Выборы-2016. Часть 1 — результаты и сравнения
В сентябре прошли выборы в Госдуму РФ VII созыва. При голосовании вся территория России была разделена на 225 округов. В каких округах каждая из партий получила высокие (или низкие) результаты? Какие значения принимала явка избирателей и как она влияла на результаты партий? Ответы на эти вопросы и ряд других наблюдений представлены в этой публикации.

Об избирательных округах
Выборы в Госдуму в 2016 проводились по смешанной системе — 225 мест в парламенте распределялись по партийным спискам, остальные 225 мест по одномандатным округам. Далее всюду будет идти речь о пропорциональной (по партийным спискам) составляющей голосования. Границы избирательных округов были определены Центризбиркомом. Любопытно, что использовалась так называемая «лепестковая» модель (или джерримендеринг) формирования округов, с целью совмещения в одном округе городского и сельского населения. Этот способ задания округов может оказывать влияние на итоговые результаты только в мажоритарной, но не пропорциональной, составляющей выборов.
Источники данных
Сведения о результатах голосования предоставляет ЦИК РФ. Разнообразные цифры с разбивкой по округам доступны на этой странице. Геоданные всех избирательных округов подготовлены Михаилом Каленковым и его соратниками из сообщества GIS-LAB. Подробности здесь. Карты составлены в проекции EPSG:3857.
Географические карты
Во главу угла была поставлена быстрая отрисовка карт. Поэтому использовались геоданные с максимально упрощенной геометрией округов — 0.1% от исходных данных. Кроме того, я выбирал между двумя библиотеками для работы с географическими картами — leaflet и highcharts. Оказалось, что для используемого датасета leaflet на моем лэптопе строит карту c 225 округами за 200 — 300 мс. В highcharts для отображения той же карты требуется примерно в 6 раз больше времени. Хотя, на мой вкус, карты в highcharts выглядят более эстетично по сравнению с картами библиотеки leaflet. Для отрисовки избирательных округов Москвы и Санкт-Петербурга использовался более подробный файл с упрощением до 30% от исходных данных. В leaflet удобнее работать с shape файлами, поэтому исходные geojson файлы был конвертированы в требуемый формат.
Отображение результатов голосования
Я использовал R и shiny для представления результатов голосования в избирательных округах. Если у вас установлен R, то вы можете запустить показанное ниже приложение на своем компьютере. Для этого требуется загрузить библиотеки shiny и pacman — команда install.packages(c("shiny", "pacman")), и запустить приложение командой shiny::runGitHub("e-chankov/elections_2016_districts"). Для просмотра был использован Firefox 49.0.2 в полноэкранном режиме.
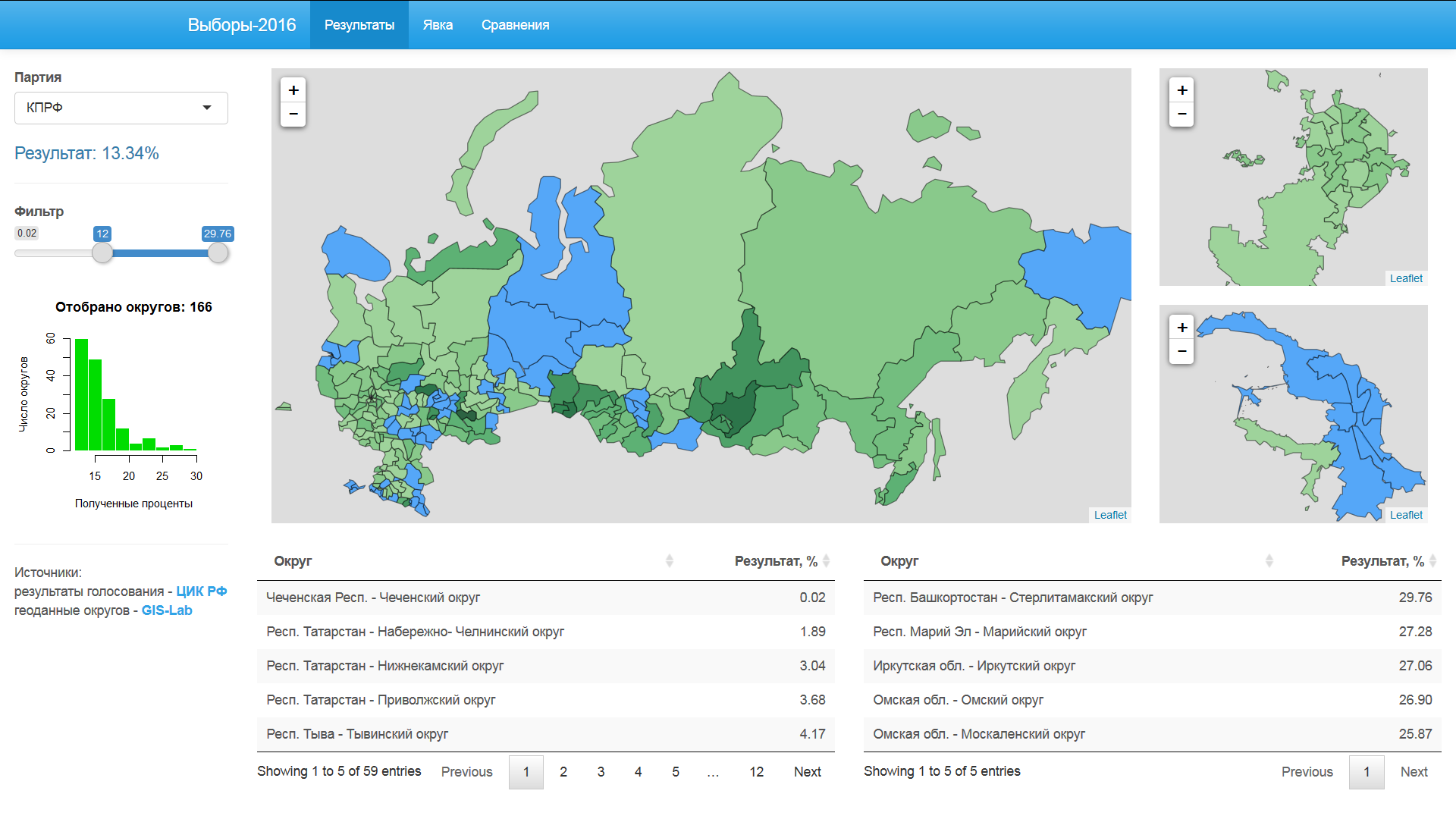
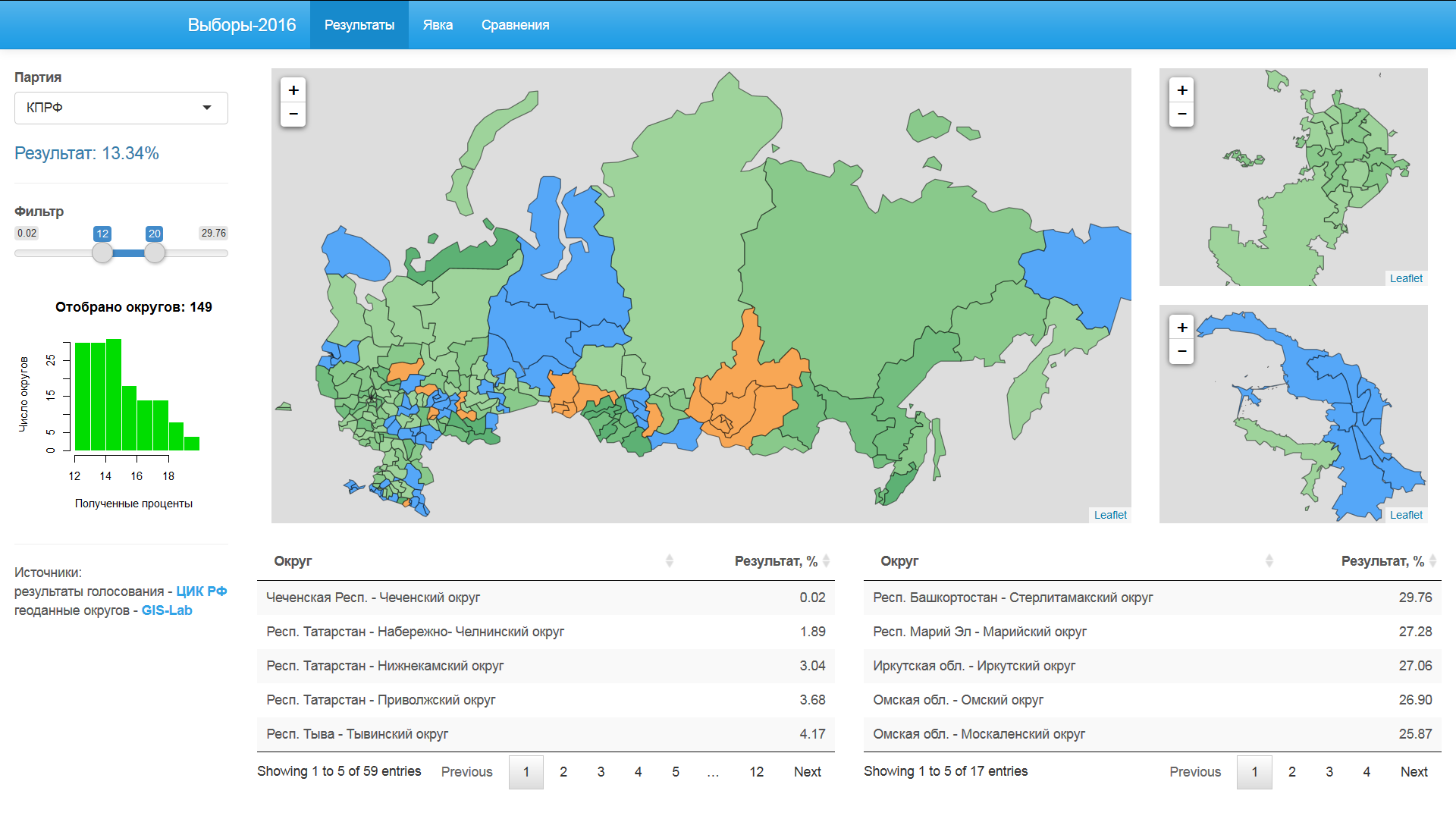
Результаты партий
Три снимка ниже демонстрируют результаты партий «Единая Россия», «КПРФ» и «РОСТ».



Фильтр позволяет выделять округа, которые не попали в заданный диапазон. Синий цвет — результаты меньше нижней границы фильтра, оранжевый цвет — результаты выше верхней границы фильтра.
Явка
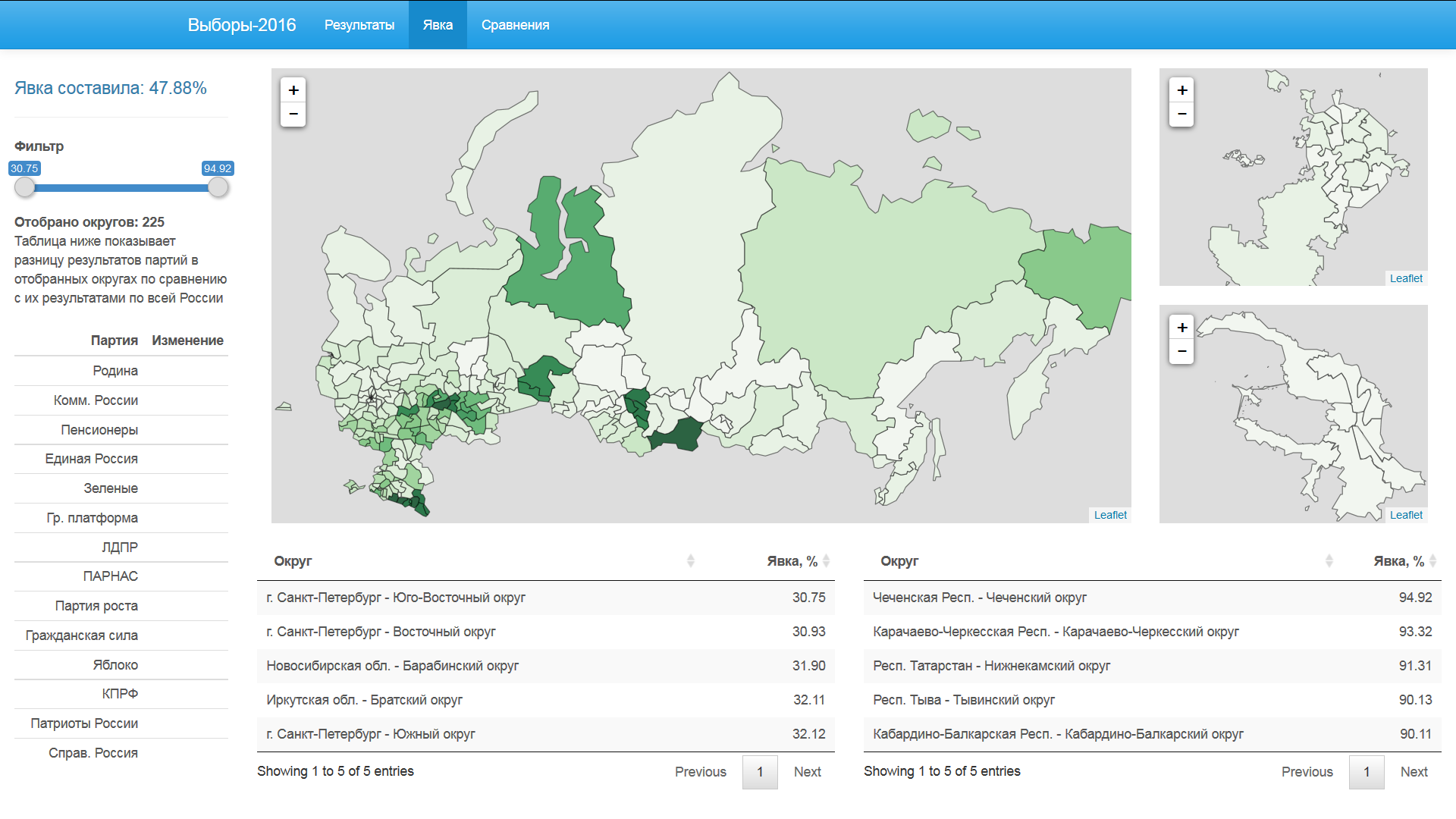
Как и в предыдущей вкладке, задание границ явки выделяет округа вне установленных рамок. По тем округам, которые удовлетворяют условию фильтра, вычисляются процентные результаты партий и сравниваются с набранными значениями по всем округам.

«Единая Россия» теряет более 10% от своего итогового результата, если учитывать только округа с явкой до 48%. Больше всех приобретает «ЛДПР» — 3.5%.

Картина меняется на противоположную, если отсекать округа с меньшей явкой. Только изменение в процентах не столь сильное, как при исключении округов с высокой явкой. При данных границах больше всех теряет «Яблоко».
Сравнение результатов партий
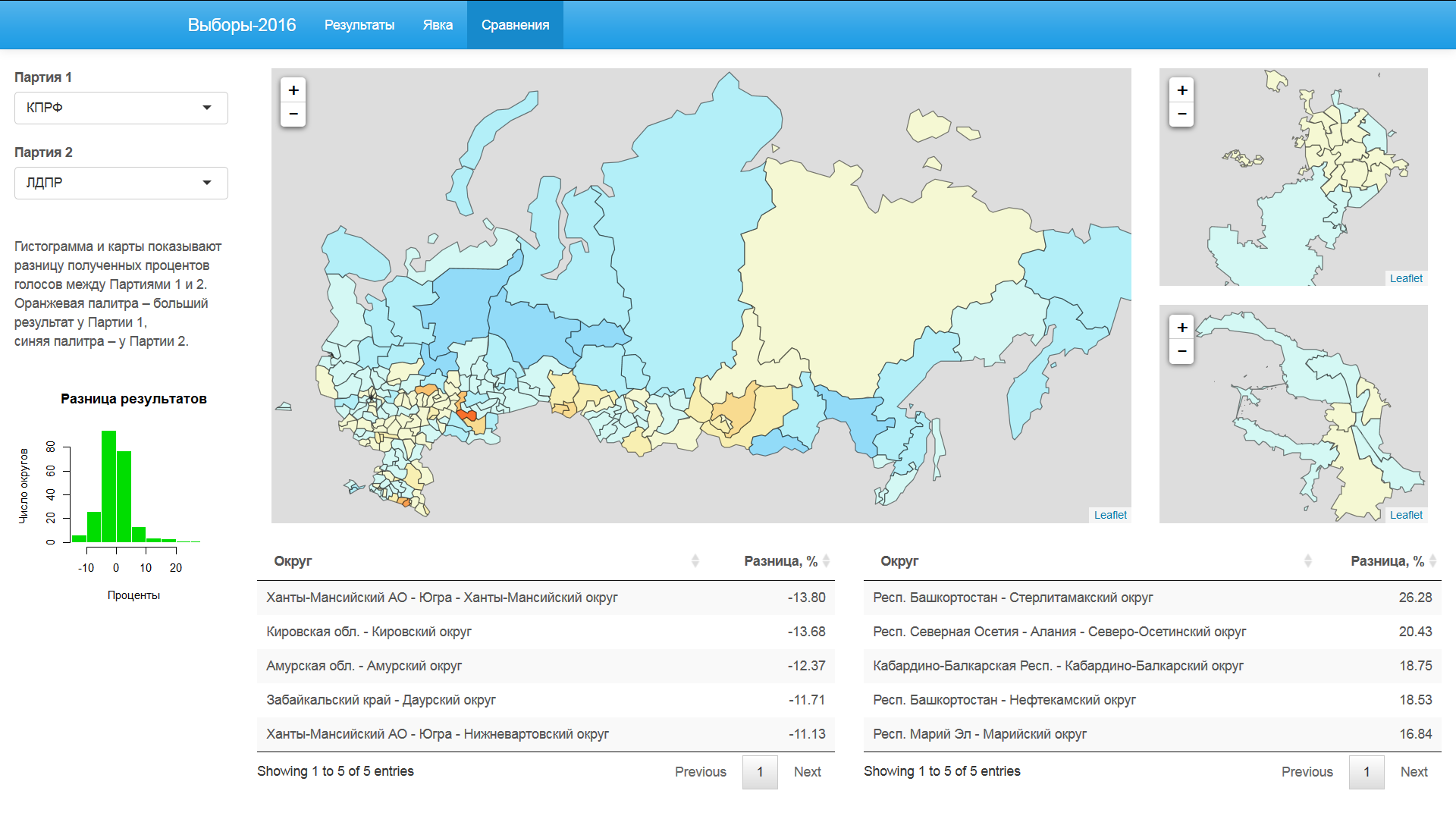
У «ЛДПР», по сравнению с «КПРФ», преимущество на Дальнем Востоке и севере России.

«Яблоко» явно превосходит «Коммунистов России» в Москве и Санкт-Петербурге. В большей части остальных регионов у «Коммунистов России» преимущество перед «Яблоком».
Данные, R-скрипт с предобработкой данных и R-скрипты для shiny приложения доступны на GitHub.
Во второй части статьи вы найдете диаграммы с результатами голосования по участковым комиссиям.
Эти графики показывают необычные закономерности в исследуемых данных.
