Выявляем волков в овечьей шкуре среди пользователей сайта

Привет. Я в свободное время развиваю свой небольшой сайт — платформу для ведения личных дневников. Похож на ЖЖ или Дайри, но более современный и молодежный, полузакрытый, уютный. И у нас есть необходимость отслеживать, когда пользователи создают себе дополнительные аккаунты. В этом посте хочу поделиться своими идеями и опытом, как это у нас реализовано.
Зачем это нужно
Сразу скажу, что у нас нет никакой рекламы, и мы никому данные пользователей не продаем. Коммерческого интереса у нас от сайта сейчас совсем никакого. И в целом, у нас многие сидят с нескольких аккаунтов. Это нормально.
Наше внимание привлекают два случая. Люди пытаются накручивать рейтинг, голосуя за свои посты и комментарии, либо дважды за чужие. Это нарушение правил. Либо дополнительные аккаунты используются для троллинга. Модератор может наложить ограничения на один аккаунт, но человеку это не страшно, если у него есть еще два. Такое тоже стараемся пресекать. Если твинки не отслеживать, обычные добросовестные пользователи вскоре просто сбегут с сайта.
Особенно забавно, когда новый аккаунт ведут от женского имени. Пишут о каких-то личных переживаниях, довольно эмоционально, но при этом сдержанно в деталях. Записи вызывают отклик у других пользователей, они обсуждают и поддерживают друг друга. Совершенно обычный дневник, ничто не вызывает подозрений. И только модераторы знают, что это парень-тролль.
Очевидно, проблему нельзя решить чисто технически простыми способами. Например, человек может всегда заходить в один аккаунт только из дома, а в другой — только с рабочего компьютера. Связать их между собой будет трудно. Или наоборот, реальный случай, когда три аккаунта появились почти одновременно и регулярно использовались только с одного адреса. Но оказалось, что это просто три друга, которые живут в одной квартире.
Поэтому мы можем только оценить вероятность, что два аккаунта управляются одним человеком. Еще от системы определения твинков хотелось бы, чтобы она минимально зависела от кода на клиенте. У нас и без того сайт рендерится не так быстро, как хотелось бы, поэтому не стоит грузить его лишними скриптами. К тому же, их работе могут помешать. И чтобы система была быстрой, простой в реализации и удобной в использовании.
Простые решения
Уникальный cookie
Можно сохранять в каждом браузере пользователя cookie c уникальной строкой. Тогда мы всегда легко сможем видеть, какие аккаунты используются из одного браузера.
Плюсы:
очень просто и быстро;
если строка совпадает, это гарантированно тот же браузер.
Минусы:
cookie можно удалить;
можно заходить через приватный режим;
можно заходить из разных контейнеров;
можно заходить из разных браузеров.
Первый минус решается способами вроде evercookie. Но это дополнительный потенциально тормозящий сайт код.
FingerprintJS
Можно идентифицировать браузер пользователя по набору его характеристик. Если браузеры двух пользователей совпадают по характеристикам, то скорее всего это один и тот же браузер.
Плюсы:
готовое простое решение;
если идентификаторы браузеров совпадают, то это с высокой вероятностью один тот же браузер.
Минусы:
это тяжелая клиентская библиотека;
чем выше точность определения, тем сильнее тормоза на клиенте;
не работает, если заходить из разных браузеров;
популярные скрипты отслеживания блокируются браузерами.
IP-адрес
Можно проверять адреса, с которых люди заходят в свои аккаунты. Если два аккаунта используются с одного адреса, возможно, это один и тот же человек.
Проблема — у большинства людей динамический адрес. Сегодня он используется одним человеком, а завтра другим. Если это мобильный оператор, что сейчас распространено, то адрес переназначается другому устройству вообще в течение получаса. А в случае GPON целый многоквартирный дом может ходить в интернет по одному адресу через NAT.
Плюсы:
также довольно просто и быстро;
работает полностью на сервере;
позволяет отслеживать вход с разных браузеров и даже с разных устройств.
Минусы:
Чуть менее простые решения
В итоге мы используем в собственной реализации все три эти метода в совокупности.
Идентификация браузера по заголовкам
Что, если попробовать составлять отпечаток браузера не на клиенте, а на сервере? Тогда это совсем не будет нагружать браузер и не будет блокироваться. Но точность определения, конечно, сильно снизится.
Все знают, что браузеры при каждом запросе отправляют заголовок User-Agent. Вариантов его значения довольно много. Есть еще три менее очевидных заголовка, которые можно использовать. Это Accept, Accept-Encoding и Accept-Language. Их значения зависят не только от самого браузера, но и от настроек системы. И есть совсем неочевидный заголовок Connection. Но я видел только два его варианта, поэтому решил не принимать во внимание.
Все эти заголовки различаются на разных устройствах и браузерах, но меняются довольно редко. В User-Agent раз в несколько недель при обновлении браузера увеличивается версия. Другие заголовки должны меняться еще реже.
Точность метода довольно низкая, поэтому добавим ограничение по времени. Множество людей могут пользоваться одинаковыми браузерами. Если один аккаунт завершил свою активность, а потом сразу же стал активен другой с такого же браузера, то предполагаем, что это один и тот же человек. Но чем больше пройдет времени, тем больше разных людей с таким же браузером будут пользоваться сайтом. Мы не можем связать их между собой только этим методом. Таким образом, нам важно отследить именно переключение между аккаунтами.
Считаем, что пользователь завершил свою текущую активность на сайте, если с последнего запроса прошло больше часа. Маловероятно, что человек всегда будет сидеть одновременно с двух аккаунтов. Чаще бывает, что используют аккаунты поочередно. При этом перелогиниваться необязательно, так как это могут быть разные контейнеры или приватный режим. Поэтому отслеживаем именно периоды активности из идущих с небольшим промежутком времени запросов.
Алгоритм
Читаем запрос клиента.
Если метод не GET, то пропускаем запрос, так как заголовки будут отличаться.
Считаем хеш-сумму нужных заголовков.
Записываем в базу первый и последний хеш за период активности пользователя.
Код подсчета отпечатка выглядит приблизительно так.
func browserID(req *http.Request) uint64 {
var id uint64
// для каждого заголовка считаем хеш-сумму
// и приписываем в конец id
// headers — это массив названий заголовков
for _, key := range headers {
val := headerFieldFunc(req, key)
id = (id << 8) + uint64(val)
}
return id
}
func headerFieldFunc(req *http.Request, key string) uint8 {
val := req.Header.Get(key)
// если заголовка в запросе нет, то возвращаем 255,
// так как это число не может получиться
// в результате подсчета хеш-суммы
if val == "" {
return 255
}
// считаем контрольную сумму
var s1, s2 uint32
for _, b := range []byte(val) {
s1 += uint32(b)
s2 += s1
}
s1 %= 15
s2 %= 15
return uint8((s2 << 4) | s1)
}Так как сервер у меня работает на Go, я написал небольшую библиотеку для составления отпечатков браузеров на Go. По умолчанию использует перечисленные четыре заголовка, можно добавлять свои. Для каждого заголовка считается контрольная сумма Флетчера. Сначала использовал 16-битную сумму, но и 8 бит должно быть достаточно. В результате получается 32-битное целое число — отпечаток браузера.
Результаты использования
За последние десять дней наш сайт использовали с 619 разных браузеров. И на них пришлось 378 уникальных отпечатка. То есть в среднем точность без учета временного ограничения составляет около 60%. При этом большую часть обеспечивает User-Agent — их всего 308. Остальные заголовки увеличивают точность еще примерно на четверть.
Но точность одинакова не всегда. Заголовки User-Agent почти одинаковые у большинства iPhone и у многих устройств на Windows 10, с точностью до номера версии. А вот не самые популярные смартфоны на Android могут быть определены почти стопроцентно. Это возможно благодаря тому, что браузеры передают в заголовке конкретную модель устройства и версию ОС. Вроде бы последнее время от этого решили отказаться как раз в целях защиты от отслеживания, но пока это много где еще остается.
Этот метод можно улучшить, добавив дополнительные заголовки. Например, включить в nginx определение региона по IP и писать его в запрос. Также можно со временем перейти с использования заголовка User-Agent на HTTP Client hints.
Идентификация устройства по характеристикам
Можно сказать, это свой самописный кусочек FingerprintJS. Я взял только те характеристики, которые относятся именно к устройству. Таким образом мы можем отследить вход в разные аккаунты на одном компьютере или смартфоне, даже если всегда используются разные браузеры.
Использованные свойства:
платформа,
количество процессоров,
распознаваемое количество одновременных касаний экрана,
разрешение экрана,
глубина цвета экрана,
часовой пояс.
Все эти свойства меняются очень редко и совпадают в разных браузерах. Также можно было бы брать информацию об ОС и модели из User-Agent, но ее легко подделать.
Браузеры перестали выдавать точные характеристики для защиты от отслеживания, но для нас выдаваемых значений достаточно. Дополнительно также используем ограничение по времени.
Алгоритм
Получаем значения нужных свойств через JS.
Склеиваем все в одну строку.
Считаем хеш-сумму строки.
Записываем в cookie, чтобы автоматически отправлять на сервер и не пересчитывать каждый раз.
На сервере также записываем первый и последний хеш за период активности пользователя.
let dev = Cookies.get("dev")
if(!dev) {
let w = window
let s = w.screen
let n = w.navigator
// склеиваем характеристики в строку
let isLs = ((screen.orientation || {}).type || "").startsWith("landscape")
dev = (n.platform || "no") + ";" + (n.hardwareConcurrency || 0) + ";" + (n.maxTouchPoints || 0) +
";" + (isLs ? s.width : s.height) + ";" + (isLs ? s.height : s.width) + ";" + s.colorDepth +
";" + new Date().getTimezoneOffset()
// считаем хеш-сумму
let a = 1, b = 0
for(let i = 0; i < dev.length; i++)
{
let c = dev.charCodeAt(i)
a += c
b += a
}
dev = b % 65521 * 65536 + a % 65521
dev = dev.toString(16)
Cookies.set("dev", dev, { expires: 1826, sameSite: "Lax" })
}Результаты использования
За последние десять дней метод позволяет различить 241 уникальных отпечатка устройства. То есть точность определения ниже, чем по отпечатку браузера. Но точно так же основная проблема в популярных устройствах вроде iPhone, которых много, и они одинаковы. Среди не самых модных смартфонов совпадения более редки.
Мы можем объединить два этих метода. Очевидно, что нам не нужно отслеживать совпадения отпечатков браузера при несовпадении устройств. В совокупности они дают 607 уникальных значений. То есть точность определения получается уже достаточно высокой.
Уникальное значение cookie
Первая версия. Генерируем случайное число — уникальный идентификатор прямо на клиенте и записываем в cookie.
Мы можем доверять в этом клиенту, так как подделывать идентификатор не имеет смысла. Нам не важно конкретное значение, важно только, чтобы оно не совпадало с чужими. А чтобы выдать себя за другого, человек должен как-то подсмотреть cookie в его браузере.
У нас около двух тысяч пользователей, у каждого по два-три устройства. Итого пять тысяч устройств. Достаточно хранить 32-битное целое, так как проблема совпадений не должна проявиться до 65 тысяч идентификаторов.
let uid = Cookies.get("uid")
if(!uid || uid === "0") {
let uid = Math.floor(Math.random() * 4294967296).toString(16)
Cookies.set("uid", uid, { expires: 1826, sameSite: "Lax" })
}Вторая версия. Все же у нас нет гарантии, что ГПСЧ браузеров не будут инициализированы одинаково. В теории возможно, что идентификаторы у разных людей все же совпадут. Поэтому лучше генерировать число на стороне сервера.
При первом логине пользователя в новом браузере считаем хеш-сумму от имени пользователя и соли. От хеша берем восемь байт для удобства хранения как 64-битное целое. На клиенте так же сохраняем это число в cookie. Таким образом, в случае очистки хранилища браузера или входа с нового устройства будет установлен тот же идентификатор. Это поможет связать браузеры между собой. При этом идентификатор не будет повторяться для других людей, и его будет сложно подделать. Если в том же браузере используется другой аккаунт, старый идентификатор остается в cookie.
func Uid2(user, salt string) string {
sum := sha256.Sum256([]byte(user + salt))
return hex.EncodeToString(sum[:8])
}Результаты использования
По задумке, это самый точный метод обнаружения. Количество различных браузеров выше я определяю именно по этому полю.
IP-адрес
Аналогично записываем адрес каждых первого и последнего запроса. Можно считать хеш-сумму, чтобы хранить меньше ПДн. Что тут еще добавить?
Результаты использования
За десять дней у нас в логе 2484 адреса. Как видно, они меняются очень часто. Сам по себе этот метод обычно дает мало информации.
Бэкенд
После обработки клиентского запроса различными сервисами и на различных этапах, все сходится в одном месте — в структуру userLog. Она хранит данные последних запросов и периодически сохраняет их в БД PostgreSQL.
type userLog struct {
db *sql.DB
log *zap.Logger
ch chan *userRequest
tick *time.Ticker
prev map[string]*userRequest
}
func CreateUserLog(db *sql.DB, log *zap.Logger) middleware.Builder {
ul := &userLog{
db: db,
log: log,
ch: make(chan *userRequest, 200),
tick: time.NewTicker(time.Hour),
prev: make(map[string]*userRequest),
}
// запускаем горутину для работы с БД
go ul.run()
// возвращаем функцию-обработчик HTTP-запросов
return func(handler http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ul.ServeHTTP(w, r)
handler.ServeHTTP(w, r)
})
}
}В обработчике запроса читаем созданные на предыдущих этапах HTTP-заголовки и сохраняем в структуру userRequest. Затем через канал передаем ее в горутину. Структура определена так.
type userRequest struct {
user string
ip string
ua string
dev string
app string
uid string
at time.Time
}В горутине ожидаем новые запросы и по таймеру сбрасываем старые запросы в БД.
func (ul *userLog) run() {
for {
select {
case <-ul.tick.C:
// переносим старые запросы из словаря в БД
ul.clearOld()
case req := <-ul.ch:
// добавляем запрос в словарь
ul.addRequest(req)
}
}
}При добавлении нового запроса проверяем, есть ли уже такой ключ в словаре. Если да, то просто обновляем последнее время запроса. Если нет, то добавляем запрос в словарь и сохраняем в БД как начало периода активности. Ключ — это IP плюс браузер, плюс устройство, плюс уникальное значение cookie, плюс имя пользователя.
func (ul *userLog) addRequest(req *userRequest) {
key := req.key()
prevReq, found := ul.prev[key]
if found {
prevReq.at = req.at
return
}
ul.prev[key] = req
ul.save(req, true)
}
func (req userRequest) key() string {
var str strings.Builder
str.Grow(68)
str.WriteString(req.ip)
str.WriteString(req.dev)
str.WriteString(req.app)
str.WriteString(req.uid)
str.WriteString(req.user)
return str.String()
}Периодически записываем завершенные периоды активности в таблицу. Таблица объявлена так.
CREATE TABLE "user_log" (
"name" Text NOT NULL,
"user_agent" Text NOT NULL,
"ip" Inet NOT NULL,
"device" Integer NOT NULL,
"app" Bigint NOT NULL,
"uid" Integer NOT NULL,
"at" Timestamp With Time Zone NOT NULL,
"first" Boolean NOT NULL -- true, если это начала периода
);Использование
Как сделать это все удобным в использовании? Конечно, надо написать Телеграм-бот. Тем более, у нас на сайте уже есть бот, который отправляет пользователям уведомления о новых событиях. Достаточно только добавить в него пару модераторских команд.
По команде сначала проверяем, существует ли вообще такой аккаунт в системе. Если да, то ищем в таблице совпадения по IP, браузеру, устройству и уникальному идентификатору.
// поиск совпадений по IP, другие запросы аналогичны
sqlf.Select("ul.name, COUNT(*) AS cnt").
From("user_log AS ul").
Where("ul.name <> lower(?)", user).
Where("ol.name = lower(?)", user).
Where("ul.first <> ol.first").
GroupBy("ul.name").
OrderBy("cnt DESC").
Limit(10).
Join("user_log AS ol", "ul.ip = ol.ip").
Where("(CASE WHEN ul.at > ol.at THEN ul.at - ol.at ELSE ol.at - ul.at END) < interval '1 hour'")
Вот пример выполнения команды. Совпадения по IP, устройству и браузеру показаны в течение коротких промежутков времени, совпадения по идентификатору в cookie — за все время. Совпадения по браузеру учитываются только в совокупности с устройством. В скобках указано количество совпадений с каждым аккаунтом. Чем это число выше относительно других, тем менее вероятна случайность.
Здесь совершенно определенно видно, что я использую два аккаунта. Вторым пунктом в список по IP попала моя знакомая. Вероятно, это тот день, когда я заходил на сайт у нее в гостях. А третий пункт — это совершенно случайное совпадение. Мы живем в одном городе, но никогда не виделись. Также видно много людей, случайно совпавших по устройству.
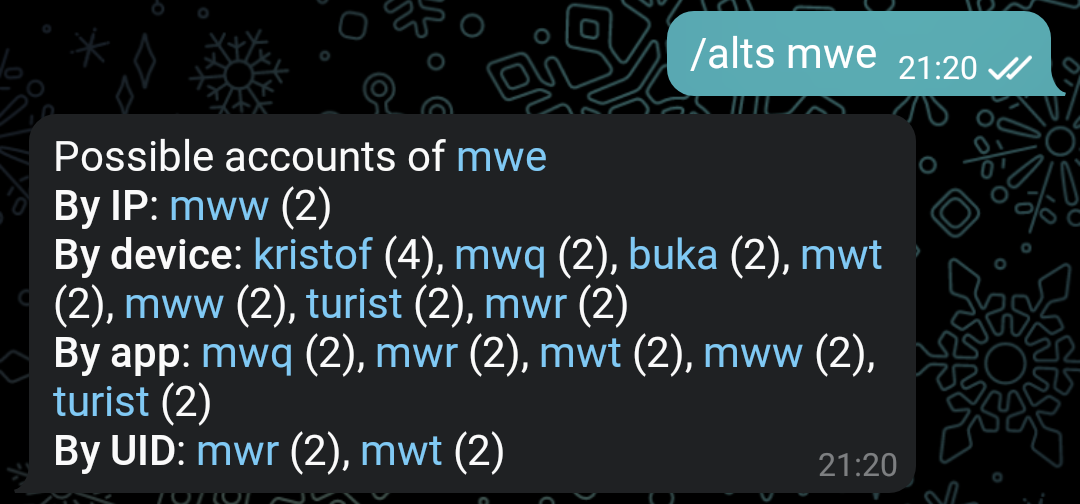
А тут у человека закончилась фантазия для новых ников. Все восемь аккаунтов — одно и то же лицо. Похоже, что он очищал хранилище браузера, и у него часто менялись адреса. Но все равно аккаунты нашлись.
Второй вариант использования — сравнение двух аккаунтов, чтобы проверить свои подозрения. Сначала также проверяем, существуют ли пользователи в системе. Потом загружаем списки совпадающих и различных IP и User-Agent.
// поиск совпадений по IP
sqlf.Select("COUNT(*) AS cnt, MIN(ul.at), MAX(ul.at)").
Select("ul.ip").
From("user_log AS ul").
Where("ul.name = lower(?)", userA).
Where("ol.name = lower(?)", userB).
Where("ul.first <> ol.first").
Where("(CASE WHEN ul.at > ol.at THEN ul.at - ol.at ELSE ol.at - ul.at END) < interval '1 hour'").
Join("user_log AS ol", "ul.ip = ol.ip").
OrderBy("cnt DESC").
GroupBy("ul.ip").
Limit(10)
// поиск различий по IP
sub := sqlf.Select("*").From("user_log").Where("name = ?", b)
sqlf.Select("COUNT(*) AS cnt, MIN(ol.at), MAX(ol.at)").
Select("ol.ip").
From("").SubQuery("(", ") AS ul", sub).
Where("ol.name = lower(?)", a).
Where("ul.ip IS NULL").
RightJoin("user_log AS ol", "ul.ip = ol.ip").
OrderBy("cnt DESC").
GroupBy("ol.ip").
Limit(10)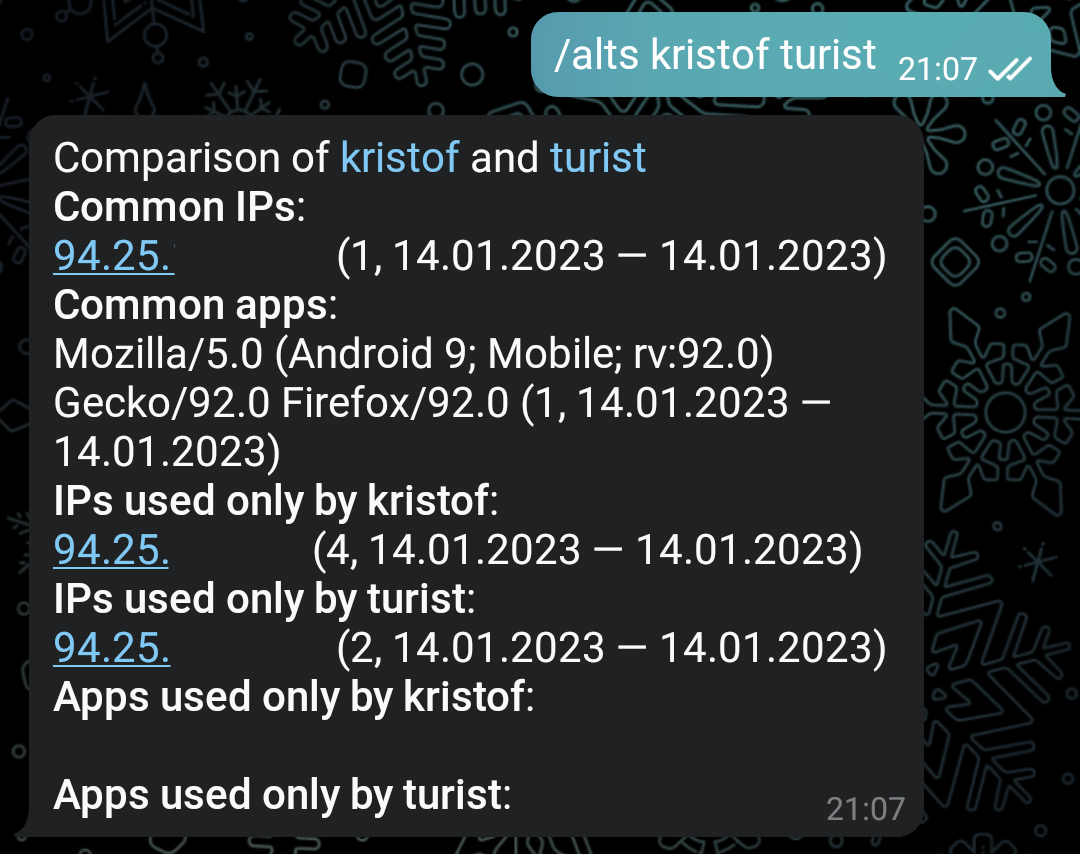
Вот пример выполнения команды. Есть совпадающие IP и User-Agent, также есть входы с разных адресов, но ни одного входа с различающихся User-Agent. Дальше можно выяснить провайдера, которому принадлежат адреса, и оценить распространенность устройства. После этого принимать решение о необходимости дальнейших действий.
Итоги
Большинство твинков однозначно видно по идентификатору в cookie. Если человек очищает хранилище в браузере или заходит через приватный режим, его все равно видно по IP, браузеру и устройству. Если человек заходит из другого браузера, остается IP и устройство. Если даже человек заходит с другого устройства, вероятнее всего в логе будет совпадение IP. Либо наоборот, если меняется адрес, то человек может попасться по другим методам. Но в последних случаях требуется дополнительно проверить, что это не ложное срабатывание.
В таком виде система довольно успешно работает уже больше года. Мы вычислили и удалили или забанили множество аккаунтов троллей. Но в точности оценить эффективность трудно. Если мы не нашли чей-то твинк этими способами, то не нашли его никак. В будущем хотелось бы еще больше автоматизировать и увеличить точность поиска твинков, но пока до этого не доходят руки.
