Видеоускоритель AMD Radeon RX 7900 XT (20 ГБ): теория, архитектура, описание карты XFX, синтетические, игровые тесты (включая тесты с трассировкой лучей), выводы

Общие сведения
Наконец-то до нас добралось долгожданное новое поколение графической архитектуры AMD — пока что не топовая модель Radeon RX 7900 XTX, а ее младшая сестра Radeon RX 7900 XT. Еще в декабре прошлого года компания AMD выпустила в продажу две модели видеокарт, и до нас они ехали несколько дольше обычного. Новые видеокарты основаны на GPU уже третьего поколения графической архитектуры RDNA (RDNA3), который стал первым графическим процессором, основанным на чиплетах — нескольких кристаллах на одной подложке — аналогично процессорам Ryzen той же AMD. Это должно помочь получить максимальную эффективность и снизить себестоимость по сравнению с привычным подходом в виде одного большого кристалла.
Компания AMD решила использовать чиплетную конфигурацию в Navi 31 (кодовое имя графических процессоров серии Radeon RX 7900) для того, чтобы достичь лучшей производительности при сохранении относительно невысокой сложности кристаллов (а значит, и меньшей себестоимости) — этот подход отличается от больших GPU, которые делает Nvidia. Инженеры AMD отделили некоторые участки, которые вполне можно перенести на более проверенный и менее дорогой техпроцесс, такие как кэш-память третьего уровня Infinity Cache и контроллеры GDDR6-памяти, и перенесли их с большого основного кристалла на шесть маленьких — memory cache die (MCD), что можно увидеть на схематическом изображении GPU.

Эти кристаллы производятся при помощи техпроцесса 6 нм, а основная часть GPU — graphics compute die (GCD) — при помощи более совершенного процесса 5 нм. И так как соединение кэшей и GPU должно быть высокоскоростным, то эти кристаллы соединяются друг с другом при помощи очень быстрого соединения, обеспечивающего пропускную способность более 5 ТБ/с между GCD и всеми MCD.
Архитектура RDNA3 обещает около 50% прироста энергоэффективности по сравнению с RDNA2, и это неплохая заявка на высокую конкурентоспособность, ведь решения на основе RDNA2 уже неплохо соперничали с видеокартами Nvidia. Новая архитектура приносит множество улучшений в вычислительных возможностях, подсистеме памяти и выводе информации на дисплеи, а также пытается устранить некоторые недоработки предыдущей архитектуры — RDNA3 обладает специализированными блоками ускорения искусственного интеллекта и улучшенными блоками аппаратной трассировки лучей, которые являлись главной ахиллесовой пятой предыдущего поколения.
Архитектура RDNA3 вводит новые вычислительные блоки с удвоенным темпом вычислений и оптимизацией, направленной на улучшение использования имеющихся ресурсов SIMD, а также новыми блоками ускорения ИИ, которые используются для выполнения матричных вычислений. По данным AMD, все улучшения должны дать рост производительности на такт на 17% по сравнению с RDNA2. Добавим к этому большее количество потоковых процессоров в чипе и повышенную тактовую частоту — и получим серьезный рост производительности по сравнению с предыдущим поколением. При этом типичное энергопотребление топовой модели RX 7900 XTX составляет всего 355 Вт, а для рассматриваемой сегодня RX 7900 XT — и вовсе лишь 300 Вт, что позволяет обходиться двумя 8-контактными разъемами дополнительного питания и кулерами меньшего размера по сравнению с решениями конкурента.

По данным AMD, новый флагман компании — Radeon RX 7900 XTX — обеспечивает до 70% преимущества в 4K-разрешении по сравнению с предыдущей топовой моделью RX 6950 XT. Это связано как с архитектурными преимуществами новой версии RDNA, так и с повышенной тактовой частотой и бо́льшим количеством исполнительных блоков, за что спасибо чиплетной конфигурации и продвинутым техпроцессам TSMC. Но сегодня мы рассмотрим модель Radeon RX 7900 XT, основанную на урезанной версии графического процессора Navi 31. Она также предназначена для требовательных игроков, выбирающих исключительно 4K-разрешение и максимальные настройки качества, а главным конкурентом для RX 7900 XT на рынке является Nvidia GeForce RTX 4070 Ti, имеющая чуть меньшую цену.
Основой рассматриваемой сегодня модели видеокарты Radeon RX 7900 XT является новый графический процессор Navi 31, базирующийся на архитектуре RDNA третьего поколения, которая очень похожа и тесно связана с архитектурами RDNA предыдущих версий, так что перед прочтением статьи будет полезно ознакомиться с нашими предыдущими материалами по видеокартам компании AMD:

| Графические ускорители серии Radeon RX 7900 | |
|---|---|
| Кодовое имя чипа | Navi 31 |
| Технология производства | 5 нм и 6 нм (N5 и N6 TSMC) |
| Количество транзисторов | 57,7 млрд (26,8 млрд у Navi 21) |
| Площадь ядра | 522 мм² (520 мм² у Navi 21) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 384-битная: 6 независимых 64-битных контроллера памяти с поддержкой GDDR6 |
| Частота графического процессора | до 2500 МГц |
| Вычислительные блоки | 96 вычислительных блоков CU, состоящих в целом из 6144 (или 12288, смотря как считать) ALU для целочисленных расчетов и расчетов с плавающей запятой (поддерживаются форматы INT4, INT8, INT16, FP16, FP32 и FP64) |
| Блоки трассировки лучей | 96 блоков Ray Accelerator для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 384 блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 24 широких блока ROP на 192 пикселя с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка интерфейсов HDMI 2.1b и DisplayPort 2.1 |
| Спецификации референсной видеокарты Radeon RX 7900 XT | |
|---|---|
| Частота ядра (игровая/турбо) | 2025/2400 МГц |
| Количество универсальных процессоров | 5376 (10752) |
| Количество текстурных блоков | 336 |
| Количество блоков блендинга | 192 |
| Эффективная частота памяти | 20 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 320 бит |
| Объем памяти | 20 ГБ |
| Пропускная способность памяти | 800 ГБ/с |
| Вычислительная производительность (FP32) | до 51,6 терафлопс |
| Теоретическая максимальная скорость закраски | 460 гигапикселей/с |
| Теоретическая скорость выборки текстур | 804 гигатекселя/с |
| Шина | PCI Express 4.0×16 |
| Разъемы | один HDMI 2.1b, два DisplayPort 2.1 и один USB Type C |
| Энергопотребление | до 300 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2,5 |
| Рекомендуемая цена | $899 |
Наименование новой модели видеокарты соответствует принятому несколько лет назад принципу названий для решений компании AMD: по сравнению с Radeon RX 6900 XT поменялась первая цифра поколения. Суффикс XT остался, но теперь это не топовая модель: новинка стоит на шаг ниже флагмана семейства, которым является Radeon RX 7900 XTX, который мы также очень скоро подробно разберем.
Цены на пару видеокарт Radeon RX 7900 решили установить… несколько более высокие, чем мы привыкли, но это объясняется общей ситуацией на мировых рынках. Нас больше беспокоит очень малая разница в цене между XT и XTX — всего лишь $100 на североамериканском рынке. Мы еще не раз остановимся на этом вопросе, но даже поверхностный взгляд на характеристики двух видеокарт говорит о том, что разница в производительности между ними получилась больше разницы в цене.

Впрочем, сравнивать цены правильнее с решениями конкурента, и с этим всё более-менее нормально: главным конкурентом RX 7900 XT является младшая из трех вышедших старших видеокарт нового семейства GeForce — RTX 4070 Ti. Интереснее всего, что в этом поколении не видеокарта AMD сто́ит дешевле конкурирующей, а решение Nvidia. Хотя всегда можно сказать, что у них есть еще более дорогая RTX 4080, но по скорости RX 7900 XT ближе все-таки к RTX 4070 Ti.
По объему видеопамяти для рассматриваемой сегодня видеокарты AMD в соответствии с шириной шины особого выбора не было: можно было поставить или 10, или 20 ГБ. Понятно, что объема в 10 ГБ не хватает уже сейчас, и для RX 7900 XT можно считать второй вариант не просто приемлемым и достаточным на данный момент, но и перспективным. Пока что наличие 20 ГБ видеопамяти против 12 ГБ у RTX 4070 Ti не принесет преимущества RX 7900 XT, но эту разницу можно считать потенциальным недостатком решения Nvidia, что может негативно сказаться в ближайшие годы.
Референсный дизайн у моделей Radeon RX 7900 XT и RX 7900 XTX схожий, но рассматриваемая сегодня младшая модель в целом чуть меньше по всем размерам и не имеет RGB-подсветки, в отличие от старшей. Обе видеокарты значительно меньше соответствующих по цене видеокарт компании Nvidia. Для вывода изображения используются два стандартных разъема DisplayPort 2.1 и один HDMI 2.1, также есть разъем USB-C с поддержкой вывода DisplayPort — для использования с VR-шлемами.

Для дополнительного питания AMD использует два привычных 8-контактных разъема, что в теории дает до 375 Вт при долговременной нагрузке. Nvidia применяет спорный новый 16-контактный разъем 12VHPWR, который, впрочем, дает возможность подать до 600 Вт питания. То есть, с одной стороны, видеокарты AMD куда проще установить в любую систему, не имеющую новых (и довольно редких пока) блоков питания, зато два 8-контактных разъема ограничивают максимальную мощность, подаваемую на видеокарту. Неудивительно, что некоторые розничные варианты видеокарт серии RX 7900 имеют по три 8-контактных разъема — особенно предназначенные для любителей разгона.
Новый дизайн референсных видеокарт нового поколения довольно строг — четкие линии, матовый черный цвет, отсутствие лишних украшательств. Вид у референсных карт простой и элегантный, а для желающих более цветастого внешнего вида партнеры AMD выпустили большое количество моделей с собственными дизайном, размерами, подсветкой и системами охлаждения, некоторые из них фабрично разогнаны и имеют повышенные уровни энергопотребления и производительности.
Особенности архитектуры
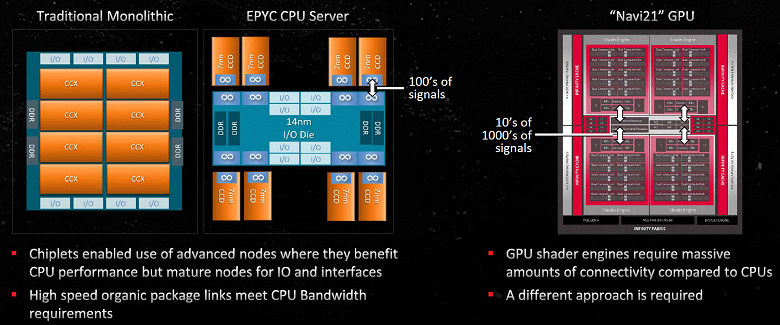
Одним из самых важных отличий Navi 31 является переход на чиплетную компоновку. В теории, чиплеты отлично подходят для конфигурации GPU, так как позволяют разбивать огромные монолитные кристаллы на несколько более мелких — это позволяет как улучшать масштабируемость (набирать топовые модели из большего количества кристаллов, а средние и младшие — из меньшего количества точно таких же) и применять кристаллы, произведенные при помощи разных техпроцессов, что может быть полезно для снижения себестоимости. А основная сложность в чиплетной компоновке GPU — линии связи между чиплетами, которые должны быть очень быстрыми и при этом не слишком большими по площади и потреблению энергии, иначе это съест всю пользу от разделения на чиплеты.
Чиплетная конфигурация
Чиплетная организация Navi 31 состоит из одного основного кристалла Graphics Compute Die (GCD) и нескольких чиплетов с кэшем и контроллерами памяти — Memory Cache Die (MCD) и отличается от организации центральных процессоров Zen последних поколений. В Zen 2 и более поздних используется отдельный чиплет ввода-вывода Input/Output Die (IOD), содержащий все внешние интерфейсы вроде PCIe и USB, а в последних добавили и функциональность обработки видеоданных и встроенного графического ядра целиком. Чиплет IOD соединен с одним или двумя вычислительными чиплетами — Core Compute Die/Core Complex Die (CCD), содержащим вычислительные ядра, кэш-память и остальное, при помощи быстрого соединения.
Типичные вычислительные алгоритмы, работающие на ядрах CPU, в основном помещаются в кэш-память разных уровней, а каналов к внешней памяти у настольных Zen всего два 64-битных, и в этом заключается важное отличие CPU от GPU. CCD-чиплеты Ryzen имеют небольшую площадь, порядка 70 мм² для Ryzen 7000, а IOD может иметь площадь лишь 122 мм² — также в серии Ryzen 7000. Графические процессоры совершенно иные, им нужна очень большая пропускная способность памяти для того, чтобы обеспечить работой все вычислительные ядра GPU — до 1 ТБ/с и больше. Да и требования к скорости связей внутри основной части GPU выше, высокие межкристальные задержки при разделении на много мелких кристаллов не подходят. Поэтому решение из Ryzen тут не сработало бы, а оптимально чуть ли не противоположное — размещение контроллеров памяти и кэш-памяти на нескольких небольших кристаллах, тогда как основные вычислительные блоки расположены в едином центральном чиплете GCD.

Основной чиплет содержит почти всё: вычислительные блоки CU и все основные функциональные блоки, кроме контроллеров памяти и кэш-памяти третьего уровня. Чиплеты с контроллерами памяти и L3-кэшем — Memory Cache Die (MCD) — содержат довольно большие блоки кэш-памяти Infinity Cache и физический интерфейс памяти GDDR6, плюс линки Infinity Link для подключения к основному чиплету GCD.
Главный чиплет содержит 45,7 млрд транзисторов в кристалле площадью 300 мм², который производится на TSMC с использованием современного техпроцесса 5 нм, а чиплеты MCD содержат лишь по 2,05 млрд транзисторов каждый и имеют площадь всего 37 мм² — они производятся по техпроцессу 6 нм. Кэш-память и внешние интерфейсы памяти масштабируются хуже всего, и плотность транзисторов в этом случае получается заметно ниже, чем для основного чиплета — 55,4 млн транзисторов на мм², тогда как у GCD почти втрое плотнее — 152,3 млн/мм².
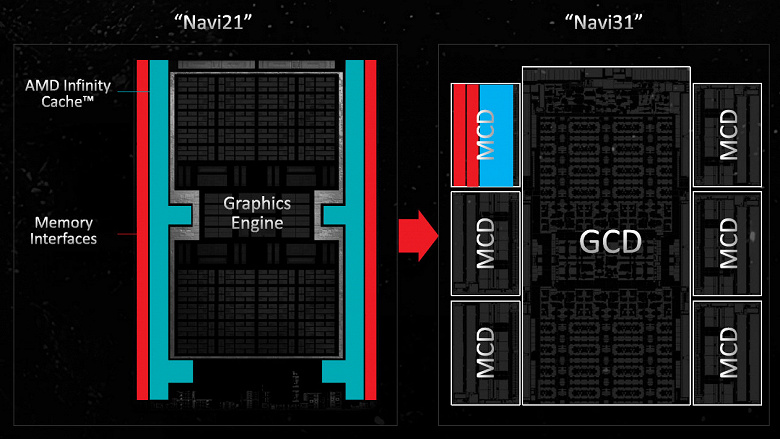
Отделение контроллеров памяти и кэш-памяти третьего уровня от остальных функциональных блоков графического процессора помогает снизить себестоимость производства, что потенциально может позволить AMD выпускать решения с лучшими характеристиками при схожей цене. Пока что не очень понятно, дает ли текущее разделение на чиплеты достаточное снижение себестоимости производства кристаллов, чтобы покрыть накладные расходы на сборку этих чиплетов на одной подложке и их дополнительное тестирование. Вероятно, пока что это компромиссное решение на начальной стадии, но потенциал у него немалый.
Кроме того, у чиплетов есть и явные недостатки — в виде дополнительных накладных расходов и задержек, связанных с использованием связи чиплетов между собой, которая явно менее производительна, чем соответствующие линии в одном кристалле. Но это лишь начало — чиплеты Zen 2 тоже не были идеальными, а скорее не слишком эффективными, но зато в чиплетной организации Zen 3 и Zen 4 компания уже добилась ожидаемого преимущества. Вероятно, так же будет и с графическими процессорами.
И не надо путать чиплетный графический процессор Navi 31 с многочиповым модулем Vega 10, в котором просто используется HBM2-память в отдельных кристаллах, но на той же подложке. В чиплетном GPU различные блоки помещены в разные кристаллы, и один основной чиплет GCD просто не может работать самостоятельно — без L3-кэшей и контроллеров памяти, находящихся в отдельных MCD-чиплетах. Канал связи между чиплетами кэша-памяти и графическим чиплетом называется Infinity Link — он отвечает за маршрутизацию Infinity Fabric между кристаллами GPU, и совокупная пропускная способность между чиплетами составляет 5,3 ТБ/с, а пропускная способность между отдельными чиплетами составляет 900 ГБ/с, что больше ПСП для Radeon RX 6950 XT.

Одной из возможных проблем чиплетной организации может быть дополнительное энергопотребление всех каналов Infinity Link — естественно, что внешние каналы потребляют больше энергии, чем внутренние. Но в AMD отдельно работали над оптимизацией связей между чиплетами GPU, и в итоге получили высокопроизводительное разветвленное соединение, упакованное куда более плотно по сравнению с тем, что используется в Ryzen. Это значительно снизило требования к энергопотреблению, и в итоге получилось, что все соединения Infinity Fanout, обеспечивающие высокую пропускную способность, потребляют менее 5% общего энергопотребления всего GPU, а это не так уж и много.

Еще один момент, связанный с логикой Infinity Link на чиплетах GCD и MCD — немалая площадь, которую она занимает на кристаллах. На GCD все шесть интерфейсов занимают до 10% площади, а на MCD и вовсе около 15% от общей площади чиплета. Так что однокристальный GPU такой сложности был бы не слишком большим — явно менее 425 мм². Правда, с учетом новизны и относительной дороговизны производства по техпроцессу 5 нм, чиплетная организация может быть вполне обоснована даже на начальной стадии, если себестоимость производства разных чиплетов и сборка их на одной подложке, а также дополнительное тестирование, обходятся дешевле производства одного большего кристалла.
Основной вычислительный кристалл
Чиплетная компоновка — просто более удобный формат физической организации большого чипа, а интересные архитектурные изменения RDNA3 скрыты внутри основного чиплета — в исполнительных блоках. Рассмотрим базовые блоки любого современного чипа AMD — вычислительные блоки Compute Unit (CU), каждый из которых имеет собственное локальное хранилище для обмена данными или расширения локального регистрового стека, а также кэш-память и полноценный текстурный конвейер с блоками выборки и фильтрации текстур. Каждый из таких вычислительных блоков самостоятельно занимается планированием и распределением работы, и в RDNA3 с ними произошли некоторые изменения, на которых мы подробно остановимся в дальнейшем. А пока что рассмотрим блок-схему полной версии графического процессора Navi 31:
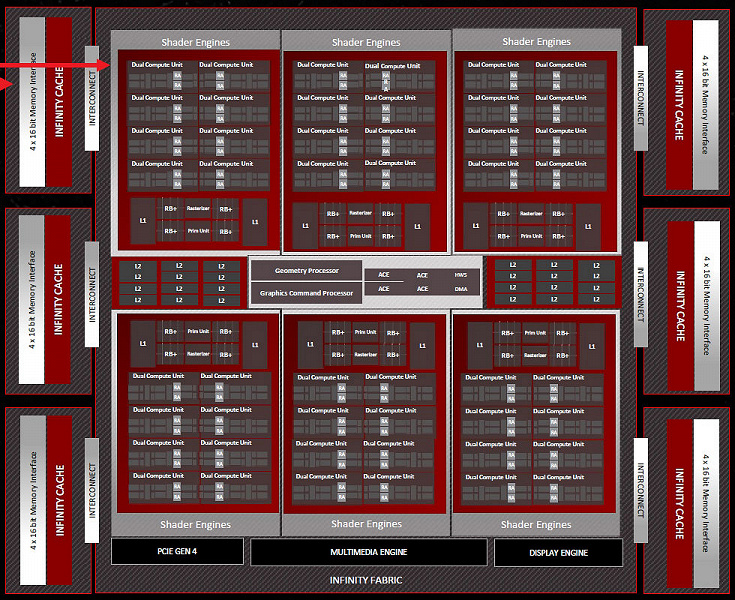
Основной чиплет GCD содержит шесть шейдерных движков Shader Engines, каждый из которых состоит из 16 вычислительных блоков (или восьми двойных вычислительных блоков RDNA3), имеющих по 1024 потоковых процессора. То есть, всего в чипе содержится 6144 потоковых процессора, 96 ускорителей трассировки лучей и 96 ИИ-ускорителей. Navi 31 имеет 384 текстурных блока TMU и аж 192 блоков ROP — вполовину больше, чем Navi 21.
Топовая модель Radeon RX 7900 XTX основана на полном чипе Navi 31 и включает все 96 CU, а младшая видеокарта из пары использует основной чиплет с несколькими отключенными блоками — число потоковых процессоров снижено с 6144 до 5376 (активны 84 вычислительных блока из 96), 84 ускорителей трассировки лучей, 336 текстурных модуля и все 192 блока ROP. Это не единственное изменение RX 7900 XT: из шести MCD-чиплетов с 96 МБ L3-кэша модель XT использует только пять кристаллов, что ограничивает объем L3-кэша на уровне 80 МБ, ширина шины памяти становится 320-битной (один 64-битный контроллер находится в неактивном MCD — точнее, два 32-битных) и ее объем урезается до 20 ГБ по сравнению с 24 ГБ у топовой модели. Чипы GDDR6-памяти работают на эффективной скорости 20 Гбит/с, что в итоге дает неплохую пропускную способность в 800 ГБ/с.
Что касается физического воплощения, то все шесть чиплетов MCD на подложке RX 7900 XT присутствуют, конечно же — в том числе чтобы не нарушать прижим радиатора охлаждения, но один из них электрически отключен от основного чиплета — и в теории, этот отключенный кристалл чиплета MCD может быть бракованным и нерабочим, а уж как дело обстоит на деле — доподлинно неизвестно.
Улучшенная подсистема памяти
Итак, архитектура RDNA3 — это улучшенная и расширенная RDNA2 с некоторыми новыми возможностями. Для увеличения пропускной способности в ней была серьезно изменена подсистема кэширования на всех уровнях, а соответствующее увеличение вычислительной производительности достигается не просто добавлением большего количества вычислительных блоков, но реализацией возможности двойного запуска команд на исполнение.
AMD утверждает, что они смогли улучшить использование исполнительных блоков на 20% — если в графических процессорах RDNA2 функциональные блоки относительно часто простаивали, то в RDNA3 над этим поработали. Самые большие изменения внутри основного чиплета произошли в вычислительных блоках CU и процессорах — увеличенный объем кэш-памяти всех уровней, увеличенный регистровый файл, а также более широкие и производительные интерфейсы между блоками. Самих блоков CU в Navi 31 больше, чем в Navi 21, и они работают быстрее на 17,4% за такт и на более высокой частоте, что вместе дает значительное повышение производительности GPU нового поколения.
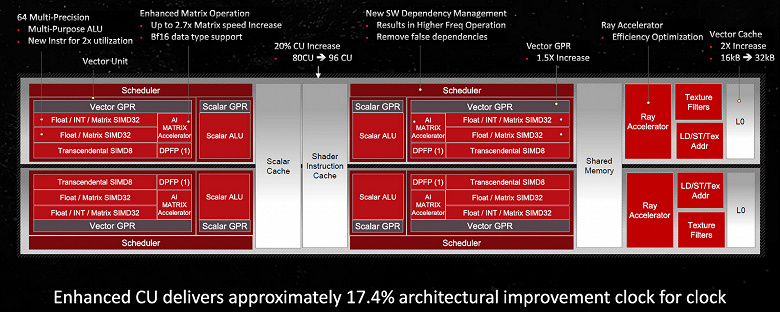
Navi 31 имеет больше вычислительных блоков по сравнению с Navi 21, и каждый из них имеет более высокую вычислительную производительность, поэтому для сохранения эффективности должна быть усилена подсистема памяти. И в RDNA3 получили значительное увеличение пропускной способности на каждом уровне подсистемы памяти, а особенно ускорились кэши первого и второго уровней. Как и прошлое поколение RDNA, третье имеет четырехканальный скалярный кэш объемом 16 КБ, задержка загрузки и использования для которого несколько снижена благодаря повышенной тактовой частоте. L0-кэш увеличен до 32 КБ (вдвое больше, чем в RDNA 2), также была увеличена емкость кэшей среднего уровня — L1 и L2 — для того, чтобы лучше справляться с повышенной пропускной способностью более мощного графического процессора. RDNA2 имела 16-канальный L1-кэш объемом в 128 КБ, совместно используемый массивом шейдерных блоков, а в RDNA3 его емкость удвоили до 256 КБ, сохраняя 16-канальность. Емкость L2-кэша также увеличена до 6 МБ по сравнению с 4 МБ в RDNA2 при сохранении той же 16-канальности. При этом, несмотря на увеличение пропускной способности, в RDNA3 обеспечивается снижение задержек для L1 и L2.
Канал между основными вычислительными блоками и L1-кэшем стал в полтора раза шире — 6144 байта за такт, как и канал между L1- и L2-кэшем — 3072 байта за такт. L3-кэш, также известный как Infinity Cache, в Navi 31 по сравнению с Navi 21 даже уменьшился в объеме — он составляет 96 МБ (для старшей модели RX 7900 XTX) против 128 МБ, зато связь между L3 и L2 стала в 2,25 раза шире — 2304 байта за такт, и пропускная способность его повысилась до 5,3 ТБ/с, что в 2,7 раз больше, чем пиковая пропускная способность интерфейса у RX 6950 XT. Всё это справедливо лишь для топовой RX 7900 XTX, а младшая RX 7900 XT имеет лишь пять активных MCD и уже 1920 байт/такт до 80 МБ кэша Infinity Cache.
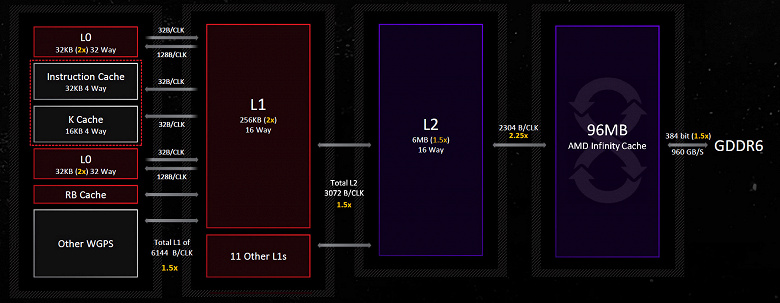
Другие ухудшения в подсистеме кэширования в виде повышенных задержек L3-кэша неудивительны — Infinity Cache теперь реализован в виде отдельных чиплетных кристаллов с контроллерами памяти и L3-кэшем. Возможно, RDNA3 сможет справиться с этим, обслуживая большее количество обращений к памяти при помощи более быстрого и объемного L2-кэша, и количество обращений к Infinity Cache в целом снизится.
Что касается ПСП видеопамяти, шесть 64-битных каналов дают 384-битную шину GDDR6-памяти, которая работает на скорости 20 Гбит/с — по сравнению с 16 Гбит/с у 6900 XT и 18 Гбит/с у RX 6950 XT. Так что пропускная способность возросла до 960 ГБ/с (для RX 7900 XTX), и это лишь на 5% меньше, чем 1008 ГБ/с у GeForce RTX 4090, хотя в прошлом поколении разрыв был чуть ли не двукратным — 512 ГБ/с и 936 ГБ/с для RX 6900 XT и RTX 3090, соответственно. Этот прирост будет весьма полезным в современных играх, особенно в 4K-разрешении. Да и ПСП у RX 7900 XT также достаточно велика, хоть от него и отрезали один из шести контроллеров памяти. Это должно сохранить относительно высокую производительность и при сниженном объеме L3-кэша.
Что касается сравнения с конкурирующими GPU, то компания Nvidia для уменьшения требований к пропускной способности внешней памяти в разы увеличила объем L2-кэша вместо добавления третьего уровня кэш-памяти — это увеличило задержку доступа к L2-кэшу по сравнению с графическими процессорами AMD, но зато дало графическим процессорам архитектуры Ada Lovelace преимущество по задержке. И объем L2-кэша в чипах семейства GeForce RTX 40 чуть ли не равен объему Infinity Cache в чипах AMD. Кроме этого, задержка доступа к видеопамяти в RDNA3 чуть выше по сравнению с Ada Lovelace — отчасти потому, что решения AMD проверяют дополнительный уровень кэш-памяти.
Рассматриваемая модель Radeon RX 7900 XT имеет 20 ГБ локальной памяти, и этот объем можно считать более чем достаточным —, а если вдруг нужно больше, то существует старшая модель RX 7900 XTX с 24 ГБ памяти, которая продается чуть дороже. Хотя игры становятся всё более требовательными и используют всё больше и больше ресурсов (та же аппаратная трассировка лучей предъявляет дополнительные требования к объему памяти) и некоторые современные игры уже занимают более 12 ГБ памяти при максимальных графических настройках, на данный момент даже 12 ГБ локальной видеопамяти (как у RTX 4070 Ti) всё еще достаточно, но 20 ГБ можно считать приличным запасом на будущее, да и сейчас нехватка 12 ГБ может сказаться, хоть и в редких случаях.
В дополнение к обычной иерархии глобальной памяти, графические процессоры имеют и быструю оперативную память — локальной память GPU. В графических процессорах компании AMD это называется Local Data Share (LDS), а графические процессоры Nvidia называют это общей (или разделяемой) памятью. Как и в предыдущих поколениях RDNA, в каждом укрупненном вычислительном блоке новой архитектуры RDNA3 есть LDS объемом в 128 КБ, состоящей из двух блоков по 64 КБ, каждый из которых связан с одним из CU. Похоже, что в RDNA3 были улучшены задержки доступа к LDS благодаря архитектурным улучшениям и высокой тактовой частоте, а низкая задержка доступа к LDS может быть полезна в том числе и при трассировке лучей, так как эта память используется для хранения информации о BVH.
Изменения вычислительных блоков
Одними из самых важных изменений в графической архитектуре RDNA3 стали вычислительные блоки с одновременным запуском двух инструкций на исполнение (dual issue), специальные оптимизации для более полного использования имеющихся ресурсов, поддержка новых математических форматов, а также ускорение ИИ-вычислений при помощи перераспределения ресурсов SIMD для исполнения матричных функций. Все вместе эти оптимизации должны дать повышение производительности на такт порядка 17% по сравнению с вычислительными блоками архитектуры RDNA2.
RDNA3 имеет большое преимущество в вычислительной производительности — не только потому, что у него больше укрупненных блоков WGP самих по себе, но и благодаря архитектурному изменению. SIMD-блоки получили ограниченную возможность одновременного выполнения двух инструкций — некоторые операции могут быть упакованы в одну инструкцию VOPD (vector operation, dual — векторная операция, двойная) в режиме Wave32. В режиме Wave64 SIMD-блоки начинают выполнение вейвфронта шириной 64 за один цикл. Wave64 может использовать ALU в режиме удвоенного темпа при исполнении соответствующего кода, а в режиме Wave32 компилятор выполняет переупорядочивание и упаковку инструкций в VOPD.
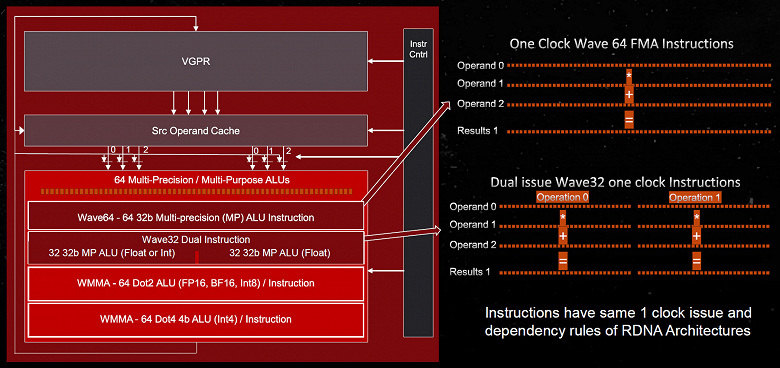
К сожалению, пока что прирост производительности от этого нововведения невелик — тестовая сцена с трассировкой лучей и использованием VOPD обеспечила лишь 4% прирост в количестве кадров в секунду за счет устранения узкого места ALU. Возможно, в будущем мы увидим некоторые улучшения по мере оптимизации компилятора и развития использования сложных шейдеров и трассировки лучей. Теоретически эта возможность удваивает вычислительные возможности FP32 при небольших накладных расходах (кроме самих дополнительных исполнительных блоков), но уж слишком это зависит от возможностей компилятора шейдеров. В теории, со временем AMD может помочь разработчикам лучше оптимизировать игровой код, заменив скомпилированные автоматически шейдеры оптимизированными вручную.
Каждый SIMD-блок способен запускать до двух инструкций за такт, но они могут выдать вторую инструкцию только когда аппаратное и программное обеспечение AMD способно извлечь ее из текущего вейвфронта — если следующая инструкция не может быть выполнена параллельно с текущей, то дополнительные ALU не будут использоваться. Это означает, что в RDNA3 стало сложнее добиться вычислительной производительности, близкой к пиковой, а ведь RDNA первого поколения избавилась от похожей зависимости в GCN, когда реальная производительность была далека от теоретической. Посмотрим, что получилось у них в этот раз.
Двойной запуск команд является сравнительно дешевым способом увеличить производительность, если достаточно большую долю времени дополнительные блоки будут заняты работой при двойном запуске на исполнение. Но эффективность использования ALU в RDNA3, скорее всего, будет ниже, чем в RDNA2.
Мы видели недавно на примере видеокарт Intel, к чему приводит недостаточная эффективность использования имеющихся исполнительных блоков — теоретически они должны быть гораздо производительнее, чем получается на практике. Так и тут — в теории RX 7900 XTX/XT потенциально могут выдавать более чем вдвое больше терафлопов по сравнению с RX 6950 XT, а на практике преимущество будет куда меньше — ведь даже по заявлениям AMD оно не превышает 70%.
Соответственно, и количество потоковых процессоров в новых GPU теперь можно считать несколько иначе. AMD говорит, что в нем содержатся все те же 64 потоковых процессора (Streaming Processor — SP) на вычислительный блок CU, но теперь на один CU приходится четыре SIMD32 векторных блока, два из которых могут обрабатывать только операции с плавающей запятой FP32 или матричные, но не целочисленные INT32. Нечто схожее сделала компания Nvidia в Ampere (и это продолжилось в Ada), и получается некоторая нестыковка между подсчетом, принятым ранее и тем, что получается в RDNA3.
Потенциальную производительность FP32-вычислений для всего GPU повысили вдвое, не изменяя целочисленные возможности. То есть по сравнению с CU предыдущего поколения RDNA2 каждый CU теперь имеет 128 аналогичных потоковых процессоров и 12288 ALU на весь чип, или 64 потоковых процессоров (и 6144 потоковых процессоров на GPU) с удвоенной пропускной способностью только для FP32-вычислений. Собственные данные AMD говорят о 6144 потоковых процессорах и 96 блоках CU для RX 7900 XTX и 84 CU с 5376 ALU для RX 7900 XT, так же будем считать и мы. Но с учетом того, что пиковая производительность FP32-вычислений удвоилась — хотя бы теоретически. Это похоже на то, что есть у Nvidia в Ampere и Ada — 128 блоков FP32 и 64 блока INT32 на каждый CU.
Ускорение искусственного интеллекта
Кроме удвоенной производительности FP32-вычислений, была повышена и производительность матричных вычислений, которые часто используются в задачах искусственного интеллекта. Общее увеличение производительности матричных вычислений указывается до 2,7 раз, но это учитывает все улучшения, включая частоту и увеличенное количество блоков.
Блоки ИИ-ускорения, появившиеся в архитектуре RDNA3, переназначают SIMD32 модули для выполнения матричных вычислений вместо обычных FP32/FP16-операций. Вместе с FP16 поддерживаются форматы BF16 и INT8, и все три имеют одинаковую пиковую производительность, превышающую вдвое производительность при одинарной точности с плавающей запятой — FP32. Потоковые процессоры RDNA2 и так умели исполнять операции половинной точности FP16 в двойном темпе, но в RDNA3 были сделаны некие оптимизации по пропускной способности и улучшению энергоэффективности, включая новые инструкции, поддерживаемые именно в режиме матричных вычислений.
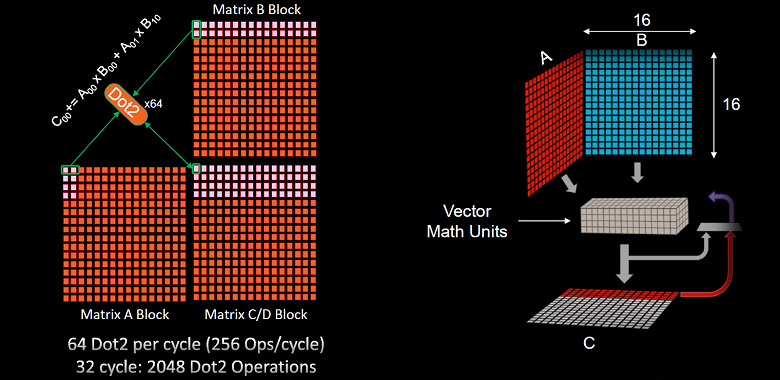
Вычислительный блок, содержащий SIMD-блоки, может работать в виде матричного ускорителя, выполняя соответствующие вычисления — AI Matrix Accelerator, что повышает производительность матричного умножения в 2,7 раза. Графический процессор Navi 31 ускоряет матричные вычисления, распространенные в задачах искусственного интеллекта, аналогично тензорным ядрам Nvidia и векторным ядрам Intel XMX. Для игровых GPU это важно для возможного будущего использования в технологии масштабирования FSR 3.0 — ведь теперь аппаратно ускоренный ИИ есть у всех трех главных компаний, производящих графические процессоры.
Пока что не совсем понятно, как сравнивать возможности GPU разных производителей по производительности матричных/векторных/тензорных вычислений, но похоже, что пиковые возможности Navi 31 всё же ощутимо ниже, чем у конкурирующих видеокарт Nvidia. И всё же, много важнее эффективная производительность в реальных задачах, и ее мы сможем сравнить лишь когда появится ПО, использующее AI Accelerator в AMD и аналогичные блоки в других GPU.
Второе поколение блоков трассировки лучей
Невозможно не упомянуть улучшения в аппаратных блоках трассировки лучей, которые были сделаны в новой архитектуре RDNA3. Ray Accelerator первого поколения, которые мы видели в RDNA2, были явно спроектированы впопыхах, в попытках догнать по функциональности конкурента. Но графические процессоры Nvidia содержат продвинутые аппаратные блоки с фиксированными функциями расчета пересечения лучей, что разгружает SIMD-блоки и значительно ускоряет обработку. Было очевидно, что в RDNA3 компания AMD должна улучшить Ray Accelerator, и по их заявлению было достигнуто повышение производительности трассировки лучей в среднем на 80% по сравнению с RDNA2, если учесть все факторы (количество блоков, тактовую частоту и программно-аппаратные оптимизации).
Трассировка лучей в графических процессорах RDNA3 лишь догоняет конкурентов. В соответствующих аппаратных блоках RDNA2, которые занимаются трассировкой лучей, нет фиксированной логики для обхода структуры Bounding Volume Hierarchy (BVH), часть работы выполняется универсальными блоками и
Полный текст статьи читайте на iXBT
