Зачем мне пылесос с ананасом или как оценить корректность рекомендательной системы
Привет, Хабр!
На связи участница профессионального сообщества NTA Ульянова Дарья.
Рекомендательные системы стали нормой, все к ним привыкли точно также как и к быстрому Wi‑Fi, навигатору или беспроводным наушникам. Они просто делают жизнь немного проще, и всем от этого выгода: пользователям, которым не приходится лишний раз искать на маркетплейсе любимую зубную пасту или корм для собаки; сервису, которому выгодно, чтобы пользователи заказывали больше.
Но не все так радужно, иногда предложения настолько невпопад: почему мне рекомендуют ананас при покупке пылесоса? Как такое пропустили в прод? Если подобное повторяется несколько раз, то сервис может потерять клиента и потенциальную прибыль.
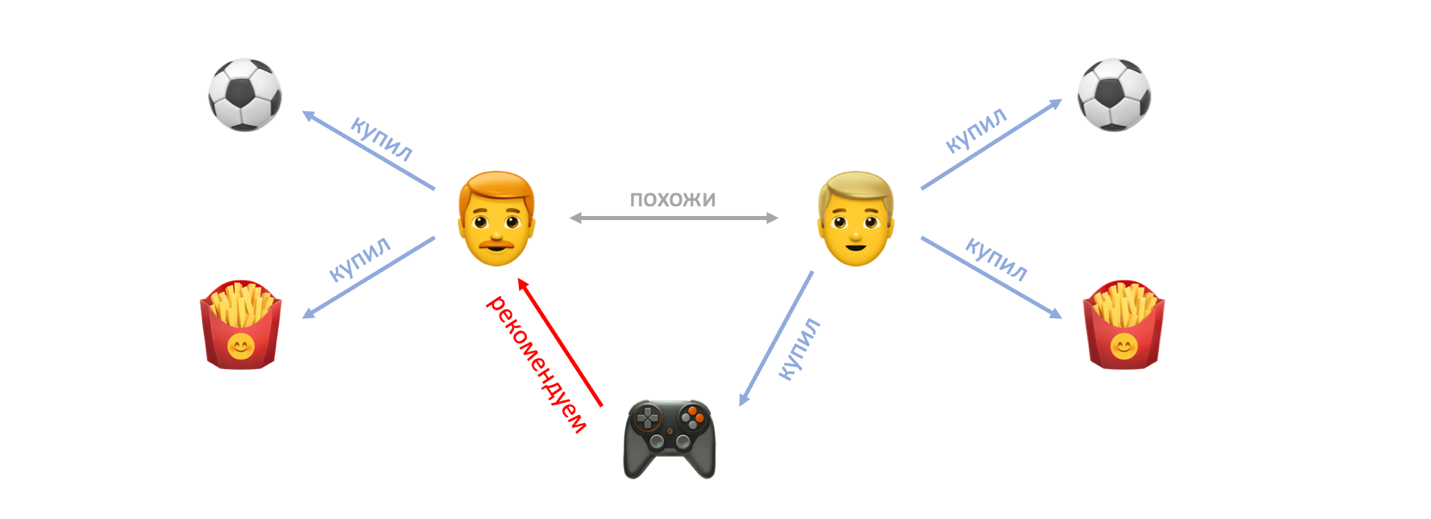
Сегодня буду разбираться с тем, как оцениваются рекомендательные системы, какие метрики качества используются, и как затем измеряется эффективность их работы для бизнеса. Это полезно при оценке сервисов с рекомендательными системами, ведь часто нам приходят чисто статистические данные, в которых надо разобраться, и дать объективную оценку проекту.
Навигация по постуПримечание
С 1 октября 2023 года в силу вступили изменения в Федеральном законе «Об информации, информационных технологиях и о защите информации». Теперь владельцы сайтов с рекомендательными алгоритмами обязаны размещать на сайте дополнительную информацию (в том числе и о применяемых технологиях и правилах пользования recsys).
Рекомендательные системы: quick overview
Но прежде всего пара слов о самих рекомендательных системах.
Рекомендательные системы (Recommender Systems, RecSys) — это сложные алгоритмы, созданные для релевантных рекомендаций продуктов/услуг пользователям.
Рекомендательные системы делятся на две большие группы: неперсонализированные и персонализированные.

Первые основываются на популярности товаров или их новизне.
Вторая группа намного обширней: с ней мы сталкиваемся, когда авторизируемся на сервисах или заходим под одним и тем же ip‑адресом несколько раз на сайт. В ней рекомендации строятся на основе нашей предыдущей деятельности на сайте или сервисе и оставленной там информации.
Персонализированные RecSys состоят из трех разных подходов к рекомендациям:
Контент основанные системы (Content based RecSys). Эта техника представляет собой алгоритм, зависящий от предметной области, в нем большое внимание уделяется анализу характеристик (атрибутов) элементов для создания прогнозов. Рекомендации строятся на основе профилей пользователей с использованием функций, извлеченных из ранее оцененных элементов; в основном пользователю рекомендуются элементы с предсказанной положительной оценкой. Техника используется в случаях, когда необходимо рекомендовать музыку, документы, новости или веб‑страницы, похожие на какую‑то определенную. Ярким примером прогноза на основе контента является рекомендация треков, похожих по звучанию или содержанию на какой‑то другой, такая функция есть во многих музыкальных сервисах.
Коллаборативная фильтрация (Collaborative Filtering) — основное направление рекомендательных систем. Использует историю, с чем взаимодействовали пользователи, для построения прогноза другим пользователям. Это происходит следующим образом: создается матрица предпочтений пользователей в отношении элементов, далее подбираются пользователи с соответствующими интересами (соседи), путем вычисления сходства между их профилями, чтобы делать рекомендации. Используются в случае сложных предсказаний, когда сложно выявить схожесть между элементами, например, в кино‑рекомендациях или при рекомендации музыки в целом.
Здесь, в свою очередь, есть два подхода:
Memory‑based подход. Использует различные алгоритмы при объединении предпочтений соседей для создания предсказаний. Предсказания строятся на основе схожести пользователей (user‑based) или схожести предметов (item‑based). В первом случае, ищутся пользователи с похожими предпочтениями и товары, которые им понравились, затем рекомендуется первому пользователю то, что понравилось другому, и наоборот. Во втором случае вычисляется сходство между товарами, а не юзерами. Item‑based подход считается более стабильным и показывает лучшие результаты, так как сходство товаров статично, а вкусы юзеров могут быстро меняться.
Model‑based подход. Модель обучается на основе предпочтений соседей и далее делает рекомендации. Процесс обучения осуществляется при помощи машинного обучения или data mining.

Гибридные системы. Это микс методов коллаборативной фильтрации и рекомендаций на основе контента для повышения точности и производительности рекомендательных систем.
Есть ещё одна классификация рекомендательных систем: онлайн и оффлайн.
Онлайн отличаются от оффлайн тем, что их основная задача «поймать» изменения популярности определенных товаров. Данных в таком случае недостаточно, чтобы была возможность «поймать» такие изменения методами коллаборативной фильтрации, поэтому онлайн методы менее персонализированы из‑за недостатка релевантных персональных данных.
Измерение качества рекомендаций
Измерение качества рекомендаций очень сложная и обширная тема, включающая в себя учет множества нюансов. Вообще, сначала надо сказать, как проводится процедура оценки recsys.
Эксперимент с оценкой качества рекомендательной системы выглядит так:
Разбиваем выборку сессий на обучение и тест.
Оптимизируем оффлайн-метрику качества на обучении.
Оцениваем качество на тесте и выбираем модель.
Внедряем модель в рекомендательный сервис.
Проводим AB-тестирование и измеряем онлайн-метрику. Подробнее про AB-тестирование: можно почитать здесь.
Онлайн‑ и оффлайн‑метрики могут быть слабо связаны, поэтому чтобы улучшить онлайн‑точность нужно оптимизировать разные аспекты качества оффлайн метрик.
А теперь подробнее про метрики: в качестве оффлайн‑метрик выступают статистические ошибки, метрики ранжирования и прочие, а в онлайн‑метриками чаще всего являются бизнес‑метрики, например, прибыли или кликабельность, о них поговорю чуть позже.
Оффлайн-метрики
Начну изучение оффлайн‑метрик оценки recsys с RMSE.
Root Mean Squared Error (RMSE) — точность предсказаний рейтингов. Формула выглядит следующим образом:

где u — конкретный user/пользователь/клиент; i‑ конкретный item/предмет/товар; rui— оценка пользователем u товара i; ȓui— предсказанная оценка пользователем u товара i.
Данная метрика имеет особое место в истории развития рекомендательных систем. Именно RMSE использовался для измерения качества рекомендаций в конкурсе от Netflix.
Однако точность предсказаний не гарантирует хороших рекомендаций. В данном случае предсказанные ȓui для каждого пользователя ранжируются в порядке убывания, и ему предлагается ТОП-10 или ТОП-20, а остальное откидывается, что не целесообразно с точки зрения вычислений.
Более адекватные метрики качества рекомендаций: precision@k, recall@k и некоторые меры качества ранжирования MAP@k, NDCG@k рассмотрю дальше.
Precision@k — точность (доля релевантных среди найденных) первых k рекомендаций для u.

где Ru (k) ϵ I — первые k предсказаний для u; Lu ϵ I — истинные предпочтения u.
Recall@k — полнота (доля найденных среди релевантных) первых k рекомендаций для u.

Mean Average Precision for the first k recommendations (MAP@k) — одна из самых используемых метрик ранжирования. На русский перевод названия формулы звучит очень странно, постараюсь пояснить формулу, начиная с конца:
Preсision@k — точность первых k рекомендаций:

где yj— релевантность: если j элемент предсказан верно, yj = 1, иначе yj = 0.
Average Precision@k — средний Preсision@k по позициям верно предсказанных элементов:

MAP@k — усредненное по всем users ap@k:

Пример ниже покажет более наглядно вычисление MAP@k.

Normalized Discounted Cumulative Gain for the first k recommendations (NDCG@k) — тоже популярная метрика ранжирования. Начну, как и с MAP@k с конца формулы:
Discounted Cumulative Gain@k — взвешенная сумма выигрышей:

где в первый множитель вычисляет больший вес релевантных предсказаний, а второй — вычисляет больший вес в начале выдачи.
Normalized Discounted Cumulative Gain@k — нормированная взвешенная сумма выигрышей:

где maxDCG@k– это DCG@k при идеальном ранжировании.
Чтобы рекомендательная система не была тривиальной и у пользователей создавалось впечатления, что их мысли читают, recsys должна учитывать множество критериев, ниже представлены самые популярные из них:

Примеры критериев, отражающих полноту рекомендательной систем. Составлено автором
«Разнообразие (diversity) — число рекомендаций из разных категорий или степень различия рекомендаций между сессиями. Пользователь должен видеть различный контент/товары, чтобы не чувствовать себя примитивным.
Есть несколько способов введения разнообразий, здесь представлю формулу совокупного разнообразия (aggregate diversity) recsys — общее количество отдельных элементов, рекомендованных всем пользователям:

где PH (u)‑ множество элементов с высокой оценкой пользователя, а Rec (u) — множество элементов, рекомендованных пользователю.
Есть несколько способов рассчитать новизну, рассмотрю способ вычисления новизны по популярности. Новизна по популярности EPC (Expected Popularity Complement) измеряет возможность recsys рекомендовать элементы из длинного хвоста.

А вот и формула:

где rel (u, ir)– релевантность элемента ir (элемент, расположенный в ранжированном списке на r позиции из N возможных) для пользователя u; (1 — pop (ir)) — непопулярность элемента ir; pop (ir) — популярность считается как отношение рейтинга ir на максимальный рейтинг элемента из множества всех доступных элементов I.
Покрытие (coverage) — доля объектов, которые хотя бы раз побывали среди рекомендованных. Бизнес в первую очередь бизнес, его задача продать товар/услугу, поэтому рекомендательная система должна рекомендовать все товары.
Расчет покрытия зависит от вида конкретной задачи. Основная формула выглядит следующим образом:

где Ip— множество рекомендованных элементов, I — множество всех доступных элементов.
Покрытие каталога, например, можно рассчитать по формуле:

где IjL — множество рекомендованных элементов из списка L, возвращаемых за j‑ую рекомендацию; N — общее количество рекомендаций за рассматриваемый промежуток времени, I — множество всех доступных элементов.
Догадливость (serendipity) — это то, о чем я упоминала ранее, способность угадывать спонтанные нетривиальные предпочтения пользователей.
Догадливость можно измерить при помощи формулы:

где RSi— элемент, принадлежащий множеству неожиданных рекомендаций UNEXP; u (RSi) — полезность элемента u (RSi) = 1, если RSi полезен пользователю, иначе u (RSi) = 0); N — общее количество рекомендаций за рассматриваемый промежуток времени.
Множество UNEXP = RS\PM, RS — рекомендации от recsys, PM — рекомендации от примитивной модели предсказаний.
Рекомендательная система должна учитывать все эти факторы при формировании предложений, поэтому на оценку recsys они тоже должны влиять. Можно оптимизировать линейную комбинацию критериев или оптимизировать один критерий при ограничении остальных.
Бизнес-метрики оценки успешности рекомендательных систем
Как измерить прибыльность рекомендательной системы для бизнеса? Как понять, что трата денег на ее разработку не была зря?
Эффективность и ценность рекомендательной системы для бизнеса зависит от различных факторов, включая область ее применения и бизнес‑модель компании. Например, компании, которые в основном получают прибыль от рекламы: онлайн издания или YouTube, которым выгодней, чтобы пользователь провел на их сервисе как можно больше времени, поэтому время сеанса пользователя в таком случае тоже может быть информативной метрикой оценки качества рекомендательной системы. В e‑commerce ключевым показателем эффективности recsys может быть прибыль и доля в ней покупок рекомендованных товаров.
Авторы статьи «Measuring the Business Value of Recommender Systems» выделяют 5 универсальных подходов для измерения влияния рекомендательных систем на бизнес, которые представлены ниже.

Ниже в таблице отражены основные комментарии к каждому подходу. Повторюсь: данные показатели можно измерить при помощи AB-тестирования.
Измерение | Комментарий |
Кликабельность или рейтинг кликов (Click Trough Rate, CTR) | С помощью этого показателя измеряется, сколько кликов получают рекомендации. Считается, что чем больше количество кликов по предсказанным объектам, тем более интересны и актуальны рекомендации для пользователя. Плюс: легко измерить. Минус: часто не является достаточно информативным показателем. |
Показатели принятия и конверсии (Adoption and Conversion Rates) | Модифицированный под свои потребности CTR. Например, YouTube ввел метрику long CTRs, по которой клики на рекомендованные видео засчитываются при условии просмотра некоторой его части. Плюс: учитывает особенности бизнес-модели, легко измерить. Минус: индивидуально разрабатывается под каждую бизнес-модель. |
Продажи и доход (Sales and Revenue) | Плюс: самый информативный показатель. Минус: сложно учесть все факторы, которые могли повлиять (сезонность и т.д.). |
Влияние на распределение продаж (Effect on Sales Distribution) | Конкретное измерение, показывает влияние рекомендательных систем на распределение продаж. |
Поведение и вовлеченность пользователей (User Engagement and Behavior) | Часто предполагается соответствие между вовлечением пользователей и удержанием клиентов, тем самым выгодой для бизнеса. |
Заключение
В этом посте я заглянула под капот рекомендательных систем и рассказала: какие системы есть, чем различаются, как оцениваются и как влияют на бизнес. Напоследок оставлю список
литературы, вдруг кого-то затянуло и хочется сильней прокачаться).
Список для изучения
