[Из песочницы] Тест конструктора CRM: EAV база данных с 75 млн записей
В статье описана очередная попытка создать систему моделирования произвольной предметной области. Будучи единожды написана, такая система не требует привлечения команды разработки для прикладного программирования под конкретный бизнес произвольного заказчика. В основе продукта лежит EAV база данных, поэтому особое внимание уделено производительности при работе со значительными объемами данных.Кто-то сразу вспомнит эпопею двадцатилетней давности: https://www.simple-talk.com/opinion/opinion-pieces/bad-carma/ (скандально известная универсальная система с единственной таблицей). Нет, мы пойдем немного другим путем.
В нашем случае всё прикладное «программирование» выполняет бизнес-аналитик (а лучше — продвинутый пользователь), просто описывая объекты с их свойствами и связями.
CRM и не толькоКак упомянуто выше, в конструкторе устранена необходимость работать с SQL, поэтому все «ужасные» особенности работы с EAV-моделью остаются за кадром. Пользователь оперирует понятиями «Клиент», «Продукт», «Сотрудник», «Имя», «Цена» и так далее.CRM — очень востребованный продукт, поэтому здесь рассмотрен именно конструктор CRM, хотя конструировать можно все что душе угодно.
Это не «Hello, World!» система. Первая ее версия (фактически — удивительно живучий прототип) работает с 2006 года по сей день в одной из реальных производственных компаний. В настоящее время этот продукт оптимизируется и дорабатывается, готовясь к встрече с серьезным заказчиком.
Оговорки Все описанное здесь — подтверждение концепции, поэтому очень прошу не придираться к мелочам вроде брутального интерфейса, формата дат и прочих косметических вещей. Реализация этих мелочей тривиальна и не влияет на ядро системы и две основные задачи проекта: Прикладное программирование без программирования Работа с большими объемами данных (в масштабе малого и среднего бизнеса) Да, известно, что дьявол прячется в мелочах, и я очень внимательно изучил многие мелочи, в том числе защищая идею перед немилосердными рецензентами черновика этой статьи.База данных EAV Если кому интересна среда, в которой работают приведенные ниже примеры: сервер — Apache 2.2, PHP 5.3, MySQL 5.5. Машина, следует заметить, достаточно слабая: Celeron E3300 @2.5GHz, 2GB RAM (домашний компьютер 5-летней давности). Клиентская часть — обычный Web-браузер.Все данные хранятся в одной таблице, состоящей из пяти полей:
Имя Назначение (тип) Описание id ID (int) Уникальный идентификатор (автоинкрементный) up Parent ID (int) ID родительской записи t Type (int) Тип объекта ord Order (int) Порядок среди равных по подчиненности val Value (string) Значение объекта Определение данных, взаимосвязи и подчиненности хранятся в виде метаданных в той же таблице, где и сами данные.Каждый объект (единица данных) занимает как минимум одну строку таблицы, в которую записаны его системный идентификатор, тип и значение. Значение хранится в виде набора символов, порциями ограниченной длины (в рассматриваемом здесь примере это 127 символов). В случае, когда размера поля Value недостаточен для хранения значения объекта, оставшаяся часть этого значения записывается в подчиненные объекты (строки), пронумерованные по порядку заполнения (в поле Order). Такие строки имеют специальный тип (Type), равный 0, который не описан в метаданных, но активно используется системой.
Метаданные подчинены несуществующему элементу с ID=0; независимые объекты подчинены синтетическому корневому элементу с ID=1.
Метаданные описывают структуру данных, и в соответствии с этой структурой система создает, хранит и обрабатывает объекты данных.
Система понимает основные типы данных, перечисленные ниже, а также позволяет создавать новые произвольные типы данных, наследующие свойства основных типов.
Тип Описание Short Строка символов (длина ограничена максимальным размером поля Value) Button Кнопка (инициирует некое контекстное действие над объектом) Chars Символы (строка символов неограниченной длины) Date Дата File Файл (источник данных) Boolean Логическое значение Memo Многострочный текст (строка, редактируемая в многострочном поле ввода) Number Целое число Report Отчет (описание произвольной выборки данных из системы) Signed Вещественное число Computable Вычисляемое значение Report column Колонка отчета (представления) Все основные типы данных также описаны как метаданные и идентифицируются системой по полю Value (условное обозначение), следовательно, все их условные обозначения жестко прописаны в коде системы. Запись метаданных для определения типа содержит в поле Type идентификатор основного типа (или свой собственный в случае, когда эта запись сама описывает основной тип).Пример описания метаданных и данных в базе: id up t val (комментарий) ord Комментарий 1 1 6 Root 0 Корневой элемент 6 0 6 SHORT 0 Основные (базовые) типы данных 7 0 7 BUTTON 0 8 0 8 CHARS 0 9 0 9 DATE 0 10 0 10 FILE 0 11 0 11 BOOLEAN 0 12 0 12 MEMO 0 13 0 13 NUMBER 0 15 0 15 SIGNED 0 16 0 16 COMPUTABLE 0 17 0 17 REPORT 0 2 0 13 Договор 0 Независимые типы 3 0 8 Заказчик 0 14 0 3 (ссылка на Заказчика) 0 4 0 13 Счет 0 5 0 15 Сумма 0 18 0 9 Дата 0 21 0 8 Продукт 0 22 0 12 Предмет договора 0 23 0 15 Цена 0 24 0 15 С/С 0 19 2 18 (Дата) 1 Реквизиты независимых типов 20 2 22 (Предмет договора) 2 25 2 23 (Цена) 3 26 2 14 (ссылка на Заказчика) 4 28 21 23 (Цена) 5 29 21 24 (С/С — Себестоимость) 6 1181 1 2 1161 (договор) 1 Данные 3561 1181 18 20060602 (дата) 1 3562 1181 22 Проведение работ… 2 3563 1181 23 40000 (сумма) 3 3565 1181 113326 (ссылка на Заказчика) 4 Индексы, построенные для таблицы: PRIMARY (id) t_val (t, val) up_t (up, t) Для высоконагруженных систем следует построить еще один индекс: t_id (t, id) Интерфейс Навигация и управление в системе осуществляются с помощью универсальных форм web-интерфейса: Словарь — список всех зарегистрированных типов Редактирование типов (описание объекта) Список объектов — список объектов выбранного типа Редактирование объекта (реквизитов экземпляра типа) Универсальный отчет — одноклеточная форма, масштабируемая под любой набор данных В Словаре можно просмотреть список всех независимых типов (то есть тех, что не являются реквизитами других типов):

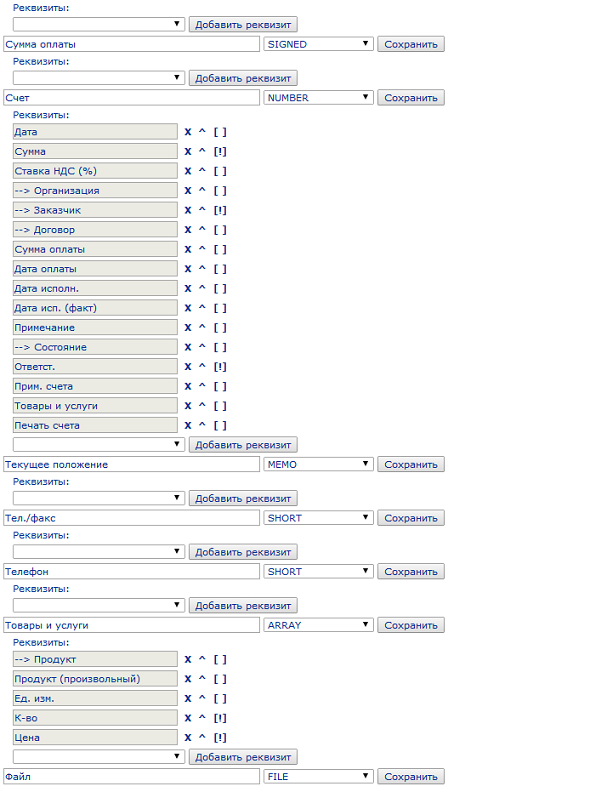
На форме Редактирования типов перечислены все зарегистрированные типы объектов с их реквизитами. Реквизитом может быть любой другой тип или ссылка на объект определенного типа (связь один-ко-многим). На приведенном ниже рисунке для Счета указаны ссылки на Организацию (которая его выставила), Заказчика, Договор и Состояние. Также для счета можно заполнить массив Товары и услуги (описанный ниже на этом же рисунке):
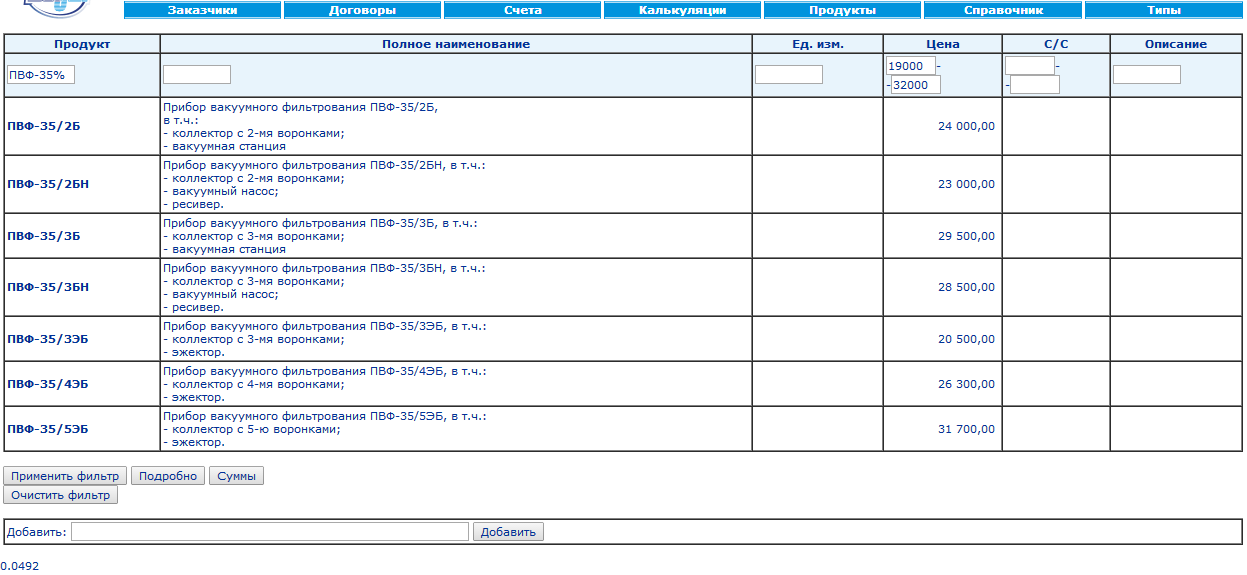
Список объектов позволяет фильтровать, сортировать, создавать и редактировать экземпляры определенного типа:
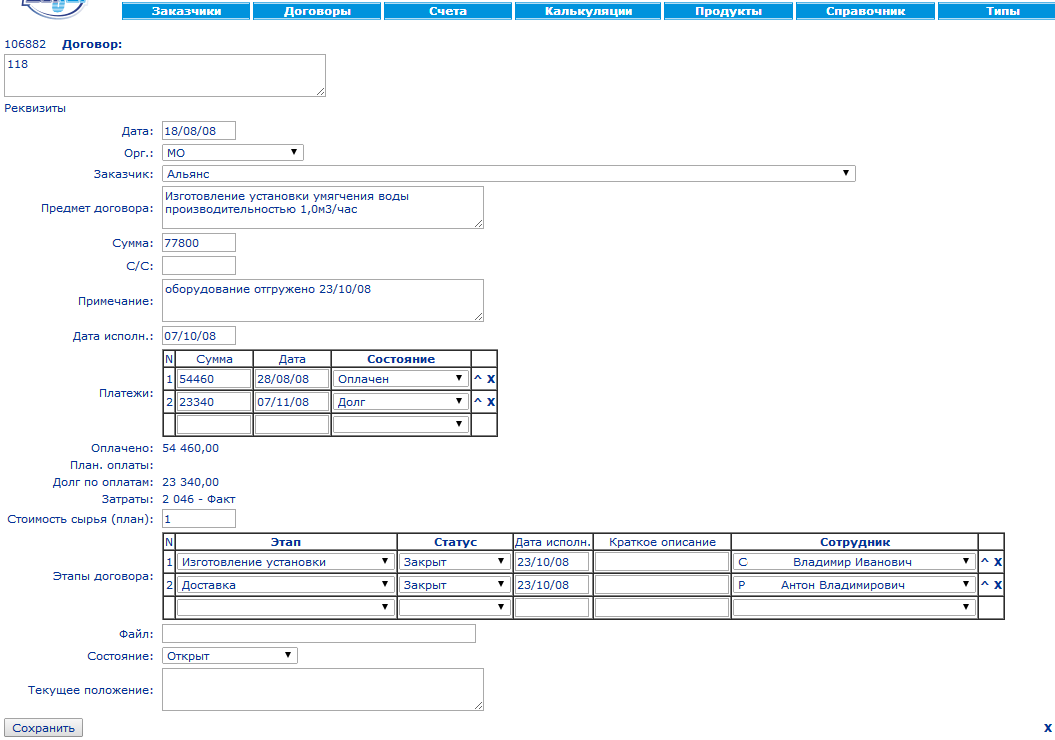
Отредактировать выбранный объект можно с помощью нехитрой универсальной формы:
Отчеты В системе реализован универсальный построитель отчетов, который позволяет создавать простые запросы на выборку и объединение данных. Построитель отчетов сам определяет, по каким признакам связаны объекты, облегчая задачу пользователю.Пример создания отчета и его результат приведен ниже в разделе Производительность.
Архитектура EAV Считается, что выборка из EAV базы сложна и громоздка. Но это — относительно. Манипуляции внутри обычной базы данных (БД) при ближайшем рассмотрении не менее сложны и громоздки, просто мы этого не видим. Точно так же все значения полей таблицы «размазаны» по поверхности носителя данных, а условия запроса дают оптимизатору лишь намеки, по какому пути и в какой последовательности отбирать нужные значения.При проектировании управляющего ядра EAV базы следует всего лишь помочь не мешать оптимизатору SQL-запросов делать выборку данных, используя всю мощь имеющихся индексов. Задача ядра — составить запрос, не требующий создания декартова произведения таблиц при отборе данных. Это несложно, и обычная БД легко с этим справляется.
По сути, мы эмулируем обычную БД в EAV базе данных.
Разумеется, создание модели традиционной БД средствами EAV базы влечет за собой некоторые накладные расходы: каждое поле данных расходует память на хранение своего собственного типа и идентификатора, а также на обязательное индексирование этих значений (да и значения самого поля тоже). Объем данных вырастет почти в два раза, в худшем случае — в три–четыре раза.
Если всё сделано правильно, то общее быстродействие EAV базы «на глаз» будет не хуже, чем в традиционной БД. «Не хуже», потому что традиционная БД постоянно растет и развивается, разработчики создают новые таблицы и пишут новые запросы, заботясь об оптимизации только когда возникают проблемы. Это часто приводит к нелинейной деградации производительности и даже коллапсу (в случае использования хинтов, например).
Ядро рассматриваемой здесь системы не подлежит дальнейшей доработке: запросы к базе (которых, к слову, менее сотни на весь проект) выполняются по отлаженному и неизменному плану. Это гарантирует, что с ростом объемов деградация производительности будет расти незначительно (при удвоении объема будет иногда добавляться один уровень индекса, соответственно замедляя поиск).
Как это работает? В обычной БД адрес поля данных это Таблица –> Идентификатор записи –> Поле. Аналог адреса поля данных в нашей EAV базе — Идентификатор. Для ускорения поиска по значению используется поле Тип (t — Type), которое участвует в составном индексе по полям Type и Value.Рассмотрим пример: нам необходимо найти все объекты, у которых свойство Фамилия равно «Zuckerberg», а дата рождения — »14.05.1984». Каждое из перечисленных свойств имеет свой тип, код которого записан в поле Type нашей единственной таблицы.
Произойдет примерно следующее:
Индекс по полям (Type, Value) сначала отправит нас в область массива данных, где хранятся фамилии, а далее ветвление индекса приведет ко всем Цукербергам Аналогично будут найден набор записей для даты рождения 14 мая 1984 года Оптимизатор объединит оба полученных выше набора по полю Up К получившейся выборке по тому же полю Up будут подтянуты сами объекты, вместе с остальными интересующими нас реквизитами (адреса которых, благодаря индексу, все лежат в одном месте) В обычной БД алгоритм поиска (для некомпилированного запроса) почти такой же, за тем исключением, что поиск ведется в три этапа: сначала нужно найти требуемую Таблицу, затем Поле, в котором уже Значение. При большом количестве таблиц и полей навигация во всем этом хозяйстве может занять ненулевое время (которое, впрочем, сравнимо с затратами на поиск в многоуровневом индексе EAV таблицы).Производительность Поскольку у нас EAV база, требуется большое количество объединений таблиц. Пока все запросы достаточно просты, SQL-сервер не испытывает проблем c оптимизацией и выполнением запросов. Ниже приведен пример одного из типичных запросов, какие я нашел в трассировке SQL реальной базы. Сделан он для отчета, который составлен не очень оптимально с точки зрения программиста (ибо составлен пользователем), однако система хорошо держит удар.Описание отчета выглядит так:

Отчет выдает выборку данных из нескольких сущностей:

Текст запроса приведет в ужас любого гуманоида (ведь он составлен машиной для машины):
SELECT a2.val v2_13, a4_331.val v4_331_9, a4_332.val v4_332_15, rv4_74.val v4_74_41_33
, av4_74_662_12.val v4_74_662_12, a4_659.val v4_659_33, a3.val v3_33
, a17464.val v17464_8, a2_132.val v2_132_33, a3_68.val v3_68_33, a3_58.val v3_58_33
, a3_10103.val v3_10103_33, tv4_74_662_12.up tv4_74_662_12, tv17464_8.up tv17464_8
FROM a a2
LEFT JOIN a a2_20 ON a2_20.up=a2.id AND a2_20.t=5
LEFT JOIN (a r2_132 CROSS JOIN a a2_132) ON r2_132.up=a2.id AND r2_132.t=131 AND a2_132.id=r2_132.val
, a ref3, a a3
LEFT JOIN a a3_68 ON a3_68.up=a3.id AND a3_68.t=65
LEFT JOIN a a3_58 ON a3_58.up=a3.id AND a3_58.t=55
LEFT JOIN a a3_10103 ON a3_10103.up=a3.id AND a3_10103.t=10102, a ref17464
, a a17464
LEFT JOIN a tv17464_8 ON tv17464_8.t=0 AND tv17464_8.ord=0 AND tv17464_8.up=a17464.id
, a ref4, a a4
LEFT JOIN a a4_331 ON a4_331.up=a4.id AND a4_331.t=18
LEFT JOIN a a4_332 ON a4_332.up=a4.id AND a4_332.t=5
LEFT JOIN (a arv4_74 CROSS JOIN a av4_74 CROSS JOIN a rv4_74) ON arv4_74.up=a4.id AND arv4_74.t=43 AND av4_74.up=arv4_74.id AND av4_74.t=41 AND rv4_74.id=av4_74.val
LEFT JOIN (a arv4_74_662_12 CROSS JOIN a av4_74_662_12) ON arv4_74_662_12.up=a4.id AND arv4_74_662_12.t=43 AND av4_74_662_12.up=arv4_74_662_12.id AND av4_74_662_12.t=662 AND av4_74_662_12.ord=av4_74.ord
LEFT JOIN a tv4_74_662_12 ON tv4_74_662_12.t=0 AND tv4_74_662_12.ord=0 AND tv4_74_662_12.up=av4_74_662_12.id
LEFT JOIN (a r4_659 CROSS JOIN a a4_659) ON r4_659.up=a4.id AND r4_659.t=131 AND a4_659.id=r4_659.val
WHERE a2.t=2 AND a2.up!=0 AND ref3.up=a2.id AND ref3.t=36 AND a3.id=ref3.val
AND ref17464.up=a2.id AND ref17464.t=17465 AND a17464.id=ref17464.val AND a4.t=4
AND ref4.t=38 AND ref4.up=a4.id AND ref4.val=a2.id
AND a4_331.val>='20080101' AND a4_331.val<='20081231'
AND a2_20.val>=100000 AND a2_20.val<=20000000
AND rv4_74.val LIKE '%аванс%' AND a4_659.val LIKE 'Отпра%'
AND a2_132.val>='Открыт' AND a2_132.val<='Отпр'
ORDER BY v4_331_9;
В то же время для сервера такой запрос прост до предела, а его план выполнения выглядит так:
Согласно плану, в запросе объединяются 24 результата подзапросов, заданы 8 фильтрующих условий, из которых для 5 может быть использован индекс. В отчете задействованы 7 разных сущностей, что в обычной базе потребовало бы объединения не меньше 7 таблиц.
Запрос выполняется около 60 мс. Для сравнения, самый простой запрос вида
SELECT val FROM a WHERE id=121853; (id — первичный ключ) выполняется на той же машине за 0,2–0,3 мс.Первый прототип системы начинал подтормаживать при объединении более 40 таблиц; последние версии системы имеют большую нагрузочную способность за счет более эффективного связывания данных. Поэтому остается достаточно большой запас прочности, даже с планируемым внедрением ролевой модели разграничения прав пользователя в системе.
Тест на больших объемах Для проверки работоспособности базы в нее был загружен справочник КЛАДР — это все населенные пункты, улицы и дома России, всего 3 504 944 объекта (в версии от декабря 2014), которые вместе со своими реквизитами и метаданными составляют больше 26 млн записей в базе.Следует сразу отметить, что справочник КЛАДР лучше выполнять не в универсальном виде, а в виде узкоспециализированного приложения. Причина — малое количество неизменных таблиц и всего пара–тройка отчетов. Тем не менее, заказчик спросил: «Справишься с КЛАДР?». Пожалуйста!
Чтобы получить хотя бы 10 млн объектов, КЛАДР был загружен в базу трижды. Для улучшенного перемешивания данных в индексах во все значения второй и третьей копии между вторым и третьим символом был вставлен номер загруженного КЛАДР — 2 или 3. Например, индекс 115162 существует также как 1125162 и 1135162.
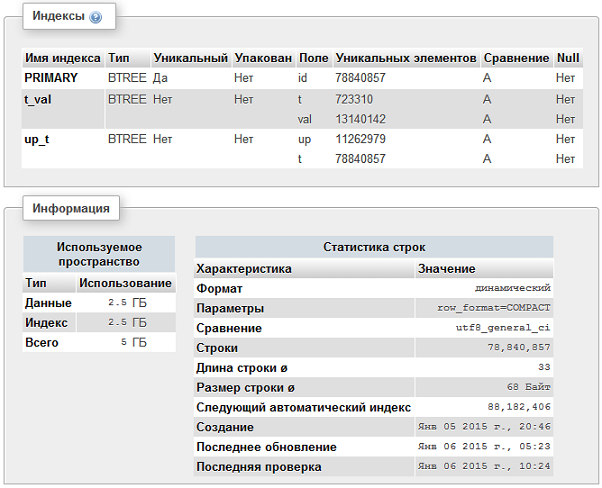
Итого получается 10.5 млн объектов записанных в 78 млн записей. Вот как это выглядит в phpMyAdmin:
Будем бомбить запросами справочник домов, которых у нас в базе 6 736 890 штук. Я заранее подготовил условия поиска по разным параметрам, которые вернут результаты из разных мест таблицы. Перезагружаем наш сервер… Поехали!
Вот что получилось (приведены скриншоты результатов запросов):
Цифры внизу таблиц: количество запросов к БД / общее время выполнения запросов (в секундах) / время построения html страницы (в секундах).
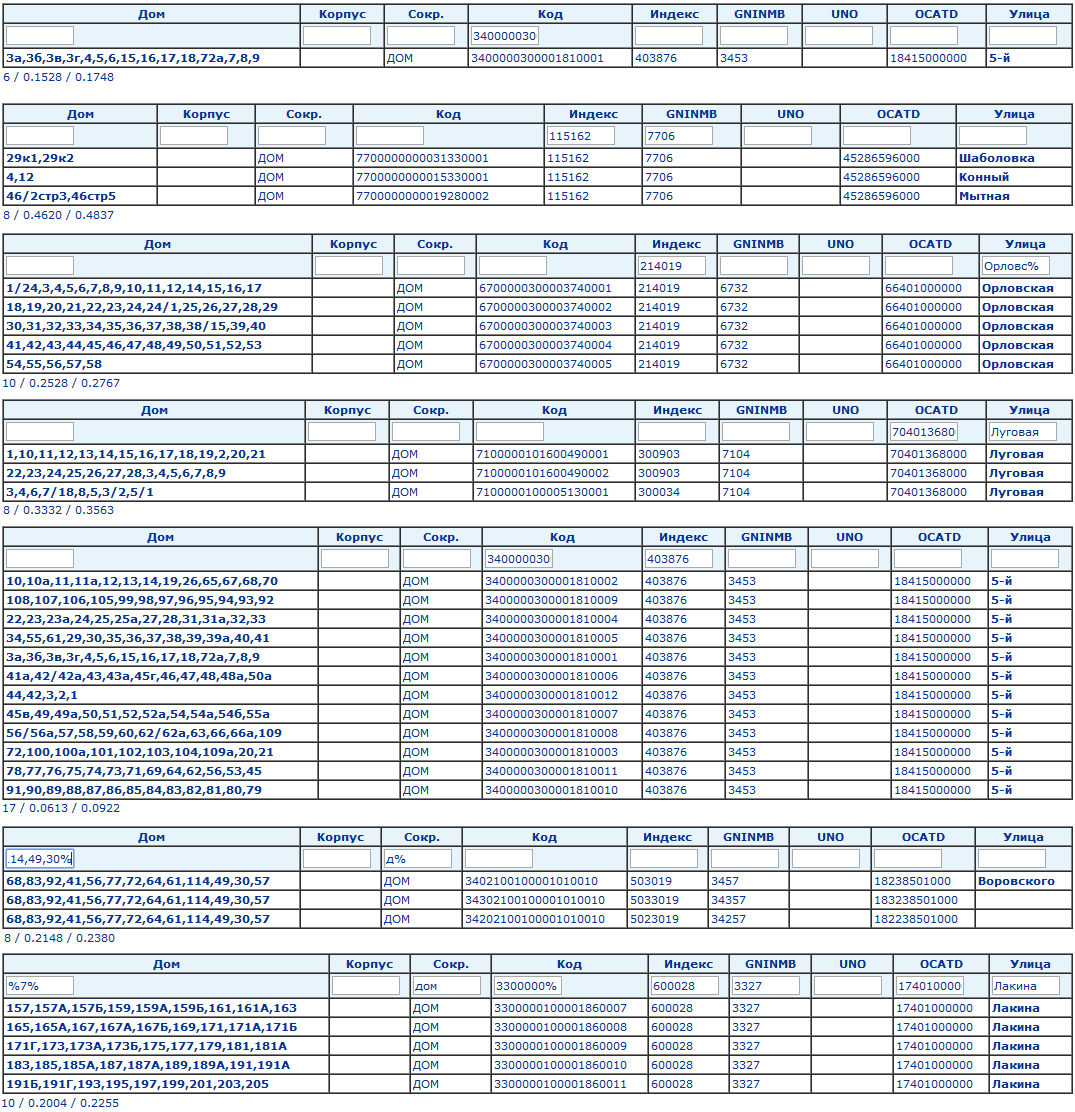
Измерения показывают очень интересный факт: при увеличении записей в таблице в 850 раз (с 92 тысяч до 78 миллионов) разница во времени построения страниц увеличивается примерно в 2 раза.
Выборка идет из «холодной» базы (индексы еще не загружены в память, кэш пуст). Это заметно по пятому результату фильтрации: несмотря на то, что в нем больше всего данных, он выполнился на порядок быстрее остальных, потому что, как минимум, блоки индекса в районе кода 3400000300001810001 уже были загружены в оперативную память после самого первого запроса (самый верхний на картинке).
По трассировке SQL-запросов видно, что простая выборка по первичному ключу выполняется за 0,4–0,7 мс, что в два раза дольше, чем в небольшой базе с 92 тысячами записей (0,2–0,3 мс). Разница в скорости более сложных запросов примерно такая же. Понятно, что в небольшой базе основное время тратится не на выборку, а на передачу запроса, его разбор и компиляцию. Внедрение prepared statements и подобные организационно-технические мероприятия, несомненно, позволят лучше разглядеть разницу при различных объемах данных, но это все еще впереди — пока мы доказываем жизнеспособность конструктора в принципе. Среднее время выполнения запросов — 240 мс, построения страниц — 264 мс, что находится в пределах нормы для комфортного пользовательского интерфейса.
Рассмотрим подробнее план выполнения самой сложной части последней выборки. Там 7 условий, и этот запрос забирает около 95% общего времени всех 17 запросов. Отбор данных выполняется так:
SELECT vals.id, vals.t, vals.val
FROM a vals, a a72, a a73, a a74, a a75, a a77, a a78, a ref_78
WHERE vals.t=32 AND vals.up=1 AND vals.val LIKE '%7%'
AND a72.up=vals.id AND a72.t=72 AND a72.val ='дом'
AND a73.up=vals.id AND a73.t=73 AND a73.val LIKE '3300000%'
AND a74.up=vals.id AND a74.t=74 AND a74.val ='600028'
AND a75.up=vals.id AND a75.t=75 AND a75.val ='3327'
AND a77.up=vals.id AND a77.t=77 AND a77.val ='17401000000'
AND a78.up=vals.id AND a78.t=ref_78.id AND a78.val=''AND ref_78.t=31 AND ref_78.val ='Лакина'
ORDER BY vals.val;
Его расширенный план выполнения выглядит так: 
Команда SHOW WARNINGS не выдает ничего криминального (одна запись Level: Note с перефразированным запросом).
Теперь на той же базе пробежимся по цепочке взаимосвязанных объектов (я даже рискну утверждать здесь, что такой режим является наиболее приближенным к реальной жизни).
Серия из 18 скриншотов с замерами времени показывает нормальный режим использования справочника КЛАДР: (1) поиск кода по известной части адреса и (2) построение адреса по коду.
Смотреть скриншоты
Синий овал на каждом экране показывает действие, ведущее на следующий экран.
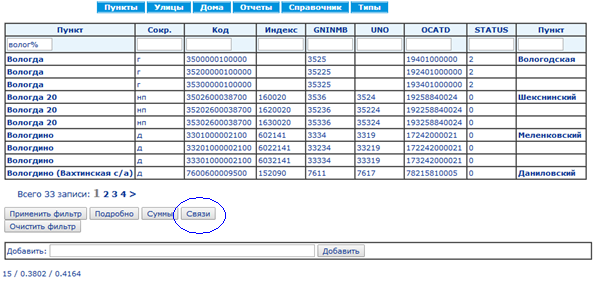

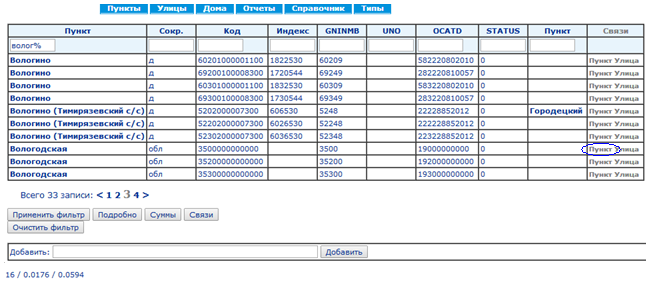
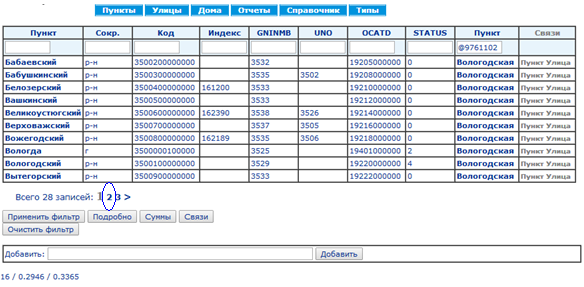

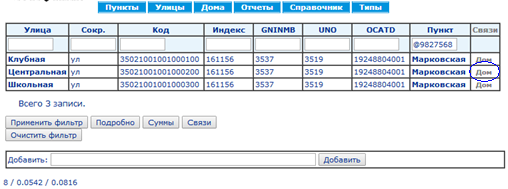

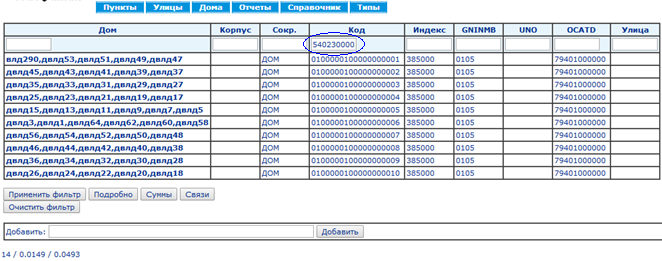
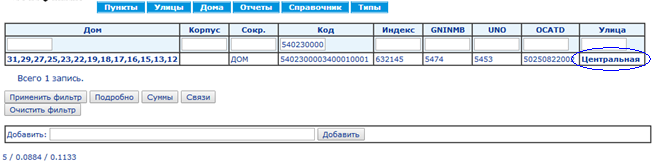
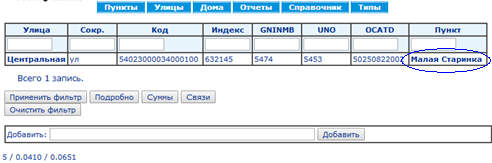


Среднее время выполнения запросов составляет 73 мс, построения страниц — 107 мс.Сравнение быстродействия традиционной БД и EAV
Теперь, объективности ради, сделаем тот же набор запросов в обычной базе данных. Загружаем те же 10.5 млн записей и видим, кстати, что размер базы уменьшился на 70% (в 3,3 раза): 
Сравнивать будем только общее время выполнения запросов к БД:
№ Кол-во условий Время EAV, мс Время обычной БД, мс Разница, разы 1 1 153 46 3,3 2 2 462 73 6,3 3 2 253 45 5,6 4 2 333 72 4,6 5 2 61 33 1,8 6 2 215 51 4,2 7 7 200 140 1,4 Среднее 240 66 3,9 В «холодных» базах быстродействие точечных запросов различается в среднем почти в 4 раза. Предполагаемая причина — EAV база грузит в память большее количество разрозненных блоков индекса, тратя время на их поиск.Стоит обратить внимание, что увеличение количества применяемых условий (фильтров) сильнее влияет на быстродействие традиционной БД, что косвенно подтверждает предположение, сделанное в предыдущем абзаце. Прежде чем сделать выбор из доступных индексов, приходится обратиться к каждому из них за статистикой, что уменьшает разницу в количестве точечных чтений с диска у двух сравниваемых баз.
Теперь cделаем поиск связанных объектов по тому же пути, что в базе EAV (см. серию из 18 скриншотов), и сравним полученные результаты:
№ Время EAV, мс Время обычной БД, мс Разница, разы 1 16 2 8,0 2 380 225 1,7 3 18 1 18,0 4 18 1 18,0 5 295 106 2,8 6 40 3 13,3 7 19 1 19,0 8 129 46 2,8 9 27 4 6,8 10 37 12 3,1 11 54 58 0,9 12 83 70 1,2 13 15 90 0,2 14 88 73 1,2 15 41 11 3,7 16 21 11 1,9 17 25 13 1,9 18 3 1 3,0 Среднее 73 41 — В этом испытании суммарное время, затраченное на выборки, различается менее чем в 2 раза. Очевидно, что для несложных запросов накладные расходы при использовании метаданных могут забирать до 95% ресурсов, однако в целом производительность базы остается на весьма приличном уровне.Известные грабли Перечислю некоторые недостатки и особенности информационной модели.Сложно написать запрос к базе вручную — нужно опираться на метаданные, что усложняет запрос в разы. С другой стороны, простые запросы в построителе отчетов составляются гораздо быстрее и проще, чем это можно сделать вручную. Не все знают SQL, а вот перечислить нужные поля, условия и функции (SUM, COUNT и др.) может любой пользователь. Пустые значения. EAV база данных не хранит атрибуты объектов с пустыми значениями, что является большим преимуществом с точки зрения использования памяти. В то же время поиск объектов с пустым (отсутствующим) атрибутом потребует просмотреть все объекты на предмет наличия этого атрибута, что весьма трудоемко при большом количестве объектов. Обойти это достаточно легко, просто записав в поле условно пустое значение (например, строку «NULL» в числовое поле), но, вероятно, такое решение придет в голову уже после обнаружения проблемы. Числовые значения. Все числа хранятся в виде строки, что делает невозможным использование индекса при диапазонном поиске для чисел. Есть несколько вариантов, как это можно исправить, но пока проблема не волнует существующих пользователей и админов (незаметна невооруженным глазом), поэтому остается как есть. Дотошный читатель может заметить, что в тексте запроса от построителя отчетов есть условия вида a4_659.id=r4_659.val, которое сравнивает числовой id с символьным val, что не всегда позволяет оптимизатору использовать индекс. Подобная конструкция использовалась для «связывания» таблиц. Примеры здесь приведены из старого прототипа; сейчас в системе таких сравнений нет, а нужный код хранится не в val, а в поле t (Type). Строки с ID 14, 26 и 3565 в Примере описания метаданных иллюстрируют уже новую схему связей. Использование кэша запросов (в нашем случае это MySQL кэш) будет почти бесполезно при одной единственной таблице. Кэш можно сразу отключить, а сделать его подобие в самом приложении. Было бы очень полезно разместить ID метаданных ближе к вершине BTREE индекса, чтобы поиск их работал быстрее (метаданных на порядки меньше данных, а используются они очень интенсивно). Это вполне реально сделать, выдавая метаданным свободные ID ближе к 0, а остальным данным — инкрементальные ID, расползающиеся симметрично в плюс и в минус. Да, будут отрицательные идентификаторы, ну и что? Повышенный расход дискового пространства под данные. Та же база КЛАДР, например, в плоских файлах занимает 320 МБ, в обычной БД — 360 МБ (500 МБ с индексами), в EAV базе — 820 МБ (1.6 ГБ с индексами). Хотя это не проблема, а больше особенность. Дешевле заплатить за новый диск, чем всего за один день работы целой команды (менеджеры, аналитики, разработчики, кодеры, тестеры и т.д.). Оптимизация Оптимизация базы конструктора CRM аналогична оптимизации обычной базы. Разница только в объеме подконтрольного кода приложения: на текущий момент это 77 запросов и около 750 строк кода.Повторюсь, оптимизация делается только на этапе разработки системы, а у конечного пользователя вопросов возникать не должно.
В рассмотренном здесь примере никакой оптимизации еще не проводилось. Единственное, что сделано, это обеспечение корректной работы с индексами для любых запросов. Навскидку, ускорить работу с метаданными удастся минимум в 1,5–2 раза.
Заключение В этом проекте удалось эмулировать работу базы данных через EAV представление обычных таблиц: SQL-сервер работает по той же схеме, что и в обычной базе, но несет некоторые накладные расходы на восстановление структуры данных по метаданным. Эти накладные расходы вырастают линейно, пропорционально сложности запроса, и не зависят от объемов данных.Да, можно сильно напрячь сервер, если задать множество условий по полям, имеющим небольшое количество уникальных значений. Однако то же самое произойдет и в обычной базе — оптимизатору не решить эту проблему без составного индекса, а таковой нельзя сделать для множества полей одновременно.
А что дальше? Сейчас идет доработка построителя отчетов. Рецензенты статьи попрекали меня отсутствием многоуровневых группировок и рекурсивных запросов. Рекурсию не обещаю (она есть не во всех движках популярных БД, что делает невозможным портирование системы), а вот все остальное обязательно будет. В планах научить систему делать все, что можно сделать с помощью языка SQL (включая INSERT, UPDATE, DELETE). Кому интересно — буду держать в курсе. Спасибо за внимание!
