Slovo и русский жестовый язык
Всем привет! В этой статье мы расскажем о непростой задаче распознавания русского жестового языка (РЖЯ) для слабослышащих. Насколько нам известно, в открытом доступе не существует универсального набора данных для распознавания РЖЯ. Поэтому мы решили выложить небольшую часть нашего датасета в открытый доступ. В статье мы затронем основные особенности РЖЯ, поговорим о проблемах и сложностях самого языка, и процессе его сбора и разметки. Расскажем, где искали экспертов и как нам в итоге удалось собрать самый большой и разнородный жестовый датасет для РЖЯ. В конце статьи представим набор предобученных нейронных сетей и небольшое приложение, демонстрирующее распознавание жестового языка. Часть датасета и веса моделей мы выложили в открытый доступ — все ссылки вы можете найти в конце статьи или в репозитории.
Введение
Существует множество наборов данных для распознавания естественных языков, что значительно упрощает жизнь в тех или иных ситуациях. Суммаризация текстов, генерация новостей, синтез речи, распознавание голосовых сообщений, и другие — все это реализовано и используется в повседневной жизни. Однако те части общества, которые вынуждены взаимодействовать друг с другом с помощью жестовых языков, остались за пределами подобных новшеств. Количество людей с дефектами слуха и речи в России оценивается от 500 тысяч до нескольких миллионов и они могут быть непонятыми и в повседневной жизни, и в экстремальных ситуациях. Например, в некоторых больницах все еще нет переводчика, что делает медицинскую помощь для носителей жестового языка менее доступной. То же касается и других важных организаций, взаимодействие с которыми является необходимостью. Помимо сложности взаимодействия, которая также способствует частичной социальной изоляции, глухие люди испытывают трудности в получении образования (жестовый язык не преподается в школах) и трудоустройстве.

Пример жестов из датасета Slovo
Создание модели распознавания жестового языка может способствовать решению некоторых существующих проблем, став частью образовательного сервиса, сервиса видеоконференций или сервиса для фондов и гос. компаний (МФЦ, банки, вокзалы, аэропорты). Основным препятствием к получению подобной модели является сложность в создании подходящего набора данных. Мы попытались решить эту проблему путем создания набора данных для распознавания русского жестового языка (РЖЯ), о чем и пойдет речь ниже.
Особенности РЖЯ
Жестовый язык в любой стране имеет ряд специфических особенностей, кардинально отличающих его от естественных языков и кратно усложняющих создание наборов данных для распознавания. Подобные и некоторые другие особенности представлены ниже:
Наличие множества диалектов в пределах одной страны (одного естественного языка). То есть, для большинства слов в, например, русском жестовом языке существует n-ое количество жестов, где n > 1. Тогда процесс обучения обобщенной на все диалекты модели будет существенно осложнен внутриклассовой вариативностью. В ином случае, для каждой модели будет необходим отдельный набор данных, что осложнено количеством диалектов, которых в России около 500, а значения слов в диалектах могут пересекаться;
Некоторые слова в РЖЯ можно показать только с помощью дактиля (алфавита жестового языка), то есть для них нет специального жеста ни в одном из диалектов;
Существенная часть слов в РЖЯ является последовательностью некоторого количества более простых слов, они называются составными;
Большой социальный разрыв между двумя обществами создает проблему поиска носителей РЖЯ, а это в свою очередь порождает и неполноту знаний о всевозможных особенностях жестового языка;
Значение жеста может зависеть от мимики и движений тела, что существенно осложняет распознавание похожих по движениям рук жестов.
Для решения этих проблем в других странах проводятся различные попытки упрощения распознавания жестовых языков. Прямо сейчас компания Google запустила очередное соревнование с призовым фондом в 200.000$ для американского жестового языка, целью которого является распознавание слов по «буквам» (каждое слово конструируется жестовыми буквами).

Также около месяца назад от Google завершилось похожее соревнование на распознавание отдельных жестов американского ЖЯ с призовым фондом в 100.000$.

Описание датасета
Нам удалось собрать датасет, состоящий из более чем 200 тысяч видео, разделенных на 3 тысячи уникальных классов. В настоящий момент мы готовы опубликовать лишь небольшую часть этого датасета, которую мы назвали Slovo. Он состоит из 20 тысяч видео — по 20 видео на один из 1000 классов (жестов). Дополнительно к датасету добавлено 400 видео, на которых не происходит жестовых событий, чтобы ввести понятие класса «не жест». Датасет разбит на тренировочную (train), и тестовую (test) выборки с 15000 и 5000 сэмплами соответственно («не жесты» отделены по 300 и 100 видео соответственно). Видео собраны с помощью 194 экспертов, прошедших экзамен на знание РЖЯ. Тестовая выборка сформирована путем привлечения 174 экспертов, а обучающая — с помощью 112 экспертов. Между обучающей и тестовой выборками есть небольшое пересечение по юзерам, но тестовый сет специально подобран так, чтобы эта выборка была максимально разнообразной. Датасет представлен в нескольких версиях:
Исходный: полноценные HD-видео, на которых помимо целевых жестов РЖЯ содержится немного «бесполезной» информации (человек подходит к камере для записи, отходит от нее для завершения съемки и т.д.). Полный архив с данными весит около 100 ГБ;
Обработанный: содержит обрезанные по разметке видео, на которых происходит выполнение целевых жестов. Она весит 15.86 ГБ, а суммарное время «полезной» записи — 9,2 часов (учитывались кадры только с жестовыми событиями).
Вместе с датасетами мы отдаем разметку начала и конца жеста. Все видео собирались преимущественно в домашних условиях, с расстоянием до камеры в среднем от 0,5 до 2 метров. 35% видео записаны в HD формате, а 65% видео имеют FullHD разрешение, и все видео имеют кадровую частоту FPS = 30. Средняя длина «жестовых» видео — 50 кадров.
На следующем рисунке представлены основные статистики по датасету Slovo. На первом графике показаны распределения по длительности видео, на втором и третьем распределения по количеству записанных видео на каждого эксперта. А на последнем изображена диаграмма распределения качества видеозаписей.

Статистики датасета
Краудсорсинг
Для сбора и разметки РЖЯ мы использовали две российские краудсорсинг-платформы: Yandex.Toloka, на которой мы только собирали видео для датасета, и ABC Elementary, где, ввиду высокой квалификации разметчиков, проходили остальные этапы краудсорсинга — сбор, валидация и разметка РЖЯ. Также использование двух платформ позволяет получить две непересекающиеся аудитории знающих РЖЯ, что повышает качество финальных данных.
Полный цикл создания датасета состоит из нескольких этапов:
Экзамен — выявление группы пользователей, знающих РЖЯ,
Сбор данных — получение необработанного датасета видео,
Валидация — проверка качества датасета, удаление дубликатов и плохих данных (низкая кадровая частота или разрешение),
Разметка — выявление участка видео с требуемым событием жеста + финальная агрегация результатов,
Фильтрация — финальный постпроцессинг для подготовки чистого датасета.

РЖЯ пайплайн
Экзамен
Экзамен является очевидной стадией сбора качественного датасета. Он позволяет отфильтровать из большой группы пользователей требуемых экспертов. Наш экзамен был относительно прост, но для не знакомых с РЖЯ людей пройти его было затруднительно.
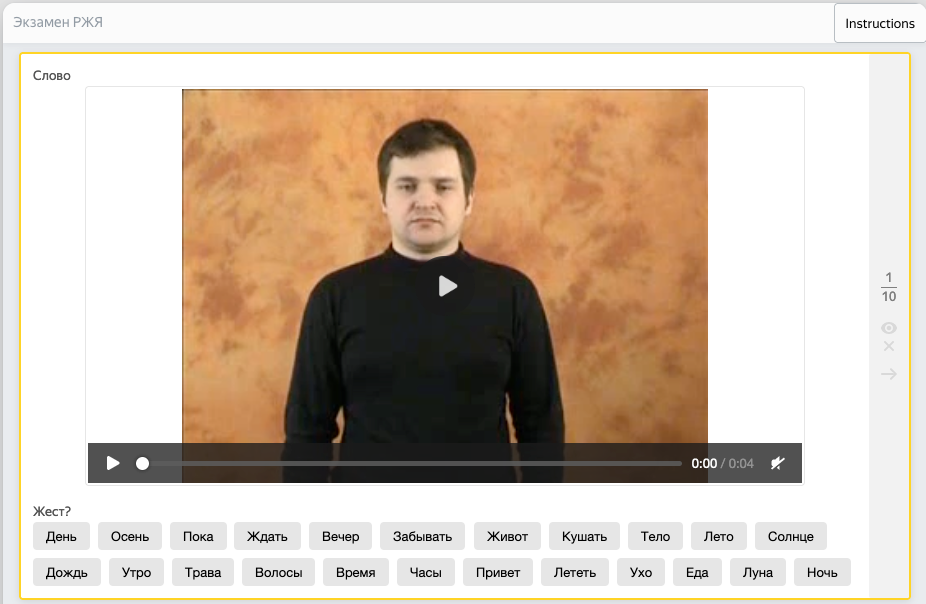
Пример экзамена на знание РЖЯ
Пользователям предоставлялось от 10 до 15 видео, которые необходимо было посмотреть и классифицировать правильный жест на них. В итоге интерес к заданию проявили около 45 тысяч человек, а полностью экзамен прошли 25 тысяч пользователей, из которых около 400 пользователей получили высокий навык >= 90%. Экспертов с навыком 90% и выше мы привлекли для стадии валидации и разметки РЖЯ, а экспертов с навыком 80% и выше попросили записывать жесты в проекте майнинга данных. На следующем рисунке представлены графики распределения навыка знания РЖЯ в наших проектах.

Распределение по экспертам
К сожалению, это только общая статистика навыка на краудсорсинг-площадке. Некоторые пользователи получают навык и не выполняют задания вообще, либо выполняют только какую-то часть и теряют интерес к проекту (независимо от мотивирующих факторов, высокой стоимости заданий и т. д.). В конечном счете, в проекте записи РЖЯ приняло участие около 200 человек.
Сбор данных
На этой стадии мы попросили квалифицированных носителей РЖЯ записать видео с тем или иным жестом. К сбору данных допускались пользователи, прошедшие экзамен с навыком не менее 80%. Сбор данных интуитивно понятен и максимально прост — пользователю предоставляется слово из РЖЯ и видео-шаблон, на котором показан нужный жест. Нужно записать жест по аналогии и отправить его через краудсорсинг-площадку. Прогресс-бар выполнения заданий в одном из пулов на стадии сбора выглядит следующим образом:

Прогресс выполнения задания на Yandex.Toloka
Валидация
Несмотря на то, что мы отобрали группу носителей РЖЯ, это не избавляет нас от проблемы некачественного выполнения заданий, поэтому без стадии валидации обойтись нельзя. На этом этапе мы показывали каждое записанное видео отдельной группе людей, которые должны были определить, правильно оно записано или нет. Критерии правильности приемки достаточно простые:
Камера исполнителя не дрожит;
Жест должен быть выполнен верно;
Руки не выходят за кадр в процессе выполнения жеста.
К проекту валидации допускались пользователи, прошедшие экзамен с навыком не менее 90%. Чтобы повысить качество сбора датасета, каждое видео на этапе валидации проверяли от 3 до 5 независимых экспертов. По умолчанию уровень перекрытия равен 3, а если ответы экспертов не согласованы — перекрытие динамически увеличивалось сначала до 4, а потом, в случае необходимости, до 5 (этот процесс происходит автоматически на краудсорсинг площадке). Финальное решение агрегировано по «мнению большинства».
Кроме того, мы использовали набор эвристик для контроля качества записи датасета и ввели дополнительные блокировки исполнителей на краудсорсинг площадке: 1) временный бан за быстрые ответы или пропуски; 2) временный или постоянный бан за неверные ответы по результатам валидации. На этой же стадии мы проверяли видео на качество записи и отбраковывали записи в плохом разрешении (min_side < 320), с низкой кадровой частотой (fps < 15), и слишком короткие записи длиной менее 1 секунды. Здесь же мы удаляли дубликаты видео, высчитывая phash отдельно взятых кадров.
Также мы периодически проверяли качество ответов пользователей и блокировали плохих экспертов на постоянной основе, если процент правильно выполненных заданий был ниже 50% (более половины их ответов отклонены на этапе валидации).
Разметка
На этапе разметки мы отдавали видео пользователям, которые должны были определить начало и конец события. Перед экспертами также был шаблон правильного выполнения жеста. Перекрытие на этапе разметки строго фиксировано и равно 3, то есть каждое видео размечено тремя независимыми пользователями. Это позволяет получить качественную усредненную разметку и не волноваться за уверенность ответов пользователей (для случая, когда перекрытие = 1).
После сбора разметки путем несложного алгоритма усреднения для каждого видео появляется размеченная область, на которой выполняется жест из РЖЯ. Записанные видео обрезаются по границам этой области и формируют финальный датасет. На следующем рисунке представлен примерный пайплайн агрегации разметки:
Собрать разметку от N = 3 пользователей
Разделить на группы начало и конец разметки
Проверить максимальную разницу между границами в каждой группе
В случае успеха усреднить границы
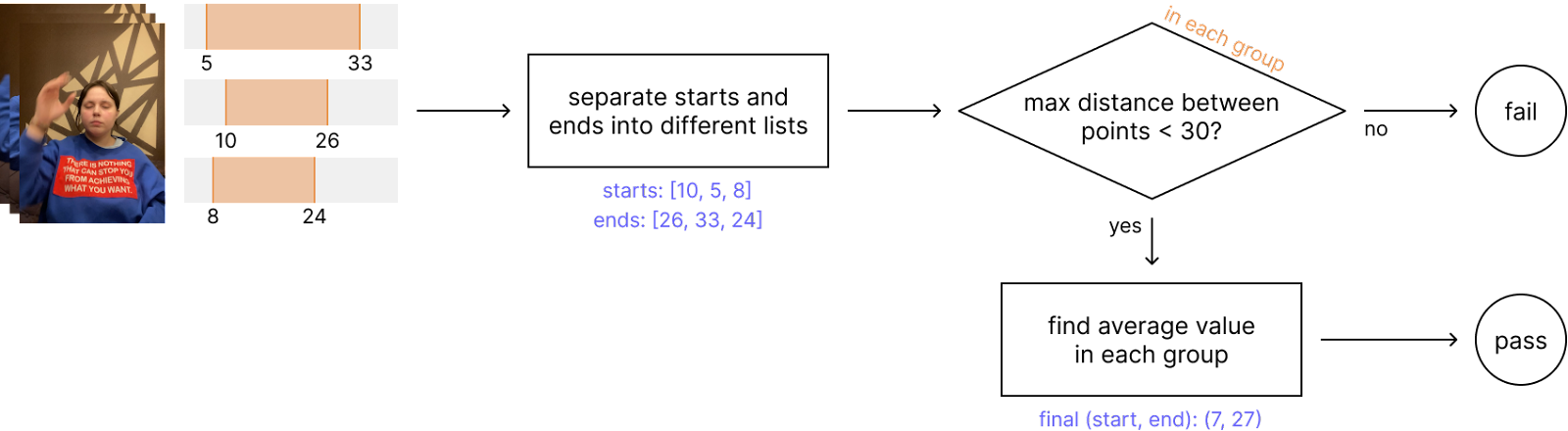
Агрегация разметки видео
К нашему удивлению, качество разметки получилось максимально высоким, а из 100K видео не удалось агрегировать только 6.
В дополнение к этому, мы разметили обработанный датасет с помощью Mediapipe — на каждом кадре размечены кисти рук. Это может повысить качество распознавания жестового языка, путем добавления алгоритмических эвристик.
Фильтрация
На этой стадии мы формируем финальный датасет. Процесс фильтрации состоял из нескольких этапов:
Убираем неподходящие видео по параметрам width, height, fps, length;
Убираем составные и сложные жесты;
Отделяем дактиль от слов (пример: буква «я» и слово «Я»);
По разметке нарезаем кадры с жестами из исходных видео;
Ускоряем слишком медленные видео*
Разбиваем датасет на обучающую и тестовую выборки по user_id.
* — мы обнаружили, что для некоторых видео, выполнение жеста было слишком медленным. поэтому для каждого класса мы посчитали среднюю длину видео и пропорционально ускорили самые длинные видео до среднего значения.
Эксперименты и демо
На нашем датасете мы обучили ряд нейронных сетей, большая часть из которых основана на современном подходе с Visual Transformers. Предварительно сетки были обучены на датасете Kinetics. Очевидно, что задача распознавания РЖЯ должна выполняться в режиме реального времени, в идеале на портативных и мобильных устройствах. Однако, далеко не все современные подходы могут обеспечить реал-тайм. Мы провели серию экспериментов с небольшими моделями типа Swin-small и Swin-tiny, но они показали очень плохие метрики. В качестве бейзлайна выбрали сверточную архитектуру на базе ResNet3D-50 и две тяжелые модели Swin-large c головой I3D и mVITv2-small. Поскольку жесты РЖЯ можно показывать любой рукой, в процессе обучения мы добавили горизонтальное отражение в качестве базовой аугментации.
Также мы провели серию экспериментов с разным окном сэмплирования входных данных — 16, 32, 48 и 64 кадров. Поскольку эксперименты с размером окна в 64 кадра давали очень плохие метрики — мы не стали включать их в финальные результаты. Помимо этого, мы прореживали исходные видео с параметром децимации от 1 до 4 (в случае d = 1 видео не меняется). Эксперименты с d > 4 также показывали очень плохие метрики, поскольку пропускалось очень много кадров и даже визуально распознать в таком разреженном потоке какой-либо жест было невозможно. В качестве основной метрики мы выбрали mean accuracy. На следующем графике представлены результаты метрик для моделей ResNet3D-50 и Swin-large.

Метрики для ResNet3D и Swin-Large
Подробное описание обучения моделей можно посмотреть в нашей статье.
Демо распознавания РЖЯ представлено на следующей гифке. В репозитории вы найдете код для запуска ONNX и Pytorch моделей. Обращаем ваше внимание, что на CPU время инференса достаточно велико, и получить реал-тайм распознавание не получится. Если у вас есть GPU — запускайте модели с использованием видеокарт.
Дальнейшие планы
На этом наши эксперименты не заканчиваются, и мы планируем развивать тему распознавания русского жестового языка по разным направлениям. Вот примерный список открытых проблем для жестовых языков, включая русский:
Изучить различные диалекты РЖЯ и найти закономерности между ними для русского жестового языка и языков СНГ группы для создания универсального решения.
Расширение жестовой корзины за счет добавления новых классов и увеличения числа видео на класс (сейчас в нашей команде идет процесс сбора датасета на около 3000 слов, в среднем по 50 видео на класс).
Решение проблемы конструирования законченных предложений, определение пауз между словами и предложениями, распознавание составных жестов, решение задачи обратной лемматизации.
Переход от текстовых предсказаний в домен звука (задача — video2speech).
Переход в мульти-модальный домен с возможностью распознавания слов не только по жестам, но и по губам, мимике и позе человека.
Решение обратной задачи text2video — это генерация видео по текстовым описаниям жестов (виртуальный сурдопереводчик)
Мульти-язычный жестовый язык, поиск закономерностей в жестовых языках разных стран мира.
Заключение
В этой статье мы представили датасет Slovo и набор обученных на нем нейронных сетей для распознавания русского жестового языка. Датасет и модели распространяются под переработанной версией лицензии Creative Commons Corporation (Attribution-ShareAlike 4.0). Следите за обновлениями, обязательно будем публиковать успехи в этом направлении.
Будем очень признательны за фидбек. Если среди вас или ваших знакомых есть носители РЖЯ, которые готовы поучаствовать в проекте — пишите нам, мы подробнее расскажем о задачах!
Авторы
Отдельное спасибо дата-инженерам — Саутину Александру и Суровцеву Петру, которые 24/7 следят за качеством наших данных.
Ссылки
Также у нашей команды появился телеграм-канал, где мы будем рассказывать о результатах нашей работы, делиться идеями и даже факапами. Подписывайтесь.
