Техники скоринга и приоритизации бэклогов
Ну что, как там ваши планы на изоляцию? Зимние вещи убрали? Желанные киношки посмотрели? Пылящиеся книжки прочитали? А до полезностей, как всегда, нет времени. Да ладно, не оправдывайтесь — для тех, кто никак не выкроит часок для просмотра видео с нашего канала на Ютубе, мы сделали быстроусвояемую статью. Имейте совесть, всего-то 15 минут вместо 60:)
Сегодня коснёмся продуктового менеджмента и разберём приоритизацию бэклогов. Продуктовый менеджмент стоит чуточку выше, чем проджект-менеджмент: он больше про управление продуктами в целом и тесно связан с маркетингом. На закуску посмотрим техники скоринга и оценку задач.
Создайте конкурс на workspace.ru — получите предложения от участников CMS Magazine по цене и срокам. Это бесплатно и займет 5 минут. В каталоге 15 617 диджитал-агентств, готовых вам помочь — выберите и сэкономьте до 30%.
Создать конкурс →
Ситуация
Когда есть есть бэклог, менеджеру нужно каким-то образом расставлять в нем приоритеты. Скрам говорит, что первыми должны идти самые важные с точки зрения бизнеса задачи. Но тут возникает две проблемы.
Первая — справедливый момент субъективизма: часто приоритеты выставляются так, как владельцу бизнеса взбредет. в голову. Но иногда владелец может сильно «галлюцинировать» и нести откровенную чушь, но при этом быть уверен, что все так и есть.
Вторая проблема: слишком много стейкхолдеров верхнего уровня со стороны бизнеса на больших проектах или в крупных компаниях. У каждого из них могут быть свои противоречивые требования. Если собрать, например, пять топов большой компании и попросить их приоритизировать свои требования, скорее всего, каждый будет утверждать, что его задачи имеют нулевой приоритет, и их нужно делать прямо сейчас.
Хорошие новости — есть несколько методик, которые помогают в этом случае:
-
договариваться о приоритетах — выбирать, что важнее, а что можно отложить;
-
устанавливать критерии приоритизации бэклога (чуть менее субъективные, чем чья-то галлюцинация — увы, совсем без субъективизма не получится).
Методы приоритизации задач
Как выглядит бэклог?
Бэклог — это таблица. В одной колонке — список чего либо (какие-то хотелки), есть колонка с оценкой (estimate) и есть колонка с приоритетами. Приоритеты — это какие-то числа, как правило, большие. Большие для того, чтобы между приоритетами оставались «дырки», куда можно добавлять новые задачи (или чтобы легко менять приоритетность).
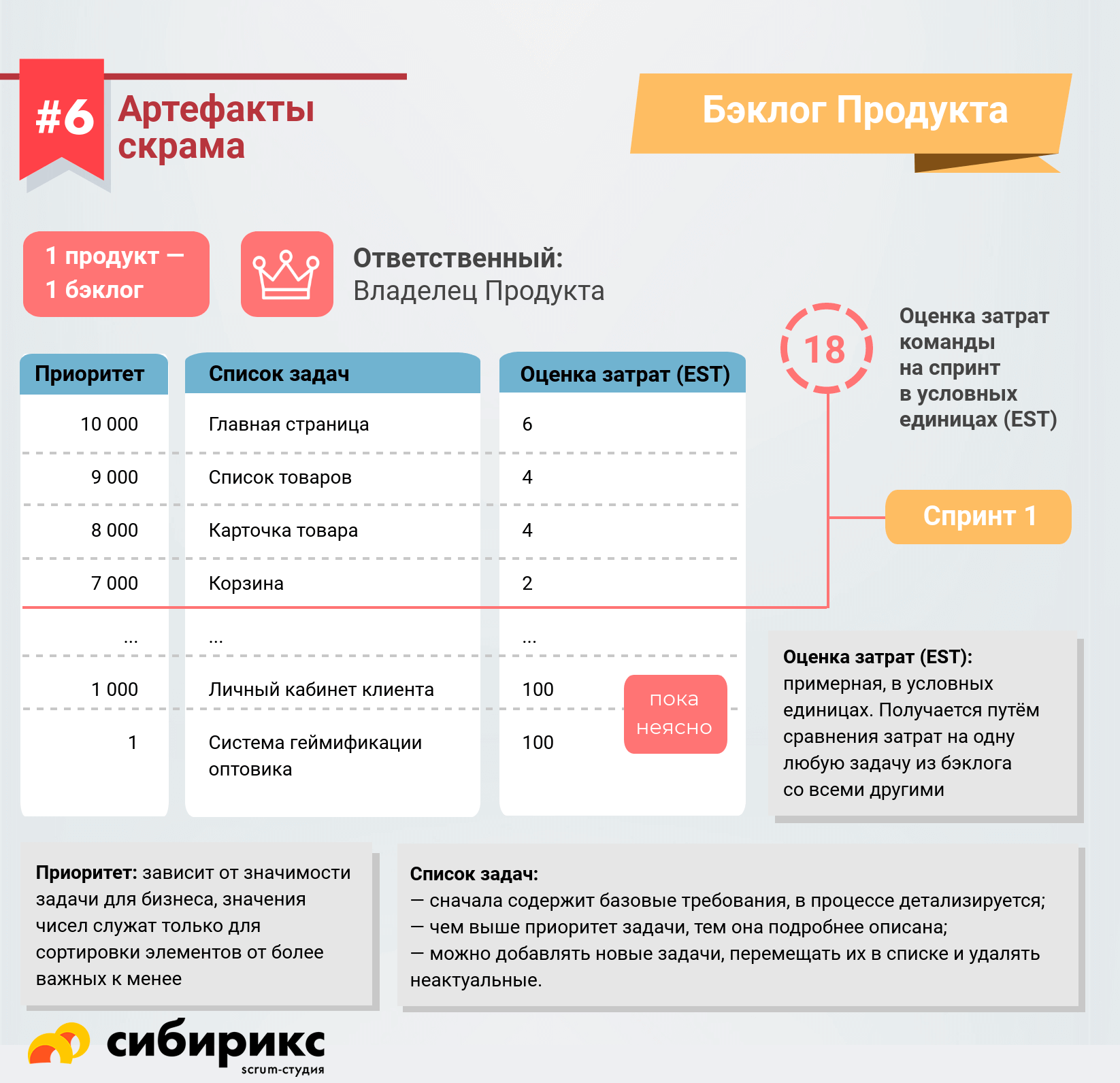
По классике приоритеты выставляются с точки зрения Business Value (ценности для бизнеса) — того, что для бизнеса нужно в первую очередь, оно и пойдет в работу на первом этапе. Но есть другие способы приоритизации, которые бывают удобнее — особенно, если у вас есть ворох разношерстных задач.
Story Mapping
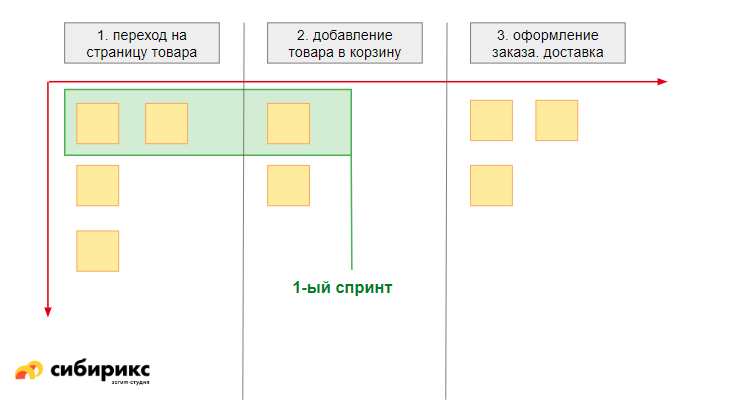
Допустим, у вас есть очень много задач, они мелкие и вообще без приоритетов и привязки к каким-то группам. Что с ними делать? Разбейте их на Story Mapping. Как это работает:
Шаг. Строим последовательность того, как юзеры будут пользоваться вашим продуктом, и какие шаги они будут предпринимать. Простой пример:

Шаг. На стикеры выписываем, какие по каждому из этих процессов есть детали — чем ниже висит стикер у каждого этапа, тем ниже у него приоритет.
Результат: весь список задач разбит по шагам пути пользователя, плюс у каждой фичи есть приоритеты (чем ниже фича висит в листе, тем у неё ниже приоритет с точки зрения всего пути пользователя).

Где и как применять
Допустим, у вас действительно набралось очень-очень много задач. Тогда вы выписываете их все на стикеры и делаете Story Mapping. Лучше — в команде.
Другой вариант — у вас идёт брейншторм, вы придумываете, каким дальше будет ваш продукт и какие фичи брать в работу. У команды много идей, какие-то хотелки вам «насыпал» маркетинг — нужно понять, каким образом это всё вообще кластеризовать. Story Mapping особенно хорошо работает в такой ситуации.
Оговорка: этот метод применим именно с точки зрения продуктового менеджмента, когда есть много задач, непонятно, какие из них первыми брать в проработку. Грубо, когда мы только продумываем сам продукт и то, какой функционал он будет включать. Дальше это уже режется на кусочки, из которых можно создавать спринты, и забирается в работу.
Плюсы Story Mapping
-
Метод позволяет построить связи в системе, на основе которых потом проще формировать спринты.
-
Когда много стейкхолдеров и много людей, у которых есть интересы в проекте, метод позволяет договориться о реальных приоритетах — что более важно, а что менее.
Value & Effort (или Lean Prioritization) для идей
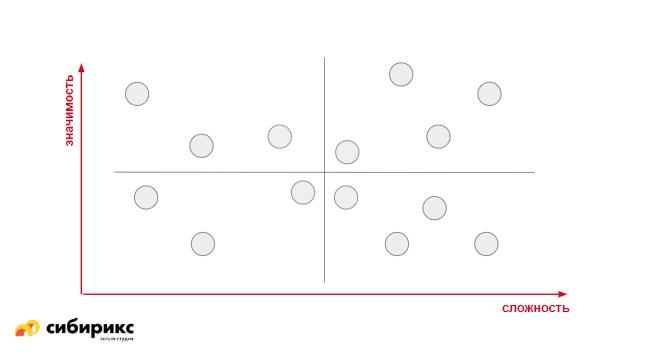
Другой хороший метод, который позволяет построить приоритеты на шкале — Value & Effort (или Lean Prioritization).
Шаг. Сначала вы берете 2 шкалы:
-
Значимость фичи
Значимость каждой фичи с точки зрения бизнеса — это примерно то же, что и «ценность для бизнеса» в обычном бэклоге. Величина оценивается в условных единицах, лучше всего — в деньгах. В целом, любой параметр, который вы оптимизируете, можно брать за Value. Это может быть количество пользователей, которых вы привлечете в проект, или уменьшение оттока пользователей в проекте.
-
Количество усилий, которое необходимо затратить на каждую из фич
Тоже можно считать, что это оценка в часах (estimate), как в бэкглоге. Но можно измерять и в Story Point-ах (сравнительная оценка требований относительно друг друга) или в человеко-часах.
Шаг. Вы оцениваете все фичи по этим двум параметрам: по значимости и трудоемкости. Есть внешние системы (вроде Hygger или Airfocus Priorities&Roadmaps), который позволяет в автоматическом режиме раскидать каким-то образом ваши фичи на такой вот доске. Оси при этом идут не от нуля — они подстраиваются под статистические данные, которые у вас получились.
Какие фичи забирать в первую очередь? Самые значимые и лёгкие, которые ближе всего к осям — они и по значимости в топе, и по стоимости адекватные.
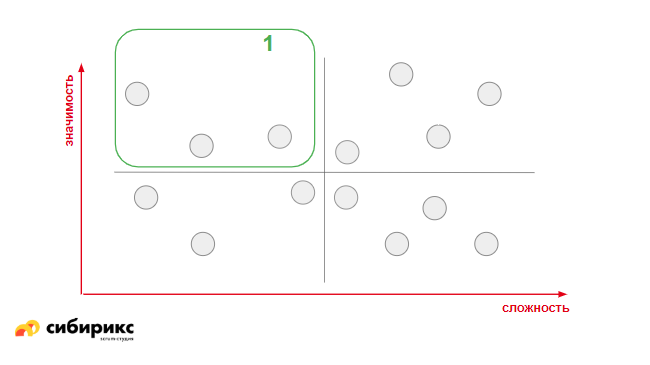
Если в первую очередь мы забираем дешевые и хорошие, то потом — дорогие, но крутые:
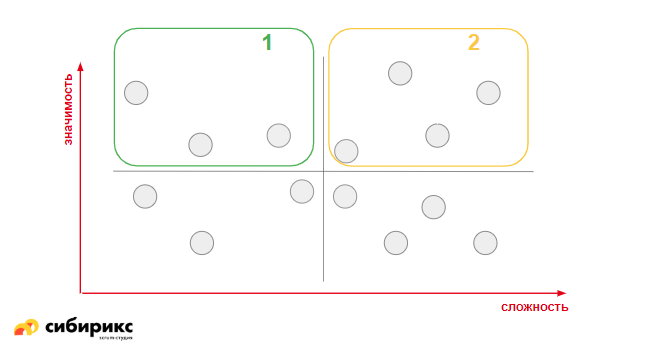
Следом — все остальные. Фичи, которые слишком дороги и не имеют никакого смысла, вы либо оставляете «на потом», либо выбрасываете.
Где и как применять
При заказной разработке такую штуку имеет смысл проделывать с клиентом, если:
-
он сам запутался,
-
он генерирует странные идеи и требования,
-
у него есть определенное ограничение по бюджету, и он не понимает, как лучше его распределить.
Последняя ситуация — частая. Мы всегда ограничены либо бюджетами, либо ресурсами, и нужно понимать, на основе чего их распределять. Более того, управляя проектами, мы можем управлять только вниманием нашей команды и нашего заказчика — большим ничем, по сути. Этот метод позволяет концентрироваться на самом важном и самом дешевом либо на дорогом, но очень важном, и помогает выбрать, на что именно сделать ставку в данный момент.
Эта методика не заставляет вас слепо верить алгоритму и брать именно рекомендованные им задачи, но благодаря ей у вас хотя бы будет подсказка, в каком направлении двигаться. Если в систему добавить новых задач, она может перестроиться. Ведь бывает, что вы сильно не уверены в своих оценках, и с течением времени аналитики их уточняют, либо вы сами уточняете оценки трудоемкости у программистов — в этом случае система также может перестраиваться в динамике. За счёт этого у вас будет более адекватная и картина мира.
MoSCoW
Еще один способ категоризации фич по нескольким группам — метод MoSCoW. Внутри — очень простые параметры:
|
M — Must Have |
Функционал, без которого вообще нельзя обойтись. Без него вы не сможете выпуститься, ваш продукт не заработает и вообще не будет нужен. |
|
S — Should Have |
Функционал, который должен быть в проекте, но при прочих равных без него как-то можно обойтись. |
|
C — Could Have |
Функционал, желательный для релиза. |
|
W — Would Have |
Наименее практичный функционал — так скажем, «всё остальное». |
Пример
Допустим, вы разрабатываете автомобиль. Must Have будут колеса, руль, ходовая часть, двигатель. Should Have — освещение ночью, сидения вместо стульев, двери и всё такое прочее. Could Have — автоматическая коробка передач и так далее. Таким же образом можно разобрать любой проект, где Must Have будет эдаким MVP.
Часто бывает, что приоритеты спускают сверху, от бизнеса, и они сконцентрированы на каких-то «хотелках» из Should Have, Could Have, Would Have, забивая на ключевые вещи (Must Have). Обычно мы это наблюдаем, например, на разработке дизайна интернет-магазина или дизайна какого-то проекта, где на систему оплаты доставки или чего-то, что на самом деле генерирует выгоду бизнесу, ставка делается в последнюю очередь. Почему? Потому что работать с Must Have больно и страшно: надо думать о том, как это будет монетизироваться, а в это никто не любит лезть, хотя это и неправильно.
Kano
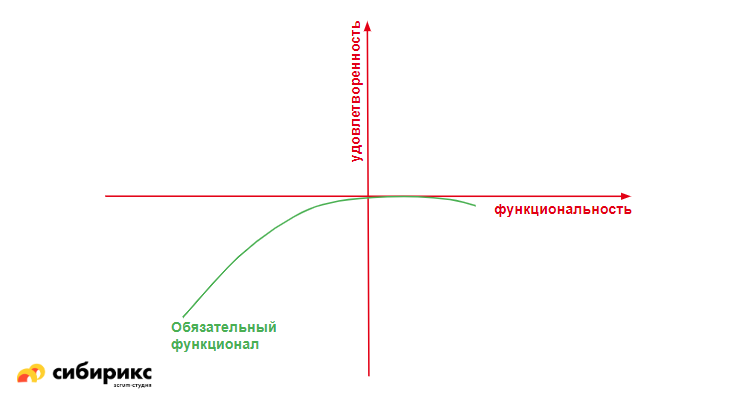
Ещё один способ категоризации фичей, пришедший из маркетинга. Суть простая: есть две оси: «удовлетворенность пользователей» и «функциональность», и есть деление функционала на группы. Для каждой группы фич нужно понять, как меняется удовлетворенность пользователя от добавления этого функционала.
Первая группа — обязательный функционал: тот же Must Have из MoSCoW. Если эти фичи есть — уже хорошо. Об удовлетворенности речи не идёт: без них продукт никому не нужен. Более того, с течением времени функции, которые сначала были «изюминкой» проекта, становятся всё более обязательными. Пример: для серверного ПО канбан-доска когда-то была чем-то эдаким, а сейчас это тот самый мастхэв.
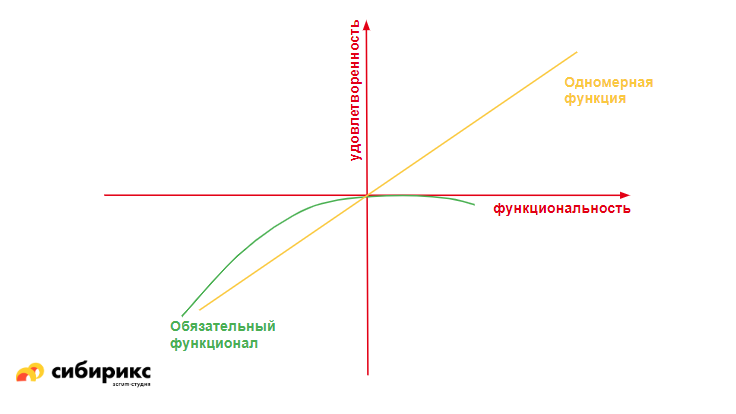
Другая группа — одномерные функции. Это значит, что есть прямая зависимость удовлетворенности пользователя от наличия этой функции. Как только функция появляется, удовлетворенность растет линейно. Если вернуться к примеру с созданием автомобиля, там это может быть климат-контроль.
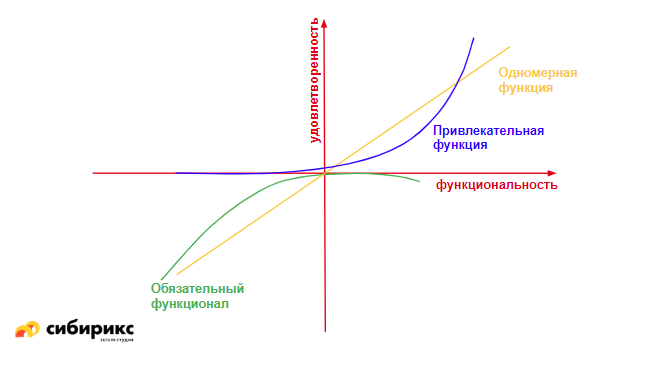
Третья группа — функции, которые привлекательны. Это то, чего пользователь не ожидал, но когда он увидел хоть какую-то реализацию этого в вашем продукте, он офигел и сказал «о, круто!». Кто летал аэрофлотом, наверняка видел, как детям раздают «взятки», чтобы эмоционально привязать их к бренду.

Как только такая функция появляется даже в посредственной реализации, удовлетворенность растет. А чем круче реализация, тем выше стремится график удовлетворенности.
Ещё одна группа — неважные функции. Их можно делать, можно не делать — всем будет безразлично.
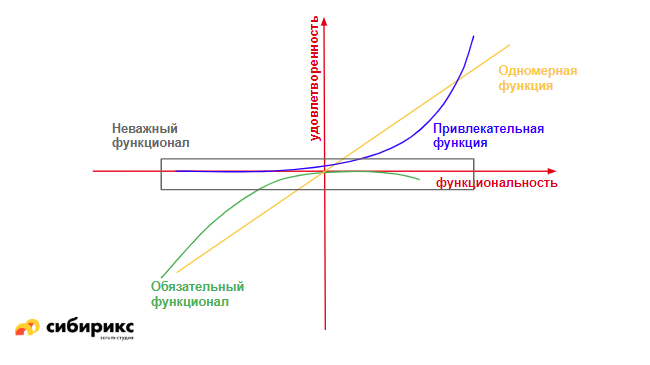
Последняя группа — нежелательные функции. Когда их нет — все хорошо, как только они появляются — все становится плохо. Эдакие антифичи :)
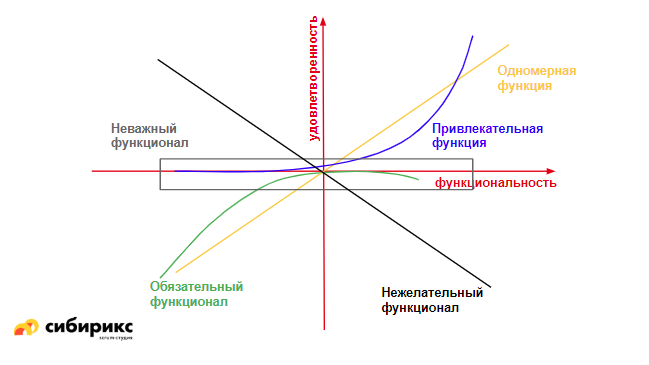
Этот метод несколько сомнителен, поскольку непонятно, каким образом выбираются приоритеты у фич. По идее, нужно опрашивать пользователей: как они считают, хороша эта фича или не очень, а потом кластеризовать на основе мнения пользователей. При этом, еще и самих пользователей нужно разбивать на целевые группы и смотреть, как каждая функция к какой целевой группе относится.
Люди при опросах часто говорят ерунду и попросту врут. Они могут говорить, что это очень важная фича, но по факту они никогда не заплатят за неё деньги. Более того, если опрашивать пользователей, обратная связь по продукту может быть очень токсичной.
Пример
Вы планируете делать следующие релизы и опрашиваете группу людей. Кто-то из них может сказать: «А вот вы там платную функцию сделали, из-за неё продукт стал хуже, фи!» Только потому, что она за деньги, эта функция покажется кому-то ненужной. Хотя для бизнеса это может быть ключевая вещь, которая приносит прибыль.
Поэтому метод Kano — абсолютно из маркетинга, но как долгосрочная стратегия имеет место быть.
Классический метод приоритизации баг-листов
В основе — список приоритетов от 0 до 8:
0 — Критические баги
Когда тестер уткнулся и не может дальше проверять, когда система падает либо что-то ломается — в общем, когда дальше невозможно.
1 — Критичное юзабилити и забытые фичи
Здесь мы применяем в том числе метод покраски бэклога, технического задания, либо прототипа (в зависимости от того, что у нас есть на руках), чтобы определить, не пропустили ли мы что-то.
2 — Некритичные баги
Баги есть, но они не мешают тестировать продукт дальше, либо они позволяют пройти полностью по цепочке либо заказа, либо чего то еще — то есть, дают полностью проверить наш продукт.
3 — Некритичное юзабилити
4 — Тексты
8 — Хотелки / не будем делать / на усмотрение менеджера
Да, промежуток между 4 и 8 сделан намеренно — менеджер при необходимости может докидать туда ещё какие-то задачи.
Для баг-листов способ хороший, но у него есть проблема. По большому счету мы в баг-листах оптимизируем метрику «готово — не готово». Объем работ понятен. Но часто встречается, что в некритичное юзабилити пытаются пропихнуть что-то такое, что находится на грани — вроде бы, юзабилити и вроде бы неплохо такое сделать, но по факту оно тянет на какую-то очень серьезную фичу.
Другая проблема — субъективизм тестировщика, который часто приходится перепроверять. Иногда это довольно трудоемкая история, когда вы лично просматриваете все баг-листы: смотрите, чего он там такого понаписал, и принимаете решение, что выкинуть, а что оставить.
Для приоритизации бэклогов такой метод не годится — для них нужны совсем другие критерии.
Оценка задач
Любая приоритизации должна отталкиваться от тех оценок, которые нам дали.
Ведь трудоемкость действительно влияет на приоритетность какой-то функции. Но как определить трудоёмкость и в какой момент стоит обсуждать трудозатраты с программистом? Ведь до этого менеджеру всё равно нужно выставить хотя бы примерные оценки.

А если серьезно, обычно есть три варианта.
Игра престолов
Приходит какой-то «верховный босс» и говорит, что из бэклога должно быть сделано прямо сейчас, и спускает вам оценки сверху. Это может быть технический директор, который расставляет оценки всех задач и говорит, что какая-то задача делается за столько-то, такая-то за столько-то. Или это можете быть вы сами :)
Такое часто встречается (хотя сами мы так стараемся не делать). Обычно по ходу декомпозиции какие-то вещи уточняются, появляются какие-то детали и нюансы. Часто с этими оценками могут быть не согласны разработчики или реальность может быть немножко сложнее, чем вы себе запланировали. Плюс у бизнеса всегда есть подсознательное понимание, за какое количество часов он готов купить эту фичу, а за какое уже не готов (и это всегда где-то на грани).
Оценка из теории вероятности
Берутся три оценки по времени: оптимистичная, пессимистичная и реалистичная, и строится график, называемый Гауссианой.
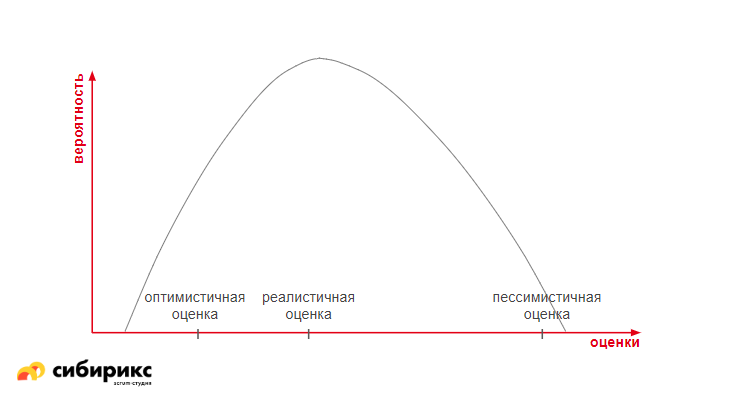
Для расчета наиболее вероятной оценки применяют формулу: (Оптимистичная + (Реалистичная * 3) + Пессимистичная) / 6.
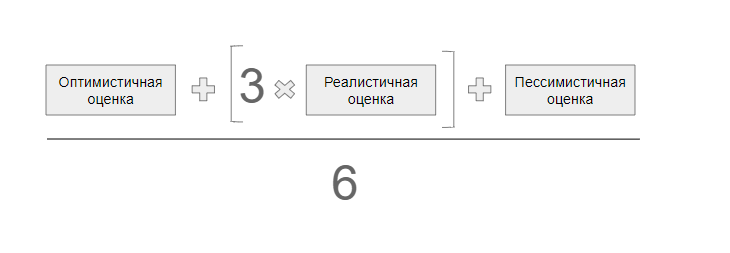
В идеале наиболее вероятная оценка будет чуть дальше, чем реалистичная.
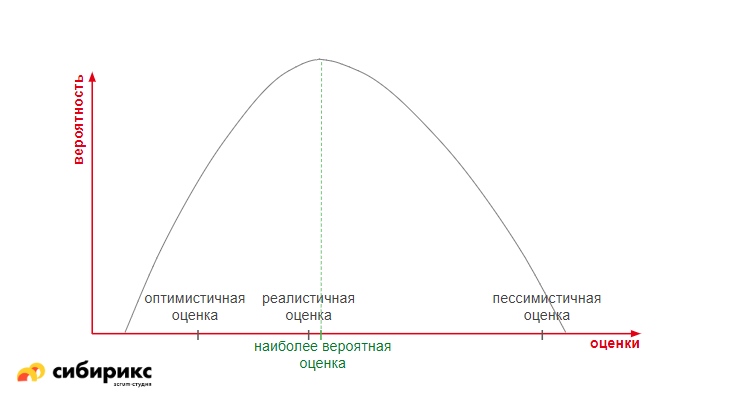
Нюанс в том, что не доказано, что в результате у нас получится нормальное распределение. Например, если взять группу людей и измерить их рост, то получится кривая, как на графике ниже: очень маленьких людей мало, очень высоких людей — тоже мало. И они не входят в норму. Остальные в выделенном диапазоне — и есть нормальное распределение.
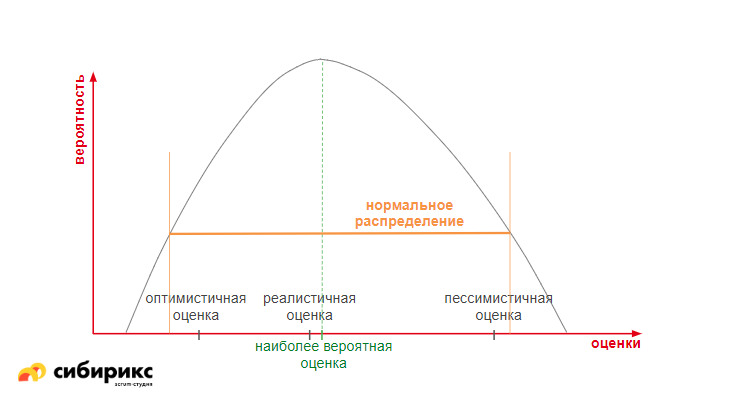
Гауссиана подразумевает, что варианты, когда задача выйдет за отметку пессимистичной оценки или вообще никогда не будет сделана, стремительно уменьшаются. Но в ИТ-среде часто бывают задачи, которые, на первый взгляд, сделать «невозможно» — программисты для них требуют поменять постановку либо продолжают доказывать эту невозможность. Другая ситуация — человек оценил задачу в 1 час, потратил всё мыслимое и немыслимое время и пришёл к выводу, что не может сделать эту задачу.
Поэтому опираться на этот метод можно, но по факту это та же «игра престолов», да и сложновато по каждой задаче давать три оценки плюс считать по формуле. И нет никакой гарантии, что в итоге всё не выйдет за рамки этих оценок и расчётов.
Planning Poker
Это наиболее простой и «чистенький» способ получить нормальные оценки, обсудить какие-то фичи, нюансы, детали. Даже на верхнем уровне по бэклогу можно такое проделать.
Минус Planning Poker — это довольно ресурсоемкая операция, поскольку нужно собирать всю команду вместе и читать бэклог. Но если вы применяете методы вроде Story Mapping, вам всё равно нужно собираться командой и делать предварительные оценки (хотя бы в днях, неделях — крупных величинах).
Плюсы Planning Poker
-
оценки распределяются в зависимости от опыта сотрудника, и здесь можно договориться;
-
оценки даются сначала закрыто, и только потом открываются — нет давления авторитета (как в случае с оценками, спущенными «сверху»).
Техники скоринга
Помогают с определением приоритетов задач в бэклоге в условиях неопредленности — когда вы только планируете и оцениваете эффект от внедрения той или иной функции.
ICE Scoring
Аббревиатура состоит из трех параметров:
-
Impact — влияние на продукт либо с точки зрения бизнеса, либо сколько денег принесет, либо что эта фича даст, насколько она крутая. Параметр задается в диапазоне от 1 до 10.
-
Confidence — уверенность в оценке сложности или в оценке влияния фичи. Например, вы придумали какую-то функцию и думаете, что она хорошо повлияет на проект. Аналитики не было, данные неточные и пока приоритет основывается только на вашем личном мнении. Чем ниже уверенность в вашем личном мнении, тем ниже показатель. Задается также в диапазоне от 1 до 10.
-
Ease — трудозатраты или простота реализации. Также задается от 1 до 10. Чем проще функция, тем у нее выше балл.
Влияние
Чтобы оценить влияние, стоит учесть несколько критериев:Если функция им отвечает, то у неё высокое влияние на продукт. Для оценки можно брать шкалу от 1 до 10, можно от 1 до 100. Последняя удобнее, поскольку есть разбег.
- улучшает конверсии,
- привлекает новых пользователей,
- удерживает существующих пользователей,
- добавляет ценности продукту.
Уверенность
Может основываться на:Лучше использовать те, где есть конкретные метрики и цифры, мнение людей оставлять на «потом».
- личном мнении, мнении команды, мнении сторонних экспертов;
- UX-исследованиях;
- опросах;
- интервью;
- наблюдениях, в том числе — за конкурентами;
- MVP;
- A/B-тестах;
- сторонних исследованиях;
- аналитике;
- топовых обращений в техподдержку;
- топовых запросах от сейлз-менеджеров;
- топовых запросах клиентов.
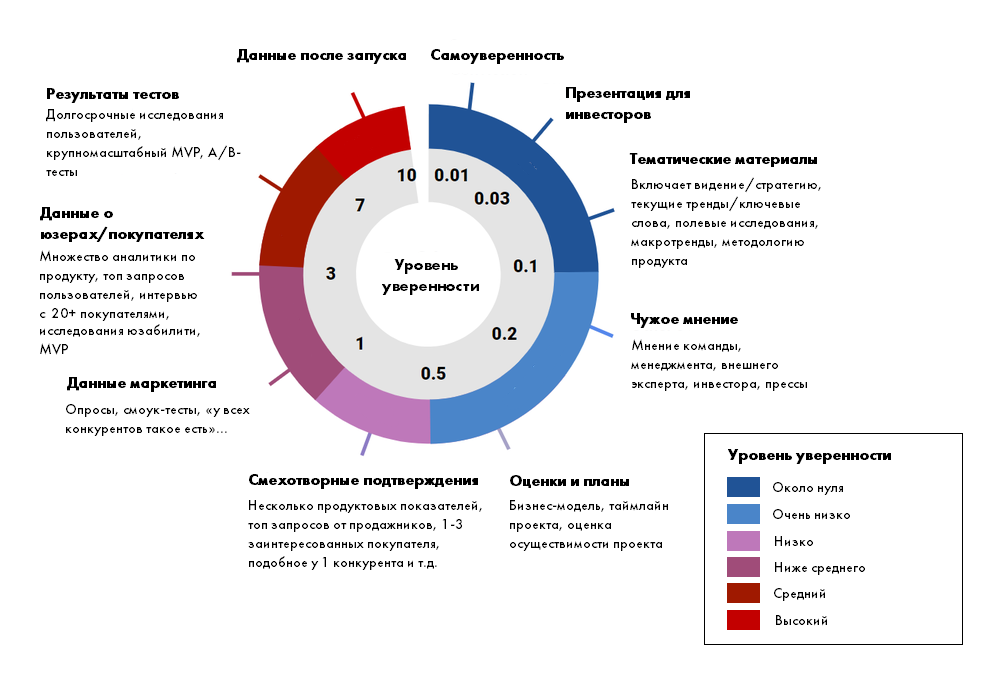
Для получения ICE нужно умножить эти три параметра — это и будет приоритет на реализацию.
Плюсы: быстро и просто.
Минусы: у метода довольно ограниченная шкала — можно получить много задач высокого приоритета, потому что по ним будут понятны и постановки, сами задачи будут простые и будут казаться важными.
RICE Scoring
Здесь используется 4 параметра:
-
Reach — охват: сколько пользователей у нас от этой фичи получат хоть какое-то удовлетворение, либо заметят эту фичу, либо будут ей пользоваться. Можно измерять количественно: например, 500 миллионов пользователей ощутят на себе эту функцию. Можно измерять в процентном отношении — например, 30% пользователей будет использовать эту фичу.
-
Impact — влияние: насколько эта функция на самом деле нам нужна, насколько она нам поможет, насколько функция крутая.
-
Confidence — уверенность: аналогично с ICE Scoring, уверенность в наших оценках и прогнозе влияния.
-
Effort — трудоемкость.
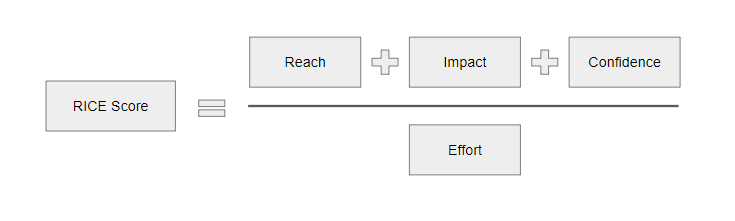
Функции, которые дают большой охват, в которых мы уверены и которые хорошо влияют на продукт и при этом дешевые по трудозатратам, находятся в топе по приоритетности в бэклоге.
Софт для приоритизации
Есть несколько программ для автоматической приоритизации — например, Hygger. Это система для Product Owner-ов, где есть много разных моделей, которые позволяют «поиграться» задачами.
То же самое проделать в любом гуглдоке: просто добавить три параметра, собрать данные — он посчитает. Это и будут ваши приоритеты. А дальше вы уже сами выбираете, что именно брать в спринт.
Иногда менеджеры для хранения всех тикетов и задач используют Jira. К сожалению, она не очень удобна для приоритизации — заточена на то, что кто-то расставляет приоритеты вручную, просто перетаскивая тикеты вверх-вниз по бэклогу. Это прикольно, если бэклог не на 1000 строк, но в какой-то момент вам станет утомительно делать это руками.
В Jira есть определенные способы классификации задач на эпики, компоненты, релизы, можно какими-то тегами задачи размечать. Есть несколько плагинов для скоринга (Issue Score for Jira, Priority Scoring Calculator), но по функциональности они не очень.
Из более-менее адекватных — внешние системы Hygger и Airfocus. Они интегрируются с Jira, но и стоят примерно столько же, сколько она сама. Поэтому самый простой способ — сделать интеграцию гуглдоков и Jira: выгружать туда бэклоги синхронно и уже там применять свои формулы, как вам нужно.
Как именно — показываем в видео:
Кроме приоритетов всегда есть проблема, как распределить по времени реализацию тех или иных задач. Когда есть только приоритеты, нет гарантии, что мы получим связанную систему (например, вы запланировали сделать корзину, а оказалось, что каталога еще нет). Поэтому помимо приоритетов также стоит использовать диаграммы Гантта, чтобы чтобы посмотреть связи в системе, насколько она корректно работает по компонентам и насколько оптимально вы распределяете ресурсы команды по времени.
В Jira, к сожалению, из «коробки» эта опция не очень хорошо реализована, поэтому тоже могут пригодиться несколько плагинов:
Как итог
Мы не избавляемся от субъективности — она остается на всех уровнях. В тот момент, когда мы говорим «это важная функция» или «это неважная функция» и когда мы даем какие-то оценки, субъективность сохраняется. Но благодаря перечисленным методам мы можем разбить эту субъективность на компоненты: по крайней мере, картинка будет более ясная.
Если вы используете такой параметр как «уверенность в оценке», вы можете с течением времени эту уверенность «докрутить». Например, у вас есть хорошая функция, которая и влияет на продукт позитивно, и дешевая, и охват дает большой, но уверенность в ней низкая. Проверьте её через метрики, аналитику, запрос экспертов, вопросы программистам — и уточните.
Для оценок хорош Planning Poker, плюс мы посмотрели несколько методик для категоризации задач. Если у вас идёт стратегическая сессия с клиентом, попробуйте Story Mapping со стикерами и распределением их по шагам пользователя. На внутренних продуктах тот же метод поможет выбрать функции, которые стоит взять в следующие релизы. Для бэклогов лучше остальных подходит RICE Scoring, чтобы оценить, какие задачи куда пойдут.
Но помните, что конечное решение — всегда за менеджером, а полученные с помощью методов циферки только задают направление.
До встречи в новых видео на нашем YouTube-канале!
Оригинал: https://blog.sibirix.ru/2020/04/15/scoring-and-priority/
Полный текст статьи читайте на CMS Magazine
