Зачем нам Reactive и как его готовить
Привет! Меня зовут Татьяна Руфанова. Сегодня мы будем понимать и принимать Reactive (Реактив). В статье расскажу, почему мы выбрали Реактив в мидл слое мобильного приложения Альфа-Банка (а у нас 300 микросервисов и треть из них реактивные), разберём, почему «нелогичное» поведение реактивной программы на самом деле очень логичное, какие сложности реактивный подход принесёт в процессе написания и исполнения кода, и как с этим бороться. А чтобы не траблшутить в проде, будем ломать тесты на Project Reactor.
Налейте чаю, включите звуки природы и настройтесь пройти все стадии принятия Reactive.
Немного о себе: работаю в Альфа-Банке уже 5 лет, участвую в продуктовой и внутренней разработке, 3 года мы с командой пишем реактивный код.
Почему мы используем Реактив в Альфа-Банке
Нагруженный микросервис до переписывания…
На картинке реальный мониторинг одного из нагруженных микросервисов Альфа-Банка в его «дореактивный» период. Приложение запущено в 8 инстансах, чтобы суммарно держать 750 запросов в секунду.
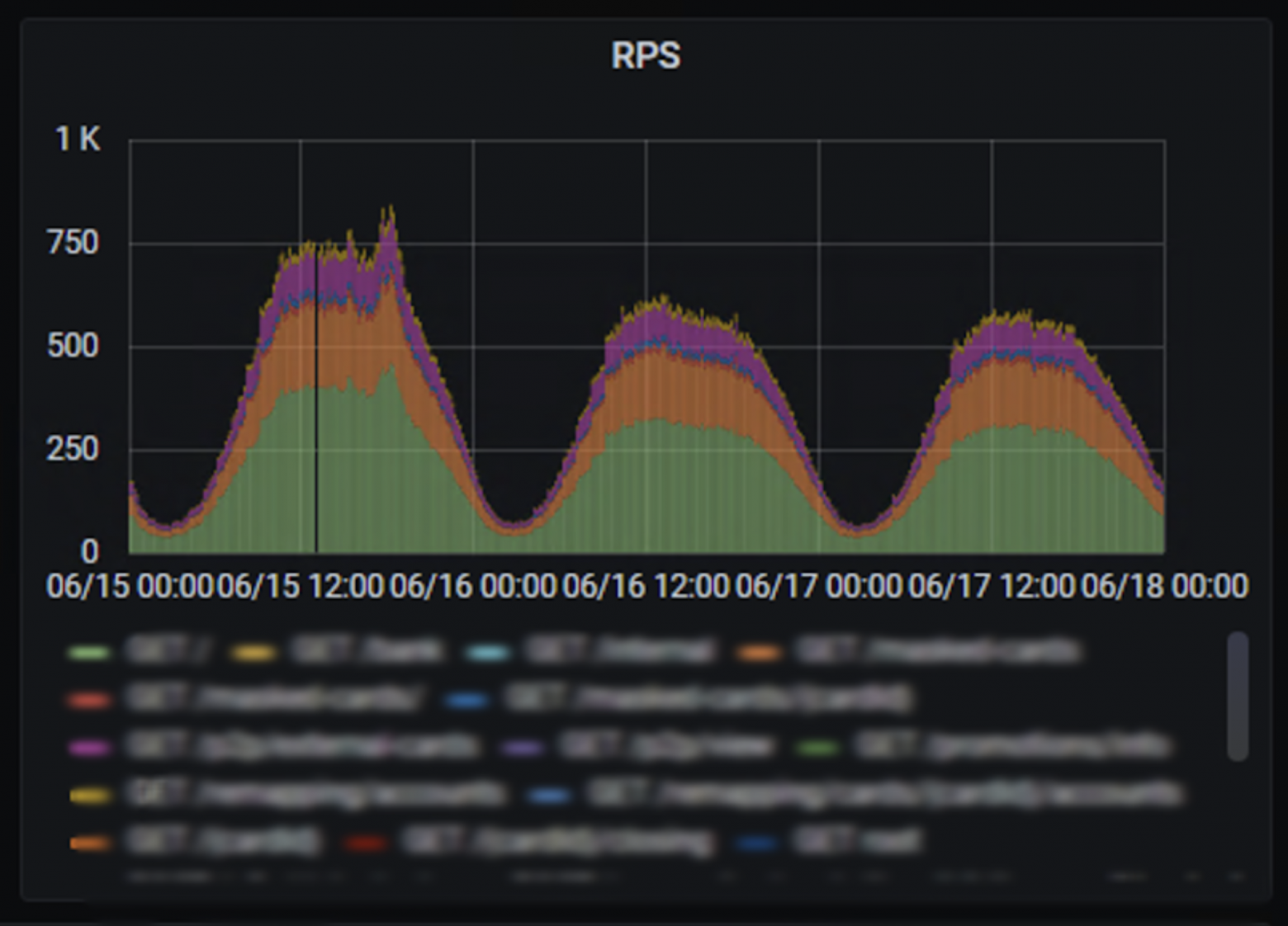
750 запросов в секунду
При этом на сервисах бэка, к которым обращается наш микросервис, могут происходить тайм-ауты, что сразу сказывается на времени ответа.
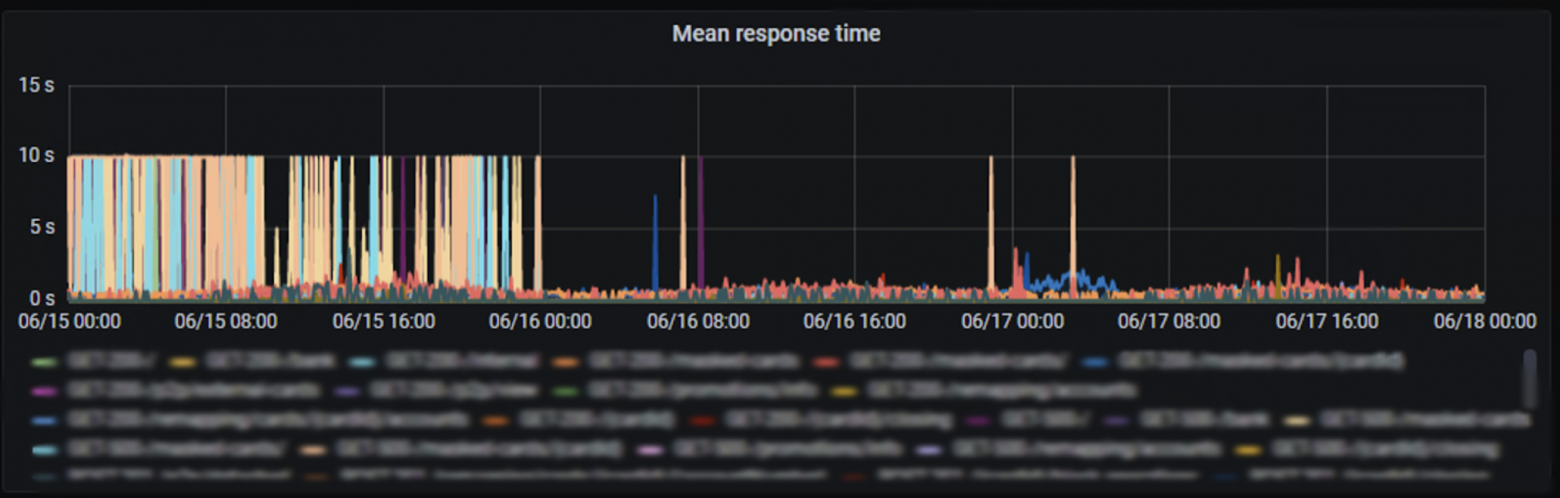
Таймауты в 10 секунд
Помимо времени ответа, таймауты бэкэнда влияют на «здоровье» микросервиса — он обрастает потоками, и в какой-то момент начинает перезапускаться.

Потоки упираются в потолок и сервис перезапускается
Почему так происходит?
У нас обычное приложение с бизнес-логикой: собери данные из нескольких сервисов, сходи в базу, кэш, соедини всё вместе и отдай наружу — никаких сложных вычислений. Зато много клиентских запросов, каждый из них порождает параллельные вызовы во внешние источники данных, а они, в свою очередь, могут долго отвечать.
Что делать, чтобы выдерживать пиковые нагрузки?
Увеличивать количество потоков в пулах севера Tomcat.
Увеличивать количество потоков в пулах внешних вызовов Hystrix.
Увеличивать память и ЦПУ самому приложению (потокам нужны ресурсы).
Увеличивать количество инстансов.
Или…
…переписать всё на Реактив! Ведь в нашем бизнес-приложении потоки большую часть времени заблокированы вводом/выводом и ждут, когда кто-нибудь пришлёт им данные по сети — потребляют ресурсы и ничего не делают!
…И после переписывания на Реактив
Мониторинги того же приложения, но уже в реактивном исполнении.
В 2,5 раза больше запросов в секунду (в пике почти 2000) на меньшее количество инстансов, всего 5.

2000 запросов в секунду
Таймауты внешних вызовов по-прежнему случаются.

Таймауты в 10 секунд
Но при этом количество потоков стабильно небольшое: 60 против 350.
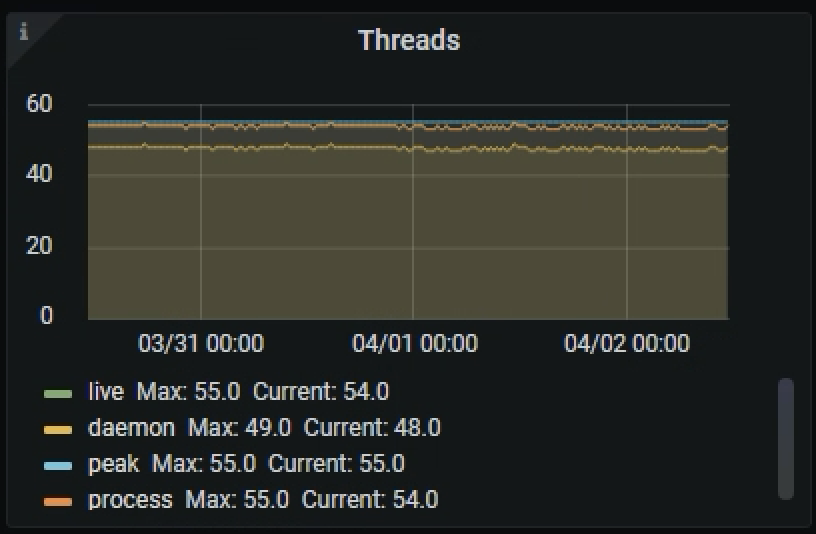
Менее 60 потоков
Почему так?
Потому что микросервис неблокирующий, теперь он на Webflux и Project Reactor, которые хорошо работают с IO. Точнее с NIO — неблокирующим вводом-выводом.
В отличие от Tomcat, где под каждый блокирующий вызов создаётся отдельный поток, в Webflux другая модель:
небольшое количество потоков бегает в цикле событий ввода вывода (event loop);
и как только для какого-то ранее приостановленного реактивного стрима приходит событие о том, что ввод или вывод окончен (то есть мы дождались или отправили данные)…
…поток продолжает выполнять логику этого стрима.
Получается, что в нашем приложении для одного клиента выполняем бизнес-логику, пока для другого ждём ответа извне. И всё это в одном и том же потоке.
Ещё раз подчеркну, что в нашем случае отсутствуют CPU Intensive задачи.
Если бы они были, у потока бы не было «свободного времени», он бы всё время занимался вычислениями. И для обработки большого количества входящих запросов, по-прежнему, потребовалось бы много параллельных потоков.
Не только теория, но и наш опыт промышленной эксплуатации показывает, что реактивные микросервисы держат нагрузки значительно лучше.
Из наших 300 микросервисов больше трети уже реактивные и мы не собираемся останавливаться! А чтобы упростить разработку и сопровождение такой большой кодовой базы, мы пишем библиотеки для реактивного логирования, кэширования, трейсинга, метрик, тестирования и прочие утилиты.
Необходимость писать библиотеки для реактивного стэка — одна из сложностей использования Реактива. Где для обычного многопоточного приложения уже всё написано и работает «из коробки», для реактивного часто нужно «доработать напильником». Но о сложностях поговорим позднее.
Помимо внутренней оптимизации работы приложения, реактивный подход позволяет выстроить реактивное взаимодействие между сервисами, делая их более отзывчивыми. Приложение может получать на вход и отдавать на выход поток данных по мере их «готовности». Так, например, клиенту банка не обязательно видеть в истории все операции сразу, тем более, что загрузка всего объёма займёт заметное время. Достаточно отобразить первую страницу и, по мере чтения данных из базы, подгружать последующие.
Реактивное межсервисное взаимодействие останется за рамками этой статьи, мы будем говорить исключительно про внутренности.
А сейчас предлагаю разобраться с тем, что такое же такое Реактив.
Что такое Реактив в Java
Reactive Streams и причем здесь Project Reactor
Если ничего не работает, почитайте документацию… Немного теории.
Здесь рекомендую познакомиться с The Reactive Manifesto, если ещё не знакомы. Манифест описывает принципы реактивного подхода в общем. Дальше мы будем говорить про реализацию в JVM, а именно про спецификацию Reactive Streams.
Цель Reactive Streams — найти минимальный набор интерфейсов, методов и протоколов, который опишет необходимые операции и сущности для реализации асинхронного потока данных с неблокирующим обратным давлением (non-blocking backpressure).
Обратное давление — это механизм, с помощью которого каждый метод обработки потока данных может управлять количеством входящих в него данных, не блокируя при этом поток. Например, когда источник отдаёт данные быстрее, чем потребитель может их обработать, backpressure поможет выровнять скорость между источником и потребителем.
Согласно спецификации реактивный стрим должен:
обработать потенциально бесконечное количество элементов;
последовательно;
асинхронно передавая элементы между компонентами;
с обязательным неблокирующим обратным давлением.
Сама спецификация Reactive Streams состоит из следующих частей:
API — определяет интерфейсы для реализации Reactive Streams, а также позволяет совмещать различные реализации.
Specification — сама спецификация, в которой описано, как должны вести себя реализации этих интерфейсов.
The Technology Compatibility Kit (TCK) — минимальный набор тестов для проверки соответствия спецификации.
Вот эти самые интерфейсы (API).
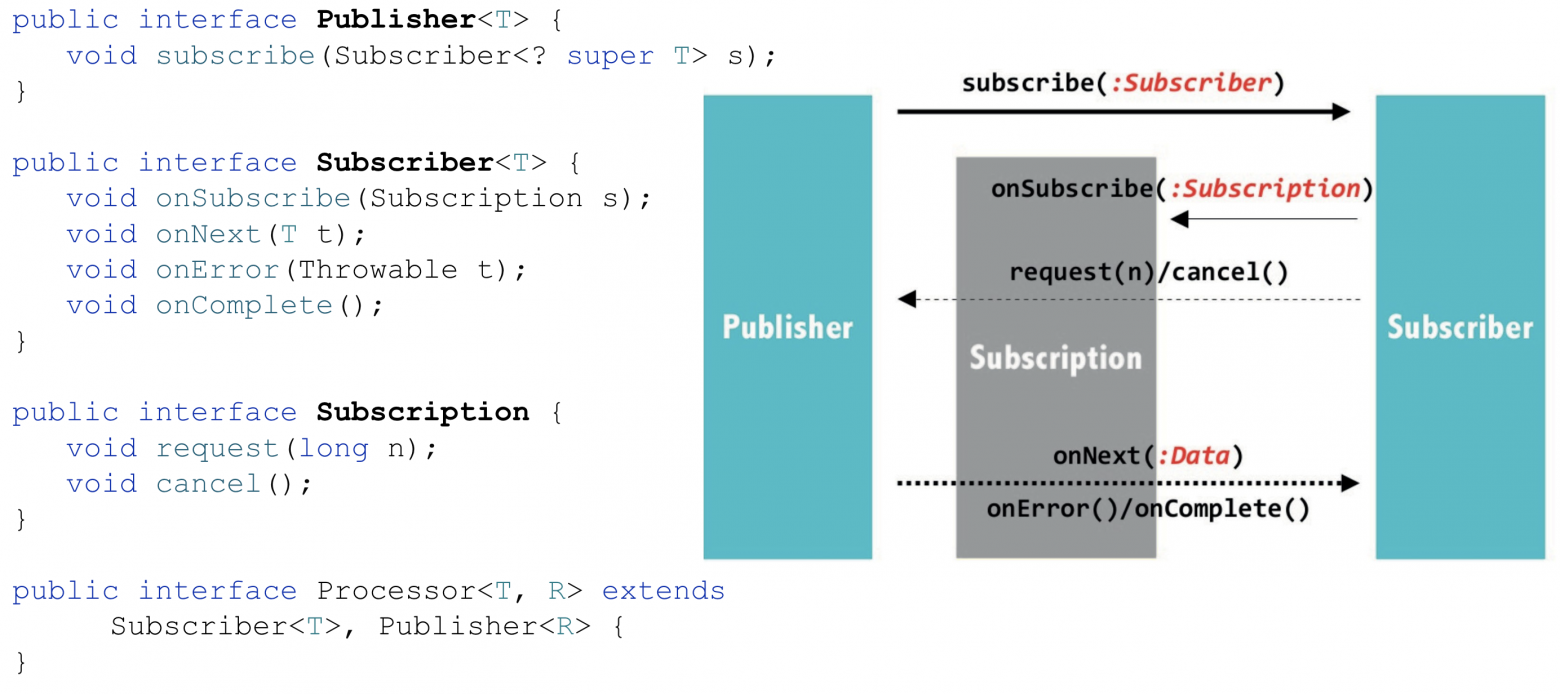
Интерфейсы Reactive Streams и взаимодействие между ними
Нас будут интересовать Publisher, Subscriber и Subscription.
Publisher — это источник данных, на который можно подписаться методом subscribe.
Subscriber — потребитель: после подписки может получать события жизненного цикла стрима (onSubscribe, onError, onComplete) или данные, ради которых всё и затевалось, они же элементы реактивного стрима (onNext).
Subscription — результат подписки потребителя на источник, с помощью которого можно запросить n элементов (request) или отменить подписку (cancel).
В Java все контрибьютят как могут, реализаций Reactive Streams много. Вот некоторые из них:

Реализации Reactive Streams
Самая популярная реализация, пожалуй, Project Reactor (настоятельно рекомендую к прочтению Reactor 3 Reference Guide целиком). И, что приятно, с ней хорошо интегрируется Spring Framework, который активно используется в микросервисах Альфа-Банка.
На диаграмме классов видно, как взаимосвязан интерфейс реактивных стримов Publisher с двумя основными классами Reactor, Flux и Mono.

Диаграмма наследования классов Project Reactor от Reactive Streams
Оба класса — источники данных с той разницей, что Flux отдаёт потенциально бесконечное количество элементов, а Mono не больше одного.
Жизненный цикл реактивного стрима
Жизненный цикл пригодится, когда мы будем говорить про накладные расходы (overhead), производительность, работу операторов и потоки. Давайте напишем небольшой реактивный стрим и рассмотрим этапы его сборки, подписки и исполнения.
Все примеры кода можно найти здесь: https://github.com/tirufanova/reactor-exx.
Сборка
В примере кода ниже:
.range создает последовательность элементов от 5 до 100;
.map преобразует каждый элемент в строку;
.filter оставляет в стриме только строки, длина которых равна 1;
.take берет из всей последовательности только 3 первых элемента.
AssemblySubscriptionExecutionTest: assemble

Сборка реактивного стрима
На оператор .hide не смотрите, он здесь для того, чтобы убрать внутренние оптимизации библиотеки, которые могут помешать нам поймать дзен понять Реактив.
Процесс сборки стрима идёт сверху вниз, по мере того, как программа выполняется. Каждый раз на каждом операторе создаётся по дополнительной обертке — «флаксу» — в примере получилось 5 штук.
Подписка
На предыдущем шаге мы только собрали цепочку операторов, которые обрабатывают элементы, но никакой обработки по факту не произошло, потому что нам нужно подписаться на стрим. Для этого подойдёт метод .blockLast, который под капотом вызывает subscribe источника (Flux).
AssemblySubscriptionExecutionTest: subscribe

Подписка на реактивный стрим
Подписка происходит снизу вверх:
сначала оператор .blockLast подписывается на оператор .take;
оператор .take подписывается на .filter;
и так далее, пока кто-то не подпишется на первый Flux.range.
И здесь на каждом вызове создаются новые обертки-декораторы. Ещё 5 пять объектов в дополнение к тем, что уже были созданы на этапе сборки.
Исполнение
Цепочка собрана, на неё подписался потребитель. Логично, что данные (элементы стрима) идут сверху вниз, от источника к потребителю. Но по реактивному стриму проходят не только элементы, но и события. А вот с ними не всё так однозначно. Добавим в реактивную цепочку две точки логирования (метод log), чтобы увидеть события.
AssemblySubscriptionExecutionTest: execute
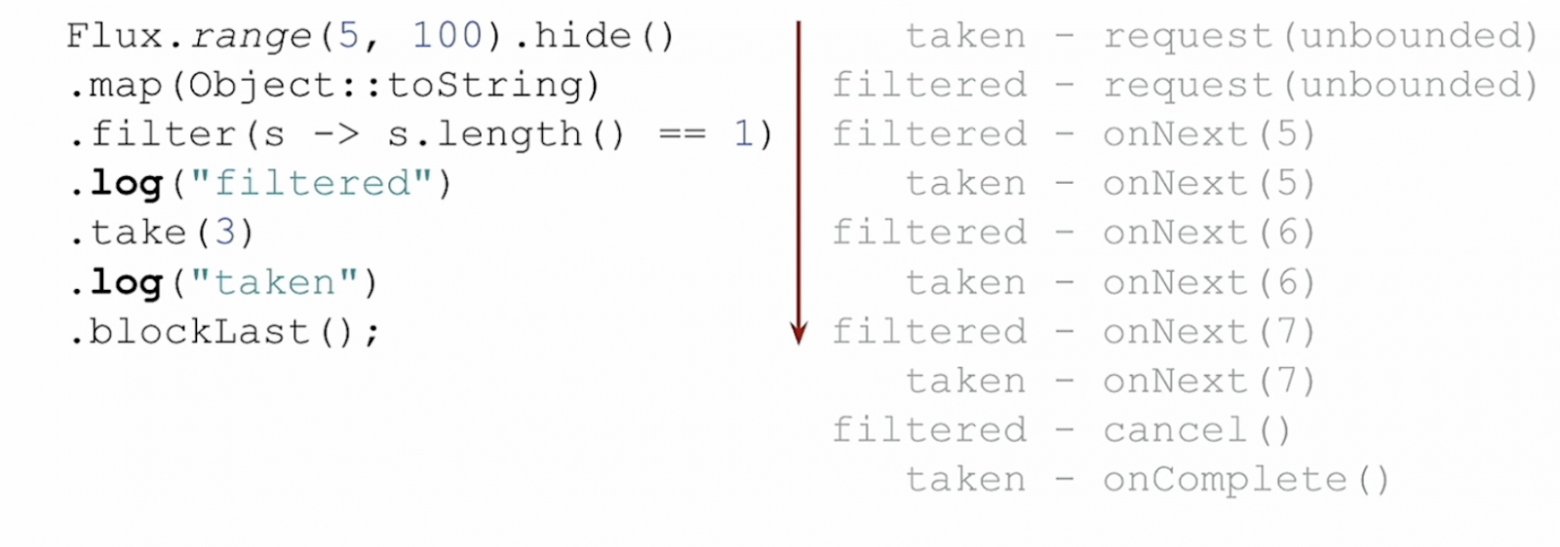
Исполнение реактивного стрима
Первым видим сигнал request. Элементы по стриму не начнут идти, пока они не будут запрошены (request). Это тот самый backpressure из реактивного манифеста и реактивной спецификации. Сигнал запроса идёт снизу вверх, от потребителя к источнику.

Запрос элементов, он же backpressure
Backpressure позволяет регулировать, сколько данных мы готовы принять и обработать. В нашем случае — unbounded — присылай всё и без остановки.
На иллюстрации запрос залогирован 2 раза, так как в реактивной цепочке 2 точки логирования. По факту, каждый оператор снизу вверх запрашивает элементы у вышестоящего. При этом количество запрошенных элементов может отличаться в зависимости от внутреннего устройства запрашивающего оператора.
Теперь, наконец-то, начинают идти элементы по стриму, сверху вниз, как и положено, генерируя события onNext.

Отправка элементов
Когда оператор .take насчитает 3 элемента, он отправляет источнику сигнал о необходимости прекратить отправку элементов. Точка логирования с меткой filtered (выше по стриму) поймала это событие. При получении такого сигнала источник должен прекратить отправку.

Отмена подписки
А после сигнала для источника, .take вниз отправляет событие о том, что элементы закончились, можно больше ничего не ждать и выходить из метода .blockLast.

Окончание стрима
Надеюсь, логика жизни реактивного стрима стала понятнее. И появилось поле для самостоятельных экспериментов.
Управление потоками
В самом начале статьи мы говорили, что реактивный подход не даст нам преимуществ в CPU Intensive задачах, потому что работает на небольшом количестве потоков (threads).
Другой случай, когда реактивный подход не подойдет — использование блокирующих вызовов. Всё по той же причине: потоков мало, они заблокируются, и приложение какое-то время не сможет выполнять никакую другую реактивную логику.
На самом деле, если по какой-то ведомой разработчику причине (например, блокирующий драйвер к базе данных), подобного рода задачи приходится решать на реактивном стэке, выход есть!
По умолчанию реактивный стрим целиком исполняется на том же потоке, на котором был создан (точнее, на котором на него произошла подписка), но этим поведением можно управлять.
Для этого нам понадобится отдельный Scheduler — реактивная абстракция пула потоков. Например, для блокирующих вызовов документация Project Reactor рекомендует использовать пул Schedulers.boundedElastic (). Осталось разобраться, как переключить нужный оператор реактивного стрима на новый пул.
Для переключения потока в реактивную цепочку необходимо добавить операторы publishOn либо subscribeOn.
publishOn
Оператор publishOn изменяет поток на этапе исполнения жизненного цикла, для событий onNext, onComplete и onError. Другими словами, поток меняется для всех операторов, выполняющихся ниже по реактивной цепочке. Это в теории… Посмотрим, что происходит на практике.
Добавим в реактивную цепочку вызов publishOn с пулом parallel, а также две точки логирования: до переключения потока (с меткой «before») и после (с меткой «after»).
PublishOnSubscribeOnTest: publishOn

Переключение публикации стрима на parallel пул оператором publishOn
Логично предположить, что все сообщения с меткой «before» будут выполнены на потоке Test worker (в моем случае это поток JUnit), а с меткой «after» — на потоке пула parallel. Всё правильно, но есть тонкости.
Программа выведет следующий лог.

Лог событий реактивного стрима с оператором publishOn
И, как мы видим, наше предположение сработало не полностью. Действительно, для событий onNext и onComplete с меткой before видим поток Test worker, а с меткой «after» — parallel-1. Но для остальных событий (выделенных жирным) поток выглядит случайным. На самом деле это не так!
Давайте разбираться. В документации к методу написано, что publishOn изменяет поток при публикации элементов (onNext), а также при публикации событий окончания стрима и ошибки (onComplete и onError). Для всех остальных событий используется поток, на котором произошло предыдущее событие. А именно:
События onSubscribe и request происходят на этапе подписки и в начале исполнения стрима, то есть никакая публикация элементов ещё не происходила. Поэтому используется тот же поток, на котором была выполнена подписка на стрим.
События onComplete при этом подчиняются тем же правилам, что и onNext. Если бы не оператор .take в нашей цепочке, отправивший сигнал cancel источнику, в логе было бы ещё одно сообщение onComplete с меткой after на потоке parallel-1.
А вот сигнал cancel отправляется оператором .take вверх по реактивной цепочке, то есть смена потока опять не происходит. Поскольку оператор .take находится после publishOn, то его сигналы будут обработаны на треде пула parallel.
А как изменить поток для остальной части реактивной цепочки, для этапа подписки?
subscribeOn
Оператор subscribeOn выполняет смену потока в процессе подписки на реактивный стрим, а именно для событий subscribe, onSubscribe и request. Вспомним жизненный цикл — событие подписки проходит снизу вверх. То есть subscribeOn изменит поток для операторов, которые находятся выше него по цепочке? Почти…
Давайте возьмем предыдущий пример с теми же метками логирования, но заменим оператор смены потока (вместо publishOn используем subscribeOn).
PublishOnSubscribeOnTest: subscribeOn

Переключение подписки стрима на parallel пул оператором subscribeOn
И посмотрим, что появится в логе.

Лог событий реактивного стрима с оператором subscribeOn
Для первых четырех сообщений метка «after» соответствует потоку Test worker, а метка «before» — потоку пула parallel.
Действительно, в момент подписки и запроса элементов событие проходит снизу вверх по реактивной цепочке: сначала выполнится «after», а потом «before» уже на новом потоке. Но метод subscribeOn никак не влияет на то, что происходит после подписки. Поэтому события остальных фаз жизненного цикла будут происходить на потоке, который был установлен в момент подписки оператором subscribeOn, то есть parallel-1. Вне зависимости от направления сигнала.
Отсюда следует правило: subscribeOn должен находиться как можно ближе к источнику (условно, следующим оператором после источника в реактивной цепочке), а publishOn — как можно ближе к операции обработки, которую хотим переключить на новый пул (непосредственно перед самой операцией).
Чтобы лучше понять это правило, попробуйте в примере выше использовать сразу оба оператора subscribeOn и publishOn, а потом поменять их местами. Сообщения в логе в этих двух случаях будут абсолютно разными.
Неявная смена потока
Операторы subscribeOn, publishOn, сигналы, события… Запутано, но код хотя бы делает то, что обещает — явно изменяет поток исполнения.
Теперь давайте уберём из нашей подопытной реактивной цепочки все операторы смены потока. А вместо них добавим новую логику обработки, метод .delayElements: отдавай каждый следующий элемент вниз по реактивной цепочке с задержкой в 5 наносекунд.
ImplicitThreadSwitchTest: delayElementsThread

Реактивный стрим с задержкой публикации элементов
Точки логирования остались те же, давайте смотреть логи.

Лог исполнения стрима с задержкой публикации
И… откуда-то взялись новые потоки! Причём разные.
Спасибо документации метода delayElements, в ней явно описано, что дальнейшее исполнение стрима будет происходить на пуле parallel. Хотя такой побочный эффект совсем не очевиден из названия метода.
На самом деле, реактивный scheduler значительно более мощный инструмент, чем просто пул потоков. Он позволяет планировать отложенное выполнение какой-либо логики. Например, задерживать публикацию элементов: получи элемент из оператора выше по цепочке, подожди, только потом отправь элемент дальше.
Во внутренней реализации метод .delayElements как раз использует отложенную публикацию на parallel пуле. Метка «after» после оператора .delayElements выводит поток для такой отложенной публикации (onNext). А cancel уже выполнится на том потоке, который оставила предшествовавшая ему отложенная публикация.
В реальной жизни не так часто возникает необходимость задерживать обработку полученных элементов. А объединять элементы из нескольких реактивных стримов — задача практически ежедневная. Например, чтобы собрать из нескольких внешних запросов общий результат.
Объединить несколько стримов помогут такие методы, как .merge, concat или zip. В реализации этих операторов явная смена потока отсутствует. Зато может произойти неявная, если один из исходных реактивных стримов запущен другом потоке. Давайте рассмотрим на примере.
ImplicitThreadSwitchTest: mergeDifferentThreads

Объединение стримов, публикующихся на разных потоках
Соберём два реактивных стрима, которые генерируют последовательности чисел.
Первый, parallelThreadFlux, отдает числа 10, 11 и переключен на отдельный поток.
Второй, testWorkerThreadFlux, отдаёт 20, 21 и запускается на потоке по умолчанию.
Используем оператор .merge для того, чтобы собрать все числа в одну последовательность. Порядок чисел при этом будет соответствовать очерёдности их получения оператором .merge. И, конечно, расставим точки логирование исходных и результирующего стрима с соответствующими метками.
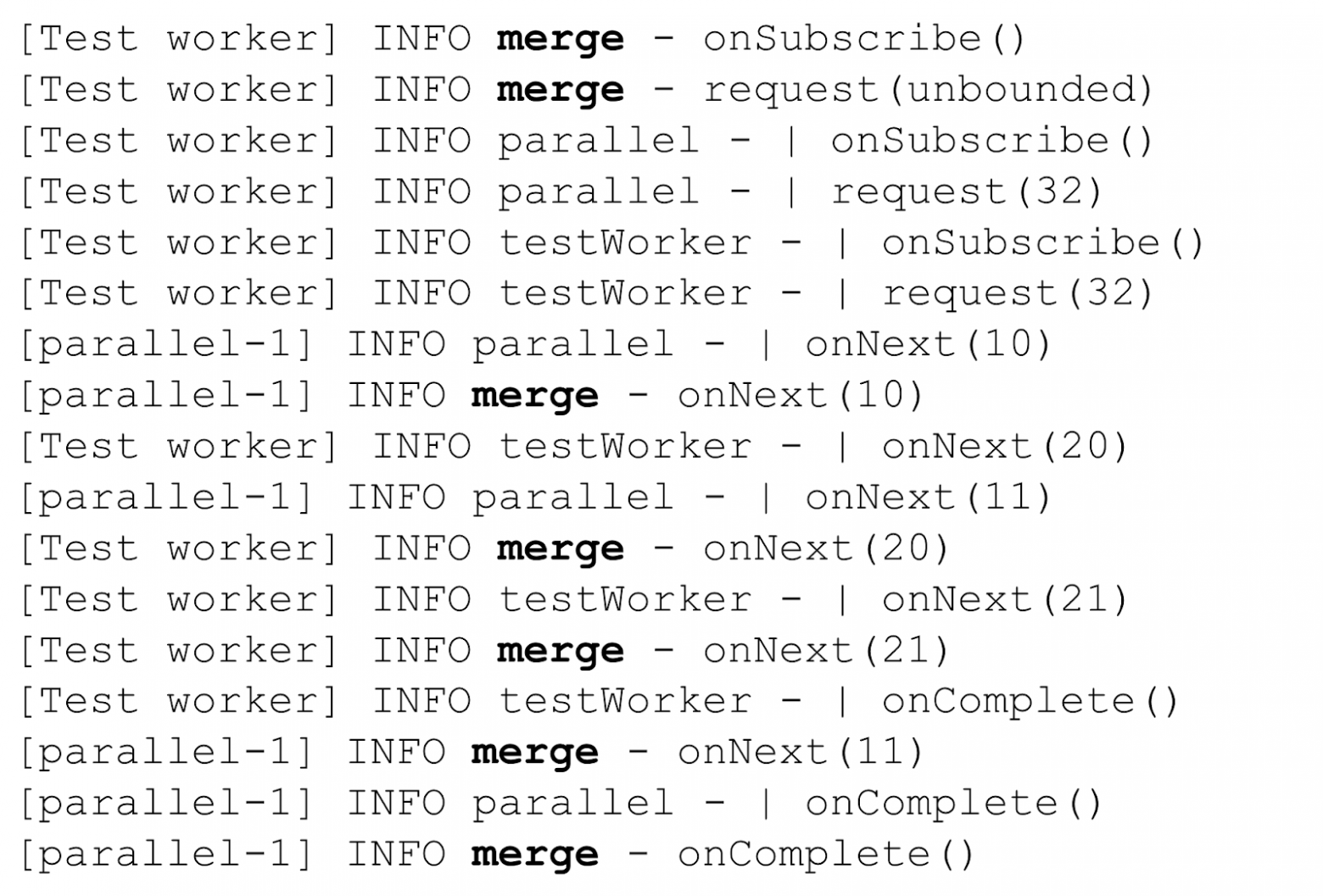
Лог стримов, публикующихся на разных потоках
Разберём сообщения в логе. Первые шесть строк: сначала оператор blockLast инициировал подписку (и запрос элементов) на оператор merge, после чего внутри оператора merge произошла поочерёдная подписка на все стримы, которые ему необходимо объединить. Все подписки и запросы элементов произошли на потоке Test worker, потому что никаких смен потока не происходило.
После запроса элементов по стримам начали идти данные. По меткам testWorker и parallel для событий onNext мы видим, что parallelThreadFlux публикует элементы на parallel пуле, а testWorkerThreadFlux на потоке на Test worker, как и ожидалось. А вот результирующая последовательность (метка merge, выделена жирным в логе) постоянно меняет поток в зависимости от того, на каком потоке (из какого стрима, соответственно) получен исходный элемент. Таким образом смена потока для результирующего стрима происходит неявно.
Почему важно помнить про неявную смену потока? Потому что она может «портить» предшествующую явную смену потока операторами publishOn и subscribeOn, и ваша логика запустится совсем не там, где вы ожидаете. Чтобы избежать такого поведения, используем publishOn и subscribeOn как можно ближе к логике, нуждающейся в отдельном потоке.
Самое время вооружиться всеми полученными знаниями и оценить сложности Реактива.
Какие сложности приносит Reactive и как с этим бороться
Сложности при написании программы
Код становится непонятнее.
Объективно нам стало сложнее. Если в императивном исполнении код будет понятен любому начинающему программисту…
ReadabilityTest: imperativeVsReactive

Императивный код
…то переписанный на Реактив тот же самый код уже требует значительно больше знаний. Обрастает «служебными» методами типа .blockLast. И вдобавок плохо читается.

Реактивный код
Это означает, что порог вхождения выше, разработка дольше, а ошибок потенциально больше.
Поэтому лучше не использовать «реактивщину» там, где она не нужна, например, где маленькая нагрузка, нет большого числа внешних вызовов или не требуется высокая отзывчивость (то есть отдавать данные как можно скорее по мере их получения, а не все сразу). Если вы всё-таки решили использовать Реактив, его придется изучить.
Даже если код уже реактивный, не стоит переделывать на Reactor всё подряд. Часто индикаторы того, что вы что-то делаете не так, это вызовы в реактивном коде методов Flux.just, Flux.fromIterable и block*. Подумайте, нельзя ли решить задачу с помощью коллекций, нереактивных стримов или императивного кода? Или остаться в реактивном подходе, но подобрать более подходящие операторы? Это снизит шансы выстрелить себе в ногу.
И, конечно, пишите тесты! В этом поможет библиотека io.projectreactor: reactor-test. Она содержит инструменты для проверки поведения реактивного стрима или реактивной логики, обрабатывающей реактивный стрим.
Помимо сложностей понимания кода, длинные реактивные цепочки порождают и другую сложность, а именно длинный стэк.
Стэк становится длиннее.
И непонятнее.
В процессе отладки мы увидим примерно следующее.

Стэк вызовов реактивного стрима
А где, собственно, наш код?… А, маленькая строчка внизу экрана. Понять, что именно происходит в процессе исполнения программы, даже опытному разработчику, достаточно сложно.
Плюс получаем оверхэд в процессе исполнения. Но об этом чуть позже.
Как помочь себе с отладкой? Можно использовать оператор .log (), он позволяет залогировать события жизненного цикла стрима с заданной меткой, в том числе элементы данных, проходящие через стрим.
Ошибки искать сложнее.
Когда мы видим стектрейс исключения (который стал длиннее, см. пункт выше), непонятно, что и где сломалось. В стектрейсе будет множество служебных реактивных обёрток, и, с большой вероятностью, наш код просто не влезет. А так как в коде приложения происходит только сборка стрима и подписка, а исполнение идёт в недрах Реактива, явная ссылка на логику, породившую ошибку, может вообще отсутствовать в стэке.
Здесь на помощь придёт библиотека io.projectreactor: reactor-tools, которая добавит в стэк вызовы нашей программы, чтобы мы смогли сопоставить исключение с кодом приложения. Одно из приятных свойств этой библиотеки то, что она не добавляет оверхэд в процессе выполнения программы, а это значит, что её можно использовать в продакшн.
Второй важный момент, который сильно упростит жизнь — логируем ошибки явно. Для этого максимально используем оператор onError. Он должен быть как можно ближе к потенциальному месту исключения. Лучше написать лишний onError, чем в логах не найти, где именно произошла ошибка.
Необходимо дорабатывать инструменты.
Выше мы много говорили про смену потоков. Реактив не даёт никаких гарантий, какая часть кода запустится в какой момент и на каком потоке, поэтому многие традиционные инструменты перестают работать. Где-то уже есть реактивные аналоги, а остальное придётся дорабатывать под себя и Реактив.
Прямое следствие смены и переиспользования потоков различными операторами реактивной цепочки то, что ThreadLocal переменные ломаются. Точнее, сами ThreadLocal, конечно, работают, а вот трэйсинги, контексты логирования, данные клиентских запросов, использовавшие эти локальные переменные в многопоточном коде, в реактивном не годятся.
Простой способ добавить контекст к реактивному стриму — явно передавать его вместе с элементами стрима. Подход надёжный, понятный, но портит архитектуру приложения. Реактивный способ решения задачи — использование контекста (Context) библиотеки Reactor.
Контекст — это аналог Map: также хранит в себе пары ключ-значение, позволяя записывать и считывать их. Контекст неизменяемый (immutable), то есть при добавлении к нему нового значения создаётся новый экземпляр контекста. Контекст привязывается к реактивному стриму на этапе подписки, то есть виден только операторам, которые находятся выше его в реактивной цепочке.
Подход нужен чаще для написания библиотек, а не кода приложения, поэтому подробно останавливаться не будем. Продолжим разбираться со сложностями и перейдём от написания программы к её исполнению.
Сложности в процессе выполнения программы
Как влияет на работу нашего приложения создание всяких обёрток? Мы говорили про длинный стек. Собственно, вот он.

Обертки-декораторы
Стэк состоит из тех самых оберток, через которые проходят наши элементы.
Чем это плохо? Оверхедом:
Больше объектов, длиннее стэк — больше потребляемой памяти.
Много маленьких объектов — больше работы для GC.
Портим оптимизации JIT компилятора.
Ограничения оптимизаций JIT компилятора
Как мы с этим боремся?
Изучаем операторы, которые используем (у Project Reactor очень хороший официальный гайд). Некоторые операторы могут добавлять накладные расходы, генерировать маленькие объекты (например, очереди) под капотом, хотя для нашей задачи мог бы подойти оператор попроще.
Стараемся не делать длинных реактивных цепочек, по возможности объединяем операторы. Например, из нескольких последовательных операторов filter всегда можно сделать один.
Используем оператор .handle. Он тоже позволяет объединять логику нескольких операторов и объединяет логику .map и .filter. Если в случае с .map и .filter. у нас создается 4 дополнительных объекта, …
HandleTest: withoutHandle
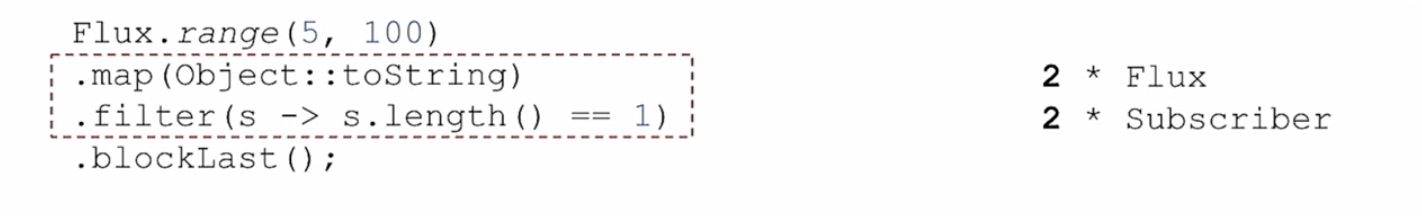
Последовательность из нескольких операторов, map и filter
…то с .handle всего 2.
HandleTest: withHandle

Замена нескольких операторов map и filter на один handle
Оговорюсь, что не стоит увлекаться преждевременными оптимизациями. Если у вас нет проблем с производительностью реактивного приложения и в нём отсутствуют длинные реактивные цепочки, то код с .map и .filter читается значительно лучше. А Project Reactor достаточно умный, чтобы делать собственные оптимизации под капотом. Как всегда, серебряной пули не существует, ищите свои рецепты, проверяйте на практике.
Теперь самое время перейти к ней, к практике.
Как сломать реактивный стрим
Реактив позволяет выполнять (условно) параллельную обработку данных, берёт на себя все сложности работы с многопоточностью. В его арсенале множество операторов манипуляции с данными и самими реактивными стримами. Но как бы не были скрыты сложности многопоточности, иногда непонимание внутреннего устройства может привести к тому, что обработка данных пойдёт не по плану.
Сейчас мы наконец-то что-нибудь сломаем! Для этого нам понадобится два оператора — groupBy и flatMap.
Оператор groupBy
Оператор groupBy разбивает исходный стрим на множество отдельных стримов по какому-то условию. Похож на работу оператора groupBy в Java Stream API.
Flux: groupBy

Оператор groupBy
Здесь нас интересует prefetch — это количество элементов, которые оператор предподгружает из реактивного стрима в свой внутренний буфер. В событиях реактивного стрима мы увидим его как backpressure, запрос элементов. Значение по умолчанию 256.
Оператор flatMap
Работает наоборот, а именно:
преобразует каждый элемент исходного реактивного стрима в новый реактивный стрим (с помощью функции, которую получает на вход);
затем сливает эти внутренние стримы в один;
при этом элементы из внутренних стримов будут чередоваться.
Тоже похож на оператор flatMap в Java Stream API.
Flux: flatMap

Оператор flatMap
Если посмотреть документацию, то мы найдём интересный параметр — concurrency. Он задаёт максимальное количество внутренних стримов, которые одновременно может объединять оператор flatMap. Значение по умолчанию — 256. То есть потенциально flatMap объединит любое количество стримов, но чтобы перейти к обработке 257 стрима, один из первых 256 должен завершиться.
Собираем стрим
В руководстве Project Reactor висит ружье, которому пора выстрелить есть примечание: если воспользоваться одновременно groupBy и flatMap, то при большом количестве групп в groupBy (high cardinality) и низкой конкурентности flatMap (одновременно обрабатывается мало стримов, low concurrency) обработка стрима может зависнуть (lead to hangs).

Примечание о взаимодействии между groupBy и flatMap
Казалось бы, у нас неблокирующая обработка, как она может зависнуть? Звучит странно. Давайте разберёмся.
Допустим, у нас есть список имён — входной стрим namesFlux.
И нам нужно посчитать количество имён по первой букве — функция countNamesFunction.
Для этого сначала сгруппируем имена по первой букве оператором groupBy, применим функцию подсчёта countNamesFunction и соединим результаты обратно в общий стрим оператором flatMap.
По всем стримам расставим точки логирования: в функции подсчёта имен, а также перед оператором groupBy и после flatMap.
GroupByWithFlatMapNamesTest: completeNamesCount

Подсчет имён
Пока всё идет по плану, в логе появятся следующие значения для 4 групп имен (остальные события опущены д
