Интервью с вице-президентом по технологической стратегии компании MapR
 Я: На протяжении нескольких лет масштабируемая файловая система являлась уникальной особенностью архитектуры MapR. Сейчас же само хранение данных становится все дешевле и дешевле, а пользователи больше заинтересованы в гибкости и производительности системы. Расскажите какие новые ключевые решения в развитии MapR, должны ответить на растущие требования потребителей.
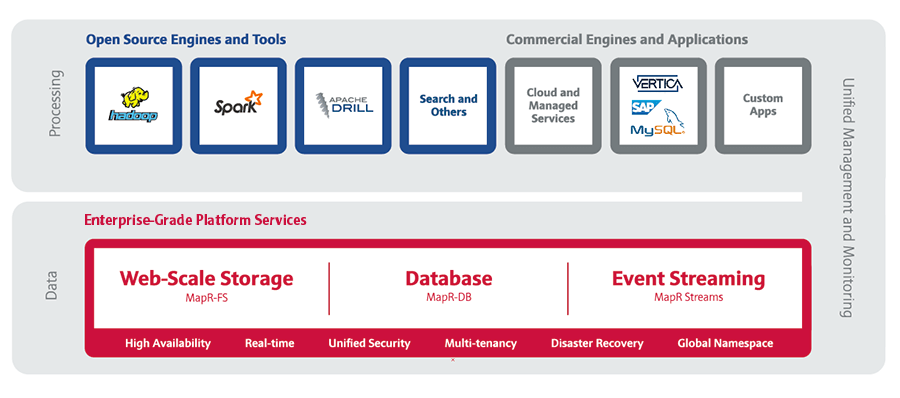
Я: На протяжении нескольких лет масштабируемая файловая система являлась уникальной особенностью архитектуры MapR. Сейчас же само хранение данных становится все дешевле и дешевле, а пользователи больше заинтересованы в гибкости и производительности системы. Расскажите какие новые ключевые решения в развитии MapR, должны ответить на растущие требования потребителей.Кристал (далее К): Компания MapR прошла довольно долгий и непростой путь с момента начала своей истории в 2009 году. По мере своего развития компания внедряла череду ведущих отраслевых инноваций, и сегодня все эти инновации собраны воедино в Конвергентной Платформе Данных MapR (далее CDP MapR).
Когда MapR впервые вышла на рынок в 2011 году, она получила известность благодаря корпоративной системе Hadoop, построенной на основе файловой системы MapR, запатентованного высокопроизводительного масштабируемого слоя хранения данных, который поддерживает Apache HDFS API. Этот продукт был признан Forrester (компанией в США, занимающейся независимыми исследованиями в области технологий и рынка) лучшей Hadoop-платформой.
В 2013 году компания представила рынку MapR DB — NoSQL базу с поддержкой Apache HBase API. Forrester также отметил этот продукт как лучшую NoSQL базу данных. Позже в MapR DB была добавлена поддержка JSON документов, а в 2014 году появился Apache Drill. Он был признан лучшим инструментом SQL по версии Gigaom (Медиа компания в Калифорнии).
В прошлом году MapR представила продукт MapR Streams — масштабируемую систему передачи сообщений, поддерживающую Apache Kafka API и обладающую высокой производительностью и высокой пропускной способностью.
Безусловно, каждый из этих инструментов может быть использован поодиночке, многие из них были признаны лучшими в своем сегменте. Но, на мой взгляд, максимальный эффект от использования CDP MapR возникает при работе всех этих продуктов — большого хранилища данных различного уровня доступности, масштабируемой NoSQL и потоковой передачи и хранения сообщений — на единой платформе. В CDP все файлы, таблицы и потоки — находящиеся потенциально в нескольких центрах обработки данных — могут быть доступны в едином пространстве. Платформа поддерживает множество различных вычислительных систем (включая MapReduce, Spark, YARN jobs и многие другие) с многопользовательским доступом. Это дает возможность создавать приложения с современной архитектурой, когда старые данные используются вместе с новыми источниками данных на высокопроизводительной платформе.
В будущем также ожидается внедрение очень интересных инновационных продуктов и опций. Например, недавно мы объявили о том, что CDP будет поддерживать микросервисы.
Я: Какие значительные релизы Вы предвидите на рынке больших данных и машинного обучения в ближайшее время?
К: Мы живем в необыкновенно захватывающее и крутое время, потому что большая часть теорий машинного обучения и искусственного интеллекта была разработана еще в 50-е годы, но только сейчас у нас есть достаточно мощные платформы больших данных, которые способны поддержать эти нагруженные данными алгоритмы в том масштабе, скорости и стоимости, которые позволяют воплотить эти теории в жизнь.
Рынок растет невероятно быстро. Сложно обозначить какой-то один конкретный продукт. Но я думаю, мы увидим серьезное развитие некоторых секторов, а именно, интернет вещей, облачные вычисления (в частности, гибридные облака или приложения, которые способны использовать несколько центров обработки данных), микросервисы (которые имеют ряд преимуществ и идеально подходят для обучения и валидации моделей машинного обучения), а также deep learning.
Я: Когда три года назад MapR установил партнерские отношения с Skytree, это был большой шаг в правильном, но неизведанном направлении. Теперь преимущества этого направления очевидны и понятны для всех. Но не кажется ли вам, что сейчас на рынке машинного обучения продукты с открытым исходным кодом более востребованы, чем патентованные?
К: Преимущество CDP — возможность дать пользователям широкий выбор инструментов и тем самым обеспечить гибкость процесса анализа и обработки данных. Да, безусловно, продукты с открытым исходным кодом быстро развиваются. Но многие клиенты ищут таких партнеров, как SkyTree, чтобы обеспечить быстрый старт за счет применения уже разнообразных алгоритмов и моделей машинного обучения. В конце концов, мы хотим предоставить свободу разработчикам приложений. CDP предоставляет такую возможность и улучшает работу приложений, независимо от того, используют ли они open source продукты или проприетарные системы.
MapR Converged Data Platform
Я: Как по вашему, Spark и Hadoop конкурируют между собой? Или все-таки эти технологии скорее дополняют друг друга? Что из них Вы бы посоветовали для построения инфраструктуры бизнеса?
К: Рынок больших данных имеет достаточно комплексный характер. На сегодня потребитель располагает широким выбором open source решений, сфокусированных на применении какого-то одного подхода к обработке данных. В результате приложения с более комплексными характеристиками часто требуют сложных, составных архитектур, состоящих из сразу нескольких решений, работающих на разных кластерах и соединенных набором протоколов.
Одно из таких решений — Apache Spark. Не так давно Apache Spark начал набирать популярность, потому что он использует методы, позволяющие упростить операции ввода-вывода по сравнению с традиционным подходом, который Apache реализовал в виде MapReduce заданий, а также поскольку Apache Spark предлагает в своем API больше инструментов, чем Map Reduce.
Однако Spark не располагает собственным слоем хранения данных, поэтому бывает, что он работает на кластере MapR или Apache Hadoop. Поэтому, отвечая на Ваш вопрос, могу сказать, что они, скорее, дополняют друг друга. Хотя на сегодняшний день очевидно, что пользователи скорее предпочитают Apache Spark чем «просто» Map Reduce задания. Но тут следует четко понимать разницу между вычислительной системой и инфраструктурой. В конце концов, и Spark, и Hadoop позволяют разрабатывать интересные приложения, но для крупных организаций было бы разумно иметь целостный подход к своим данным, а именно — использовать платформу, способную поддерживать как Hadoop, так и Spark наряду со многими другими вычислительными системами.
Я: Известно, что MapR и Google — компании-партнеры, MapR предоставляет услуги на базе облака Google. Как вы думаете, какое влияние на ваш продукт окажет чип Tensor Processing?
К: Вообще у MapR имеются партнерские отношения со всем крупными поставщиками облачных технологий, включая Google Cloud. И, кстати говоря, Google Capital — один из наших инвесторов. У нас обширная партнерская программа, в том числе с Amazon Web Services, Microsoft Azure и CenturyLink Cloud.
Мы убеждены, что облачные вычислительные платформы в будущем продолжат завоевывать рынок. Поэтому с одной стороны мы хотим развивать те вычислительные системы, которые наши клиенты пожелают использовать, и с другой стороны, мы хотим дать им возможность использовать ту инфраструктуру, которая удобна для них, будь то локальная инфраструктура (on-premise) или общедоступная или даже сочетание обоих видов.
Google Tensor Flow и TPU являются примером отличных инноваций, разрабатываемых поставщиком облачной технологии. Ведь в конце концов, алгоритмы машинного обучения (будут работать они на TPU или нет) только выигрывают от способности использовать большие наборы данных для обучения. Это, вкупе с возможностью поддержки потока данных в режиме реального времени и развитием гибкой микросервисной практики тестирования и тренировки множественных моделей, делает CDP очень привлекательной для тех клиентов, которые используют машинное обучение, в том числе и на Google Cloud.
Я: Расскажите о ваших любимых кейсах использования технологий MapR клиентами.
К: На самом деле, клиенты MapR, как правило, технически подкованные люди, они выбирают CDP, потому что сфокусированы на решении инновационных задач, значит, и платформа требуется такая, которая предоставит широкое поле для развития конкурентных преимуществ. Мне кажется, очень интересна сфера Adtech, поскольку это индустрия, развитие которой напрямую определяется технологией. Главное конкурентное преимущество компании, которая работает в этой сфере, должно состоять в качестве и скорости ее платформы. Во многих отношениях Adtech не существовало бы в том виде, в котором мы знаем эту сферу, если бы не огромные достижения в области вычислительных платформ.
Но в целом, мой любимый кейс — это проект Aadhaar, который был реализован правительством Индии. Население Индии крайне разнообразно, численность его — 1,3 миллиарда человек. Эти люди населяют 640000 деревень и говорят на 22 официальных языках. Огромное число рабочих — мигранты (300 миллионов), уровень бедности населения очень высок, 60% населения живут менее чем на 2$ в день. В стране проживают 75 миллионов бездомных людей. Правительство тратит около 40 миллиардов долларов в год на субсидии для бедных, включая питание, топливо, транспортировку. Но большая часть этих денег исчезла в неизвестном направлении из-за мошенничества и коррупции. Проблема заключалась в том, что в стране не было надежной государственной системы идентификации. Из-за низкого уровня грамотности населения правительство решило внедрить биометрическую базу данных, которая могла бы идентифицировать гражданина Индии на основе его отпечатков пальцев и сканирования радужной оболочки глаза.
Проект был запущен в 2009 году и работает на основе CDP MapR. На сегодняшний день более чем 1 миллиард жителей уже зарегистрирован в системе. Это составляет 95% взрослого населения Индии. Каждый день в системе регистрируются 500000 новых людей. Более 100 миллионов авторизаций выполняется системой ежедневно. Среднее время отклика — 200 милисекунд. Система использует зеркало MapR для большей доступности и для предотвращения ошибок, поэтому даже перебои электричества или сети не способны вывести ее из строя.
Я люблю этот кейс, поскольку он является прекрасным примером того, как технологии меняют жизни людей к лучшему. Правительственные субсидии в Индии наконец-то доходят до всех получателей и улучшают качество жизни тех, кто в этом нуждается.
Я: Какую стратегию Вы бы рекомендовали компаниям, которые пытаются интегрировать большие данные в их бизнес-стратегию?
К: Мы в MapR часто говорим о том, что компаниям необходимо разработать специальную стратегию данных. Понятия маркетинговой стратегии, технологической стратегии, ценовой стратегии привычны и понятны для бизнеса. Но сегодня этого мало, сегодня бизнесу также необходимо иметь стратегию данных. Все компании вне зависимости от индустрии сегодня признают, что огромные возможности скрыты в правильном использовании доступных им данных. Для того, чтобы сделать это наиболее эффективным образом, ИТ-компании должны поменять свой образ мышления. Теперь не приложения диктуют, какие данные необходимы. Теперь данные должны занимать центральное место. Использование платформы данных, которая предоставляет быстрый, безопасный и простой доступ ко всем данным организации, позволит ускорить развитие многих инновационных приложений.
