Тонкости R. Как минута час экономит
Довольно часто enterprise задачи по обработке данных затрагивают данные, сопровождаемые временной меткой. В R такие метки, обычно хранятся как класс POSIXct. Выбор методов работы с таким типом данных по принципу аналогии может привести к большому разочарованию и убеждению о крайней медлительности R. Хотя если взглянуть на эту чуть более пристально, то оказывается, что дело не совсем в R, а в руках и голове.
Ниже затрону пару кейсов, которые встретились в этом месяце и возможные варианты их решения. В ходе решения появляются весьма интересные вопросы. Заодно упомяну инструменты, которые оказываются крайне полезными для решения подобных задачек. Практика показала, что об их существовании знают немногие.
Кейс №1. Обработка событийных данных ИТ системы
С точки зрения бизнеса задача «как бы» тривиальная. Необходимо в доходчивом виде отобразить событийный поток распределенной системы за определённый временной промежуток. А потом обеспечить разнообразную критериальную «нарезку». В качестве источника данных выступают подсистемы логирования компонентов ИТ системы.
С позиции удобства восприятия для высокоуровневого обзора подобных данных оптимально подходит представление в виде «тепловой карты». Вот пример сгенерированного графика.

Изобретать велосипед смысла нет, был использован подход, описанный в статье «Bob Rudis, Making Faceted Heatmaps with ggplot2». Собственно говоря, поскольку данные по своей сути идентичны и представляют собой временную метку с соответствующим набором метрик, далее я буду апеллировать к этой статье и публично опубликованным данным, дабы не раскрывать частную информацию.
Нюанс №1
заключается в том, что источников поступления событий несколько и находятся они в разных часовых поясах. Время в исходных данных измеряется в UTC, а аналитику надо привязывать к рабочему циклу по времени локального часового пояса. Исходные данные выглядят следующим образом:
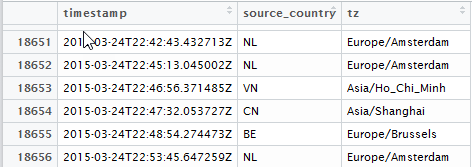
где timestamp — UTC время события в формате ISO8601 в текстовом виде, tz — маркер тайм-зоны в которой это событие произошло.
Нюанс №2
заключается в том, что используемый в статье подход dplyr::do() является устаревшим с момента выхода пакета purrr. Комментарий автора: dplyr: do () is now basically deprecated in favour of the purrr approach. А это значит, что код надо бы адаптировать под современный подход.
Сразу переходим к purrr, пропускаем подходы, связанные с циклами for и враппером Vectorize, как неэффективные. К сожалению, попытки применить «в лоб» векторизацию к POSIXct векторам значений с различным timezone невозможно. Ответ находится в результате пристального взгляда на вектор POSIXct значений функцией dput. Timezone является атрибутом вектора, но не отдельного элемента!
По этой причине применение функционального подхода map к POSIXct переменной методом поэлементной обработки дает удручающий результат: на выборке в 20 тыс записей время процессинга составляет почти 20 секунд. При этом используются свойства векторизации функции ymd_hms(), в противном случае результат был бы ещё хуже.
attacks_raw <- read_csv("./data/eventlog.csv", col_types="ccc", progress=interactive()) %>%
slice(1:20000)
attacks <- attacks_raw %>%
# mutate(rt=map(.$timestamp, ~ ymd_hms(.x, quiet=FALSE))) %>% # с этим подходом ~ в 8 раз медленнее
mutate(rt=ymd_hms(timestamp, quiet=FALSE)) %>%
mutate(hour=as.numeric(map2(.$rt, .$tz, ~ format(.x, "%H", tz=.y)))) %>%
mutate(wkday_text=map2(.$rt, .$tz, ~ weekdays(as.Date(.x, tz=.y)))) %>%
unnest(rt, hour, wkday_text)Пытаемся выяснить причину такого поведения. Для этого воспользуемся инструментом профилирования кода. Заинтересованные могут в качестве старта посмотреть детали на сайте Profvis: Profvis — Interactive Visualizations for Profiling R Code, а также ознакомиться с видео:
- 2016 Shiny Developer Conference Videos: Profiling and performance — Winston Chang;
- rconf2017: Understand Code Performance with the profiler — Winston Chang.
Результат профилирования выглядит следующим образом:
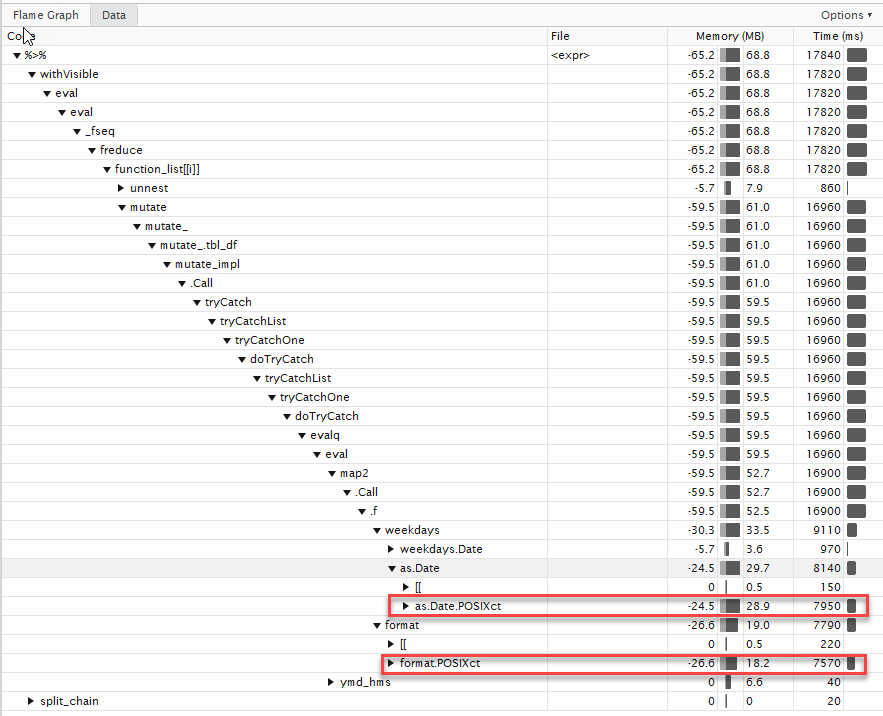
Видно, что основное время уходит на многократные преобразования POSIXct, POSIXlt. Этому есть определённые объяснения, с отдельными позициями можно ознакомиться здесь: «Why are lubridate functions so slow when compared with as.POSIXct?».
Но для нас основных выводов несколько:
- максимально вытащить все штучные действия с датами за пределы функции;
- использовать векторизацию для значений
POSIXct, обладающих одинаковым tz (т.е. мы не будем вынуждены передавать time-zone как параметр); - использовать особенности пакета
lubridate, когда при соблюдении определённых форматов текста конвертацияchr->POSIXctосуществляется не базовыми функциями R, а многократно оптимизированными (см. пакетfasttime). - вместо
dplyr::doиспользуемpurrr::map2.
Незначительно модифицировав код получаем ускорение почти в 25 раз. (при прогоне на большем массиве данных выигрыш получается почти в 100 раз).

Код выглядит следующим образом:
attacks_raw <- read_csv("./data/eventlog.csv", col_types="ccc", progress=interactive()) %>%
slice(1:20000)
parseDFDayParts <- function(df, tz) {
real_times <- ymd_hms(df$timestamp, tz=tz, quiet=TRUE)
tibble(wkday=weekdays(as.Date(real_times, tz=tz)),
hour=as.numeric(format(real_times, "%H", tz=tz)))
}
attacks <- attacks_raw %>%
group_by(tz) %>%
nest() %>%
mutate(res=map2(data, tz, parseDFDayParts)) %>%
unnest()Одной из ключевых «фишек» является группировка по time-zone с последующей векторизацией обработки.
Кейс №2. Скользящее окно по временным данным
Бизнес-кейс также является тривиальным. Есть массив временных данных, характеризующих время отклика на действия пользователя.

Необходимо посчитать APDEX индекс для оценки удовлетворённости пользователей работой приложения.

# Разбиваем, все выполненные операции на 3 категории:
# N – общее количество произведённых операций
# NS - количество итераций, которые выполнены за менее чем целевое время [0 – Т]
# NF – количество операция, которые выполнены за (Т – 4Т]
# (т.е от целевого времени до целевого времени умноженного на 4)
# Индекс APDEX = (NS + NF/2)/N.В качестве стартовой точки используем ужасающие результаты подсчета метрики по скользящему окну средствами базового R. Для выборки в 2000 записей время расчёта составляет почти 2 минуты!
apdexf <- function(respw, T_agreed = 1.2) {
which(0 < respw$response_time & respw$response_time < T_agreed)
apdex_N <- length(respw$response_time) #APDEX_total
apdex_NS <- length(which(respw$response_time < T_agreed)) # APDEX_satisfied
apdex_NF <- length(which(T_agreed < respw$response_time & respw$response_time < 4*T_agreed)) # APDEX_tolerated F=4T
apdex <- (apdex_NS + apdex_NF/2)/apdex_N
return(apdex)
}
dt = dminutes(15)
df.apdex = data.frame(timestamp=numeric(0), apdex=numeric(0))
for(t in seq(from = start_time, by = dt, length.out = floor(as.duration(end_time - start_time)/dt))){
respw <- subset(mydata, t <= timestamp & timestamp < t+dt)
df.apdex <- rbind(df.apdex, data.frame(timestamp = t, apdex = apdexf(respw)))
}Пропускаем все промежуточные шаги, сразу отмечаем места для оптимизации.
- Переход на функциональную обработку.
- Вынос всех константных вычислений за пределы функции, вызываемой в цикле. В частности, статус
satisfied\tolerated\frustratedявляется только функцией времени отклика, но не времени измерения или окна расчёта — на вынос. - Крайне важный момент — непродуктивное копирование объектов!!! Несмотря на то, что
data.frameпередается в функцию по ссылке, операции сdata.frameвнутри функции могут приводить к созданию дубликата объекта, а это есть значительные накладные расходы. Оптимизация операций с использованием особенностей методовdplyrпозволяет минимизировать количество копирования данных внутри функции, что существенно увеличивает производительность. С особенности методовdplyr, а также средствами контроля объектов, в частности, функциейdplyr::changes()можно ознакомиться в статье «Data frame performance». Ровно поэтому модель отдельных колонок со статусом времени отклика гораздо предпочтительнее одной колонки с типом статуса времени отклика. - Проводим расчёт диапазона временных окон один раз при старте вычислений с применением свойства векторизации. Расчет
POSIXct+ сдвижка по времени — весьма накладная процедура, чтобы выполнять её внутри цикла. - Используем оптимизированные функции
dplyrс внешней параметризацией. Подобное ухищрение позволяет сократить затраты на вычисления и используемую память, но несколько усложняет синтаксис за счёт возврата от NSE [Non-Standard evaluation] к SE [Standard evaluation]. (filter-->filter_). В качестве вводной информации про SE\NSE можно ознакомиться здесь: «Non-standard evaluation»
apdexf2 <- function(df, window_start, cur_time) {
t_df <- df %>%
filter_(lazyeval::interp(~ timestamp>var, var=as.name("window_start"))) %>%
filter_(lazyeval::interp(~ timestamp<=var, var=as.name("cur_time")))
# так быстрее на порядок, чем summarise
s <- sum(t_df$satisfied)
t <- sum(t_df$tolerated)
f <- sum(t_df$frustrated)
(s + t/2)/(s + t + f)
}
t_agreed <- 0.7
mydata %<>%
mutate(satisfied=if_else(t_resp <= t_agreed, 1, 0)) %>%
mutate(frustrated=if_else(t_resp > 4*t_agreed, 1, 0)) %>%
mutate(tolerated=1-satisfied-frustrated) %>%
mutate(window_start=timestamp-minutes(15))
time_df <- mydata %>%
select(window_start, timestamp)
mydata %<>%
select(timestamp, satisfied, tolerated, frustrated)
mydata$apdex <- map2(time_df$window_start, time_df$timestamp,
~ apdexf2(mydata, .x, .y)) %>%
unlist()Проведя подобную оптимизацию получаем время обработки ~ 3.5 сек. Ускорение почти в 35 раз и достигнуто оно просто незначительным переписыванием кода!

Но и это не предел. Приведённая реализация осуществляет расчёт скользящим окном для по каждой отдельной метрике. Измерения же могут приходить в произвольные моменты времени. Но на практике такая точность избыточна, вполне достаточно загрублять вычисление до 1–5 минут групповых интервалов. А это значит, что объем вычислений может уменьшиться ещё раз в 10, с пропорциональным сокращением времени вычисления.
В заключение хочу отметить, что существующий на настоящий момент набор пакетов и инструментов действительно позволяет писать на R компактно и быстро. В случае, когда и этого будет недостаточно, есть ещё резерв в виде Rcpp — написания отдельных функций на C++.
Предыдущий пост: «R в enterprise задачах. Хитрости и трюки»
Комментарии (2)
1 марта 2017 в 10:02
0↑
↓
Илья, упоминается пакет Шайни. Я правильно понимаю, что у тебя это основное средство итоговой визуализации — насколько он оптимален среди других инструментов? Можешь ли в двух словах дать оценку его? i_shutov
i_shutov
1 марта 2017 в 10:54 (комментарий был изменён)
0↑
↓
Shiny — это одноименный пакет + портал на node.js. Он обеспечивает бесшовную интеграцию с R. Продвигается RStudio как основной инструмент для потребителей аналитики. Сейчас входит в RStudio Connect.
Оценка в 2 слова — «очень удобно».- Лично я никаких иных бесплатных универсальных инструментов для создания аналитических порталов с минимальным веб программированием найти не смог. Искал долго. PowerBI тестировали давно, но отложили за сильной сыростью и недофункциональностью. Возвращаться сейчас к нему нет никаких мотивов.
А на какой инструмент посоветуете взглянуть?
