Видеоускоритель Nvidia GeForce RTX 3080, часть 1: теория, архитектура, синтетические тесты
Теоретическая часть: особенности архитектуры
После анонса предыдущей архитектуры Turing и видеокарт на ее основе из семейства GeForce RTX 20, практически сразу стало понятно, в какую именно сторону Nvidia будет развиваться в дальнейшем. Графические процессоры Turing стали первыми GPU с аппаратной поддержкой трассировки лучей и ускорением задач искусственного интеллекта, но это был лишь пробный камень, зародивший основу для применения новых технологий в играх. А вот к производительности и цене прошлого семейства компании были вопросы. Чтобы продвинуть аппаратную поддержку трассировки лучей и ИИ как можно раньше, пришлось поступиться всем остальным, и видеокарты Turing показывали порой не настолько впечатляющие результаты в других применениях. Тем более что смена техпроцесса на значительно более продвинутый тогда просто не была возможна.
Со временем это изменилось, стали доступны технологии производства полупроводников по нормам 7/8 нм. Появилась возможность добавить транзисторов при сохранении сравнительно небольшой площади кристалла. Именно поэтому в следующей архитектуре, которая была официально анонсирована в начале сентября, открылась возможность для усиления вообще всего в GPU. Видеокарты серии GeForce RTX 30, созданные на основе архитектуры Ampere, были представлены директором компании Дженсеном Хуангом во время виртуального мероприятия Nvidia, также он сделал еще несколько интересных объявлений, связанных с играми, инструментами для геймеров и разработчиков.
Вообще, с точки зрения возможностей, революционным является Turing, а Ampere было достаточно стать эволюционным развитием возможностей предыдущей архитектуры. Это вовсе не значит, что в новых GPU вообще нет ничего нового, но это означает значительное увеличение производительности. А чего еще нужно пользователям? Вменяемых цен, конечно же! Но сегодня мы больше нацелены на теорию и синтетические тесты, а о ценах и соотношении цены и производительности поговорим позже.
Первым графическим процессором на основе архитектуры Ampere стал большой «вычислительный» чип GA100, он вышел еще в мае и показал очень мощный прирост производительности в различных вычислительных задачах: нейросети, высокопроизводительные вычисления, анализ данных и т. д. Мы уже писали об архитектурных изменениях Ampere подробно, но это все-таки чисто вычислительный чип, предназначенный для узкоспециализированных применений (хотя странно говорить такое про чипы, которые все чаще вычисляют для нас различные вещи, пусть и на удаленных серверах), а игровые GPU — это совсем другое дело. И сегодня мы как раз рассмотрим новые решения семейства Ampere: чипы GA102 и GA104, на базе которых пока что анонсированы три модели видеокарт: GeForce RTX 3090, RTX 3080 и RTX 3070. Отметим, что Nvidia сразу же оговорилась, что остальные решения на чипах семейства GA10x, предназначенные для иных ценовых диапазонов, будут выпущены позднее.

Всего пока что было представлено три модели:
- GeForce RTX 3080 — топовая видеокарта игровой линейки за $699 (63 490 руб.). Имеет 10 ГБ памяти нового стандарта GDDR6X, работающей на эффективной частоте в 19 ГГц, в среднем до двух раз быстрее RTX 2080 и нацелен на обеспечение 60 FPS в 4K-разрешении. Доступна с 17 сентября.
- GeForce RTX 3070 — более доступная модель за $499 (45 490 руб.), оснащенная 8 ГБ привычной памяти GDDR6. Отличный выбор для игр в разрешении 1440p и иногда 4K, по производительности превосходит RTX 2070 в среднем на 60% и примерно соответствует GeForce RTX 2080 Ti при вдвое меньшей начальной стоимости. Появится в продаже в октябре.
- GeForce RTX 3090 — исключительная модель класса Titan за $1499 (136 990 руб.), имеющая обычное цифровое наименование. Эта трехслотовая модель с большим кулером имеет 24 ГБ GDDR6X-памяти на борту и способна справиться с любыми задачами, игровыми и не только. Видеокарта до 50% быстрее, чем Titan RTX, и предназначена для игры в 4K, и может даже обеспечить 60 FPS в 8K-разрешении во многих играх. Будет доступна в магазинах с 24 сентября.
На основе чипа GA102 сделаны модели GeForce RTX 3090 и GeForce RTX 3080, имеющие разное количество активных вычислительных блоков, а видеокарта GeForce RTX 3070 базируется на более простом GPU под кодовым именем GA104. Тем не менее, из-за всех улучшений, даже младшая модель из представленных, должна обходить флагмана предыдущей линейки в виде GeForce RTX 2080 Ti. А уж про старшие модели и не говорим, они точно намного мощнее. Заявлено, что GeForce RTX 3080 до двух раз быстрее модели предыдущего поколения — RTX 2080, а это — один из самых больших скачков в производительности GPU за долгие годы! Самая производительная GeForce RTX 3090 в новой линейке имеет 10496 вычислительных CUDA-ядер, 24 ГБ локальной видеопамяти нового стандарта GDDR6X и отлично подходит для игр в самом высоком 8K-разрешении.
Графические процессоры GA10x добавляют несколько (не очень много, по сравнению с тем же Turing, но тем не менее) новых возможностей, а главное — они значительно быстрее Turing в различных применениях, включая трассировку лучей. Ampere, благодаря специальным решениям и производству по более тонкому техпроцессу, обеспечивает значительно лучшую энергоэффективность и производительность в пересчете на единицу площади кристалла, что поможет в самых требовательных задачах, вроде трассировки лучей в играх, которая сильно просаживает производительность. Нам обещают, что игровые решения архитектуры Ampere примерно в 1,7 раза быстрее в традиционных задачах растеризации, по сравнению с Turing, и до двух раз быстрее при трассировке лучей:
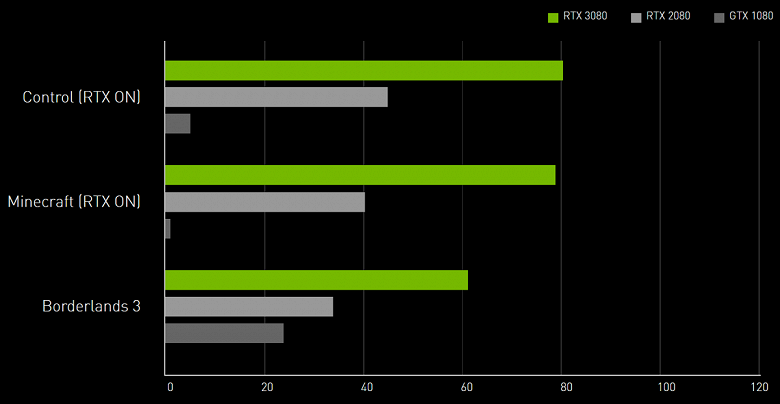
Прежде чем мы приступим к подробному рассказу о первой ласточке из нового семейства игровых Ampere, сразу же хотим раскрыть две новости: хорошую и плохую, как обычно. Начнем с плохой: из-за всяких коронавирусно-логистическо-таможенных сложностей, сэмплы видеокарт в этот раз приехали очень поздно, и мы просто не успели сделать тесты. Не помогло даже откладывание анонса GeForce RTX 3080 на пару дней. Но есть и хорошая новость: уже сегодня мы покажем вам интереснейшие результаты синтетических тестов! Да, результатов новинки в играх придется подождать еще немного, но мы сделали все, что смогли, работая ночами без выходных.
Основой рассматриваемой сегодня модели видеокарты стал абсолютно новый графический процессор архитектуры Ampere, но так как она имеет достаточно много общего с предыдущими архитектурами Turing, Volta и местами даже Pascal, то перед прочтением материала мы советуем ознакомиться с некоторыми нашими предыдущими статьями:

Картинка не перевернута, так надо :)
| Графический ускоритель GeForce RTX 3080 | |
|---|---|
| Кодовое имя чипа | GA102 |
| Технология производства | 8 нм (Samsung »8N Nvidia Custom Process») |
| Количество транзисторов | 28,3 млрд |
| Площадь ядра | 628,4 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 320-битная (из 384-битной в полном чипе): 10 (из 12 имеющихся) независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6X |
| Частота графического процессора | до 1710 МГц (турбо-частота) |
| Вычислительные блоки | 68 потоковых мультипроцессоров (из 84 в полном чипе), включающих 8704 CUDA-ядра (из 10752 ядер) для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32/FP64 |
| Тензорные блоки | 272 тензорных ядра (из 336) для матричных вычислений INT4/INT8/FP16/FP32/BF16/TF32 |
| Блоки трассировки лучей | 68 RT-ядер (из 84) для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 272 блока (из 336) текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 8 широких блоков ROP на 96 пикселей (из 112) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка HDMI 2.1 и DisplayPort 1.4a (со сжатием DSC 1.2a) |
| Спецификации референсной видеокарты GeForce RTX 2080 Super | |
|---|---|
| Частота ядра | до 1710 МГц |
| Количество универсальных процессоров | 8704 |
| Количество текстурных блоков | 272 |
| Количество блоков блендинга | 96 |
| Эффективная частота памяти | 19 ГГц |
| Тип памяти | GDDR6X |
| Шина памяти | 320-бит |
| Объем памяти | 10 ГБ |
| Пропускная способность памяти | 760 ГБ/с |
| Вычислительная производительность (FP32) | до 29,8 терафлопс |
| Теоретическая максимальная скорость закраски | 164 гигапикселей/с |
| Теоретическая скорость выборки текстур | 465 гигатекселей/с |
| Шина | PCI Express 4.0 |
| Разъемы | один HDMI 2.1 и три DisplayPort 1.4a |
| Энергопотребление | до 320 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $699 (63 490 рублей) |
Это первая модель нового поколения GeForce RTX 30, и мы очень рады, что линейка видеокарт Nvidia продолжает принцип наименования решений компании, заменяя на рынке RTX 2080 и улучшенную модель Super. Выше нее будет очень дорогая RTX 3090, а ниже — RTX 3070. То есть, все ровно так же, как и в предыдущем поколении, разве что тогда RTX 2090 не было. Остальные новинки появятся в продаже чуть позже, и мы обязательно их рассмотрим.
Рекомендованная цена для GeForce RTX 3080 также осталась равной той, что была выставлена для аналогичной модели предыдущего поколения — $699. Для нашего рынка ценовые рекомендации несколько менее приятны, но это никак не связано с жадностью калифорнийцев, пенять нужно на слабость нашей национальной валюты. В любом случае, ожидаемая от RTX 3080 производительность точно стоит этих денег. Как минимум пока у нее нет сильных конкурентов на рынке.
Да, у компании AMD для новой модели GeForce RTX 3080 нет соперников, и мы очень надеемся, что лишь пока. Относительный аналог по ценовому диапазону в виде Radeon VII давно устарел и снят с производства, а Radeon RX 5700 XT является решением более низкого уровня. Вместе с вами мы очень ждем решений на базе второй версии архитектуры RDNA, и особенно любопытен будет большой чип (так называемый «Big Navi»), видеокарты на базе которого должны дать бой верхним моделям Nvidia. Ну, а пока что сравниваем RTX 3080 только с предыдущим поколением GeForce.
Как обычно, Nvidia выпустила видеокарты новой серии и в собственном дизайне под наименованием Founders Edition. Эти модели предлагают очень любопытные системы охлаждения и строгий дизайн, которого не найти у большинства производителей видеокарт, гонящихся за количеством и размером вентиляторов, а также разноцветной подсветкой. Самое интересное в собственных GeForce RTX 30, продаваемых под брендом Nvidia — совершенно новый дизайн системы охлаждения с двумя вентиляторами, расположенными необычным образом: первый более-менее привычно выдувает воздух через решетку с торца платы, а вот второй установлен с обратной стороны и протягивает воздух прямо сквозь видеокарту (в случае GeForce RTX 3070 кулер отличается, оба вентилятора установлены с одной стороны карты).
Таким образом тепло отводится от компонентов на карте в гибридную испарительную камеру, где оно распределяется по всей длине радиатора. Левый вентилятор выводит нагретый воздух через большие вентиляционные отверстия в креплении, а правый вентилятор направляет воздух к выдувному вентилятору корпуса, где он обычно установлен в большинстве современных систем. Эти два вентилятора работают на разной скорости, которая настраивается для них индивидуально.
Подобное решение заставило инженеров менять всю конструкцию. Если обычные печатные платы проходят во всю длину видеокарт, то в случае продувного вентилятора пришлось разработать короткую печатную плату, с уменьшенным слотом NVLink, новыми разъемами питания (переходник на два обычных 8-контактных PCI-E прилагается). При этом, карта имеет 18 фаз для питания и на ней размещено необходимое количество микросхем памяти, что было сделать непросто. Эти изменения дали возможность большого выреза для вентилятора на печатной плате, чтобы потоку воздуха ничего не мешало.


Nvidia утверждает, что дизайн кулеров Founders Edition привел к заметно более тихой работе, чем стандартные кулеры с двумя осевыми вентиляторами с одной стороны, при этом эффективность охлаждения у них выше. Поэтому новые решения устройств охлаждения позволили повысить производительность без роста температуры и шума по сравнению с видеокартами предыдущего поколения Turing. При уровне потребления 320 Вт новая видеокарта или на 20 градусов холоднее модели GeForce RTX 2080 или на 10 дБА тише. Но все это еще нужно проверить на практике.
Сходу кажется, что у новой системы охлаждения есть и плюсы и минусы. Например, есть вопросы по нагреву остальных компонентов — например, модулей памяти, на которые приходится выдув горячего воздуха. Но специалисты Nvidia говорят, что исследовали этот вопрос и новый кулер не сильно влияет на нагрев других элементов системы. Есть и плюсы — SLI-системе может быть прохладнее, по сравнению с парой Turing, так как при новом кулере проще выводить горячий воздух из пространства между картами. С другой стороны, на верхнюю карту будет идти горячий воздух от нижней.
Видеокарты GeForce RTX 30 Founders Edition будут продаваться на сайте компании. Все графические процессоры новой серии в версии Founders Edition будут доступны на русскоязычном сайте Nvidia, начиная с 6 октября.Естественно, что партнеры компании выпускают карты собственного дизайна: Asus, Colorful, EVGA, Gainward, Galaxy, Gigabyte, Innovision 3D, MSI, Palit, PNY и Zotac. Некоторые из них будут продаваться участвующими в акции продавцами с 17 сентября по 20 октября в комплекте с игрой Watch Dogs: Legion и годовой подпиской на сервис GeForce Now.
Также графическими процессорами серии GeForce RTX 30 будут оснащены игровые системы компаний Acer, Alienware, Asus, Dell, HP, Lenovo и MSI и системы ведущих российских сборщиков, включая Boiling Machine, Delta Game, Hyper PC, InvasionLabs, OGO! и Edelweiss.
Архитектурные особенности
При производстве GA102 и GA104 используется техпроцесс 8 нм компании Samsung, он каким-то образом дополнительно оптимизирован именно для Nvidia и поэтому называется 8N Nvidia Custom Process. Старший игровой чип Ampere содержит 28,3 миллиарда транзисторов и имеет площадь 628,4 mm2. Это хороший шаг вперед по сравнению с 12 нм у Turing, но тот же техпроцесс TSMC 7 нм, который применяется при производстве вычислительного чипа GA100, по плотности заметно превосходит 8 нм у Samsung. Прямо сопоставлять сложно, конечно, но мы то судим по чипам одной архитектуры Ampere, сравнивая игровой GA102 и большой чип GA100.

Если разделить заявленные миллиарды транзисторов на площадь GA102, то получается плотность около 45 миллионов транзисторов на мм2. Несомненно, это заметно лучше 25 миллионов транзисторов на мм2 у TU102, выполненном по техпроцессу TSMC 12 нм, но при этом явно хуже, чем 65 миллионов транзисторов на мм2 у большого Ampere (GA100), который делают на 7-нанометровой фабрике TSMC. Конечно, не совсем правильно сравнивать разные GPU так прямо, есть еще масса оговорок, но тем не менее — меньшая плотность техпроцесса Samsung в случае игрового Ampere налицо.
Поэтому, весьма вероятно, что этот техпроцесс выбирали, принимая во внимание какие-то другие причины. Выход годных на заводе Samsung может быть лучше, условия для такого жирного клиента особые, да и себестоимость в целом может быть заметно ниже — тем более, что у TSMC все производственные мощности техпроцесса 7 нм заняты кучей других компаний. Так что игровые Ampere производят на фабриках Samsung скорее из-за несогласия Nvidia с предложенными тайваньцами ценами и/или условиями.
Переходим к тому, чем отличается новый GPU от старых. Как и предыдущие чипы Nvidia, GA102 состоит из укрупненных кластеров Graphics Processing Cluster (GPC), которые включают несколько кластеров текстурной обработки Texture Processing Cluster (TPC), которые содержат потоковые процессоры Streaming Multiprocessor (SM), блоки растеризации Raster Operator (ROP) и контроллеры памяти. И полный чип GA102 содержит семь кластеров GPC, 42 кластера TPC и 84 мультипроцессора SM. Каждый GPC содержит шесть TPC, каждый из пары SM, а также один движок PolyMorph Engine для работы с геометрией.
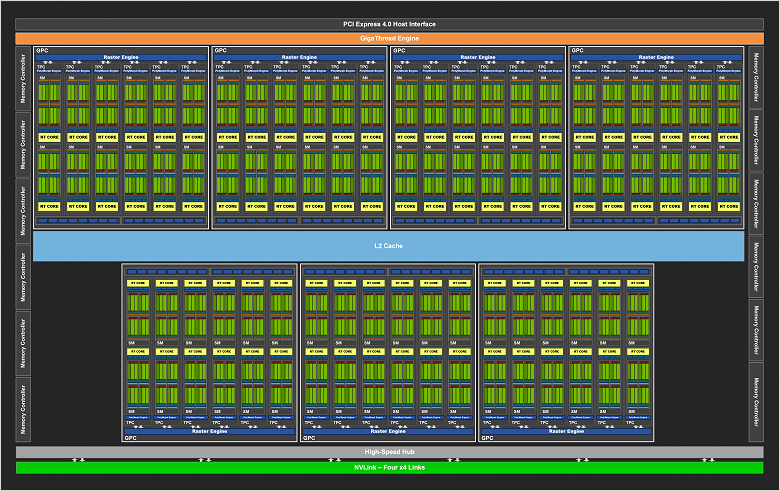
GPC — это высокоуровневый кластер, включающий все ключевые блоки для обработки данных внутри него, каждый из них имеет выделенный движок растеризации Raster Engine и теперь включает два раздела ROP по восемь блоков каждый — в новой архитектуре Ampere эти блоки не привязаны к контроллерам памяти, а находятся прямо в GPC. В итоге, полный GA102 содержит 10752 потоковых CUDA-ядра, 84 RT-ядер второго поколения и 336 тензорных ядер третьего поколения. Подсистема памяти полного GA102 содержит двенадцать 32-битных контроллеров памяти, что дает 384-бит в общем. Каждый 32-битный контроллер связан с разделом кэш-памяти второго уровня объемом в 512 КБ, что дает общий объем L2-кэша в 6 МБ для полноценной версии GA102.
Но до этого момента мы с вами рассматривали полный чип, а сегодня у нас все внимание направлено на конкретную модель видеокарты GeForce RTX 3080, использующей довольно серьезно урезанный по количеству различных блоков вариант GA102. Эта модификация получила сильно сниженные характеристики, активных кластеров GPC стало шесть, но количество блоков SM в них отличается, как видите на диаграмме. Соответственно, меньше и всех остальных блоков: 8704 CUDA-ядер, 272 тензорных ядра и 68 RT-ядер. Текстурных блоков 272 штуки, а блоков ROP — 96. Все показатели заметно ниже, чем у RTX 3090 — то ли пока много бракованных GPU, то ли Nvidia искусственно развела модели по производительности.
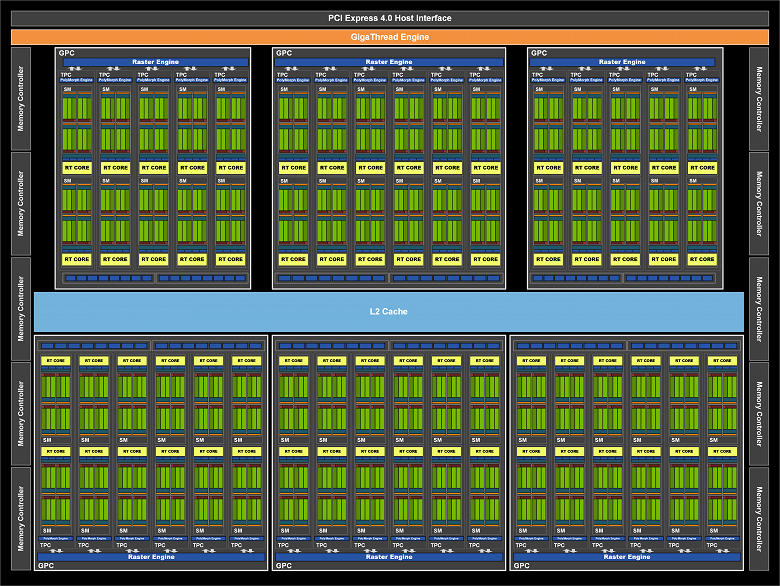
GeForce RTX 3080 имеет 10 ГБ быстрой GDDR6X-памяти, которая подключена по 320-битной шине, что дает до 760 ГБ/с пропускной способности. По поводу видеопамяти есть такое соображение — возможно, 8 и 10 гигабайт видеопамяти могут оказаться недостаточным объемом, особенно на перспективу. Nvidia уверяет, что по их исследованиям ни одна игра даже в 4K-разрешении не требует большего объема памяти (многие игры хоть и занимают весь имеющийся объем, но это не значит, что им будет недоставать меньшего), но есть один довод усомниться в таком решении — перспектива. Уже вот-вот выйдут консоли нового поколения с большим объемом памяти и быстрыми SSD, и вполне вероятно, что некоторые мультиплатформенные игры могут начать хотеть большего, чем 8–10 ГБ локальной видеопамяти. То есть, на данный момент этого достаточно, но будет ли хватать через год или два?
Да и пропускная способность тоже не вдвое увеличилась, хоть и применен новый тип памяти GDDR6X — не маловато ли? Конечно же, кэширование постоянно улучшается, как и методы внутричипового сжатия данных без потерь, но хватит ли всего этого при удвоении производительности и утроении темпа математических вычислений? Хотя Micron указывает эффективную рабочую частоту памяти как 21 ГГц, Nvidia в своих продуктах использует довольно консервативные 19,5 для RTX 3090 и 19 ГГц для RTX 3080. Может ли это говорить о сырости нового типа памяти и/или о ее слишком высоком энергопотреблении?
Как и все чипы GeForce RTX, новый GA102 содержит три основных типа вычислительных блоков: вычислительные CUDA-ядра, RT-ядра для аппаратного ускорения алгоритма Bounding Volume Hierarchy (BVH), использующегося при трассировке лучей для поиска их пересечения с геометрией сцены (подробнее об этом написано в обзоре архитектуры Turing), а также тензорные ядра, значительно ускоряющие работу с нейросетями.
Основным нововведением Ampere является удвоение FP32-производительности для каждого мультипроцессора SM, по сравнению с семейством Turing, о чем мы подробно поговорим далее. Это приводит к повышению пиковой производительности до 30 терафлопсов для модели GeForce RTX 3080, что значительно превышает показатель 11 терафлопсов для аналогичного по позиционированию решения архитектуры Turing. Почти то же самое касается и RT-ядер — хотя их число не изменилось, внутренние улучшения привели к удвоению темпа поиска пересечений лучей и треугольников, хотя пиковый показатель изменился не вдвое — с 34 RT-терафлопсов у Turing до 58 RT-терафлопсов в случае Ampere.

Ну, а улучшенные тензорные ядра хоть и не удвоили производительность при обычных условиях, так как их стало вдвое меньше, но темп вычислений то удвоился. Получается, по ускорению нейросетей никаких улучшений нет? Они есть, но заключаются исключительно в случае обработки так называемых разреженных матриц — об этом мы очень подробно писали в статье о вычислительном чипе Ampere. С учетом этой возможности, пиковая скорость тензорных блоков поднялась с 89 тензорных терафлопсов у RTX 2080 до 238 в случае RTX 3080.
Оптимизация блоков ROP
Блоки ROP в чипах Nvidia ранее были «привязаны» к контроллерам памяти и соответствующим разделам L2-кэша, и изменять ширину шины и количество ROP приходилось совместно. Но в чипах GA10x блоки ROP теперь являются частью кластеров GPC, что имеет сразу несколько последствий. Это повышает производительность растровых операций за счет увеличения общего количества имеющихся блоков ROP, а также устранения несоответствия между пропускными способностями различных блоков. Заодно можно более гибко регулировать количество блоков ROP и контроллеров памяти в разных моделях видеокарт, оставляя их не столько, сколько получается, а столько, сколько нужно.
Так как полный чип GA102 состоит из семи кластеров GPC и 16 блоков ROP на каждый, то всего в нем насчитывается 112 блоков ROP, что несколько больше по сравнению с 96 блоками ROP у предыдущих аналогичных решений прошлых поколений с 384-битной шиной памяти, вроде графического процессора TU102. Большее количество блоков ROP улучшит производительность чипа при операциях блендинга, сглаживании методом мультисэмплинга, да и в целом частота заполнения подрастет, что всегда хорошо, особенно в высоких разрешениях рендеринга.
Плюсы от помещения ROP в GPC заключаются и в том, что соотношение растеризаторов к количеству блоков ROP всегда остается неизменным, и эти подсистемы не будут ограничивать другую, как в TU106, например, где 64 блоков ROP бесполезны по причине того, что растеризаторы выдавали лишь 48 пикселей за такт, а ROP в принципе не могут смешивать больше, чем выдают растеризаторы. В решениях архитектуры Ampere подобный перекос невозможен.
Изменения в мультипроцессорах
Мультипроцессоры SM в Turing стали первыми для графических архитектур Nvidia мультипроцессорами с выделенными RT-ядрами для аппаратного ускорения трассировки лучей, тензорные ядра впервые появились в Volta, а Turing получил улучшенные тензорные ядра второго поколения. Но основным улучшением в мультипроцессорах Turing и Volta, не связанным с трассировкой и нейросетями, стала возможность параллельного исполнения FP32 и INT32-операций одновременно, а мультипроцессор в чипах GA10x выводит эту возможность на новый уровень.
Каждый мультипроцессор GA10x содержит 128 CUDA-ядер, четыре тензорных ядра третьего поколения, одно RT-ядро второго поколения, четыре текстурных блока TMU, 256 КБ регистровый файл и 128 КБ L1-кэша/конфигурируемой разделяемой памяти. Также в каждом SM есть по два FP64-блока (168 штук на весь GA102), которые не отображены на схеме, так как они размещены скорее для совместимости, ибо вычислительный темп в 1/64 от темпа FP32-операций не дает широко развернуться. Столь слабые возможности по FP64-вычислениям традиционны для игровых решений компании, они включены просто для того, чтобы соответствующий код (включая тензорные FP64-операции) хоть как-то исполнялся на всех GPU компании.
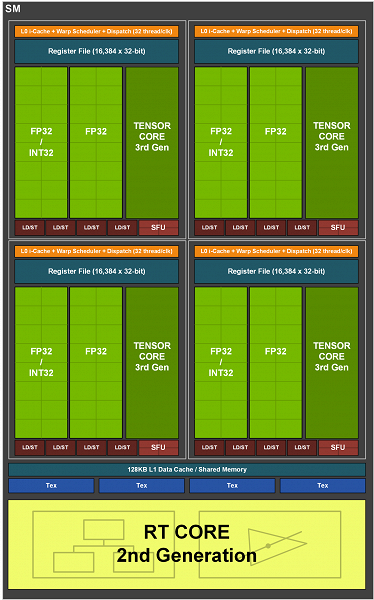
Как и в предыдущих чипах, мультипроцессор Ampere разделен на четыре вычислительных подраздела, каждый из которых имеет собственный регистровый файл объемом 64 КБ, L0-кэш инструкций, блоки диспетчера и запуска варпов, а также наборы математических блоков. Четыре подраздела SM имеют доступ к конфигурируемому пулу разделяемой памяти и L1-кэша объемом в 128 КБ.
А теперь пара слов об изменениях в SM — если в TU102 каждый мультипроцессор имел по два тензорных ядра второго поколения на каждый подраздел (всего восемь тензорных ядер на SM), то в GA10x каждый подраздел имеет лишь по одному тензорному ядру и четыре на весь SM, но эти ядра — уже третьего поколения, что означает вдвое большую производительность, по сравнению с ядрами предыдущего поколения. Но изменения и в CUDA-ядрах значительно интереснее.
Удвоение темпа FP32-вычислений
Переходим к наиболее важному архитектурному изменению Ampere, которое и выливается в значительный рост и пиковой и реальной производительности. Как известно, большинство графических вычислений используют операции с плавающей запятой и 32-битной точностью (FP32), и все GPU лучше всего подходят именно для такого типа вычислений. Казалось бы — ну что сложного в том, чтобы увеличить производительность? Увеличивай количество FP32-блоков, да и все! На деле есть масса ограничений, как физических, так и логических, и увеличить количество блоков не так уж просто.
Но процесс идет, и уже в предыдущем поколении Turing каждый из четырех подразделов SM имел два основных набора функциональных блоков ALU, выполняющих обработку данных (datapath), лишь один из которых мог обрабатывать FP32-вычисления, а второй был добавлен именно в Turing, чтобы параллельно исполнять исключительно целочисленные операции, необходимость в которых возникает не так уж редко, и эти дополнительные INT32-блоки повышали эффективность во многих задачах.
Главное же изменение в мультипроцессорах семейства Ampere заключается в том, что они добавили возможность обработки FP32-операций на обоих имеющихся наборах функциональных блоков, и пиковая производительность FP32 выросла вдвое. То есть, один набор функциональных блоков в каждом разделе SM содержит 16 CUDA-ядер, способных на исполнение такого же количества FP32-операций за такт, а второй состоит из 16 блоков FP32 и 16 блоков INT32, и способен выполнять или те или другие — 16 за такт. В результате, каждый SM может выполнять или 128 FP32-операций за такт или по 64 операций FP32 и INT32, и максимальная производительность GeForce RTX 3090 выросла до более чем 35 терафлопс, если говорить именно о FP32-вычислениях, а это более чем вдвое превышает возможности Turing.
Сразу же возникает немало вопросов об эффективности такого разделения и о том, какие задачи получат преимущество от подобного подхода. Современные игры и 3D-приложения используют смесь FP32-операций с достаточно большим количеством простых целочисленных инструкций для адресации и выборки данных и т. д. Внедрение выделенных INT32-блоков в Turing обеспечило приличный прирост производительности в таких случаях, но если задача в основном использует вычисления с плавающей запятой, то половина вычислительных блоков Turing простаивает. А добавление возможности вычисления или FP32 или INT32 в Ampere дает большую гибкость и поможет повысить производительность в большем количестве случаев.
А вот удвоенный темп исполнения FP16-операций для CUDA-ядер (не путать с тензорными) архитектурой Ampere больше не поддерживается, как это было в архитектуре Turing. Вряд ли отказ от удвоенного темпа со снижением точности расчетов будет большой проблемой для игрового GPU, так как приросты от снижения точности в игровых нагрузках составляют не более нескольких процентов, но особенность любопытная. В тензорных же вычислениях, где применение FP16 бывает полезным, все осталось по-прежнему.
Конечно, приросты от добавления второго FP32 datapath будут сильно зависеть от исполняемого шейдера и смеси применяемых в нем инструкций, но мы не видим особого смысла в подробном разборе того, в каких условиях и сколько каких инструкций сможет выполнить новый мультипроцессор, на этот вопрос полноценно ответит только практика. Единственное, что можно добавить в качестве намека — одним из применений, которое точно получит хороший прирост от удвоения темпа FP32-операций, являются шейдеры для шумоподавления изображения, полученного при помощи трассировки лучей. Также должны хорошо ускориться и другие техники постобработки, но далеко не только они.
Добавление второго массива FP32-блоков увеличивает производительность в задачах, производительность которых ограничена математическими вычислениями. Например, физические расчеты и трассировка получают прирост в 30%-60%. И чем сложнее задачи для трассировки лучей в играх, тем больший прирост производительности для Ampere будет наблюдаться по сравнению с Turing. Ведь при использовании трассировки лучей производится много вычислений адресов в памяти, и за счет возможности параллельной обработки FP32- и INT32-вычислений в графических процессорах Turing и Ampere, это работает значительно быстрее, чем на других GPU.
Улучшения системы кэширования и текстурирования
Удвоение темпа FP32-операций требует и вдвое большего количества данных, а значит — нужно увеличить пропускную способность разделяемой памяти и L1-кэша в мультипроцессоре. По сравнению с Turing, новый мультипроцессор GA10x предлагает на треть больший объединенный объем L1-кэша данных и разделяемой памяти — от 96 КБ до 128 КБ на SM. Объем разделяемой памяти может быть сконфигурирован для различных задач, в зависимости от нужд разработчика. Архитектура L1-кэша и разделяемой памяти в Ampere схожа с той, что предлагал Turing, и чипы GA10x имеют унифицированную архитектуру для разделяемой памяти, L1-кэша данных и текстурного кэша. Унифицированный дизайн позволяет изменять объем, доступный для L1-кэша и разделяемой памяти.
В вычислительном режиме, мультипроцессоры GA10x могут быть сконфигурированы в одном из вариантов:
- 128 КБ L1-кэш и 0 КБ разделяемой памяти
- 120 КБ L1-кэш и 8 КБ разделяемой памяти
- 112 КБ L1-кэш и 16 КБ разделяемой памяти
- 96 КБ L1-кэш и 32 КБ разделяемой памяти
- 64 КБ L1-кэш и 64 КБ разделяемой памяти
- 28 КБ L1-кэш и 100 КБ разделяемой памяти
Для графических и смешанных задач с применением асинхронных вычислений, GA10x выделит 64 КБ на L1-кэш данных и текстурный кэш, 48 КБ разделяемой памяти и 16 КБ будет зарезервировано для различных операций графического конвейера. В этом кроется еще одно важное отличие от Turing при графических нагрузках — объем кэша увеличится вдвое, с 32 КБ до 64 КБ, и это обязательно скажется положительно в задачах, требовательных к эффективному кэшированию, вроде трассировки лучей.
Но это еще не все. Полный чип GA102 содержит 10752 КБ кэша первого уровня, что значительно превышает объем L1-кэша в 6912 КБ у TU102. В дополнение к увеличению его объема, в GA10x вдвое выросла пропускная способность кэш-памяти, по сравнению с Turing — 128 байт за такт на мультипроцессор против 64 байт за такт у Turing. Так что общая ПСП у L1-кэша GeForce RTX 3080 стала равна 219 ГБ/с против 116 ГБ/с у GeForce RTX 2080 Super.
В Ampere произошли и некоторые изменения в TMU, о чем скромно написали в слайде вместе с улучшениями кэширования: «New L1/texture system». По некоторым данным, в Ampere удвоили темп текстурных выборок (можно считывать вдвое больше текселей за такт) для некоторых популярных форматов текстур при point sampling выборках без фильтрации — такие выборки в последнее время очень часто используют вычислительные задачи, включая фильтры шумоподавления и другие постфильтры, использующие экранное пространство и другие техники. Вместе с удвоенной пропускной способностью L1-кэша это поможет «прокормить» данными увеличенное вдвое количество FP32-блоков.
RT-ядра второго поколения
RT-ядра у Turing и Ampere весьма схожи и реализуют концепцию MIMD (Multiple Instruction Multiple Data — Множественные Команды, Множественные Данные), которая позволяет обрабатывать много лучей одновременно, что отлично подходит под задачу, в отличие от SIMD/SIMT, которые используются при исполнении трассировки лучей на универсальных потоковых процессорах, когда выделенных RT-ядер нет. Специализация блоков под конкретную задачу позволяет получить более высокую эффективность исполнения и минимальные задержки.
Некоторые специалисты считают, что все вычисления нужно делать на универсальных блоках, а не внедрять специализированные, рассчитанные на какую-то отдельную задачу. Но это в идеале, а реальность такова, что если что-то можно эффективно выполнить на универсальных блоках, то так и делают, а вот если эффективность универсальных вычислителей слишком низка, то внедряют специализированные блоки, максимально эффективные в конкретных задачах.
Трассировка лучей в принципе плохо подходит для моделей исполнения SIMD и SIMT, типичной для графических процессоров, и без выделенных блоков с ней трудно справиться с приемлемой производительностью. Именно поэтому Nvidia и внедрила в Turing специализированные RT-ядра, использующие модель MIMD, они не страдают от проблем с расхождениями и обеспечивают минимальные задержки при трассировке. А программная обработка BVH-структур в вычислительных шейдерах будет слишком медленной, на широком SIMD не получится эффективно просчитывать пересечения лучей.
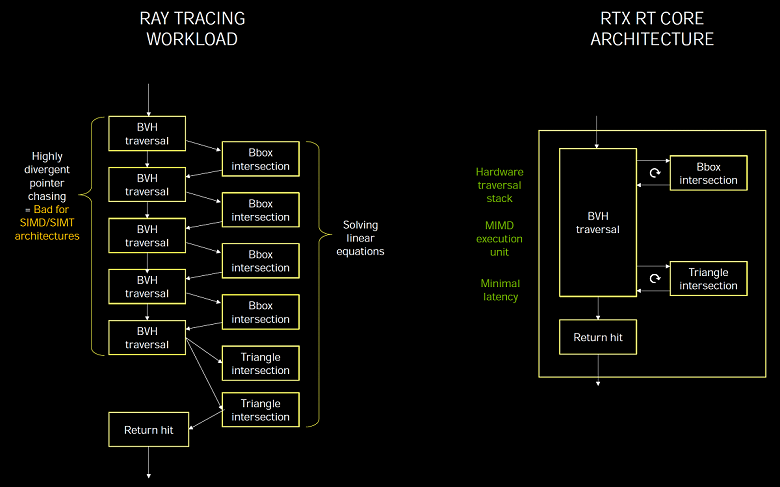
Проблема производительности при трассировки лучей заключается в том, что лучи зачастую некогерентны и их пересечения оптимизировать сложно. Например, лучи отражаются от
Полный текст статьи читайте на iXBT
