдера, первым шагом для Silverton на клиентской стороне является «обмануть» хост, чтобы он «поверил», что этот IP-адрес напрямую доступен через интерфейс или локальный линк. Этого можно добиться, конфигурируя IP-адрес провайдера как «peer» в интерфейсе через iproute:
$ ip addr add
Если хост считает IP-адрес провайдера локальным линком, он будет искать его MAC-адрес в таблице ARP. Это тоже можно подправить:
$ ip neigh replace 10.0.0.1 lladdr aa:aa:aa:aa:aa:aa nud permanent dev eth0
Теперь каждый раз поиск маршрута будет возвращать следующий участок как
10.0.0.1, и трафик будет отправляться на aa: aa: aa: aa: aa: aa напрямую.
Коммутатор получает фреймы данных от хоста на физический MAC-адрес, который, как известно, подсоединен напрямую. Коммутатор может определить на какой интерфейс отправить фрейм, просматривая локальную таблицу MAC-адресов, где указано соответствие MAC-адреса места назначения и исходящего интерфейса.
Хотя описанный процесс может показаться весьма сложным, наша первая версия Silverton содержала менее 200 строк кода. И это сэкономило нам сотни тысяч долларов на каждой точке присутствия, которую мы разворачивали. Со временем Silverton «вырос» и стал обеспечивать всю динамическую конфигурацию сети: от обозначения полей описания до манипулирования объявлениями о маршрутизации и опустошения BGP-сессий.
Кроме того, Silverton обеспечил ценный уровень абстракции. Он поддерживал иллюзию, что каждый хост напрямую соединен с каждым провайдером, что было нашей начальной точкой (рис. 1 — вариант А). Поддерживая несколько таблиц маршрутизации в ядре и выбирая, какую использовать для каждого пакета, мы смогли создать инструменты и приложения поверх Silverton. Примером может служить утилита st-ping, которая пингует места назначения по всем подключенным провайдерам.

Рис. 5. Пинг по всем транзитным провайдерам в точке присутствия
Предпосылки для Faild
Поскольку мы уже убедились, что избавившись от традиционных сетевых устройств, можно значительно сократить капитальные затраты, то обратили внимание на балансировщики нагрузки.
Традиционно нагрузка распределялась исключительно с помощью балансировщиков или ECMP-маршрутизаторов. Недавно противоположный подход стал набирать силу, в частности, такие сервисы как MagLev и GLB осуществляют балансировку с помощью ПО, запущенного на хостах.
Наша разработка Faild — это синтез двух подходов, где мы используем аппаратную обработку на традиционных коммутаторах везде, где это возможно, и перекладывая обработку на хосты там, где это необходимо. Результатом такого подхода стал распределенный балансировщик.
Балансировка клиентских запросов: хождение по канату
Представьте набор серверов, который обслуживает ряд клиентов, как показано на рис. 6. С точки зрения клиента, какой сервер обслужил его запрос, совершенно не важно до тех пор, пока ответ получен достаточно быстро. Это дает гибкость в сопоставлении того, какие запросы обрабатываются какими ресурсами. Это называется балансировкой нагрузки и осуществляется практически на каждом уровне сетевого стека. Здесь мы сфокусируемся на балансировке входящих клиентских запросов в контексте CDN.
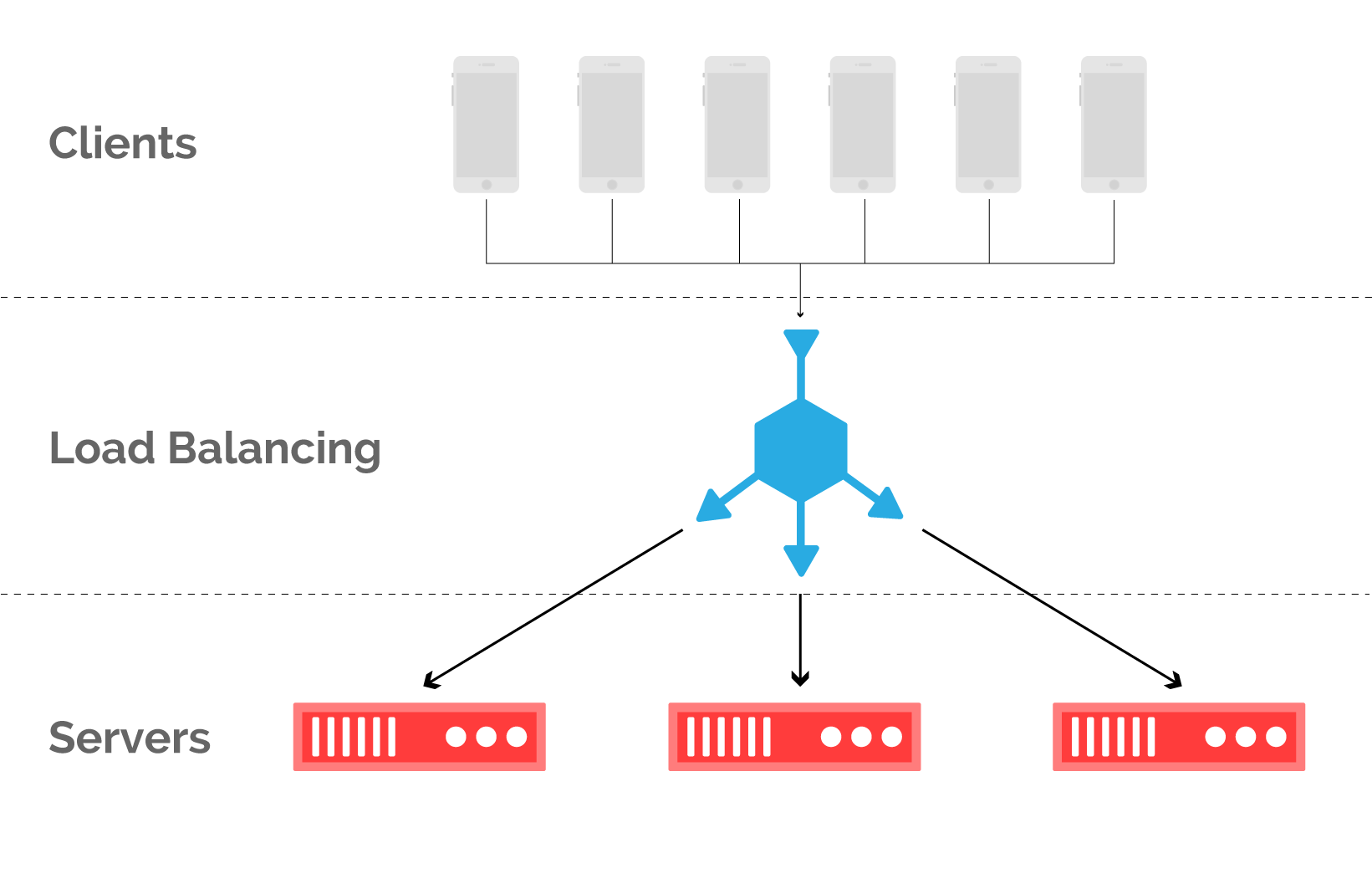
Рис. 6. При балансировке клиентские запросы сопоставляются с серверами кэша в точке присутствия
Главная проблема балансировки http-запросов заключается в неизбежном ограничении: если пакет из установленного TCP-соединения перенаправлен на неправильный сервер, то соответствующий TCP-поток будет сброшен.

Рис. 7. Топология сети, использующей балансировщик (а) и соответствующий ей поток пакетов (b)
Балансировщики обычно работают как прокси, терминируют соединения от клиентов и направляют трафик по серверам бэкенда, как показано на рис. 7(а).
Балансировщик может мониторить состояние серверов бэкенда, чтобы принимать решение, куда направлять входящие потоки. При правильной реализации распределение запросов по серверам бэкенда близко к оптимальному, но обходится очень дорого. Балансировщик отслеживает состояние каждого сетевого соединения, и это тяжелая задача, для которой зачастую используют специализированное «железо».
Однако поддерживать информацию о состоянии соединений — это дополнительная сложность. Как известно, отправителю проще создавать соединения, чем получателю — отслеживать их, и эта ассиметрия в TCP регулярно используется при проведении DOS-атак. Большинство балансировщиков содержат дополнительные средства для предотвращения SYN-флуда, но они все равно являются «узким местом» сети. Даже виртуализированные балансировщики, которые работают на обычном оборудовании, такие как Google MagLev, требуют отслеживания состояния потоков, и поэтому для них также опасны DOS-атаки.
DNS: вариант обхода
DNS превращает имена в адреса, и это может быть использовано для балансировки нагрузки между серверами, если будут возвращаться только IP-адреса нормально функционирующих серверов.

Рис. 8. Архитектура выбора сервера через DNS (a) и соответствующий поток пакетов (b)
Этот подход не требует отслеживания состояния потоков и поэтому хорошо масштабируется. Однако у него есть фундаментальное ограничение в части обработки отказа. Ответ DNS может кэшироваться нижестоящими резолверами на протяжении минут, а иногда даже и часов. Период кэширования ответа передается через поле TTL в ответе, но это не всегда учитывается резолверами. Поэтому распространение изменения может занять значительное время, в течение которого клиент будет подключен к неработающему серверу.
Такие компании как Spotify или Netflix могут контролировать и приложение конечного пользователя и серверы на границе, и поэтому могут обойти эту проблему с DNS, внедряя выбор сервера в свои приложения. Такие CDN как Fastly не могут так поступить, поскольку должны работать с множеством вариантов — начиная от видеостриминга до вызовов API. Единственное, что известно наверняка — это то, что запрос будет сделан по HTTP.
ECMP: «меньшее зло»
Другая известная альтернатива — это ECMP (Equal Cost Multi-Path). ECMP сопоставляет одному и тому же префиксу места назначения несколько следующих участков сети, и выбор такого участка определяется через хэширование полей в заголовке пересылаемого пакета. Вычисляя хэш от таких полей, которые не меняются за время жизни потока (адреса источника, места назначения и порты), мы можем быть уверены, что все пакеты потока отправляются на один и тот же следующий участок сети.
Серверы могут сигнализировать через BGP о своей доступности подключенному коммутатору, хэширующему пакеты.
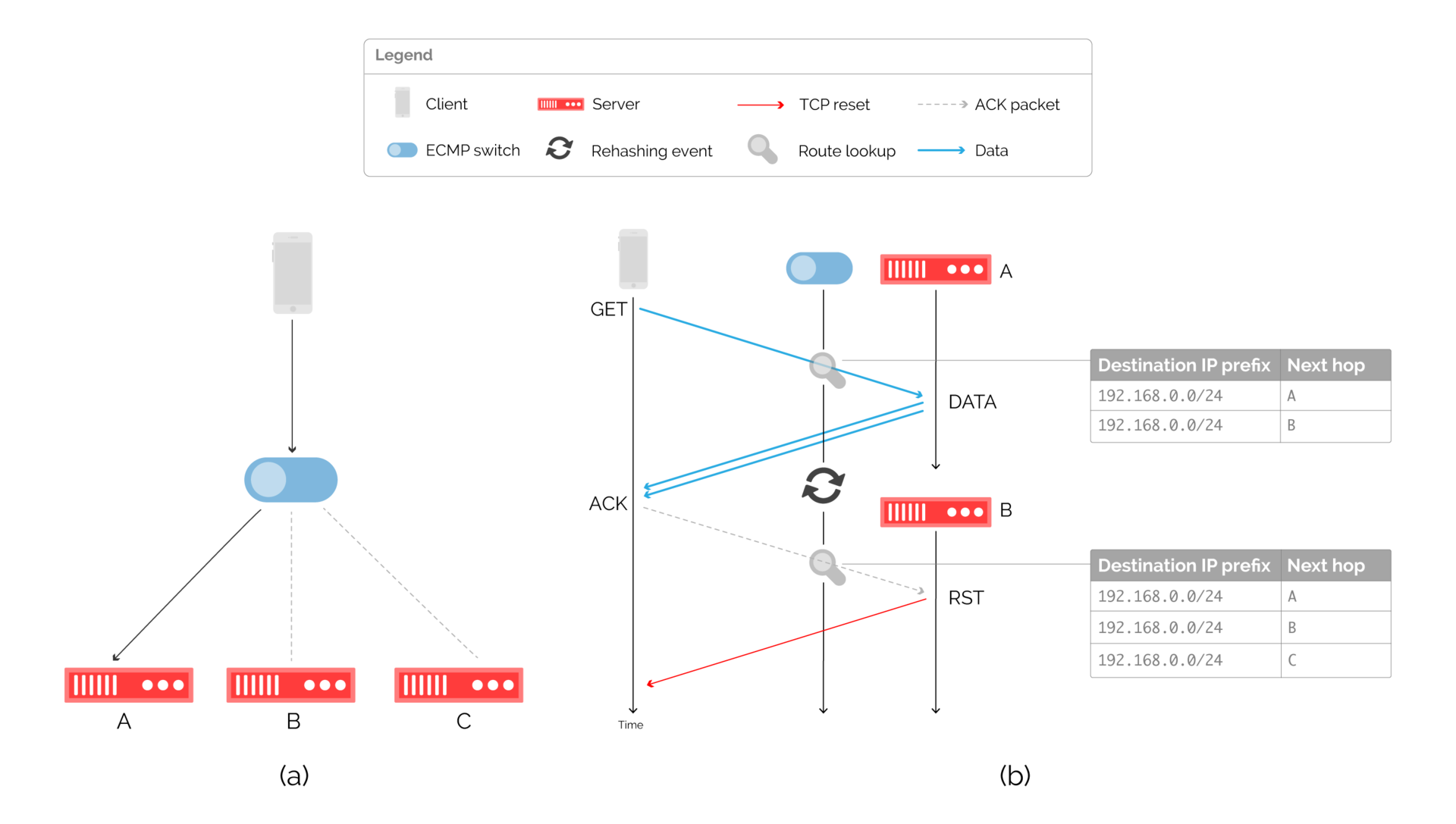
Рис. 9: Балансировка через ECMP-коммутатор и соответствующий поток пакетов в момент перехэширования.
Недостаток такого подхода заключается в том, что до недавнего времени производители не поддерживали постоянство хэширования в ECMP. При изменении маршрута, вызванного добавлением или исключением сервера, результат хэширования мог измениться, из-за чего пакеты могли быть отправлены на другой сервер. Эта ситуация показана на рис. 9(b).
Несмотря на это, ECMP остается популярным подходом в индустрии CDN. Отказываясь от отслеживания состояний, ECMP хорошо работает при стабильной работе серверов, создавая взамен проблемы с соединениями при смене состояний.
«Эластичный» ECMP: первое приближение
Перехэширование случается, когда изменяется информация о следующих участках сети. Возможной альтернативой могло бы быть использование таблиц ARP как средства обхода проблемы. Указывая в таблице маршрутизации статичные следующие участки сети, мы можем заставить коммутатор осуществить поиск в ARP-таблице. Мы также можем перенастраивать ARP-таблицу, чтобы влиять на пересылку пакетов.
Возникают две проблемы:
- Мы больше не можем использовать протоколы маршрутизации, такие как BGP или OSPF, чтобы направлять трафик на серверы. Обычные протоколы маршрутизации обеспечивают доступность, изменяя таблицу маршрутизации, но наш подход переносит управление трафиком на слой соединений. Мы должны написать контроллер, который напрямую изменяет ARP-таблицу на коммутаторе, как показано на рисунке 10. Контроллер обменивается информацией с агентами, работающими на подключенных кэшах. Каждый агент проверяет состояние локальной сущности Varnish, которая обрабатывает http-запросы от конечных клиентов.
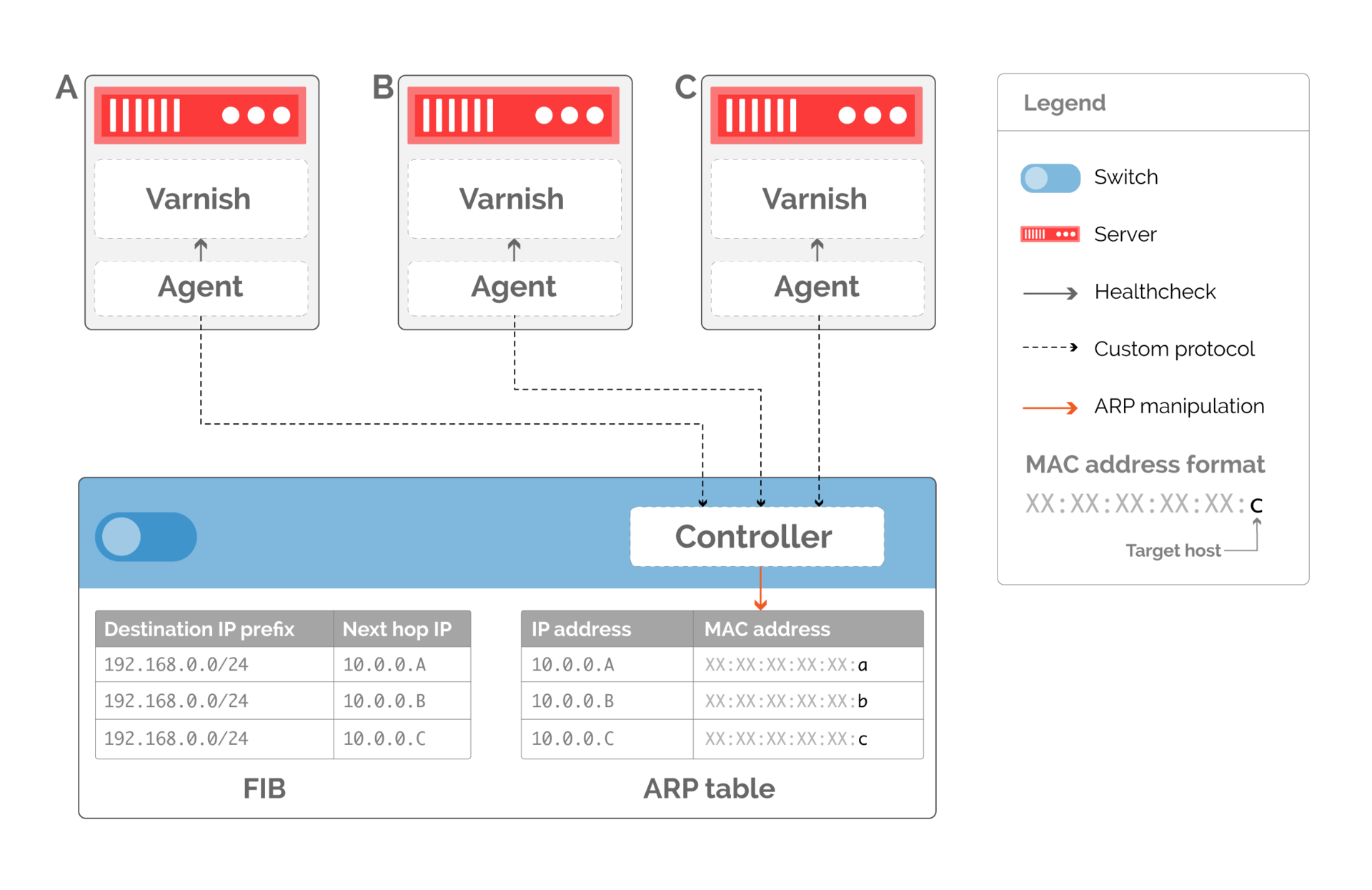
Рис. 10. Кастомный протокол маршрутизации, основанный на изменении ARP-таблицы. Таблица маршрутизации остается постоянной, а ARP-таблица изменяется, чтобы указывать на доступные серверы - Глубина детализации, с которой мы можем балансировать трафик, теперь напрямую связана с количеством следующих участков сети в таблице маршрутизации. Как показано на рис. 10, если мы удалим сервер, обслуживающий трафик, нам нужно переписать ARP-запись, чтобы она указывала на доступный сервер, потенциально удваивая трафик на другой сервер. Чтобы избежать этого, мы можем создать несколько следующих участков сети, как показано на рис. 11. Если у нас будет два виртуальных следующих участка сети на каждый сервер, то доступные серверы будут иметь равное количество ARP-записей, указывающих на них, когда сервер B перестает работать.
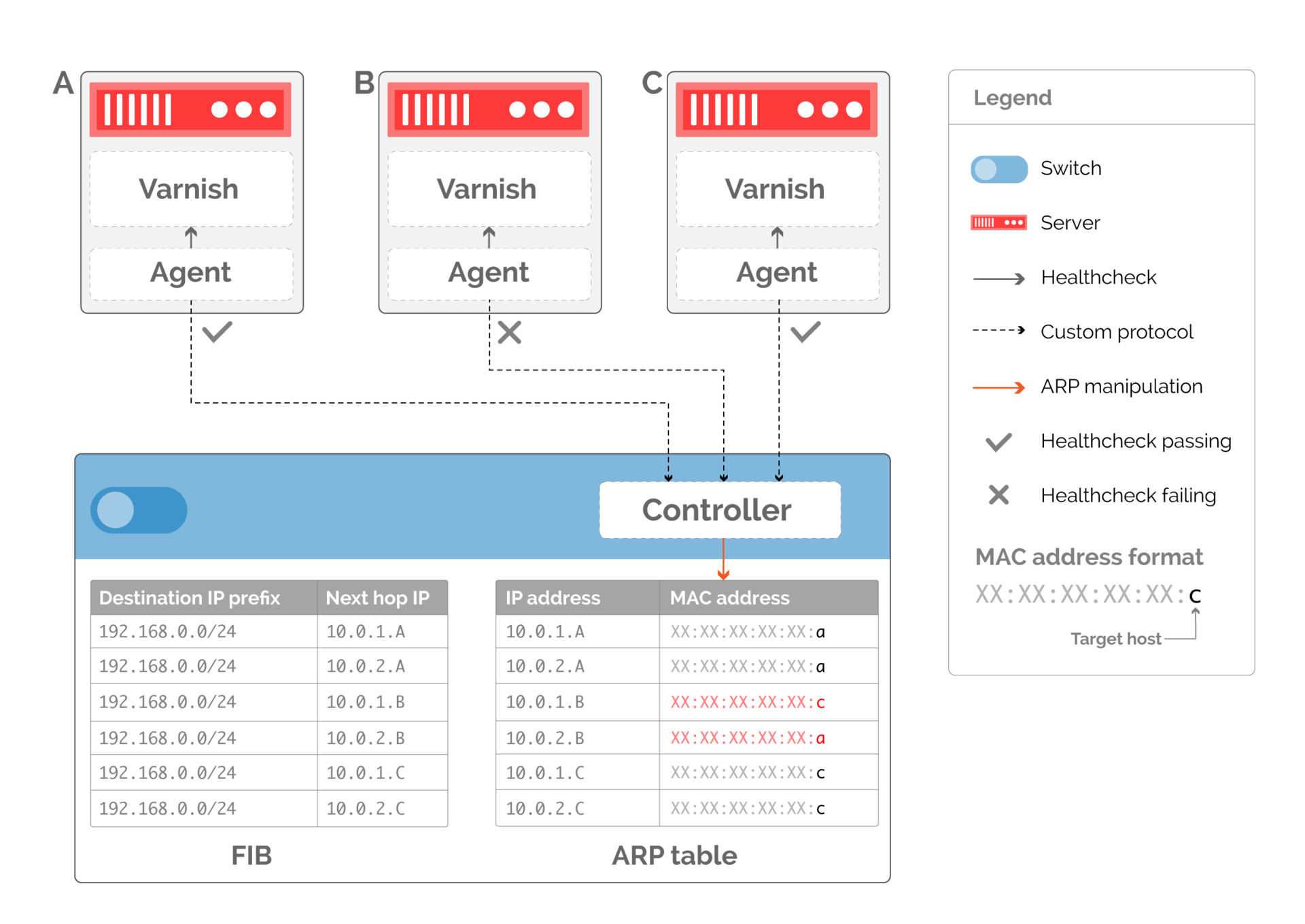
Рис. 11. Дополнительные следующие участки сети обеспечивают равномерное распределение трафика, когда сервер B перестает работать
Faild: обходной слой
«Эластичный» ЕСМР все равно не может обеспечить аккуратный вывод сервера из числа работающих. Вернемся к рис. 11. Если хост B выходит из строя, это приведет к тому, что трафик пойдет ко всем оставшимся серверам. Все существующие соединения будут при этом сброшены.
Считается, что это неизбежно, и с этим стоит смириться, поскольку это вызвано редкими явлениями выхода из строя аппаратной части или проблемами с ПО. Однако на практике серверы часто выводятся из «продакшна», чтобы провести апгрейд ПО. Сбрасывание соединений из-за этого вызывает не только временную проблему с трафиком. Это мешает быстро внедрять новое ПО, поскольку каждый апгрейд будет приводить к проблемам.
Правильная обработка отказа не может быть внедрена только на коммутаторе, поскольку он не «знает», какие потоки являются активными в любой момент времени. Наше решение заключалось в том, чтобы распределить отслеживание состояния между контроллером и хостами. Для этого мы и разработали собственное решение Faild.
Первый шаг к аккуратному выводу сервера из «продакшна» — сигнализировать об этом. Хотя наши предыдущие примеры предполагали, что у интерфейса хоста есть только один MAC-адрес, на практике такого ограничения нет. Мы можем внести в ARP-таблицу на коммутаторе не только информацию о ранее работавшем хосте, но и о новом (рис. 12).
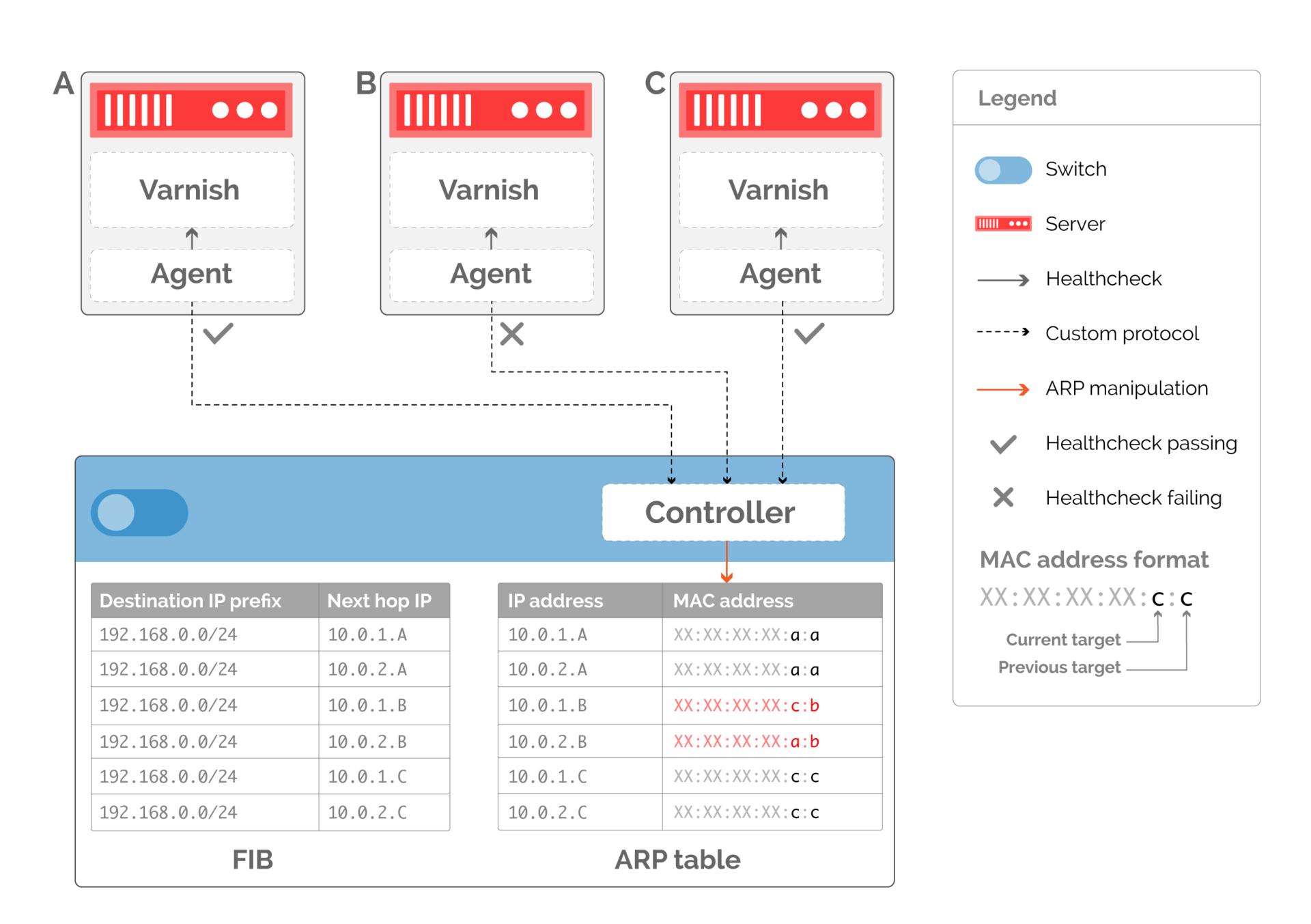
Рис. 12. Кодирование хостов для замены неработающего через MAC-адреса
Теперь, когда мы передали информацию о доступности на коммутатор, мы можем делегировать решение о балансировке серверам. Это не только избавляет от необходимости отслеживать состояние потоков в сети. Это также переносит вычислительную нагрузку на серверы, которых в точке присутствия больше, чем коммутаторов.
Эта нагрузка, связанная с вычислениями, уменьшается через внедрение обработки на принимающей стороне в качестве отдельного модуля ядра. Он эффективно обрабатывает поступающие пакеты в соответствие с MAC-адресом места назначения (см. рис. 13).
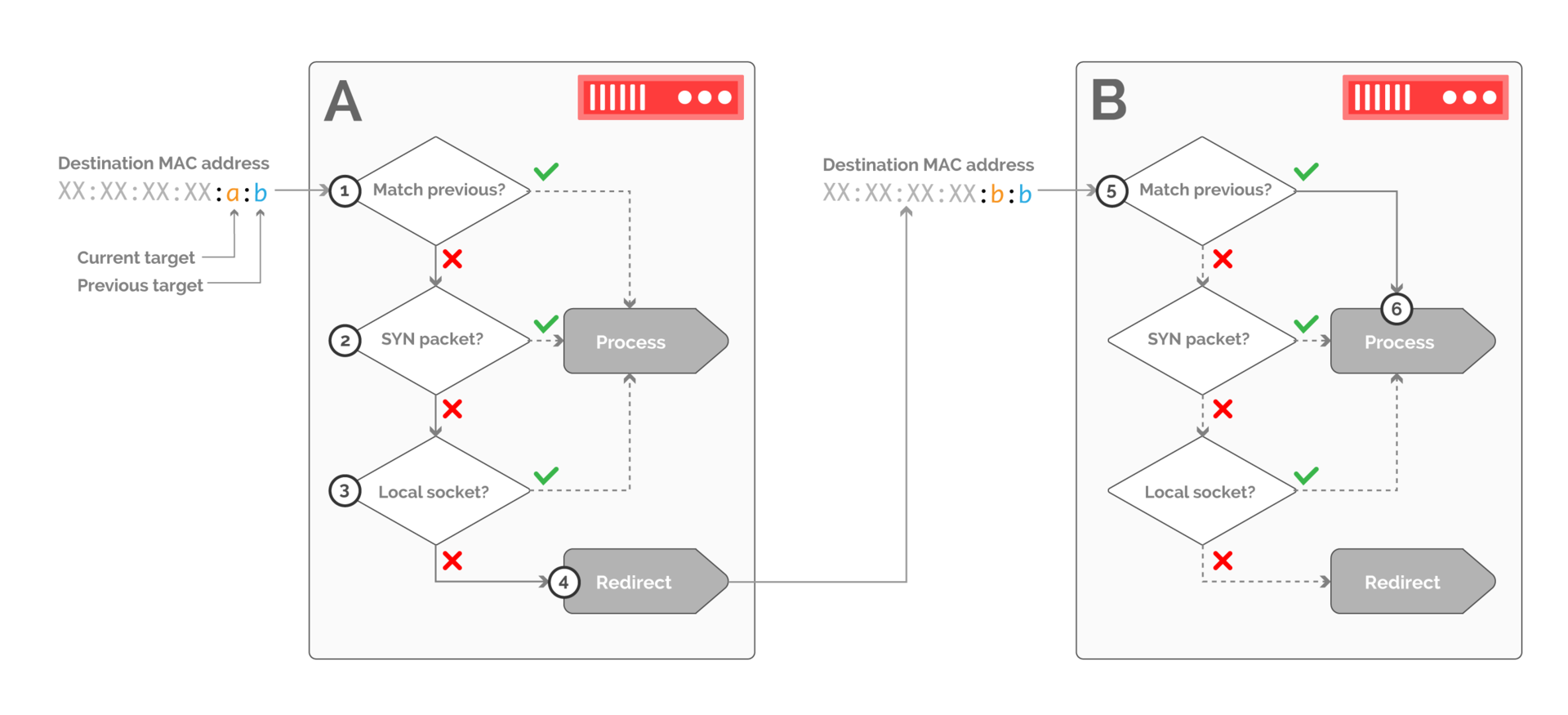
Рис. 13. Пример обработки пакетов на принимающей стороне при переходе трафика с хоста В на хост А. Пакеты фильтруются на хосте А и принимаются только если они принадлежат новому соединению или соответствуют локальному TCP-сокету
Модуль ядра получающего хоста должен сначала определить, соответствует ли предыдущее место назначения этому хосту. Если да, то обработка передается на локальный сетевой стек. Если нет — надо убедиться, что пакет принадлежит новому соединению (через флаг SYN в заголовке TCP — шаг 2), или существующему соединению, что может быть осуществлено через поиск в таблице сокетов (шаг 3).
Если никакие из этих условий не выполнены, пакет перенаправляется на предыдущее место назначения через переписывание MAC-заголовка.
Аналогичная логика применяется и на хосте В (шаг 5). В этом случае хост, указанный как предыдущее место назначения, соответствует хосту, поэтому пакет принимается.
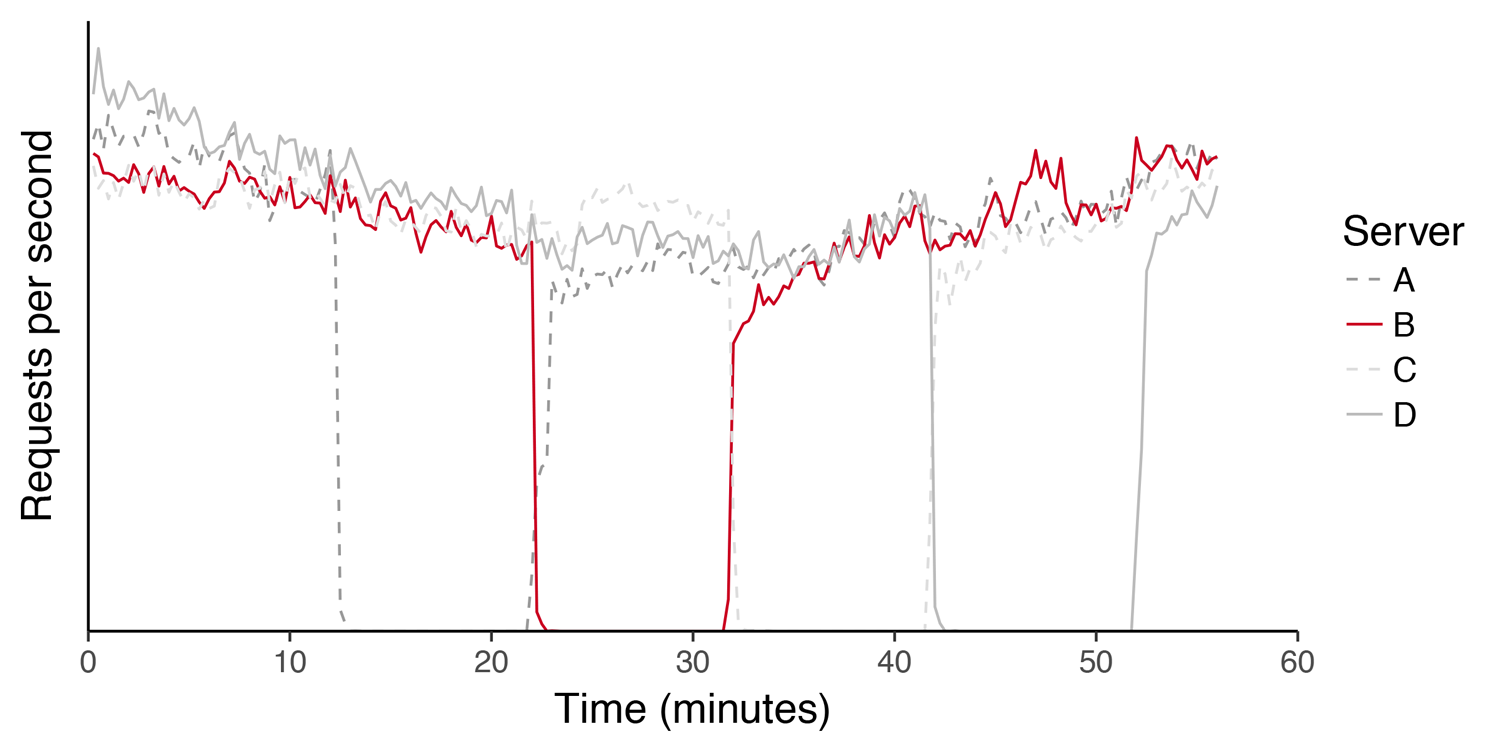
Рис. 14. График нагрузки (запросы в секунду) на кластере серверов во время последовательного апгрейда ядра. Хосты покидают и возвращаются в «продакшн» без влияния на сервис
Внедрение Faild за последние 3 года повлияло не только на работу с трафиком. Снизив негативное влияние от необходимых работ на серверах, Faild позволил нам разворачивать новое ПО быстрее, без влияния на клиентов, а также и ускорить нашу реакцию на обнаружение уязвимостей.
Итоги
Fastly достигла объема, измеряющегося миллионами запросов в секунду, с тех пор, как в 2013 году было внедрено решение Faild. Значительный вклад в это внесла «эластичная» балансировка, сокращающая стоимость переконфигурации сети без потерь для пользователей.
Через комбинирование ECMP, переписывание ARP и манипуляции с ядром, этот рост удалось поддержать кастомными решениями, не приобретая ничего сложнее обычных коммутаторов.
