Заметки Датасатаниста: реляционные vs связанные данные

Сегодня мы поговорим о простой, казалось бы, теме, как реляционные и связанные данные.
Несмотря на всю ее простоту, замечаю, что иногда люди действительно путаются в них — я решил это исправить, написав краткое и неформальное объяснение, чем они являются и зачем нужны.
Мы обсудим, что такое реляционная модель и связанные с ней SQL и реляционная алгебра. Потом перейдем к примерам связанных данных из Викидата, а далее RDF, SPARQL и чутка поговорим про Datalog и логическое представление данных. В конце выводы — когда применять реляционную модель, а когда связно-логическую.
Основная цель заметки — это описать, когда что имеет смысл применять и почему. Так как тут немало непростых концепций сошлись в одном месте, то конечно же можно было бы по каждой написать книгу —, но наша задача сегодня дать представление о теме и мы будем разбирать неформально на простых примерах.
Если у вас есть сомнения, чем одно отличается от второго и зачем вообще нужны связанные данные (LinkedData), то добро пожаловать под кат.

Реляционные данные
Начнем со стандартного определения
Реляционная база данных — это набор данных с предопределенными связями между ними. Эти данные организованы в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных.
Когда применяются:
- Моделирование фиксированного домена
- Схема данных меняется либо мало, либо изменения касаются сразу существенной группы записей
- Основные запросы — фильтрация категорий по ключевым полям записей, агрегация, генерация отчетов и аналитики на основе статистических показателей, etc
В такой ситуации, единицей моделирования является таблица и связи между таблицами (как например внешние ключи). По сути — таблица это предикат с фиксированными атрибутами т.е. мы всегда знаем арность табличного предиката.
Приведем в качестве примера связей ограничений внешний ключ: ключ «p (_, X, _) → q (_, Y, _)», который задает ограничения в виде X \subset Y, где X — это атрибут отношения p, а Y атрибут отношения q.

Еще более важно, что по сути в мире реляционных данных — у нас все таблица! И операции берут на вход таблицу и возвращают таблицу, например:

Язык реляционных данных: SQL и реляционная алгебра
Реляционная алгебра (алгебра Кодда) — это по сути набор операций над таблицами, которые возвращают таблицы. То есть, для вас центральным элементом моделирования являются именно фиксированные таблицы и их преобразования.
Язык SQL — это декларативная надстройка и конкретная имплементация идей реляционной алгебры.
Пример простого запроса и соответствующие ему реляционные операторы из алгебры.

Пока все, что мы рассмотрели это классические вещи, которые мы знаем из любого курса по базам данных.
Связанные данные (linked data) и графы знаний (knowledge graphs)
Просто представим, что будет, если у нас появляются новые свойства и это происходит, возможно, в режиме реального времени? То есть домен не фиксированный —, а гибкий и расширяемый?
В такой ситуации мы, конечно, можем добавлять таблицы и колонки в таблицы вгоняя NULL или дефолтные значения. Но помимо того, что это неудобно технически, это еще и неподходящий инструмент с точки зрения моделирования.
Представьте, что вы моделируете жизнь людей во всех ее возможных аспектах. Даже два разных человека у вас будут иметь достаточно разный набор ключевых свойств и это абсолютно нормально!
У вас нет фиксированного списка того, как будет описан конкретный персонаж Писатель и Футболист — это два Человека, которые имеет немало важных, но, тем не менее, разных свойств.
Начнем с писателя Дугласа Адамса — верхние свойства довольно типичны для любого человека — здесь и далее мы используем Wikidata в качестве примера LinkedData.
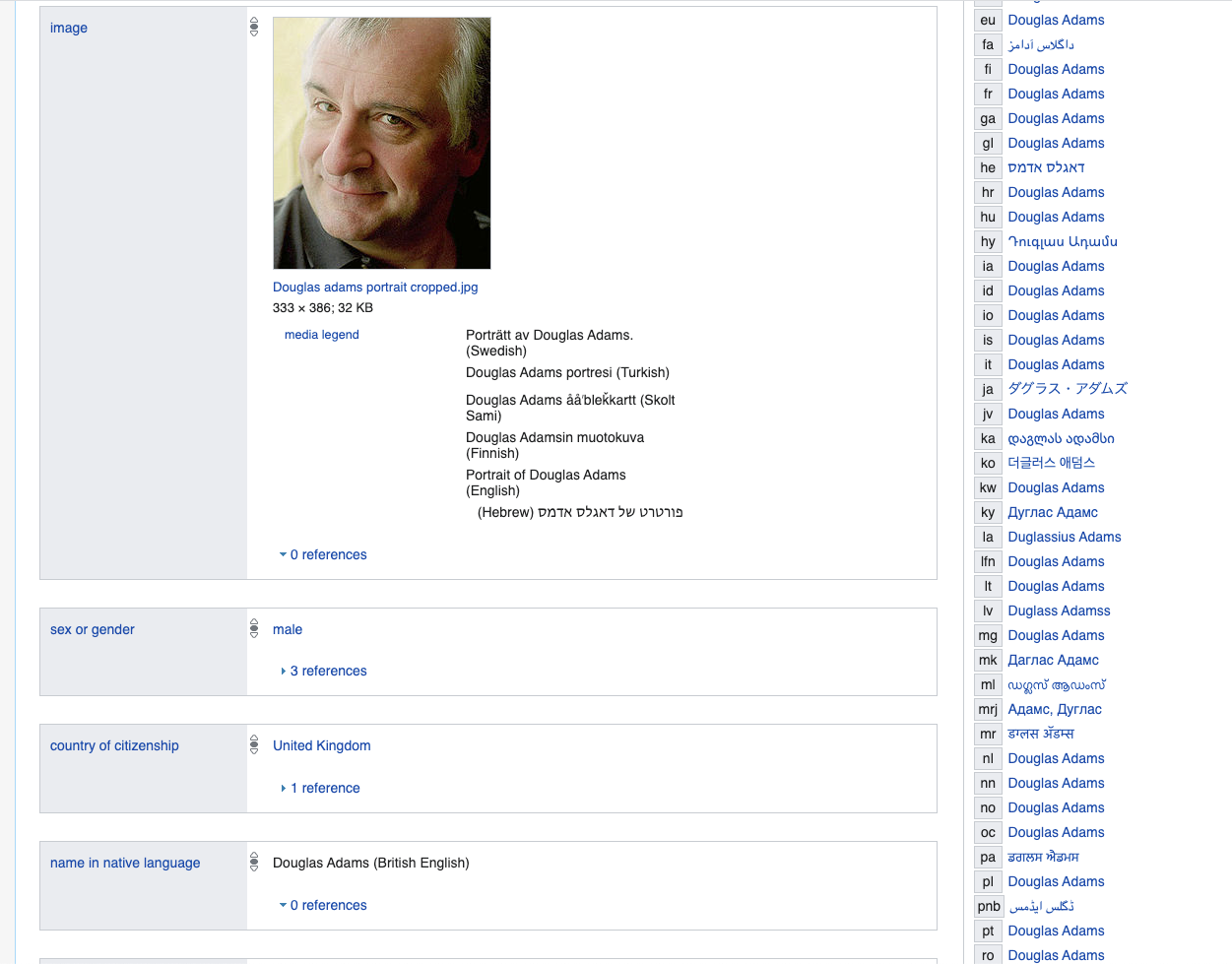
www.wikidata.org/wiki/Q42
Но копнем чуть глубже и
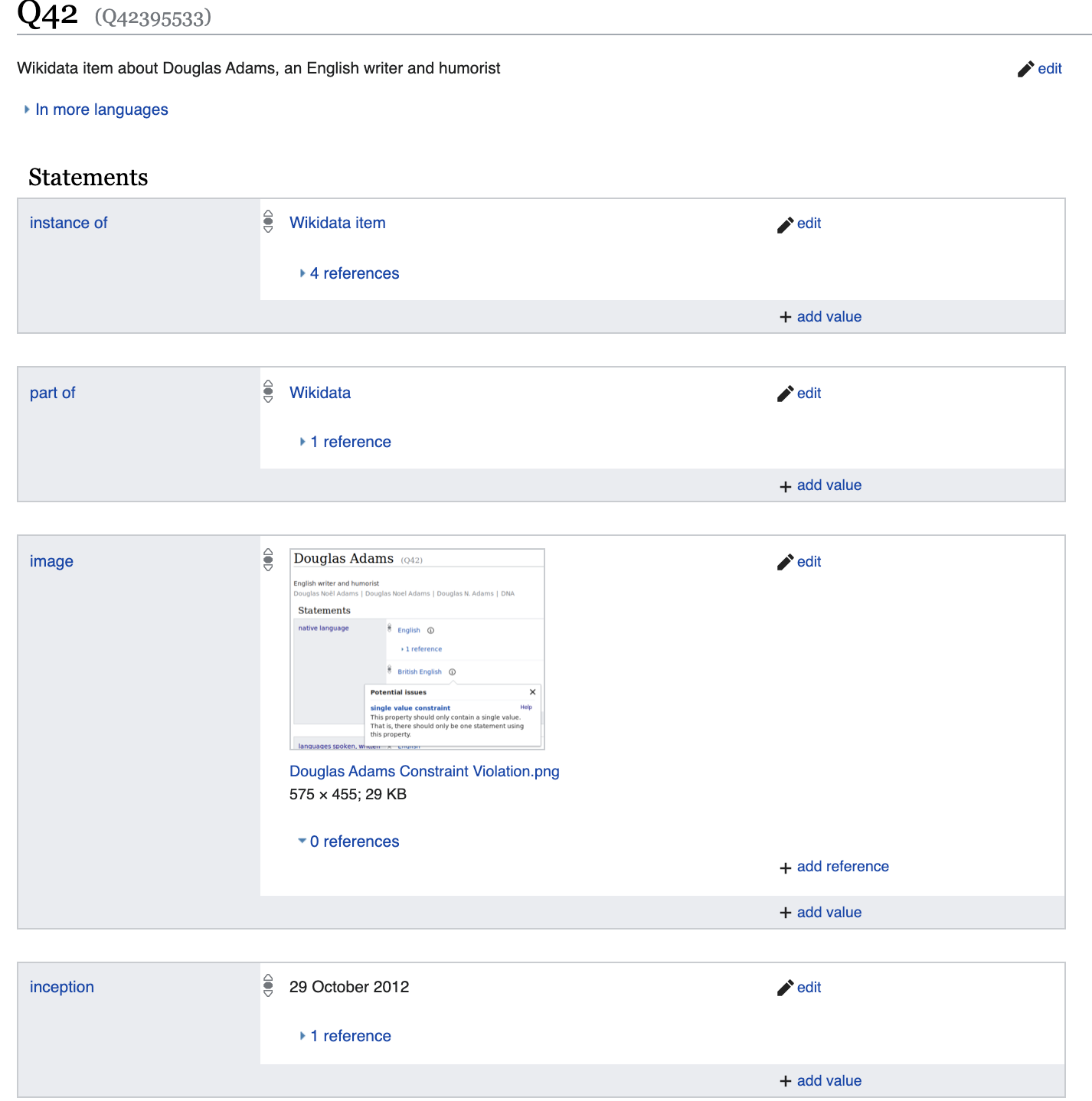
и видим набор свойств, который будет существенно отличаться от, например, Диего Марадонны
Поговорим чуть подробнее о свойствах указанных здесь. Например, свойство gender: male

По сути является отражением логического факта: p21(Q42, Q6581097).
Где p21 → это gender_identity/2 — бинарный предикат
Q42 → дуглас адамс
Q6581097 → male
Таким образом все данные представлены в виде либо унарных предикатов, например is_dead (Q42), либо в виде бинарных p21(Q42, Q6581097).
По сути это другая парадигма парадигма моделирования — логика первого порядка, но на унарных и бинарных предикатах.
И здесь очень просто добавлять новые данные: все, что не указано в виде предиката над объектами — это false, в литературе это известно, как Closed-world assumption.
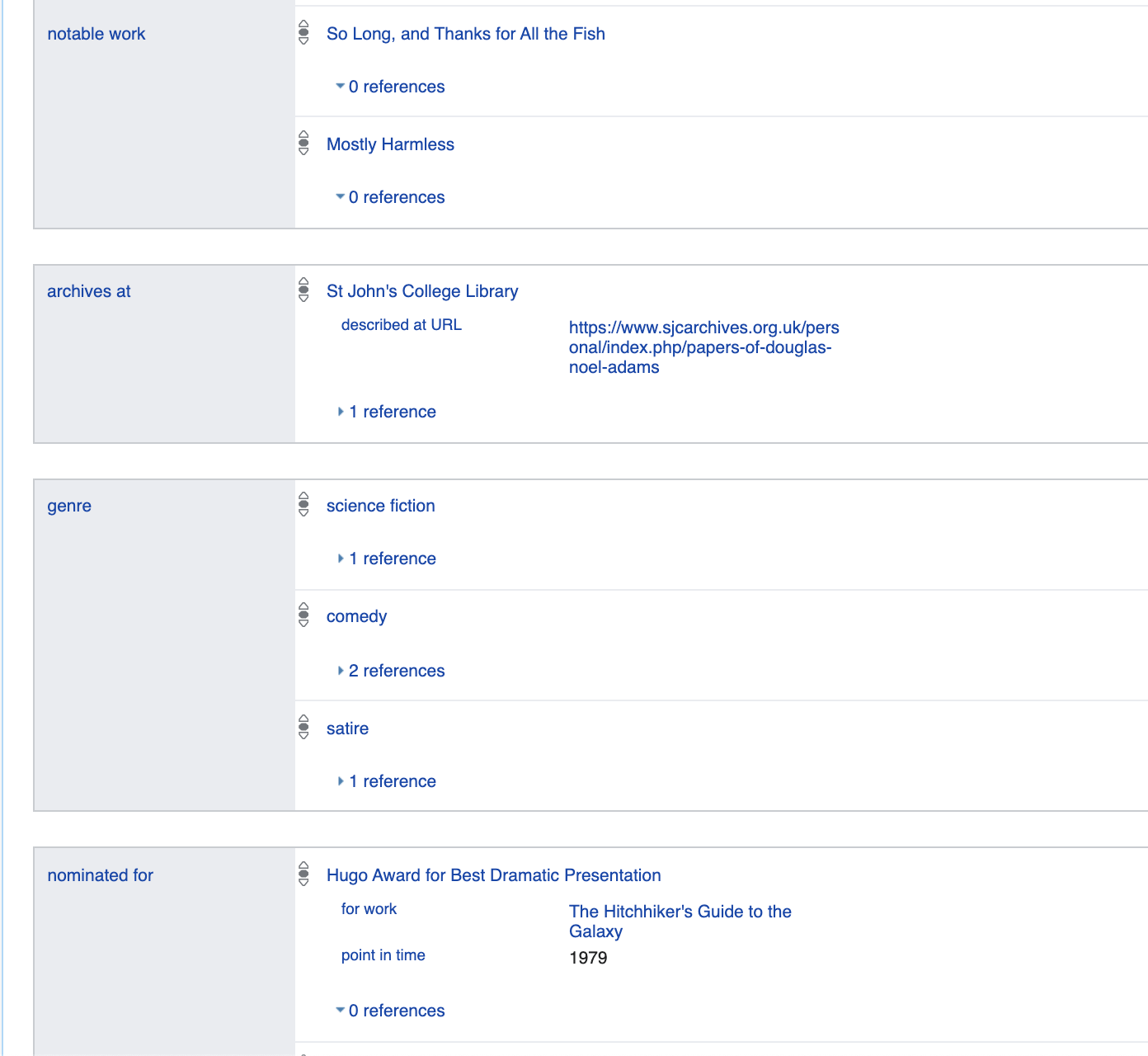
Более того данный формат допускает абсолютно естественное мета-моделирование
https://www.wikidata.org/wiki/Q42395533
Есть несколько основных хранения и написания запросов к таким данным — разберем популярные опции.
RDF и Язык запросов SPARQL
RDF — это формальный язык описания связанных данных для последующей обработки с помощью запросов, то есть это машиночитаемый формат.
По сути для него ключевые является понятие тройки:

И вот пример записи данных в данной моделе (префиксы определяют, где лежат «описания» данных предикатов)

Этот формат записи позволяет графически изображать данные об объектах — например, так можно записать информацию о городе Берлин.

Для формата RDF создали языка запросов SPARQL: который по сути описывает ограничения на логические предикаты и говорит, какую переменную из логического выражения надо извлечь:

Фактически мы хотим найти значение переменной ? country, такой что для предиката member_of верно, что member_of (? country, q458), а q458 — это ID европейского союза.
В настоящем коде это может выглядеть следующим образом:
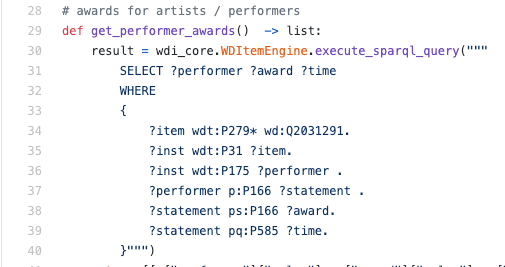
Итого: RDF — это формат представления данных в виде троек (бинарные предикаты) и SPARQL — это язык запросов к тройкам на основе логики.
Язык запросов Datalog и производные
Также для написания запросов к RDF (и не только к нему, об этом позже) можно использовать Datalog — декларативный (часто) язык, который синтаксически представляет собой подмножество Prolog (чаще всего).
В нем запросы имеют следующий вид:
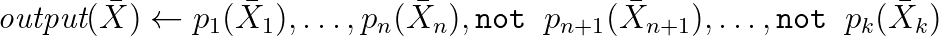
Часто синтаксис расширен с помощью агрегаций и других практически важных вещей. По сути, это правила вывода, взятые из логики, и с их помощью можно моделировать вывод новых свойств и писать запросы к RDF. Следующий реальный пример работающий с ВикиДата на основе одного из диалектов

Еще одно важное преимущество логических языков запросов на основе Datalog — для них RDF — это просто формат записи фактов (утверждений) бинарной логики. С таким же успехом они могут обрабатывать и любые другие логические утверждения — совершенно необязательно бинарные.
Выводы
Во-первых, реляционные данные хорошо подходят для моделирования фиксированных доменов, где схема либо меняется редко, либо изменения касаются не просто единичных записей, а целых сегментов.
Во-вторых, реляционные языки хорошо подходят для моделирования задач, где нужно извлекать подтаблицы, трансформировать и комбинировать имеющиеся — это не идеальный инструмент, когда существенная часть работы идет на уровне модификации и/или логического вывода над конкретной записью.
В-третьих, в случае если домен моделирования — это всеобъятная область, да еще и меняющаяся, где даже записи одного класса разительно отличаются хорошо подходят связные данные.
В-четвертых, стандартным представлением является RDF и его имеет смысл попробовать в первую очередь. Прикрутив к нему нужные базы и используя SPARQ-образные языки, можно извлекать нужные данные.
В-пятых, если моделирование тройками становится громоздким и неудобным, можно рассмотреть логическое представление данных и Datalog в качестве языка запросов.


