Рецепт «Быстрых данных» на основе решения для больших данных
 Источник изображенияПри обсуждении работы с большими данными, чаще всего затрагиваются вопросы аналитики и проблемы организации процесса вычислений. Нам с коллегами выпала возможность поработать над задачами другого рода — ускорением доступа к данным и балансированием нагрузки на систему хранения. Ниже я расскажу о том, как мы с этим справились.
Источник изображенияПри обсуждении работы с большими данными, чаще всего затрагиваются вопросы аналитики и проблемы организации процесса вычислений. Нам с коллегами выпала возможность поработать над задачами другого рода — ускорением доступа к данным и балансированием нагрузки на систему хранения. Ниже я расскажу о том, как мы с этим справились.
Свой «рецепт» мы смастерили из уже существующих «ингредиентов»: железки и программного инструмента. Сначала я расскажу, каким образом перед нами возникла задача ускорения доступа. Затем рассмотрим железку и программный инструмент. В заключение поговорим о двух проблемах, с которыми нам пришлось столкнуться в ходе работы.Начнем с описания задачи.В среде, которую нам пришлось оптимизировать, для хранения данных используется горизонтально масштабируемое сетевое хранилище. Если вам не знакомы эти слова, не пугайтесь, я сейчас все объясню :)
Горизонтально масштабируемая система хранения данных (по-английски — scale-out NAS) — это кластерная система, состоящая из множества узлов, объединенных между собой высокоскоростной внутренней сетью. Все узлы доступны пользователю по-отдельности через внешнюю сеть, например, через интернет.
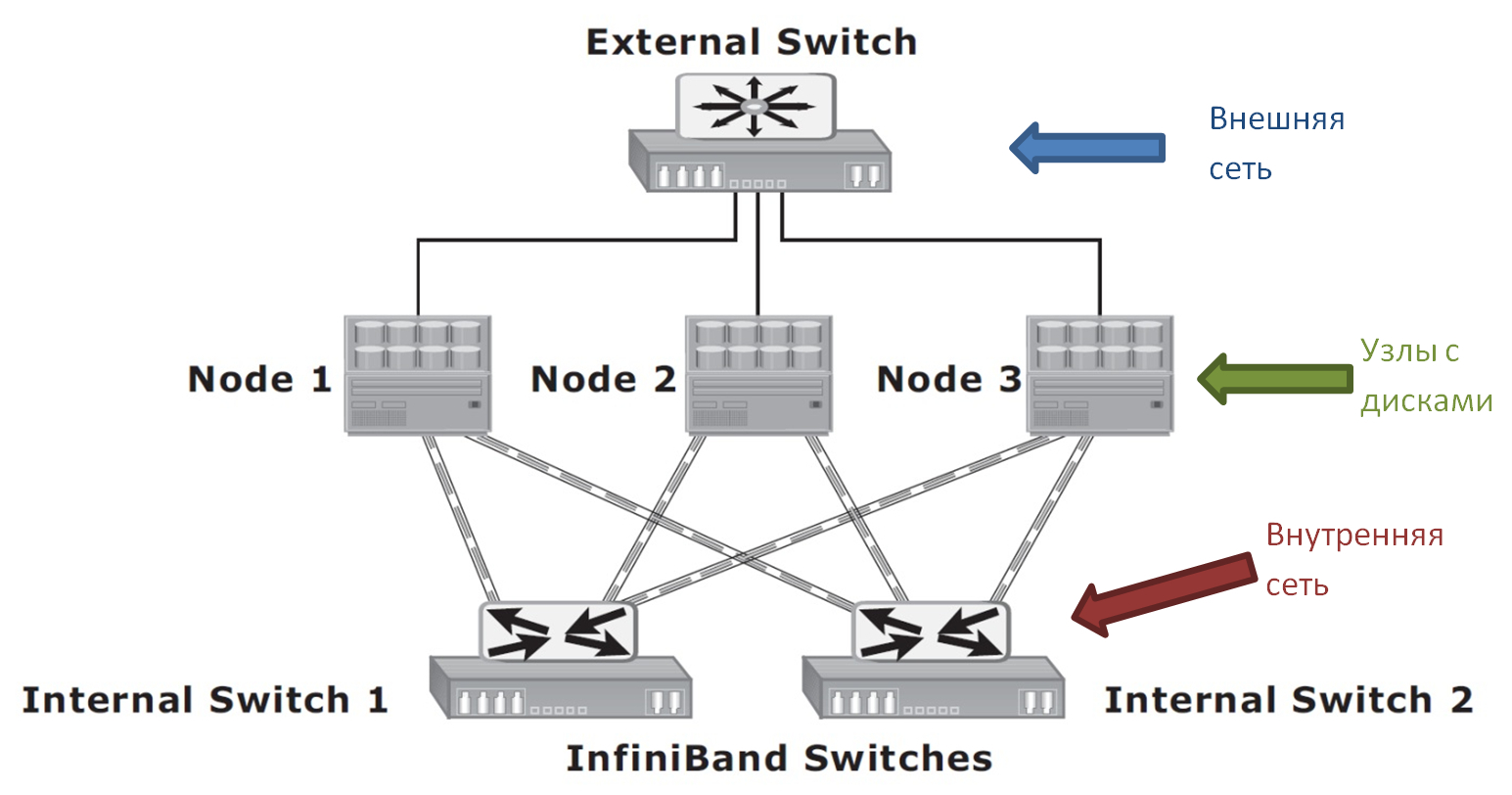
На схеме изображено только три узла. На самом деле, их может быть гораздо больше. В этом и состоит прелесть scale-out систем. Как только вам становятся нужны дополнительное дисковое пространство или производительность, вы просто добавляете новые узлы в кластер.
Выше я сказал, что каждый из узлов кластера доступен по-отдельности. Имеется, в виду, что с каждым узлом можно установить отдельное сетевое соединение (или даже несколько). Однако через какой бы узел пользователь ни подключался к кластеру, он видит единую файловую систему.
В дата-центре scale-out хранилище выглядит примерно так (узлы кластера уложены в стильные стойки).
 В нашем случае для хранения данных использовалась как раз система, изображенная на картинке: Isilon от компании EMC. Она была выбрана из-за своей почти неограниченной масштабируемости: один кластер способен предоставить до 30 петабайт дискового пространства. Причем извне все пространство будет доступно как одна-единственная файловая система.
В нашем случае для хранения данных использовалась как раз система, изображенная на картинке: Isilon от компании EMC. Она была выбрана из-за своей почти неограниченной масштабируемости: один кластер способен предоставить до 30 петабайт дискового пространства. Причем извне все пространство будет доступно как одна-единственная файловая система.
Проблема, которую нам предстояло решить, связана с конкретной моделью использования Исилона. В оптимизируемой нами среде доступ к данным осуществляется через систему управления данными. Я не буду вдаваться здесь в детали, т.к. это отдельная большая тема. Расскажу только о следствиях такого подхода. Причем я значительно упрощу общую картину, чтобы сконцентрироваться только на тех вещах, которые наиболее существенны для дальнейшего.
Упрощенно картина доступа к данным в нашей среде выглядит следующим образом:
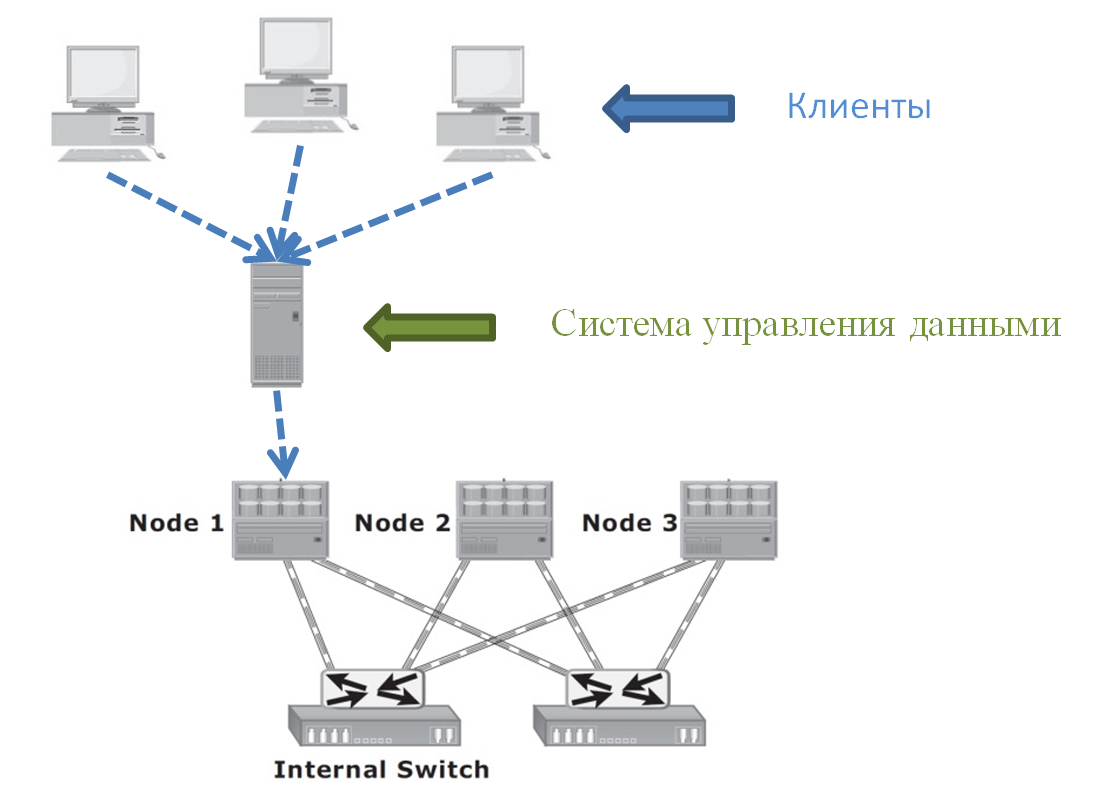
Множество клиентов обращаются к системе управления данными, которая запущена на выделенном сервере. Клиенты не пишут/читают данные из Исилона напрямую. Это делается только через систему управления, которая потенциально может производить над данными какие-то манипуляции: например, шифровать.
На схеме сервер системы управления общается только с одним узлом системы хранения данных (СХД). И это то, что мы имели на самом деле. Поток многочисленных клиентских запросов шел на один единственный узел СХД. Получается, что нагрузка на кластер могла быть сильно не сбалансированной в том случае, когда остальные узлы не нагружались другими серверами или клиентами.
Исилон, вообще говоря, предоставляет отличные возможности автоматической балансировки нагрузки. Например, если какой-то сервер попытается установить соединение с Исилоном, то оно будет обслуживаться узлом, наименее загруженным на данный момент. Конечно, для того, чтобы такая балансировка стала возможной, необходимо, настроить и использовать Исилон соответствующим образом.
Однако автоматическая балансировка нагрузки на СХД возможна только на уровне сетевых соединений. Например, если на каком-то узле кластера накопится большое количество «прожорливых» соединений, СХД сможет «раскидать» их по более свободным узлам. Но в случае с единственным нагруженным соединением, СХД бессильна.
Теперь несколько слов о том, что собой представляет единственное высоконагруженное соединение, которое нам предстояло разгрузить. Это просто NFS-монтировка. Если вы не знакомы с NFS, загляните под спойлер.
NFS
В Unix есть понятие виртуальной файловой системы. Это такой обобщенный интерфейс для доступа к информации. Через него можно получить доступ уже к конкретным файловым системам. По сути, файловые системы различных устройств просто встраиваются в локальную файловую систему и выглядят для пользователя ее частью. На нижнем уровне может использоваться файловая система дискеты или же удаленные файловые системы, доступ к которым осуществляется через сеть. Одним из примеров такой удаленной файловой системы и является NFS.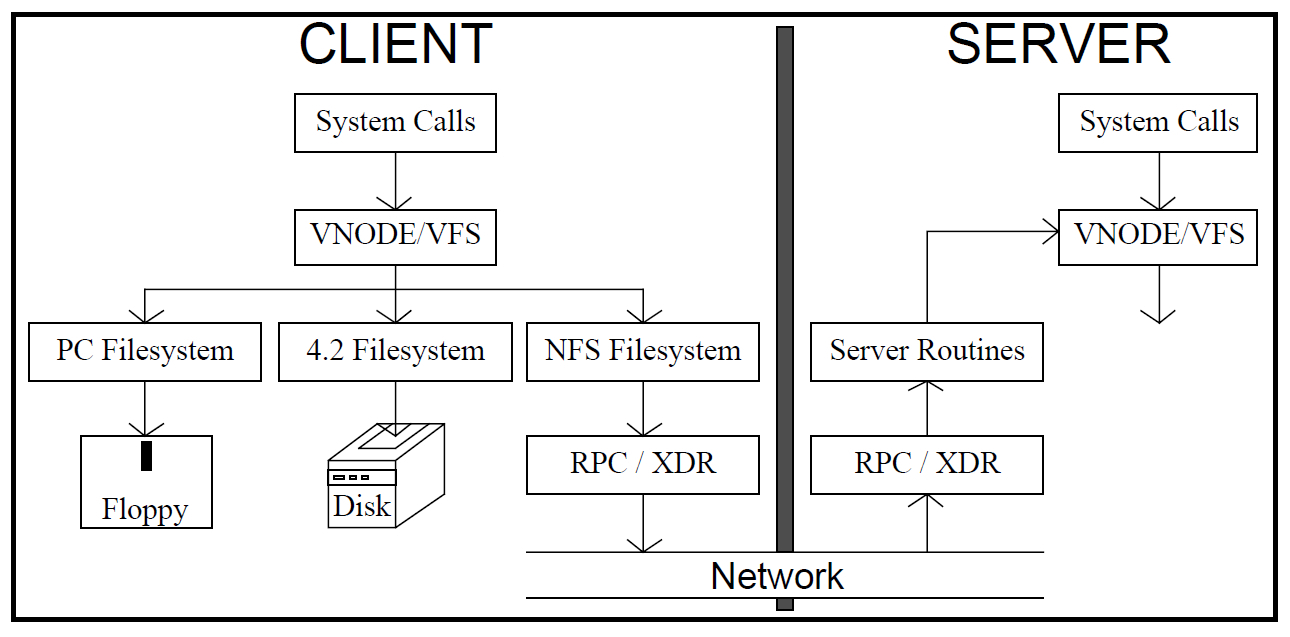 Сейчас, когда проблема понятна, самое время рассказать о том, как мы ее решили.Как я уже говорил, нам помогли железка и программное решение, предназначенные для работы с большими данными. Железка — это все тот же Исилон. И нам очень повезло, что два с лишним года назад к ней было добавлено одно интересное свойство. Без него разбираться с балансированием нагрузки было бы значительно сложнее. Свойство, о котором идет речь, — это поддержка протокола HDFS. На нем основан второй ингредиент нашего рецепта.
Сейчас, когда проблема понятна, самое время рассказать о том, как мы ее решили.Как я уже говорил, нам помогли железка и программное решение, предназначенные для работы с большими данными. Железка — это все тот же Исилон. И нам очень повезло, что два с лишним года назад к ней было добавлено одно интересное свойство. Без него разбираться с балансированием нагрузки было бы значительно сложнее. Свойство, о котором идет речь, — это поддержка протокола HDFS. На нем основан второй ингредиент нашего рецепта.
Если вы не знакомы с этой аббревиатурой и технической стороной вопроса, вэлкам под спойлер.
HDFS HDFS — это распределенная файловая система, которая является частью Hadoop — платформы для разработки и выполнения распределенных программ. Hadoop сегодня широко используется для проведения аналитики больших данных.Классическое вычислительное решение на базе Hadoop — это кластер, состоящий из вычислительных узлов (compute nodes) и узлов с данными (data nodes). Вычислительные узлы выполняют распределенные вычисления, загружая/сохраняя информацию с узлов данных. Оба типа узлов являются, скорее, логическими компонентами кластера, нежели физическими. Например, на одном физическом сервере может быть развернут один вычислительный узел и несколько узлов данных. Хотя наиболее типичной является ситуация, когда на одной физической машине запущено два узла, по одному каждого вида.
Общение вычислительных узлов с узлами данных происходит как раз по протоколу HDFS. Посредником в этом общении выступает каталог файловой системы HDFS, который представлен в кластере узлом еще одного типа — name node. Если отказаться от несущественных оговорок, можно считать, что в кластере есть только один узел-каталог.
Data-узлы хранят блоки данных. В каталоге же, помимо всего прочего, хранится информация о том, каким образом блоки, относящиеся к конкретным файлам, распределены по узлам данных.
Процесс помещения файла в HDFS со стороны клиента выглядит примерно следующим образом:
HDFS-клиент обращается к каталогу с просьбой создать файл
если все в порядке, каталог сигнализирует о том, что файл создан
когда клиент готов записать очередной блок этого файла, он снова обращается к каталогу с просьбой сообщить адрес узла данных, на который нужно отправить блок
каталог возвращает соответствующий адрес
клиент отправляет блок по этому адресу
успешная запись подтверждается
когда клиент отправил все блоки, он может запросить закрытие файла
Изначально HDFS-интерфейс поддержан в Исилоне вовсе не для того, чтобы мы с коллегами могли воспользоваться им для балансирования нагрузки на СХД. Если вам интересно, c какой целью в Исилон реализован HDFS, то заходите в очередной спойлер.Native-поддержка HDFS
В Исилоне интерфейс HDFS был поддержан для того, чтобы СХД можно было использовать непосредственно с Hadoop. К чему это привело? См. схемы ниже. На первой показан один из типичных сценариев организации Hadoop-кластера (изображены не все виды узлов, которые существуют в кластере)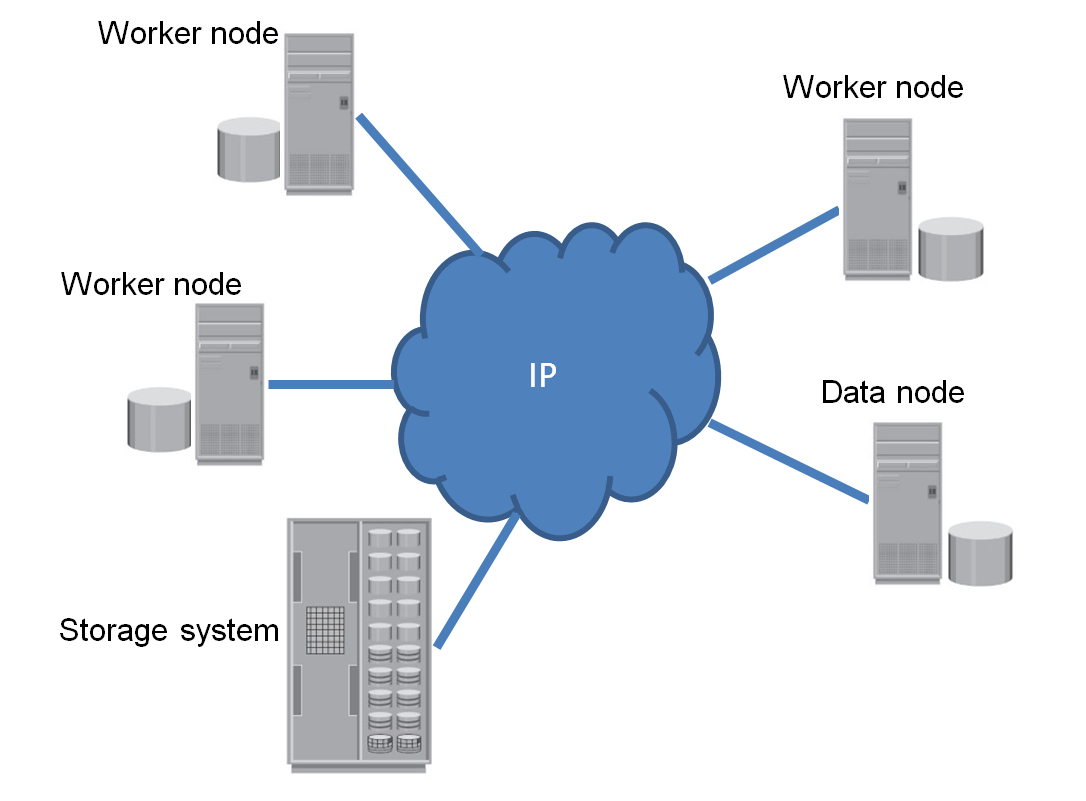 Worker node — это сервер, совмещающий функции вычислений и хранения данных. Data node — это сервер, только хранящий данные. Рядом со всеми серверами изображены «толстые» диски, на которых размещаются данные, находящиеся под управлением HDFS.
Worker node — это сервер, совмещающий функции вычислений и хранения данных. Data node — это сервер, только хранящий данные. Рядом со всеми серверами изображены «толстые» диски, на которых размещаются данные, находящиеся под управлением HDFS.
Зачем на рисунке изображена СХД? Она представляет собой продуктовое хранилище данных. В нем складируются файлы, которые поступают в продуктовую среду при выполнении повседневных бизнес-операций. Обычно эти файлы передаются в СХД по какому-нибудь широко распространенному протоколу. Например, NFS. Если мы хотим их проанализировать, то необходимо скопировать файлы (сделать staging) в хадуповский кластер. Если речь идет о многих терабайтах, то staging может занимать многие часы.
На второй картинке показано, что меняется, если в среде используется СХД с поддержкой HDFS. У серверов исчезают большие диски. Дополнительно из кластера удаляются сервера, которые занимались исключительно предоставлением доступа к данным. Все дисковые ресурсы теперь консолидированы в одной-единственной СХД. Отпадает необходимость делать staging. Аналитические расчеты теперь можно выполнять прямо над продуктовыми копиями файлов.
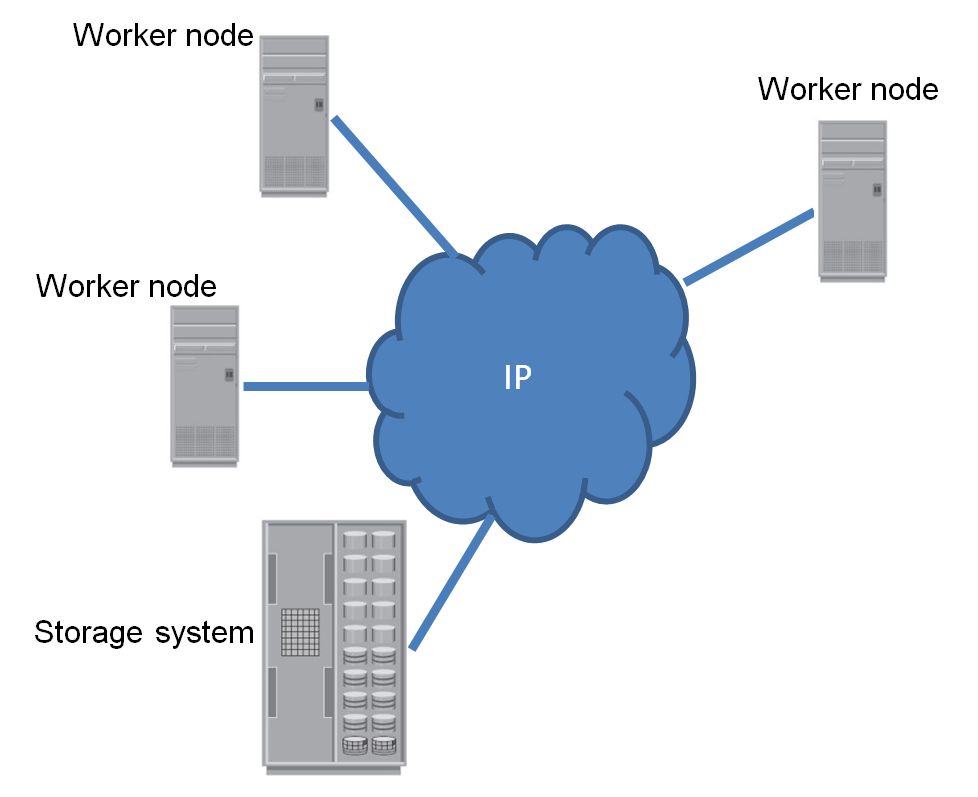 Данные по-прежнему могут попадать в СХД по NFS-протоколу. А считываться по протоколу HDFS. Если, по каким-то причинам, вычисления нельзя проводить на продуктовых копиях файлов, то данные можно скопировать внутри все той же СХД. Не буду перечислять все прелести такого подхода. Их много, и о них уже много было написано в англоязычных блогах и новостных лентах.
Данные по-прежнему могут попадать в СХД по NFS-протоколу. А считываться по протоколу HDFS. Если, по каким-то причинам, вычисления нельзя проводить на продуктовых копиях файлов, то данные можно скопировать внутри все той же СХД. Не буду перечислять все прелести такого подхода. Их много, и о них уже много было написано в англоязычных блогах и новостных лентах.
Лучше, скажу несколько слов о том, как работа с исилоновским HDFS-интерфейсом выглядит со стороны клиента. Каждый из узлов кластера может выступать в роли узла данных HDFS (если не запрещено настройками). Но что более интересно и чего нет в «реальном» HDFS, каждый узел может выполнять также роль каталога (name node). При этом надо иметь в виду, что исилоновский HDFS с точки зрения «внутренностей» не имеет почти ничего общего с хадуповской реализацией HDFS. Файловая система HDFS в Исилоне продублирована только на уровне интерфейса. Вся внутренняя кухня оригинальная и очень эффективная. Например, для защиты данных используются собственные экономичные и быстрые исилоновские технологии, в отличие от копирования по цепочке узлов данных, которое реализовано в «стандартной» HDFS.
Посмотрим теперь, каким образом HDFS помог нам справиться с балансированием нагрузки на Исилон. Вернемся к разобранному выше в спойлере примеру записи файла в HDFS. Что мы имеем в случае Исилона? Чтобы добавить очередной блок к файлу, клиент должен обратиться к каталогу, дабы узнать адрес узла данных, который примет этот блок. В Исилоне к любому узлу кластера можно обратиться как к каталогу. Делается это либо напрямую через адрес узла, либо через специальную службу, которая занимается балансировкой соединений. Адрес, который вернет каталог, соответствует наименее загруженному в данный момент узлу. Получается, что отправляя блоки в HDFS, вы всегда передаете их на самые свободные узлы. Т.е. вы автоматом имеете очень тонкую, гранулированную балансировку: на уровне отдельных элементарных операций, а не монтировок, как в случае с NFS.
Заметив это, мы решили использовать HDFS как самостоятельный интерфейс. «Самостоятельный» здесь означает, что интерфейс задействуется в отрыве от Hadoop. Возможно, это первый пример такого рода. По крайне мере, пока что я не слышал о том, чтобы HDFS использовался отдельно от семейства хадуповских или околохадуповских продуктов.
В итоге, мы «прикрутили» HDFS к нашей системе управления данными. Больше всего проблем, которые нам предстояло при этом решить, было на стороне самой системы управления. О них я говорить здесь не буду, т.к. это отдельная большая тема, завязанная к тому же на специфику конкретной системы. Но я расскажу о двух небольших проблемах, которые связаны с использованием HDFS как самостоятельной файловой системы.
Первая проблема заключается в том, что HDFS не выделена в отдельный продукт. Она распространяется как часть Hadoop. Поэтому не существует какого-то «стандарта HDFS» или «спецификации HDFS». По сути, HDFS существует в виде эталонной реализации от Apache. Так что если вы хотите узнать детали реализации (например, какова политика захвата и освобождения лизов), то вам придется заниматься реверс-инжинирингом, либо чтением исходного кода, либо поиском людей, которые уже проделали это до вас.
Вторая проблема заключается в поиске низкоуровневой библиотеки для HDFS.
После поверхностного поиска в сети может показаться, что таких библиотек множество. Однако в действительности существует одна эталонная Java-библиотека от Apache. Большинство других библиотек для C++, C, Python и прочих языков являются просто обертками вокруг Java-библиотеки.
Взять Java-библиотеку для нашего C++ проекта мы не могли. Даже с учетом соответствующей обертки. Во-первых, затаскивать на сервер системы управления данными вместе с нашим небольшим HDFS-модулем еще и Java-машину было непозволительной роскошью. Во-вторых, на просторах интернета встречаются некоторые нарекания на производительность Java-библиотеки.
Ситуация была такой, что если бы мы не нашли готовую C++ библиотеку для HDFS, нам пришлось бы писать свою. А это дополнительное время на реверс-инжиниринг. К счастью, библиотеку мы нашли.
В прошлом году (а может, и еще раньше) начали появляться первые native-библиотеки для HDFS. На текущий момент, мне известно о двух из них: для С и Python. Hadoofus и Snakebite. Возможно, появилось что-то еще. Я давно не повторял поиск.
Для своего проекта мы взяли Hadoofus. За все время использования мы нашли в ней только две ошибки. Первая — простая — приводила к тому, что библиотека не собиралась C++-компилятором. Вторая более неприятная: дедлок при многопоточном использовании. Проявлялся он крайне редко, что усложняло анализ проблемы. На текущий момент обе ошибки устранены. Хотя над полноценным тестированием отсутствия дедлоков мы все еще работаем.
Никаких других проблем, связанных с использованием HDFS, нам решать не пришлось.
В целом надо отметить, что написание HDFS-клиента для Исилона проще, чем написание клиента для «стандартного» HDFS. Несомненно, любой «стандартный» HDFS-клиент будет без проблем работать с Исилоном. Обратное не обязано быть верным. Если вы пишете HDFS-клиент исключительно для Исилона, то задача упрощается.
Рассмотрим пример. Допустим, вам надо прочитать блок данных с HDFS. Для этого клиент обращается к каталогу и спрашивает, с каких узлов данных можно этот блок взять. В общем случае в ответ на такой запрос каталог возвращает координаты не одного узла, а нескольких, на которых хранятся копии этого блока. Если клиенту не удастся получить ответ от первого узла в списке (например, этот узел упал), то он обратится ко второму, третьему и т.д., пока не найдется узел, который ответит.
В случае с Исилоном вам не нужно думать о подобных сценариях. Исилон всегда возвращает адрес одного-единственного узла, который вас обязательно обслужит. Это не означает, что исилоновские узлы не могут «упасть». В конце концов, вывести узел из строя можно хотя бы топором. Однако если Исилон по каким-то причинам теряет узел, он просто передает его адрес другому — уцелевшему — узлу в кластере. Так что сценарий отказоустойчивости в значительной мере уже заложен в «железку», и вам не нужно полностью реализовывать его в софте.
На этом рассказ о нашем «рецепте» можно считать законченным. Осталось только добавить несколько слов о результатах.
Амортизированный выигрыш в производительности, по сравнению с работой через NFS, составляет в нашей среде около 25%. Эта цифра получена при сравнении «самих с собой»: в обоих случаях производительность измерялась на одном и том же оборудовании и одном и том же софте. Единственное, что различалось — это модуль для доступа к файловой системе.
Если рассматривать только операции чтения, то выигрыш в 25% наблюдается также при скачивании каждого отдельного файла. В случае с записью данных, можно говорить только об амортизированном выигрыше. Запись каждого отдельного файла происходит медленнее, чем через NFS. Для этого есть две причины:
HDFS не поддерживает многопоточную запись файлов наша система управления данными имеет особенности, которые из-за названного ограничения HDFS не позволяют организовать быструю запись отдельного файла Будь запись файлов организована в системе управления данными более оптимально, выигрыш в 25% при записи можно было бы ожидать и для отдельного трансфера.Отмечу, что замедление выгрузки каждого конкретного файла нас не сильно расстроило, т.к. для нас наиболее существенна пропускная способность при пиковых нагрузках. К тому же в окружениях, аналогичных нашему, чтение данных — гораздо более частая операция, чем запись.
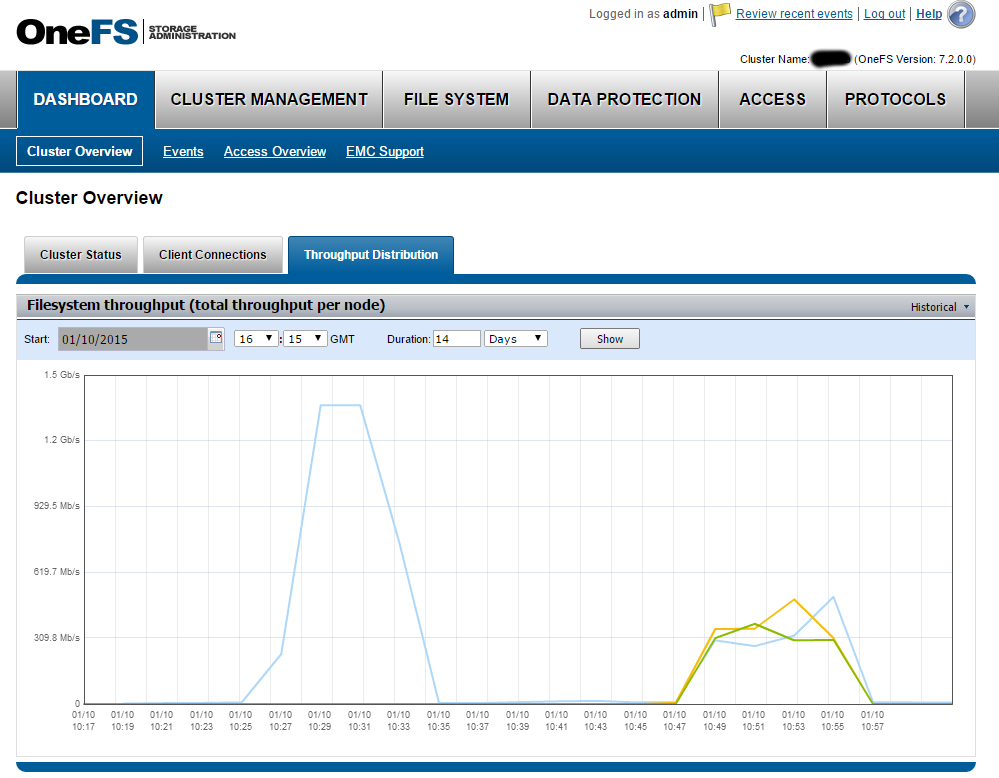
В заключение приведу иллюстрацию, которая дает представление о том, каким образом изменяется загруженность Исилона при использовании HDFS в качестве интерфейса.
Скриншот показывает загруженность кластера при передаче в обе стороны файла размером 2Гб (файл был загружен и скачан 14 раз подряд). Синий высокий пик слева получен при работе через NFS. Чтение и запись происходят через одну монтировку, и всю нагрузку в этом случае принимает на себя один узел кластера. Разноцветные низкие пики справа соответствуют работе через HDFS. Видно, что теперь нагрузка «размазана» по всем имеющимся в кластере узлам (3 штуки).
 На этом, пожалуй, все.
На этом, пожалуй, все.
Пусть у вас всегда все работает быстро и надежно!
