
Разработчики OrioleDB предложили улучшить API для альтернативных движков PostgreSQL
Разработчики OrioleDB проанализировали текущее состояние низкоуровневого API, применяемого для доступа расширений к таблицам и индексам в PostgreSQL (Table/Index Access Method (AM) API), и предложили пути его улучшения. С момента появления в PostgreSQL 12 подобного API разработчики получили возможность создавать альтернативные механизмы хранения данных. Однако, несмотря на наличие этого API и известные ограничения встроенного механизма хранения, до сих пор не появилось полнофункциональных транзакционных движков хранения, реализованных исключительно в виде расширений.
Наиболее востребованными функциями для альтернативных табличных движков PostgreSQL являются:
- Альтернативные реализации MVCC, например, хранилища на основе журнала UNDO.
Индексно-организованные таблицы, где индекс не является необязательным дополнением к таблице, которое ускоряет запросы, а представляет собой основную структуру данных, в которой хранятся данные таблицы.
Изменения, необходимые в API Table/Index AM для поддержки альтернативных реализаций MVCC, рассматриваются с оглядкой на расширение OrioleDB, разработанное для устранения известных недостатков встроенного механизма хранения PostgreSQL. Проблема в том, что для полной интеграции OrioleDB с PostgreSQL требуются внесение изменений в код PostgreSQL, что усложняет внедрение проекта и подчёркивает необходимость модернизации текущего API Table AM.
API Table AM не навязывает напрямую способ реализации MVCC. Тем не менее, API Table AM и API Index AM делают следующее предположение: каждый TID (Tuple/row Identifier) либо индексируется всеми индексами, либо не индексируется вообще. Даже если Index AM имеет несколько ссылок на один TID (например, GIN), все эти ссылки должны соответствовать одному и тому же индексированному значению.
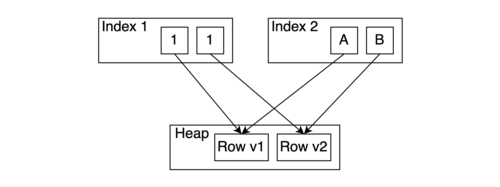
Этот принцип критиковали за увеличение числа операций записи («write amplification») — если обновляется один индексированный атрибут, необходимо обновить каждый индекс в таблице. При необходимости в полной мере использовать преимущества журнала UNDO или построить другой метод хранения без «усиления записи» (например, метод WARM), требуется нарушить это предположение.
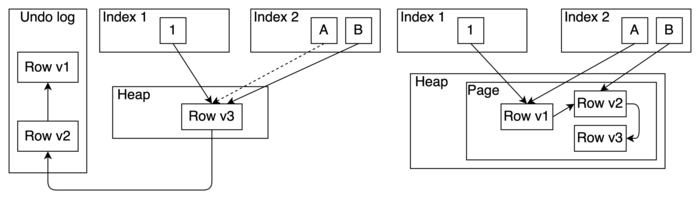
Table AM основанный на UNDO, который не будет нарушать это предположение, напоминает существующий метод HOT (Heap-Only Tuples), за исключением того, что старые версии строк сохраняются в журнале UNDO и не должны умещаться в той же странице. Но, по мнению авторов, этого преимущества недостаточно, чтобы оправдать существование отдельного Table AM.
Практические ограничения существующего API:
- Во время обновления строки таблицы индексы обновляются по принципу «все или ничего».
Отсутствие в API Index AM возможности точечного удаления определённых кортежей. В настоящее время можно удалять кортежи из индексов массово с помощью методов ambulkdelete и amvacuumcleanup. Попытка реализовать точечное удаление через этот API привела бы к низкой эффективности, поскольку большинство текущих реализаций должны сканировать весь индекс. Кроме того, API не позволяет указать какие из кортежей, ссылающиеся на один и тот же TID, следует удалить. Он может удалить только их все.
Индексы в настоящее время ссылаются на строки таблицы по номеру блока (32 бита) и номеру смещения (16 бит). И только 11 бит номера смещения можно безопасно передать из TID таблицы во все методы доступа индекса. При этом альтернативным реализациям MVCC может потребоваться хранить дополнительную полезную нагрузку (payload) вместе с TID. Например, в OrioleDB требуется один или несколько бит для реализации индексов «delete-marking» или полной информации о видимости.
Предложено два способа преодолеть ограничения на практике:
Подход 1: API Index AM предоставляет возможности для альтернативной реализации MVCC.
В то время как Table AM продолжает отвечать за все компоненты MVCC, Index AM предоставляет необходимые возможности для альтернативной реализации MVCC, а именно: хранение пользовательской полезной нагрузки (payload) вместе с TID, метод точечного удаления и даже метод точечного обновления (если TID в индексе не может быть изменён, пользовательская полезная нагрузка — может). Кроме этого, так как необходимо разрешить нескольким кортежам индекса ссылаться на один и тот же TID, методы API, применяемые при сканировании индекса, также нуждаются в обновлении.
Подход 2: Индексы, поддерживающие MVCC.
Альтернативой было бы разрешить индексы, поддерживающие MVCC. То есть «executor» (или, возможно, Table AM) просто вызывает методы insert () и delete () в Index AM, в то время как Index AM предоставляет возможность сканирования c учётом MVCC. Это значительно упростило бы сканирование с использованием только индексов (index-only). Даже весь Table AM в таком случае мог бы стать промежуточным слоем, хранящим данные в индексе.
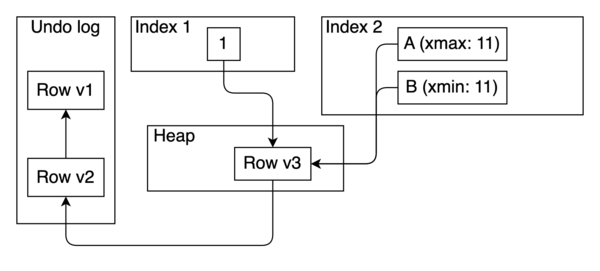
На диаграмме ниже приведён пример. Значение индекса 2 обновляется транзакцией 11 со значения «A» на значение «B». Поэтому значение «A» отмечено как xmax == 11, а значение «B» отмечено как xmin == 11. Таким образом можно сканировать индекс 2 и получать только видимые кортежи в соответствии с MVCC без проверок кучи (heap). Сборка мусора индекса 2 также может быть выполнена без использования кучи.
При внедрении всех перечисленных новшеств в API индексных методов доступа, маловероятно, чтобы удалось одновременно доработать все индексы для поддержки всех новых возможностей. Более реалистично разрешить несколько реализаций для одного индексного метода доступа. Например, в дополнение к обычному B-tree, расширение сможет реализовать альтернативный B-tree с поддержкой MVCC внутри индекса и поддержкой идентификаторов записи произвольной длины.
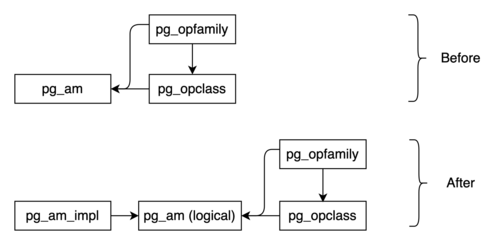
Таким образом, предлагается пересмотреть не только API Table AM, но и API Index AM, который исправно служил сообществу PostgreSQL на протяжении многих лет. Более того, предлагается разделить Index AM на логический слой и слой реализации. Эта переосмысленная архитектура позволит PostgreSQL поддерживать различные модели хранения.
Источник: http://www.opennet.ru/opennews/art.shtml? num=62991
Полный текст статьи читайте на OpenNet прочитано 50252 раза
