[Из песочницы] Помехоустойчивое кодирование. Часть 1: код Хэмминга

Код Хэмминга — не цель этой статьи. Я лишь хочу на его примере познакомить вас с самими принципами кодирования. Но здесь не будет строгих определений, математических формулировок и т.д. Эта просто неплохой трамплин для понимания более сложных блочных кодов.
Сначала уясним, что представляют собой операции с числами над полем Галуа. Элемент поля в некотором роде похож на регистр. Число имеет ограниченное кол-во значений. Если прибавлять к нему по единице, то в какой-то момент значение превысит размерность поля и обратиться в ноль. Размерность может быть любой, начиная с 2. Вот к примеру операции сложения, умножения в над GF (4), это краткое обозначение:

Да, да, 2+3 = 1, 3×3 = 2, в полях Галуа возможно и такое. Но мы будем иметь дело пока что с размерностью два, т.е. бит информации. Операция умножения заменяется на логическое И (AND), сложение — на исключающее или (XOR). Если кто вдруг забыл:

Самый, пожалуй, известный код Хэмминга (7,4). Что значат эти цифры? Вторая — число бит информационного слова — то, что мы хотим передать в целости и сохранности. А первое — размер кодового слова: информация удобренная избыточностью. Кстати термины «информационное слово» и «кодовое слово», употребляются во всех 7-ми книгах по теории помехоустойчивого кодирования, которые мне довелось бегло пролистать.
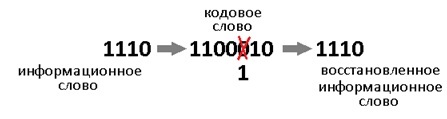
Такой код исправляет 1 ошибку. И не важно где она возникла. Избыточность несёт в себе 3 бита информации, этого достаточно, чтобы указать на одно из 7 положений ошибки или показать, что её нет. То есть ровно 8 вариантов ответов мы ждём. А 8 = 2^3, вот как всё совпало.
Чтобы получить кодовое слово, нужно информационное слово представить в виде полинома и умножить его на порождающий полином g (x). Любое число, переведя в двоичный вид, можно представить в виде полинома. Это может показаться странным и у не подготовленного читателя сразу встаёт только один вопрос «да зачем же так усложнять?». Уверяю вас, он отпадёт сам собой, когда мы получим первые результаты.
К примеру информационное слово 1010, значение каждого его разряда это коэффициент в полиноме:

Во многих книгах пишут наоборот x+x^3. Не поддавайтесь на провокацию, это вносит только путаницу, ведь в записи числа 2-ичного, 16-ричного, младшие разряды идут справа, и сдвиги мы делаем влево/вправо ориентируясь на это. А теперь давайте умножим этот полином на порождающий полином. Порождающий полином специально для Хэмминга (7,4), встречайте: g (x)=x^3+x+1. Откуда он взялся? Ну пока считайте что он дан человечеству свыше, богами (объясню позже).

Если нужно складывать коэффициенты, то делаем это в поле GF (2), то есть x^4+x^4=0. И в конечном итоге результат перемножения как видите из 4х членов. В двоичном виде это 1001110. Итак, получили кодовое слово, которое будем передавать на сторону по зашумлённому каналу. Замете, что перемножив информационное слово (1010) на порождающий полином (1011) как обычные числа — получим другой результат 1101110. Этого нам не надо, требуется именно «полиномиальное» перемножение. Программная реализация такого умножения очень простая. Нам потребуется 2 операции XOR и 2 сдвига влево (1й из которых на один разряд, второй на два, в соответствии с g (x)=1011):

Давайте теперь специально внесём ошибку в полученное кодовое слово. Например в 3-й разряд. Получиться повреждённое слово: 1000110.
Как расшифровать сообщение и исправить ошибку? Разумеется надо «полиномиально» разделить кодовое слово на g (x). Тут я уже не буду писать иксы. Помните что вычитание в GF (2) это то же самое что сложение, что в свою очередь, тоже самое что исключающее или. Поехали:

В программной реализации опять же ничего сверх сложного. Делитель (1011) сдвигаем влево до самого конца на 3 разряда. И начинаем удалять (не без помощи XOR) самые левые единицы в делимом (100110), на его младшие разряды даже не смотрим. Делимое поэтапно уменьшается 100110 → 0011110 → 0001000 → 0000011, когда в 4 м и левее разрядах не остаётся единиц, мы останавливаемся.
Нацело разделить не получилось, значит у нас есть ошибка (ну конечно же). Результат деления в таком случае нам без надобности. Остаток от деления является синдром, его размер равен размеру избыточности, поэтому мы дописали там ноль. В данном случае содержание синдрома нам никак не помогает найти местоположение повреждения. А жаль. Но если мы возьмём любое другое информационное слово, к примеру 1100. Точно так же перемножим его на g (x), получим 1110100, внесём ошибку в тот же самый разряд 1111100. Разделим на g (x) и получим в остатке тот же самый синдром 011. И я гарантирую вам, что к такому синдрому мы придём в обще для всех кодовых слов с ошибкой в 3-м разряде. Вывод напрашивается сам собой: можно составить таблицу синдромов для всех 7 ошибок, делая каждую из них специально и считая синдром.

В результате собираем список синдромов, и то на какую болезнь он указывает:

Теперь у нас всё есть. Нашли синдром, исправили ошибку, ещё раз поделили в данном случае 1001110 на 1011 и получили в частном наше долгожданное информационное слово 1010. В остатке после исправления уже будет 000. Таблица синдромов имеет право на жизнь в случае маленьких кодов. Но для кодов, исправляющих несколько ошибок — там список синдромов разрастается как чума. Поэтому рассмотрим метод «вылавливания ошибок» не имея на руках таблицы.
Внимательный читатель заметит, что первые 3 синдрома вполне однозначно указывают на положение ошибки. Это касается только тех синдромов, где одна единица. Кол-во единиц в синдроме называют его «весом». Опять вернёмся к злосчастной ошибке в 3 м разряде. Там, как вы помните был синдром 011, его вес 2, нам не повезло. Сделаем финт ушами — циклический сдвиг кодового слова вправо. Остаток от деления 0100011 / 1011 будет равен 100, это «хороший синдром», указывает что ошибка во втором разряде. Но поскольку мы сделали один сдвиг, значит и ошибка сдвинулась на 1. Вот собственно и вся хитрость. Даже в случае жуткого невезения, когда ошибка в 6 м разряде, вы, обливаясь потом, после 3 мучительных делений, но всё таки находите ошибку — это победа, лишь потому, что вы не использовали таблицу синдромов.
А как насчёт других кодов Хэмминга? Я бы сказал кодов Хэмминга бесконечное множество: (7,4), (15,11), (31,26), … (2^m-1, 2^m-1-m). Размер избыточности — m. Все они исправляют 1 ошибку, с ростом информационного слова растёт избыточность. Помехоустойчивость слабеет, но в случае слабых помех код весьма экономный. Ну ладно, а как мне найти порождающую функцию например для (15,11)? Резонный вопрос. Есть теорема, гласящая: порождающий многочлен циклического кода g (x) делит (x^n+1) без остатка. Где n — нашем случае размер кодового слова. Кроме того порождающий полином должен быть простым (делиться только на 1 и на самого себя без остатка), а его степень равна размеру избыточности. Можно показать, что для Хэмминга (7,4):
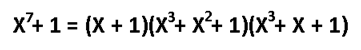
Этот код имеет целых 2 порождающих полинома. Не будет ошибкой использовать любой из них. Для остальных «хэммингов» используйте вот эту таблицу примитивных полиномов:
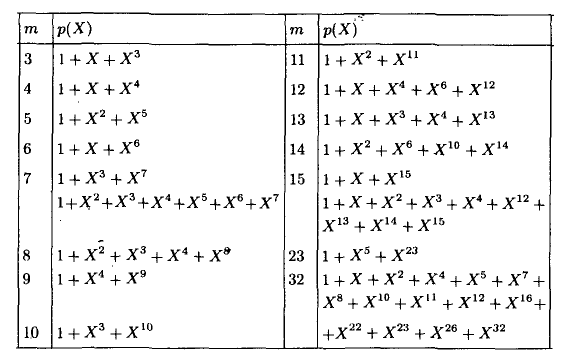
Соответственно для (15,11) порождающий многочлен g (x)=x^4+x+1. Ну, а теперь переходим к десерту — к матрицам. С этого обычно начинают, но мы этим закончим. Для начала преобразую g (x) в матрицу, на которую можно умножить информационное слово, получив кодовое слово. Если g = 1011, то:
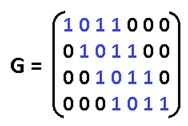
Называют её «порождающей матрицей». Дадим обозначение информационному слову d = 1010, а кодовое обозначим k, тогда:

Это довольно изящная формулировка. По быстродействию ещё быстрее, чем перемножение полиномов. Там нужно было делать сдвиги, а тут уже всё сдвинуто. Вектор d указывает нам: какие строки брать в расчёт. Самая нижняя строка матрицы — нулевая, строки нумеруются снизу вверх. Да, да, всё потому что младшие разряды располагаются справа и от этого никуда не деться. Так как d=1010, то я беру 1ю и 3ю строки, произвожу над ними операцию XOR и вуаля. Но это ещё не всё, приготовьтесь удивляться, существует ещё проверочная матрица H. Теперь перемножением вектора на матрицу мы можем получить синдром и никаких делений полиномов делать не надо.

Посмотрите на проверочную матрицу и на список синдромов, который получили выше. Это ответ на вопрос откуда берётся эта матрица. Здесь я как обычно подпортил кодовое слово в 3 м разряде, и получил тот самый синдром. Поскольку сама матрица — это и есть список синдромов, то мы тут же находим положение ошибки. Но в кодах, исправляющие несколько ошибок, такой метод не прокатит. Придётся вылавливать ошибки по методу, описанному выше.
Чтобы лучше понять саму природу исправления ошибок, сгенерируем в обще все 16 кодовых слов, ведь информационное слово состоит всего из 4х бит:

Посмотрите внимательно на кодовые слова, все они, отличаются друг от друга хотя бы на 3 бита. К примеру возьмёте слово 1011000, измените в нём любой бит, скажем первый, получиться 1011010. Вы не найдёте более на него похожего слова, чем 1011000. Как видите для формирования кодового слова не обязательно производить вычисления, достаточно иметь эту таблицу в памяти, если она мала. Показанное различие в 3 бита — называется минимальное «хэммингово расстояние», оно является характеристикой блокового кода, по нему судят сколько ошибок можно исправить, а именно (d-1)/2. В более общем виде код Хэмминга можно записать так (7,4,3). Отмечу только, что Хэммингово расстояние не является разностью между размерами кодового и информационного слов. Код Голея (23,12,7) исправляет 3 ошибки. Код (48, 36, 5) использовался в сотовой связи с временным разделением каналов (стандарт IS-54). Для кодов Рида-Соломона применима та же запись, но с уточнением размерности поля Галуа, это уже недвоичные коды.
Список используемой литературы:
1. М. Вернер. Основы кодирования (Мир программирования) — 2004
2. Р. Морелос-Сарагоса. Искусство помехоустойчивого кодирования (Мир связи) — 2006
3. Р. Блейхут. Теория и практика кодов, контролирующих ошибки — 1986
