[Перевод] 5 млн долларов за строчку кода: подробный разбор сбоя сервисов Datadog
В марте сервисы Datadog не работали более суток. Что пошло не так, как отреагировала команда инженеров, и что можно извлечь из этого инцидента? Это перевод эксклюзивного исследования, которое провел Гергели Орош (Gergely Orosz), консультант mobile.dev, автор нескольких книг по работе с инфраструктурой, в прошлом — инженер в Uber, Skype, Microsoft.
Оригинал опубликован в рамках серии «Реальные инженерные кейсы», выпуск №8. Серия публикуется в информационном бюллетене Pragmatic Engineer. В каждом выпуске Гергели исследует интересные инциденты, которые происходили в Big Tech и стартапах.
Datadog предлагает решения для мониторинга сервисов и приложений, а также для оповещения команд при возникновении аномалий. Такие observability-услуги помогают отслеживать надежность работы сервисов, а их отказ обычно негативно влияет на бизнес. В среду, 8 марта 2023 года, подобный отказ произошел у Datadog — проблемы со стабильностью наблюдались более 24 часов. Инцидент обошелся компании недешево: по данным опубликованного позднее квартального отчета упущенная выгода составила $5 млн. Убыток равен приблизительно доходу компании за день. Причина убытков кроется в системе тарификации Datadog: компания берет деньги за объем переданных данных или количество логов, и, скорее всего, во время инцидента деньги с клиентов не взимали.
Мартовский инцидент стал первым глобальным сбоем в работе Datadog: одновременно пострадали все регионы, в которых работает компания, а с простоем столкнулись все клиенты. Прошло более 2 месяцев, но Datadog до сих пор не опубликовала постмортем, что нетипично для столь резонансных инцидентов. Неделю назад я связался с Datadog по поводу этой задержки: мне сказали, что более подробная информация будет опубликована, но не уточнили, когда именно.
Смущает и то, что 4 мая на пресс-конференции по итогам квартала генеральный директор компании Оливье Помель заявил, что постмортем был опубликован и рекомендовал всем с ним ознакомиться:
«Мы поделились некоторой информацией о том, что произошло, и выпустили постмортем. Рекомендую всем с ним ознакомиться, потому что документ получился захватывающим».
Однако на момент этого заявления в открытом доступе не было никакого постмортема! Я поинтересовался у представителей Datadog, не оговорился ли генеральный директор, и, если нет, где этот постмортем находится, ведь предполагается, что увидеть его может каждый. Ответа, к сожалению, я не дождался, хотя предпринял несколько попыток его получить.
Зато мне удалось получить два постмортема, предназначенных для ряда клиентов Datadog. Они и легли в основу этого исследования.
Что будет в статье:
Рассмотрим хронологию событий, концепции TTD, TTM, TTR, оценим работу Datadog по этим метрикам.
Совершим глубокое погружение в обновление ОС, вызвавшее сбой. Обсудим CVEs, переполнение буфера, поговорим о системном процессе и системных дампах. А еще о том, почему необходимо проверять changelog’и операционных систем. Возможно, компания Datadog упустила нечто критическое перед обновлением?
Попытаемся понять, что на самом деле вызвало перебои в работе. Разберем тонкости работы
systemd-networkdи попробуем представить, что происходит при одновременном создании десятков тысяч виртуальных машин.Разберемся, почему размещение инфраструктуры в 5 регионах у 3 разных облачных провайдеров не помогло. Вообще, перебои в работе сервисов вроде Datadog недопустимы, поэтому инфраструктура была диверсифицирована. Так как же вышло, что все регионы в AWS, GCP и Azure упали одновременно, хотя прямого соединения между ними не было?
Обсудим меры, предпринятые компанией. Что сделала Datadog, чтобы избежать очередной волны обновлений?
Поговорим о проблемах в коммуникациях во время падения. Datadog не сумела правильно выстроить общение с клиентами. С каким-то пользователями поддержка поработала отлично, другие же не получили ничего — ни постмортемов, ни рекомендаций. Как так вышло?
Извлечем из всего этого урок. Какую пользу другие инженерные команды могут вынести из этой ситуации?
Примечание: через несколько часов после выхода этой статьи Datadog наконец-то опубликовала свой постмортем. Им оказался тот самый документ, который они разослали ряду своих клиентов 2 месяца назад — в районе 20–22 марта 2023 года. Это один из двух постмортемов, которые я использовал при подготовке материала. В нем можно узнать о конкретных шагах по восстановлению сервиса — в статье я не рассматриваю их ради экономии времени. Остается загадкой, почему компания два месяца ждала, прежде чем обнародовать постмортем, который был давно готов, и почему она пренебрегает культурой прозрачности.
1. Хронология событий и TTD, TTM, TTR
Я буду использовать центральноевропейское летнее время (CEST), так как основная часть инженеров Datadog находится в этом часовом поясе. Однако для удобства читателей в скобках я буду приводить и североамериканское восточное время (EST).
8 марта, 07:00 CEST (01:00 EST): На десятках тысяч виртуальных машин (ВМ) обновляется операционная система. Эти машины начинают таинственным образом исчезать из сети.
07:03, CEST (01:03 EST): Срабатывает первый внутренний алерт из-за аномалии с одной из метрик.
07:18 CEST (01:18 EST): Оперативная группа начинает выяснять ситуацию.
07:31 CEST (01:31 EST): Клиенты получают уведомление об инциденте:
«Мы выясняем причины проблем с работой нашего веб-приложения. В результате у некоторых пользователей могут возникать ошибки или возрастать задержки».
Время до обнаружения (time until detection, TTD) — 31 минута. При инциденте TTD указывает, сколько времени прошло с его начала до того, как он подтвержден дежурной командой и объявлено о перебоях в работе.
В книге Seeking SRE Мартин Чек (Martin Check) описывает эту метрику следующим образом:
«Время до обнаружения — время от начала инцидента до момента, когда его фиксирует оператор. Счетчик запускается, когда инцидент впервые становится заметен для клиента, даже если мониторинг его не обнаружил. Часто это время совпадает со временем нарушения соглашения об уровне обслуживания (SLA).
Верьте или нет, но TTD является наиболее важной метрикой для инцидентов, требующих ручного вмешательства. Она определяет эффективность и точность вашего мониторинга. Если вы не узнаете о проблемах клиента, то не сможете начать процесс восстановления и не внедрите автоматизированные решения для реагирования или смягчения последствий. Но возможно, еще важнее другое следствие: клиенты не получат уведомления о том, что команда знает о проблеме и пытается ее устранить. Задача TTD — сбалансировать чувствительность мониторинга таким образом, чтобы быстро и точно обнаруживать все проблемы на стороне клиентов, не отвлекая инженеров на решение вопросов, которые на клиентов не влияют».
08:23 CEST (02:23 EST): Обнаружено потенциальное негативное влияние на ввод и мониторинг данных. Клиентам приходит сообщение от Datadog:
«Выясняем причины задержки с приемом всех типов данных. Оповещения мониторинга могут поступать с опозданием. Кроме того, могут наблюдаться задержки при обработке данных в веб-приложении».
Напрашивается вопрос: не должен ли тогда ТТD составлять 1 час 23 минуты вместо 31 минуты? Datadog объявила об инциденте через 31 минуту после его начала, но о том, что основная функциональность по вводу и мониторингу данных нарушена, сообщила клиентам лишь спустя 1 час 23 минуты.
21:39 CEST (15:39 EST): Через 14 часов после начала инцидента в его хронологии появилось первое более подробное описание:
«Ожидаем возобновления работы с данными в течение нескольких часов (не минут и дней)».
9 марта 9:58 CEST (03:58 EST): Объявлено о возобновлении работы всех сервисов. При этом обработка данных по-прежнему ведется с задержками (это связано с большими объемами накопившейся информации).
10 марта 06:25 CEST (00:25 EST): Инцидент полностью устранен, все накопившиеся данные обработаны.
Время на устранение последствий (TTM) — период времени с начала инцидента до перехода сервисов в статус healthy. В случае с Datadog восстановление работоспособности сервисов заняло 1 сутки 2 часа 58 минут, а полное устранение инцидента — 1 сутки 23 часа 25 минут. В Seeking SRE схема метрики TTM выглядит так:
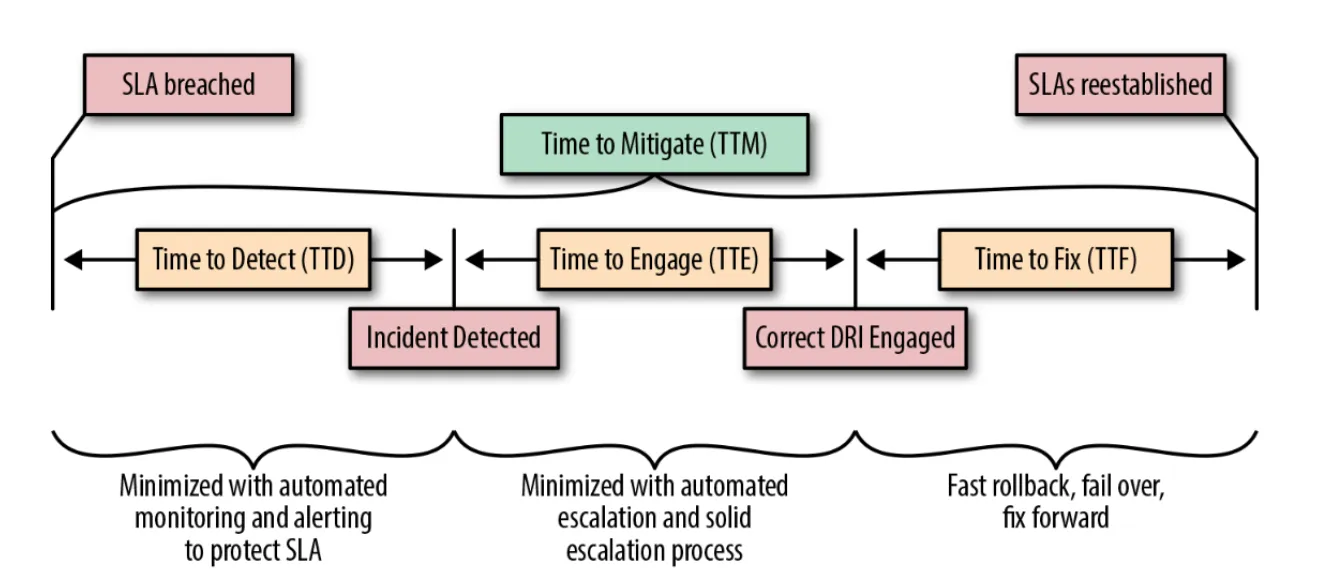
«Время на устранение последствий включает в себя время до обнаружения (TTD), время на привлечение инженера или инженерной группы (time to engage, TTE) и время на починку (time to fix, TTF). Определить TTE обычно сложно, поэтому в большинстве инцидентов эта информация не фиксируется. Отслеживать TTE полезно, чтобы выявить, в каких случаях трудно оперативно привлечь инженеров, отвечающих за конкретную систему».
Источник: Seeking SRE
Время на восстановление (time to remediate, TTR): пока неясно. После устранения последствий инцидента инженерным группам часто приходится решать один или несколько вопросов:
Как сократить время обнаружения инцидента в будущем? Обычно это подразумевает улучшение мониторинга и уменьшение числа «пустых» алертов.
Как сократить время на устранение последствий для следующего инцидента? Для этого может потребоваться совершенствование систем, передача их во владение дежурным командам, совершенствование ранбуков (runbooks), внесение изменений, позволяющих автоматизировать откат изменений, и так далее.
Внесение изменений, направленных на устранение системных первопричин инцидента. Проводятся ли автоматизированные тесты, внедряются ли в процесс ручные операции или другие изменения, способные решить системные проблемы, лежащие в основе инцидента? Общие подходы включают в себя автоматическое канареечное тестирование и откат, статический анализ, автоматизированные тесты (например, модульные, интеграционные или сквозные), применение staging-окружений.
Чем серьезнее последствия сбоя, тем больше времени может занять работа по устранению его причин. Это связано с тем, что серьезные падения могут послужить стимулом, чтобы внести сложные и трудоемкие изменения, повышающие надежность работы системы в будущем.
2. Разбираемся с обновлением ОС, вызвавшим сбой
Причиной сбоя в работе Datadog стало обновление операционной системы. На виртуальных машинах работает Ubuntu Linux, дистрибутив которой регулярно обновляется до последней версии. Проблема возникла во время обновления до версии 22.04, которое включало обновление безопасности systemd.
systemd отвечает за запуск сервисов в Linux и управление ими. Это первый процесс, который выполняется после загрузки ядра Linux, ему присваивается ID 1. systemd запускает инициализацию пользовательского пространства, а также сервисы во время работы Linux. То есть он является основой всех операционных систем на базе Linux.
Ниже вы видите примечания к обновлению от 2 марта 2023 года. Именно это обновление ОС — и одно из двух изменений в systemd — вызвало проблемы у Datadog несколько дней спустя:
"SECURITY UPDATE: buffer overrun vulnerability in format_timespan()
- debian/patches/CVE-2022-3821.patch: time-util: fix buffer-over-run
- CVE-2022-3821
SECURITY UPDATE: information leak vulnerability in systemd-coredump
- debian/patches/CVE-2022-4415.patch: do not allow user to access coredumps with changed uid/gid/capabilities
- CVE-2022-4415”Давайте проанализируем эти примечания и попытаемся понять причину падения виртуальных машин Datadog. Первое, что бросается в глаза, — идентификатор CVE под обоими фиксами.
Что такое CVE? Common Vulnerabilities and Exposures (CVE) — обнародованный список уязвимостей в системе безопасности. Программа CVE реализуется корпорацией MITRE при финансовой поддержке Министерства внутренней безопасности США. Идентификаторы CVE — надежный способ распознавания уязвимостей и координации исправлений между вендорами. В случае с Linux, учитывая количество ее разновидностей вроде Red Hat, Ubuntu или Debian, CVE помогают определить, какой дистрибутив устранил определенные уязвимости. Просмотреть все CVE можно на домашней странице списка, есть даже аккаунт в Twitter с перечнем последних обнаруженных CVE. Список длинный и пополняется ежечасно.
Исправление переполнения буфера
Первое исправление касалось CVE-2022–3821 — переполнения буфера. Оно происходит, когда программа пишет данные в буфер, но выходит за пределы памяти, выделенной для нее. При этом она перезаписывает соседние участки памяти, принадлежащие другим программам.
Переполнение буфера влияет на рантайм работающей программы. Переполнение буфера в systemd может привести к непредсказуемому поведению процесса или его аварийному завершению:
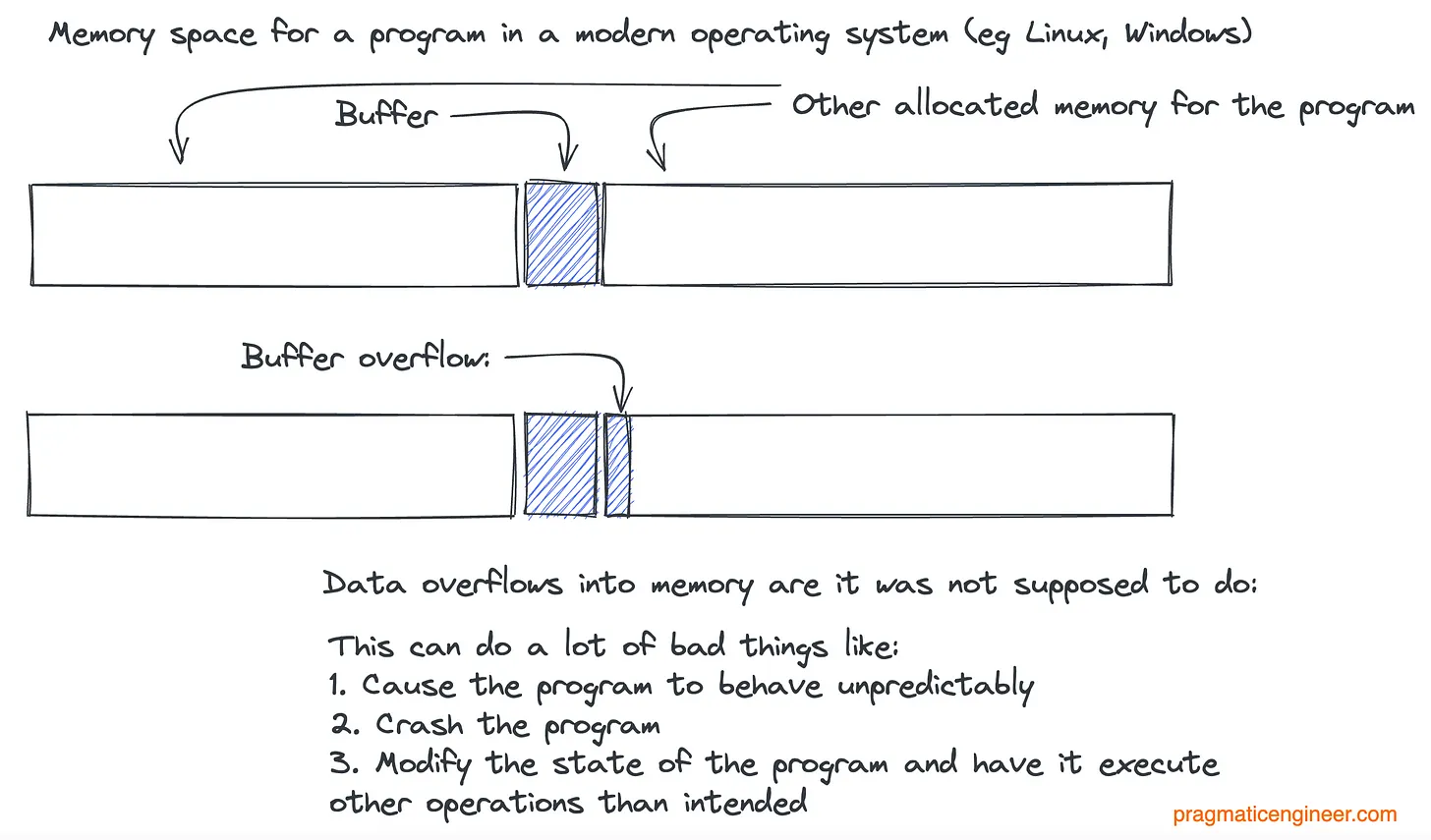
Переполнение буфера. Распространенная уязвимость и потенциальный вектор атаки
Более изощренный способ эксплуатации переполнения буфера предполагает использование этого изъяна для выполнения кастомного кода. Например, можно заставить программу перейти по адресу в область памяти, которую контролирует злоумышленник, и выполнить вредоносный код (спасибо Seebs за исправления в этой части!).
В случае systemd злоумышленник может «скормить» определенные значения времени и степени точности, которые приведут к выходу за пределы буфера в format_timespan() и последующему аварийному завершению работы systemd. Поскольку systemd управляет всеми процессами, его выход из строя означает падение всей операционной системы (kernel panic). Злоумышленник может вставить определенные даты во входные данные, парсируемые методом format_timespan() в systemd, и вызвать отказ в обслуживании и системный сбой.
Вот фикс для этой уязвимости:

Хотя изменения коснулись всего одной строки (и трех строк в тестах), нужно приложить немало усилий, чтобы понять, что тут происходит. Отчасти это связано с тем, что метод format_timespan занимает сотню строк, а задействованные в нем переменные типа i, j, k, l, m, n плохо документированы. В результате трудно понять, что именно они делают. К счастью, соответствующий issue ставит все на свои места:
«Проблема с кодом выше в том, что n = MIN ((size_t) k, l) может присвоить n размер буфера l. Тогда p += n; это приведет к тому, что p будет указывать на байт после буфера buf, что приведет к перезаписи буфера в *p=0 (ошибка на единицу)».
Этот CVE — еще одно свидетельство того, как трудно писать безопасный код: классическая ошибка на единицу обнаруживается спустя годы после ее появления!
Могло ли исправление переполнения буфера привести к проблемам? Маловероятно, поскольку оно закрывает вектор атаки, который в ином случае привел бы к падению системы.
Исправление уязвимости, связанной с утечкой информации
Второе исправление касалось CVE-2022–4415 — уязвимости, при которой systemd-coredump не соблюдал параметр ядра fs.suid_dumpable.
systemd-coredump — это утилита, входящая в состав systemd. Она обрабатывает дампы ядра — файлы, содержащие состояние памяти и регистров процесса на момент завершения программы. Дампы ядра могут быть полезны при отладке, поскольку это точный снимок системы в момент сбоя.
С помощью переменной suid_dumpable можно настроить, какая именно информация будет добавляться в файл дампа ядра. Возможны следующие варианты:
1 (
default): процессы, которые изменили уровни привилегий или являютсяexecute-only, не будут выгружаться в дамп.2 (
debug): все процессы выгружают данные в дамп при первой возможности. Это небезопасно, так как позволяет обычным пользователям изучать содержимое памяти привилегированных процессов.3 (
suidsafe): применяется, когда администраторы пытаются отладить проблемы в нормальной среде.
Проблема была в том, что по умолчанию использовался второй режим, то есть сбрасывались все процессы — даже те, для которых у пользователя нет привилегий на просмотр.
Могло ли устранение уязвимости, которая потенциально приводила к утечке информации, вызвать проблемы у Datadog? Вряд ли. Сложности могли бы возникнуть, если бы некие процессы анализировали дампы ядра упавших процессов. Они бы просто лишились доступа к подробностям об использовании памяти root-процессами.
3. Что на самом деле вызвало перебои в работе
Обновления systemd были относительно безобидными в контексте работы тысяч виртуальных машин. Они лишь делали дистрибутив Linux более безопасным. И, как оказалось, ни одно из обновлений systemd не было непосредственной причиной сбоя.
Проблема была в принудительном выкате исправлений. systemd — это процесс №1, и, если что-то меняется во время обновления, он перезапускается сам и делает то же самое со своими дочерними процессами. Это не полная перезагрузка, но последствия могут быть похожими.
Именно здесь и проявилась проблема:
Обновление безопасности внесло изменения в процесс
systemd, который является главным в Linux.Когда
systemdперезапустился, все его подпроцессы, включаяsystemd-networkd, также перезапустились.systemd-networkdуправляет сетевыми конфигурациями. Из-за перезапускаsystemdбыл перезапущенsystemd-networkd. В результате были непреднамеренно удалены сетевые маршруты.Маршрутами, которые удалил
systemd-network, управлял слой контейнерной маршрутизации Cilium на базе eBPF (extended Berkeley Packet Filter). Cilium обеспечивает связь между контейнерами. Сетевой слой Datadog управляет кластерами Kubernetes.Из-за удаления маршрутов виртуальные машины (узлы) просто исчезли из сетевого управляющего слоя (network control plane) и перешли в офлайн.
Ранее удаления маршрутов при обновлении
systemdне происходило. Это объясняется тем, что при запуске нового узла на нем не было сохраненных маршрутов. То есть запускsystemd-networkdс нуля ничего не стирал.
Проблема заключалась в том, что обновление происходило почти одновременно на десятках тысяч виртуальных машин. Но самой страшной оказалась потеря сетевого управляющего слоя.
В условиях круговой зависимости перезагрузка также привела к отключению слоя, управляющего маршрутизацией сети. Выпадение узлов из управляющего слоя неприятно, но их можно быстро вернуть обратно. Однако главная проблема была в другом. Постмортем ее описывает:
«Среди виртуальных машин, которые были выведены из строя этим багом, были те, что обеспечивают работу наших региональных управляющих слоев [на базе Cilium]. Это привело к тому, что большинство кластеров Kubernetes не могли планировать новые рабочие нагрузки, автоматически восстанавливаться и масштабироваться.
В результате мы постепенно начали лишаться мощностей. К [08.31 CEST] процесс приобрел такой масштаб, что стал заметен для [клиентов]».
Давайте наглядно представим, что произошло. Начальное состояние региона:
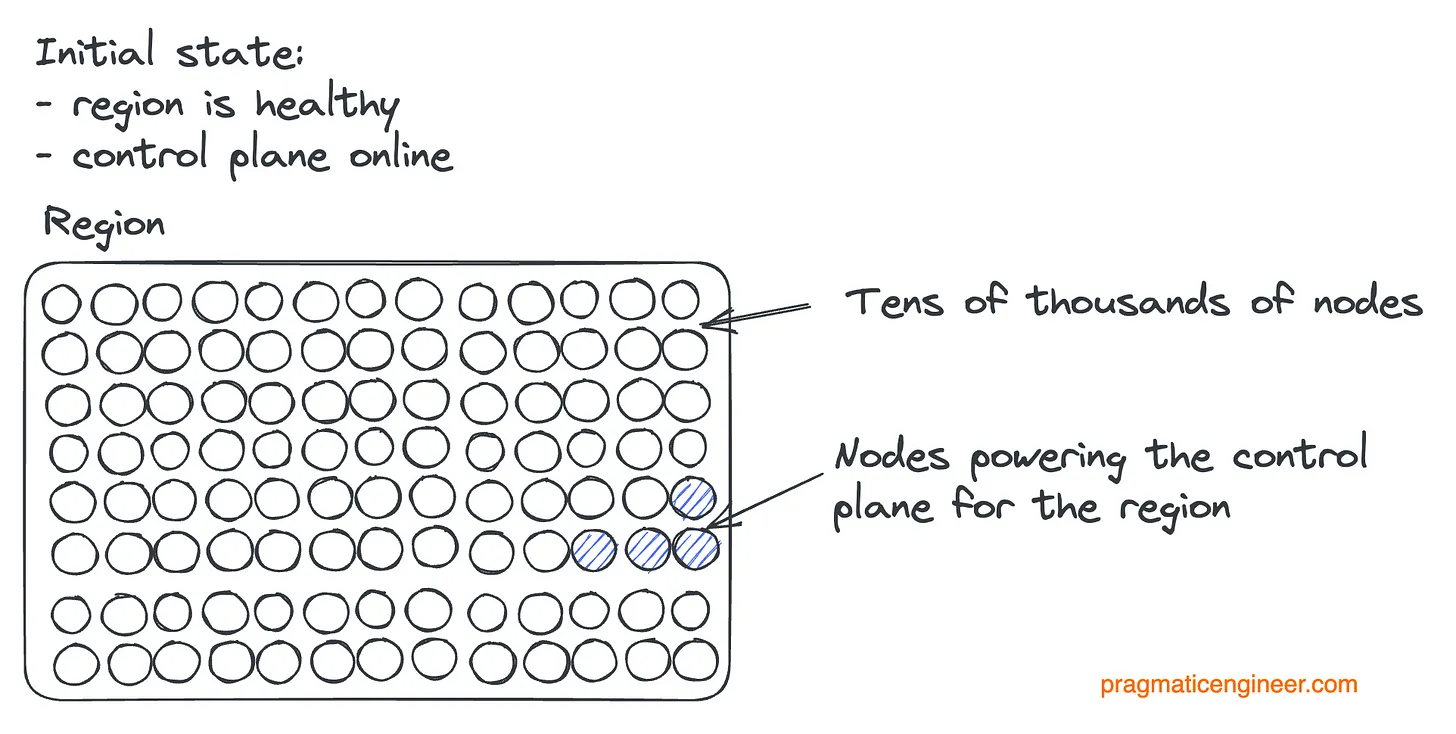
Первое обновление systemd; часть узлов стала недоступна:
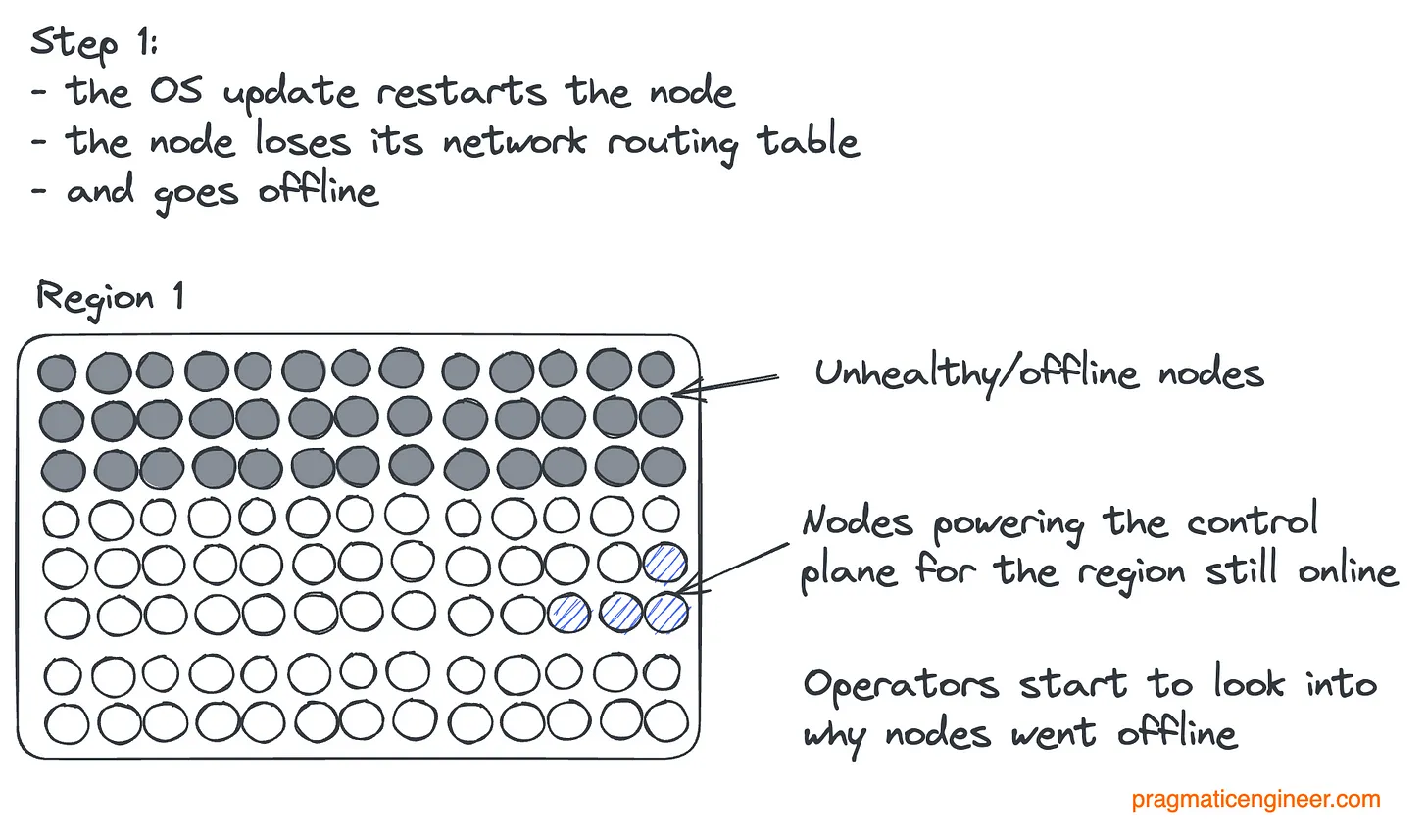
Обновление продолжается; часть узлов управляющего слоя выведена из строя:
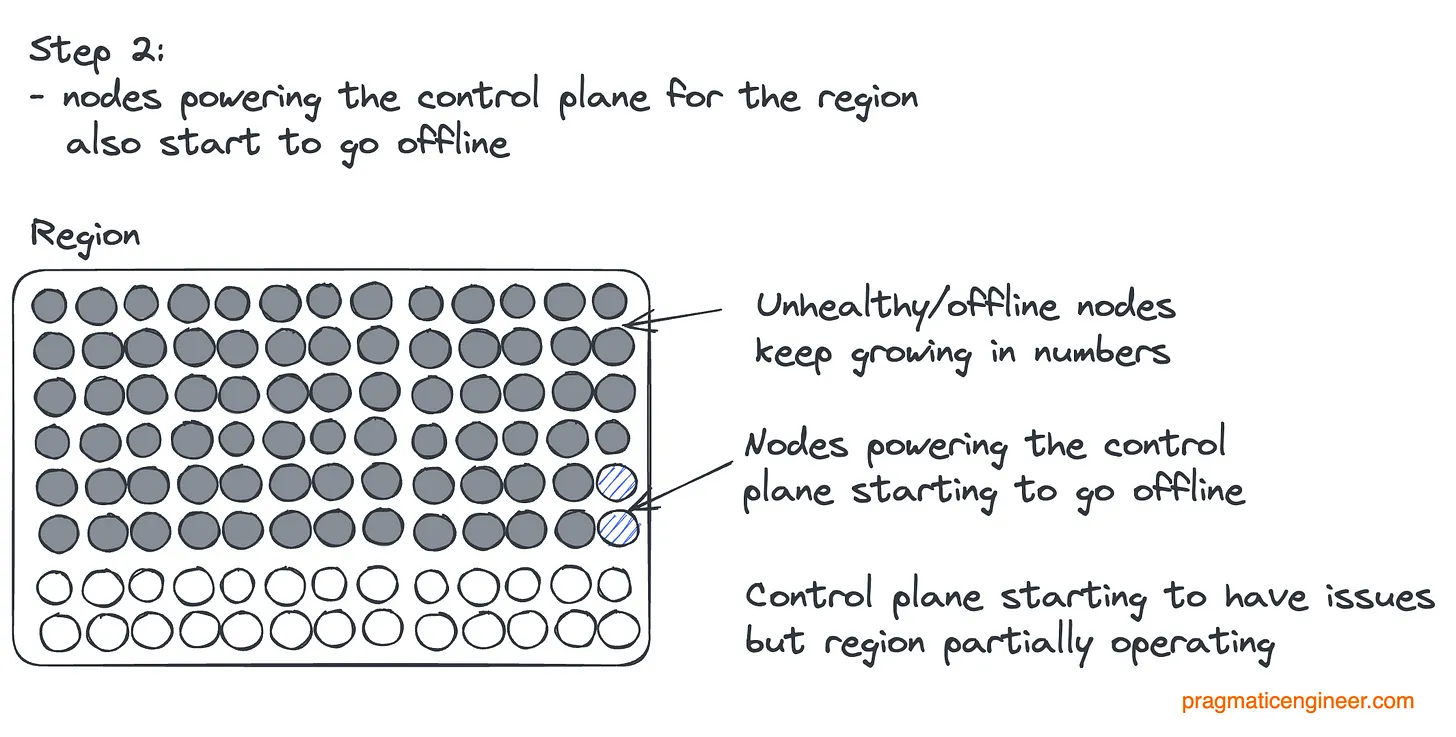
Наконец, все узлы управляющего слоя выведены из строя, регион перестает работать:
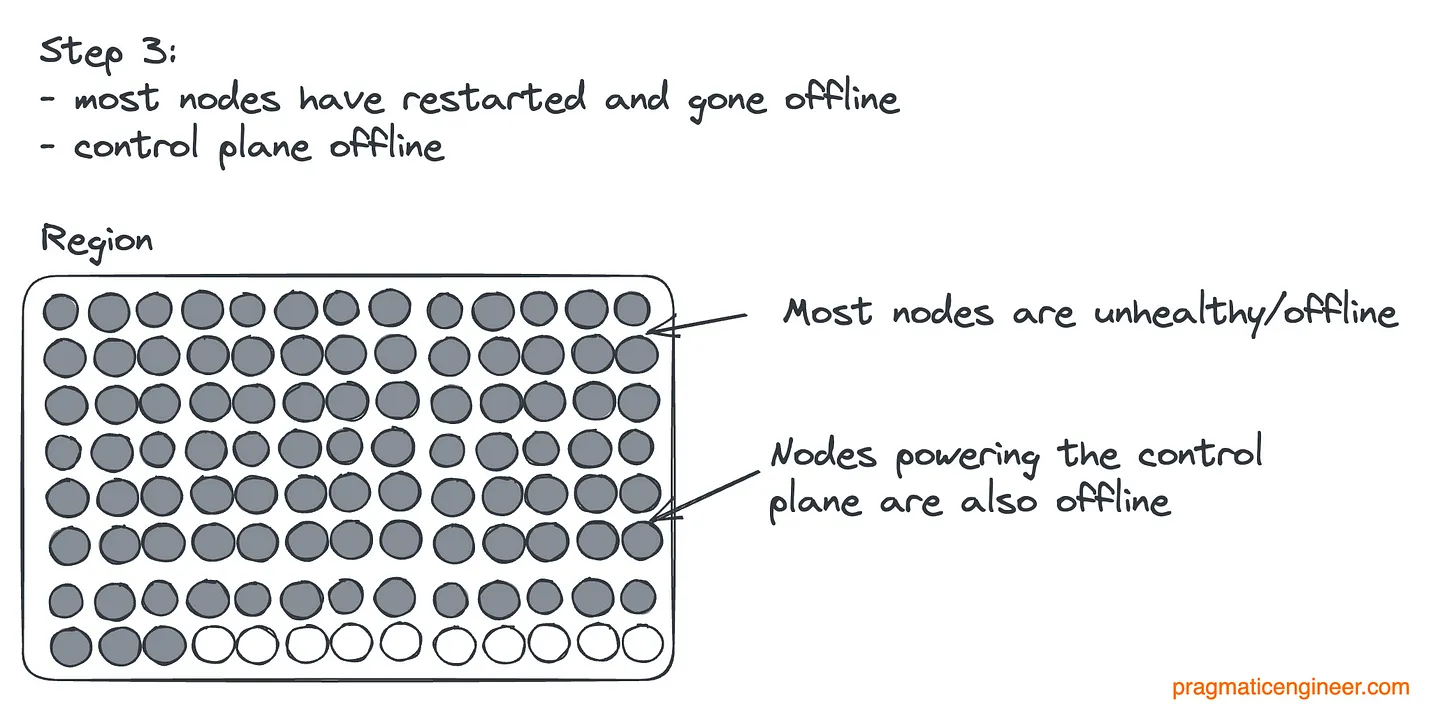
То есть истинной проблемой стало отключение управляющего слоя. Если бы его узлы остались в строю, оно, скорее всего, было бы кратковременным. В этом случае Datadog могла просто добавить пропавшие узлы в маршруты. Отказ управляющего слоя привел к тому, что в первую очередь необходимо было вернуть в строй его и выяснить, почему он вообще исчез.
Такая круговая зависимость, когда компонент, управляющий инфраструктурой, зависит от управляемой им инфраструктуры, напоминает то, что произошло с Roblox в октябре 2022 года (видеоигра не работала три дня подряд). Тогда возникла похожая зависимость: отвечавший как оркестрацию контейнеров Nomad и сервис для управления секретами Vault использовали для обнаружения сервисов Consul. Когда Consul отвалился, за ним последовал и Vault. В свою очередь, Vault был необходим для работы Consul — порочный круг.
Можно ли было предсказать подобное развитие событий? Хотя произошедшее легко анализировать задним числом, все же стоит задаться вопросом: можно ли было спрогнозировать, что systemd и systemd-networkd способны поломать маршруты Cilium?
После публикации этой статьи инженер-программист Дуглас Камата (Douglas Camata) из Red Hat отметил, что Cilium и systemd известны своими сбоями при обновлении ОС. Например, issue, описывающий, как обновление systemd ломает сетевой трафик Cilium, оставался открытым с марта 2020 года по июнь 2022-го.
Однако проблема, о которой идет речь, была исправлена в Cilium за 9 месяцев до сбоя Datadog (фикс вошел в релиз 1.10.13 Cilium). Инженер, знакомый с этим проблемами, мог бы насторожиться, узнав, что скоро выйдет обновление ОС, вносящее изменения в systemd. При этом не похоже, что кто-то мог предсказать, какое влияние окажет обновление systemd на пути в Cilium. Для этого описываемый сценарий обновления нужно было протестировать.
4. Почему не помогла работа в 5 регионах у 3 разных облачных провайдеров?
К чести Datadog, ряд практик компании должен был сделать такой сбой невозможным:
1. Запрет на одновременное применение патчей безопасности. Комментарий из постмортема:
«Выкат нового кода, исправлений безопасности или измененной конфигурации проходит последовательно регион за регионом, кластер за кластером, узел за узлом. Что касается процесса, мы не применяем изменения in situ (в месте нахождения); наоборот, узлы и контейнеры заменяются по принципу синих/зеленых развертываний. Для неудачных изменения происходит автоматический откат. Мы уверены в таком подходе, потому что он применяется десятки раз в день».
2. Распределение инфраструктуры по 5 регионам и 3 облачным провайдерам. Datadog не привязывает инфраструктуру к единственному провайдеру. Основываясь на этой информации, я провел обратный поиск IP-адресов центров обработки данных и облачных провайдеров, которых они, скорее всего, используют. Вот что получилось:
AWS для US1 (Восточное побережье США; вероятно, используется дата-центр AWS us-east-1) и для AP1 (Япония; по всей видимости, используется дата-центр AWS ap-northeast-1 вблизи Токио);
Google Cloud для EU1 и US5;
Azure для US3 (западное побережье США; вероятно, задействован центр обработки данных Microsoft в Куинси).
У каждого облачного провайдера Datadog использует несколько регионов и работает с десятками зон доступности.
Учитывая все это, возникает вопрос: как с такими мерами предосторожности рядовое обновление ОС «поубивало» все виртуальные машины и переросло в глобальный сбой? Инциденты такого рода должны выявляться на уровне виртуальных машин или, в крайнем случае, кластеров. Даже если один облачный провайдер потребует незамедлительной установки патча на все виртуальные машины, у остальных политика наверняка будет иной.
Похоже, Datadog использует облачных провайдеров как Infrastructure as a Service для своих машин и запускает собственные виртуальные образы поверх одного и того же образа ОС у разных облачных провайдеров. И в этом есть корень проблемы. Из постмортема:
«В базовом образе ОС, который мы используем для запуска Kubernetes, был включен устаревший канал обновления безопасности, это привело к автоматическому применению обновления. Мы используем минималистичные базовые образы ОС, поэтому такие обновления происходят нечасто.
Ситуацию усугубило то, что время, в которое происходит автоматическое обновление, по умолчанию установлено в ОС на окно между 06:00 и 07:00 UTC (всемирное координированное время)».
В этом и заключалась проблема.
Все виртуальные машины Datadog обновились в течение часа и перезапустили systemd. Причем произошло это у всех трех облачных провайдеров и во всех пяти регионах, хотя сетевая связанность между регионами отсутствовала. Конфигурация была одной и той же. Часовой пояс обновления не был привязан к региону — везде использовался UTC.
Справедливости ради стоит отметить, что подобные открытия — редкость вне таких глобальных инцидентов. Как отмечается в постмортеме, автоматические обновления случаются нечасто и обычно не требуют перезапуска ключевого системного процесса — systemd.
Последний раз обновление безопасности для systemd выходило более года назад, в январе 2022-го. Оно могло вызвать такую же проблему с перезапуском systemd-networkd и очисткой таблиц маршрутизации. Похоже, в январе 2022-го у Datadog была другая инфраструктура: например, использовалась другая ОС для Kubernetes-кластера.
Datadog обеспечила избыточность инфраструктуры, разбросав ее по трем вендорам. Любопытно, что это как раз усложнило восстановление после сбоя. Вот что по этому поводу пишут в постмортеме:
«У некоторых облачных провайдеров логика автоматического масштабирования правильно определила пострадавший узел как нездоровый, но не инициировала его немедленный вывод из эксплуатации. В этом случае помогла бы простая перезагрузка пострадавшего инстанса. Она прошла бы намного быстрее для stateful-рабочих нагрузок, данные которых оставались в целости и сохранности, тем самым ускорив процесс восстановления.
Логика автоматического масштабирования других облачных провайдеров сразу заменяет нездоровый узел на новый. Данные на нездоровом узле теряются и их необходимо восстанавливать, что сильно усложняет задачу. Одновременная замена десятков тысяч узлов привела к возникновению «громогласного стада» (thundering herd), которое испытывало на прочность региональные ограничения скорости облачного провайдера различными способами, ни один из которых [на тот момент] не был очевиден заранее».
То есть работать оказалось проще с облачными провайдерами, которые не пытались мудрить по поводу нездоровых узлов. На них уже была таблица маршрутизации — достаточно было загрузить ее в systemd-networkd. Datadog могла бы просто перезапустить узлы. Усугубили ситуацию именно те провайдеры, которые при первых признаках нездоровья запускали новый узел и избавлялись от старого, нездорового.
Под «громогласным стадом» понимается ситуация, когда большое количество потоков, процессов или виртуальных машин одновременно становятся доступными и нагружают систему, конкурируя за ее ресурсы. В нашем случае нагрузка пришлась на ресурсы облачного провайдера, которому пришлось одномоментно запустить десятки тысяч виртуальных машин.
Классическое решение проблемы «громогласного стада» заключается в том, чтобы установить какой-то механизм очередей или ожидания. С ним все ВМ не запускаются одновременно, некоторое их количество стартует поэтапно. Конечно, об этом легко рассуждать сейчас, когда проблема уже решена.
5. Предпринятые меры
После устранения последствий сбоя команда Datadog предприняла ряд шагов, чтобы исключить его повторение:
Сделала образы ОС устойчивыми к обновлениям
systemd. Одной из причин сбоя было то, что из-за обновления systemd были удалены таблицы маршрутизации. Datadog внесла изменение в конфигурациюsystemd-networkd: после обновления systemd таблицы маршрутизации, необходимые для Cilium, больше не удаляются.
Отключила автоматические обновления. Устаревший канал обновлений безопасности в базовом образе Ubuntu был отключен во всех регионах. Отныне все обновления, включая обновления безопасности, будут выкатываться вручную и контролируемым образом.
У тех, кто интересуется вопросами безопасности, второй пункт может вызвать закономерные вопросы. Не скажется ли он на безопасности? Учитывая, что Datadog уже изменила свой сервис, сделав его устойчивым к обновлениям ОС, не следует ли оставить автоматические обновления включенными?
По словам команды, их отключение не влияет на уровень безопасности. Инженеры просматривают и применяют обновления безопасности на уровне ОС и не полагаются на автоматические обновления.
На мой взгляд, Datadog поступает мудро, отказываясь от автоматических обновлений, способных одновременно перезагрузить весь парк машин. Я бы рекомендовал оставлять автоматические обновления включенными только тем компаниям, которые не обновляют свой стек или инструменты вручную.
6. Проблемы с коммуникацией во время сбоя
Я поговорил с клиентами Datadog, пострадавшими от сбоя, и изучил сообщения об инциденте. Вот мои мысли насчет того, как все прошло с точки зрения информирования клиентов и общественности и что именно пошло не так.
Коммуникацию можно назвать приемлемой. Datadog незамедлительно объявила об инциденте. Также компания публиковала обновленную информацию.
Про глобальный сбой, затрагивающий всех клиентов, объявили через 31 минуту. Скорость, конечно, не впечатляет, но, учитывая постепенную деградацию сервиса, время отклика можно назвать нормальным. С другой стороны, потребовалось около полутора часов, чтобы оповестить клиентов о проблемах с приемом данных и мониторингом — слишком долго для сбоя такого масштаба.
После этого обновления выходили сравнительно часто — примерно каждый час. К сожалению, часто они просто копировали ранее опубликованные:

Сообщения о сбое в работе Datadog, опубликованные за четыре часа. Сводки выходили часто, но обычно просто копировали предыдущее сообщение без каких-либо новых сведений и конкретики. Кроме того, в них ничего не говорилось о том, что могут и должны делать клиенты.
Например, 14 сообщений подряд были вариацией фразы: «Наблюдается задержка при получении данных и обработке оповещений мониторинга для всех типов данных». Формально такие обновления удовлетворяли спрос на регулярное информирование, но в действительности не содержали никаких новых сведений для клиентов.
Первое значимое публичное сообщение команды Datadog появилось через 14 часов после инцидента. В нем было:
Представлено высокоуровневое резюме проблемы: «Обновление системы на ряде узлов, управляющих нашими вычислительными кластерами, привело к тому, что часть этих узлов потеряла сетевое соединение».
Описан текущий статус: «Мы выявили и устранили первоначальную проблему и перестроили наши кластеры (…) Работа по восстановлению в настоящее время затруднена из-за огромного масштаба сбоя».
Рассказано о том, чего ожидать дальше: «Рассчитываем восстановить работоспособность за несколько часов (не минут и дней)».
Мне нравится, что команда дала значимую, хотя и расплывчатую, оценку («восстановление работоспособности в течение нескольких часов — не минут и дней»), а затем выполнила это обещание, отдав приоритет основной функциональности.
Для большинства клиентов работа Datadog была восстановлена в течение полутора дней. Все данные были загружены в течение двух дней (о потерях не сообщалось).
После завершения инцидента компания не общалась с клиентами централизованно. После устранения крупного сбоя следующим шагом является его анализ и публикация постмортема, о чем и говорится в разделе «Анализ инцидента и лучшие практики постмортемов». Обычно принято делиться результатами с клиентами, чтобы укрепить доверие.
Но именно в этот момент история сбоя Datadog приняла странный оборот.
Некоторые клиенты получили двухстраничный предварительный постмортем через несколько дней после инцидента. В нем кратко описывались такие детали, как проблема с systemd-networkd, вызвавшая сбой, и действия, предпринятые Datadog, которые гарантируют, что подобные сбои в будущем не повторятся. Через две недели после инцидента часть клиентов получила четырехстраничный PDF с подробностями и детальным обзором сбоя.
Но некоторые клиенты не получили ни одного из этих документов. Кому-то постмортем не достался даже после явного запроса: я разговаривал с клиентом, который платит Datadog более $100 тысяч в год. Узнав о том, что другие получили постмортем, он дважды его запрашивал — 11 мая и 12 мая, но так и не получил ответа.
В чем причина столь разного отношения? Я пообщался с десятком пострадавших, но не обнаружил никакой взаимосвязи между тем, сколько они платят Datadog, и уровнем обслуживания. Некоторые мелкие ($50 тысяч в год) и крупные (более $1 миллиона в год) клиенты были полностью удовлетворены сервисом. Другие же клиенты разных масштабов после сбоя не получили ни одного постмортема от компании (в том числе те, кто тратит на Datadog более $1 миллиона в год).
Единственное, что приходит на ум — абсолютно разное отношение менеджеров по работе с клиентами к своим обязанностям. Некоторые менеджеры проявляли инициативу и пересылали все доступные документы своим подопечным. Другие этого не делали.
Почему Datadog полагается на менеджеров при распространении постмортемов? Ранее у компании никогда не случалось глобального сбоя, который затронул бы всех клиентов. Когда он случился, оказалось, что унифицированного процесса коммуникации с ними просто не существует. Далеко не все получили уведомления о предварительном постмортеме, то же самое касается и внутреннего постмортема, который некоторые клиенты получили через две недели после инцидента. Генеральный директор Datadog дополнительно обострил ситуацию, призвав всех ознакомиться с постмортемом.
Еще один минус — отсутствие новостей в течение двух с половиной месяцев после столь масштабного сбоя. Нередко компаниям требуется
