[Перевод] Анализ TSDB в Prometheus 2

База данных временных рядов (TSDB, time series database) в Prometheus 2 — это отличный пример инженерного решения, которое предлагает серьёзные улучшения в сравнении с хранилищем v2 в Prometheus 1 в плане скорости накопления данных и выполнения запросов, эффективности использования ресурсов. Мы внедряли Prometheus 2 в Percona Monitoring and Management (PMM), и у меня была возможность разобраться с производительностью Prometheus 2 TSDB. В этой статье я расскажу о результатах этих наблюдений.
Средняя рабочая нагрузка Prometheus
Для тех, кто привык иметь дело с базами данных основного назначения, обычная рабочая нагрузка Prometheus довольно любопытна. Скорость накопления данных стремится к стабильной величине: обычно сервисы, которые вы мониторите, посылают примерно одинаковое количество метрик, и инфраструктура меняется относительно медленно.
Запросы информации могут приходить из разных источников. Некоторые из них, например алерты, также стремятся к стабильной и предсказуемой величине. Другие, такие как пользовательские запросы, могут вызывать всплески, хотя, это не характерно для большей части нагрузки.
Тест нагрузки
В ходе тестирования я сконцентрировался на способности накапливать данные. Я развернул Prometheus 2.3.2, скомпилированный с помощью Go 1.10.1 (как часть PMM 1.14) на сервисе Linode, используя этот скрипт: StackScript. Для максимально реалистичного генерирования нагрузки, при помощи этого StackScript я запустил несколько MySQL-нод с реальной нагрузкой (Sysbench TPC-C Test), каждая из которых эмулировала 10 нод Linux/MySQL.
Все нижеследующие тесты проводились на сервере Linode с восемью виртуальными ядрами и 32 Гбайт памяти, на котором запущены 20 нагрузочных симуляций мониторинга двухсот инстансов MySQL. Или, в терминах Prometheus, 800 таргетов (targets), 440 сборов (scrapes) в секунду, 380 тысяч записей (samples) в секунду и 1,7 млн активных временных рядов.
Дизайн
Обычный подход традиционных баз данных, в том числе тот, что использовал Prometheus 1.x, заключается в лимите памяти. Если его недостаточно, чтобы выдержать нагрузку, вы столкнётесь с большими задержками, и какие-то запросы не будут выполнены. Использование памяти в Prometheus 2 конфигурируется через ключ storage.tsdb.min-block-duration, который определяет, как долго записи будут храниться в памяти перед сбросом на диск (по умолчанию это 2 часа). Количество необходимой памяти будет зависеть от количества временных рядов, ярлыков (labels) и интенсивности сбора данных (scrapes) в сумме с чистым входящим потоком. В плане дискового пространства Prometheus стремится использовать по 3 байта на запись (sample). С другой стороны, требования к памяти куда выше.
Несмотря на то, что есть возможность конфигурировать размер блока, не рекомендуется настраивать его вручную, поэтому вы поставлены перед необходимостью дать Prometheus столько памяти, сколько он попросит для вашей нагрузки.
Если памяти будет недостаточно, чтобы поддерживать входящий поток метрик, Prometheus упадёт с out of memory или до него доберётся OOM killer.
Добавить swap, чтобы оттянуть момент падения, когда у Prometheus заканчивается память, не особо помогает, потому что использование этой функции вызывает взрывное потребление памяти. Я думаю, что дело в Go, его garbage collector и в том, как он работает со swap.
Другим интересным подходом выглядит настройка сброса head block на диск в определённое время, вместо того чтобы отсчитывать его со времени старта процесса.
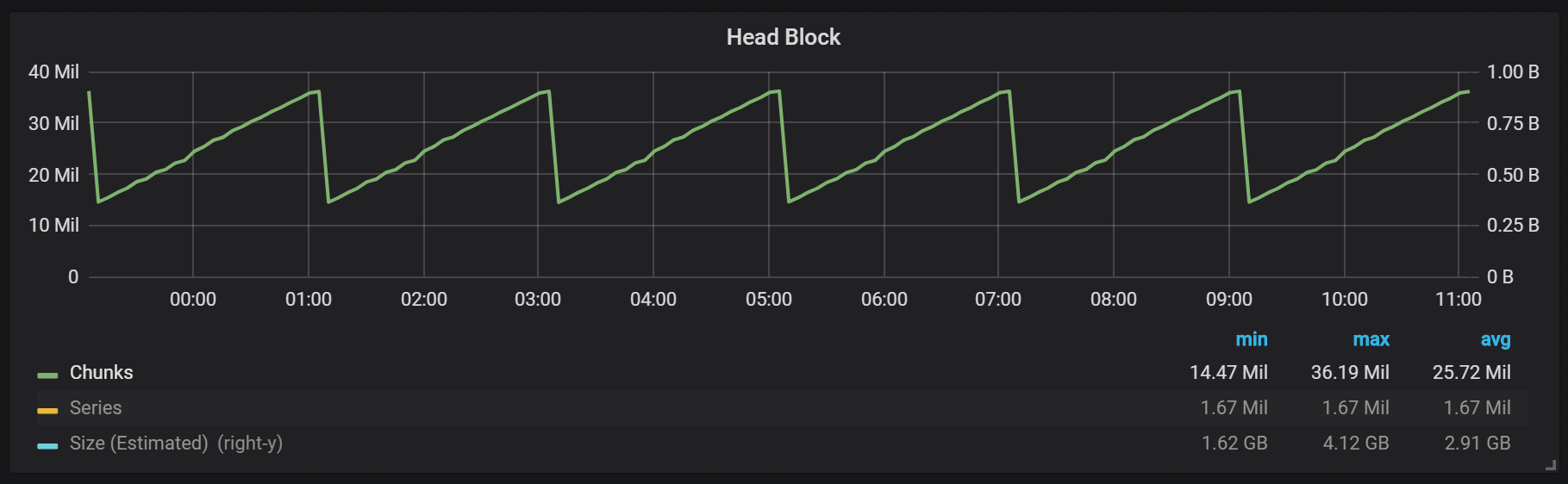
Как вы можете видеть из графика, сбросы на диск происходят каждые два часа. Если вы поменяете параметр min-block-duration на один час, то эти сбросы будут происходить каждый час, начиная через полчаса.
Если вы хотите использовать этот и другие графики в вашей инсталляции Prometheus, можете использовать этот дашборд. Он был разработан для PMM, но, с небольшими изменениями, подходит к любой инсталляции Prometheus.
У нас есть активный блок, называемый head block, который хранится в памяти; блоки же с более старыми данными доступны через mmap(). Это убирает необходимость конфигурировать кеш отдельно, но также означает, что вам нужно оставлять достаточно места для кеша операционной системы, если вы хотите делать запросы к данным старше тех, которые вмещает head block.
А ещё это значит, что потребление Prometheus виртуальной памяти будет выглядеть довольно высоким, о чём не стоит беспокоиться.

Ещё один интересный момент дизайна — использование WAL (write ahead log). Как видно из документации по хранилищу, Prometheus использует WAL для избежания потерь при падениях. Конкретные механизмы гарантии живучести данных, к сожалению, недостаточно документированы. Версия Prometheus 2.3.2 сбрасывает WAL на диск каждые 10 секунд, и этот параметр не конфигурируется пользователем.
Уплотнения (Compactions)
Prometheus TSDB спроектирована по образу LSM-хранилища (Log Structured merge — журнально-структурированное дерево со слиянием): head block сбрасывается периодически на диск, в то же время механизм уплотнения объединяет несколько блоков вместе для избежания сканирования слишком большого количества блоков при запросах. Здесь видно количество блоков, которые я наблюдал на тестовой системе после суток нагрузки.
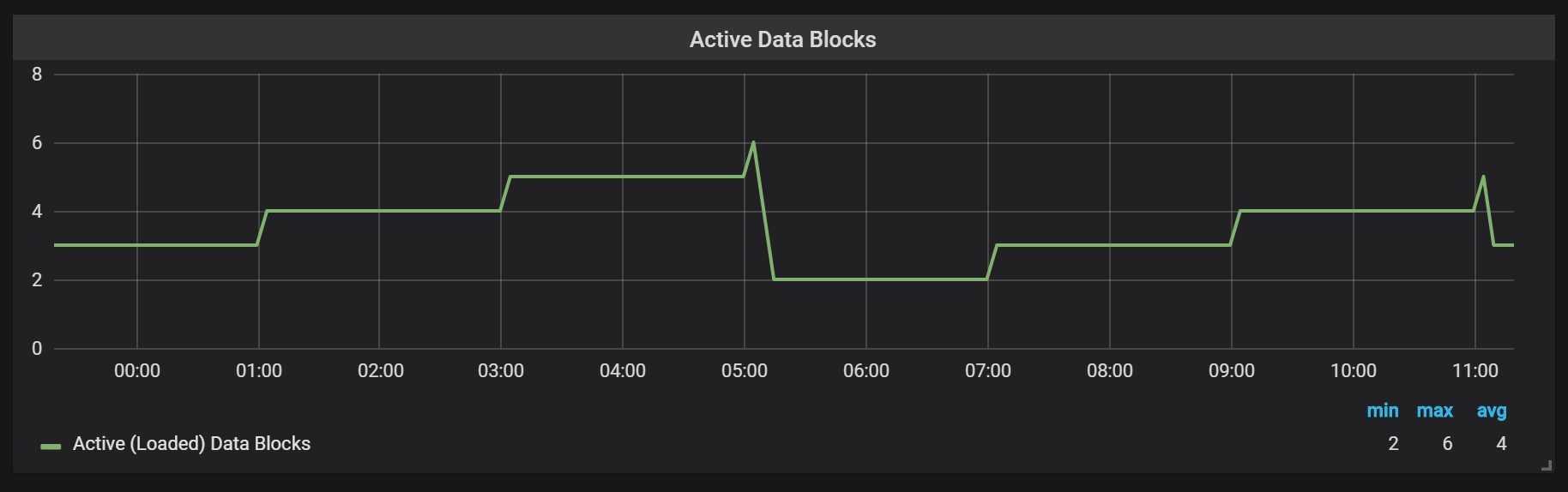
Если вы хотите узнать больше о хранилище, вы можете изучить файл meta.json, в котором есть информация об имеющихся блоках и о том, как они появились.
{
"ulid": "01CPZDPD1D9R019JS87TPV5MPE",
"minTime": 1536472800000,
"maxTime": 1536494400000,
"stats": {
"numSamples": 8292128378,
"numSeries": 1673622,
"numChunks": 69528220
},
"compaction": {
"level": 2,
"sources": [
"01CPYRY9MS465Y5ETM3SXFBV7X",
"01CPYZT0WRJ1JB1P0DP80VY5KJ",
"01CPZ6NR4Q3PDP3E57HEH760XS"
],
"parents": [
{
"ulid": "01CPYRY9MS465Y5ETM3SXFBV7X",
"minTime": 1536472800000,
"maxTime": 1536480000000
},
{
"ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ",
"minTime": 1536480000000,
"maxTime": 1536487200000
},
{
"ulid": "01CPZ6NR4Q3PDP3E57HEH760XS",
"minTime": 1536487200000,
"maxTime": 1536494400000
}
]
},
"version": 1
}
Уплотнения в Prometheus привязаны ко времени сброса head block на диск. В этот момент может проводиться несколько таких операций.
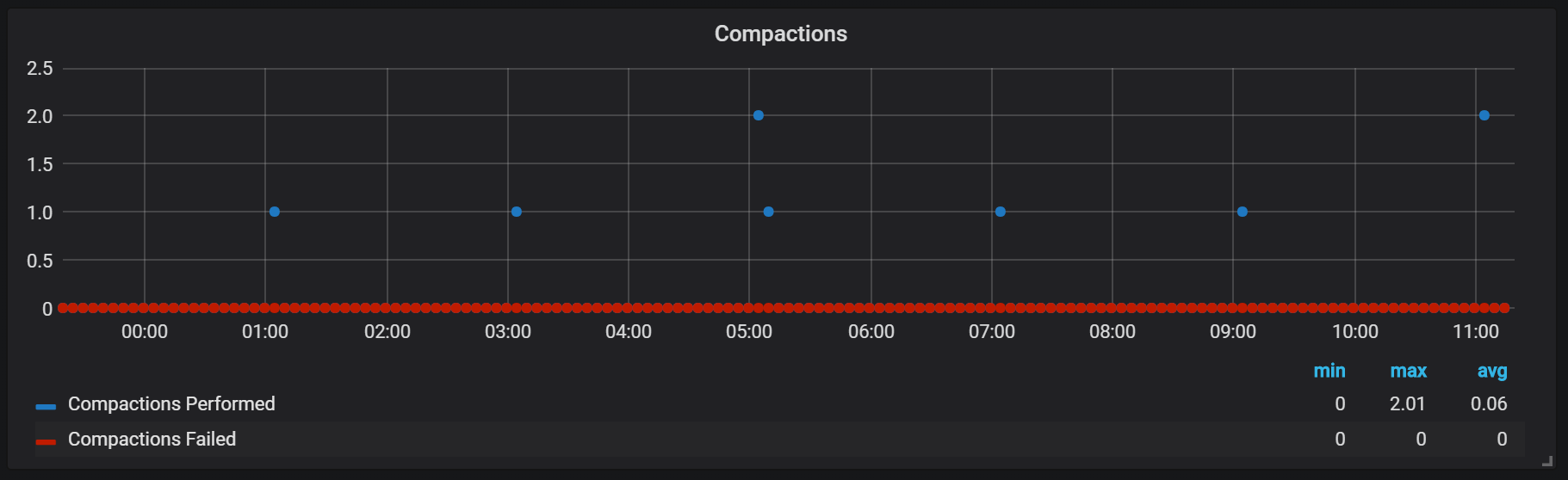
Судя по всему, уплотнения никак не ограничены и могут вызывать большие скачки дискового I/O во время выполнения.

Скачки загрузки CPU

Разумеется, это довольно негативно влияет на скорость работы системы, а также является серьёзным вызовом для LSM-хранилищ: как делать уплотнения для поддержки высокой скорости запросов и при этом не вызывать слишком сильного оверхеда?
Использование памяти в процессе уплотнений тоже выглядит довольно любопытно.

Мы можем видеть, как после уплотнения большая часть памяти меняет состояние с Cached на Free: значит, потенциально ценная информация была оттуда убрана. Любопытно, используется ли тут fadvice() или какая-то ещё техника минимизации, или это вызвано тем, что кеш был освобождён от блоков, уничтоженных при уплотнении?
Восстановление после сбоя
Восстановление после сбоев занимает время, и это обосновано. Для входящего потока в миллион записей в секунду мне пришлось ждать около 25 минут, пока производилось восстановление с учётом SSD-диска.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)"
level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)"
level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))"
level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090
level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..."
level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R
level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus
level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM
level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0
level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q
level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB
level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363
level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started"
level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
Основная проблема процесса восстановления — высокое потребление памяти. Несмотря на то, что в нормальной ситуации сервер может стабильно работать с таким же объёмом памяти, при падении он может не подняться из-за OOM. Единственное решение, которое я нашёл, это отключить сбор данных, поднять сервер, позволить ему восстановиться и перезагрузить уже со включенным сбором.
Разогрев
Ещё одно поведение, о котором следует помнить в ходе разогрева — соотношение низкой производительности и высокого потребления ресурсов прямо после старта. В ходе некоторых, но не всех стартов я наблюдал серьёзную нагрузку по CPU и памяти.
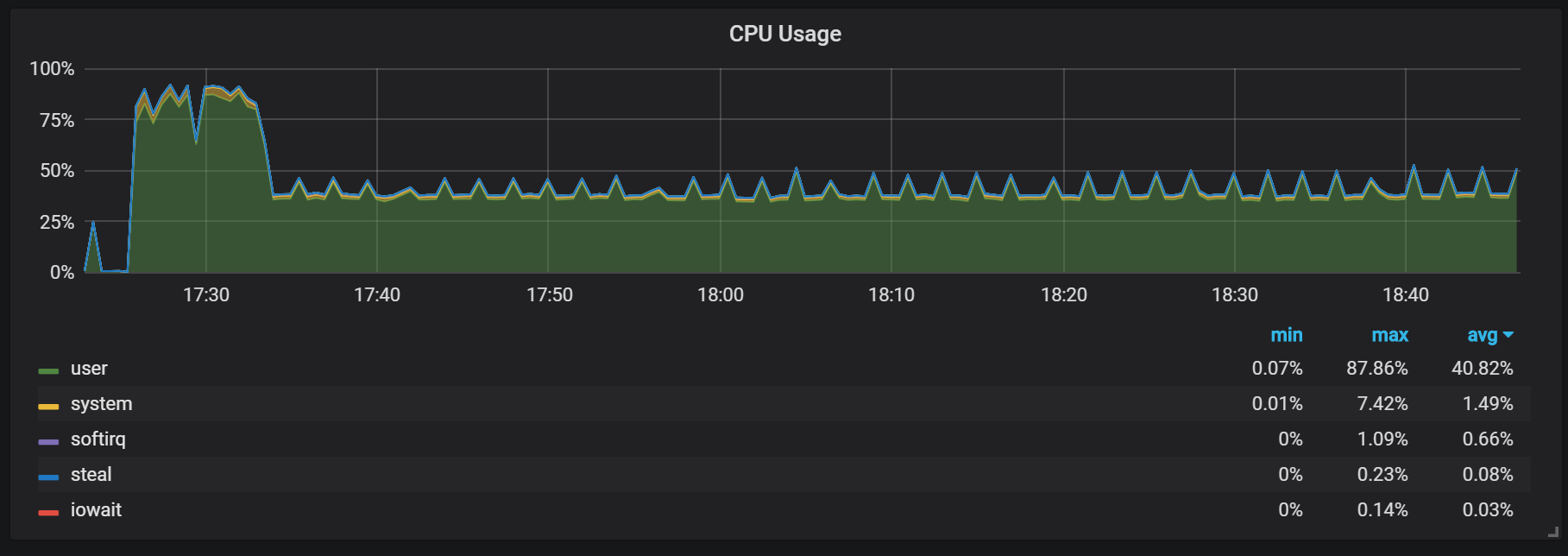

Провалы в использовании памяти говорят о том, что Prometheus не может со старта сконфигурировать все сборы, и какая-то информация оказывается потеряна.
Я не выяснил точные причины высокой нагрузки на процессор и память. Подозреваю что это связано с созданием новых временных рядов в head block с высокой частотой.
Скачки нагрузки на CPU
Помимо уплотнений, которые создают довольно высокую нагрузку по I/O, я заметил серьёзные скачки нагрузки на процессор каждые две минуты. Всплески дольше при высоком входящем потоке и похоже, что они вызваны сборщиком мусора Go, по крайней мере, некоторые ядра полностью загружены.

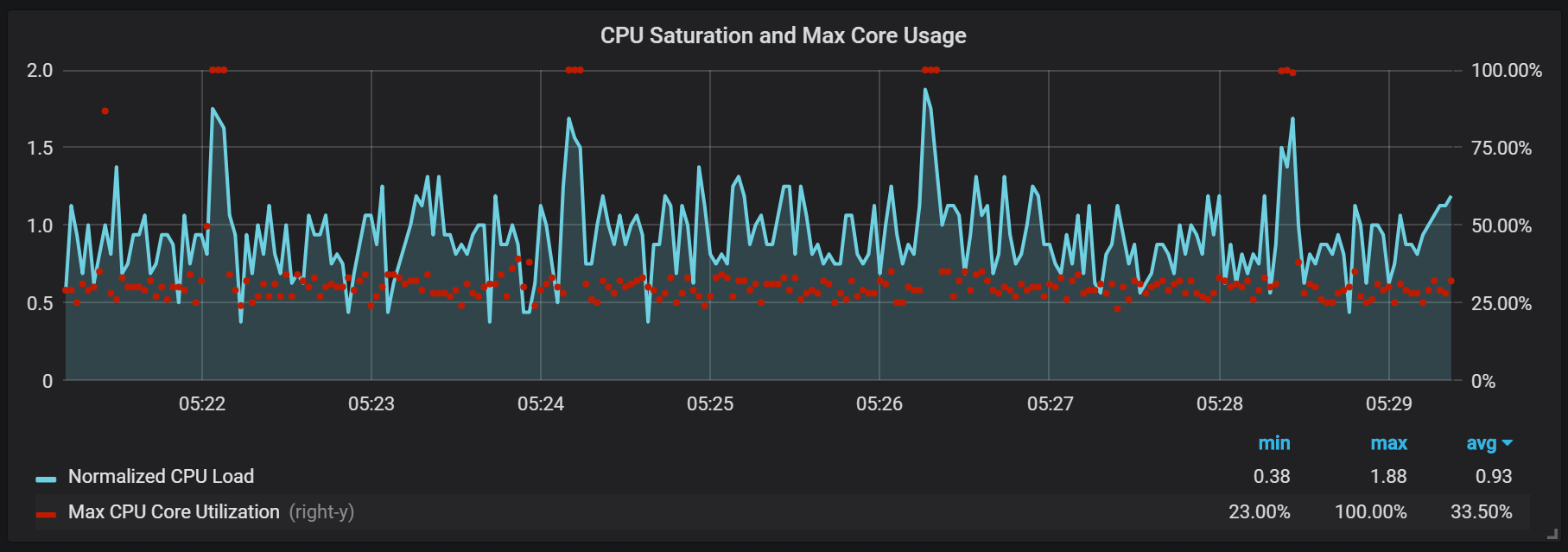
Эти скачки не так уж и несущественны. Похоже, что когда они возникают, внутренняя точка входа и метрики Prometheus становятся недоступны, что вызывает провалы в данных в эти же промежутки времени.
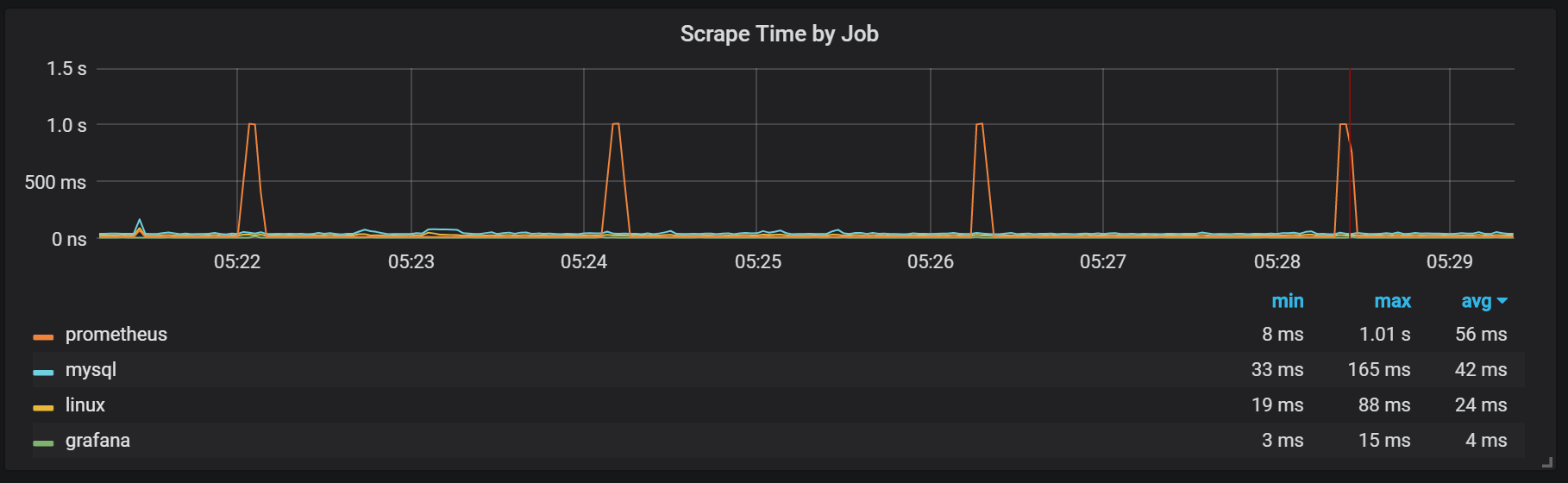
Также можно заметить, что экспортёр Prometheus затыкается на одну секунду.
Мы можем заметить корреляции с уборкой мусора (GC).

Заключение
TSDB в Prometheus 2 действует быстро, способна справляться с миллионами временных рядов и в то же время с тысячами записей, совершаемых в секунду, используя довольно скромное железо. Утилизация CPU и дискового I/O тоже впечатляет. Мой пример показывал до 200 000 метрик в секунду на одно использованное ядро.
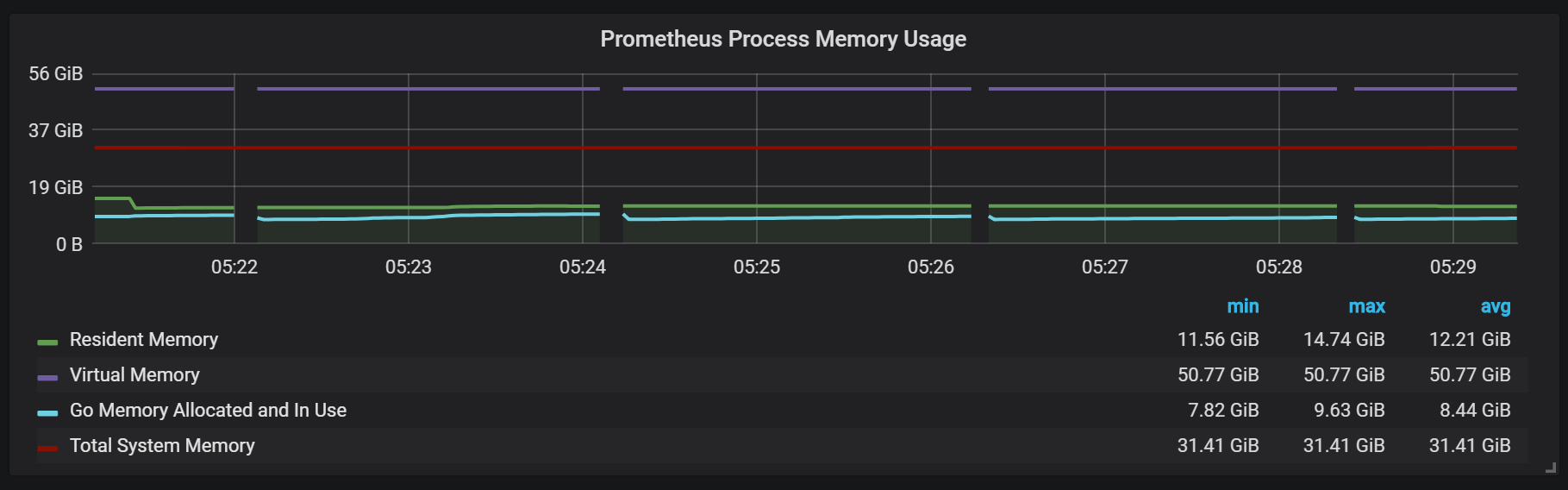
Для планирования расширения надо помнить о достаточных объёмах памяти, и это должна быть реальная память. Объём используемой памяти, который я наблюдал, составлял около 5 Гбайт на 100 000 записей в секунду входящего потока, что давало в сумме с кешем операционной системы около 8 Гбайт занятой памяти.
Разумеется, ещё предстоит немало работы по укрощению всплесков CPU и дискового I/O, и это неудивительно, учитывая, насколько ещё молода TSDB Prometheus 2 в сравнении с InnoDB, TokuDB, RocksDB, WiredTiger, но все они имели похожие проблемы в начале жизненного цикла.
