[recovery mode] Реализация функции потерь Triplet Loss в Python (функция тройных потерь)
Большинство из нас думают о машинном обучении как о «черном ящике», который принимает некоторые данные и выдает отличные результаты. В последние годы этот черный ящик работает как имитация человека в соответствующих областях, где он используется, и достигает выдающихся результатов.

Black box
Но, по моему опыту, изучение этого черного ящика может быть увлекательным, забавным и иногда разочаровывающим. Этот черный ящик делает много вещей, которые никто не мог предсказать десять лет назад. Самая интересная часть машинного обучения — понять, как этот черный ящик делает что-то за кулисами, что делает возможным чудесные вещи.
Зачем все это?
Когда я недавно столкнулся с моделью распознавания лиц под названием FaceNet, я был поражен ее невероятной точностью в распознавании лиц, несмотря на то, что она была обучена на одном кадре. Я хотел понять, что происходит за кулисами этой модели, и, прочитав немного о FaceNet, звездой шоу для меня стала используемая функция потерь, которая была ничем иным, как функцией тройных потерь. Меня поразил тот факт, что небольшие интуитивные мыслительные процессы, происходящие в нашем мозгу каждую секунду, могут решать необычные проблемы. Это и побудило меня написать эту статью.
Приступим
Здесь я попытаюсь объяснить, что я понимаю под концепцией тройной функции потерь (Triplet Loss). Эта функция потерь стала популярной после того, как модель Facenet, созданная компанией Google, стала современной моделью распознавания лиц, которая использует тройную функцию потерь под капотом.
В этом разделе функция тройных потерь объясняется с помощью аналогии, чтобы помочь вам понять ее интуитивно. Предположим, у вас есть два друга (назовем их A и B). Вы учитесь в одном классе (т.е. на одном курсе); известно, что А — лучший ученик в классе. В день подведения итогов вы получили 50 баллов, а два других ваших друга (А и Б) — 95 и 93 балла соответственно. Если предположить, что ваши родители теперь знают результаты и знают, что А — лучший, то они делают вывод, что между оценками Б и лучшего (А) нет большой разницы, а вы тоже задохлик, поэтому естественно, что Б тоже лучший. Потому что есть большая разница между твоей оценкой и лучшей (А).
Мы, люди, почти всегда проводим подобную категоризацию и рассуждаем в соответствии с правилом, согласно которому вещи, принадлежащие к одной категории, имеют схожие свойства (в данном сценарии — метки).
Другими словами, мы пытаемся уменьшить расстояния и различия между похожими вещами и увеличить расстояния и различия между разными вещами.
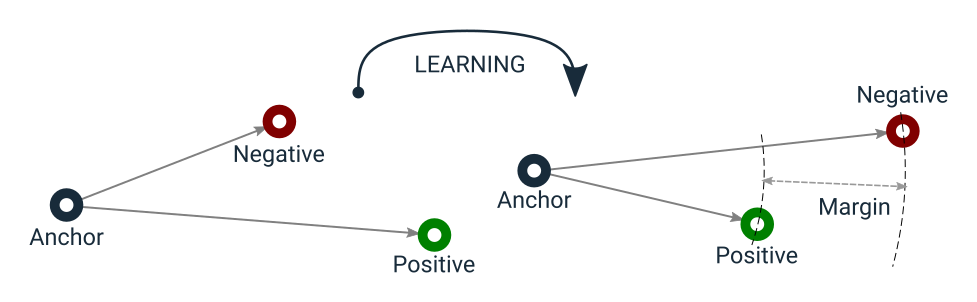
Triplet Loss минимизирует расстояние между якорем и позитивом, оба из которых имеют одинаковую идентичность, и максимизирует расстояние между якорем и негативом другого идентификатора.
Давайте проанализируем приведенную выше диаграмму в соответствии с текущим сценарием: А — якорь, поскольку известно, что он является вершиной (идентифицирован); Б — считается отрицательным (поскольку разница в оценках между А и якорем велика); В — считается положительным (поскольку разница в оценках между Б и якорем невелика). Таким образом, обучая модель классификации, веса параметров можно настроить так, чтобы минимизировать тройные потери, то есть уменьшить разницу между похожими и увеличить разницу между разными.
Теперь мы готовы понять, как тройные потери работают в модели Facenet: На этапе обучения модели Facenet каждый вход состоит из трех изображений лиц. Два из них — изображения одного и того же человека (одно якорное, одно положительное), а последнее — другого человека (отрицательное). Модель Facenet обрабатывает изображение лица каждого человека и кодирует его признаки в 128-мерном пространстве, т.е. выдает вектор размером 128.
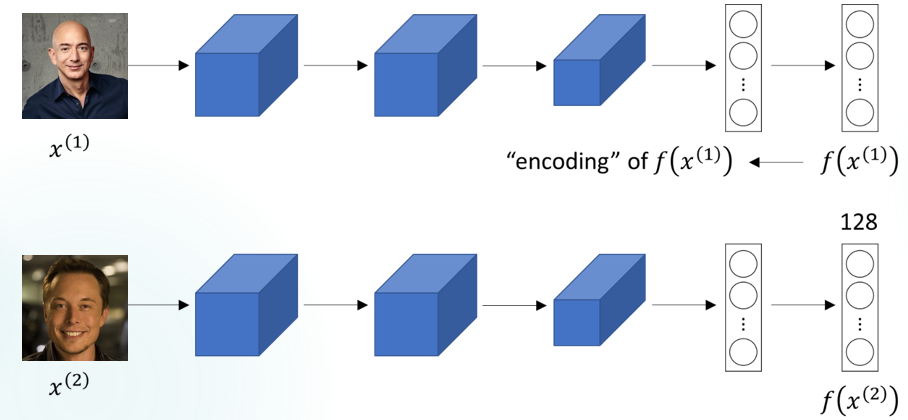
Кодирование изображения в вектор размера 128
Следуя процессу мысленной аналогии, описанному выше, можно сказать, что в 128-мерном пространстве два лица различны, если расстояние между двумя кодированными точками велико, и одинаковы, если расстояние мало (в принципе, пороговое значение для определения размера расстояния сохраняется). Поэтому модель корректирует веса таким образом, чтобы расстояние между кодированными точками было больше.
Расстояние между опорным изображением и позитивным изображением мало.
Расстояние между опорным изображением и отрицательным изображением большое.
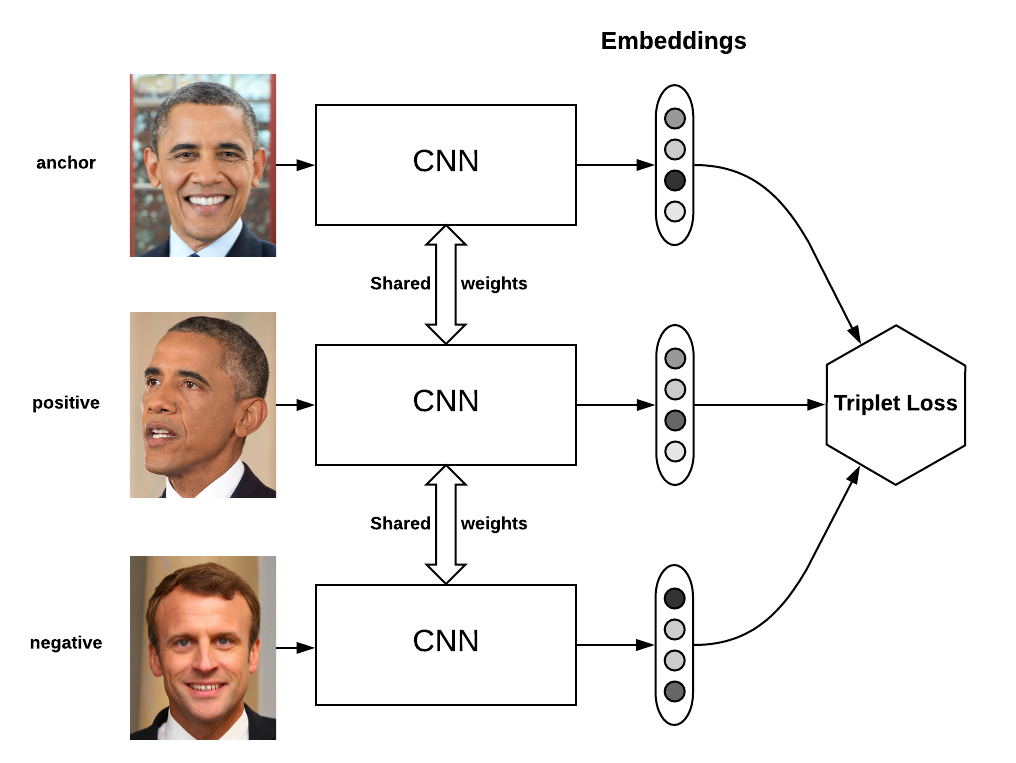
Рабочий процесс FaceNet
Это поможет вам понять формулу для тройной функции потерь.
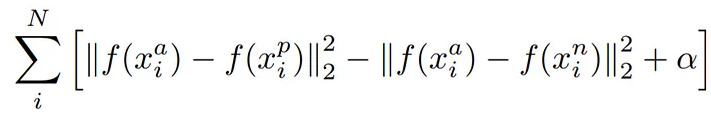
Математическое уравнение триплетной функции потерь.
f (x) принимает x в качестве входных данных и возвращает 128-мерный вектор w.
i обозначает i-й вход.
Нижний индекс a указывает на изображение привязки , p указывает на положительное изображение, n указывает на отрицательное изображение.
Наша цель — минимизировать вышеприведенное уравнение.
Минимизация первого члена → расстояние между якорем и позитивным изображением.
Максимизация (поскольку перед ним отрицательный знак) второго члена → расстояние между якорем и отрицательным изображением.
Третий член — это смещение, которое действует как порог (и здесь его можно игнорировать).
Ну, а теперь, самое интересное, ради чего мы все здесь собрались — реализация обучения модели Triplet Loss на языке Python.
Обучение модели Triplet Loss на MNIST
Загрузка набора данных MNIST
Загружает набор данных MNIST из файлов CSV. Определяет функции, используемые для выборки пакетов из набора данных, и для этого набор данных реорганизуется более удобным способом с помощью словаря, где ключи обращаются ко всем образцам из каждого класса.
Мы допускаем что вы знакомы с библиотеками tensorflow, matplotlib, seaborn и pandas и что для вас не составит труда найти и скачать набор данных MNIST. В любом случае, надеемся, что это будет для вас полезной практикой!
import tensorflow as tf
import pandas as pd
import random
import numpy as np
# Loading dataset
train_images = pd.read_csv("../input/train_images_mnist.csv")
train_labels = pd.read_csv("../input/train_labels_mnist.csv")
test_images = pd.read_csv("../input/test_images_mnist.csv")
test_labels = pd.read_csv("../input/test_labels_mnist.csv")
def reorganizeMNIST(x, y):
assert x.shape[0] == y.shape[0]
dataset = {i: [] for i in range(10)}
for i in range(x.shape[0]):
dataset[y[i]].append(x[i])
return dataset
def get_batch(dataset, k):
# Sample BATCH_K random images from each category of the MNIST dataset,
# returning the data along with its labels
batch = []
labels = []
for l in range(10):
indices = random.sample(range(len(dataset[l])), k)
indices = np.array(indices)
batch.append([dataset[l][i] for i in indices])
labels += [l] * k
batch = np.array(batch).reshape(10 * k, 28, 28, 1)
labels = np.array(labels)
# Shuffling labels and batch the same way
s = np.arange(batch.shape[0])
np.random.shuffle(s)
batch = batch[s]
labels = labels[s]
return batch, labels
train_set = reorganizeMNIST(train_images.values, train_labels.values.reshape(-1))
valid_set = reorganizeMNIST(test_images.values, test_labels.values.reshape(-1))/opt/conda/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_convertersВизуализация вложений t-SNE на необработанных данных
Глядя на вложения t-SNE из необработанных данных пикселей, мы можем получить базовую информацию о том, как данные распределяются, прежде чем какая-либо работа по кластеризации будет выполнена моделью Triplet Loss.
import matplotlib.pyplot as plt
import matplotlib.patheffects as PathEffects
import seaborn as sns
sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context('notebook', font_scale=1.5,
rc={"lines.linewidth": 2.5})
from sklearn.manifold import TSNE
def scatter(x, labels, subtitle=None):
# We choose a color palette with seaborn.
palette = np.array(sns.color_palette("hls", 10))
# We create a scatter plot.
f = plt.figure(figsize=(8, 8))
ax = plt.subplot(aspect='equal')
sc = ax.scatter(x[:,0], x[:,1], lw=0, s=40,
c=palette[labels.astype(np.int)])
plt.xlim(-25, 25)
plt.ylim(-25, 25)
ax.axis('off')
ax.axis('tight')
# We add the labels for each digit.
txts = []
for i in range(10):
# Position of each label.
xtext, ytext = np.median(x[labels == i, :], axis=0)
txt = ax.text(xtext, ytext, str(i), fontsize=24)
txt.set_path_effects([
PathEffects.Stroke(linewidth=5, foreground="w"),
PathEffects.Normal()])
txts.append(txt)
if subtitle != None:
plt.suptitle(subtitle)
plt.show()
# Getting a batch from training and validation data for visualization
x_train, y_train = get_batch(train_set, 32)
x_val, y_val = get_batch(valid_set, 32)
x_train = x_train.reshape(-1, 784)
x_val = x_val.reshape(-1, 784)
# Generating and visualizing t-SNE embeddings of the raw data
# of the first 512 samples.
tsne = TSNE()
train_tsne_embeds = tsne.fit_transform(x_train)
scatter(train_tsne_embeds, y_train, "Samples from Training Data")
eval_tsne_embeds = tsne.fit_transform(x_val)
scatter(eval_tsne_embeds, y_val, "Samples from Validation Data")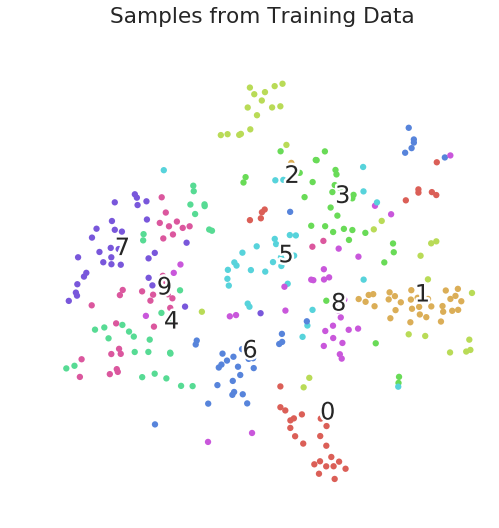
Образцы тренировочных данных
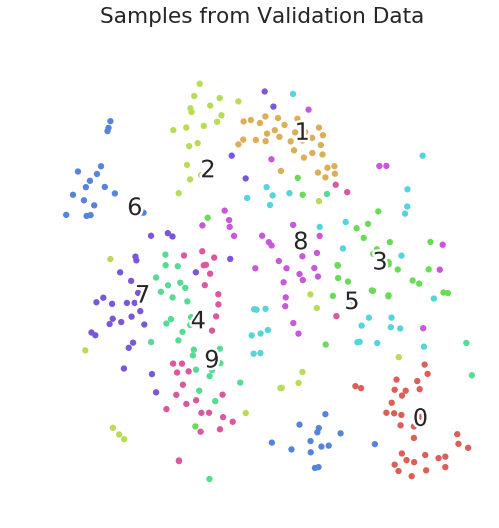
Образцы валидационных данных
Определение функции Triplet Loss и модели внедрения
Функция Triplet Loss определена на основе реализаций FaceNet и In Defense of the Triplet Loss for Person Re-Identification.
В реализацию можно внести множество небольших изменений, таких как определение мягкого поля или использование различных функций расстояния. Эта реализация определяет жесткий запас на уровне 0,2 и использует евклидово расстояние (а не квадратное евклидово расстояние, как в FaceNet) в качестве функции потерь.
#import tensorflow as tf
def all_diffs(a, b):
# Returns a tensor of all combinations of a - b
return tf.expand_dims(a, axis=1) - tf.expand_dims(b, axis=0)
def euclidean_dist(embed1, embed2):
# Measures the euclidean dist between all samples in embed1 and embed2
diffs = all_diffs(embed1, embed2) # get a square matrix of all diffs
return tf.sqrt(tf.reduce_sum(tf.square(diffs), axis=-1) + 1e-12)
TL_MARGIN = 0.2 # The minimum distance margin
def bh_triplet_loss(dists, labels):
# Defines the "batch hard" triplet loss function.
same_identity_mask = tf.equal(tf.expand_dims(labels, axis=1),
tf.expand_dims(labels, axis=0))
negative_mask = tf.logical_not(same_identity_mask)
positive_mask = tf.logical_xor(same_identity_mask,
tf.eye(tf.shape(labels)[0], dtype=tf.bool))
furthest_positive = tf.reduce_max(dists*tf.cast(positive_mask, tf.float32), axis=1)
closest_negative = tf.map_fn(lambda x: tf.reduce_min(tf.boolean_mask(x[0], x[1])),
(dists, negative_mask), tf.float32)
diff = furthest_positive - closest_negative
return tf.maximum(diff + TL_MARGIN, 0.0)
EMBEDDING_DIM = 4 # Size of the embedding dimension (units in the last layer)
def embedImages(Images):
conv1 = tf.layers.conv2d(Images,
filters=128, kernel_size=(7, 7),
padding='same',
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer,
name='conv1')
pool1 = tf.layers.max_pooling2d(conv1,
pool_size=(2, 2), strides=(2, 2),
padding='same',
name='pool1')
conv2 = tf.layers.conv2d(pool1,
filters=256, kernel_size=(5, 5),
padding='same',
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer,
name='conv2')
pool2 = tf.layers.max_pooling2d(conv2,
pool_size=(2, 2), strides=(2, 2),
padding='same',
name='pool2')
flat = tf.layers.flatten(pool2, name='flatten')
# Linear activated embeddings
embeddings = tf.layers.dense(flat,
activation=None,
kernel_initializer=tf.truncated_normal_initializer,
units=EMBEDDING_DIM,
name='embeddings')
return embeddings
# Placeholders for inserting data
Images = tf.placeholder(tf.float32, [None, 28, 28, 1], name='images_ph')
Labels = tf.placeholder(tf.int32, [None], name='labels_ph')
# Embeds images using the defined model
embedded_images = embedImages(Images)
# Measure distance between al embeddings
dists = euclidean_dist(embedded_images, embedded_images)
# Calculate triplet loss for the give dists
loss = tf.reduce_mean(bh_triplet_loss(dists, Labels))
global_step = tf.Variable(0, trainable=False, name='global_step')
learning_rate = tf.train.exponential_decay(0.001, global_step, 5000, 0.96, staircase=True)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_step = optimizer.minimize(loss=loss, global_step=global_step)/opt/conda/lib/python3.6/site-packages/tensorflow/python/ops/gradients_impl.py:100: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "Обучение модели на 5000 эпохах
Теперь мы в течение некоторого времени подаем модели некоторые данные, а затем визуализируем вложения результатов с помощью t-SNE.
with tf.Session() as sess:
tf.global_variables_initializer().run()
loss_hist = []
lr_hist = []
# Train for 5000 epochs
for i in range(5000):
data, labels = get_batch(train_set, 8)
feed_dict = {Images: data, Labels: labels}
_, lr, raw_loss, embeddings = sess.run([train_step,
optimizer._lr, loss, embedded_images], feed_dict)
lr_hist.append(lr)
loss_hist.append(raw_loss)
# Training is finished, get a batch from training and validation
# data to visualize the results
x_train, y_train = get_batch(train_set, 32)
x_val, y_val = get_batch(valid_set, 32)
# Embed the images using the network
train_embeds = sess.run(embedded_images,
feed_dict={Images: x_train, Labels:y_train})
val_embeds = sess.run(embedded_images,
feed_dict={Images: x_val, Labels: y_val})
tsne_train = tsne.fit_transform(train_embeds)
tsne_val = tsne.fit_transform(val_embeds)
scatter(tsne_train, y_train, "Results on Training Data")
scatter(tsne_val, y_val, "Results on Validation Data")
Результаты по тренировочным данным

Результаты по проверочным данным
Выводы
Вот так вместе с вами мы смогли разобрать такую очень интересную тему машинного обучения, как функцию тройных потерь (Triplet Loss) и даже произвести обучение модели на наборе данных MNIST.
