[Из песочницы] Клиническая обработка сигналов речи и машинное обучение. Часть 1
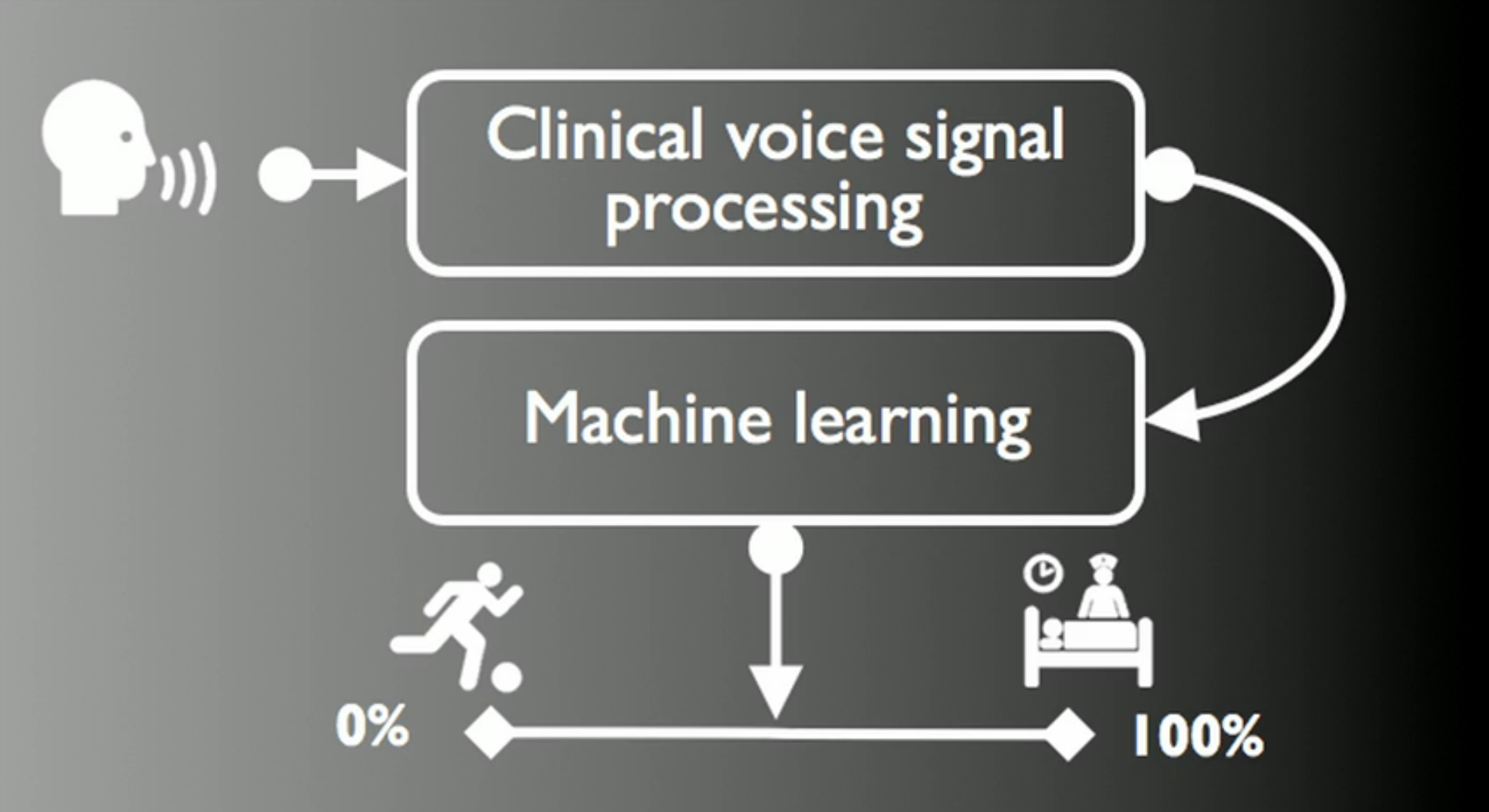 Из выступления Max Little (основателя PVI) на конференции TED в 2012 году.Здравствуй, Хабрахабр. Данный цикл статей будет посвящен рассмотрению возможности и построению Open Source универсального анализатора нарушений речи.
Из выступления Max Little (основателя PVI) на конференции TED в 2012 году.Здравствуй, Хабрахабр. Данный цикл статей будет посвящен рассмотрению возможности и построению Open Source универсального анализатора нарушений речи.
В данной статье будет рассказано о проекте Parkinson Voice Initiative, посвященному ранней диагностике Болезни Паркинсона по голосу (успешность распознавания составляет 98,6± 2.1% за 30 секунд по телефонному разговору).Будет произведено сравнение точности используемых в нем алгоритмов выбора особенностей (ВО) — Feature Selection Algorithm — LASSO, mRMR, RELIEF, LLBFS.
Битва между Random Forest (RF) и Supported Vector Machine (SVM) за звание лучшего анализатора в данного рода приложениях.
НачалоЧитая статьи по синтезу и распознаванию речи, нашел упоминание о том, что при болезни изменяется голос. Проверив очевидность факта, что я не первый догадался использовать распознавание речи для диагностики болезней (первые клиницисты определили некоторые features — особенности еще в 40-х годах прошлого века, записывая на магнитофонную ленту, а потом вручную анализируя), пошел по ссылкам Гугла. Одна из первых указывала на проект PVI. Посмотрев выступление основателя на конференции TED 2012 года (доступны субтитры на русском от Ирины Жандаровой), я нашел необходимые аргументы в пользу такого проекта для себя, для врачей и пациентов, и, надеюсь, для программистов.
Посмотрев выступление основателя на конференции TED 2012 года (доступны субтитры на русском от Ирины Жандаровой), я нашел необходимые аргументы в пользу такого проекта для себя, для врачей и пациентов, и, надеюсь, для программистов.
До 2012 года не существовало биомаркеров Болезни Паркинсона, а существующие скорее для определения динамики развития, нежели чем для первичной диагностики. Кроме этого, вопрос их доступности, цены, времени получения результата и трудоемкости остается открытым.
 Отрывок из презентации TED 2012 года (субтитры на русском от Ирины Жандаровой).
Отрывок из презентации TED 2012 года (субтитры на русском от Ирины Жандаровой).
Аргументы Особенности Невролог Проверка голоса Не инвазивность + + Использование существующей инфраструктуры + + Точность + + Удаленность + Возможность использования не профессионалом + Высокая скорость получения результата + Очень низкая стоимость + Масштабируемость + Также это позволяет часто проводить проверки на наличие заболевания.
Замечательно, подумал я, можно легко сделать такие же анализаторы и по другим болезням, кликнул на вкладку Science и увидел, что этот анализатор начали делать с 2006 года. Срок разработки несколько понизил уровень энтузиазма, но не отбил желание.
Почему этот сайт не дает медицинских советов, если они имеют такой точный анализатор?
На это есть несколько возможных причин (они подходят для любого анализатора болезни):
Юридическое регулирование. Им придется взять на себя ответственность для того, чтобы давать медицинские советы; Они не уверены в том, что набрали достаточное количество данных; Ложно-позитивные и ложно-негативные определения болезни; Болезнь может не иметь такой тяжести, чтобы начало проявляться расстройство речи (т.е. она может развиться позднее); Наконец, некоторые симптомы вообще не проявляются на любой тяжести у некоторого количества людей (люди выздоравливают или умирают раньше); Еще существующая схожесть с некоторыми болезнями (например, для данного проекта, это Essential Tremor — другая разновидность тремора, чем при Болезни Паркинсона). Судя по всему, данные доступны врачам и исследователям, которые смогут правильно их оценить.
Темпы роста уникальных записей голосов людей вы можете увидеть ниже. Данные за 2012 год (через 8 лет после начала программы)на основе Твиттера Max Little @MaxALittle показывают, что количество людей, проходящих тест, больше зависит от освещения средствами массовой информации и соцсетями, как и везде.
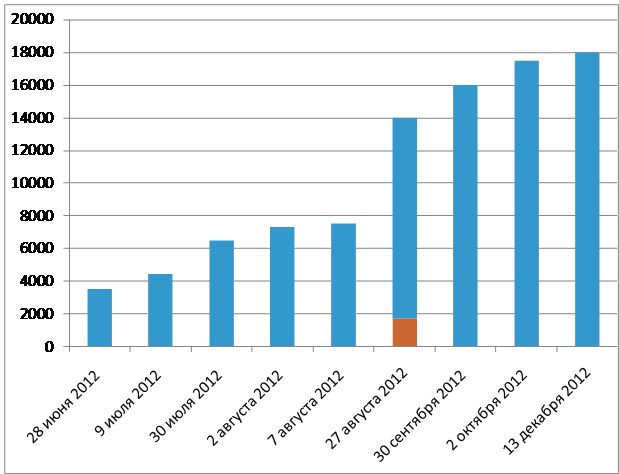
Верхняя граница столбца — общее количество прошедших голосовой тест на проекте PVI. 27 августа были опубликованы данные, что 1700 из 14000 подписавшихся (приблизительно 12% больны Паркинсоном) — красный столбик.
В память о Аароне Шварце он выложил свои публикации в свободный доступ, благодаря чему каждый может с ними ознакомиться, посмотреть технические детали и развить его работы.
To honour Aaron Swartz memory, all my publications to-date, for free: www.maxlittle.net/publications/ #pdftribute
Max Little @MaxALittle 14 янв. 2013 г. Основатель проекта Parkinson Voice Initiative, его число Эрдёша равно 4.
Основатель проекта Parkinson Voice Initiative, его число Эрдёша равно 4.
В последнем исследовании Max Little от 2012 года, размещенном на сайте — «Новые алгоритмы для обработки сигналов речи для высокоточной классификации Болезни Паркинсона» произведено сравнение 4 алгоритмов выбора особенностей (ВО). Данные, на основе которых проходило исследование, включало 132 особенностей и 263 записей, включающих в себя фонации контрольной группы (61 запись от 10 человек) и лиц, больных Болезнью Паркинсона (202 записи от 33 человек).
Технические детали Используя все особенности, исследованные в данной работе, SVM, с 10-кратной cross-validation — перекрестной проверкой (ПП), повторенной 100 раз, показал точность 97.7±2.8%, а при использовании RF, с 10-кратной перекрестной проверкой, повторенной 100 раз — достигнутая точность составила 90.2±5.9%.Наилучшие результаты, описанные в литературе до этого, достигали 93,1±2.9% точности в классификации на выборке из 22 особенностей с использованием алгоритма GP-EM (for genetic programming and the expectation maximization algorithm — для генетического программирования и максимизации ожиданий).
Для повышения качества предсказаний и снижения трудоемкости в обработке сигналов речи в исследовании было решено создать поднабор из 10 особенностей. Всесторонний поиск через все возможные поднаборы достаточно затратный в машинном времени, поэтому были разработаны алгоритмы по ВО, которые предлагают быстрые, принципиальные подходы к уменьшению набора особенностей.
Поднаборы особенностей в каждом случае были выбраны с помощью подхода ПП, используя только обучающую информацию на каждой итерации ПП. Они повторяли процесс ПП в целом 10 раз, где каждый раз особенности (для каждого ВО алгоритма) появлялись в нисходящем порядке выбора. В идеале, каждый раз должен получаться один и тот же порядок, но на практике так не происходит.
RELIEF RELIEF, используя всего 10 особенностей (из 132) на данных 256 фонаций, показал 98,6± 2.1% точность (истинно положительные: 99.2 ± 1.8%; истинно отрицательные: 95.1 ± 8.4%) с SVM и 93,5% точность с RF.RELIEF — это алгоритм, основанный на определении «веса» особенности, который повышает особенности, которые разделяют образцы из различных классов. Это соотносится с максимизацией исправляющей способности алгоритмов, и было отнесено к k-Nearest-Neighbor классификатору. Противоположно алгоритму mRMR (рассмотренному ниже), RELIEF использует сопряженность, как неотъемлемую часть процесса выбора особенностей.
LLBFS Второе место занял алгоритм LLBFS (Local Learning-Based Feature Selection — основанный на локальном обучении выбор особенности) с точностью 97.1 ± 3.7% (истинно положительные: 99.7 ± 1.7%; истинно отрицательные: 89.1 ±13.9%).LLBFS нацелен на разбиение трудноразрешимых комбинаторных проблем ВО в набор локальных линейных проблем через локальное обучение. Исходным особенностям были назначены веса, которые отражают их важность для проблемы классификации, после чего из них были выбраны особенности, имеющие максимальный вес. LLBFS был задуман, как расширение RELIEF и базируется на ядерной оценки плотности распределения и понятиях максимизации исправляющей особенности.
LASSO Least Absolute Shrinkage and Selection Operator (LASSO), метод оценки параметров линейной модели, имеющий возможности редукции размерности, занял 3 место с точностью 94.4 ± 4.4% (истинно положительные: 97.5 ± 3.4%; истинно отрицательные: 86.5 ± 14.3%).LASSO штрафует за абсолютное число коэффициентов, устанавливаемых в линейной регрессии; это ведет к сокращению некоторых из них до нуля, что эффективно показывает связанные с ними особенности. LASSO показало предсказывающие способности (корректно идентифицировало все «правильные» особенности, вносящие вклад в предсказывание ответа) при разреженной установке, когда особенности не высоко сопряжены. В то же время, когда особенности коррелируют, все еще могли быть выбраны «шумные» особенности (не вносящие вклад в ответ) и выброшены некоторые полезные особенности для предсказывания результата.
mRMR Minimum Redundancy Maximum Relevance (mRMR), (минимальная избыточность — максимальная релевантность) занял последнее место среди исследуемых алгоритмов ВО, с точностью 94.1 ± 3.9 (истинно положительных: 97.6 ± 3.3; истинно отрицательных: 84.3 ± 13.2).Алгоритм mRMR использует эвристический критерий для установления баланса между максимальной релевантностью (связью силы особенностей с ответом) и минимальным избытком (связями между парами особенностей). Это жадный алгоритм (основанный на выборе одной особенности за один проход), который акцентирует внимание только на попарную избыточность и игнорирует сопряженность (соединения логическими связями особенностей для предсказывания ответа).SVM vs. RF В данном исследовании SVM взял верх над RF. Автор исследования пробовал изменять параметр настройки RF (количество особенностей, среди которых должен осуществляться поиск для построения каждой ветви дерева), но это не дало заметно отличающихся результатов для общей точности RF.Возможные улучшения, предлагаемые автором исследования:
SVM и RF могут быть настроены для вывода «Не знаю», через введение дополнительного класса, если возможность отнесения к другим классам ниже некоторой предварительно-заданной черты, что позволит повысить точность определения, а также даст повод присмотреться внимательнее к данному случаю врачам.
В следующей части будут обсуждены особенности, на основании которых можно получить такие замечательные результаты.
P.S. Если вам интересна данная тема и вы готовы помочь в разработке — пишите, обсудим.
